
三歪學(xué)了幾天Storm,上線了一版,全都是Bug
本文公眾號來源:Java3y
作者:三歪
本文已收錄至我的GitHub
聽說過大數(shù)據(jù)的同學(xué)應(yīng)該都聽說過Storm吧?其實我現(xiàn)在負(fù)責(zé)的系統(tǒng)用的就是Storm,在最開始接手系統(tǒng)的時候,我是完全不了解Storm的(現(xiàn)在其實也是一知半解而已)
由于最近在整理系統(tǒng),所以順便花了點時間入門了一下Storm(前幾天花了點時間改了一下,上線以后一堆Bug,于是就果斷回滾了。)
這篇文章來講講簡單Storm的簡單使用,沒有復(fù)雜的東西。看完這篇文章,等到接手Storm的代碼的時候你們『大概』『應(yīng)該』能看懂Storm的代碼。
什么是Storm
我們首先進官方看一下Storm的介紹:
Apache Storm is a free and open source distributed realtime computation system
Storm是一個分布式的實時計算系統(tǒng)。
分布式:我在之前已經(jīng)寫過挺多的分布式的系統(tǒng)了,比如Kafka/HDFS/Elasticsearch等等。現(xiàn)在看到分布式這個詞,三歪第一反應(yīng)就是「它的存儲或者計算交由多臺服務(wù)器上完成,最后匯總起來達到最終的效果」。
實時:處理速度是毫秒級或者秒級的
計算:可以簡單理解為對數(shù)據(jù)進行處理,比如清洗數(shù)據(jù)(對數(shù)據(jù)進行規(guī)整,取出有用的數(shù)據(jù))。
我們使用Storm做了什么?
我現(xiàn)在做的消息管理平臺是可以推送各類的消息的(IM/PUSH/短信/微信消息等等),消息下發(fā)后,我們是肯定要知道這條消息的下發(fā)情況的(是否發(fā)送成功,如果用戶沒收到是由于什么原因?qū)е掠脩魶]收到,消息是否被點擊了等等)。
消息是否成功下發(fā)到用戶上,這是運營和客服經(jīng)常關(guān)心的問題。
消息下發(fā)的效果,這是運營非常關(guān)心的問題
基于上面問題,我們用了Storm做了一套自己的埋點方案,幫助我們快速確認(rèn)消息是否成功下發(fā)到用戶上以及統(tǒng)計消息下發(fā)的效果。
聽起來好像很牛逼,下面我來講講背景,看完你就會發(fā)現(xiàn)一點兒都不難。
需求背景
消息管理平臺雖然看起來只是發(fā)消息的,但是系統(tǒng)設(shè)計還是有點東西的。我們以「微服務(wù)」的思想去看這個系統(tǒng),會將不同的功能模塊抽取到不同的系統(tǒng)的。
其中PUSH(推送)的鏈路是最長的,一條消息下發(fā)經(jīng)過的后端系統(tǒng)就有7個,如圖下:
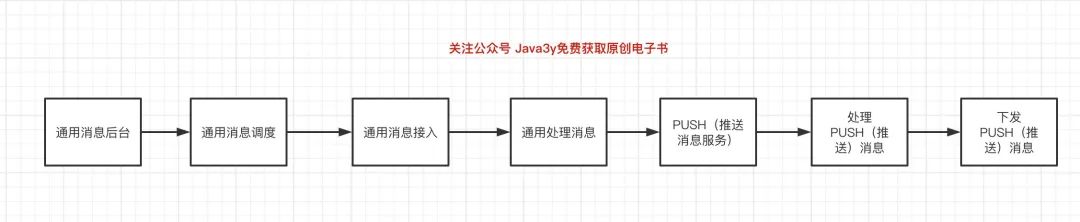
這7個系統(tǒng)都有可能「干掉」了這條消息,導(dǎo)致用戶沒收到。如果我們每去查一個問題,都要逐一排查每個系統(tǒng),那實在是太慢了。
很多時候客服反饋過來的問題都是當(dāng)天的,甚至是前幾分鐘的,我們需要有一個及時的反饋給客服來幫助用戶找到為什么收不到消息的原因。
于是我們要做兩個功能:
- 能夠查詢用戶當(dāng)天所有的消息下發(fā)情況。(能夠快速定位是哪個系統(tǒng)什么原因?qū)е掠脩羰詹坏较ⅲ?/li>
- 查詢某條消息的實時整體下發(fā)情況。(能夠快速查看該消息的整體下發(fā)情況,包括下發(fā)量,中途過濾的量以及點擊量)
如果是單純查問題,我們將各個系統(tǒng)的日志收集到Kafka,然后寫到Elasticsearch這個是完全沒問題的(現(xiàn)在我們也是這么干的)
涉及到統(tǒng)計相關(guān)的,我們就有自己的一套埋點方案,這個是便于對數(shù)據(jù)的統(tǒng)計,也能完成部分排查的功能。
需求實現(xiàn)
前面提到了「埋點」,實際上就是打日志。其實就是在關(guān)鍵的地方上打上日志做記錄,方便排查問題。
比如,現(xiàn)在我們有7個系統(tǒng),每個系統(tǒng)在執(zhí)行消息的時候都會可能導(dǎo)致這條消息發(fā)不出去(可能是消息去重了,可能是用戶的手機號不正確,可能是用戶太久沒有登錄了等等都有可能)。我們在這些『關(guān)鍵位置』都打上日志,方便我們?nèi)ヅ挪椤?/p>
這些「關(guān)鍵位置」我們都給它用簡單的數(shù)字來命個名。比如說:我們用「11」來代表這個用戶沒有綁定手機號,用「12」來代表這個用戶10分鐘前收到了一條一模一樣的消息,用「13」來代表這個用戶屏蔽了消息.....
「11」「12」「13」「14」「15」「16」這些就叫做「點位」,把這些點位在關(guān)鍵的位置中打上日志,這個就叫做「埋點」
有了埋點,我們要做的就是將這些點位收集起來,然后統(tǒng)一處理成我們的格式,輸出到數(shù)據(jù)源中。
OK,就是分三步:
- 收集日志
- 清洗日志
- 輸出到數(shù)據(jù)源
收集日志我們有l(wèi)ogAgent幫我們收集到Kafka,實時清洗日志我們用的就是Storm,清洗完我們輸出到Redis(實時)/Hive(離線)。
Storm一般是在處理(清洗)那層,Storm的上下游也很明確了(上游是消息隊列,下游寫到各種數(shù)據(jù)源,這種是最常見的):
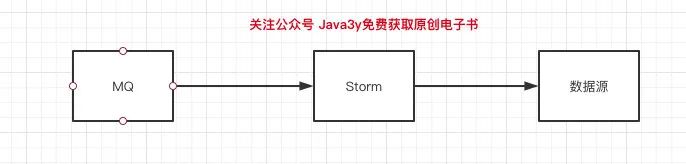
Storm統(tǒng)一清洗出來放到Redis,我們就可以通過接口來很方便去查一條消息的整體下發(fā)情況,比如:

到這里,主要想說明我們通過Storm來實時清洗數(shù)據(jù),下來來講講Storm的基本使用~
Storm入門
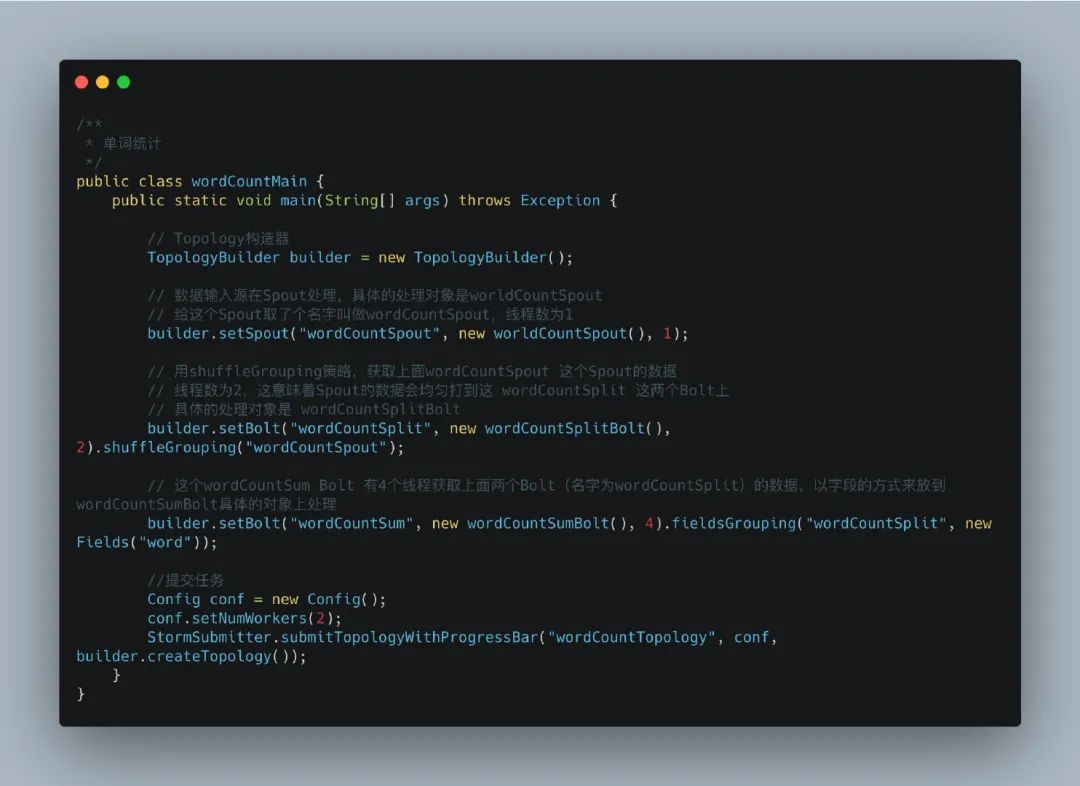
我們從一段最簡單的Storm代碼入門,先看看下面的代碼:
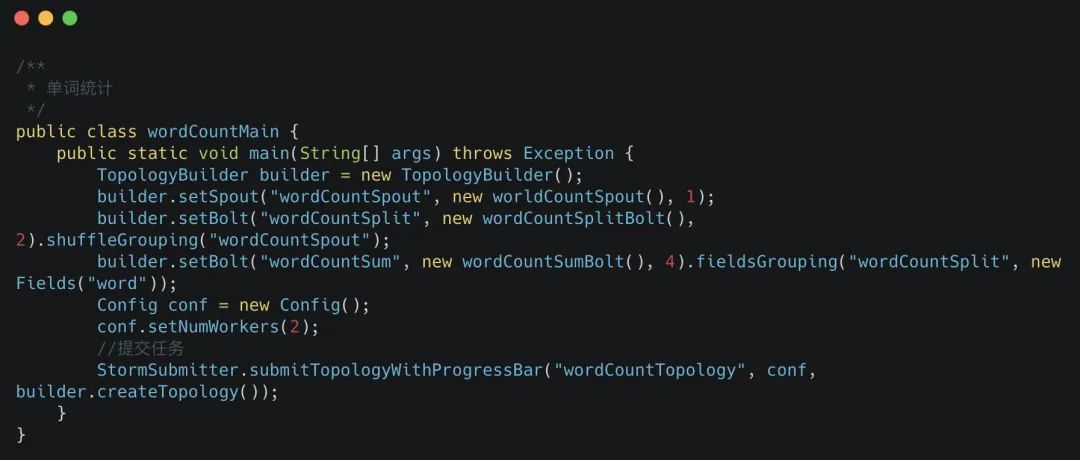
如果完全沒看過Storm代碼的同學(xué),看到上面的代碼會怎么分析?我是這樣的:
- 首先有一個TopologyBuilder的東西,這個東西可能是Storm的構(gòu)造器之類的
- 然后設(shè)置了Spout和Bolt(但是我不知道這兩個東西是用來干嘛的,但是我可以點進去對象里邊看看做了什么)
- 然后設(shè)置了一下Config配置(應(yīng)該是設(shè)置Storm分配多少內(nèi)存,多少線程之類的,反正跟配置相關(guān))
- 最后用StormSubmitter提交任務(wù),把配置和TopologyBuilder的內(nèi)容給提交上去。
我們簡單搜一下,就可以發(fā)現(xiàn)它的流程大致是這樣的:
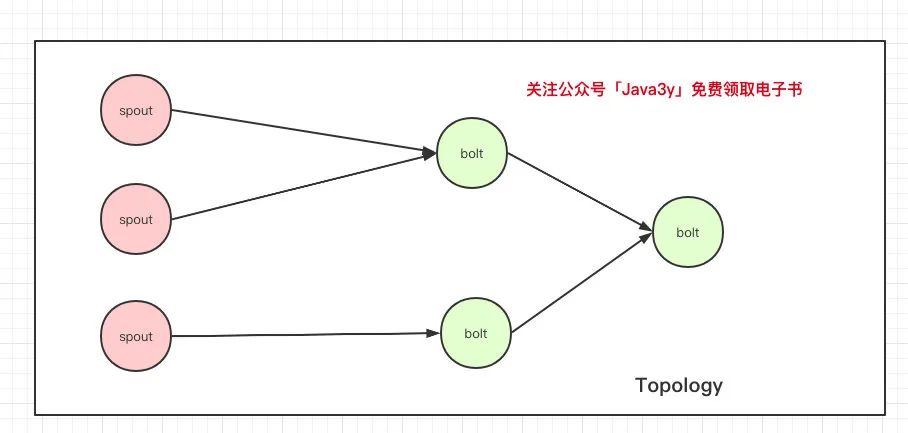
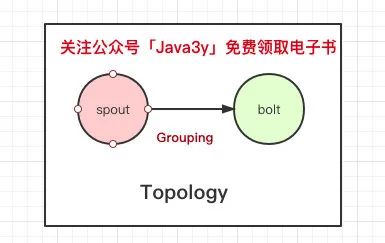
Spout是數(shù)據(jù)的源頭,一般我們用它去接收數(shù)據(jù),Spout接收到數(shù)據(jù)后往Bolt上發(fā)送,Bolt處理數(shù)據(jù)(清洗)。Bolt清洗完數(shù)據(jù)可以寫到一個數(shù)據(jù)源或者傳遞給下一個Bolt繼續(xù)清洗。
Topology關(guān)聯(lián)了我們在程序中定義好的Spout和Bolt。各種 Spout 和 Bolt 連接在一起之后,就成了一個 Topology,一個 Topology 就是一個 Storm 應(yīng)用。
Spout往Bolt傳遞數(shù)據(jù),Bolt往Bolt傳遞數(shù)據(jù),這個傳遞的過程叫做Stream,Stream傳遞的是一個一個Tuple。
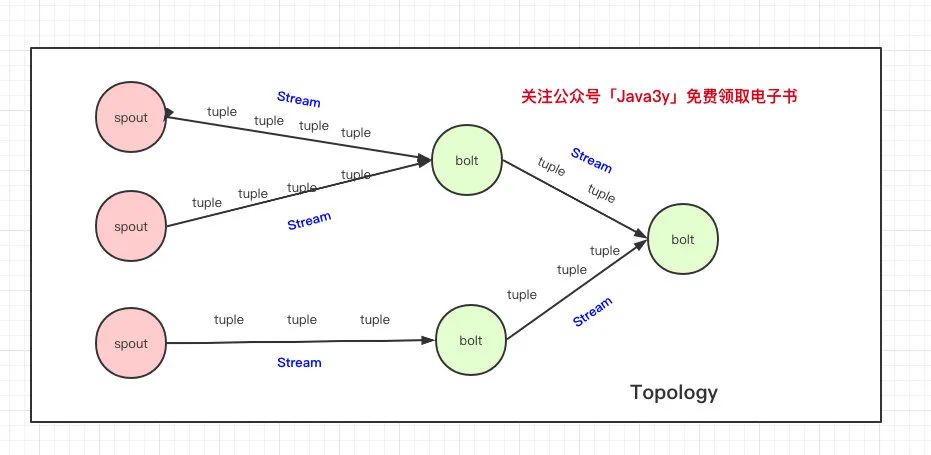
現(xiàn)在問題來了,我們的Spout和Bolt之間是怎么關(guān)聯(lián)起來的呢?Bolt和Bolt之間是怎么關(guān)聯(lián)起來的呢?
在上面的圖我們知道一個Topology會有多個Spout和多個Bolt,那我怎么知道這個Spout傳遞的數(shù)據(jù)是給這個Bolt,這個Bolt傳遞的數(shù)據(jù)是給另外一個Bolt?(說白了,就是上面圖上的箭頭是怎么關(guān)聯(lián)的呢?)
在Storm中,有Grouping的機制,就是決定Spout的數(shù)據(jù)流向哪個Bolt,Bolt的數(shù)據(jù)流向下一個Bolt。
為了提高并發(fā)度,我們在setBolt的時候,可以指定Bolt的線程數(shù),也就是所謂的Executor(Spout也同樣可以指定線程數(shù)的,只是這次我拿Bolt來舉例)。我們的結(jié)構(gòu)可能會是這樣的:
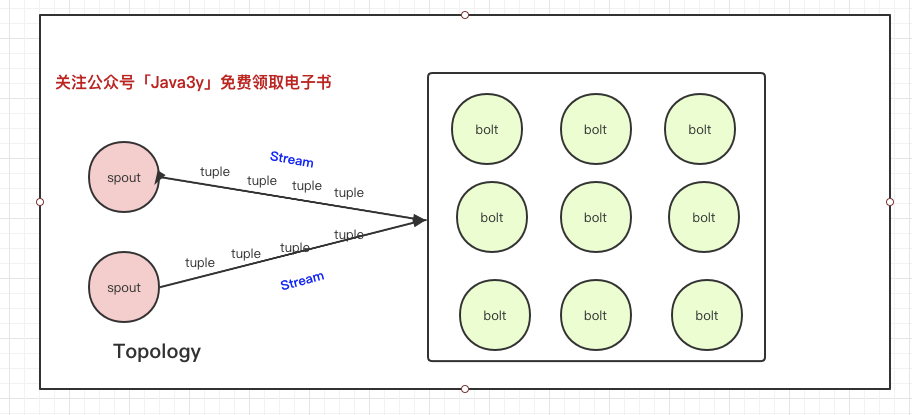
分組的策略有以下:
- 1)shuffleGrouping(隨機分組)
- 2)fieldsGrouping(按照字段分組,在這里即是同一個單詞只能發(fā)送給一個Bolt)
- 3)allGrouping(廣播發(fā)送,即每一個Tuple,每一個Bolt都會收到)
- 4)globalGrouping(全局分組,將Tuple分配到task id值最低的task里面)
- 5)noneGrouping(隨機分派)
- 6)directGrouping(直接分組,指定Tuple與Bolt的對應(yīng)發(fā)送關(guān)系)
- 7)Local or shuffle Grouping
- 8)partialKeyGrouping(關(guān)鍵字分組,與按字段分組很相似,但他分配更加均衡)
- 9)customGrouping (自定義的Grouping)
shuffleGrouping策略我們是用得最多的,比如上面的圖上有兩個Spout,我們會將這兩個Spout的Tuple均勻分發(fā)到各個Bolt中執(zhí)行。
說到這里,我們再回頭看看最開始的代碼,我給補充一下注釋,你們應(yīng)該就能看得懂了:
我還是再畫一個圖吧:
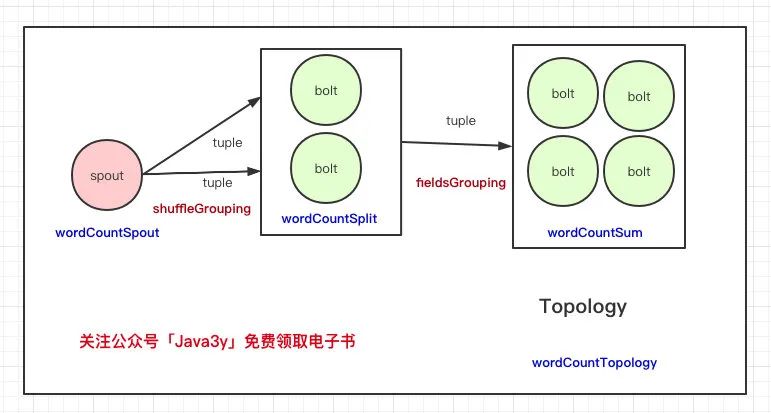
入門的過程復(fù)雜嗎?不復(fù)雜。說白了就是Spout接收到數(shù)據(jù),通過grouping機制將Spout的數(shù)據(jù)傳到給Bolt處理,Bolt處理完看還需不需要繼續(xù)往下處理,如果需要就傳遞給下一個Bolt,不需要就寫到數(shù)據(jù)源、調(diào)接口等等。
Storm架構(gòu)
當(dāng)我們提交任務(wù)之后,會發(fā)生什么呢?我們來看看。
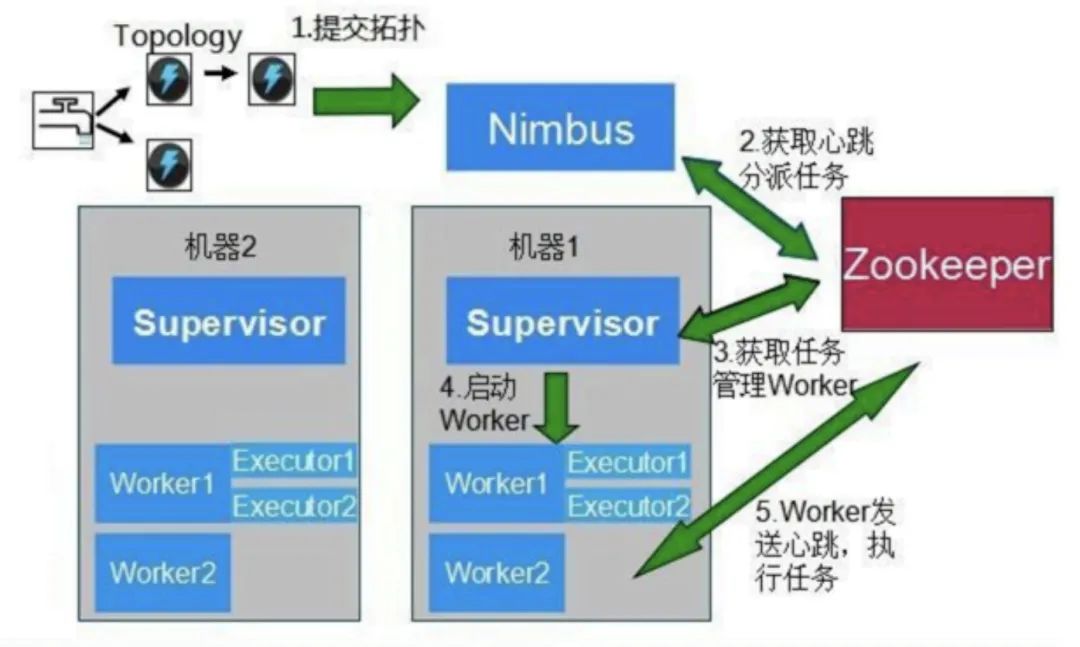
- 任務(wù)提交后,會被上傳到Nimbus節(jié)點上,它是主控節(jié)點,負(fù)責(zé)分配代碼、布置任務(wù)及檢測故障
- Nimbus會去Zookeeper上讀取整個集群的信息,將任務(wù)交給Supervisor,它是工作節(jié)點,負(fù)責(zé)創(chuàng)建、執(zhí)行任務(wù)
- Supervisor創(chuàng)建Worker進程,每個Worker對應(yīng)一個Topology的子集。Worker是Task的容器,Task是真正的任務(wù)執(zhí)行者。
流程大致如下:
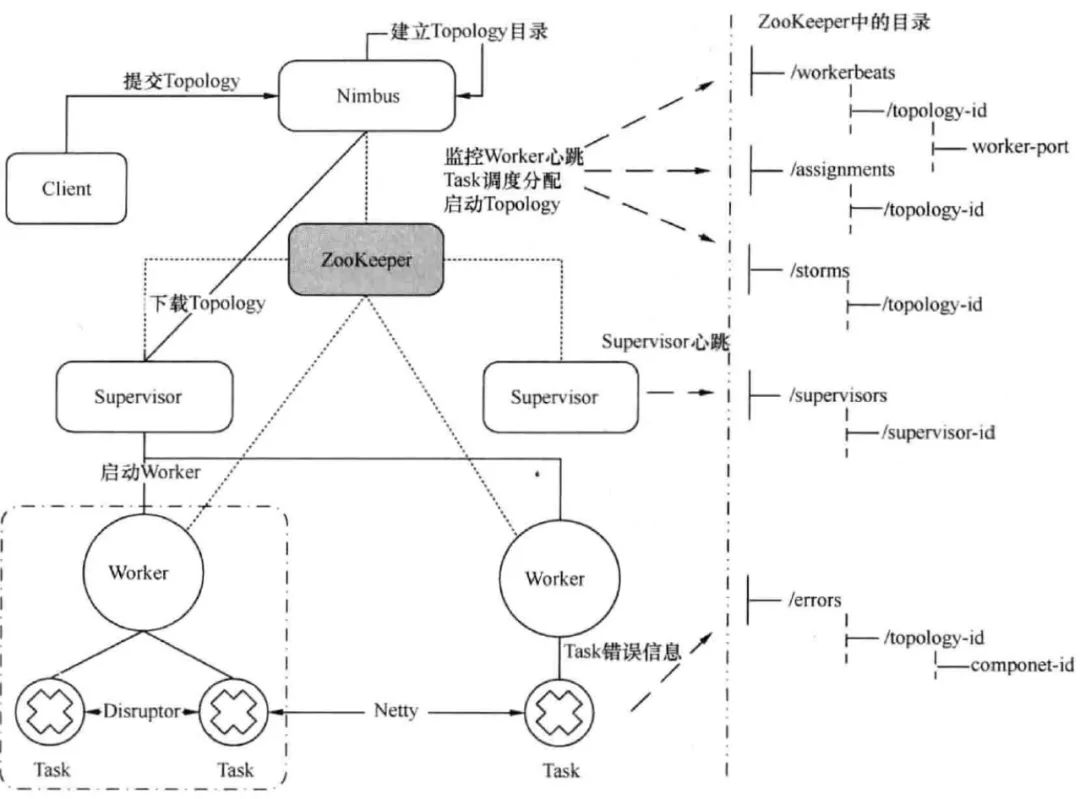
Nimbus和Supervisor都是節(jié)點(服務(wù)器),Storm用Zookeeper去管理Supervisor節(jié)點的信息。
Supervisor節(jié)點下會創(chuàng)建Worker進程,創(chuàng)建多少個Worker進程由Conf配置文件決定。線程Executor,由進程產(chǎn)生,用于執(zhí)行任務(wù),Executor線程數(shù)有多少個是在setBolt、setSpout的時候決定。Task是真正的任務(wù)執(zhí)行者,Task其實就是包裝了Bolt/Spout實例。
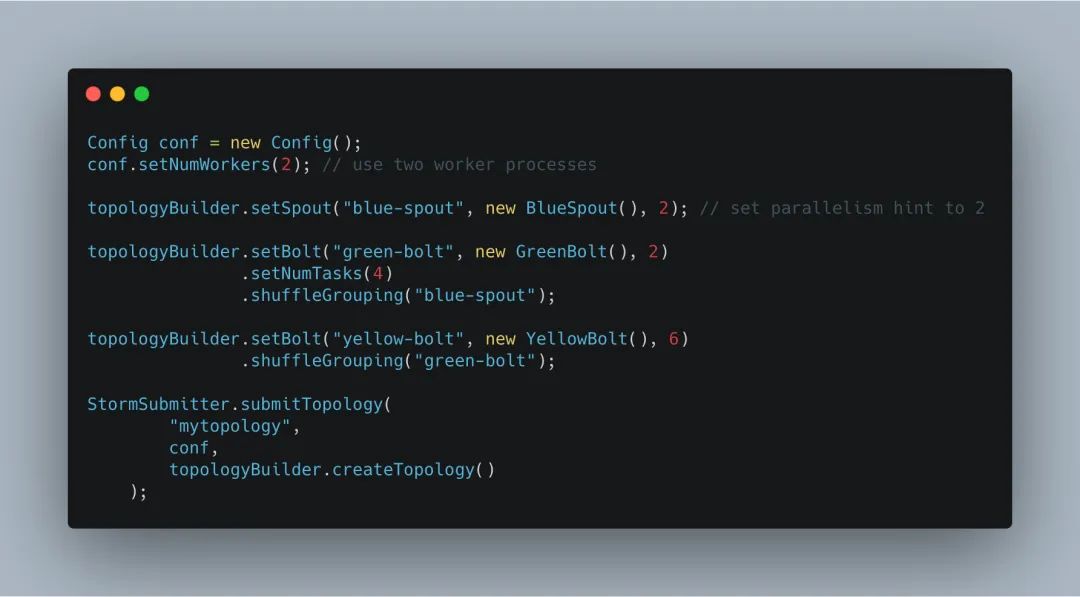
關(guān)于Worker、Executor、Task之間的關(guān)系,在官網(wǎng)有一個例子專門說明了,我們可以看看。先放出代碼:
內(nèi)部的圖:
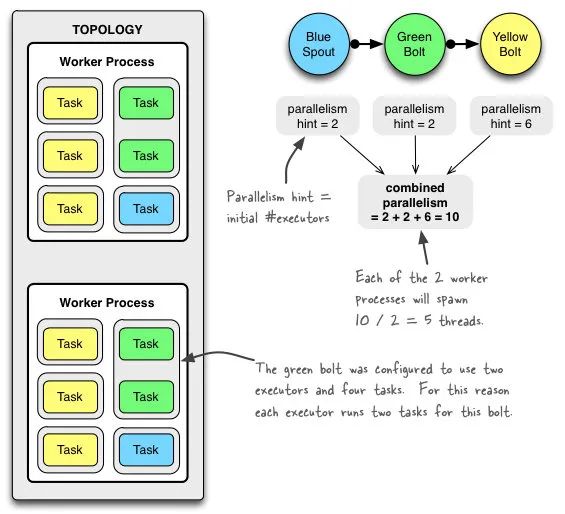
解釋一下:
- 默認(rèn)情況下:如果不指定Tasks數(shù),那么一個線程會有一個Task
conf.setNumWorkers(2)代表會創(chuàng)建兩個Worker進程setSpout("blue-spout", new BlueSpout(), 2)藍(lán)色Spout會有兩個線程處理,因為有兩個進程,所以一個進程會有一個藍(lán)色Spout線程topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4)綠色Bolt會有兩個線程處理,因為有兩個進程Worker所以一個進程會有一個綠色Bolt線程。又因為設(shè)置了4個Task數(shù),所以一個線程會分配兩個綠色的TasktopologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6).shuffleGrouping("green-bolt")。黃色Bolt會有6個線程處理,因為創(chuàng)建了兩個進程,所以一個進程會有3個黃色Bolt線程。沒有單獨設(shè)置Task書,所以一個線程默認(rèn)有一個Task
從上面我們可以知道threads ≤ tasks線程數(shù)是肯定小于等于Task數(shù)的。有沒有好奇寶寶會問:「Storm用了線程,那么會有線程不安全的情況嗎?」(其實這是三歪剛學(xué)的疑問)
一般來說不會,因為很多情況下,一個線程是對應(yīng)一個Task的(Task你可以理解為Bolt/Spout的實例),既然每個線程是處理自己的實例了,那當(dāng)然不會有線程安全的問題啦。(當(dāng)然了,你如果在Bolt/Spout中設(shè)置了靜態(tài)成員變量,那還是會有線程安全問題)
最后
這篇文章簡單地介紹了一下Storm,Storm的東西其實還有很多,包括ack機制什么的。現(xiàn)在進官方找文檔,都在主推Trident了,有興趣的同學(xué)可以繼續(xù)往下看。
話又說回來,我司也在主推Flink了,這塊后續(xù)如果有遷移計劃,我也準(zhǔn)備學(xué)學(xué)搞搞,到時候再來分享分享入門文章。
參考資料:
- http://storm.apache.org/releases/2.1.0/Understanding-the-parallelism-of-a-Storm-topology.html
- https://blog.csdn.net/w8y56f/article/details/88826489
各類知識點總結(jié)
下面的文章都有對應(yīng)的原創(chuàng)精美PDF,在持續(xù)更新中,可以來找我催更~
- 92頁的Mybatis
- 129頁的多線程
- 141頁的Servlet
- 158頁的JSP
- 76頁的集合
- 64頁的JDBC
- 105頁的數(shù)據(jù)結(jié)構(gòu)和算法
- 142頁的Spring
- 58頁的過濾器和監(jiān)聽器
- 30頁的HTTP
- Hibernate
- AJAX
- Redis
- ......
掃碼或者微信搜Java3y?免費領(lǐng)取原創(chuàng)思維導(dǎo)圖、精美PDF。在公眾號回復(fù)「888」領(lǐng)取,PDF內(nèi)容純手打有任何不懂歡迎來問我。
原創(chuàng)電子書
原創(chuàng)思維導(dǎo)圖
 |
|
