
得物數(shù)據(jù)庫(kù)中間件平臺(tái)“彩虹橋”演進(jìn)之路
前言
隨著得物 App 用戶開(kāi)始快速增長(zhǎng),業(yè)務(wù)線日趨豐富,也對(duì)底層數(shù)據(jù)庫(kù)帶來(lái)了較大的壓力。各個(gè)業(yè)務(wù)線對(duì)于數(shù)據(jù)分片、讀寫(xiě)分離、影子庫(kù)路由等等的需求成為了剛需,所以需要一個(gè)統(tǒng)一的中間件來(lái)支撐這些需求,得物“彩虹橋”應(yīng)運(yùn)而生。
在北歐神話中,彩虹橋是連結(jié)阿斯加德(Asgard)【1】和 米德加爾特(中庭/Midgard)的巨大彩虹橋。我們可以把它當(dāng)作是“九界之間”的連接通道,也是進(jìn)入阿斯加德的唯一穩(wěn)定入口。而得物的彩虹橋是連接服務(wù)與數(shù)據(jù)庫(kù)之間的數(shù)據(jù)庫(kù)中間層處理中間件,可以說(shuō)得物的每一筆訂單都與它息息相關(guān)。
1. 技術(shù)選型
前期我們調(diào)研了Mycat、ShardingSphere、kingshard、Atlas等開(kāi)源中間件,綜合了適用性、優(yōu)缺點(diǎn)、產(chǎn)品口碑、社區(qū)活躍度、實(shí)戰(zhàn)案例、擴(kuò)展性等多個(gè)方面,最終我們選擇了ShardingSphere。準(zhǔn)備在ShardingSphere的基礎(chǔ)上進(jìn)行二次開(kāi)發(fā)、定制一套適合得物內(nèi)部環(huán)境的數(shù)據(jù)庫(kù)中間件。
Apache ShardingSphere 是一款開(kāi)源分布式數(shù)據(jù)庫(kù)生態(tài)項(xiàng)目,由 JDBC、Proxy 和 Sidecar(規(guī)劃中) 3 款產(chǎn)品組成。其核心采用可插拔架構(gòu),通過(guò)組件擴(kuò)展功能。對(duì)上以數(shù)據(jù)庫(kù)協(xié)議及 SQL 方式提供諸多增強(qiáng)功能,包括數(shù)據(jù)分片、訪問(wèn)路由、數(shù)據(jù)安全等;對(duì)下原生支持 MySQL、PostgreSQL、SQL Server、Oracle 等多種數(shù)據(jù)存儲(chǔ)引擎。ShardingSphere 已于2020年4月16日成為 Apache 軟件基金會(huì)的頂級(jí)項(xiàng)目,并且在全球多個(gè)國(guó)家都有團(tuán)隊(duì)在使用。
目前我們主要是ShardingSphere的Proxy模式提供服務(wù),后續(xù)將會(huì)在JDBC&Proxy混合架構(gòu)繼續(xù)探索。
2.彩虹橋目前的能力
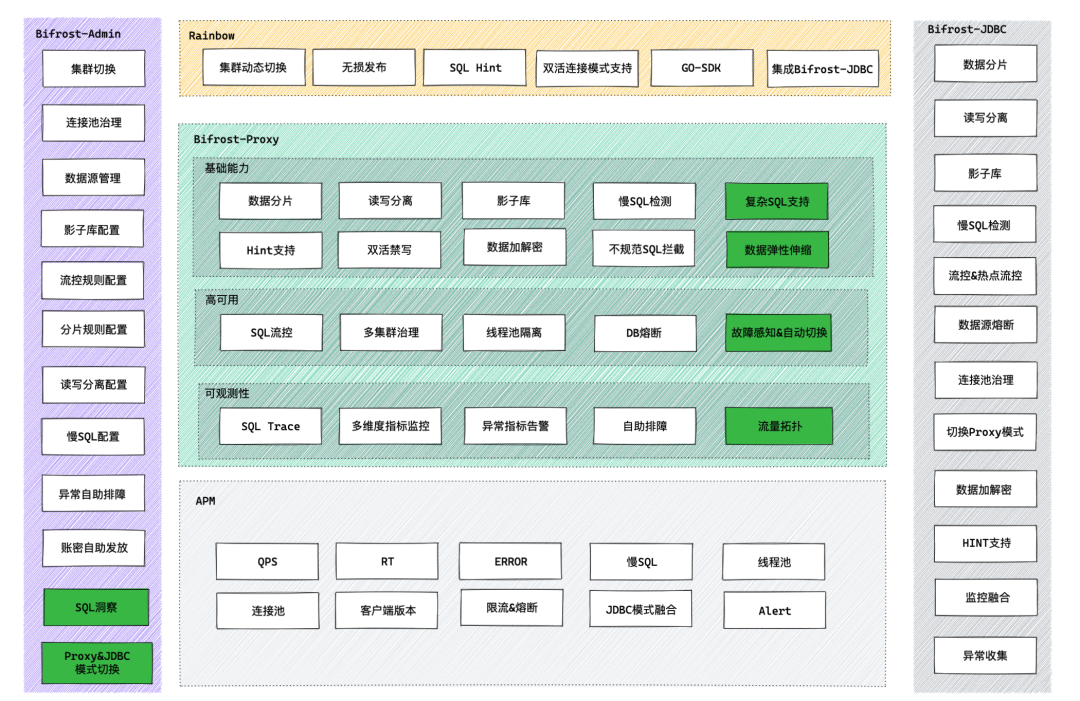
其中白色模塊為現(xiàn)階段以及具備的能力,綠色模塊為規(guī)劃&正在做的功能。下面介紹一下幾個(gè)重點(diǎn)功能。注意,以下功能都是基于Proxy模式。
2.1 數(shù)據(jù)分片
數(shù)據(jù)分片指按照某個(gè)維度將存放在單一數(shù)據(jù)庫(kù)中的數(shù)據(jù)分散地存放至多個(gè)數(shù)據(jù)庫(kù)或表中以達(dá)到提升性能瓶頸以及可用性的效果。數(shù)據(jù)分片的有效手段是對(duì)關(guān)系型數(shù)據(jù)庫(kù)進(jìn)行分庫(kù)和分表。分庫(kù)和分表均可以有效地避免由數(shù)據(jù)量超過(guò)可承受閾值而產(chǎn)生的查詢瓶頸。除此之外,分庫(kù)還能夠用于有效地分散對(duì)數(shù)據(jù)庫(kù)單點(diǎn)的訪問(wèn)量;分表雖然無(wú)法緩解數(shù)據(jù)庫(kù)壓力,但卻能夠提供盡量將分布式事務(wù)轉(zhuǎn)化為本地事務(wù)的可能,一旦涉及到跨庫(kù)的更新操作,分布式事務(wù)往往會(huì)使問(wèn)題變得復(fù)雜。使用多主多從的分片方式,可以有效地避免數(shù)據(jù)單點(diǎn),從而提升數(shù)據(jù)架構(gòu)的可用性。
通過(guò)分庫(kù)和分表進(jìn)行數(shù)據(jù)的拆分來(lái)使得各個(gè)表的數(shù)據(jù)量保持在閾值以下,以及對(duì)流量進(jìn)行疏導(dǎo)應(yīng)對(duì)高訪問(wèn)量,是應(yīng)對(duì)高并發(fā)和海量數(shù)據(jù)系統(tǒng)的有效手段。數(shù)據(jù)分片的拆分方式又分為垂直分片和水平分片。
按照業(yè)務(wù)拆分的方式稱(chēng)為垂直分片,又稱(chēng)為縱向拆分,它的核心理念是專(zhuān)庫(kù)專(zhuān)用。彩虹橋主要提供的分片能力是水平分片,水平分片又稱(chēng)為橫向拆分。相對(duì)于垂直分片,它不再將數(shù)據(jù)根據(jù)業(yè)務(wù)邏輯分類(lèi),而是通過(guò)某個(gè)字段(或某幾個(gè)字段),根據(jù)某種規(guī)則將數(shù)據(jù)分散至多個(gè)庫(kù)或表中,每個(gè)分片僅包含數(shù)據(jù)的一部分。例如:根據(jù)主鍵分片,偶數(shù)主鍵的記錄放入 0 庫(kù)(或表),奇數(shù)主鍵的記錄放入 1 庫(kù)(或表),如下圖所示。
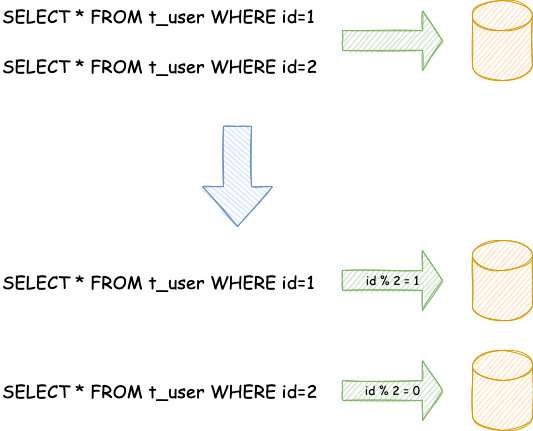
水平分片從理論上突破了單機(jī)數(shù)據(jù)量處理的瓶頸,并且擴(kuò)展相對(duì)自由,是數(shù)據(jù)分片的標(biāo)準(zhǔn)解決方案。
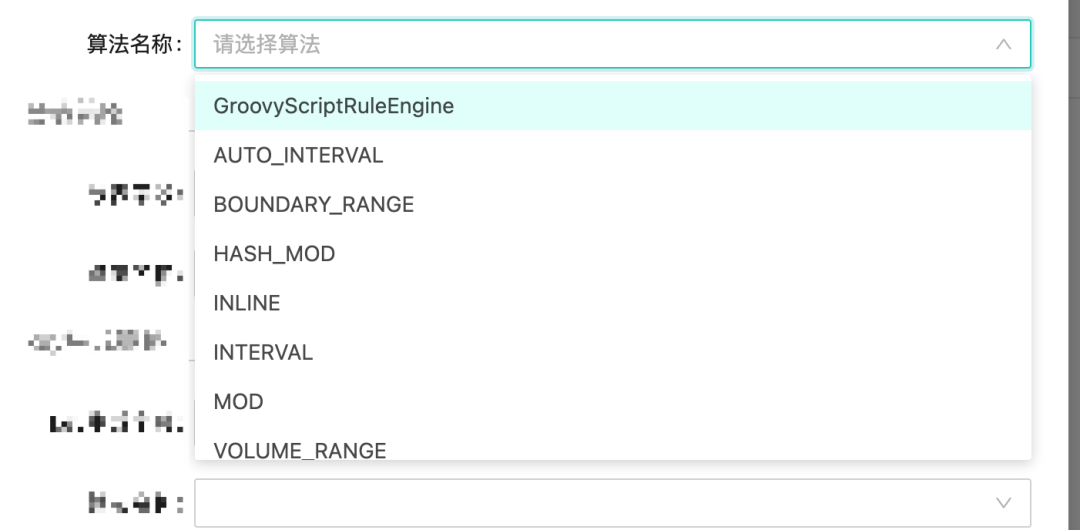
當(dāng)然實(shí)際使用場(chǎng)景的分片規(guī)則是非常復(fù)雜的,我們提供一些內(nèi)置算法比如取模、HASH取模、自動(dòng)時(shí)間段分片算法、Inline表達(dá)式等。當(dāng)內(nèi)置算法無(wú)法滿足要求時(shí),還可以基于groovy來(lái)定制專(zhuān)屬的分片邏輯。
2.2 讀寫(xiě)分離
面對(duì)日益增加的系統(tǒng)訪問(wèn)量,數(shù)據(jù)庫(kù)的吞吐量面臨著巨大瓶頸。對(duì)于同一時(shí)刻有大量并發(fā)讀操作和較少寫(xiě)操作類(lèi)型的應(yīng)用系統(tǒng)來(lái)說(shuō),將數(shù)據(jù)庫(kù)拆分為主庫(kù)和從庫(kù),主庫(kù)負(fù)責(zé)處理事務(wù)性的增刪改操作,從庫(kù)負(fù)責(zé)處理查詢操作,能夠有效的避免由數(shù)據(jù)更新導(dǎo)致的行鎖,使得整個(gè)系統(tǒng)的查詢性能得到極大的改善。通過(guò)一主多從的配置方式,可以將查詢請(qǐng)求均勻地分散到多個(gè)數(shù)據(jù)副本,能夠進(jìn)一步地提升系統(tǒng)的處理能力。
與將數(shù)據(jù)根據(jù)分片鍵打散至各個(gè)數(shù)據(jù)節(jié)點(diǎn)的水平分片不同,讀寫(xiě)分離則是根據(jù) SQL 語(yǔ)義的分析,將讀操作和寫(xiě)操作分別路由至主庫(kù)與從庫(kù)。
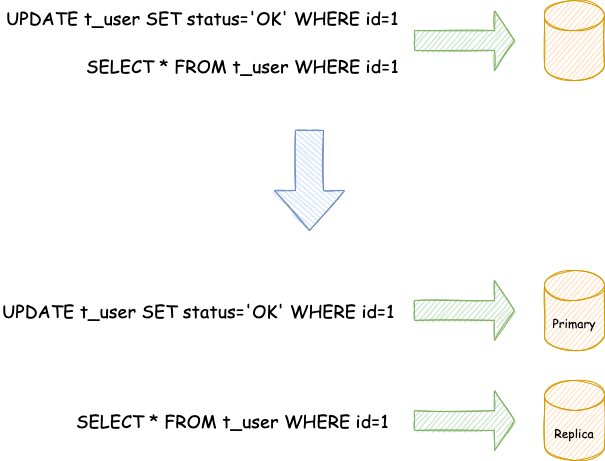
這里配置的方式比較簡(jiǎn)單,給目標(biāo)主庫(kù)綁定一個(gè)或多個(gè)從庫(kù)、設(shè)置對(duì)應(yīng)的負(fù)載均衡算法即可。

這里的實(shí)現(xiàn)方式就是通過(guò)SQL解析,把查詢語(yǔ)句路由到對(duì)應(yīng)的從庫(kù)即可,但是在一些對(duì)主從同步延遲比較敏感的場(chǎng)景,可能需要強(qiáng)制走主庫(kù),這里我們也提供一個(gè)API(原理就是SQL Hint),讓上游可以指定某些模塊讀強(qiáng)制走主,還有相關(guān)全局配置可以讓事務(wù)內(nèi)所有讀請(qǐng)求全部走主。
2.3 影子庫(kù)壓測(cè)
在基于微服務(wù)的分布式應(yīng)用架構(gòu)下,業(yè)務(wù)需要多個(gè)服務(wù)是通過(guò)一系列的服務(wù)、中間件的調(diào)用來(lái)完成,所以單個(gè)服務(wù)的壓力測(cè)試已無(wú)法代表真實(shí)場(chǎng)景。在測(cè)試環(huán)境中,如果重新搭建一整套與生產(chǎn)環(huán)境類(lèi)似的壓測(cè)環(huán)境,成本過(guò)高,并且往往無(wú)法模擬線上環(huán)境的復(fù)雜度以及流量。因此,業(yè)內(nèi)通常選擇全鏈路壓測(cè)的方式,即在生產(chǎn)環(huán)境進(jìn)行壓測(cè),這樣所獲得的測(cè)試結(jié)果能夠準(zhǔn)確地反應(yīng)系統(tǒng)真實(shí)容量和性能水平。
全鏈路壓測(cè)是一項(xiàng)復(fù)雜而龐大的工作。需要各個(gè)微服務(wù)、中間件之間配合與調(diào)整,以應(yīng)對(duì)不同流量以及壓測(cè)標(biāo)識(shí)的透?jìng)鳌Mǔ?huì)搭建一整套壓測(cè)平臺(tái)以適用不同測(cè)試計(jì)劃。在數(shù)據(jù)庫(kù)層面需要做好數(shù)據(jù)隔離,為了保證生產(chǎn)數(shù)據(jù)的可靠性與完整性,需要將壓測(cè)產(chǎn)生的數(shù)據(jù)路由到壓測(cè)環(huán)境數(shù)據(jù)庫(kù),防止壓測(cè)數(shù)據(jù)對(duì)生產(chǎn)數(shù)據(jù)庫(kù)中真實(shí)數(shù)據(jù)造成污染。這就要求業(yè)務(wù)應(yīng)用在執(zhí)行 SQL 前,能夠根據(jù)透?jìng)鞯膲簻y(cè)標(biāo)識(shí),做好數(shù)據(jù)分類(lèi),將相應(yīng)的 SQL 路由到與之對(duì)應(yīng)的數(shù)據(jù)源。
這里配置的方式類(lèi)似讀寫(xiě)分離,也是給目標(biāo)主庫(kù)綁定一個(gè)影子庫(kù),當(dāng)SQL攜帶了影子標(biāo)就會(huì)被路由到影子庫(kù)。

2.4 限流&熔斷
當(dāng)DB的壓力超過(guò)自身水位線時(shí),會(huì)導(dǎo)致DB發(fā)生故障。當(dāng)我們預(yù)估出某個(gè)維度的水位線后,可以配置對(duì)于的限流規(guī)則,拒絕掉超過(guò)本身水位線以外的請(qǐng)求來(lái)保護(hù)DB。讓系統(tǒng)盡可能跑在最大吞吐量的同時(shí)保證系統(tǒng)整體的穩(wěn)定性。維度方面我們支持DB、Table、SQL以及DML類(lèi)型。
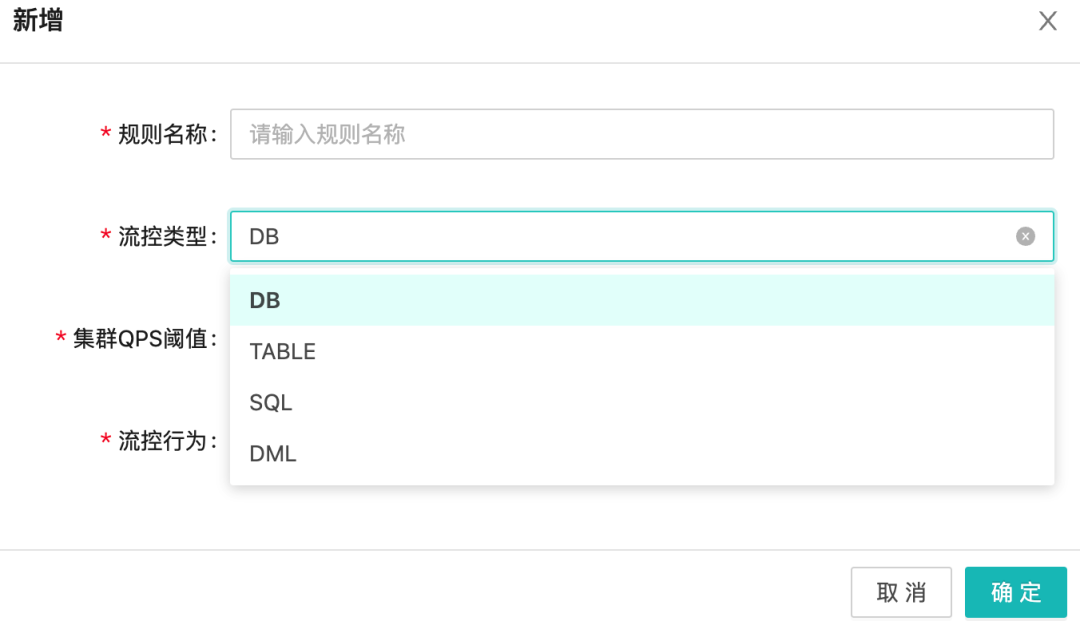
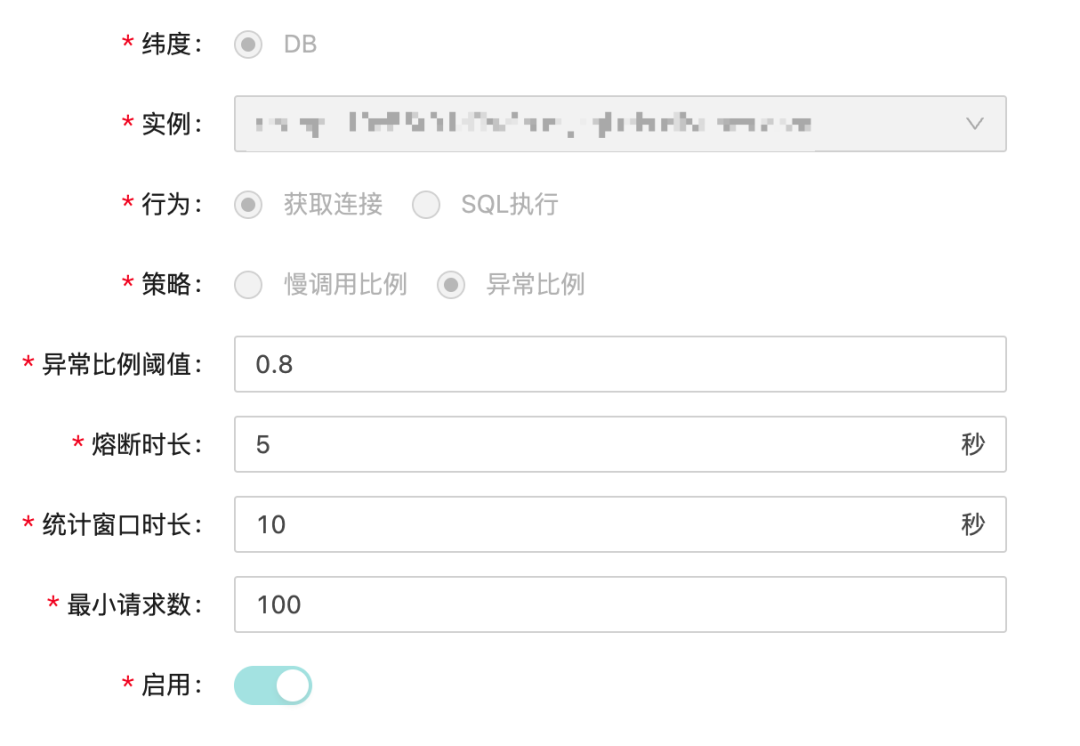
彩虹橋下面連接了上百個(gè)RDS實(shí)例,每個(gè)RDS實(shí)例都有可能出現(xiàn)各種故障,當(dāng)單個(gè)實(shí)例出現(xiàn)故障會(huì)影響到整個(gè)邏輯庫(kù),會(huì)迅速造成阻塞誘發(fā)雪崩效應(yīng)。所以我們需要一種快速失敗的機(jī)制來(lái)防止雪崩,目前我們是支持DB實(shí)例級(jí)別的熔斷,基于獲取連接&SQL執(zhí)行2種行為,以及執(zhí)行時(shí)間跟失敗比例來(lái)實(shí)現(xiàn)熔斷,以達(dá)到在DB故障時(shí)快速失敗的效果。
2.5 流量糾偏
在雙活架構(gòu)下,彩虹橋作為數(shù)據(jù)庫(kù)的代理層,可以保證雙活架構(gòu)下流量切換過(guò)程的流量做兜底攔截,保證數(shù)據(jù)一致性。原理就是基于SQL Hint攜帶的userId與機(jī)房規(guī)則做匹配,攔截不屬于當(dāng)前機(jī)房的流量。
3. 基于ShardingSphere我們做了哪些改造
雖然ShardingSphere Proxy本身其實(shí)已經(jīng)足夠強(qiáng)大,但是針對(duì)得物內(nèi)部環(huán)境,還是存在一些缺陷和功能缺失,主要分為以下幾點(diǎn):
易用性
分片、讀寫(xiě)分離等規(guī)則配置文件過(guò)于復(fù)雜,對(duì)于業(yè)務(wù)開(kāi)發(fā)不夠友好
規(guī)則動(dòng)態(tài)變更完全依賴配置中心,缺失完善的變更流程
連接池治理能力不完善
Hint方式不夠友好,需要業(yè)務(wù)寫(xiě)RAL語(yǔ)句
自定義分片算法需要發(fā)布
SQL兼容性
穩(wěn)定性
多集群治理功能缺失
邏輯庫(kù)之間的隔離性缺失
限流熔斷組件缺失
數(shù)據(jù)源、規(guī)則動(dòng)態(tài)變更有損
雙活架構(gòu)下流量糾偏功能的缺失
發(fā)布有損
可觀測(cè)性
SQL Trace功能不完善
監(jiān)控指標(biāo)不夠全面
SQL洞察能力缺失
性能
由于多了一次網(wǎng)絡(luò)轉(zhuǎn)發(fā),單條SQL的RT比直連會(huì)上浮2~3ms
針對(duì)數(shù)據(jù)源、規(guī)則的配置、變更、審計(jì)等一系列操作,集成到管控臺(tái)進(jìn)行統(tǒng)一操作。通過(guò)圖形化的方式降低了分片、讀寫(xiě)分離等規(guī)則配置文件的復(fù)雜度,并且加上一系列校驗(yàn)來(lái)規(guī)避了一部分因?yàn)榕渲梦募e(cuò)誤導(dǎo)致的低級(jí)錯(cuò)誤。其次加上了審計(jì)功能,保障了配置動(dòng)態(tài)變更的安全性和可控性。
為了解決以上問(wèn)題,我們做了以下改造與優(yōu)化。
3.1 易用性提升
管控臺(tái)新增了連接池治理,基于RDS連接數(shù)、Proxy節(jié)點(diǎn)數(shù)、掛載數(shù)據(jù)源數(shù)量等因素自動(dòng)計(jì)算出一個(gè)安全合理的連接池大小。
新增Client,針對(duì)Hint做一系列適配,比如影子標(biāo)傳遞、雙活架構(gòu)用戶id傳遞、trace傳遞、強(qiáng)制路由等等。使用方只需要調(diào)用Client中的API,即可在發(fā)出SQL階段自動(dòng)改寫(xiě)成Proxy可以識(shí)別的Hint增強(qiáng)語(yǔ)句。
管控臺(tái)新增了集群治理功能:由于我們部署了多套Proxy集群,為了最大程度的保障故障時(shí)的爆炸半徑,我們按照業(yè)務(wù)域?qū)roxy集群進(jìn)行了劃分,盡量保證統(tǒng)一業(yè)務(wù)域下面的邏輯庫(kù)流量進(jìn)入同一套集群。
新增了Groovy來(lái)支持自定義分片算法,在后臺(tái)配置好分片邏輯后審核通過(guò)即可生效,無(wú)需Proxy發(fā)版
3.2 穩(wěn)定性提升
3.2.1 Proxy多集群治理
(1)背景
隨著Proxy承載的業(yè)務(wù)域越來(lái)越多,如果所有的流量都通過(guò)負(fù)載均衡路由到Proxy節(jié)點(diǎn),當(dāng)一個(gè)庫(kù)出現(xiàn)問(wèn)題時(shí),可能會(huì)導(dǎo)致整個(gè)集群癱瘓,爆炸范圍不可控。而且由于DB的連接數(shù)資源有限,這就導(dǎo)致Proxy的節(jié)點(diǎn)無(wú)法大規(guī)模橫向擴(kuò)展。
(2)解決方案
為了不同業(yè)務(wù)域之間的隔離性,我們部署了多套Proxy集群,并且通過(guò)管控臺(tái)維護(hù)各個(gè)邏輯庫(kù)與集群之間的關(guān)系。保證同一業(yè)務(wù)域下面的邏輯庫(kù)流量進(jìn)入同一套集群。并且在某個(gè)集群發(fā)生故障時(shí),可把故障集群中的邏輯庫(kù)迅速、無(wú)損的動(dòng)態(tài)切換至備用集群,盡可能減少Proxy本身故障給業(yè)務(wù)帶來(lái)的損失。
而針對(duì)連接數(shù)治理方面,Proxy在初始化連接池的時(shí)候會(huì)判斷一下當(dāng)前邏輯庫(kù)是否在當(dāng)前集群,如果不在把最小連接數(shù)配置設(shè)置成最小,如果在則按照正常配置加載,并在集群切換前后做好目標(biāo)集群的預(yù)熱以及原集群的回收。這樣可以極大程度上緩解DB連接池資源對(duì)Proxy節(jié)點(diǎn)的橫向擴(kuò)展。
(3)實(shí)現(xiàn)原理
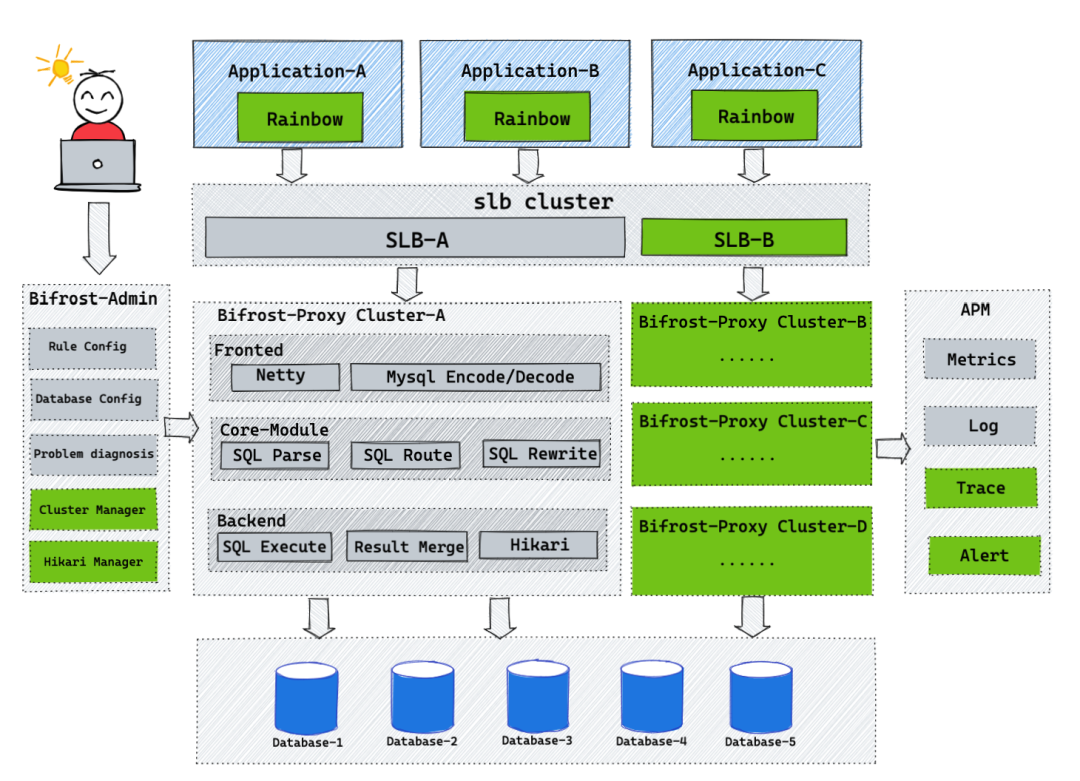
上游應(yīng)用引入Rainbow(自研連接池)后,在連接池初始化之前會(huì)根據(jù)邏輯庫(kù)讀取當(dāng)前庫(kù)所在集群,并動(dòng)態(tài)把Proxy的域名替換成其所在集群的域名。同時(shí)還會(huì)新增對(duì)集群配置的監(jiān)聽(tīng),這樣在管控臺(tái)切換集群操作后,Rainbow會(huì)根據(jù)切換后的集群域名創(chuàng)建一個(gè)新的連接池,然后替換掉老的連接池,老的連接池也會(huì)進(jìn)行延時(shí)優(yōu)雅關(guān)閉,整個(gè)過(guò)程對(duì)上游應(yīng)用無(wú)感知。
(4)架構(gòu)圖
3.2.2 Proxy工作線程池隔離
(1)背景
開(kāi)源版本的Proxy,所有邏輯庫(kù)共用一個(gè)線程池,當(dāng)單個(gè)邏輯庫(kù)發(fā)生阻塞的情況,會(huì)耗盡線程池資源,導(dǎo)致其他邏輯庫(kù)也跟著受影響。
(2)解決方案
我們這里采用了基于線程池的隔離方案,引入了獨(dú)占&共享線程池的概念,優(yōu)先使用邏輯庫(kù)獨(dú)占線程池,當(dāng)獨(dú)占線程池出現(xiàn)排隊(duì)情況再使用共享線程池,共享線程池達(dá)到一定負(fù)載后會(huì)在一個(gè)時(shí)間窗口內(nèi)強(qiáng)制路由到獨(dú)占線程池,在保障隔離性的前提下,最大化利用線程資源。
3.2.3 流控與熔斷
(1)背景
開(kāi)源版本的Proxy缺少對(duì)庫(kù)、表、SQL等維度的流控,當(dāng)短時(shí)間內(nèi)爆發(fā)超過(guò)系統(tǒng)水位的流量時(shí),很可能就會(huì)擊垮DB導(dǎo)致線上故障,而且缺少針對(duì)DB快速失敗的機(jī)制,當(dāng)DB發(fā)生故障(比如CPU 100%)無(wú)法快速失敗的情況下,會(huì)迅速造成阻塞誘發(fā)雪崩效應(yīng)。
(2)解決方案
新增了各個(gè)維度(DB、table、SQL、語(yǔ)句類(lèi)型)的限流,各個(gè)庫(kù)可以根據(jù)預(yù)估的水位線以及業(yè)務(wù)需要配置一個(gè)合理的閾值,最大程度保護(hù)DB。同時(shí)我們也引入DB實(shí)例的熔斷策略,在某個(gè)實(shí)例出現(xiàn)故障時(shí)可快速失敗。在分庫(kù)場(chǎng)景下,可最大程度減少對(duì)其他分片的影響,進(jìn)一步縮小了故障的爆炸半徑,提升彩虹橋整體的穩(wěn)定性。
(3)實(shí)現(xiàn)原理
流控跟熔斷都是基于sentinel來(lái)實(shí)現(xiàn)的,在管控臺(tái)配置對(duì)應(yīng)的規(guī)則即可。
3.2.4 無(wú)損發(fā)布
(1)背景
在前期,Proxy每次發(fā)布或者重啟的時(shí)候,都會(huì)收到上游應(yīng)用SQL執(zhí)行失敗的一些報(bào)警,主要的原因是因?yàn)樯嫌闻cProxy之間是長(zhǎng)連接,這時(shí)如果有連接正在執(zhí)行SQL,那么就會(huì)被強(qiáng)制斷開(kāi)導(dǎo)致SQL執(zhí)行失敗,一定程度上對(duì)上游的業(yè)務(wù)造成損失。
(2)解決方案
發(fā)布系統(tǒng)配合自研連接池Rainbow,在Proxy節(jié)點(diǎn)發(fā)布或重啟之前,會(huì)通知Rainbow連接池優(yōu)雅關(guān)閉應(yīng)用于需要重啟&發(fā)布的Proxy節(jié)點(diǎn)之間的連接,在Proxy流量跌0后再執(zhí)行重啟&發(fā)布。
3.3 可觀測(cè)性
3.3.1 運(yùn)行時(shí)指標(biāo)
(1)背景
開(kāi)源版本對(duì)于Proxy運(yùn)行時(shí)的監(jiān)控指標(biāo)很少,導(dǎo)致無(wú)法觀測(cè)到Proxy上面每個(gè)庫(kù)運(yùn)行的詳細(xì)狀態(tài)。
(2)解決方案
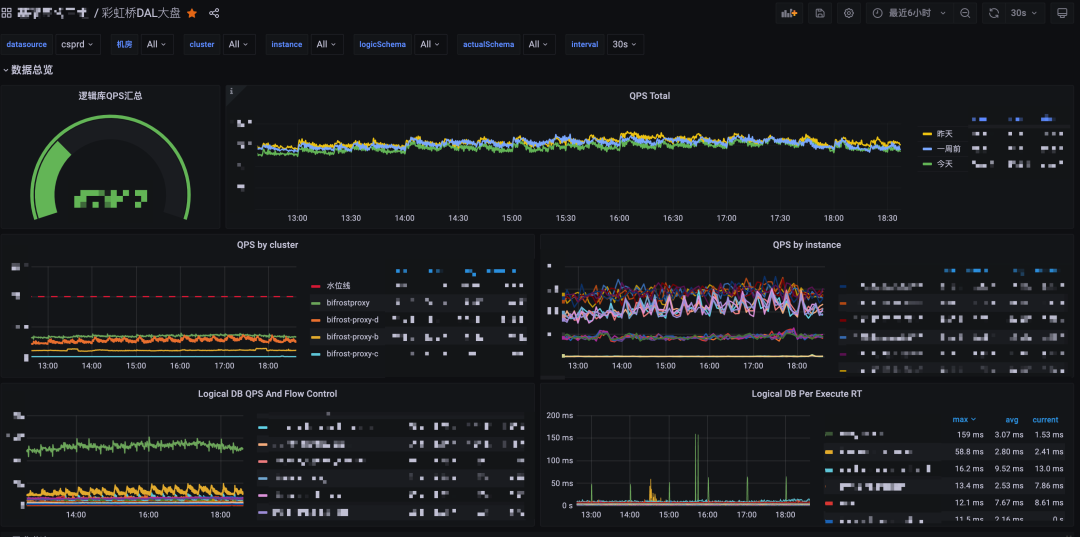
在Proxy各個(gè)執(zhí)行階段加了埋點(diǎn),新增了以下指標(biāo)、并繪制了對(duì)應(yīng)的監(jiān)控大盤(pán)。
庫(kù)&表級(jí)別的QPS、RT、error、慢SQL指標(biāo)
Proxy-DB連接池的各項(xiàng)連接數(shù)指標(biāo)
流控熔斷指標(biāo)
線程池活躍線程數(shù)、隊(duì)列大小指標(biāo)
(3)效果圖
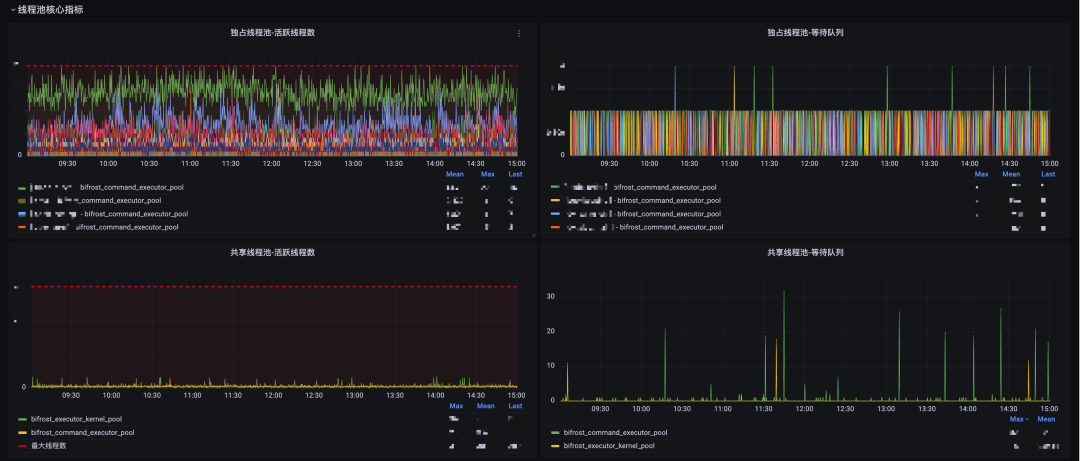
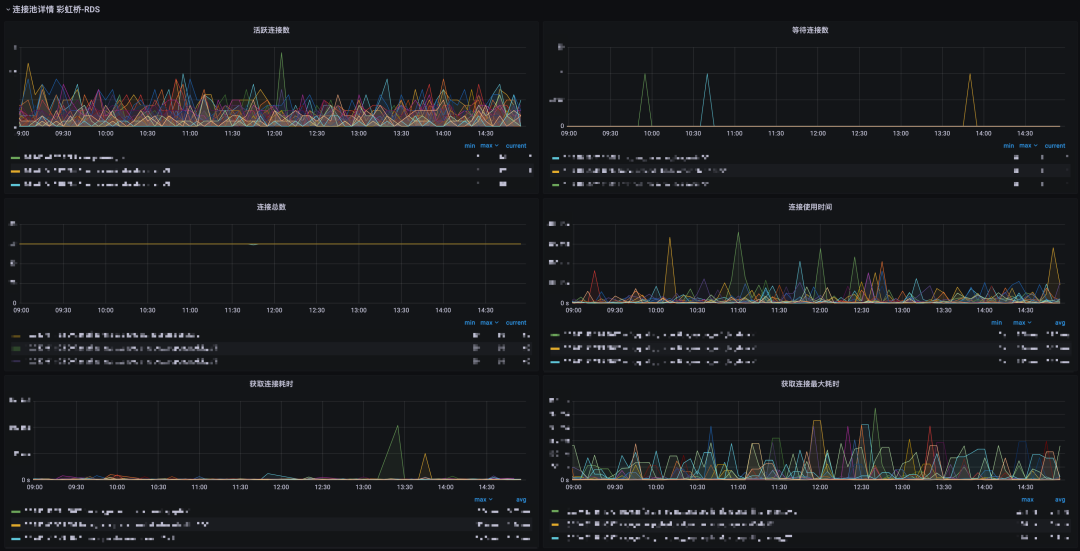
3.3.2 全鏈路追蹤
(1)背景
開(kāi)源版本的trace只支持Proxy內(nèi)部執(zhí)行階段的鏈路追蹤,無(wú)法和上游串聯(lián),導(dǎo)致排障效率低下。
(2)解決方案
主要通過(guò)RAL、SQL注釋2種方式傳遞trace信息,實(shí)現(xiàn)了上游到Proxy的全鏈路追蹤。
(3)實(shí)現(xiàn)原理
我們首先想到的方案就是通過(guò)SQL注釋方式傳遞trace信息,但是在真正投產(chǎn)之后卻發(fā)現(xiàn)了一些問(wèn)題,在上游使用了prepare模式(useServerPrepStmts=true&cachePrepStmts=true)時(shí),Proxy會(huì)緩存statmentId和SQL,而trace每次都不一樣,這樣會(huì)導(dǎo)致存儲(chǔ)緩存無(wú)限增長(zhǎng)最終導(dǎo)致OOM。
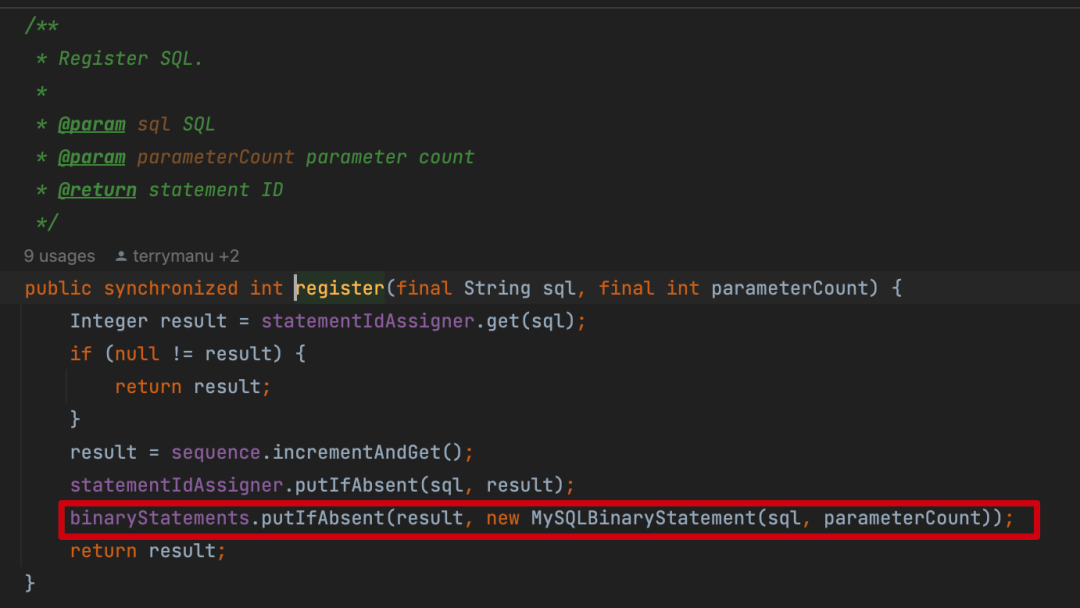
所以通過(guò)SQL注釋方式傳遞trace信息只適用于非prepare場(chǎng)景。于是我們又新增了一種方案就是在每次SQL執(zhí)行之前發(fā)送一條RAL語(yǔ)句來(lái)傳遞trace信息,并在Proxy中緩存channelId與trace信息的對(duì)應(yīng)關(guān)系,由于單個(gè)channel所有的SQL都是串行執(zhí)行,加上channelId數(shù)量可控,不會(huì)無(wú)限膨脹。但是這種方案相對(duì)于每次SQL執(zhí)行之前都有一次RAL語(yǔ)句的執(zhí)行,對(duì)性能的影響還是比較大的。從監(jiān)控上看下來(lái)每次SQL執(zhí)行的RT會(huì)上浮2-3ms(網(wǎng)絡(luò)傳輸),對(duì)于一些鏈路較長(zhǎng)的接口來(lái)說(shuō)還是挺致命的。
(4)總結(jié)
綜合下來(lái)2種方案其實(shí)都有比較明顯的缺點(diǎn),針對(duì)這個(gè)問(wèn)題之前ShardingSphere的小伙伴來(lái)過(guò)我們得物進(jìn)行過(guò)一次深度溝通,亮哥給出了一個(gè)比較可行的方案,就是通過(guò)虛擬列傳輸trace信息,但是需要上游對(duì)SQL進(jìn)行改寫(xiě),這可能會(huì)增加上游應(yīng)用的負(fù)擔(dān),目前這塊我們還沒(méi)有開(kāi)始做。
3.3.3 SQL洞察
(1)背景
目前Proxy雖然有打印邏輯SQL和物理SQL的日志,但是由于生產(chǎn)請(qǐng)求量較大,開(kāi)啟日志會(huì)對(duì)IO有較大挑戰(zhàn)。所以目前我們生產(chǎn)環(huán)境還是關(guān)閉的狀態(tài)。而且這個(gè)日志也無(wú)法與上游串聯(lián),對(duì)于排障的幫助也是比較有限。
(2)解決方案
目前也只有個(gè)大概的思路,還沒(méi)有完善的方案,要達(dá)到的效果就是收集所有Proxy執(zhí)行的邏輯SQL、物理SQL以及上游信息,包括JDBCDatabaseCommunicationEngine以外的一些SQL(比如TCL等等),并通過(guò)管控臺(tái)實(shí)時(shí)查詢。最終的效果類(lèi)似阿里云RDS的收費(fèi)服務(wù)-SQL洞察
3.4 bug修復(fù)
由于歷史原因,我們是基于Apache ShardingSphere 5.0.0-alpha上做的二次開(kāi)發(fā),在實(shí)際使用的過(guò)程中遇到了很多bug,大部分都給官方提了issue,并且在彩虹橋版本上做了修復(fù),當(dāng)然ShardingSphere社區(qū)的小伙伴也給與了很多幫助和修復(fù)的思路。
3.5 JDBC&Proxy混合架構(gòu)
(1)背景
上面4項(xiàng)內(nèi)容大多數(shù)針對(duì)Proxy模塊或上游連接池模塊的改造,但是還是有一些問(wèn)題是Proxy模式暫時(shí)無(wú)法解決的,比如前面提到的SQL兼容性和性能問(wèn)題。還有就是如果整個(gè)Proxy集群全部宕機(jī)情況下我們沒(méi)有一個(gè)兜底機(jī)制。所以Proxy模式并不適用于所有場(chǎng)景。在Apache ShardingSphere的官方文檔可以看到這樣一段內(nèi)容:
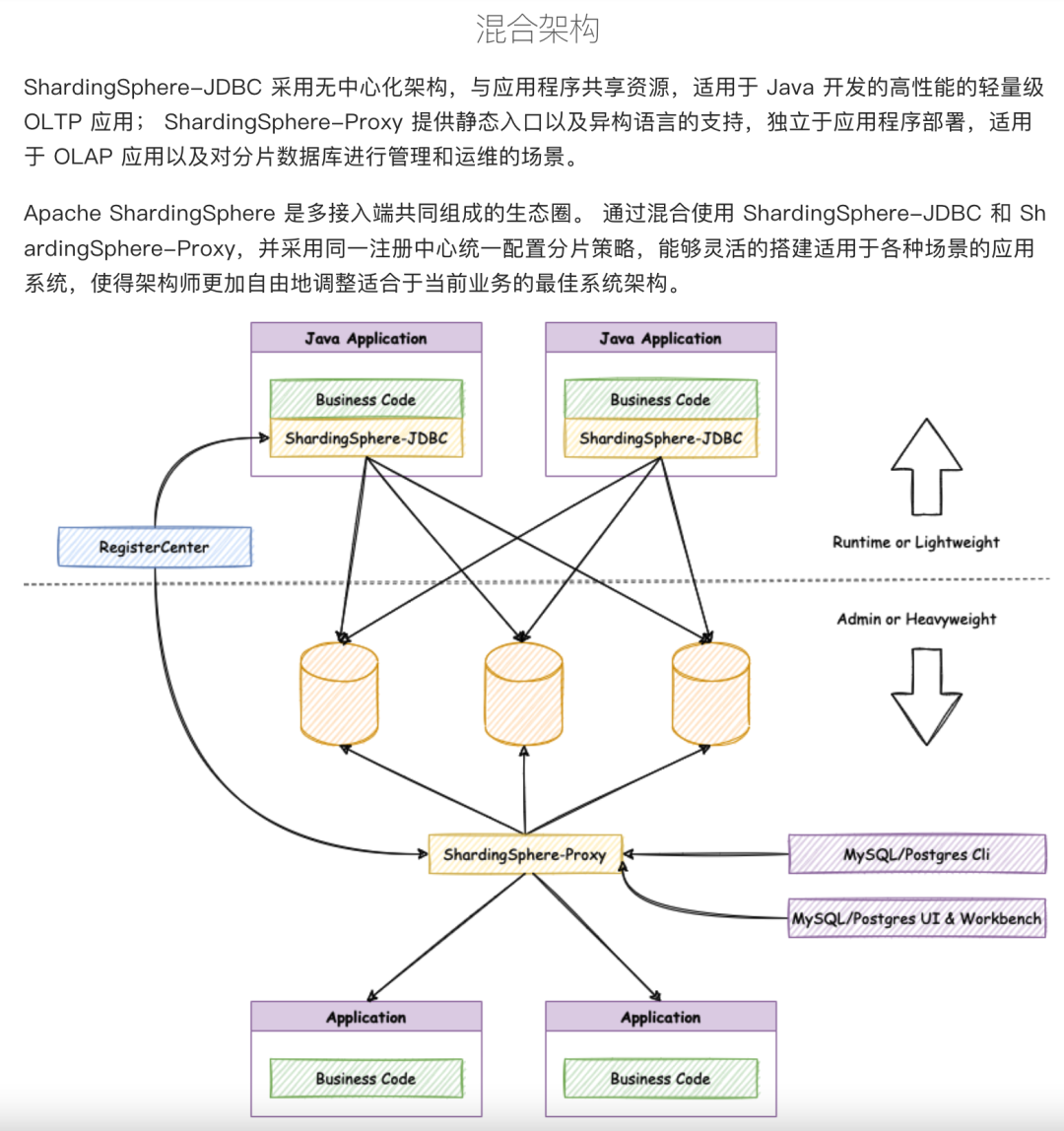
于是我們準(zhǔn)備在JDBC&Proxy混合架構(gòu)上做了進(jìn)一步探索。
(2)解決方案
在管控臺(tái)實(shí)現(xiàn)對(duì)邏輯庫(kù)的模式配置,并通過(guò)自研連接池Rainbow感知并根據(jù)不同模式啟動(dòng)不同類(lèi)型的數(shù)據(jù)源。并且可以在后臺(tái)切換模式后無(wú)損動(dòng)態(tài)調(diào)整,這樣對(duì)于使用者來(lái)說(shuō)是完全無(wú)感知的。對(duì)SQL性能、兼容性要求比較高的應(yīng)用可以調(diào)整為JDBC模式。同時(shí)當(dāng)Proxy所有集群癱瘓時(shí)也有個(gè)兜底的方案,不至于全站崩潰。
(3)實(shí)現(xiàn)原理
Rainbow連接池啟動(dòng)的時(shí)候會(huì)查詢當(dāng)前邏輯庫(kù)對(duì)應(yīng)的模式,如果是Proxy模式則直接連接Proxy來(lái)啟動(dòng)連接池,如果是JBDC則根據(jù)該邏輯庫(kù)的數(shù)據(jù)源配置以及分片&讀寫(xiě)分離&影子庫(kù)等等規(guī)則來(lái)加載JDBC模式的數(shù)據(jù)源,對(duì)應(yīng)的DataSource為GovernanceShardingSphereDataSource。并且會(huì)監(jiān)聽(tīng)這個(gè)模式配置,當(dāng)模式發(fā)生變化后會(huì)動(dòng)態(tài)無(wú)損替換當(dāng)前連接池。具體的無(wú)損替換方案與前面提到的集群切換類(lèi)似。同時(shí)需要解決的還有監(jiān)控問(wèn)題和連接池資源的管理,Proxy切換至JDBC模式后指標(biāo)的暴露由Proxy節(jié)點(diǎn)變成了上游節(jié)點(diǎn),對(duì)應(yīng)的大盤(pán)也需要做對(duì)應(yīng)的融合,連接池治理這塊也使用了新的計(jì)算模式做了對(duì)應(yīng)的適配。
4. 目前的困惑
由于歷史原因,我們是基于Apache ShardingSphere 5.0.0-alpha上做的二次開(kāi)發(fā),目前社區(qū)最新的版本是5.1.2-release,從5.0.0-alpha~5.1.2-release做了大量的優(yōu)化跟bug修復(fù),但是我們沒(méi)有很好的辦法將社區(qū)的代碼合并到我們的內(nèi)部代碼,因?yàn)闊o(wú)法確定社區(qū)開(kāi)源版本更改的內(nèi)容,會(huì)不會(huì)對(duì)現(xiàn)有業(yè)務(wù)產(chǎn)生影響,短時(shí)間內(nèi)也無(wú)法享受社區(qū)帶來(lái)的紅利。同時(shí)我們也在尋找一種方式將我們做的一些優(yōu)化后續(xù)合并到社區(qū)中,也算是一種反哺社區(qū)。為中國(guó)開(kāi)源做一份貢獻(xiàn)~
5. 寫(xiě)在最后
ShardingShpere的源碼非常優(yōu)秀,很多地方的設(shè)計(jì)非常的巧妙,模塊劃分的也很清晰。但總體的代碼非常龐大,剛開(kāi)始閱讀起來(lái)還是非常吃力的。雖然文章的大部分是在指出目前開(kāi)源版本的問(wèn)題,但再優(yōu)秀的產(chǎn)品也不可能適用所有場(chǎng)景。今年年初ShardingSphere團(tuán)隊(duì)的大牛們包括亮哥也來(lái)到了我們得物總部和我們做了一次線下交流,給我們分享了很多干貨,我們也提出了一些我們現(xiàn)在遇到的一些問(wèn)題,亮哥也給出了非常有用的思路和指導(dǎo)。非常期待后續(xù)可以再來(lái)一次線下交流。
*文/陳浩
------------- END ------------- 掃描下方二維碼,加入技術(shù)群。暗號(hào):加群