
使用pickle模塊序列化數(shù)據(jù),優(yōu)化代碼
一、pickle模塊介紹
二、pickle可以序列化哪些Python對(duì)象
None、True和False
整數(shù)、浮點(diǎn)數(shù)、復(fù)數(shù)
str、byte、bytearray
只包含可序列化對(duì)象的集合,包括tuple、list、set和dict
定義在模塊最外層的函數(shù)(使用def定義,lambda函數(shù)不可以)
定義在模塊最外層的內(nèi)置函數(shù)
定義在模塊最外層的類
某些類實(shí)例
三、案例分享
1. 將數(shù)據(jù)序列化保存
# coding=utf-8
import pickle
data = {
... # 文末附完整數(shù)據(jù)獲取方式
}
with open('S10.pkl', 'wb') as pkl_file:
pickle.dump(data, pkl_file)
2. 讀取數(shù)據(jù)并反序列化
# coding=utf-8
import matplotlib.pyplot as plt
from matplotlib import ticker
from numpy import mean
import pickle
with open('S10.pkl', 'rb') as pkl_file:
data = pickle.load(pkl_file)
location = ["上單", "打野", "中單", "下路", "輔助"]
win_loc_kill, win_loc_die, win_loc_assists = [[list() for _ in range(5)] for _ in range(3)]
lose_loc_kill, lose_loc_die, lose_loc_assists = [[list() for _ in range(5)] for _ in range(3)]
for i in range(5):
win_loc_kill[i] = [value[0][i][0] for value in data.values()]
win_loc_die[i] = [value[0][i][1] for value in data.values()]
win_loc_assists[i] = [value[0][i][2] for value in data.values()]
lose_loc_kill[i] = [value[1][i][0] for value in data.values()]
lose_loc_die[i] = [value[1][i][1] for value in data.values()]
lose_loc_assists[i] = [value[1][i][2] for value in data.values()]
# noinspection PyTypeChecker
win_avg_kill = [round(mean(kill), 2) for kill in win_loc_kill]
# noinspection PyTypeChecker
win_avg_die = [round(mean(die), 2) for die in win_loc_die]
# noinspection PyTypeChecker
win_avg_assists = [round(mean(assists), 2) for assists in win_loc_assists]
# noinspection PyTypeChecker
lose_avg_kill = [round(mean(kill), 2) for kill in lose_loc_kill]
# noinspection PyTypeChecker
lose_avg_die = [round(mean(die), 2) for die in lose_loc_die]
# noinspection PyTypeChecker
lose_avg_assists = [round(mean(assists), 2) for assists in lose_loc_assists]
fig, axs = plt.subplots(nrows=2, ncols=1, figsize=(20, 16), dpi=100)
x = range(len(location))
axs[0].bar([i-0.2 for i in x], win_avg_kill, width=0.2, color='b')
axs[0].bar(x, win_avg_die, width=0.2, color='r')
axs[0].bar([i+0.2 for i in x], win_avg_assists, width=0.2, color='g')
axs[1].bar([i-0.2 for i in x], lose_avg_kill, width=0.2, color='b')
axs[1].bar(x, lose_avg_die, width=0.2, color='r')
axs[1].bar([i+0.2 for i in x], lose_avg_assists, width=0.2, color='g')
for a, b in zip(x, win_avg_kill):
axs[0].text(a-0.2, b+0.1, '%.02f' % b, ha='center', va='bottom', fontsize=14)
for a, b in zip(x, win_avg_die):
axs[0].text(a, b+0.1, '%.02f' % b, ha='center', va='bottom', fontsize=14)
for a, b in zip(x, win_avg_assists):
axs[0].text(a+0.2, b+0.1, '%.02f' % b, ha='center', va='bottom', fontsize=14)
for a, b in zip(x, lose_avg_kill):
axs[1].text(a-0.2, b+0.1, '%.02f' % b, ha='center', va='bottom', fontsize=14)
for a, b in zip(x, lose_avg_die):
axs[1].text(a, b+0.1, '%.02f' % b, ha='center', va='bottom', fontsize=14)
for a, b in zip(x, lose_avg_assists):
axs[1].text(a+0.2, b+0.1, '%.02f' % b, ha='center', va='bottom', fontsize=14)
for i in range(2):
axs[i].xaxis.set_major_locator(ticker.FixedLocator(x))
axs[i].xaxis.set_major_formatter(ticker.FixedFormatter(location))
axs[i].set_yticks(range(0, 11, 2))
axs[i].grid(linestyle="--", alpha=0.5)
axs[i].legend(['擊殺', '死亡', '助攻'], loc='upper left', fontsize=16, markerscale=0.5)
axs[i].set_xlabel("位置", fontsize=18)
axs[i].set_ylabel("場(chǎng)均數(shù)據(jù)", fontsize=18, rotation=0)
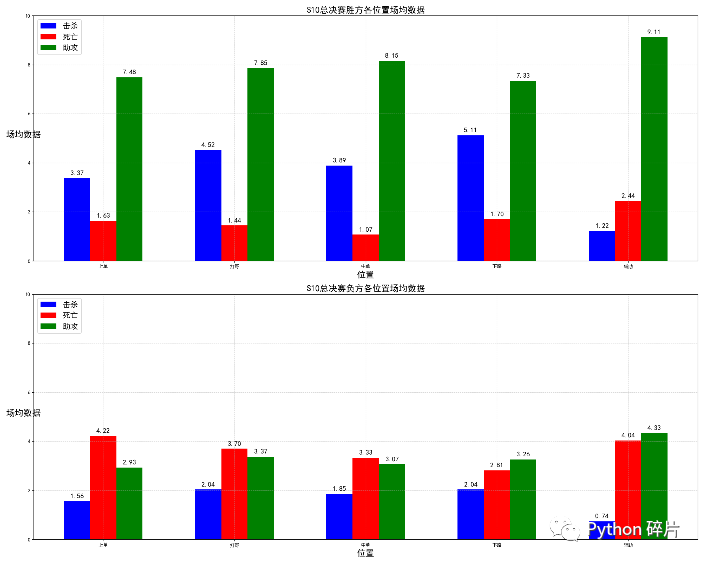
axs[0].set_title("S10總決賽勝方各位置場(chǎng)均數(shù)據(jù)", fontsize=18)
axs[1].set_title("S10總決賽負(fù)方各位置場(chǎng)均數(shù)據(jù)", fontsize=18)
plt.show()
評(píng)論
圖片
表情