
神奇的 SQL 之性能優(yōu)化,讓 SQL 飛起來

寫在前面
下文將盡量介紹一些不依賴具體數(shù)據(jù)庫實現(xiàn),使 SQL 執(zhí)行速度更快、消耗內(nèi)存更少的優(yōu)化技巧,只需調(diào)整 SQL 語句就能實現(xiàn)的通用的優(yōu)化 Tips

說句很重要的心里話:祝大家在 2021 年,健康好運,平安幸福!

環(huán)境準備
DROP?TABLE?IF?EXISTS?tbl_customer;
CREATE?TABLE?tbl_customer?(
??id?INT(11)?UNSIGNED?NOT?NULL?AUTO_INCREMENT?COMMENT?'自增主鍵',
??name?VARCHAR(50)?NOT?NULL?COMMENT?'顧客姓名',
??age?TINYINT(3)?NOT?NULL?COMMENT?'年齡',
??id_card?CHAR(18)?NOT?NULL?COMMENT?'身份證',
??phone_number?CHAR(11)?NOT?NULL?COMMENT?'手機號碼',
??PRIMARY?KEY?(id)
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8?COMMENT='顧客表';
INSERT?INTO?tbl_customer(name,?age,id_card,phone_number)?VALUES
('張三',19,'430682198109129210','15174480311'),
('李四',21,'430682198109129211','15174480312'),
('王五',22,'430682198109129212','15174480313'),
('六一',23,'430682198109129213','15174480314'),
('六二',25,'430682198109129214','15174480315'),
('六三',27,'430682198109129215','15174480316'),
('六四',29,'430682198109129216','15174480317');
DROP?TABLE?IF?EXISTS?tbl_recharge_record;
CREATE?TABLE?tbl_recharge_record?(
??id?INT(11)?UNSIGNED?NOT?NULL?AUTO_INCREMENT?COMMENT?'自增主鍵',
??customer_id?INT(11)?NOT?NULL?COMMENT?'顧客ID',
??recharge_type?TINYINT(2)?NOT?NULL?COMMENT?'充值方式?1:支付寶,?2:微信,3:QQ,4:京東,5:銀聯(lián),6:信用卡,7:其他',
??recharge_amount?DECIMAL(15,2)?NOT?NULL?COMMENT?'充值金額,?單位元',
??recharge_time?DATETIME?NOT?NULL?COMMENT?'充值時間',
??remark?VARCHAR(500)?NOT?NULL?DEFAULT?'remark'?COMMENT?'備注',
??PRIMARY?KEY?(id),
??KEY?idx_c_id(customer_id)
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8?COMMENT='顧客充值記錄表';
INSERT?INTO?tbl_recharge_record(customer_id,recharge_type,recharge_amount,recharge_time)?VALUES
(1,1,10000,NOW()),
(2,2,20000,NOW()),
(1,2,10000,NOW()),
(1,3,10000,NOW()),
(2,7,20000,NOW()),
(3,3,15000,NOW()),
(4,1,10000,NOW()),
(5,1,10000,NOW()),
(6,1,10000,NOW()),
(7,1,10000,NOW()),
(7,1,10000,NOW()),
(6,1,10000,NOW()),
(5,1,10000,NOW()),
(4,1,10000,NOW()),
(3,1,10000,NOW()),
(2,1,10000,NOW()),
(1,1,10000,NOW()),
(2,1,10000,NOW()),
(3,1,10000,NOW()),
(2,1,10000,NOW()),
(3,1,10000,NOW()),
(4,1,10000,NOW()),
(2,1,10000,NOW()),
(2,1,10000,NOW()),
(1,1,10000,NOW());
神奇的 SQL 之 MySQL 執(zhí)行計劃 → EXPLAIN,讓我們了解 SQL 的執(zhí)行過程! cnblogs.com/youzhibing/p/11909681.html
使用高效的查詢
使用 EXISTS 代替 IN
IN 使用起來確實簡單,也非常好理解;我們來看下它的執(zhí)行計劃

我們再來看看?EXISTS?的執(zhí)行計劃:

通常來講,EXISTS 比 IN 更快的原因有兩個
1、如果連接列(customer_id)上建立了索引,那么查詢 tbl_recharge_record 時可以通過索引查詢,而不是全表查詢
其實有很多數(shù)據(jù)庫也嘗試著改善了 IN 的性能
Oracle 數(shù)據(jù)庫中,如果我們在有索引的列上使用 IN, 也會先掃描索引
PostgreSQL 從版 本 7.4 起也改善了使用子查詢作為 IN 謂詞參數(shù)時的查詢速度
神奇的 SQL 之謂詞 → 難理解的 EXISTS
cnblogs.com/youzhibing/p/11385136.html
使用連接代替 IN
回到問題:查詢有充值記錄的顧客信息,如果用連接來實現(xiàn),SQL 改如何寫?

避免排序
但是,除了?ORDER BY?顯示的排序,數(shù)據(jù)庫內(nèi)部還有很多運算在暗中進行排序;會進行排序的代表性的運算有下面這些

靈活使用集合運算符的 ALL 可選項
默認情況下,這些運算符會為了排除掉重復數(shù)據(jù)而進行排序
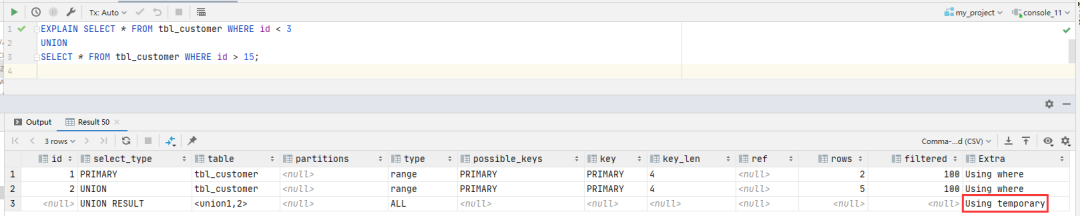
如果我們不在乎結果中是否有重復數(shù)據(jù),或者事先知道不會有重復數(shù)據(jù),可以使用?UNION?ALL?代替?UNION?

加上 ALL 可選項是一個非常有效的優(yōu)化手段,但各個數(shù)據(jù)庫對它的實現(xiàn)情況卻是參差不齊,如下圖所示

使用 EXISTS 代替 DISTINCT
會發(fā)現(xiàn)執(zhí)行計劃中有個?Using?temporary?,表示用到了排序運算


在極值函數(shù)中使用索引
SQL 語言里有兩個極值函數(shù):MAX 和 MIN ,使用這兩個函數(shù)時都會進行排序
例如:SELECT MAX(recharge_amount) FROM tbl_recharge_record
但是如果參數(shù)字段上建有索引,則只需要掃描索引,不需要掃描整張表
例如:SELECT MAX(customer_id) FROM tbl_recharge_record;
減少排序的數(shù)據(jù)量
有效利用索引
在 GROUP BY 子句和 ORDER BY 子句中使用索引
使用索引
減少臨時表
但是,頻繁使用臨時表會帶來兩個問題
1、臨時表相當于原表數(shù)據(jù)的一份備份,會耗費內(nèi)存資源
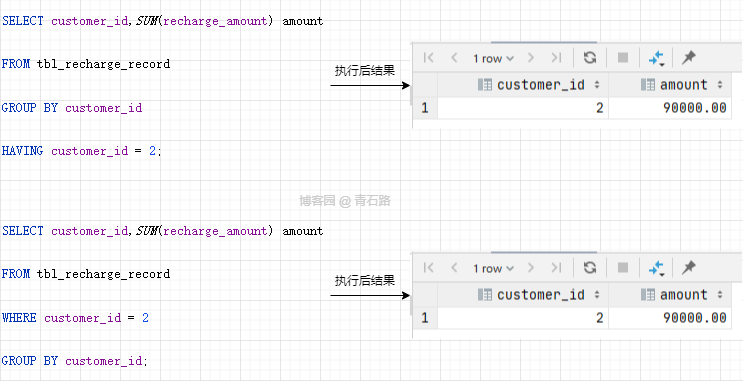
靈活使用 HAVING 子句
但是如果對 HAVING 不熟,我們往往找出替代它的方式來實現(xiàn),就像這樣

然而,對聚合結果指定篩選條件時不需要專門生成中間表,像下面這樣使用 HAVING 子句就可以

需要對多個字段使用 IN 謂詞時,將它們匯總到一處
我們來看一個示例,多個字段使用 IN 謂詞
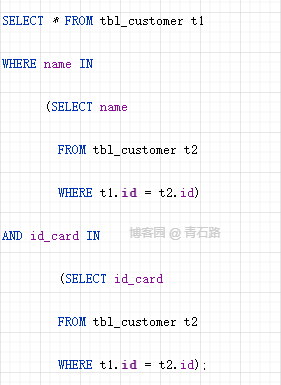
這段代碼中用到了兩個子查詢,我們可以進行列匯總優(yōu)化,把邏輯寫在一起

還可以進一步簡化,在 IN 中寫多個字段的組合

先進行連接再進行聚合
合理地使用視圖
特別是視圖的定義語句中包含以下運算的時候,SQL 會非常低效,執(zhí)行速度也會變得非常慢

總結
小結下文中的 Tips
1、參數(shù)是子查詢時,使用 EXISTS 或者 JOIN 代替 IN
2、在 SQL 中,很多運算都會暗中進行排序,盡量規(guī)避這些運算
3、SQL 的書寫,盡量往索引上靠,避免用不上索引的情況
參考
來源:cnblogs.com/youzhibing/p/11909821.html
版權申明:內(nèi)容來源網(wǎng)絡,版權歸原創(chuàng)者所有。除非無法確認,我們都會標明作者及出處,如有侵權煩請告知,我們會立即刪除并表示歉意。謝謝!
