
計算機視覺中的注意力機制
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達


本文轉載自知乎,已獲作者授權轉載。
https://zhuanlan.zhihu.com/p/146130215
之前在看DETR這篇論文中的self_attention,然后結合之前實驗室組會經(jīng)常提起的注意力機制,所以本周時間對注意力機制進行了相關的梳理,以及相關的源碼閱讀了解其實現(xiàn)的機制
attention機制可以它認為是一種資源分配的機制,可以理解為對于原本平均分配的資源根據(jù)attention對象的重要程度重新分配資源,重要的單位就多分一點,不重要或者不好的單位就少分一點,在深度神經(jīng)網(wǎng)絡的結構設計中,attention所要分配的資源基本上就是權重了
視覺注意力分為幾種,核心思想是基于原有的數(shù)據(jù)找到其之間的關聯(lián)性,然后突出其某些重要特征,有通道注意力,像素注意力,多階注意力等,也有把NLP中的自注意力引入。
參考文獻:http://papers.nips.cc/paper/7181-attention-is-all-you-need
參考資料:https://zhuanlan.zhihu.com/p/48508221
GitHub:https://github.com/huggingface/transformers
自注意力有時候也稱為內(nèi)部注意力,是一個與單個序列的不同位置相關的注意力機制,目的是計算序列的表達形式,因為解碼器的位置不變性,以及在DETR中,每個像素不僅僅包含數(shù)值信息,并且每個像素的位置信息也很重要。

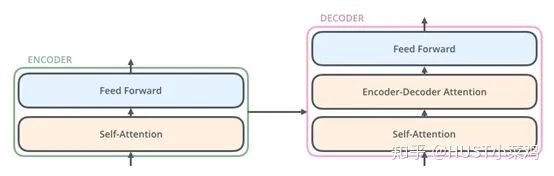
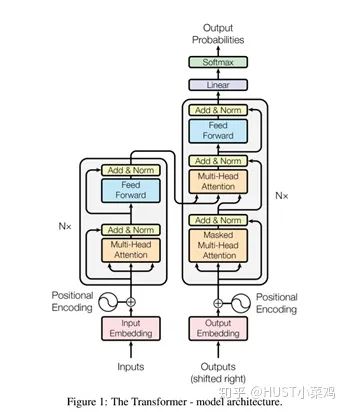
所有的編碼器在結構上都是相同的,但它們沒有共享參數(shù)。每個編碼器都可以分解成兩個子層:
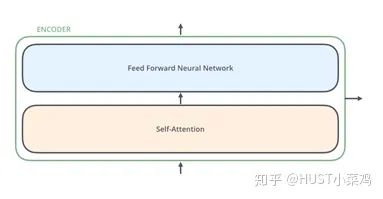
在transformer中,每個encoder子層有Multi-head self-attention和position-wise FFN組成。
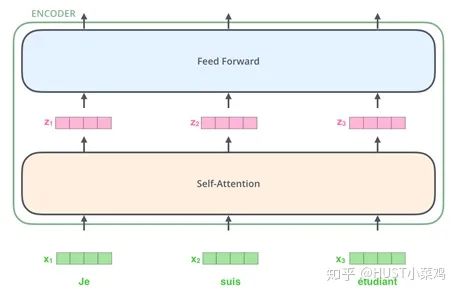
Self-Attention
Self-Attention是Transformer最核心的內(nèi)容,可以理解位將隊列和一組值與輸入對應,即形成querry,key,value向output的映射,output可以看作是value的加權求和,加權值則是由Self-Attention來得出的。
具體實施細節(jié)如下:
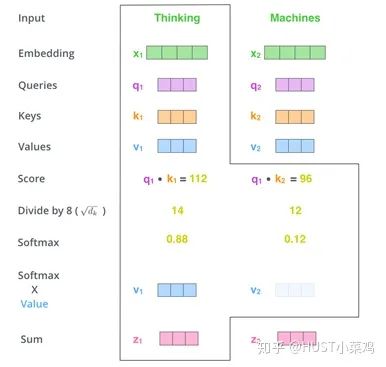
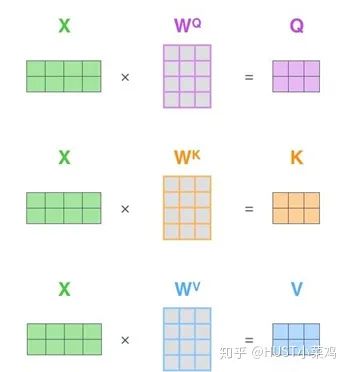
在self-attention中,每個單詞有3個不同的向量,它們分別是Query向量,Key向量和Value向量,長度均是64。它們是通過3個不同的權值矩陣由嵌入向量X乘以三個不同的權值矩陣得到,其中三個矩陣的尺寸也是相同的。均是512×64。
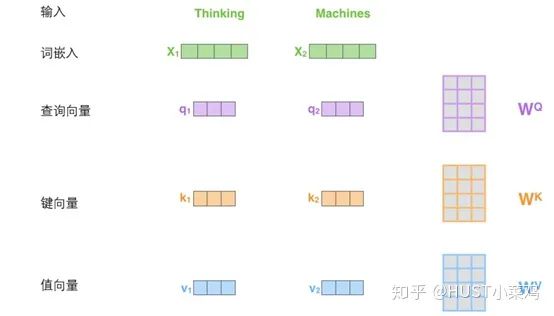
1)將輸入單詞轉化成嵌入向量;
2)根據(jù)嵌入向量得到q,k,v三個向量;
3)為每個向量計算一個score:score=q×v;
4)為了梯度的穩(wěn)定,Transformer使用了score歸一化,即除以sqrt(dk);
5)對score施以softmax激活函數(shù);
6)softmax點乘Value值v,得到加權的每個輸入向量的評分v;
7)相加之后得到最終的輸出結果z。
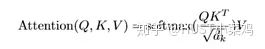


# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved"""DETR Transformer class.Copy-paste from torch.nn.Transformer with modifications:* positional encodings are passed in MHattention* extra LN at the end of encoder is removed* decoder returns a stack of activations from all decoding layers"""import copyfrom typing import Optional, Listimport torchimport torch.nn.functional as Ffrom torch import nn, Tensorclass Transformer(nn.Module):def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False,return_intermediate_dec=False):super().__init__()encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)encoder_norm = nn.LayerNorm(d_model) if normalize_before else Noneself.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)decoder_norm = nn.LayerNorm(d_model)self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,return_intermediate=return_intermediate_dec)self._reset_parameters()self.d_model = d_modelself.nhead = nheaddef _reset_parameters(self):for p in self.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)def forward(self, src, mask, query_embed, pos_embed):# flatten NxCxHxW to HWxNxCbs, c, h, w = src.shapesrc = src.flatten(2).permute(2, 0, 1)pos_embed = pos_embed.flatten(2).permute(2, 0, 1)query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)mask = mask.flatten(1)tgt = torch.zeros_like(query_embed)memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,pos=pos_embed, query_pos=query_embed)return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)class TransformerEncoder(nn.Module):def __init__(self, encoder_layer, num_layers, norm=None):super().__init__()self.layers = _get_clones(encoder_layer, num_layers)self.num_layers = num_layersself.norm = normdef forward(self, src,mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):output = srcfor layer in self.layers:output = layer(output, src_mask=mask,src_key_padding_mask=src_key_padding_mask, pos=pos)if self.norm is not None:output = self.norm(output)return outputclass TransformerDecoder(nn.Module):def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):super().__init__()self.layers = _get_clones(decoder_layer, num_layers)self.num_layers = num_layersself.norm = normself.return_intermediate = return_intermediatedef forward(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):output = tgtintermediate = []for layer in self.layers:output = layer(output, memory, tgt_mask=tgt_mask,memory_mask=memory_mask,tgt_key_padding_mask=tgt_key_padding_mask,memory_key_padding_mask=memory_key_padding_mask,pos=pos, query_pos=query_pos)if self.return_intermediate:intermediate.append(self.norm(output))if self.norm is not None:output = self.norm(output)if self.return_intermediate:intermediate.pop()intermediate.append(output)if self.return_intermediate:return torch.stack(intermediate)return outputclass TransformerEncoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False):super().__init__()self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dim_feedforward, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.activation = _get_activation_fn(activation)self.normalize_before = normalize_beforedef with_pos_embed(self, tensor, pos: Optional[Tensor]):return tensor if pos is None else tensor + posdef forward_post(self,src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):q = k = self.with_pos_embed(src, pos)src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))src = src + self.dropout2(src2)src = self.norm2(src)return srcdef forward_pre(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):src2 = self.norm1(src)q = k = self.with_pos_embed(src2, pos)src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src2 = self.norm2(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))src = src + self.dropout2(src2)return srcdef forward(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):if self.normalize_before:return self.forward_pre(src, src_mask, src_key_padding_mask, pos)return self.forward_post(src, src_mask, src_key_padding_mask, pos)class TransformerDecoderLayer(nn.Module):def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False):super().__init__()self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)# Implementation of Feedforward modelself.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(dim_feedforward, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.activation = _get_activation_fn(activation)self.normalize_before = normalize_beforedef with_pos_embed(self, tensor, pos: Optional[Tensor]):return tensor if pos is None else tensor + posdef forward_post(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):q = k = self.with_pos_embed(tgt, query_pos)tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,key_padding_mask=tgt_key_padding_mask)[0]tgt = tgt + self.dropout1(tgt2)tgt = self.norm1(tgt)tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask)[0]tgt = tgt + self.dropout2(tgt2)tgt = self.norm2(tgt)tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))tgt = tgt + self.dropout3(tgt2)tgt = self.norm3(tgt)return tgtdef forward_pre(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):tgt2 = self.norm1(tgt)q = k = self.with_pos_embed(tgt2, query_pos)tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,key_padding_mask=tgt_key_padding_mask)[0]tgt = tgt + self.dropout1(tgt2)tgt2 = self.norm2(tgt)tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),key=self.with_pos_embed(memory, pos),value=memory, attn_mask=memory_mask,key_padding_mask=memory_key_padding_mask)[0]tgt = tgt + self.dropout2(tgt2)tgt2 = self.norm3(tgt)tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))tgt = tgt + self.dropout3(tgt2)return tgtdef forward(self, tgt, memory,tgt_mask: Optional[Tensor] = None,memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None,memory_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None,query_pos: Optional[Tensor] = None):if self.normalize_before:return self.forward_pre(tgt, memory, tgt_mask, memory_mask,tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)return self.forward_post(tgt, memory, tgt_mask, memory_mask,tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)def _get_clones(module, N):return nn.ModuleList([copy.deepcopy(module) for i in range(N)])def build_transformer(args):return Transformer(d_model=args.hidden_dim,dropout=args.dropout,nhead=args.nheads,dim_feedforward=args.dim_feedforward,num_encoder_layers=args.enc_layers,num_decoder_layers=args.dec_layers,normalize_before=args.pre_norm,return_intermediate_dec=True,)def _get_activation_fn(activation):"""Return an activation function given a string"""if activation == "relu":return F.reluif activation == "gelu":return F.geluif activation == "glu":return F.gluraise RuntimeError(F"activation should be relu/gelu, not {activation}.")
軟注意力是一個[0,1]間的連續(xù)分布問題,更加關注區(qū)域或者通道,軟注意力是確定性注意力,學習完成后可以通過網(wǎng)絡生成,并且是可微的,可以通過神經(jīng)網(wǎng)絡計算出梯度并且可以前向傳播和后向反饋來學習得到注意力的權重。
1、空間域注意力(spatial transformer network)
論文地址:http://papers.nips.cc/paper/5854-spatial-transformer-networks
GitHub地址:https://github.com/fxia22/stn.pytorch
空間區(qū)域注意力可以理解為讓神經(jīng)網(wǎng)絡在看哪里。通過注意力機制,將原始圖片中的空間信息變換到另一個空間中并保留了關鍵信息,在很多現(xiàn)有的方法中都有使用這種網(wǎng)絡,自己接觸過的一個就是ALPHA Pose。
spatial transformer其實就是注意力機制的實現(xiàn),因為訓練出的spatial transformer能夠找出圖片信息中需要被關注的區(qū)域,同時這個transformer又能夠具有旋轉、縮放變換的功能,這樣圖片局部的重要信息能夠通過變換而被框盒提取出來。

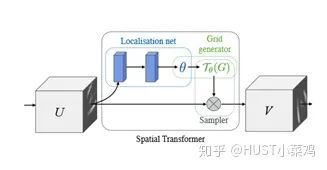
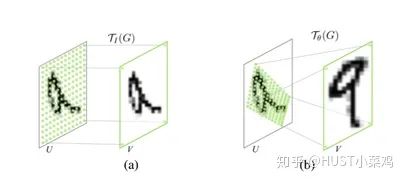
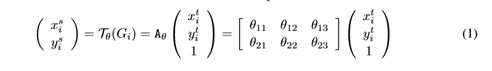
主要在于空間變換矩陣的學習
class STN(Module):def __init__(self, layout = 'BHWD'):super(STN, self).__init__()if layout == 'BHWD':self.f = STNFunction()else:self.f = STNFunctionBCHW()def forward(self, input1, input2):return self.f(input1, input2)class STNFunction(Function):def forward(self, input1, input2):self.input1 = input1self.input2 = input2self.device_c = ffi.new("int *")output = torch.zeros(input1.size()[0], input2.size()[1], input2.size()[2], input1.size()[3])#print('decice %d' % torch.cuda.current_device())if input1.is_cuda:self.device = torch.cuda.current_device()else:self.device = -1self.device_c[0] = self.deviceif not input1.is_cuda:my_lib.BilinearSamplerBHWD_updateOutput(input1, input2, output)else:output = output.cuda(self.device)my_lib.BilinearSamplerBHWD_updateOutput_cuda(input1, input2, output, self.device_c)return outputdef backward(self, grad_output):grad_input1 = torch.zeros(self.input1.size())grad_input2 = torch.zeros(self.input2.size())#print('backward decice %d' % self.device)if not grad_output.is_cuda:my_lib.BilinearSamplerBHWD_updateGradInput(self.input1, self.input2, grad_input1, grad_input2, grad_output)else:grad_input1 = grad_input1.cuda(self.device)grad_input2 = grad_input2.cuda(self.device)my_lib.BilinearSamplerBHWD_updateGradInput_cuda(self.input1, self.input2, grad_input1, grad_input2, grad_output, self.device_c)return grad_input1, grad_input2
2、通道注意力(Channel Attention,CA)
通道注意力可以理解為讓神經(jīng)網(wǎng)絡在看什么,典型的代表是SENet。卷積網(wǎng)絡的每一層都有好多卷積核,每個卷積核對應一個特征通道,相對于空間注意力機制,通道注意力在于分配各個卷積通道之間的資源,分配粒度上比前者大了一個級別。

論文:Squeeze-and-Excitation Networks(https://arxiv.org/abs/1709.01507)
GitHub地址:https://github.com/moskomule/senet.pytorch
Squeeze操作:將各通道的全局空間特征作為該通道的表示,使用全局平均池化生成各通道的統(tǒng)計量
Excitation操作:學習各通道的依賴程度,并根據(jù)依賴程度對不同的特征圖進行調(diào)整,得到最后的輸出,需要考察各通道的依賴程度
整體的結構如圖所示:


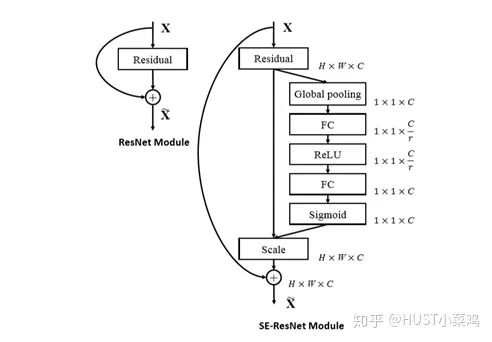
將輸入特征進行 Global avgpooling,得到1×1×Channel
然后bottleneck特征交互一下,先壓縮channel數(shù),再重構回channel數(shù)
最后接個sigmoid,生成channel間0~1的attention weights,最后scale乘回原輸入特征
SE-ResNet的SE-Block
class SEBasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,base_width=64, dilation=1, norm_layer=None,*, reduction=16):super(SEBasicBlock, self).__init__()self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes, 1)self.bn2 = nn.BatchNorm2d(planes)self.se = SELayer(planes, reduction)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.se(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
ResNet的Basic Block
class BasicBlock(nn.Module):def __init__(self, inplanes, planes, stride=1):super(BasicBlock, self).__init__()self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes)self.bn2 = nn.BatchNorm2d(planes)if inplanes != planes:self.downsample = nn.Sequential(nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes))else:self.downsample = lambda x: xself.stride = stridedef forward(self, x):residual = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out += residualout = self.relu(out)return out
兩者的差別主要體現(xiàn)在多了一個SElayer,詳細可以查看源碼
3、混合域模型(融合空間域和通道域注意力)
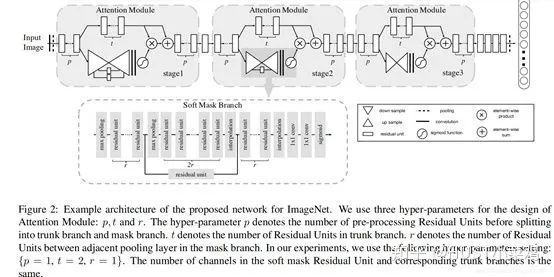
(1)論文:Residual Attention Network for image classification(CVPR 2017 Open Access Repository)
文章中注意力的機制是軟注意力基本的加掩碼(mask)機制,但是不同的是,這種注意力機制的mask借鑒了殘差網(wǎng)絡的想法,不只根據(jù)當前網(wǎng)絡層的信息加上mask,還把上一層的信息傳遞下來,這樣就防止mask之后的信息量過少引起的網(wǎng)絡層數(shù)不能堆疊很深的問題。
該文章的注意力機制的創(chuàng)新點在于提出了殘差注意力學習(residual attention learning),不僅只把mask之后的特征張量作為下一層的輸入,同時也將mask之前的特征張量作為下一層的輸入,這時候可以得到的特征更為豐富,從而能夠更好的注意關鍵特征。同時采用三階注意力模塊來構成整個的注意力。
(2)論文:Dual Attention Network for Scene Segmentation(CVPR 2019 Open Access Repository)
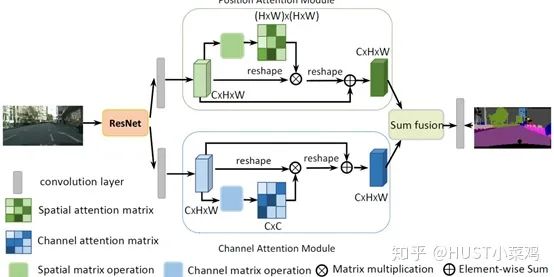
論文:non-local neural networks(CVPR 2018 Open Access Repository)
GitHub地址:https://github.com/AlexHex7/Non-local_pytorch
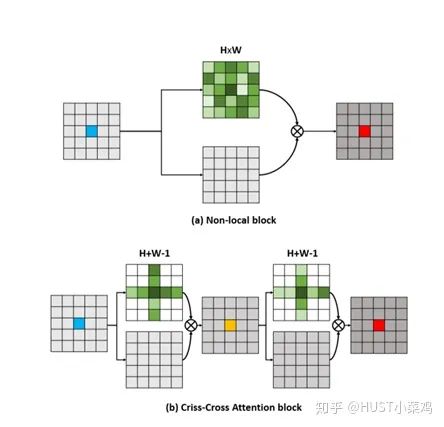
Local這個詞主要是針對感受野(receptive field)來說的。以單一的卷積操作為例,它的感受野大小就是卷積核大小,而我們一般都選用3*3,5*5之類的卷積核,它們只考慮局部區(qū)域,因此都是local的運算。同理,池化(Pooling)也是。相反的,non-local指的就是感受野可以很大,而不是一個局部領域。全連接就是non-local的,而且是global的。
但是全連接帶來了大量的參數(shù),給優(yōu)化帶來困難。卷積層的堆疊可以增大感受野,但是如果看特定層的卷積核在原圖上的感受野,它畢竟是有限的。這是local運算不能避免的。
然而有些任務,它們可能需要原圖上更多的信息,比如attention。如果在某些層能夠引入全局的信息,就能很好地解決local操作無法看清全局的情況,為后面的層帶去更豐富的信息。
文章定義的對于神經(jīng)網(wǎng)絡通用的Non-Local計算如下所示:
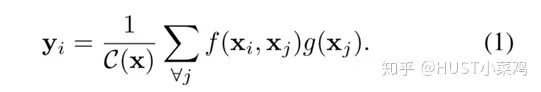
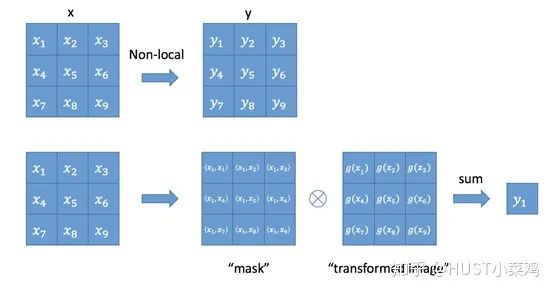
如果按照上面的公式,用for循環(huán)實現(xiàn)肯定是很慢的。此外,如果在尺寸很大的輸入上應用non-local layer,也是計算量很大的。
后者的解決方案是,只在高階語義層中引入non-local layer。還可以通過對embedding(θ,?,g)的結果加pooling層來進一步地減少計算量。
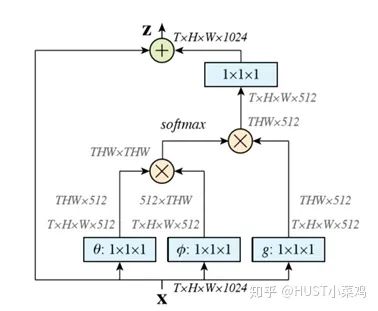
首先對輸入的 feature map X 進行線性映射(通過1x1卷積,來壓縮通道數(shù)),然后得到 θ, ?, g 特征
通過reshape操作,強行合并上述的三個特征除通道數(shù)外的維度,然后對 進行矩陣點乘操作,得到類似協(xié)方差矩陣的東西(這個過程很重要,計算出特征中的自相關性,即得到每幀中每個像素對其他所有幀所有像素的關系)
然后對自相關特征 以列or以行(具體看矩陣 g 的形式而定) 進行 Softmax 操作,得到0~1的weights,這里就是我們需要的 Self-attention 系數(shù)
最后將 attention系數(shù),對應乘回特征矩陣g中,然后再上擴channel 數(shù),與原輸入feature map X殘差
5、位置注意力(position-wise attention)
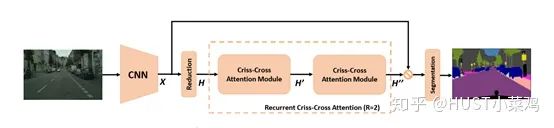
論文:CCNet: Criss-Cross Attention for Semantic Segmentation(ICCV 2019 Open Access Repository)
Github地址:https://github.com/speedinghzl/CCNet
本篇文章的亮點在于用了巧妙的方法減少了參數(shù)量。在上面的DANet中,attention map計算的是所有像素與所有像素之間的相似性,空間復雜度為(HxW)x(HxW),而本文采用了criss-cross思想,只計算每個像素與其同行同列即十字上的像素的相似性,通過進行循環(huán)(兩次相同操作),間接計算到每個像素與每個像素的相似性,將空間復雜度降為(HxW)x(H+W-1)
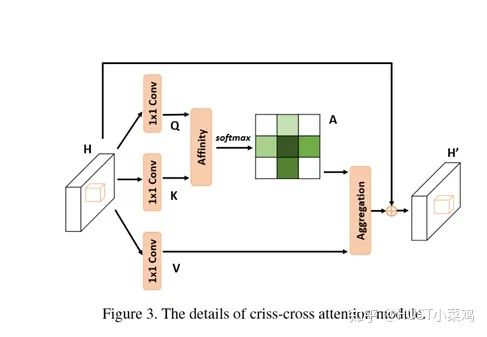
def _check_contiguous(*args):if not all([mod is None or mod.is_contiguous() for mod in args]):raise ValueError("Non-contiguous input")class CA_Weight(autograd.Function):def forward(ctx, t, f):# Save contextn, c, h, w = t.size()size = (n, h+w-1, h, w)weight = torch.zeros(size, dtype=t.dtype, layout=t.layout, device=t.device)_ext.ca_forward_cuda(t, f, weight)# Outputctx.save_for_backward(t, f)return weightdef backward(ctx, dw):t, f = ctx.saved_tensorsdt = torch.zeros_like(t)df = torch.zeros_like(f)_ext.ca_backward_cuda(dw.contiguous(), t, f, dt, df)_check_contiguous(dt, df)return dt, dfclass CA_Map(autograd.Function):def forward(ctx, weight, g):# Save contextout = torch.zeros_like(g)_ext.ca_map_forward_cuda(weight, g, out)# Outputctx.save_for_backward(weight, g)return outdef backward(ctx, dout):weight, g = ctx.saved_tensorsdw = torch.zeros_like(weight)dg = torch.zeros_like(g)_ext.ca_map_backward_cuda(dout.contiguous(), weight, g, dw, dg)_check_contiguous(dw, dg)return dw, dgca_weight = CA_Weight.applyca_map = CA_Map.applyclass CrissCrossAttention(nn.Module):""" Criss-Cross Attention Module"""def __init__(self,in_dim):super(CrissCrossAttention,self).__init__()self.chanel_in = in_dimself.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self,x):proj_query = self.query_conv(x)proj_key = self.key_conv(x)proj_value = self.value_conv(x)energy = ca_weight(proj_query, proj_key)attention = F.softmax(energy, 1)out = ca_map(attention, proj_value)out = self.gamma*out + xreturn out__all__ = ["CrissCrossAttention", "ca_weight", "ca_map"]
0/1問題,哪些被attention,哪些不被attention。更加關注點,圖像中的每個點都可能延伸出注意力,同時強注意力是一個隨機預測的過程,更加強調(diào)動態(tài)變化,并且是不可微,所以訓練過程往往通過增強學習。
參考資料:
【1】blog.csdn.net/xys43038
【2】https://zhuanlan.zhihu.com/p/33345791
【3】https://zhuanlan.zhihu.com/p/54150694
好消息!
小白學視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~