
Pandas數(shù)據(jù)探索分析,分享兩個神器!
在使用 pandas 進行數(shù)據(jù)分析時,進行一定的數(shù)據(jù)探索性分析(EDA)是必不可少的一個步驟,例如常見統(tǒng)計指標計算、缺失值、重復(fù)值統(tǒng)計等。
使用 df.describe() 等函數(shù)進行探索當然是常見操作,但若要進行更完整、詳細的分析缺則略顯不足。
本文就將分享兩個用于數(shù)據(jù)探索的 pandas 插件。
pandas_profiling
首先要介紹的是pandas_profiling,它擴展了pandas DataFrame的功能,這也是在之前多篇文章中提到的插件。
只需使用pip install pandas_profiling即可安裝,在導(dǎo)入數(shù)據(jù)之后使用df.profile_report()一行命令即可快速生成描述性分析報告??
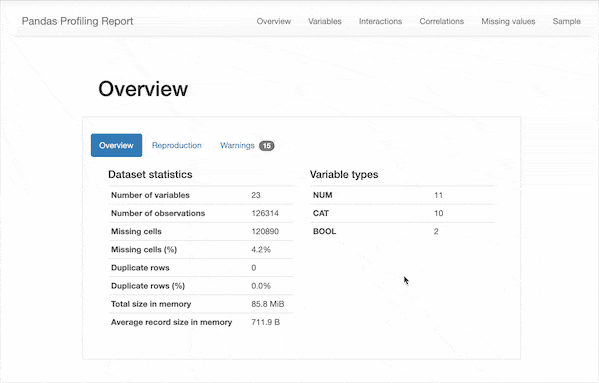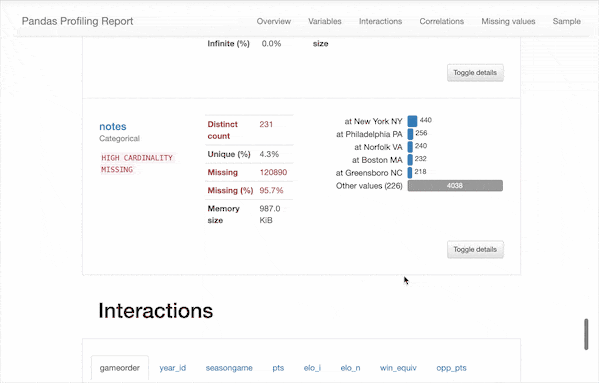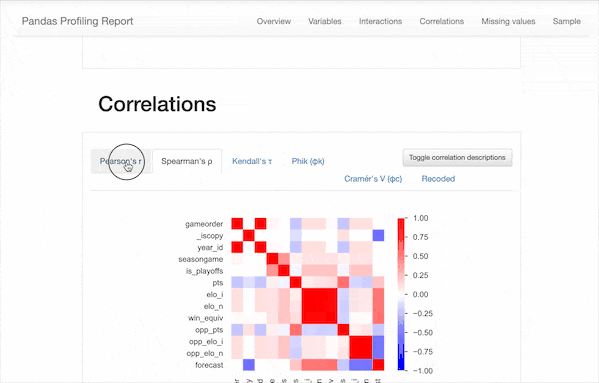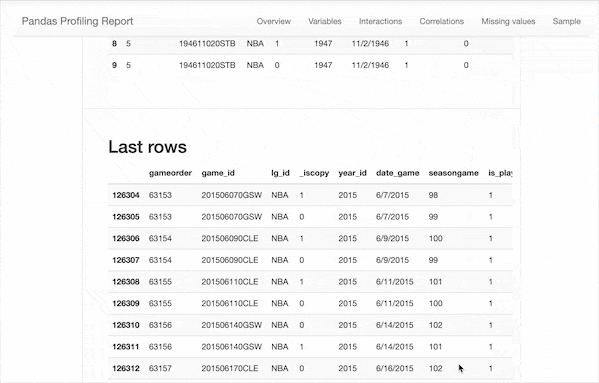
可以看到,除了之前我們需要的一些描述性統(tǒng)計數(shù)據(jù),該報告還包含以下信息:
“”
類型推斷:檢測數(shù)據(jù)幀中列的數(shù)據(jù)類型。 要點:類型,唯一值,缺失值 分位數(shù)統(tǒng)計信息,例如最小值,Q1,中位數(shù),Q3,最大值,范圍,四分位數(shù)范圍 描述性統(tǒng)計數(shù)據(jù),例如均值,眾數(shù),標準偏差,總和,中位數(shù)絕對偏差,變異系數(shù),峰度,偏度 最常使用的值 直方圖 相關(guān)性矩陣 缺失值矩陣,計數(shù),熱圖和缺失值樹狀圖 文本分析:了解文本數(shù)據(jù)的類別(大寫,空格),腳本(拉丁,西里爾字母)和塊(ASCII)
進一步我們還以將該報告保存為html格式,方便后續(xù)的查看,感興趣的讀者可以自行嘗試。
sweetviz
第二個值得一用的是 sweetviz,同樣是一個開源 Python 庫,可生成美觀、高密度的可視化,只需兩行代碼即可啟動 EDA。
該插件圍繞快速可視化目標值和比較數(shù)據(jù)集而構(gòu)建。它的目標是幫助快速分析目標特征、訓(xùn)練與測試數(shù)據(jù)以及其他此類數(shù)據(jù)特征任務(wù)。
安裝方法同上,執(zhí)行pip install sweetviz即可。使用方法也是類似,導(dǎo)入數(shù)據(jù)后只需兩行代碼即可輸出分析報告
import?sweetviz?as?sv
report?=?sv.analyze(df)
report.show_html()
和 pandas_profiling 不一樣的是,現(xiàn)在我們只能得到一個html文件,打開即可看到相關(guān) EDA 報告??
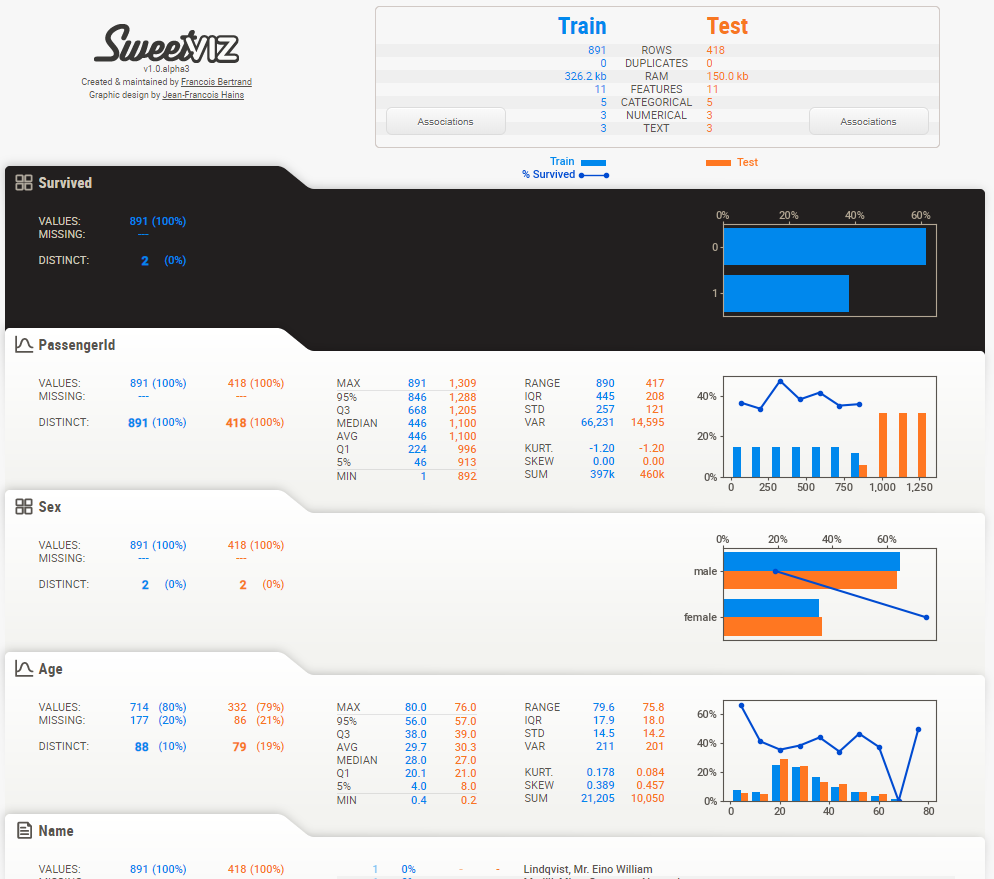
可以看到,自動生成的報告主要有以下幾個部分
“”
目標分析
顯示目標值,例如泰坦尼克號數(shù)據(jù)集中的“幸存”,與其他特征的關(guān)系) 可視化和比較
不同的數(shù)據(jù)集(例如訓(xùn)練與測試數(shù)據(jù)) 組內(nèi)特征(例如男性與女性) 混合型聯(lián)想
Sweetviz 無縫集成了數(shù)值(Pearson 相關(guān))、分類(不確定系數(shù))和分類-數(shù)值(相關(guān)比)數(shù)據(jù)類型的關(guān)聯(lián),為所有數(shù)據(jù)類型提供最大的信息。 類型推斷
自動檢測數(shù)字、分類和文本特征,可選擇手動覆蓋 概要信息
類型、唯一值、缺失值、重復(fù)行、最常見值 數(shù)值分析:最小值/最大值/范圍、四分位數(shù)、平均值、眾數(shù)、標準偏差、總和、中值絕對偏差、變異系數(shù)、峰態(tài)、偏度
從上面的介紹我們也能看出,兩個 EDA 的插件側(cè)重點有所不同,我們在實際使用時也應(yīng)該根據(jù)數(shù)據(jù)特征與分析目標靈活使用!
推薦閱讀
牛逼!Python常用數(shù)據(jù)類型的基本操作(長文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達式(長文系列第②篇)
推薦閱讀
牛逼!Python常用數(shù)據(jù)類型的基本操作(長文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達式(長文系列第②篇)