
京東開源FaceX-Zoo:PyTorch面部識別工具箱
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達


近年來,基于深度學習的人臉識別取得了長足的進展。然而,實際的模型制作和深度人臉識別的進一步研究仍需要相應(yīng)的公眾支持。例如,人臉表示網(wǎng)絡(luò)的生產(chǎn)需要一個模塊化的訓練方案,以考慮從各種最先進的骨干候選人和訓練監(jiān)督的現(xiàn)實世界的人臉識別需求的適當選擇;對于性能分析和比較,標準和自動評估與一堆模型在多個基準將是一個理想的工具;此外,人臉識別在整體管道形態(tài)上的部署也受到了公眾的歡迎。此外,還有一些新出現(xiàn)的挑戰(zhàn),如近期全球COVID-19大流行帶來的蒙面人臉識別,在實際應(yīng)用中越來越受到關(guān)注。一個可行且優(yōu)雅的解決方案是構(gòu)建一個易于使用的統(tǒng)一框架來滿足上述需求。為此,作者引入了一個新的開源框架,命名為FaceX-Zoo,它是面向人臉識別的研發(fā)社區(qū)。采取高度模塊化和可伸縮設(shè)計,FaceX-Zoo提供一個培訓模塊各種監(jiān)督頭和脊椎state-of-theart人臉識別,以及標準化評價模塊使評價模型在大多數(shù)流行的基準只是通過編輯一個簡單的配置。此外,還提供了一個簡單但功能齊全的face SDK,用于驗證和培訓模型的主要應(yīng)用。作者沒有盡可能多地采用先前的技術(shù),而是使FaceX-Zoo能夠隨著面部相關(guān)領(lǐng)域的發(fā)展而輕松地升級和擴展。
代碼鏈接:https://github.com/JDAI-CV/FaceX-Zoo
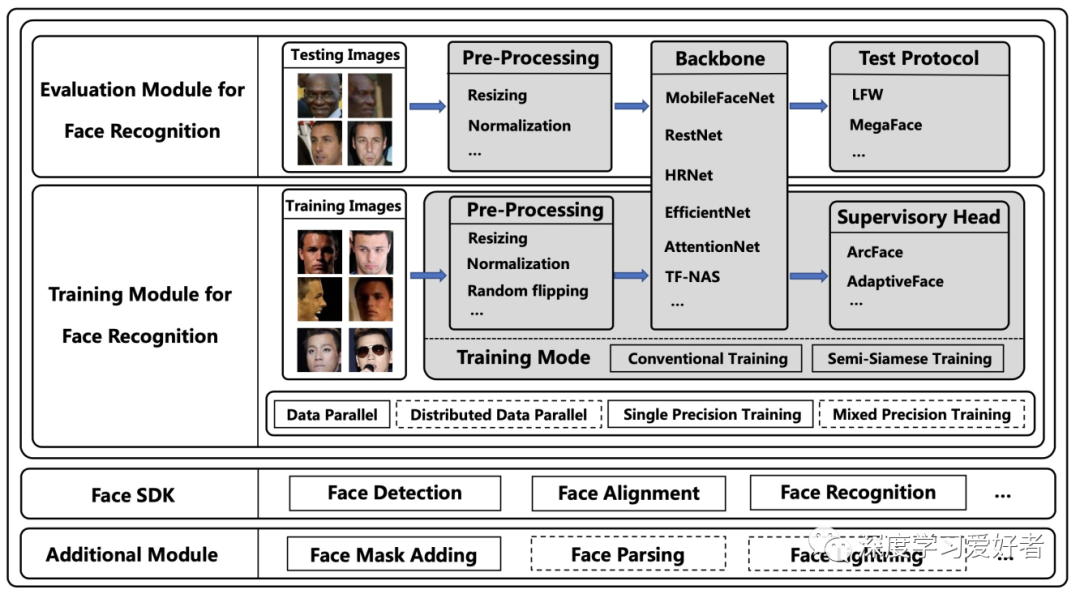
FaceX-Zoo的架構(gòu)。實框中的模塊是當前版本中已經(jīng)提供的模塊,虛線框中的模塊將在后續(xù)版本中添加
上圖巧妙地展示了FaceX-Zoo的總體架構(gòu)。整個項目主要包括四個部分:培訓模塊、評估模塊、附加模塊和face SDK,其中前兩個模塊是本項目的核心部分。培訓和評估模塊包括預(yù)處理、培訓模式、主干、監(jiān)督負責人和測試協(xié)議等幾個組成部分。作者將詳細說明如下。
預(yù)處理:這個模塊在將圖像發(fā)送到網(wǎng)絡(luò)之前完成圖像的基本轉(zhuǎn)換。對于訓練,作者實現(xiàn)了常用的操作,如大小調(diào)整、歸一化、隨機裁剪、隨機翻轉(zhuǎn)、隨機旋轉(zhuǎn)等。可根據(jù)不同需求,靈活添加定制操作。對于評估,只使用大小調(diào)整和標準化。同樣地,測試增強,如五種作物,水平翻轉(zhuǎn)等,也可以通過自定義輕松添加到作者的框架中。
訓練模式:將傳統(tǒng)的人臉識別訓練模式作為基線例程。具體來說,通過DataLoader對訓練輸入進行調(diào)度,然后將訓練輸入發(fā)送到骨干網(wǎng)進行前向傳遞,最后計算一個準則作為訓練損失進行后向更新。此外,作者考慮了人臉識別中的一種實際情況,即使用淺分布數(shù)據(jù)[11]來訓練網(wǎng)絡(luò)。因此,作者整合了最近的訓練策略,以促進淺面數(shù)據(jù)的訓練。
骨干:利用骨干網(wǎng)提取人臉圖像的特征。作者在FaceX-Zoo中提供了一系列最先進的骨干架構(gòu),如下所示。此外,只要修改配置文件并添加體系結(jié)構(gòu)定義文件,就可以在PyTorch的支持下輕松定制任何其他體系結(jié)構(gòu)選擇:
MobileFaceNet:為移動設(shè)備上的應(yīng)用程序提供一個高效的網(wǎng)絡(luò)。
ResNet:一系列用于通用視覺任務(wù)的經(jīng)典架構(gòu)。
SE-ResNet:配備SE塊的ResNet,重新校準通道的特征響應(yīng)。
HRNet:深度高分辨率表示學習網(wǎng)絡(luò)。
EfficientNet:一組在深度、寬度和分辨率之間擴展的架構(gòu)。
GhostNet:一個旨在通過廉價操作生成更多特征地圖的模型。
AttentionNet:一個由注意模塊堆疊而成的網(wǎng)絡(luò),用來學習注意感知功能。
TF-NAS:由NAS搜索的一系列具有延遲約束的架構(gòu)
監(jiān)督:監(jiān)控頭定義為實現(xiàn)人臉準確識別的監(jiān)控單點及其相應(yīng)的計算模塊。為了學習人臉識別的判別特征,通常對預(yù)測的logit進行一些具體的操作,如歸一化、縮放、添加邊距等,然后再發(fā)送到softmax層。作者在FaceX-Zoo中實現(xiàn)了一系列的softmaxstyle損失,如下:
AM-Softmax:在目標logit上增加余數(shù)保證金懲罰的附加保證金損失。
ArcFace:一個附加的角度邊距損失,在目標角度上增加邊距懲罰。
AdaCos:基于余弦的softmax損耗,超參數(shù)無和自適應(yīng)縮放。
AdaM-Softmax:自適應(yīng)margin loss,可以自適應(yīng)地調(diào)整不同類別的margin。
CircleLoss:一個統(tǒng)一的公式,用類級標簽和成對標簽學習。
CurricularFace :一個損失函數(shù),在不同的訓練階段,自適應(yīng)地調(diào)整簡單和困難樣本的重要性。
MV-Softmax:一種損失函數(shù),自適應(yīng)地強調(diào)錯誤分類的特征向量,指導判別特征學習。NPCFace:一個損失函數(shù),它強調(diào)對消極和積極難題的訓練。
測試協(xié)議:有各種基準來衡量人臉識別模型的準確性。其中許多側(cè)重于特定的人臉識別挑戰(zhàn),比如跨年齡、跨姿勢和跨種族。其中常用的測試協(xié)議主要基于LFW[18]和megface[20]的基準。作者將這些協(xié)議集成到FaceX-Zoo中,使用簡單,指令清晰,通過簡單的配置,人們可以很容易地在單個或多個基準上測試他們的模型。此外,通過添加測試數(shù)據(jù)和解析測試對,可以方便地擴展額外的測試協(xié)議。值得注意的是,還提供了一個基于megface的蒙面人臉識別基準。
LFW:它包含了從網(wǎng)上收集的13,233張帶有姿勢、表情和照明變化的身份圖像。作者提供了在這個經(jīng)典基準上10倍交叉驗證的平均精度。
CPLFW:包含3930個身份的11322張圖像,側(cè)重于跨姿態(tài)人臉驗證。遵循官方協(xié)議,采用10倍交叉驗證的平均精度。
CALFW:它包含了4022個身份的12174張圖像,旨在跨年齡人臉驗證。采用10倍交叉驗證的平均精度。
AgeDB30:它包含了12240張圖像,440個身份,每個測試對有30歲的年齡差距。作者提供了10倍交叉驗證的平均準確性。
RFW:包含了11,430個身份的40,307幅圖像,被提出用來測量人臉識別中潛在的種族偏見。RFW中有四個測試子集,分別為African, Asian, Caucasian和Indian,作者分別提供每個子集的平均準確率。
megface:它包含80個探測身份和100萬個畫廊干擾物,旨在評估大規(guī)模的人臉識別性能。作者提供了megface的k級識別準確性。
megface - mask:它包含與megface相同的探測身份和圖庫干擾物,而每個探測圖像都由一個虛擬面具添加。該協(xié)議旨在評估大規(guī)模蒙面人臉識別的性能。
Background:由于最近全球COVID- 19大流行,蒙面人臉識別已成為許多場景下的關(guān)鍵應(yīng)用需求。然而,用于訓練和評估的掩蔽人臉數(shù)據(jù)集很少。為了解決這個問題,作者授權(quán)了FaceX-Zoo的框架,通過名為FMA-3D (3D-based face mask Adding)的專門模塊,在現(xiàn)有的人臉圖像中添加虛擬面具。
FMA-3D:給定一個真正的戴面具的臉圖像(圖2 (a))和B non-masked臉圖像(圖2 (d)),作者合成一個寫實的戴面具的臉圖像的面具和面部區(qū)域B。首先,作者利用一個面具分割模型[23]從圖像中提取面具區(qū)域(圖2 (B)),然后映射紋理映射到UV空間真實感三維人臉重建方法PRNet[12](圖2 (c))。對于圖像B,作者采用與A相同的方法計算UV空間中的紋理貼圖(圖2(e))。接下來,作者在UV空間中混合蒙版紋理貼圖和人臉紋理貼圖,如圖2(f)所示。最后,根據(jù)圖像b的UV位置圖繪制混合紋理圖,合成出蒙面圖像(圖2(g))。圖3為FMA-3D合成的更多蒙面圖像。與基于2d和基于gan的方法相比,作者的方法在魯棒性和保真性方面表現(xiàn)出了優(yōu)異的性能,特別是對于大的頭部姿態(tài)。
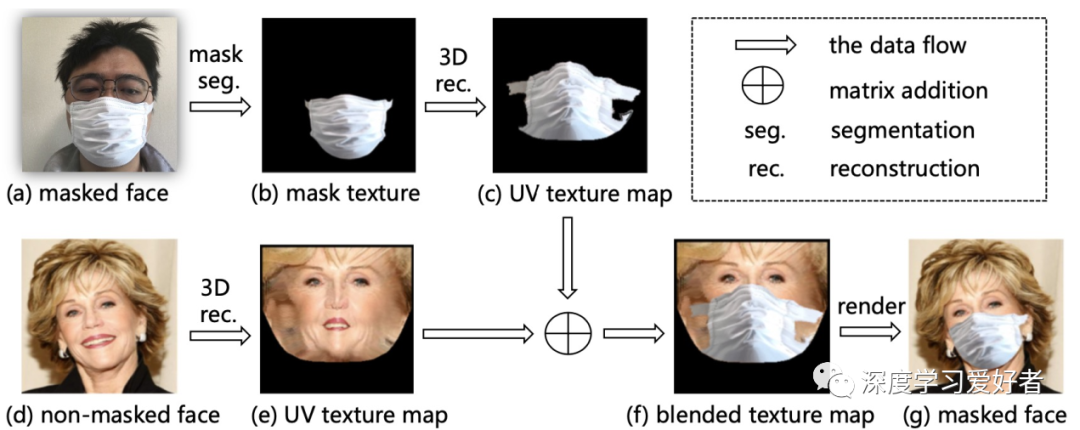
圖2:在人臉圖像上佩戴虛擬口罩的方法。蒙版模板可以根據(jù)輸入的蒙版面從多種選擇中采樣

圖3 上層:原始的未蒙面的人臉圖像。下層:FMA-3D合成的蒙面人臉圖像。
訓練蒙面人臉識別模型。借助作者的FMA-3D,可以方便地從現(xiàn)有的非掩模數(shù)據(jù)集中合成大量的掩模人臉圖像,如MS-Celeb-1M-v1c。由于現(xiàn)有的數(shù)據(jù)集已經(jīng)有了ID標注,作者可以直接使用它們來訓練人臉識別網(wǎng)絡(luò),而不需要額外的標注。訓練方法可以是傳統(tǒng)的常規(guī)或SST,以及訓練頭和骨干可以實例化與FaceXZoo集成的選擇。注意,測試基準可以以相同的方式從非屏蔽版本擴展到屏蔽版本。
實驗和結(jié)果:利用FMA-3D,作者將MS-Celeb1M-v1c的訓練數(shù)據(jù)合成為其掩碼版本MS-Celeb1M-v1c- mask。它包括MSCeleb1M-v1c中每個身份的原始人臉圖像,以及與原始人臉對應(yīng)的蒙面人臉圖像。作者選擇MobileFaceNet作為骨干,MV-Softmax作為監(jiān)控頭。該模型經(jīng)過18個epochs的訓練,批量大小為512。學習速率初始化為0:1,然后在epoch選擇10, 13和16。為了對模型進行蒙面識別任務(wù)的評價,作者利用FMA-3D合成了基于megface的蒙面數(shù)據(jù)集,命名為megface -mask,其中包含了蒙面探針圖像,保留了未蒙面畫廊圖像。如圖4所示
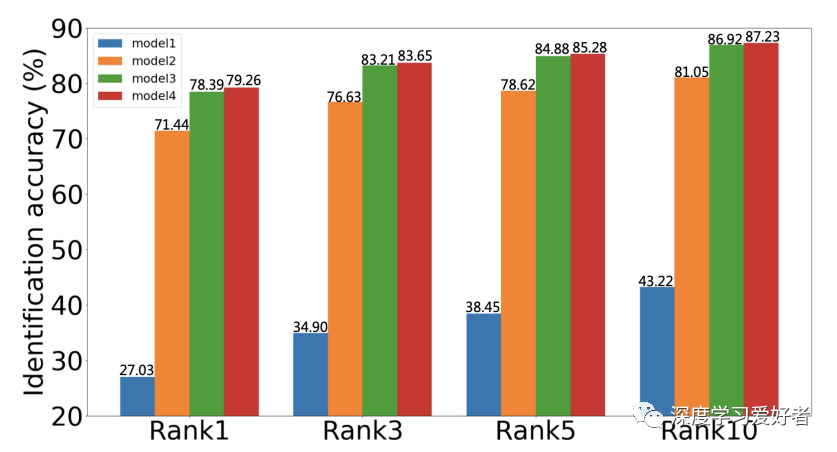
圖4
在未來,作者將從廣度、深度和效率三個方面對FaceX-Zoo進行改進。首先,將包含更多的附加模塊,如face解析和face lightning,從而豐富FaceX-Zoo中的X功能。第二,隨著深度學習技術(shù)的發(fā)展,骨干架構(gòu)和監(jiān)督負責人模塊將不斷得到補充。第三,通過分布式數(shù)據(jù)并行技術(shù)和混合精度訓練來提高訓練效率
每日堅持論文分享不易,如果喜歡我們的內(nèi)容,希望可以推薦或者轉(zhuǎn)發(fā)給周圍的同學。

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~