
緩存和數(shù)據(jù)庫一致性問題,看這篇就夠了

源?/?? ? ? ??文/?
到底是更新緩存還是刪緩存? 到底選擇先更新數(shù)據(jù)庫,再刪除緩存,還是先刪除緩存,再更新數(shù)據(jù)庫? 為什么要引入消息隊(duì)列保證一致性? 延遲雙刪會(huì)有什么問題?到底要不要用? ...
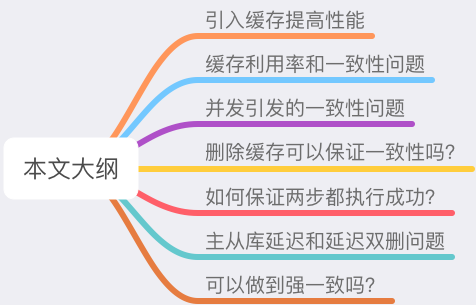
引入緩存提高性能
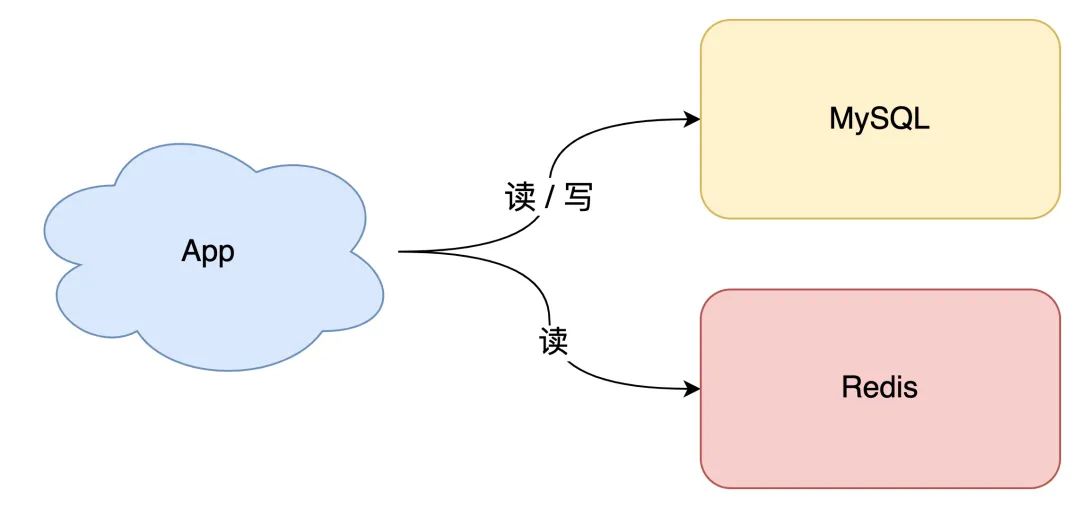
數(shù)據(jù)庫的數(shù)據(jù),全量刷入緩存(不設(shè)置失效時(shí)間) 寫請(qǐng)求只更新數(shù)據(jù)庫,不更新緩存 啟動(dòng)一個(gè)定時(shí)任務(wù),定時(shí)把數(shù)據(jù)庫的數(shù)據(jù),更新到緩存中
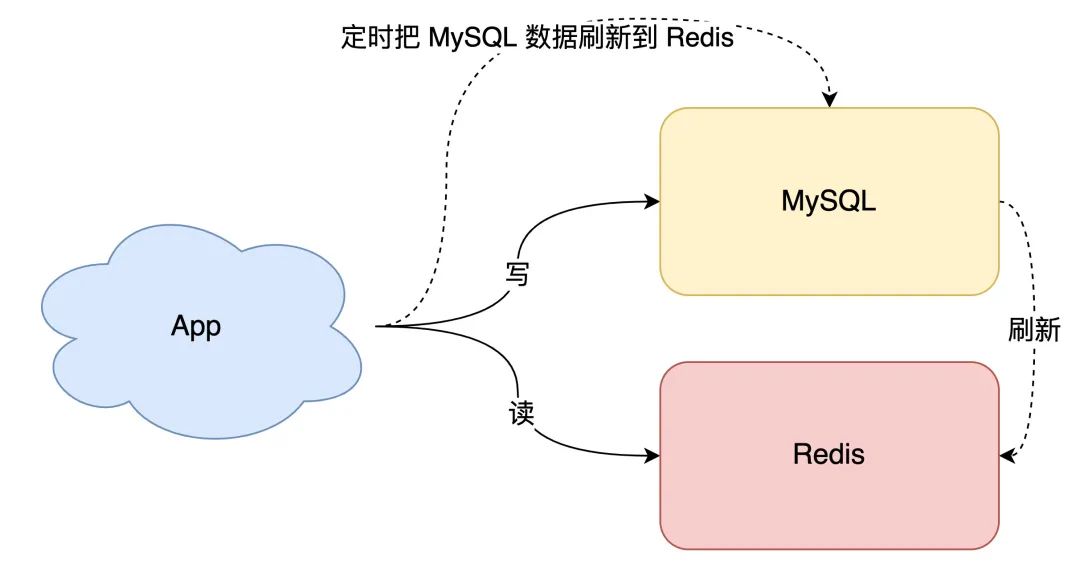
緩存利用率低:不經(jīng)常訪問的數(shù)據(jù),還一直留在緩存中 數(shù)據(jù)不一致:因?yàn)槭恰付〞r(shí)」刷新緩存,緩存和數(shù)據(jù)庫存在不一致(取決于定時(shí)任務(wù)的執(zhí)行頻率)
緩存利用率和一致性問題
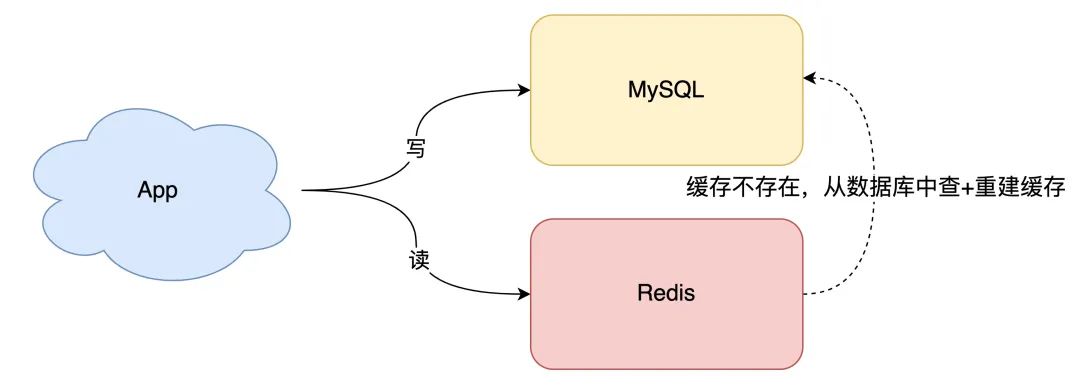
寫請(qǐng)求依舊只寫數(shù)據(jù)庫 讀請(qǐng)求先讀緩存,如果緩存不存在,則從數(shù)據(jù)庫讀取,并重建緩存 同時(shí),寫入緩存中的數(shù)據(jù),都設(shè)置失效時(shí)間
先更新緩存,后更新數(shù)據(jù)庫 先更新數(shù)據(jù)庫,后更新緩存
并發(fā)引發(fā)的一致性問題
線程 A 更新數(shù)據(jù)庫(X = 1) 線程 B 更新數(shù)據(jù)庫(X = 2) 線程 B 更新緩存(X = 2) 線程 A 更新緩存(X = 1)
同樣地,采用「先更新緩存,再更新數(shù)據(jù)庫」的方案,也會(huì)有類似問題,這里不再詳述。
刪除緩存可以保證一致性嗎?
先刪除緩存,后更新數(shù)據(jù)庫 先更新數(shù)據(jù)庫,后刪除緩存
線程 A 要更新 X = 2(原值 X = 1) 線程 A 先刪除緩存 線程 B 讀緩存,發(fā)現(xiàn)不存在,從數(shù)據(jù)庫中讀取到舊值(X = 1) 線程 A 將新值寫入數(shù)據(jù)庫(X = 2) 線程 B 將舊值寫入緩存(X = 1)
緩存中 X 不存在(數(shù)據(jù)庫 X = 1) 線程?A?讀取數(shù)據(jù)庫,得到舊值(X?=?1) 線程 B 更新數(shù)據(jù)庫(X = 2) 線程 B 刪除緩存 線程 A 將舊值寫入緩存(X = 1)
緩存剛好已失效 讀請(qǐng)求 + 寫請(qǐng)求并發(fā) 更新數(shù)據(jù)庫 + 刪除緩存的時(shí)間(步驟 3-4),要比讀數(shù)據(jù)庫 + 寫緩存時(shí)間短(步驟 2 和 5)
如何保證兩步都執(zhí)行成功?
立即重試很大概率「還會(huì)失敗」 「重試次數(shù)」設(shè)置多少才合理? 重試會(huì)一直「占用」這個(gè)線程資源,無法服務(wù)其它客戶端請(qǐng)求
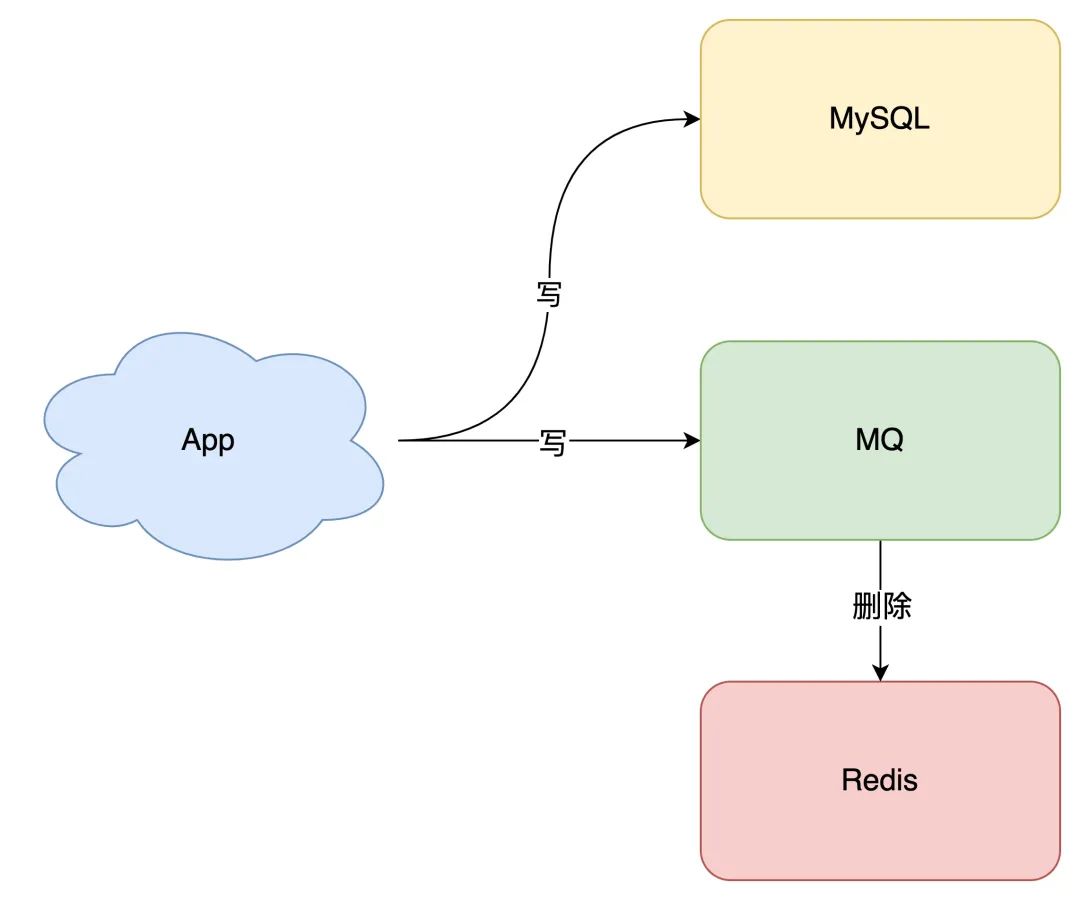
消息隊(duì)列保證可靠性:寫到隊(duì)列中的消息,成功消費(fèi)之前不會(huì)丟失(重啟項(xiàng)目也不擔(dān)心) 消息隊(duì)列保證消息成功投遞:下游從隊(duì)列拉取消息,成功消費(fèi)后才會(huì)刪除消息,否則還會(huì)繼續(xù)投遞消息給消費(fèi)者(符合我們重試的場(chǎng)景)
寫隊(duì)列失敗:操作緩存和寫消息隊(duì)列,「同時(shí)失敗」的概率其實(shí)是很小的 維護(hù)成本:我們項(xiàng)目中一般都會(huì)用到消息隊(duì)列,維護(hù)成本并沒有新增很多
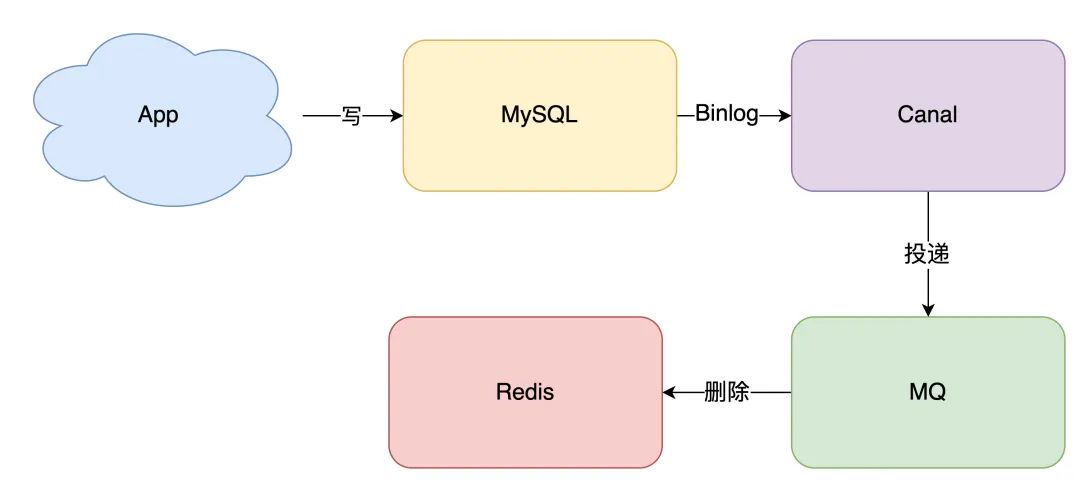
無需考慮寫消息隊(duì)列失敗情況:只要寫 MySQL 成功,Binlog 肯定會(huì)有 自動(dòng)投遞到下游隊(duì)列:canal 自動(dòng)把數(shù)據(jù)庫變更日志「投遞」給下游的消息隊(duì)列
如果你有留意觀察很多數(shù)據(jù)庫的特性,就會(huì)發(fā)現(xiàn)其實(shí)很多數(shù)據(jù)庫都逐漸開始提供「訂閱變更日志」的功能了,相信不遠(yuǎn)的將來,我們就不用通過中間件來拉取日志,自己寫程序就可以訂閱變更日志了,這樣可以進(jìn)一步簡化流程。
主從庫延遲和延遲雙刪問題
線程 A 要更新 X = 2(原值 X =?1) 線程 A 先刪除緩存 線程 B 讀緩存,發(fā)現(xiàn)不存在,從數(shù)據(jù)庫中讀取到舊值(X = 1) 線程 A 將新值寫入數(shù)據(jù)庫(X = 2) 線程 B 將舊值寫入緩存(X = 1)
線程 A 更新主庫 X = 2(原值 X = 1) 線程 A 刪除緩存 線程 B 查詢緩存,沒有命中,查詢「從庫」得到舊值(從庫 X = 1) 從庫「同步」完成(主從庫 X = 2) 線程 B 將「舊值」寫入緩存(X = 1)
問題1:延遲時(shí)間要大于「主從復(fù)制」的延遲時(shí)間 問題2:延遲時(shí)間要大于線程 B 讀取數(shù)據(jù)庫 + 寫入緩存的時(shí)間
可以做到強(qiáng)一致嗎?
總結(jié)
后記

?推薦閱讀

華為最美小姐姐被外派墨西哥后...

國內(nèi)有程序員電視劇了,結(jié)果看了一分鐘,就吐了...
男女洗澡前后區(qū)別,太形象了!
END


頂級(jí)程序員:topcoding
做最好的程序員社區(qū):Java后端開發(fā)、Python、大數(shù)據(jù)、AI
一鍵三連「分享」、「點(diǎn)贊」和「在看」
評(píng)論
圖片
表情