
c語言之共用體union、枚舉、大小端模式
上一個專題我們詳細的分享了c語言里面的結構體用法,讀者在看這些用法的時候,可以一邊看一邊試驗,掌握了這些基本用法就完全夠用了,當然在以后的工作中,如果有遇到了更高級的用法,我們可以再來總結學習歸納。好了,開始我們今天的主題分享。
一、共用體union:
1、什么是共用體union?
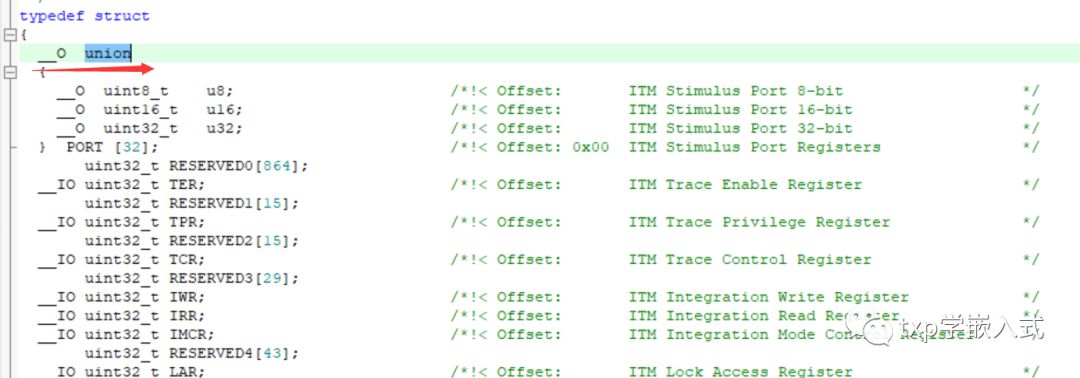
? ? 這個共用體,估計大家平時在代碼也比較少見,我去看了一下stm32的例程里面沒怎么看到這個用法(下面的示例分享是在stm32里面找的);其實這個共用體union(也叫聯(lián)合體)跟我們上次分享的結構體定義是非常像的,比如說:類型定義、變量定義、使用方法上很相似。就像下面兩個例子一樣,把許多類型聯(lián)合在一起(不過雖然形式上類似,但是具體用法還是有區(qū)別的,下面會講他們之間的區(qū)別):
union?st{
???int?a;
???char?b;
};
2、共用體與結構體的區(qū)別:
? ? ??
? ? ?結構體類似于一個包裹,結構體中的成員彼此是獨立存在的,分布在內存的不同單元中,他們只是被打包成一個整體叫做結構體而已;共用體中的各個成員其實是一體的,彼此不獨立,他們使用同一個內存單元。可以理解為:有時候是這個元素,有時候是那個元素。更準確的說法是同一個內存空間有多種解釋方式。所以共用體用法總結如下:
union中可以定義多個成員,union的內存大小由最大的成員的大小來決定。?
union成員共享同一塊大小的內存,一次只能使用其中的一個成員。
對某一個成員賦值,會覆蓋其他成員的值(這是為啥呢?,簡單來講就是因為他們共享一塊內存。但前提是成員所占字節(jié)數(shù)相同,當成員所占字節(jié)數(shù)不同時只會覆蓋相應字節(jié)上的值,比如對char成員賦值就不會把整個int成員覆蓋掉,因為char只占一個字節(jié),而int占四個字節(jié))。
共用體union的存放順序是所有成員都從低地址開始存放的。
3、代碼實戰(zhàn):
????#include?
????typedef?union{
????????int?a;
???????????char?c;
??????????//int?a;
?????????//?int?b;
??}st;
?????int?main(void)
????{
?????????st?haha;
?????????haha.c='B';
????????//??haha.a=10;
???????//haha.b=60;
???????printf("the?haha?size?is?%d\n",sizeof(haha));
???????printf("haha.c=%d\n",haha.c);
???????return?0;
}?
#include?
?typedef?union{
???int?a;
???char?c;
???int?b;
?}st;
?int?main(void)
?{
???????????st?haha;
???????????haha.c='B';
???????????haha.a=10;
???????????haha.b=60;
???????????printf("the?haha?size?is?%d\n",sizeof(haha));
printf("haha.c=%d,haha.a=%d,haha.b=%d\n",haha.c,haha.a,haha.b);
??????????printf("the?a?is?0x%x\n",&haha.a);
??????????printf("the?c?is?0x%x\n",&haha.c);
??????????printf("the?b?is?0x%x\n",&haha.b);
?????????return?0;
?}?
演示結果:
???the?haha?size?is?4
???haha.c=66
?the?haha?size?is?4
?haha.c=60,haha.a=60,haha.b=60
?the?a?is?0x61feac
?the?c?is?0x61feac
?the?b?is?0x61feac
說明:
? ? ? ?通過上面的代碼示例,讀者可以發(fā)現(xiàn)這個共用體的大小,并不是像我們之前結構體那樣是把每個成員所占內存大小加起來,而是我們上面說的那樣,共用體由成員占用內存大小最大的那個決定的,上面的示例中int 占用4個字節(jié)大小,為最大的,所以sizeof(haha)得出結果就是4個字節(jié)大小,而且讀者細心可以發(fā)現(xiàn)到打印出來的結果a和b都是60,它是訪問內存占用大小最大的那個成員的數(shù)值,因為那個'B'的acii碼值是是66;通過示例,我們也發(fā)現(xiàn)共用體訪問其成員方式跟結構體是一樣的(上面也有說到過)。下面是和結構體做對比的代碼示例:
???????#include?
??????//?共用體類型的定義
?????struct?mystruct
????{
???????????int?a;
???????????char?b;
?????};
???????// a和b其實指向同一塊內存空間,只是對這塊內存空間的2種不同的解析方式。
??????//?如果我們使用u1.a那么就按照int類型來解析這個內存空間;如果我們使用?
?????//?u1.b那么就按照char類型
??????//?來解析這塊內存空間。
????union?myunion
????{
???????int?a;
???????char?b;
???????double?c;
???};
???int?main(void)
???{
????????struct?mystruct?s1;
????????s1.a?=?23;
????????printf("s1.b?=?%d.\n",?s1.b);???????//?s1.b?=?0.?結論是s1.a和s1.b是獨立無關的
????????printf("&s1.a?=?%p.\n",?&s1.a);
????????printf("&s1.b?=?%p.\n",?&s1.b);
????????union?myunion?u1;???????//?共用體變量的定義
????????u1.a?=?23;??
????????u1.b='B';
????????u1.a=u1.b;??????????//?共用體元素的使用
????????printf("u1.a?=?%d.\n",?u1.a);
????????printf("u1.b?=?%d.\n",?u1.b);???
????????printf("u1.c?=?%d.\n",?u1.c);???
???????//?u1.b?=?23.結論是u1.a和u1.b是相關的
???????//?a和b的地址一樣,充分說明a和b指向同一塊內存,只是對這塊內存的不同解析規(guī)則????
????????printf("&u1.a?=?%p.\n",?&u1.a);
????????printf("&u1.b?=?%p.\n",?&u1.b);
????????printf("the?sizeof?u1?is?%d\n",sizeof(u1));
?????????return?0;
?}
演示結果:
s1.b?=?22.
&s1.a?=?0061FEA8.
&s1.b?=?0061FEAC.
u1.a?=?66.
u1.b?=?66.
u1.c?=?66.4、
&u1.a?=?0061FEA0.
&u1.b?=?0061FEA0.
the?sizeof?u1?is?8
4、小結:
union的sizeof測到的大小實際是union中各個元素里面占用內存最大的那個元素的大小。因為可以存的下這個就一定能夠存的下其他的元素。
union中的元素不存在內存對齊的問題,因為union中實際只有1個內存空間,都是從同一個地址開始的(開始地址就是整個union占有的內存空間的首地址),所以不涉及內存對齊。
二、枚舉
1、什么是枚舉?
? ? ?枚舉在C語言中其實是一些符號常量集。直白點說:枚舉定義了一些符號,這些符號的本質就是int類型的常量,每個符號和一個常量綁定。這個符號就表示一個自定義的一個識別碼,編譯器對枚舉的認知就是符號常量所綁定的那個int類型的數(shù)字。枚舉符號常量和其對應的常量數(shù)字相對來說,數(shù)字不重要,符號才重要。符號對應的數(shù)字只要彼此不相同即可,沒有別的要求。所以一般情況下我們都不明確指定這個符號所對應的數(shù)字,而讓編譯器自動分配。(編譯器自動分配的原則是:從0開始依次增加。如果用戶自己定義了一個值,則從那個值開始往后依次增加)。
2、為什么要用枚舉,和宏定義做對比:
??
? ? ?(1)C語言沒有枚舉是可以的。使用枚舉其實就是對1、0這些數(shù)字進行符號化編碼,這樣的好處就是編程時可以不用看數(shù)字而直接看符號。符號的意義是顯然的,一眼可以看出。而數(shù)字所代表的含義除非看文檔或者注釋。
? ? (2)宏定義的目的和意義是:不用數(shù)字而用符號。從這里可以看出:宏定義和枚舉有內在聯(lián)系。宏定義和枚舉經(jīng)常用來解決類似的問題,他們倆基本相當可以互換,但是有一些細微差別。
? ? (3)宏定義和枚舉的區(qū)別:
枚舉是將多個有關聯(lián)的符號封裝在一個枚舉中,而宏定義是完全散的。也就是說枚舉其實是多選一。
? ? (4)使用枚舉情況:
什么情況下用枚舉?當我們要定義的常量是一個有限集合時(譬如一星期有7天,譬如一個月有31天,譬如一年有12個月····),最適合用枚舉。(其實宏定義也行,但是枚舉更好)
不能用枚舉的情況下(定義的常量符號之間無關聯(lián),或者無限的),這個時候就用宏定義。
總結:
?
? ? ? ?宏定義先出現(xiàn),用來解決符號常量的問題;后來人們發(fā)現(xiàn)有時候定義的符號常量彼此之間有關聯(lián)(多選一的關系),用宏定義來做雖然可以但是不貼切,于是乎發(fā)明了枚舉來解決這種情況。
3、代碼示例:
a、幾種定義方法:
??/*????????//?定義方法1,定義類型和定義變量分離開
???enum?week
???{
????????????SUN,????????//?SUN?=?0
????????????MON,????????//?MON?=?1;
????????????TUE,
????????????WEN,
????????????THU,
????????????FRI,
????????????SAT,
??};
??enum?week?today;
??*/
??/*????????//?定義方法2,定義類型的同時定義變量
???enum?week
???{
????????????SUN,????????//?SUN?=?0
????????????MON,????????//?MON?=?1;
????????????????TUE,
????????????????WEN,
????????????THU,
????????????FRI,
????????????SAT,
????}today,yesterday;
??*/
???/*????????//?定義方法3,定義類型的同時定義變量
?????enum?
?????{
????????????SUN,????????//?SUN?=?0
????????????MON,????????//?MON?=?1;
????????????TUE,??
????????????WEN,
????????????THU,
????????????FRI,
????????????SAT,
????}today,yesterday;
?????*/
????/*????????//?定義方法4,用typedef定義枚舉類型別名,并在后面使用別名進行變量定義
??????????typedef?enum?week
??????????{
????????????SUN,????????//?SUN?=?0
????????????MON,????????//?MON?=?1;
????????????TUE,
????????????WEN,
????????????THU,
????????????FRI,
????????????SAT,
??????????}week;
???*/
??/*????????//?定義方法5,用typedef定義枚舉類型別名,并在后面使?
?用別名進行變量定義
????????typedef?enum?
????????{
????????????SUN,????????//?SUN?=?0
????????????MON,????????//?MON?=?1;
????????????TUE,
????????????WEN,
????????????THU,
????????????FRI,
????????????SAT,
??????????}week;
b、錯誤類型舉例(下面的舉例中也加入了結構體作為對比):
?/*????//?錯誤1,枚舉類型重名,編譯時報錯:error: conflicting
//????types?for?‘DAY’
??????typedef?enum?workday
??????{
?????????????MON,???????//?MON?=?1;
?????????????TUE,
?????????????WEN,
?????????????THU,
?????????????FRI,
???????}DAY;
?????typedef?enum?weekend
?????????{
????????????SAT,
????????????SUN,
?????????}DAY;
??????*/
?????/*????//?錯誤2,枚舉成員重名,編譯時報錯:redeclaration //of
??//?enumerator?‘MON’
???typedef?enum?workday
??????{
???????? ? MON,???????//?MON?=?1;
????????? TUE,
?????? ???WEN,
???????? ?THU,
?????? ??FRI,
???????}workday;
??????typedef?enum?weekend
??????{
?????????MON,
?????????SAT,
?????????SUN,
???????}weekend;
?????//?結構體中元素可以重名
?????typedef?struct?
?????{
????????int?a;
????????char?b;
?????}st1;
??????typedef?struct?
??????{
?????????int?a;
?????????char?b;
??????}st2;
??????*/
說明:
? ? ? ? ? ??
? ? ? 經(jīng)過測試,兩個struct類型內的成員名稱可以重名,而兩個enum類型中的成員不可以重名。實際上從兩者的成員在訪問方式上的不同就可以看出了。struct類型成員的訪問方式是:變量名.成員,而enum成員的訪問方式為:成員名。因此若兩個enum類型中有重名的成員,那代碼中訪問這個成員時到底指的是哪個enum中的成員呢?所以不能重名。但是兩個#define宏定義是可以重名的,該宏名真正的值取決于最后一次定義的值。編譯器會給出警告但不會error,下面的示例會讓編譯器發(fā)出A被重復定義的警告。
?#include?
?#define?A??5
?#define?A?7
?int?main(void)
?{
????printf("hello?world\n");
???return?0;
??}?
c、代碼實戰(zhàn)演示:
#include?
???typedef?enum?week
???{
?????????SUN,???????//?SUN?=?0
?????????MON,???????//?MON?=?1;
?????????TUE,????????//2
?????????WEN,????????//3
?????????THU,
?????????FRI,
?????????SAT,
???}week;
??int?main(void)
??{
??????//?測試定義方法4,5
????????week?today;
???????today?=?WEN;
???????printf("today?is?the?%d?th?day?in?week\n",?today);
???????return?0;
??}?
演示結果:
??today?is?the?3?th?day?in?week
d、接著我們把上面枚舉變量改變它的值(不按照編譯模式方式來),看看會發(fā)生什么變化:
??#include?
??typedef?enum?week
?{
?? ? ?SUN,????????//?SUN?=?0
???? MON=8,??????//?MON?=?1;
???? TUE,????????//2
???? WEN,????????//3
?? ? ?THU,
??? ? FRI,
??? ?SAT,
?}week;
??????int?main(void)
??????{
??????????//?測試定義方法4,5
???????week?today,hh;
???????today?=?WEN;
???????hh=SUN;
???????printf("today?is?the?%d?th?day?in?week\n",?SUN);
???????printf("today?is?the?%d?th?day?in?week\n",?today);
???????return?0;
??}?
演示結果(我們可以看到改變了枚舉成員值,它就在這個基礎遞增下面的成員值):
????????today?is?the?0?th?day?in?week
????????today?is?the?10?th?day?in?week
注意:
? ? ??
這里要注意,只能把枚舉值賦予枚舉變量,不能把元素的數(shù)值直接賦予枚舉變量,如一定要把數(shù)值賦予枚舉變量,則必須用強制類型轉換,但是我在測試時,發(fā)現(xiàn)編譯器居然可以這樣賦值,讀者最好自己測試一下(不過這里后面發(fā)現(xiàn)在c語言里面可以這樣操作,在c++里面不可以這樣操作,必須強制類型轉換)。
枚舉元素不是字符常量也不是字符串常量,使用時不要加單、雙引號。
枚舉類型是一種基本數(shù)據(jù)類型,而不是一種構造類型,因為它不能再分解為任何基本類型。
枚舉值是常量,不是變量。
三、大小端模式:
1、什么是叫大小端模式?
? ? ?a、什么叫大端模式(big-endian)?
? ? ? ? ? ?在這種格式中,字數(shù)據(jù)的高字節(jié)存儲在低地址中,而字數(shù)據(jù)的低字節(jié)則存放在高地址中。
? ?b、什么叫小端模式(little-endian)?
? ? 與大端存儲格式相反,在小端存儲格式中,低地址中存放的是字數(shù)據(jù)的低字節(jié),高地址存放的是字數(shù)據(jù)的高字節(jié)。
2、實際解釋:
? -----?我們把一個16位的整數(shù)0x1234存放到一個短整型變量(short)中。這個短整型變量在內存中的存儲在大小端模式由下表所示:
地址偏移 | 大端模式 | 小端模式 |
0x00 | 12 | 34 |
0x01 | 34 | 12 |
?說明:
? ? ? ??由上表所知,采用大小模式對數(shù)據(jù)進行存放的主要區(qū)別在于在存放的字節(jié)順序,大端方式將高位存放在低地址,小端方式將低位存放在低地址。
3、代碼實戰(zhàn)來判斷大小端模式:
#include?
????//?共用體中很重要的一點:a和b都是從u1的低地址開始的。
???//?假設u1所在的4字節(jié)地址分別是:0、1、2、3的話,那么a自然就是0、1、2、3;
??//?b所在的地址是0而不是3.
????union?myunion
????{
????????int?a;
????????char?b;
?????};
????//?如果是小端模式則返回1,小端模式則返回0
??????int?is_little_endian(void)
?????{
??????????union?myunion?u1;
??????????u1.a?=?1;?????????????//?地址0的那個字節(jié)內是1(小端)或者0(大端)
??????????return?u1.b;
???}
??int?is_little_endian2(void)
??{
?????????int?a?=?1;
?????????char?b?=?*((char?*)(&a));??????//?指針方式其實就是共用體的本質
?????????return?b;
?}
??????int?main(void)
??????{
???????int?i?=?is_little_endian2();
??????if?(i?==?1)
?????{
???????????printf("小端模式\n");
?????}
?????else
????{
??????????printf("大端模式\n");
????}
????????return?0;
????}
演示結果:
? ? ? ? ? ? ? ? ?
??這是小端模式
4、看似可行實則不行的測試大小端方式:位與、移位、強制類型轉化:
????#include?
????int?main(void)
????{
??????????????//?強制類型轉換
??????????????int?a;
??????????????char?b;
??????????????a?=?1;
??????????????b?=?(char)a;
?????????????printf("b?=?%d.\n",?b);??//?b=1
???????????????????/*
????????????????//?移位
?????????????????int?a,?b;
?????????????????a?=?1;
?????????????????b?=?a?>>?1;
?????????????????printf("b?=?%d.\n",?b);????//b=0
??????????????????*/
???????????????/*
???????//?位與
????????int?a?=?1;
??????? int b = a &?0xff;???????//?也可以寫成:char b
????????printf("b?=?%d.\n",?b);???//b=1??
?????*/
???????????return?0;
?????}
說明:
(1)位與運算:
? ?結論:位與的方式無法測試機器的大小端模式。(表現(xiàn)就是大端機器和小? ? 端機器的&運算后的值相同的)
? ?理論分析:位與運算是編譯器提供的運算,這個運算是高于內存層次的(或者說&運算在二進制層次具有可移植性,也就是說&的時候一定是高字節(jié)&高字節(jié),低字節(jié)&低字節(jié),和二進制存儲無關)。
(2)移位:
? ? 結論:移位的方式也不能測試機器大小端。
? ? 理論分析:原因和&運算符不能測試一樣,因為C語言對運算符的級別是高于二進制層次的。右移運算永遠是將低字節(jié)移除,而和二進制存儲時這個低字節(jié)在高位還是低位無關的。
(3)強制類型轉換和上面分析一樣的。
5、通信系統(tǒng)中的大小端(數(shù)組的大小端)
(1)譬如要通過串口發(fā)送一個0x12345678給接收方,但是因為串口本身限制,只能以字節(jié)為單位來發(fā)送,所以需要發(fā)4次;接收方分4次接收,內容分別是:0x12、0x34、0x56、0x78.接收方接收到這4個字節(jié)之后需要去重組得到0x12345678(而不是得到0x78563412)。
(2)所以在通信雙方需要有一個默契,就是:先發(fā)/先接的是高位還是低位?這就是通信中的大小端問題。
(3)一般來說是:先發(fā)低字節(jié)叫小端;先發(fā)高字節(jié)就叫大端。在實際操作中,在通信協(xié)議里面會去定義大小端,明確告訴你先發(fā)的是低字節(jié)還是高字節(jié)。
(4)在通信協(xié)議中,大小端是非常重要的,大家使用別人定義的通信協(xié)議還是自己要去定義通信協(xié)議,一定都要注意標明通信協(xié)議中大小端的問題。
四、總結:
? ? ? ? 上面分享了一些我們常用的一些用法,掌握了這些就可以了,當日后工作中有其他用法,再總結歸納,完善自己的知識體系。
叨叨一下,最近建了一個學習群,用于學習交流,需要加群的,加微信號:cyuyan2020,備注:加群
點【在看】是最大的支持?