
美團(tuán)優(yōu)選大數(shù)據(jù)開發(fā)崗面試真題-附答案詳細(xì)解析
此面試題來(lái)自牛客網(wǎng)友分享的美團(tuán)優(yōu)選一面,面試時(shí)長(zhǎng)一小時(shí)。網(wǎng)友情況:海外水本,在某三線中廠工作2年。
參考答案由本公眾號(hào)提供。如有錯(cuò)誤,歡迎指正!
以下為面試過(guò)程中提問(wèn),崗位為大數(shù)據(jù)開發(fā),根據(jù)提問(wèn)內(nèi)容看出,主要偏數(shù)倉(cāng)方向
自我介紹 到北京工作的意愿 SQL題,給一張城市和交易額表,一張城市對(duì)應(yīng)省份表, 取出 省份 總 交易額大于 500 的 省份 的名字 SQL題,基于剛才, 得出 省份 總 交易額 [0,500 ] , [500,1000 ] , [1000,+∞ ] 在以下三個(gè)區(qū)間的 省份 的 數(shù)量 SQL題,還是基于剛才, 按從小到大的順序得出每個(gè)城市的累計(jì)交易額,可以用窗口 根據(jù)分隔符劃分字段,可以用正則表達(dá) 主要負(fù)責(zé)的產(chǎn)品 產(chǎn)品的指標(biāo)如何知道帶來(lái)多少價(jià)值 指標(biāo)如何做到精準(zhǔn) 就項(xiàng)目中提到的某個(gè)實(shí)體,講一下他對(duì)應(yīng)的屬性有哪些 如果你建模的話,你會(huì)如何建模 主要都抽取哪些數(shù)據(jù)源,使用什么工具 描述一下抽取的內(nèi)部邏輯,怎么實(shí)現(xiàn)的 除了工作,有去讀什么書學(xué)習(xí)嗎 你覺(jué)得flink和spark streaming有什么區(qū)別 spark streaming相比f(wàn)link有什么優(yōu)點(diǎn) 有什么想問(wèn)的嗎
答案詳細(xì)解析
1. 自我介紹
面試的時(shí)候,面試官說(shuō)的第一句話就是:“介紹一下你自己吧。”
很多人真的很實(shí)誠(chéng)的就只說(shuō)一句:“我叫xx,來(lái)自xx,今年xx歲。”然后雙方冷場(chǎng)。
這樣的自我介紹還不如前段時(shí)間流行的一句話:“我叫xx,我喜歡唱跳、rap、籃球。”起碼你還讓面試官知道了你的特長(zhǎng)。
所以這里就需要你用最短的時(shí)間讓面試官記住你,突出自己的優(yōu)勢(shì)、有論證力的說(shuō)服對(duì)方。
原則如下:不要大段背誦簡(jiǎn)歷內(nèi)容;不要說(shuō)流水賬,內(nèi)容冗長(zhǎng);自我介紹時(shí)間盡量控制在一分鐘左右。
那么怎么在最短時(shí)間內(nèi)滿足以上三條。
羅振宇說(shuō)過(guò):“笨拙的人講道理,而聰明的人會(huì)說(shuō)故事。”
所以面試時(shí)我們要擺脫常規(guī)回答,學(xué)會(huì)“講故事”。那故事怎么講,記住以下八個(gè)字,將自己的經(jīng)歷或想法套進(jìn)去:
目標(biāo):就是我想要做什么,我想要成為什么樣的人;
阻礙:做這件事的難點(diǎn)是什么,有哪些“質(zhì)疑”點(diǎn);
努力:為了克服難點(diǎn)和“質(zhì)疑”,我做了哪些事情;
結(jié)果:通過(guò)我的努力,我現(xiàn)在獲得了什么樣的成就。
有時(shí)間了針對(duì) 自我介紹 我再詳細(xì)的講解下,這部分還是很重要的,因?yàn)檫@部分就是“推銷”自己,給自己打廣告的時(shí)間。
2. 到北京工作的意愿
招人肯定是希望找到一個(gè)踏實(shí),穩(wěn)定的人,而不是那種來(lái)了幾天或一段時(shí)間就走的人。面試官問(wèn)你這個(gè)問(wèn)題,一是在看你大概能在公司呆多久,二是看公司是否有必要培養(yǎng)你或者錄用你。
所以回答時(shí)一定要表達(dá)出你一定能來(lái)北京并且能長(zhǎng)時(shí)間待下去(即使你不是這樣),具體回答發(fā)揮個(gè)人想象。
3. SQL題,給一張城市和交易額表,一張城市對(duì)應(yīng)省份表, 取出 省份 總 交易額大于 500 的 省份 的名字
為了便于理解,根據(jù)上面的問(wèn)題,我們先構(gòu)造這兩張表:
城市交易額表 business_table
city_num:城市編號(hào)
gmv:交易額
| city_num | gmv |
|---|---|
| 1001 | 210 |
| 1001 | 90 |
| 1002 | 250 |
| 1003 | 200 |
| 1004 | 700 |
| 1005 | 350 |
| 1005 | 150 |
| 1006 | 250 |
| 1007 | 150 |
城市對(duì)應(yīng)省份表:province_table
province_num:省份編號(hào)
province_name:省份名稱
city_num:城市編號(hào)
| province_num | province_name | city_num |
|---|---|---|
| 11 | a | 1001 |
| 11 | a | 1005 |
| 12 | b | 1002 |
| 12 | b | 1003 |
| 13 | c | 1004 |
| 13 | c | 1006 |
| 13 | c | 1007 |
根據(jù)以上表,sql 語(yǔ)句如下(以下僅為其中一種寫法,僅供參考)
SELECT MAX(tmp.province_name)
FROM (
SELECT bt.city_num, bt.gmv, pt.province_num, pt.province_name
FROM business_table bt
LEFT JOIN province_table pt ON bt.city_num = pt.city_num
) tmp
GROUP BY tmp.province_num
HAVING SUM(tmp.gmv) > 500;
4. SQL題,基于剛才, 得出 省份 總 交易額 [0,500 ] , [500,1000 ] , [1000,+oo ] 在以下三個(gè)區(qū)間的 省份 的 數(shù)量
參考 sql 語(yǔ)句如下:
SELECT
COUNT(CASE
WHEN tmp2.pro_gmv >= 0
AND tmp2.pro_gmv < 500 THEN tmp2.pro_name
ELSE NULL END) AS gmv_0_500,
COUNT(CASE
WHEN tmp2.pro_gmv >= 500
AND tmp2.pro_gmv < 1000 THEN tmp2.pro_name
ELSE NULL END) AS gmv_500_1000,
COUNT(CASE
WHEN tmp2.pro_gmv >= 1000 THEN tmp2.pro_name
ELSE NULL END) AS gmv_1000_
FROM (
SELECT MAX(tmp.province_name) AS pro_name, SUM(tmp.gmv) AS pro_gmv
FROM (
SELECT bt.city_num, bt.gmv, pt.province_num, pt.province_name
FROM business_table bt
LEFT JOIN province_table pt ON bt.city_num = pt.city_num
) tmp
GROUP BY tmp.province_num
) tmp2;
5. SQL題,還是基于剛才, 按從小到大的順序得出每個(gè)城市的累計(jì)交易額,可以用窗口
參考 sql 語(yǔ)句如下:
# 既然面試官讓用窗口函數(shù),那咱們就別客氣了
SELECT city_num, gmv
FROM (
SELECT DISTINCT city_num, SUM(gmv) OVER(PARTITION BY city_num) AS gmv
FROM business_table
) tmp
ORDER BY gmv;
6. 根據(jù)分隔符劃分字段,可以用正則表達(dá)
# java
String address="上海|上海市|閔行區(qū)|吳中路";
String[] splitAddress=address.split("\\|"); //如果以豎線為分隔符,則split的時(shí)候需要加上兩個(gè)斜杠 \\ 進(jìn)行轉(zhuǎn)義
#sql
hive> select split('abcdef', 'c') from test;
["ab", "def"]
7. 主要負(fù)責(zé)的產(chǎn)品
這個(gè)根據(jù)簡(jiǎn)歷或者你自己的情況實(shí)際實(shí)說(shuō)就行。
8. 產(chǎn)品的指標(biāo)如何知道帶來(lái)多少價(jià)值
這題沒(méi)有標(biāo)準(zhǔn)答案,根據(jù)自己的理解回答即可。
以下僅供參考:
在《精益數(shù)據(jù)分析》一書中給出了兩套比較常用的指標(biāo)體系建設(shè)方法論,其中一個(gè)就是比較有名的海盜指標(biāo)法,也就是我們經(jīng)常聽到的AARRR海盜模型。海盜模型是用戶分析的經(jīng)典模型,它反映了增長(zhǎng)是系統(tǒng)性地貫穿于用戶生命周期各個(gè)階段的:用戶拉新(Acquisition)、用戶激活(Activation)、用戶留存(Retention)、商業(yè)變現(xiàn)(Revenue)、用戶推薦(Referral)。
為什么要說(shuō)這個(gè)模型呢,因?yàn)橥ㄟ^(guò)這個(gè)模型中的一些關(guān)鍵指標(biāo)我們可以反推出產(chǎn)品的指標(biāo)所帶來(lái)的價(jià)值有哪些。
AARRR模型:
A 拉新: 通過(guò)各種推廣渠道,以各種方式獲取目標(biāo)用戶,并對(duì)各種營(yíng)銷渠道的效果評(píng)估,不斷優(yōu)化投入策略,降低獲客成本。涉及關(guān)鍵指標(biāo)例如 新增注冊(cè)用戶數(shù)、激活率、注冊(cè)轉(zhuǎn)化率、新客留存率、下載量、安裝量等,我們通過(guò)這些指標(biāo)就可反應(yīng)出獲取目標(biāo)用戶的效果是怎樣的。
A 活躍:活躍用戶指真正開始使用了產(chǎn)品提供的價(jià)值,我們需要掌握用戶的行為數(shù)據(jù),監(jiān)控產(chǎn)品健康程度。這個(gè)模塊主要反映用戶進(jìn)入產(chǎn)品的行為表現(xiàn),是產(chǎn)品體驗(yàn)的核心所在。涉及關(guān)鍵指標(biāo)例如 DAU/MAU 、日均使用時(shí)長(zhǎng)、啟動(dòng)APP時(shí)長(zhǎng)、啟動(dòng)APP次數(shù)等。通過(guò)這些指標(biāo)可以反映出用戶的活躍情況。
R 留存:衡量用戶粘性和質(zhì)量的指標(biāo)。涉及關(guān)鍵指標(biāo)例如 留存率、流失率等。通過(guò)這些指標(biāo)可以反映出用戶的留存情況。
R 變現(xiàn): 主要用來(lái)衡量產(chǎn)品商業(yè)價(jià)值。涉及關(guān)鍵指標(biāo)例如 生命周期價(jià)值(LTV)、客單價(jià)、GMV等。這些指標(biāo)可以反映出產(chǎn)品的商業(yè)價(jià)值。
R 推薦:衡量用戶自傳播程度和口碑情況。涉及關(guān)鍵指標(biāo)例如 邀請(qǐng)率、裂變系數(shù)等。
9. 指標(biāo)如何做到精準(zhǔn)
同上題,沒(méi)有標(biāo)準(zhǔn)答案。
僅供參考:
指標(biāo)要做到精準(zhǔn),就必須使用科學(xué)方法選指標(biāo)。
選指標(biāo)常用方法是指標(biāo)分級(jí)方法和OSM模型。
1. 指標(biāo)分級(jí)方法:指標(biāo)分級(jí)主要是指標(biāo)內(nèi)容縱向的思考,根據(jù)企業(yè)戰(zhàn)略目標(biāo)、組織及業(yè)務(wù)過(guò)程進(jìn)行自上而下的指標(biāo)分級(jí),對(duì)指標(biāo)進(jìn)行層層剖析,主要分為三級(jí)T1、T2、T3。
T1指標(biāo):公司戰(zhàn)略層面指標(biāo) 用于衡量公司整體目標(biāo)達(dá)成情況的指標(biāo),主要是決策類指標(biāo),T1指標(biāo)使用通常服務(wù)于公司戰(zhàn)略決策層。
T2指標(biāo):業(yè)務(wù)策略層面指標(biāo) 為達(dá)成T1指標(biāo)的目標(biāo),公司會(huì)對(duì)目標(biāo)拆解到業(yè)務(wù)線或事業(yè)群,并有針對(duì)性做出一系列運(yùn)營(yíng)策略,T2指標(biāo)通常反映的是策略結(jié)果屬于支持性指標(biāo)同時(shí)也是業(yè)務(wù)線或事業(yè)群的核心指標(biāo)。T2指標(biāo)是T1指標(biāo)的縱向的路徑拆解,便于T1指標(biāo)的問(wèn)題定位,T2指標(biāo)使用通常服務(wù)業(yè)務(wù)線或事業(yè)群。
T3指標(biāo):業(yè)務(wù)執(zhí)行層面指標(biāo) T3指標(biāo)是對(duì)T2指標(biāo)的拆解,用于定位T2指標(biāo)的問(wèn)題。T3指標(biāo)通常也是業(yè)務(wù)過(guò)程中最多的指標(biāo)。根據(jù)各職能部門目標(biāo)的不同,其關(guān)注的指標(biāo)也各有差異。T3指標(biāo)的使用通常可以指導(dǎo)一線運(yùn)營(yíng)或分析人員開展工作,內(nèi)容偏過(guò)程性指標(biāo),可以快速引導(dǎo)一線人員做出相應(yīng)的動(dòng)作。
2. OSM模型(Obejective,Strategy,Measurement):是指標(biāo)體系建設(shè)過(guò)程中輔助確定核心的重要方法,包含業(yè)務(wù)目標(biāo)、業(yè)務(wù)策略、業(yè)務(wù)度量,是指標(biāo)內(nèi)容橫向的思考。
O:用戶使用產(chǎn)品的目標(biāo)是什么?產(chǎn)品滿足了用戶的什么需求?主要從用戶視角和業(yè)務(wù)視角確定目標(biāo),原則是切實(shí)可行、易理解、可干預(yù)、正向有益。
S:為了達(dá)成上述目標(biāo)我采取的策略是什么?
M:這些策略隨之帶來(lái)的數(shù)據(jù)指標(biāo)變化有哪些?
10. 就項(xiàng)目中提到的某個(gè)實(shí)體,講一下他對(duì)應(yīng)的屬性有哪些
實(shí)際項(xiàng)目問(wèn)題,根據(jù)簡(jiǎn)歷中寫的敘述。
這里也給我們提個(gè)醒:簡(jiǎn)歷中所寫的項(xiàng)目我們必須非常熟悉才行,并且我們需要熟悉所寫項(xiàng)目的整個(gè)生命周期,包括項(xiàng)目開發(fā) 前中后 期的所有內(nèi)容,說(shuō)的時(shí)候可以比簡(jiǎn)歷上寫的更詳細(xì),但是千萬(wàn)不能和簡(jiǎn)歷上有出入。
11. 如果你建模的話,你會(huì)如何建模
具體的建模可看這篇文章:數(shù)倉(cāng)建設(shè)中最常用模型--Kimball維度建模詳解
以下內(nèi)容截取自上述文章
提到建模,就牢記維度建模四步走,模型怎么建,就圍繞以下四步敘說(shuō):
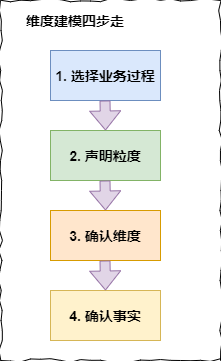
1、選擇業(yè)務(wù)過(guò)程
維度建模是緊貼業(yè)務(wù)的,所以必須以業(yè)務(wù)為根基進(jìn)行建模,那么選擇業(yè)務(wù)過(guò)程,顧名思義就是在整個(gè)業(yè)務(wù)流程中選取我們需要建模的業(yè)務(wù),根據(jù)運(yùn)營(yíng)提供的需求及日后的易擴(kuò)展性等進(jìn)行選擇業(yè)務(wù)。
2、聲明粒度
從關(guān)注原子粒度開始設(shè)計(jì),也就是從最細(xì)粒度開始,因?yàn)樵恿6饶軌虺惺軣o(wú)法預(yù)期的用戶查詢。但是上卷匯總粒度對(duì)查詢性能的提升很重要的,所以對(duì)于有明確需求的數(shù)據(jù),我們建立針對(duì)需求的上卷匯總粒度,對(duì)需求不明朗的數(shù)據(jù)我們建立原子粒度。
3、確認(rèn)維度
維度表是作為業(yè)務(wù)分析的入口和描述性標(biāo)識(shí),所以也被稱為數(shù)據(jù)倉(cāng)庫(kù)的“靈魂”。聲明完粒度之后,就要確定哪些屬性是維度,那么怎么確定哪些屬于維度屬性呢,這里就不詳細(xì)展開了,可以點(diǎn)擊上面的文章鏈接,有詳細(xì)說(shuō)明。
4、確認(rèn)事實(shí)
維度建模的核心原則之一是同一事實(shí)表中的所有度量必須具有相同的粒度。這樣能確保不會(huì)出現(xiàn)重復(fù)計(jì)算度量的問(wèn)題。有時(shí)候往往不能確定該列數(shù)據(jù)是事實(shí)屬性還是維度屬性。記住最實(shí)用的事實(shí)就是數(shù)值類型和可加類事實(shí)。
這塊內(nèi)容太多了,說(shuō)完以上四步之后可以在具體的聊下數(shù)倉(cāng)是怎么分層的,每層都存放什么數(shù)據(jù)等。具體文章可點(diǎn)擊:結(jié)合公司業(yè)務(wù)分析離線數(shù)倉(cāng)建設(shè)
12. 主要都抽取哪些數(shù)據(jù)源,使用什么工具
根據(jù)簡(jiǎn)歷的項(xiàng)目回答。
以下僅供參考,主要抽取的數(shù)據(jù):
業(yè)務(wù)庫(kù)數(shù)據(jù),使用sqoop進(jìn)行抽取 流量日志數(shù)據(jù),使用flume實(shí)時(shí)采集 第三方公司數(shù)據(jù),使用通用接口采集
13. 描述一下抽取的內(nèi)部邏輯,怎么實(shí)現(xiàn)的
根據(jù)簡(jiǎn)歷的項(xiàng)目回答。
以下僅供參考:
在開始創(chuàng)建抽取系統(tǒng)之前,需要一份邏輯數(shù)據(jù)映射,它描述了那些提交到前臺(tái)的表中原始字段和最終目標(biāo)字段之間的關(guān)系。該文檔貫穿ETL系統(tǒng)。
設(shè)計(jì)邏輯:
有一個(gè)規(guī)劃 確定候選的數(shù)據(jù)源 使用數(shù)據(jù)評(píng)估分析工具分析源系統(tǒng) 接受數(shù)據(jù)線和業(yè)務(wù)規(guī)則的遍歷 充分理解數(shù)據(jù)倉(cāng)庫(kù)數(shù)據(jù)模型 驗(yàn)證計(jì)算和公式的有效性
邏輯數(shù)據(jù)映射的組成:目標(biāo)表名稱、表類型、SCD(緩慢變化維度)、源數(shù)據(jù)庫(kù)、源表名稱、源列名稱、轉(zhuǎn)換。
這個(gè)表必須清晰的描述在轉(zhuǎn)換的過(guò)程中包含的流程,不能有任何疑問(wèn)的地方。
表類型給了我們數(shù)據(jù)加載過(guò)程執(zhí)行的次序:先是維表,然后是事實(shí)表。與表類型一起,加載維表過(guò)程SCD類型很重要,開發(fā)之前需要理解哪些列需要保留歷史信息以及如何獲取歷史信息所需的策略。
在源系統(tǒng)得到確認(rèn)和分析之前,完整的邏輯數(shù)據(jù)映射是不存在的,源系統(tǒng)分析通常分為兩個(gè)主要階段:數(shù)據(jù)發(fā)現(xiàn)階段,異常檢測(cè)階段。
數(shù)據(jù)發(fā)現(xiàn)階段:需要ETL小組深入到數(shù)據(jù)的需求中,確定每一個(gè)需要加載到數(shù)據(jù)倉(cāng)庫(kù)中的源系統(tǒng),表和屬性,為每一個(gè)元素確定適當(dāng)?shù)脑椿蛘哂涗浵到y(tǒng)是一個(gè)挑戰(zhàn),必須仔細(xì)評(píng)估。
異常檢測(cè)階段:檢查源數(shù)據(jù)庫(kù)中每一個(gè)外鍵是否有NULL值。如果存在NULL值,必須對(duì)表進(jìn)行外關(guān)聯(lián)。如果NULL不是外鍵而是一個(gè)列,那么必須有一個(gè)處理NULL數(shù)據(jù)的業(yè)務(wù)規(guī)則。只要允許,數(shù)據(jù)倉(cāng)庫(kù)加載數(shù)據(jù)一定用默認(rèn)值代替NULL。
14. 除了工作,有去讀什么書學(xué)習(xí)嗎
僅供參考:
前段時(shí)間讀了《數(shù)倉(cāng)工具箱-維度建模權(quán)威指南》這本書,受益頗多,對(duì)維度建模有了一個(gè)清晰的認(rèn)知,維度建模就是時(shí)刻考慮如何能夠提供簡(jiǎn)單性,以業(yè)務(wù)為驅(qū)動(dòng),以用戶理解性和查詢性能為目標(biāo)的這樣一種建模方法。
目前正在讀《大數(shù)據(jù)日知錄:架構(gòu)與算法》,這本書涉及到的知識(shí)非常多,全面梳理了大數(shù)據(jù)存儲(chǔ)與處理的相關(guān)技術(shù),看書能讓我更加系統(tǒng)化,體系化的學(xué)習(xí)大數(shù)據(jù)的技術(shù)。
注:以上兩本書的電子版,可在
五分鐘學(xué)大數(shù)據(jù)公眾號(hào)后臺(tái)獲取,回復(fù)關(guān)鍵字:數(shù)倉(cāng)工具箱或大數(shù)據(jù)日知錄
15. 你覺(jué)得flink和spark streaming有什么區(qū)別
這個(gè)問(wèn)題是一個(gè)非常宏觀的問(wèn)題,因?yàn)閮蓚€(gè)框架的不同點(diǎn)非常之多。但是在面試時(shí)有非常重要的一點(diǎn)一定要回答出來(lái):Flink 是標(biāo)準(zhǔn)的實(shí)時(shí)處理引擎,基于事件驅(qū)動(dòng)。而 Spark Streaming 是微批( Micro-Batch )的模型。
下面就分幾個(gè)方面介紹兩個(gè)框架的主要區(qū)別:
架構(gòu)模型:
Spark Streaming 在運(yùn)行時(shí)的主要角色包括:Master、Worker、Driver、Executor; Flink 在運(yùn)行時(shí)主要包:Jobmanager、Taskmanager 和 Slot。 任務(wù)調(diào)度:
Spark Streaming 連續(xù)不斷的生成微小的數(shù)據(jù)批次,構(gòu)建有向無(wú)環(huán)圖 DAG, Spark Streaming 會(huì)依次創(chuàng)DStreamGraph、JobGenerator、JobScheduler; Flink 根據(jù)用戶提交的代碼生成 StreamGraph,經(jīng)過(guò)優(yōu)化生成 JobGraph,然后提交給JobManager 進(jìn)行處理, JobManager 會(huì)根據(jù) JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 調(diào)度最核心的數(shù)據(jù)結(jié)構(gòu),JobManager 根據(jù) ExecutionGraph 對(duì) Job 進(jìn)行調(diào)度。 時(shí)間機(jī)制:
Spark Streaming 支持的時(shí)間機(jī)制有限,只支持處理時(shí)間。 Flink 支持了流處理程序在時(shí)間上的三個(gè)定義:處理時(shí)間、事件時(shí)間、注入時(shí)間。同時(shí)也支持 watermark 機(jī)制來(lái)處理滯后數(shù)據(jù)。 容錯(cuò)機(jī)制:
對(duì)于 Spark Streaming 任務(wù),我們可以設(shè)置 checkpoint,然后假如發(fā)生故障并重啟,我們可以從上次 checkpoint 之處恢復(fù),但是這個(gè)行為只能使得數(shù)據(jù)不丟失,可能 會(huì)重復(fù)處理,不能做到恰好一次處理語(yǔ)義。 Flink 則使用兩階段提交協(xié)議來(lái)解決這個(gè)問(wèn)題。
Flink的兩階段提交協(xié)議具體可以看這篇文章:八張圖搞懂 Flink 端到端精準(zhǔn)一次處理語(yǔ)義 Exactly-once
16. Spark Streaming相比Flink有什么優(yōu)點(diǎn)
一般都是問(wèn) Flink 比 Spark 有什么優(yōu)勢(shì),這個(gè)是反過(guò)來(lái)問(wèn)的,要注意哦
微批處理優(yōu)勢(shì):
Spark Streaming 的微批處理雖然實(shí)時(shí)性不如Flink,但是微批對(duì)于實(shí)時(shí)性要求不是很高的任務(wù)有著很大優(yōu)勢(shì)。
比如10W+的數(shù)據(jù)寫入MySql,假如采用Flink實(shí)時(shí)處理,Sink 到 MySql 中,F(xiàn)link是事件驅(qū)動(dòng)的,每條都去插入或更新數(shù)據(jù)庫(kù),明顯不靠譜,因?yàn)閿?shù)據(jù)庫(kù)扛不住。假如在Flink的Sink處加上批處理,雖然可以提高性能,但是如果最后一個(gè)批次沒(méi)有達(dá)到批大小閾值,數(shù)據(jù)就不會(huì)刷出進(jìn)而導(dǎo)致數(shù)據(jù)丟失。 Flink是基于狀態(tài)的計(jì)算,所以在多個(gè)窗口內(nèi)做關(guān)聯(lián)操作是很難實(shí)現(xiàn)的,只能把所有狀態(tài)丟到內(nèi)存中,但如果超出內(nèi)存,就會(huì)直接內(nèi)存溢出。Spark 因?yàn)槭腔赗DD的可以利用RDD的優(yōu)勢(shì),哪怕數(shù)據(jù)超出內(nèi)存一樣算,所以在較粗時(shí)間粒度極限吞吐量上Spark Streaming要優(yōu)于Flink。
語(yǔ)言優(yōu)勢(shì):
Flink和Spark都是由Scla和Java混合編程實(shí)現(xiàn),Spark的核心邏輯由Scala完成,而Flink的主要核心邏輯由Java完成。在對(duì)第三方語(yǔ)言的支持上,Spark支持的更為廣泛,Spark幾乎完美的支持Scala,Java,Python,R語(yǔ)言編程。
17. 有什么想問(wèn)的嗎
面試是雙方相互了解的過(guò)程,所以出于禮貌在面試結(jié)束詢問(wèn)一下你有沒(méi)有什么想問(wèn)的。當(dāng)然面試官也想借此了解你對(duì)他們公司的了解程度及感興趣程度。
所以請(qǐng)不要回答“我沒(méi)有問(wèn)題了”,而是要把這個(gè)問(wèn)題當(dāng)作最后一次發(fā)言機(jī)會(huì)。問(wèn)的問(wèn)題要圍繞著這家公司本身,要讓對(duì)方覺(jué)得你很關(guān)心、關(guān)注公司。
以下是可以問(wèn)的:
公司對(duì)這個(gè)崗位的期望是什么樣的?其中,哪些部分是我需要特別努力的? 是否有資深的人員能夠帶領(lǐng)新進(jìn)者,并讓新進(jìn)者有發(fā)揮的機(jī)會(huì)? 公司強(qiáng)調(diào)團(tuán)隊(duì)合作。那在這個(gè)工作團(tuán)隊(duì)中,哪些個(gè)人特質(zhì)是公司所希望的? 能否為我介紹一下工作環(huán)境?
以下是不該問(wèn)的:
薪資待遇 過(guò)于高深的問(wèn)題 超出應(yīng)聘崗位的問(wèn)題

--end--
掃描下方二維碼 添加好友,備注【交流】 可私聊交流,也可進(jìn)資源豐富學(xué)習(xí)群
更文不易,點(diǎn)個(gè)“在看”支持一下??