
CPU讀寫內存,炸了!


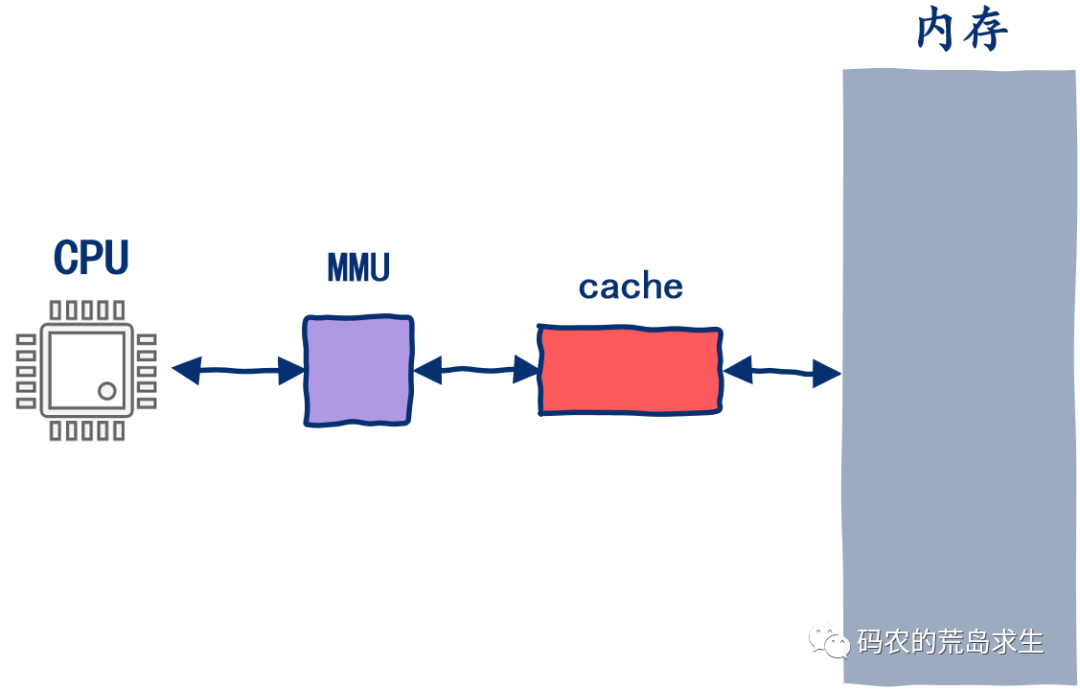
誰來告訴CPU讀寫內存

兩種內存讀寫
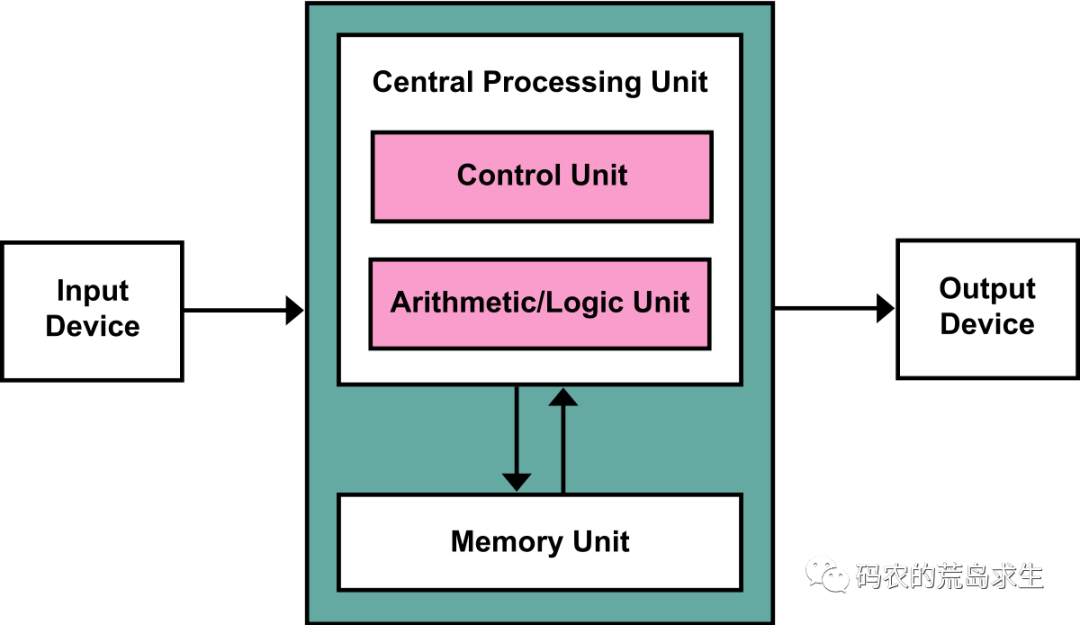
程序執(zhí)行過程中需要讀寫來自內存中的數據
CPU需要訪問內存讀取下一條要執(zhí)行的機器指令

急性子吃貨 VS 慢性子廚師
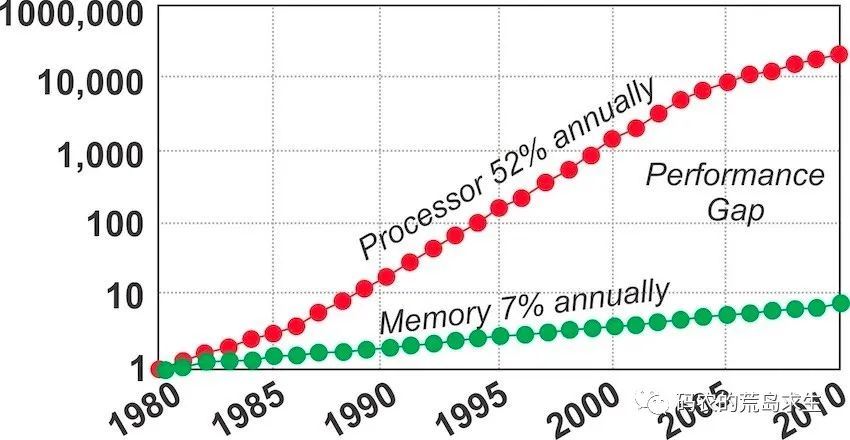
無處不在的28定律

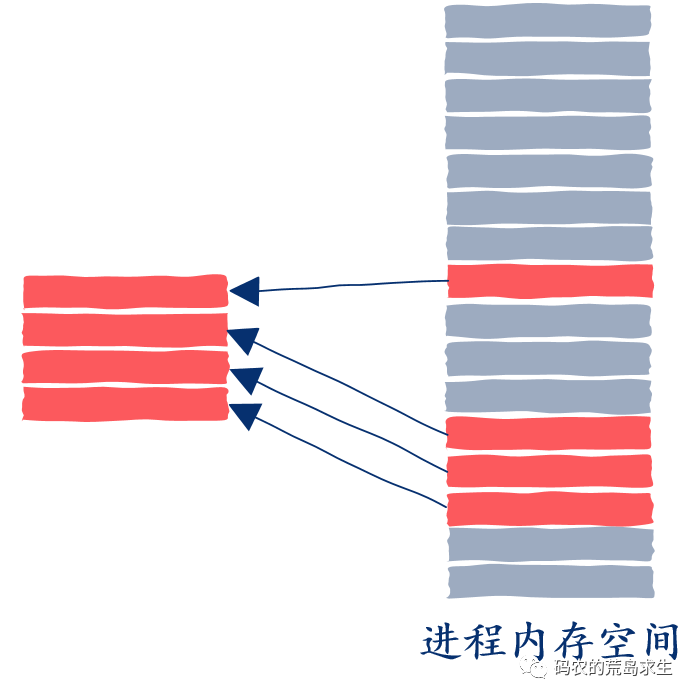
四兩撥千斤
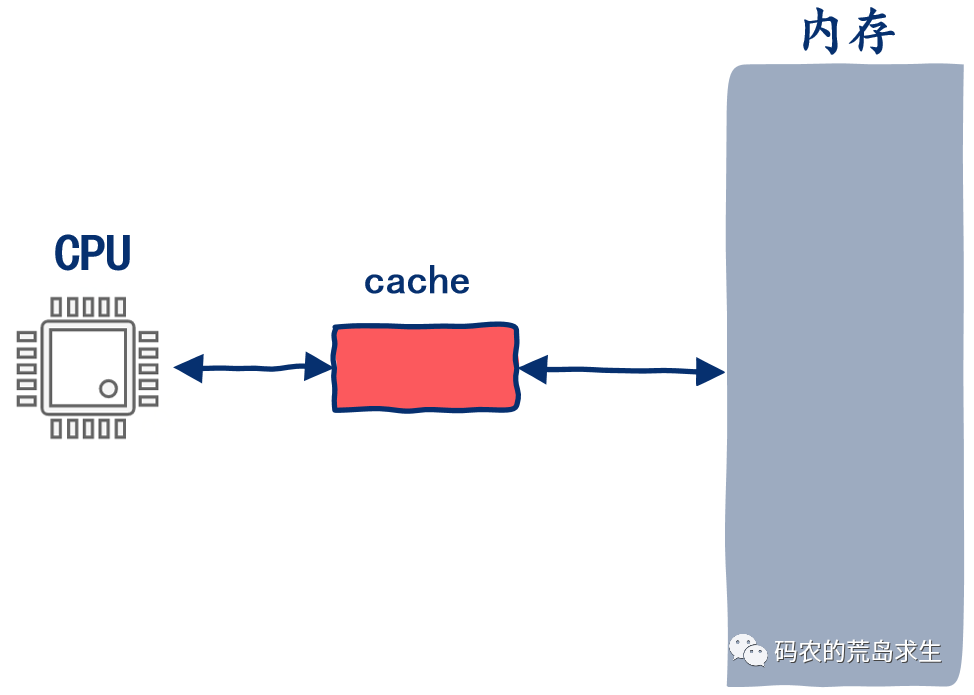
天下沒有免費的午餐
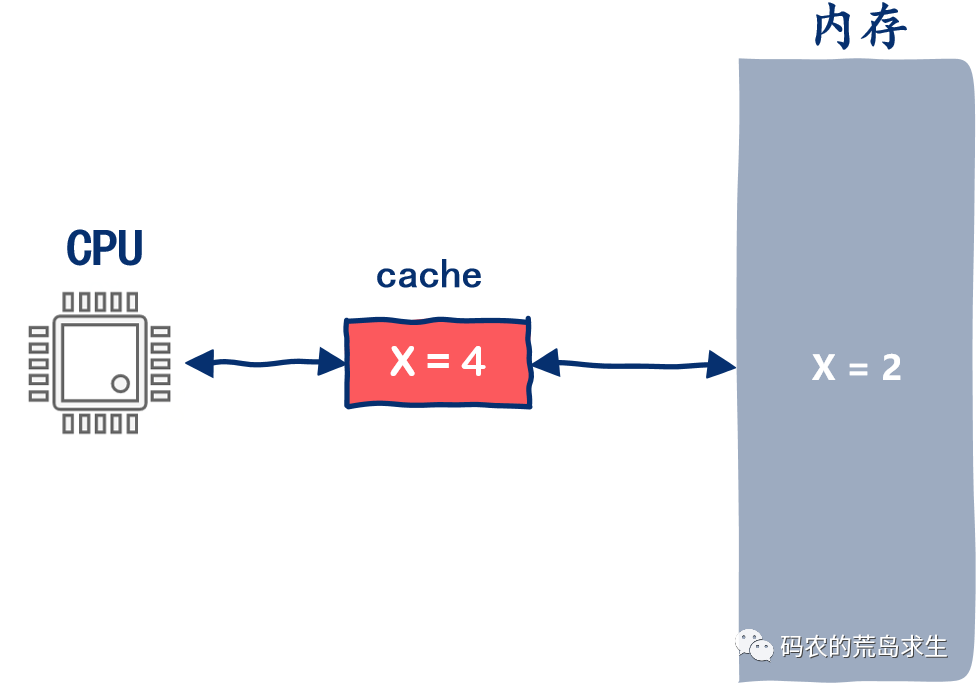
同步緩存更新
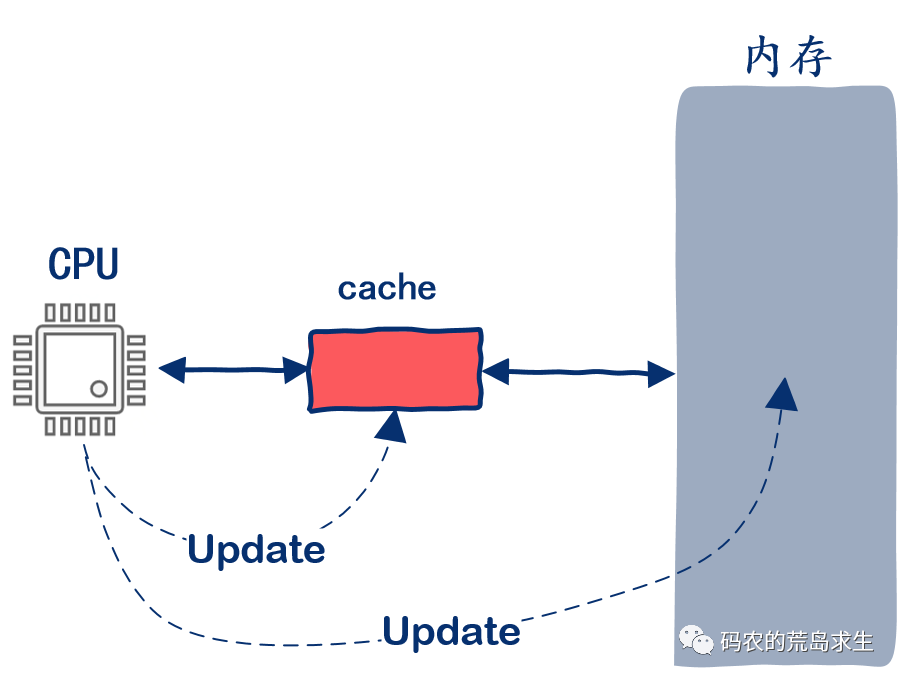
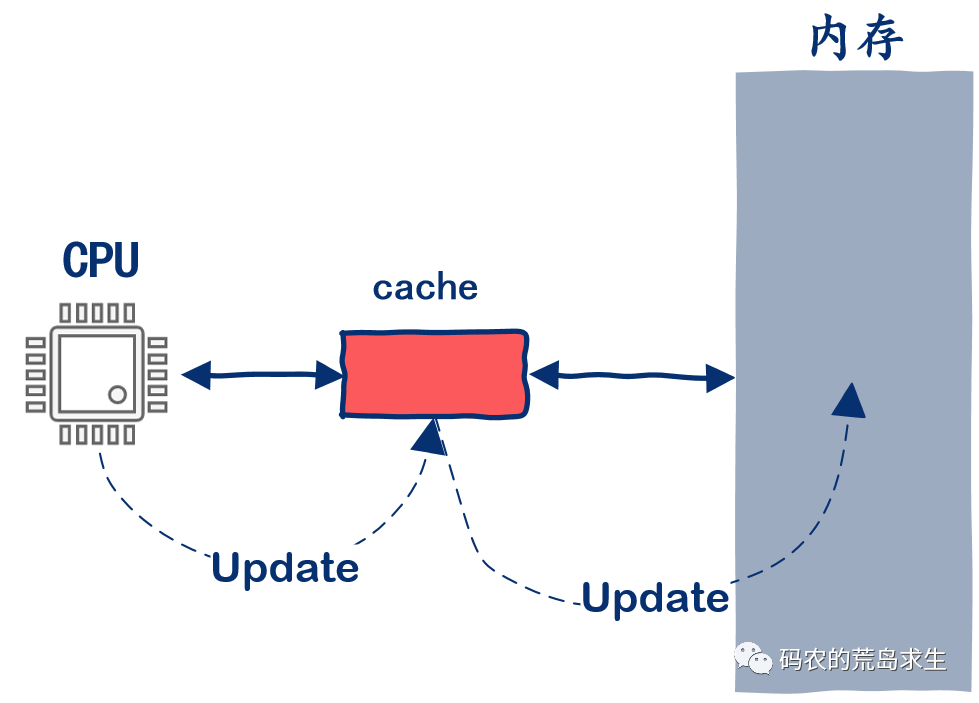
異步更新緩存
多級cache
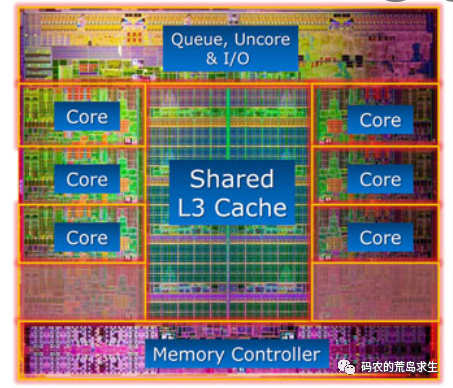
多核,多問題
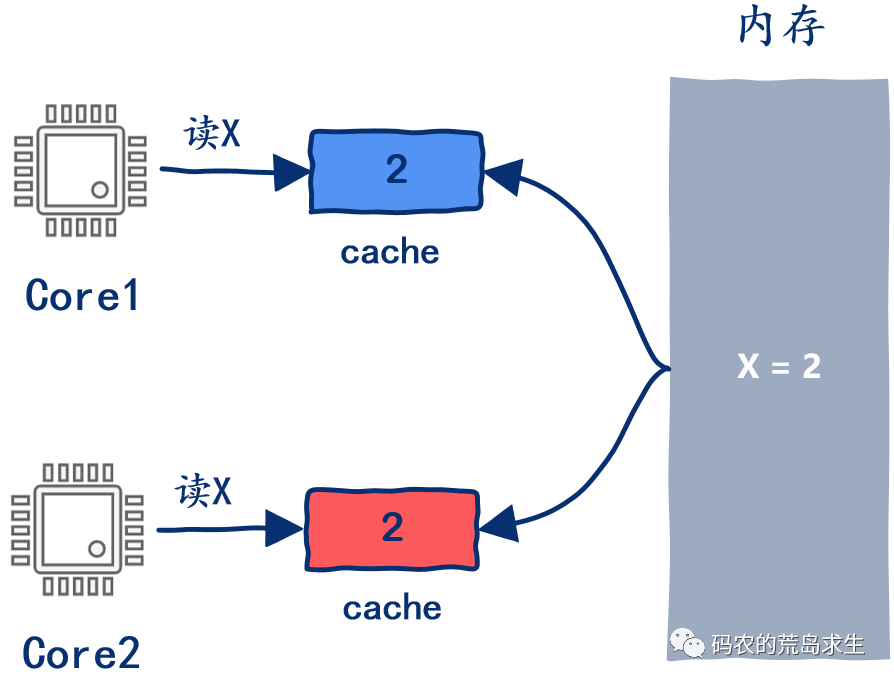
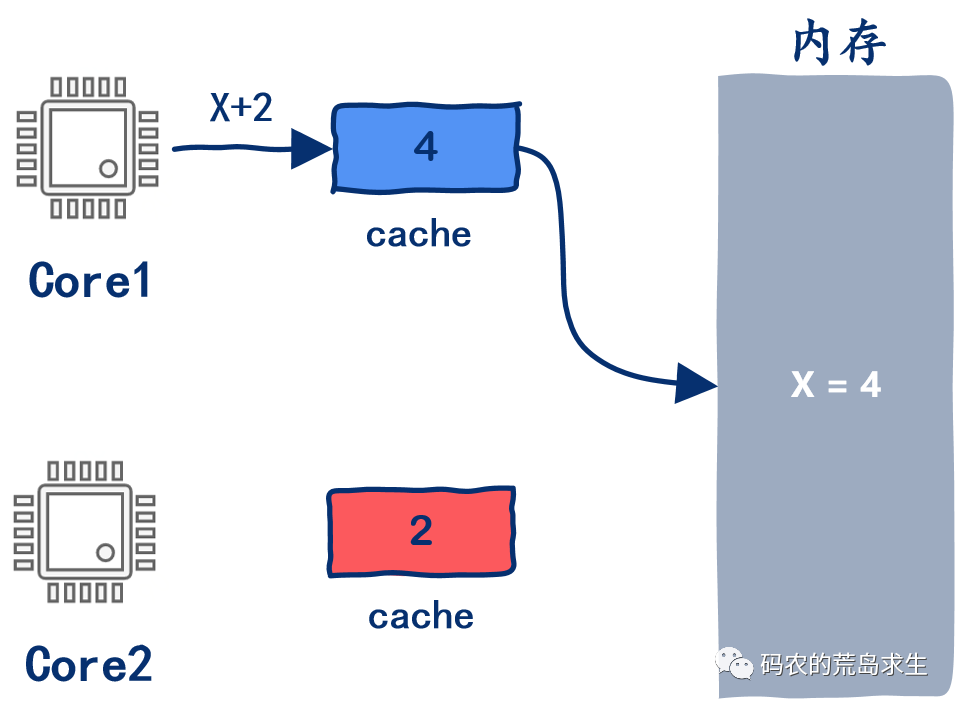
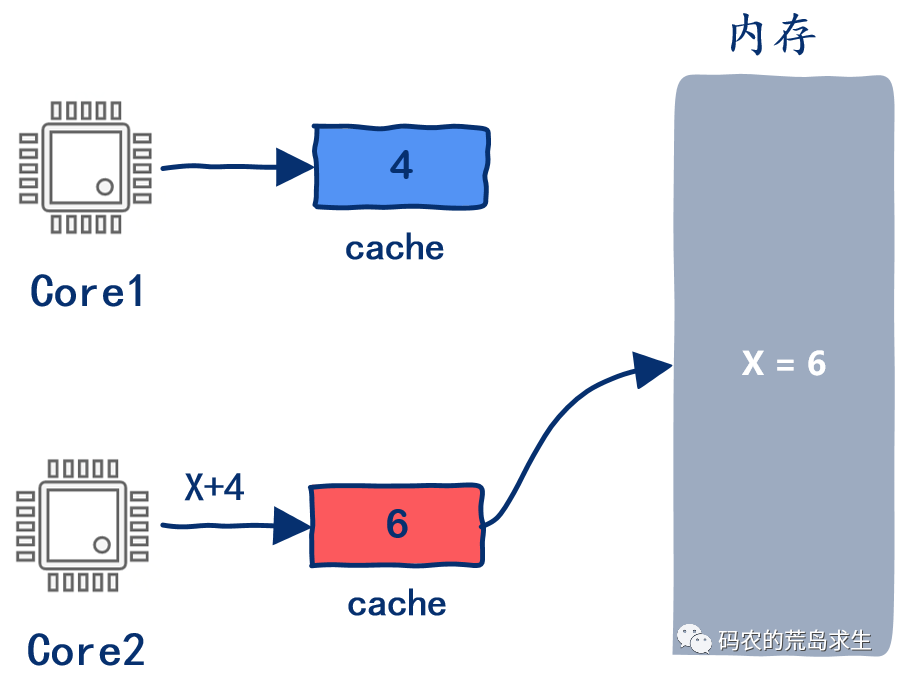
多核cache一致性
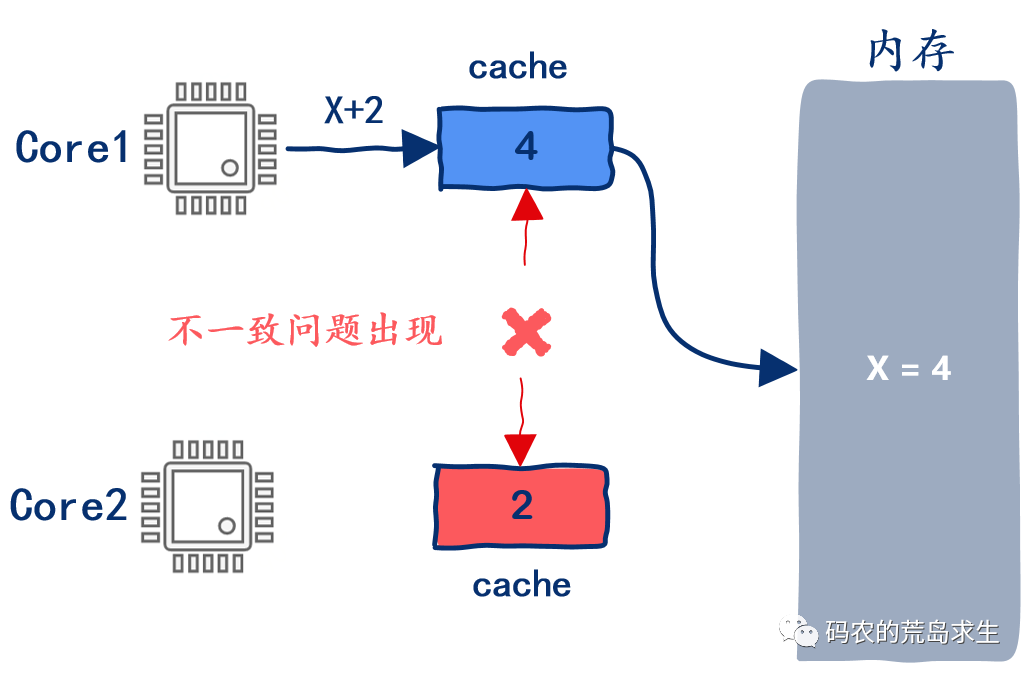
夠復雜了吧!

你以為的不是你以為的

天真的CPU
總結
評論
圖片
表情