
centerX: 用新的視角的方式打開CenterNet
AI編輯:我是小將
本文作者:?CPFLAME
https://zhuanlan.zhihu.com/p/323814368
本文已由原作者授權(quán)
筆者重構(gòu)了一版centernet(objects as points)的代碼,并加入了蒸餾,多模型蒸餾,轉(zhuǎn)caffe,轉(zhuǎn)onnx,轉(zhuǎn)tensorRT,把后處理也做到了網(wǎng)絡(luò)前向當中,對落地非常的友好。
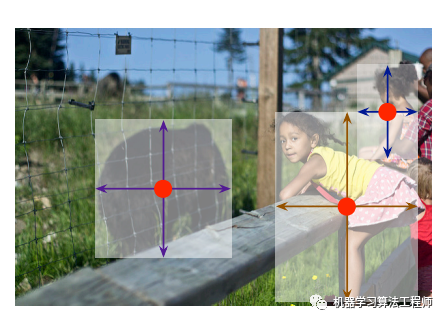
放一個centerX多模型蒸餾出來的效果圖,在蒸餾時沒有用到數(shù)據(jù)集的標簽,只用了兩個teacher的model蒸餾同一個student網(wǎng)絡(luò)。就用大家的老婆來做demo吧。

不感興趣的童鞋可以收藏一下筆者的表情包,如果覺得表情包好玩,跪求去github點贊。
代碼地址:https://github.com/CPFLAME/centerX/
centernet是我最喜歡的檢測文章之一,沒有anchor,沒有nms,結(jié)構(gòu)簡單,可拓展性強,最主要的是:落地極其方便,選一個簡單的backbone,可以沒有bug的轉(zhuǎn)成你想要的模型(caffe,onnx,tensorRT)。并且后處理也極其的方便。
但是centernet原版的代碼我初看時有點吃力,但也沒有重構(gòu)的想法,過了一些時日后我找到了centernet-better和centernet-better-plus,于是把他們的代碼白嫖了過來然后自己完善一下,形成對我友好的代碼風格。(當然剽竊最多的其實是fast reID和detectron2)

由于本人不喜歡寫純技術(shù)方面的博客,也不想寫成一篇純PR稿(從本科開始就深惡痛覺寫實驗報告),更不想讓人覺得讀這篇文章是在學習,所以本篇文章不太正經(jīng),也沒有捧一踩一的操作,跟別人的宣傳稿不太一樣。
畢竟代碼寫的不是打打殺殺,而是人情世故,真學東西還得看其他人的文章,看我的也就圖一樂。
宣傳部分
一般來說讀文章的人點進來都會帶著這樣一個心理,我為什么要用centerX,明明我用別的框架用的很順利了,轉(zhuǎn)過來多麻煩你知道嗎,你在教我做事?

如果你需要用檢測算法快速的落地,需要一個速度快并精度尚可的模型,而且可以無坑轉(zhuǎn)caffe,onnx,tensorRT,同時基本不用寫后處理,那centerX會很適合你。(原本centernet的后處理需要額外的3X3 pooling和topK的操作,被作者用一個極騷操作放到了網(wǎng)絡(luò)里面)
如果你想在檢測的任務(wù)上體會一下模型蒸餾的快感,在baseline上無痛漲點,或者找一些detection蒸餾的靈感,可以來centerX康康。
如果你同時只有兩個單類標注的數(shù)據(jù)集,但是你懶得去補全這兩個數(shù)據(jù)集各自缺失的類別標注,你可以嘗試使用centerX訓練得到一個可以同時預測兩類標注的檢測器。
如果你想基于centernet做一些學術(shù)研究,你同樣也可以在centerX的projects里面重構(gòu)自己的代碼,和centerX里面centernet的codebase并不沖突,可以快速定位bug。
如果你是苦逼的學生或者悲催的工具人,你可以用centerX來向上管理你的老師或者領(lǐng)導,因為centerX里面的mAP點不高,稍微調(diào)一下或者加點東西就可以超越本人的baseline,到時候匯報的時候可以拍著胸脯說你跑出的東西比作者高了好幾個點,然后你的KPI就可以稍微有點保障了。(文章后面會給幾個方向怎么跑的比作者更高)

centerX的底層框架白嫖自優(yōu)秀檢測框架detectron2,如果之前有跑過detectron2的經(jīng)驗,相信可以和馬大師的閃電連五鞭一樣,無縫銜接的使用。
如果沒有detectron2的使用經(jīng)驗,那也沒有關(guān)系,我專門寫了懶人傻瓜式run.sh,只需要改改config和運行指令就可以愉快地跑起來了。
如果上述的理由都沒有打動你,那么如果我用這篇文章把你逗樂了,懇求去github給個star吧。
代碼核心思想
受到老領(lǐng)導道家思維編程的啟發(fā),centerX的trick里面也貫徹了一些具有中國特色社會主義的中心主題思想。
代碼cv大法————拿來主義
模型蒸餾————先富帶動后富
多模型蒸餾,兩個單類檢測模型融合成為一個多類檢測模型————圣人無常師
共產(chǎn)主義loss,解決模型對lr太過敏感問題————馬克思主義
把后處理放到神經(jīng)網(wǎng)絡(luò)中————團結(jié)我們真正的朋友,以攻擊我們的真正的敵人,分清敵我。《毛選》

centerX各個模塊
基礎(chǔ)實現(xiàn)
這個方面沒有什么好說的,也沒有做到和其他框架的差異化,只是在detectron2上對基礎(chǔ)的centernet進行了復現(xiàn)而已,而且大部分代碼都是白嫖自centernet-better和centernet-better-plus,就直接上在COCO上的實驗結(jié)果吧。
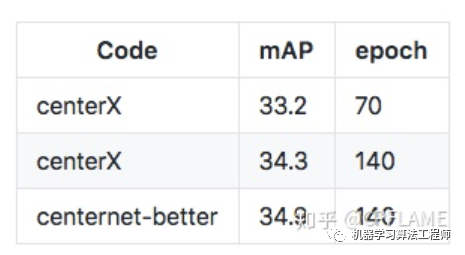
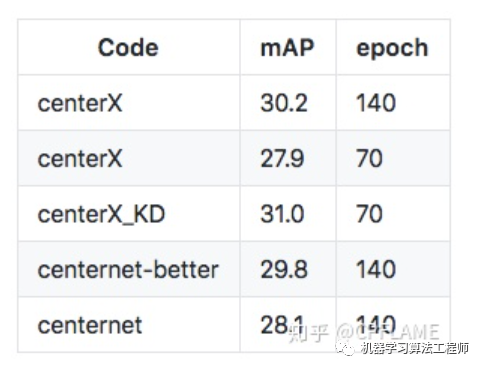
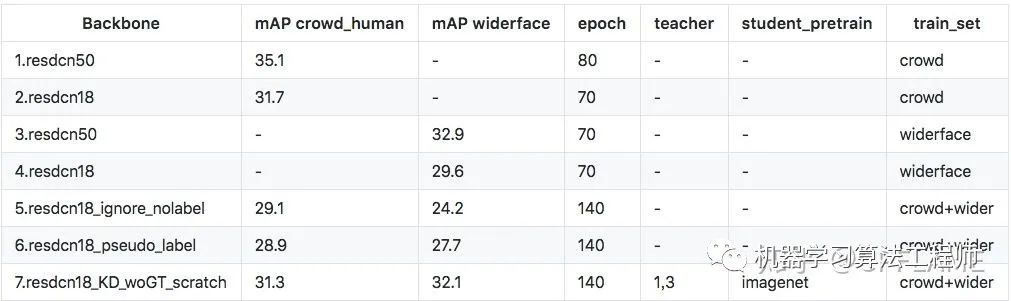
centerX_KD是用27.9的resnet18作為學生網(wǎng)絡(luò),33.2的resnet50作為老師網(wǎng)絡(luò)蒸餾得到的結(jié)果,詳細過程在在下面的章節(jié)會講。
模型蒸餾
大嘎好,我是detection。我時常羨慕的看著隔壁村的classification,embedding等玩伴,他們在蒸餾上面都混得風生水起,什么logits蒸餾,什么KL散度,什么Overhaul of Feature Distillation。每天都有不同的家庭教師來指導他們,憑什么我detection的教育資源就很少,我detection什么時候才能站起來!

造成上述的原因主要是因為detection的范式比較復雜,并不像隔壁村的classification embedding等任務(wù),開局一張圖,輸出一個vector:
1.two stage的網(wǎng)絡(luò)本身由于rpn輸出的不確定性,導致teacher和student的proposal對齊是個大問題。
2.筆者嘗試過在中間層feature上進行蒸餾,這樣就可以偷懶不用寫最后的logits蒸餾部分的代碼了,結(jié)果沒有卵用,還是得在logits上蒸餾比較穩(wěn)。
3.我編不下去了
我們再來回頭看看centernet的范式,哦,我的上帝,多么簡單明了的范式:
1.網(wǎng)絡(luò)輸出三個頭,一個預測中心點,一個預測寬高,一個預測中心點的偏移量
2.沒有復雜的正負樣本采樣,只有物體的中心點是正樣本,其他都是負樣本
這讓筆者看到了在detection上安排家庭教師的希望,于是我們仿照了centernet本來的loss的寫法,仿照了一個蒸餾的loss。具體的實現(xiàn)可以去code里面看,這里就說一下簡單的思想。
1.對于輸出中心點的head,把teacher和student輸出的head feature map過一個relu層,把負數(shù)去掉,然后做一個mse的loss,就OK了。
2.對于輸出寬高和中心點的head,按照原centernet的實現(xiàn)是只學習正樣本,在這里筆者拍腦袋想了一個實現(xiàn)方式:我們用teacher輸出中心點的head過了relu之后的feature作為系數(shù),在寬高和中心點的head上所有像素點都做L1 loss后和前面的系數(shù)相乘。
3.在蒸餾時,三個head的蒸餾loss差異很大,需要手動調(diào)一下各自的loss weight,一般在300次迭代后各個蒸餾loss在0~3之間會比較好。
4.所以在之前我都是300次epoch之后直接停掉,然后根據(jù)當前l(fā)oss 預估一個loss weight重新開始訓練。這個愚蠢的操作在我拍了另外一次腦袋想出共產(chǎn)主義loss之后得以丟棄。
5.在模型蒸餾時我們既可以在有標簽的數(shù)據(jù)上聯(lián)合label的loss進行訓練,也可以直接用老師網(wǎng)絡(luò)的輸出在無標簽的數(shù)據(jù)集上蒸餾訓練。基于這個特性我們有很多妙用
6.當在有標簽的數(shù)據(jù)上聯(lián)合label的loss進行訓練時,老師訓N個epoch,學生訓N個epoch,然后老師教學生,并保留原本的label loss再訓練N個epoch,這樣學生的mAP是訓出來最高的。
7.當在無標簽的數(shù)據(jù)集上蒸餾訓練時,我們就跳出了數(shù)據(jù)集的限制,先在有標簽的數(shù)據(jù)集上老師訓N個epoch,然后老師在無標簽的數(shù)據(jù)集上蒸餾學生模型訓練N個epoch,可以使得學生模型的精度比baseline要高,并且泛化性能更好。
8.之前在centernet的source code上還跑過一個實驗,相同的網(wǎng)絡(luò),自己蒸餾自己也是可以漲點的。在centerX上我忘記加進去了。
9.結(jié)構(gòu)相同的teacher和student可以漲點,不一樣結(jié)構(gòu)可能會掉點。
我們拉到實驗的部分,上述的瞎比猜想得到驗證。
多模型蒸餾
看到蒸餾效果還可以,可以在不增加計算量的情況下無痛漲點,筆者高興了好一陣子,直到筆者在實際項目場景上遇到了一個尷尬地問題:
我有一個數(shù)據(jù)集A,里面有物體A的標注
我有一個數(shù)據(jù)集B,里面有物體B的標注
現(xiàn)在由于資源有限,只能跑一個檢測網(wǎng)絡(luò),我怎么得到可以同時預測物體A和物體B的檢測器?
因為數(shù)據(jù)集A里面可能會有大量的未標注的B,B里面也會有大量的未標注的A,直接放到一起訓練肯定不行,網(wǎng)絡(luò)會學傻
常規(guī)的操作是去數(shù)據(jù)集A里面標B,然后去數(shù)據(jù)集B里面標A,這樣在加起來的數(shù)據(jù)集上就可以訓練了。但是標注成本又很貴,這讓灑家如何是好?
稍微騷一點的操作是在A和B上訓練兩個網(wǎng)絡(luò),然后在缺失的標注數(shù)據(jù)集上預測偽標簽,然后在補全的數(shù)據(jù)集上訓練
novelty更高的操作是在沒有標注的數(shù)據(jù)集上屏蔽網(wǎng)絡(luò)對應(yīng)的輸出,(該操作僅在C個二分類輸出的檢測器下可用)
有沒有一種方法,也不用標數(shù)據(jù),也不用像偽標簽那么粗糙,直接躺平,同時novelty也比較高,比較好跟領(lǐng)導說KPI的一個方法?
在筆者再次拍了拍腦袋后,發(fā)揮了我最擅長的技能:白嫖。想到了這樣一個方案:
我先在數(shù)據(jù)A上訓練個老師模型A,然后在數(shù)據(jù)B上訓練老師模型B,然后我把老師模型A和B的功力全部傳給學生模型C,豈不美哉?
我們再來看看centernet的范式,我再次吹爆這個作者的工作,不僅簡單易懂的支持了centerPose,centertrack,center3Ddetection,還可以輸出可旋轉(zhuǎn)的物體檢測。
無獨有偶,可能是為了方便復用focal loss,作者在分類時使用了C個二分類的分類器,而不是softmax分類,這給了筆者白嫖的靈感:既然是C個二分類的分類器,那么對于每一個類別,那么我們可以給學生網(wǎng)絡(luò)分別找一個家庭教師,這樣就可以擁有多倍的快樂。
理論上來說可以有很多個老師,并且每個老師教的類別都可以是多個。
那么我們的多模型蒸餾就可以用現(xiàn)有的方案拼湊起來了。這相當于我同時白嫖了自己的代碼,以及不完整標注的數(shù)據(jù)集,白嫖是真的讓人快樂啊。和上述提到的操作進行一番比♂較,果然用了的多模型蒸餾的效果要好一些。又一個瞎比猜想被驗證了。
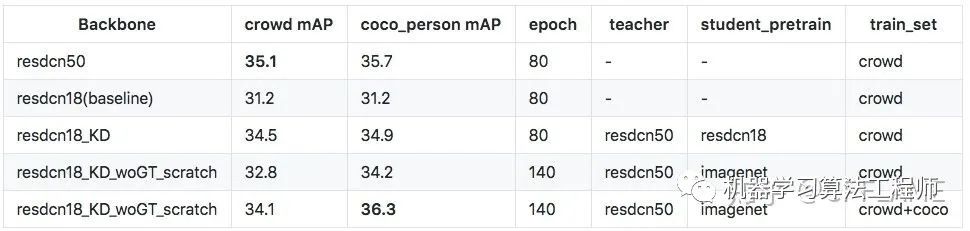
筆者分別在人體和車,以及人體和人臉上做了實驗。數(shù)據(jù)集為coco_car,crowd_human,widerface.
共產(chǎn)主義loss
筆者在訓練centerX時,出現(xiàn)過這樣一個問題,設(shè)置合適的lr時,訓練的一切都那么自然又和諧,而當我lr設(shè)置大了以后,有時候會訓到一半,網(wǎng)絡(luò)直接loss飛漲然后mAP歸零又重新開始往上爬,導致最后模型的mAP很拉胯。對于這種情況脾氣暴躁的我直接爆了句粗口。

罵完了爽歸爽,問題還是要解決的,為了解決這個問題,筆者首先想到筆者的代碼是不是哪里有bug,但是找了半天都沒找到,筆者還嘗試了如下的方式:
加入clip gradients,不work
自己加了個skip loss,當本次iter的loss是上次loss的k=1.1倍以上時,這次loss全部置0,不更新網(wǎng)絡(luò),不work
換lr_scheduler, 換optimalizer, 不work
看來這個bug油鹽不進,軟硬不吃。訓練期間總會出現(xiàn)某個時間段loss突然增大,然后網(wǎng)絡(luò)全部從頭開始訓練的情況。
這讓我想到了內(nèi)卷加速,資本主義泡沫破裂,經(jīng)濟大危機后一切推倒重來。這個時候才想起共產(chǎn)主義的好,毛主席真是永遠滴神。
既然如此,咱們一不做二不休,直接把蛋糕給loss們分好,讓共產(chǎn)主義無產(chǎn)階級的光照耀到它們身上,筆者一氣之下把loss的大小給各個兔崽子head們給規(guī)定死,具體操作如下:
給每個loss設(shè)置一個可變化的loss weight,讓loss一直保持在一個固定的值。
考慮到固定的loss值比較硬核,筆者把lr設(shè)置為cosine的lr,讓lr比較平滑的下降,來模擬正常情況下網(wǎng)絡(luò)學習到的梯度分布。
其實本loss可以改名叫adaptive loss,但是為了紀念這次的氣急敗壞和思維升華,筆者依然任性的把它稱之為共產(chǎn)主義loss。
接下來就是實驗部分看看管不管用了,于是筆者嘗試了一下之前崩潰的lr,得益于共產(chǎn)主義的好處,換了幾個數(shù)據(jù)集跑實驗都沒有出現(xiàn)mAP拉胯的情況了,期間有幾次出現(xiàn)了loss飛漲的情況,但是在共產(chǎn)主義loss強大的調(diào)控能力之下迅速恢復到正常狀態(tài),看來社會主義確實優(yōu)越。同時筆者也嘗試了用合適的lr,跑baseline和共產(chǎn)主義loss的實驗,發(fā)現(xiàn)兩者在±0.3的mAP左右,影響不大。
筆者又為此高興了好一段時間,并且發(fā)現(xiàn)了共產(chǎn)主義loss可以用在蒸餾當中,并且表現(xiàn)也比較穩(wěn)定,在±0.2個mAP左右。這下蒸餾可以end2end訓練了,再也不用人眼去看loss、算loss weight、停掉從頭訓了。
模型加速
這個部分的代碼都在code的projects/speedup中,注意網(wǎng)絡(luò)中不能包含DCN,不然轉(zhuǎn)碼很難。
centerX中提供了轉(zhuǎn)caffe,轉(zhuǎn)onnx的代碼,onnx轉(zhuǎn)tensorRT只要裝好環(huán)境后一行指令就可以轉(zhuǎn)換了,筆者還提供了轉(zhuǎn)換后不同框架的前向代碼。
其中筆者還找到了centernet的tensorRT前向版本(后續(xù)筆者把它稱為centerRT),在里面用cuda寫了centernet的后處理(包括3X3 max pool和topK后處理)。筆者在轉(zhuǎn)完了tensorRT之后想直接把centerRT白嫖過來,結(jié)果發(fā)現(xiàn)還是有些麻煩,centerRT有點像是為了centernet原始實現(xiàn)定制化去寫的。這就有了以下的問題
不僅是tensorRT版本,所有的框架上我都不想寫麻煩的后處理,我想把麻煩的操作都寫到網(wǎng)絡(luò)里面去,這樣我就什么都不用干了,直接躺平
在centernet cls head的輸出后面再加一層3X3的max pooling,可以減少一部分后處理的代碼
有沒有辦法使得最后中心點head的輸出滿足以下條件:1.除了中心點之外,其他的像素值全是0,(相當于已經(jīng)做過了pseudo nms);2.后處理只需要在這個feature上遍歷>thresh的像素點位置就可以了。
如果x1表示centernet的中心點輸出,x2表示經(jīng)過了3X3 maxpool之后的輸出,那么在python里面其實只需要寫上一行代碼就得到上述的條件:y = x1[x1==x2]。但是筆者在使用轉(zhuǎn)換時,onnx不支持==的操作。得另謀他路。

這次筆者拍碎了腦袋都沒想到怎么白嫖,于是在獻祭了幾根珍貴的頭發(fā)之后,強行發(fā)動了甩鍋技能,把后處理操作都扔給神經(jīng)網(wǎng)絡(luò),具體操作如下:
x2是x1的max pool,我們需要的是x1[x1==x2]的feature map
那么我們只需要得到x1==x2,也就是一張二值化的mask,然后用mask*x1就可以了,。
由于x2是x1的max pool,所以x1-x2 <= 0, 我們在x1-x2上加一個很小的數(shù),使得等于0的像素點變成正數(shù),小于0的像素點仍然為負數(shù)。然后在加個relu,乘以一個系數(shù)使得正數(shù)縮放到1,就可以得到我們想要的東西了。
代碼如下:
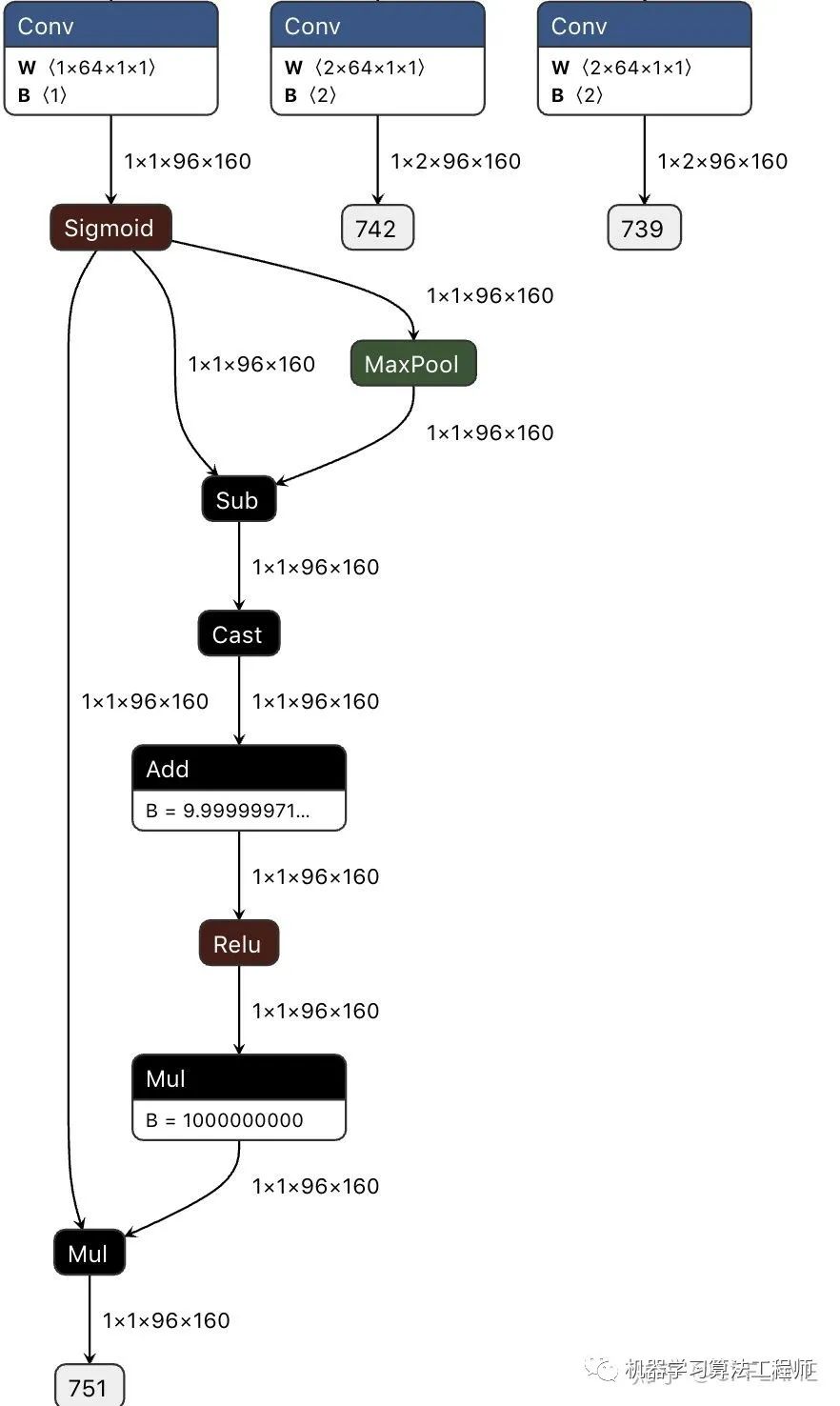
def centerX_forward(self, x):
x = self.normalizer(x / 255.)
y = self._forward(x)
fmap_max = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)(y['cls'])
keep = (y['cls'] - fmap_max).float() + 1e-9
keep = nn.ReLU()(keep)
keep = keep * 1e9
result = y['cls'] * keep
ret = [result,y['reg'],y['wh']] ## change dict to list
return retonnx中可視化如下:
然后我們可以來康康經(jīng)歷了騷操作之后的后處理代碼,極其的簡單,相信也可以在任何的框架上快速的實現(xiàn):
def postprocess(self, result, ratios, thresh=0.3):
clses, regs, whs = result
# clses: (b,c,h,w)
# regs: (b,2,h,w)
bboxes = []
for cls, reg, wh, ratio in zip(clses, regs, whs, ratios):
index = np.where(cls >= thresh)
ratio = 4 / ratio
score = np.array(cls[index])
cat = np.array(index[0])
ctx, cty = index[-1], index[-2]
w, h = wh[0, cty, ctx], wh[1, cty, ctx]
off_x, off_y = reg[0, cty, ctx], reg[1, cty, ctx]
ctx = np.array(ctx) + np.array(off_x)
cty = np.array(cty) + np.array(off_y)
x1, x2 = ctx - np.array(w) / 2, ctx + np.array(w) / 2
y1, y2 = cty - np.array(h) / 2, cty + np.array(h) / 2
x1, y1, x2, y2 = x1 * ratio, y1 * ratio, x2 * ratio, y2 * ratio
bbox = np.stack((cat, score, x1, y1, x2, y2), axis=1).tolist()
bbox = sorted(bbox, key=lambda x: x[1], reverse=True)
bboxes.append(bbox)
return bboxes值得注意的是上述騷操作在轉(zhuǎn)caffe的時候會報錯,所以不能加。如果非要添加上去,得在caffe的prototxt中自行添加scale層,elementwise層,relu層,這個筆者沒有實現(xiàn),大家感興趣可以自行添加。
優(yōu)化方向
考慮到大家需要向上管理,筆者寫幾個可以漲點的東西
在centernet作者本來的issue里面提到,centernet很依賴于網(wǎng)絡(luò)最后一層的特征,所以加上dlaup會漲點特別明顯,但是由于feature的channel太多,會有一些時間損耗。筆者實測在某個backbone+deconv上加上dlaup之后,batchsize=8時間由32ms->44ms左右,有一些代價,所以筆者沒有加。后續(xù)應(yīng)該可以把dlaup里面的卷積全部改為depthwise的,找到一個速度和精度的平衡
想想辦法看看能不能把Generalized Focal Loss,Giou loss等等剽竊過來,稍微改一下加到centernet里面
調(diào)參,lr,lossweight,或者共產(chǎn)主義loss里面各個固定loss值,不同數(shù)據(jù)集上不同backbone的參數(shù)都可以優(yōu)化
用一個牛逼的pretrain model
把隔壁fast reid的自動超參搜索白嫖過來
除了以上的在精度方面的優(yōu)化之外,其實筆者還想到很多可以做的東西,咱們不在精度這個地方跟別人卷,因為卷不過別人,檢測這個領(lǐng)域真是神仙打架,打不過打不過。我們想著把蛋糕做大,大家一起有肉吃
蒸餾不僅適用于centernet,筆者再提一個瞎比猜想:所有的one-stage detector和anchor-free的檢測器都可以蒸餾,而且最后的檢測頭的cls層全部改為C個2分類以后,應(yīng)該也可以實現(xiàn)多模型蒸餾
centerPose,其實本來作者的centerpose就已經(jīng)做到一個網(wǎng)絡(luò)里面去了,但是筆者覺得可以把白嫖發(fā)揮到極致,把只在pose數(shù)據(jù)集上訓過的simplebaseline網(wǎng)絡(luò)蒸餾到centernet里面去,這樣的好處是:1.檢測的標注和pose的標注可以分開,作為兩個單獨的數(shù)據(jù)集去標注,這樣的話可以白嫖的數(shù)據(jù)集就更多了。2:并且做到一個網(wǎng)絡(luò)里面速度會更快。
centerPoint,直接輸出矩形框四個角點相對于中心點的偏移量,而不是矩形框的寬高,這樣的話相當于檢測的輸出是個任意四邊形,好處為:1.我們在訓練的時候可以加入任何旋轉(zhuǎn)的數(shù)據(jù)增強而不用擔心gt標注框變大的問題,同時說不定我們用已有的檢測數(shù)據(jù)集+旋轉(zhuǎn)數(shù)據(jù)增強訓練出來的網(wǎng)絡(luò)就具備了預測旋轉(zhuǎn)物體的能力。2.這個網(wǎng)絡(luò)在檢測車牌,或者身份證以及發(fā)票等具有天然的優(yōu)勢,直接預測四個角點,不用做任何的仿射變換,也不用換成笨重的分割網(wǎng)絡(luò)了。
結(jié)語
其實有太多的東西想加到centerX里面去了,里面有很多很好玩的以及非常具有實用價值的東西都可以去做,但是個人精力有限,而且剛開始做centerX完全是基于興趣愛好去做的,本人也只是渣碩,無法full time撲到這個東西上面去,所以上述的優(yōu)化方向看看在我有生之年能不能做出來,做不出來給大家提供一個可行性思路也是極好的。

非常感謝廖星宇,何凌霄對centerX代碼,以及發(fā)展方向上的貢獻,感謝郭聰,于萬金,蔣煜襄,張建浩等同學對centerX加速模塊的采坑指導。
再放一遍自己的github:https://github.com/CPFLAME/centerX
以及感謝如下杰出的工作
https://github.com/xingyizhou/CenterNet
https://github.com/facebookresearch/detectron2
https://github.com/FateScript/CenterNet-better
https://github.com/lbin/CenterNet-better-plus
https://github.com/JDAI-CV/fast-reid
https://github.com/daquexian/onnx-simplifier
https://github.com/CaoWGG/TensorRT-CenterNet
推薦閱讀
mmdetection最小復刻版(十一):概率Anchor分配機制PAA深入分析
MMDetection新版本V2.7發(fā)布,支持DETR,還有YOLOV4在路上!
無需tricks,知識蒸餾提升ResNet50在ImageNet上準確度至80%+
不妨試試MoCo,來替換ImageNet上pretrain模型!
mmdetection最小復刻版(七):anchor-base和anchor-free差異分析
mmdetection最小復刻版(四):獨家yolo轉(zhuǎn)化內(nèi)幕
機器學習算法工程師
? ??? ? ? ? ? ? ? ? ? ? ? ??????? ??一個用心的公眾號
?
