
mysql的這幾個(gè)坑你踩過(guò)沒(méi)?真是防不勝防
一、前言
對(duì)于從事互聯(lián)網(wǎng)開(kāi)發(fā)的同學(xué)來(lái)說(shuō),mysql可謂是再熟悉不過(guò)的了。無(wú)論是DBA、開(kāi)發(fā)或測(cè)試,基本上天天要跟它打交道,很多同學(xué)可能已經(jīng)身經(jīng)百戰(zhàn)了。但是,筆者遇到過(guò)的這些坑不知道你們都經(jīng)歷過(guò)沒(méi)?
?
二、有符號(hào)和無(wú)符號(hào)
以前我們公司在項(xiàng)目開(kāi)發(fā)之初制定開(kāi)發(fā)規(guī)范時(shí),對(duì)mysql的int類型字段定義成有符號(hào),還是無(wú)符號(hào)問(wèn)題專門討論過(guò)。
觀點(diǎn)一:
對(duì)于能夠確定里面存的值一定是正數(shù)的字段,定義成UNSIGNED無(wú)符號(hào)的,可以節(jié)省一半的存儲(chǔ)空間。創(chuàng)建無(wú)符號(hào)字段的語(yǔ)句如下:
create table test_unsigned(a int UNSIGNED, b int UNSIGNED);觀點(diǎn)二:
建議都定義成有符號(hào)的,使用起來(lái)比較簡(jiǎn)單,mysql默認(rèn)int類型就是有符號(hào)的,創(chuàng)建有符號(hào)字段的語(yǔ)句如下:
create table test_signed(a int);insert into test_signed values(-1);
執(zhí)行結(jié)果:

在字段a中插入-1,我們看到是可以操作成功的。
這兩個(gè)方案,經(jīng)過(guò)我們激烈討論之后,選擇了使用有符號(hào)定義int類型字段。為什么呢?
create table test_unsigned(a int UNSIGNED, b int UNSIGNED);insert into test_unsigned values(1,2);
先創(chuàng)建test_unsigned表,里面包含兩個(gè)無(wú)符號(hào)字段a和b,再插入一條數(shù)據(jù)a=1,b=2
select b - a from test_unsigned;沒(méi)有問(wèn)題,返回1
但是如果sql改成這樣:
select a - b from test_unsigned;執(zhí)行結(jié)果:

報(bào)錯(cuò)了。。。
所以,在使用無(wú)符號(hào)字段時(shí),千萬(wàn)要注意字段相減出現(xiàn)負(fù)數(shù)的坑,建議還是使用有符號(hào)字段,避免不必要的問(wèn)題。
三、自動(dòng)增長(zhǎng)
建過(guò)表的同學(xué)都知道,對(duì)于表的主鍵可以定義成自動(dòng)增長(zhǎng)的,這樣一來(lái),就可以交給數(shù)據(jù)庫(kù)自己生成主鍵值,而無(wú)需在代碼中指定,而且生成的值是遞增的。一般情況下,創(chuàng)建表的語(yǔ)句如下:
create table test_auto_increment (a int auto_increment primary key);但如果改成這樣的會(huì)怎樣?
create table test_auto_increment (a int auto_increment);執(zhí)行結(jié)果:

報(bào)錯(cuò)了。。。
截圖中沒(méi)有全部顯示出來(lái),完整的提示語(yǔ)是這樣的:
1075 - Incorrect table definition; there can be only one auto column and it must be defined as a key, Time: 0.006000意思是自動(dòng)增長(zhǎng)字段,必須被定義成key,所以我們需要加上primary key。
此外,還有一個(gè)有趣的實(shí)驗(yàn):
insert into test_auto_increment(a) values (null),(50),(null),(8),(null);大家猜猜執(zhí)行結(jié)果會(huì)是什么樣的?

第一個(gè)null插入1,然后按真實(shí)的數(shù)字大小排序后插入,后面兩個(gè)null,是在最大的數(shù)字上面加1。
再看看這條sql主鍵中插入負(fù)數(shù),能執(zhí)行成功嗎?
insert into test_auto_increment values(-3);答案是可以,主鍵可以插入負(fù)數(shù)。

還有這條sql呢,主鍵中插入0?
insert into test_auto_increment values(0);執(zhí)行結(jié)果:
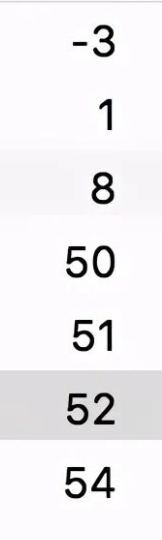
也可以執(zhí)行成功,但是沒(méi)有插入數(shù)據(jù)
?
四、字段長(zhǎng)度
我們?cè)趧?chuàng)建表的時(shí)候,給字段定義完類型之后,緊接著需要指定字段的長(zhǎng)度,比如:varchar(20),biginit(20)等。那么問(wèn)題來(lái)了,varchar代表的是字節(jié)長(zhǎng)度,還是字符長(zhǎng)度呢?
create table test_varchar(a varchar(20));insert into test_varchar values('蘇三說(shuō)技術(shù)');select length(a),CHARACTER_LENGTH(a) from test_varchar;
執(zhí)行后的結(jié)果:

我們看到中文的5個(gè)字length函數(shù)統(tǒng)計(jì)后長(zhǎng)度為15,代表占用了15個(gè)字節(jié),而使用charcter_length函數(shù)統(tǒng)計(jì)長(zhǎng)度是5,代表有5個(gè)字符。所以varchar代表的是字符長(zhǎng)度,因?yàn)橛行?fù)雜的字符或者中文,一個(gè)字節(jié)表示不了,utf8編碼格式的一個(gè)中文漢字占用3個(gè)字節(jié)。不同的數(shù)據(jù)庫(kù)編碼格式,占用不同的字節(jié)數(shù)對(duì)照表如下:
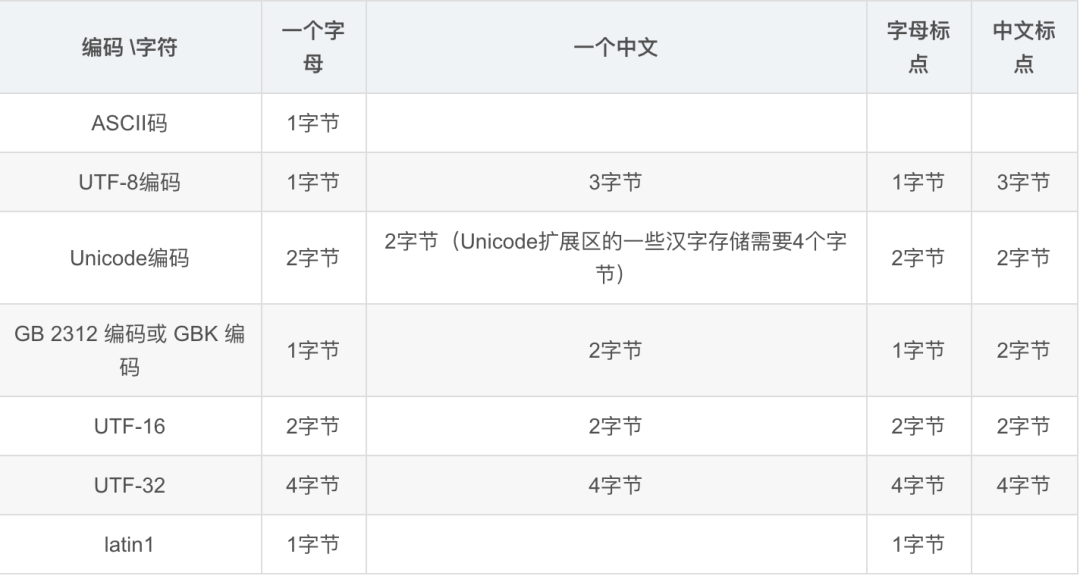
mysql除了varchar和char是代表字符長(zhǎng)度之外,其余的類型都是代表字節(jié)長(zhǎng)度。
int(n) 這個(gè)n表示什么意思呢?從一個(gè)列子出發(fā):
create table test_bigint (a bigint(4) ZEROFILL);insert into test_bigint values(1);insert into test_bigint values(123456);select * from test_bigint;
ZEROFILL表示長(zhǎng)度不夠填充0
執(zhí)行結(jié)果:

mysql常用數(shù)字類型字段占用字節(jié)數(shù)對(duì)照表:
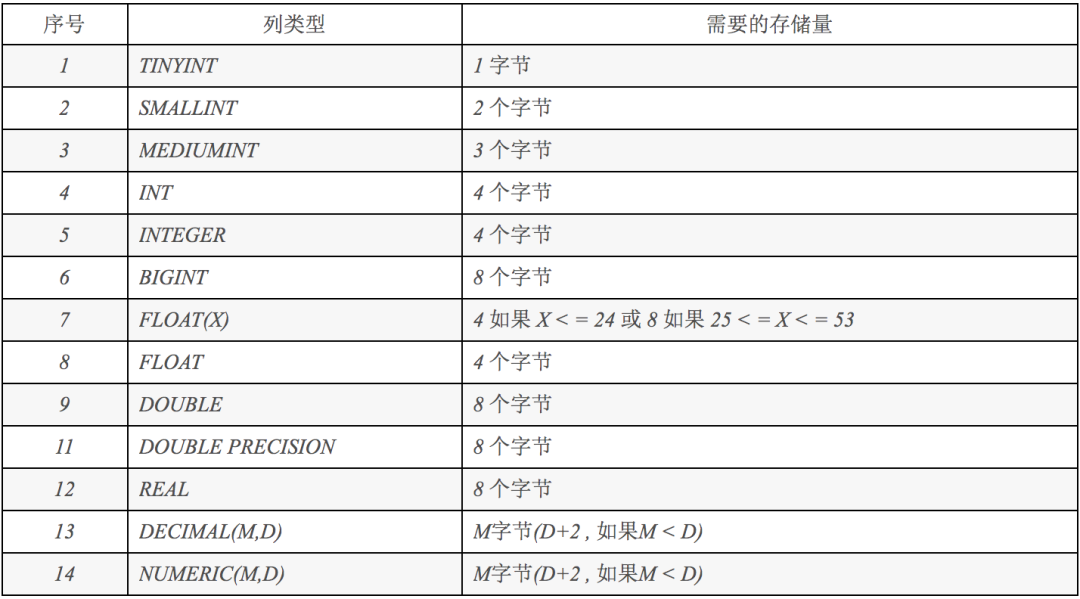
從表中可以看出bigint實(shí)際長(zhǎng)度是8個(gè)字節(jié),但是我們定義的a顯示4個(gè)字節(jié),所以在不滿4個(gè)字節(jié)時(shí)前面填充0。滿了4個(gè)字節(jié)時(shí),按照實(shí)際的長(zhǎng)度顯示,比如:123456。但是,需要注意的是,有些mysql客戶端即使?jié)M了4個(gè)字節(jié),也可能只顯示4個(gè)字節(jié)的內(nèi)容,比如顯示:1234。
所以bigint(4),這里的4表示顯示的長(zhǎng)度為4個(gè)字節(jié),實(shí)際長(zhǎng)度還是8個(gè)字節(jié)。
五、忽略大小寫(xiě)
我們知道在英文字母中有大小寫(xiě)問(wèn)題,比如:a 和 A 是一樣的嗎?我們認(rèn)為肯定是不一樣的,但是數(shù)據(jù)庫(kù)是如何處理的呢?
create table test_a(a varchar(20));insert into test_a values('a');insert into test_a values('A');select * from test_a where a = 'a';
執(zhí)行結(jié)果是什么呢?

本以為只會(huì)返回a,但是實(shí)際上把A也返回了,這是為什么呢?
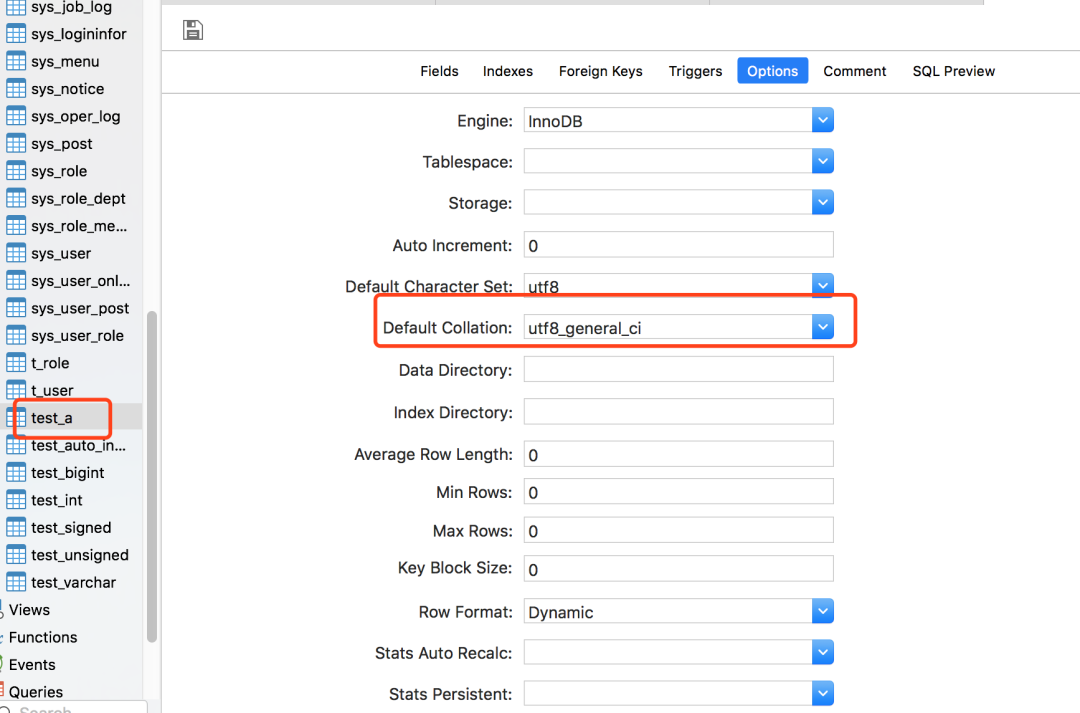
該表默認(rèn)的Collation是utf8_general_ci,這種Collation會(huì)忽略大小寫(xiě),所以才會(huì)出現(xiàn)查詢小寫(xiě)字母a的值,意外把大寫(xiě)字母A的值也查詢出來(lái)了。
那么如果我們只想查詢出小寫(xiě)a的值該怎么辦?先看看mysql支持哪些Collation?
show collation;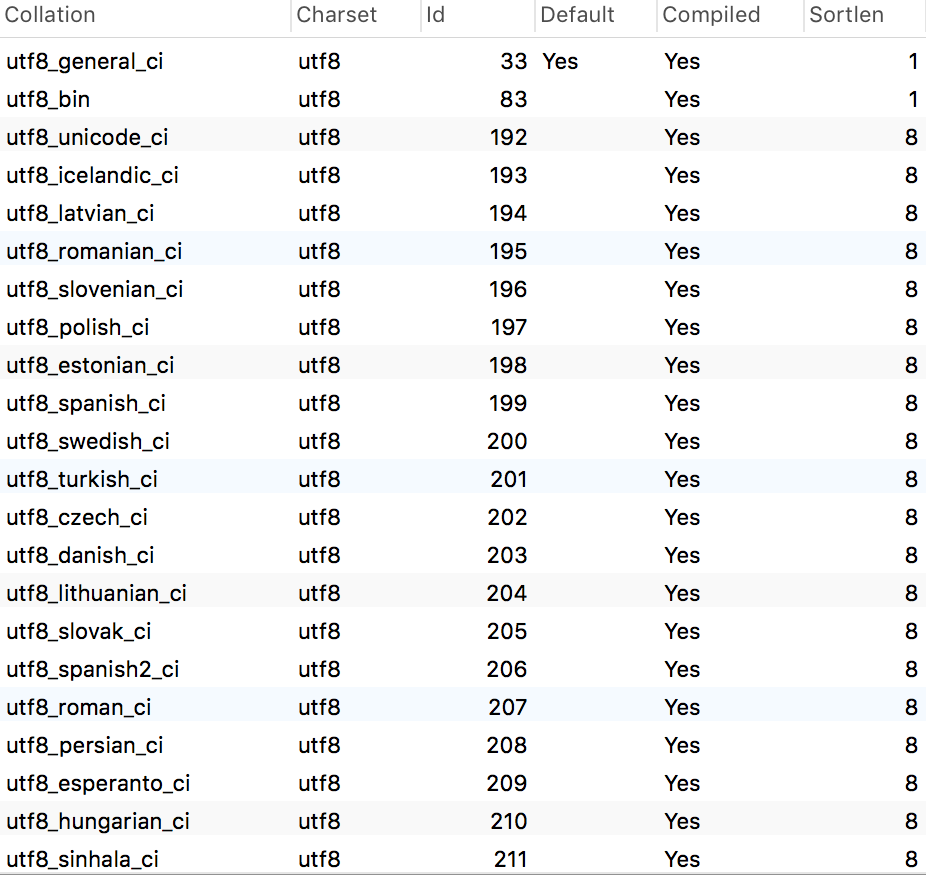
從上圖中我們可以找到utf8_bin,這個(gè)表示二進(jìn)制格式的數(shù)據(jù),我們?cè)O(shè)置成種類型的試試。
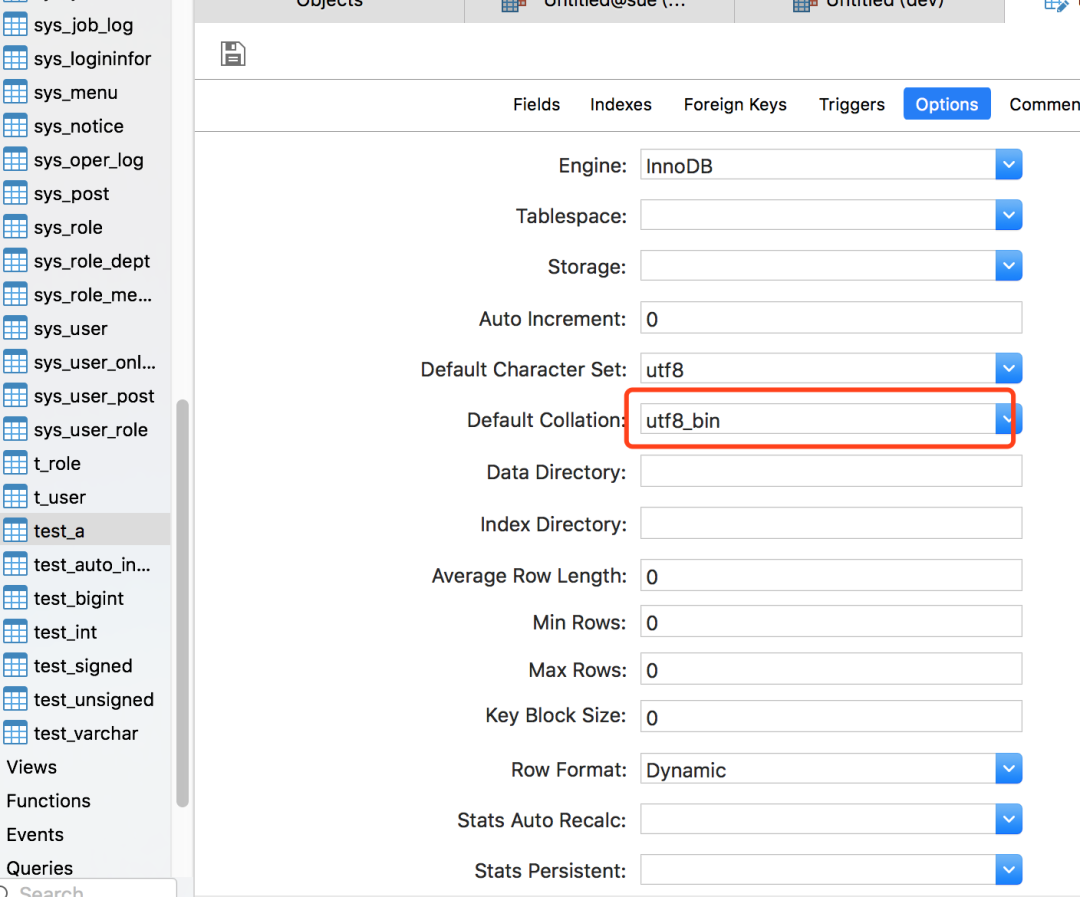
修改一下字段類型
ALTER TABLE test_a MODIFY COLUMN a VARCHAR(20) BINARY CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL;
再查看一下數(shù)據(jù)
select * from test_a where a = 'a';
執(zhí)行結(jié)果:

果然,結(jié)果對(duì)了。
六、特殊字符
筆者之前做項(xiàng)目的時(shí)候,提供過(guò)一個(gè)留言的功能,結(jié)果客戶端用戶輸入了一個(gè)emoji表情,直接導(dǎo)致接口報(bào)錯(cuò)了。
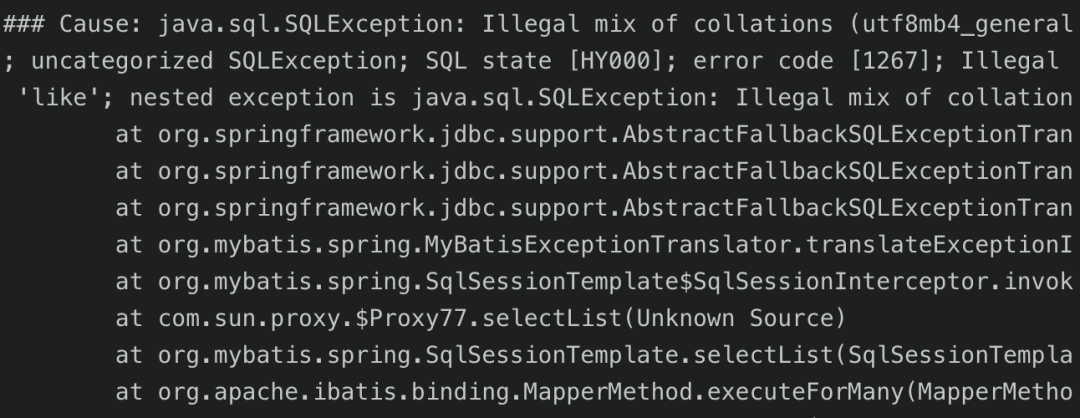
最后定位原因是由于當(dāng)時(shí)數(shù)據(jù)庫(kù)和表的字符編碼都是用的utf8,mysql的utf8編碼的一個(gè)字符最多3個(gè)字節(jié),但是一個(gè)emoji表情為4個(gè)字節(jié),所以u(píng)tf8不支持存儲(chǔ)emoji表情。
該如何解決這個(gè)問(wèn)題呢?
將字符編碼改成utf8mb4,utf8mb4最多能有4字節(jié),不過(guò),在mysql5.5.3或更高的版本才支持。
在mysql 的配置文件 my.cnf 或 my.ini 配置文件中修改如下:
[client]default-character-set = utf8mb4[mysqld]character-set-server = utf8mb4collation-server = utf8mb4_general_ci
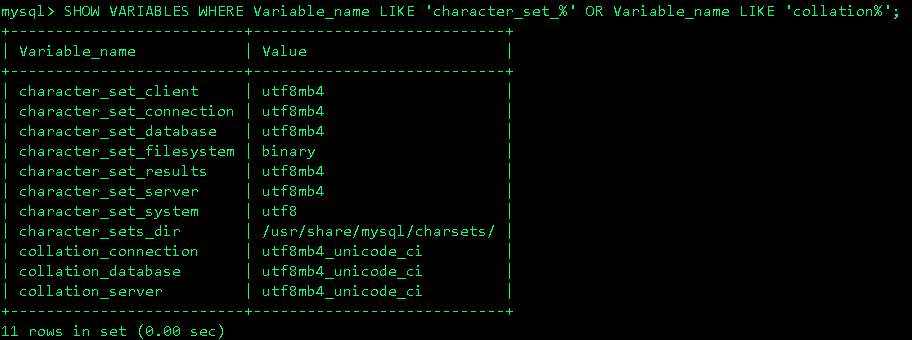
重啟MySQL,然后使用以下命令查看編碼,應(yīng)該全部為utf8mb4,這是修改整個(gè)數(shù)據(jù)庫(kù)的編碼方式。
SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%' OR Variable_name LIKE 'collation%';ji結(jié)果為:
也可以單獨(dú)修改某張表的編碼方式:
alter table test_a convert to character set utf8mb4 collate utf8mb4_bin;以及修改某個(gè)字段的編碼方式:
ALTER TABLE test_a CHANGE a a VARCHAR(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;此外,建議同學(xué)們?cè)趧?chuàng)建數(shù)據(jù)庫(kù)和表的時(shí)候字符編碼都定義成utf8mb4,避免一些不必要的問(wèn)題。
有道無(wú)術(shù),術(shù)可成;有術(shù)無(wú)道,止于術(shù)
歡迎大家關(guān)注Java之道公眾號(hào)
好文章,我在看??