
HDFS 為何在大數(shù)據(jù)領(lǐng)域經(jīng)久不衰?
1 概述
1.1 簡(jiǎn)介
Hadoop實(shí)現(xiàn)了一個(gè)分布式文件系統(tǒng)(Hadoop Distributed File System),簡(jiǎn)稱HDFS 源自于Google的GFS論文,發(fā)表于2003年,HDFS是GFS的克隆版
1.2 設(shè)計(jì)目標(biāo)
filel:node1 node2 node3file2: node2 node3 node4file3: node3 node4 node5file4: node5 node6 node7
不管文件多大,都存儲(chǔ)在一個(gè)節(jié)點(diǎn),在進(jìn)行數(shù)據(jù)處理時(shí),很難進(jìn)行并行處理,節(jié)點(diǎn)可能就成為網(wǎng)絡(luò)瓶頸,很難進(jìn)行大數(shù)據(jù)的處理 存儲(chǔ)負(fù)載很難均衡,每個(gè)節(jié)點(diǎn)的利用率很低
巨大的分布式文件系統(tǒng) 運(yùn)行在普通廉價(jià)的硬件 易擴(kuò)展、為用戶提供性能不錯(cuò)的文件存儲(chǔ)服務(wù)
2 如何設(shè)計(jì)一個(gè)分布式文件系統(tǒng)
NameNode用于管理文件系統(tǒng)的命名空間以及調(diào)節(jié)客戶訪問(wèn)文件 還有多個(gè)DataNode(簡(jiǎn)稱DN),數(shù)據(jù)節(jié)點(diǎn),作為從節(jié)點(diǎn)(slave server)存在 通常每個(gè)集群中的DataNode,都會(huì)被NameNode所管理,DataNode用于存儲(chǔ)數(shù)據(jù)
NameNode,而其他集群中的機(jī)器各自運(yùn)行一個(gè)DataNode實(shí)例。雖然一臺(tái)機(jī)器上也可以運(yùn)行多個(gè)節(jié)點(diǎn),但不推薦。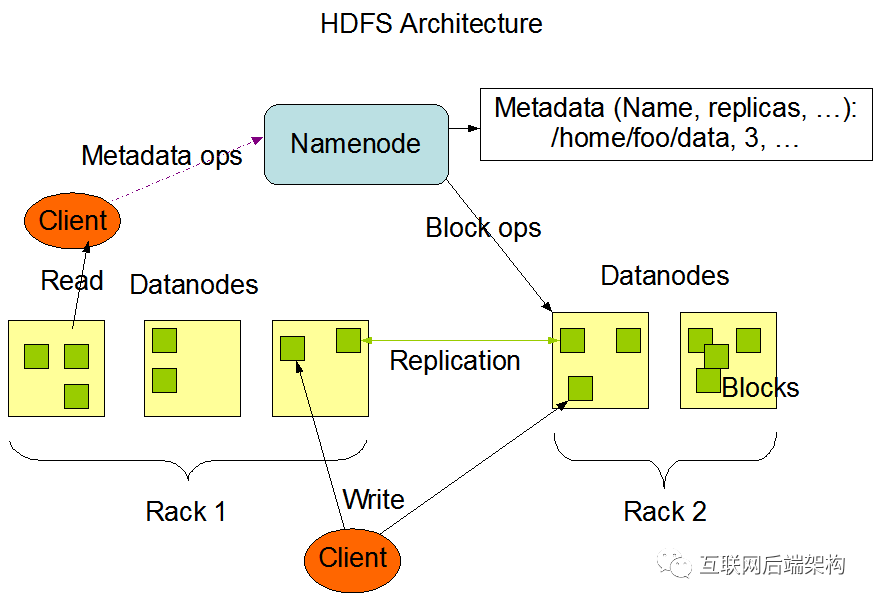
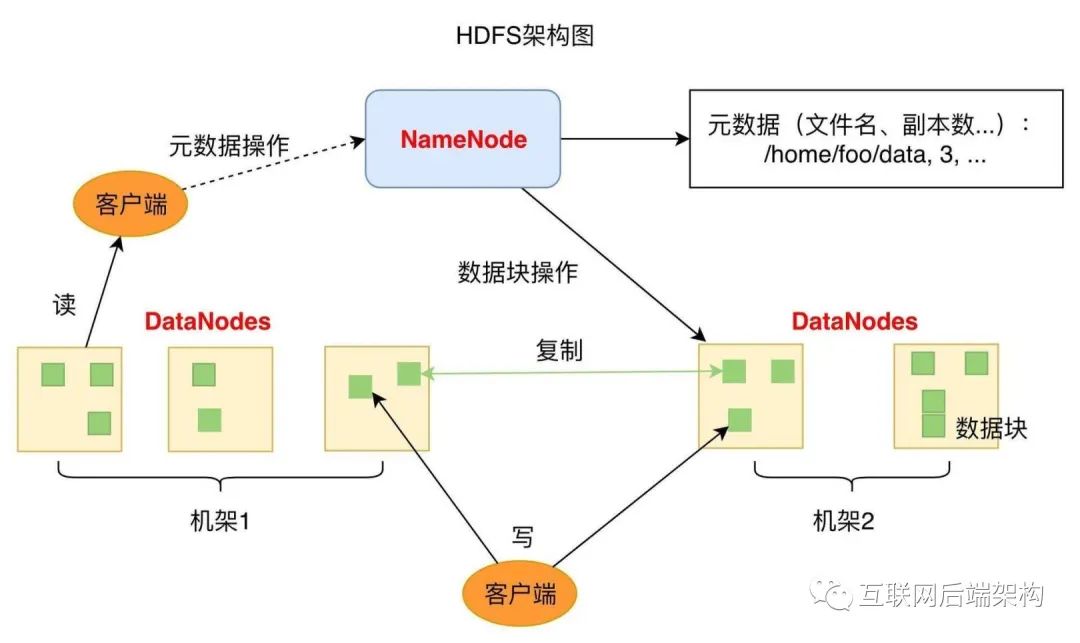
DataNode
存儲(chǔ)用戶的文件對(duì)應(yīng)的數(shù)據(jù)塊(Block) 會(huì)定期向NN發(fā)送心跳信息,匯報(bào)本身及其所有的block信息和健康狀況
NameNode
負(fù)責(zé)客戶端請(qǐng)求的響應(yīng) 負(fù)責(zé)元數(shù)據(jù)(文件的名稱、副本系數(shù)、Block存放的DN)的管理
3 S副本機(jī)制
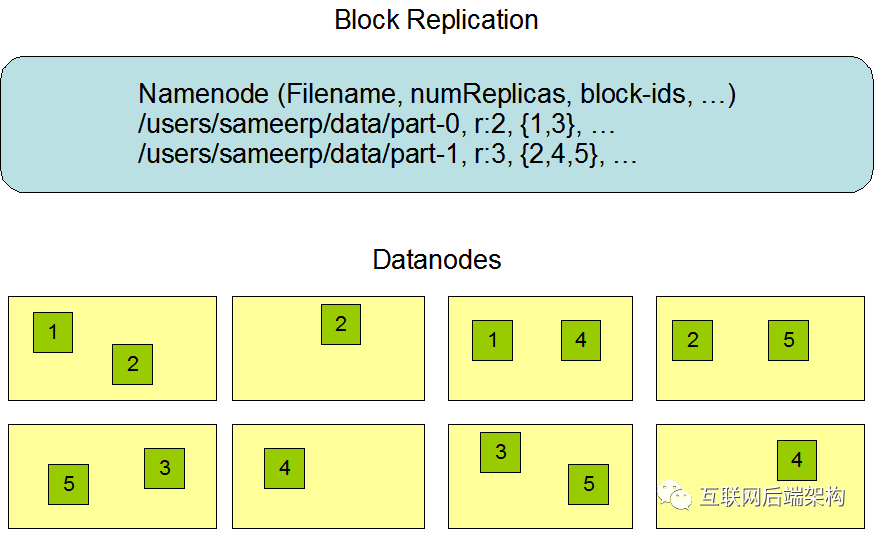
Block多份復(fù)制存儲(chǔ)的示意圖
Block1的兩個(gè)備份存儲(chǔ)在DataNode0和DataNode2兩個(gè)服務(wù)器上 Block3的兩個(gè)備份存儲(chǔ)DataNode4和DataNode6兩個(gè)服務(wù)器上
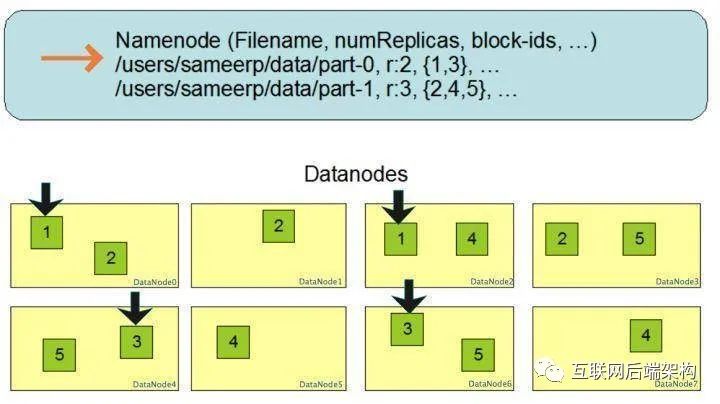
副本存放策略
第一個(gè)副本會(huì)隨機(jī)選擇,但是不會(huì)選擇存儲(chǔ)過(guò)滿的節(jié)點(diǎn) 第二個(gè)副本放在和第一個(gè)副本不同且隨機(jī)選擇的機(jī)架 第三個(gè)和第二個(gè)放在同一機(jī)架上的不同節(jié)點(diǎn) 剩余副本完全隨機(jī)節(jié)點(diǎn)
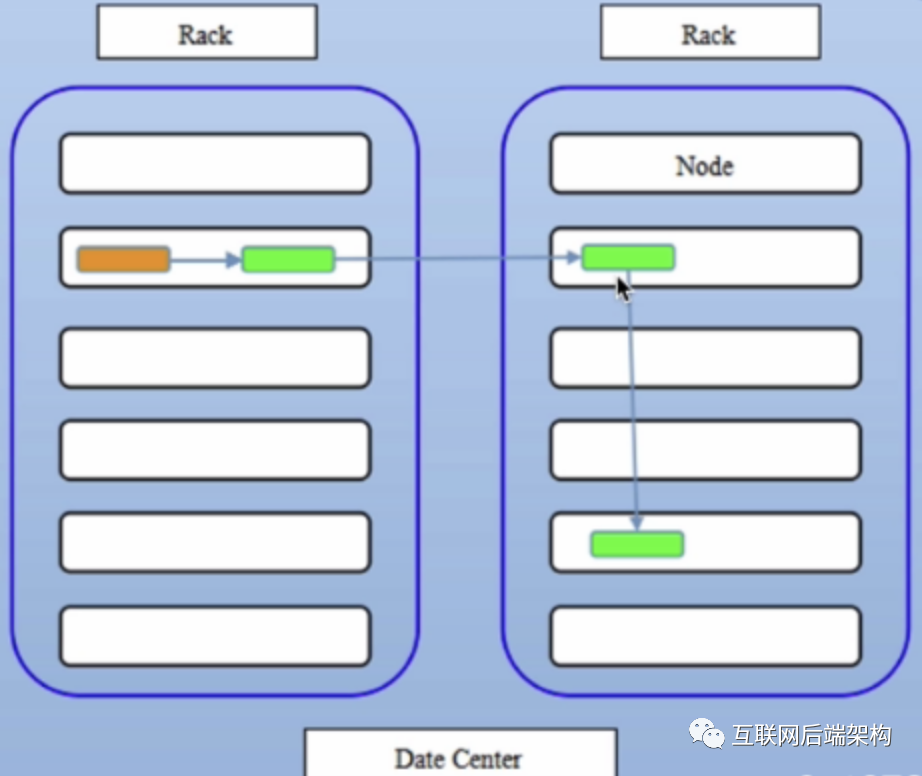
合理性分析
可靠性:block存儲(chǔ)在兩個(gè)機(jī)架 寫帶寬:寫操作僅穿過(guò)一個(gè)網(wǎng)絡(luò)交換機(jī) 讀操作:選擇其中一個(gè)機(jī)架去讀 block分布在整個(gè)集群
5 HDFS的高可用設(shè)計(jì)
5.1 數(shù)據(jù)存儲(chǔ)故障容錯(cuò)
5.2 磁盤故障容錯(cuò)
5.3 DataNode故障容錯(cuò)
5.4 NameNode故障容錯(cuò)
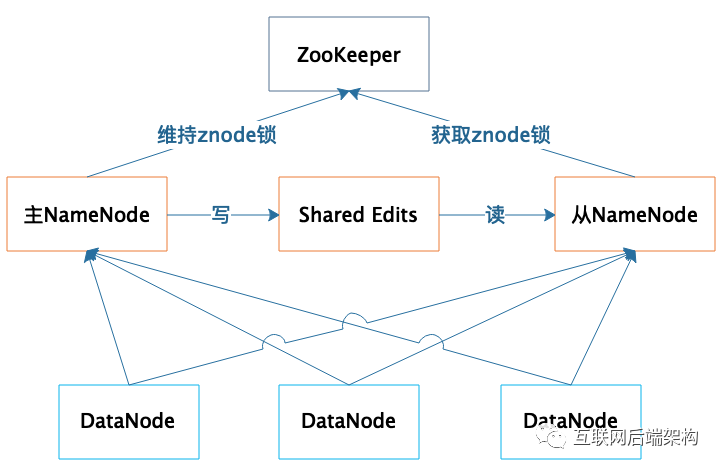
一臺(tái)作為主服務(wù)器提供服務(wù) 一臺(tái)作為從服務(wù)器進(jìn)行熱備
6 保證系統(tǒng)可用性的策略
冗余備份
失效轉(zhuǎn)移
降級(jí)
總結(jié)
評(píng)論
圖片
表情