編輯:好困 yaxin
【新智元導讀】算力就是生產(chǎn)力,得算力者得天下。千億級參數(shù)AI模型預示著算力大爆炸時代來臨,不如織起一張「算力網(wǎng)」試試?
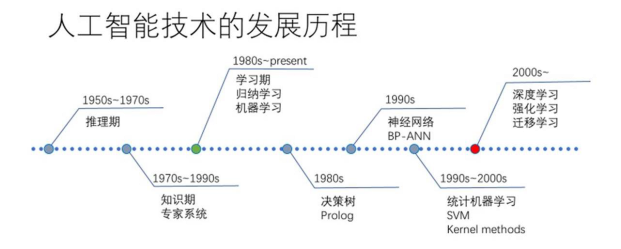
人工神經(jīng)網(wǎng)絡在上世紀80年代早已提出,卻受制于有限的計算力歷經(jīng)數(shù)年寒冬。不過,隨著新一代人工智能技術(shù)的快速發(fā)展和突破。以深度學習計算模式為主人工智能算力需求呈指數(shù)級增長。從16年的AlphaGo,到17年的AlphaZero,再到18年的AlphaFold,人工智能演化發(fā)展的速度進一步加快。而2020年發(fā)布的GPT-3更是把人工智能的水平提到了一個新的高度。
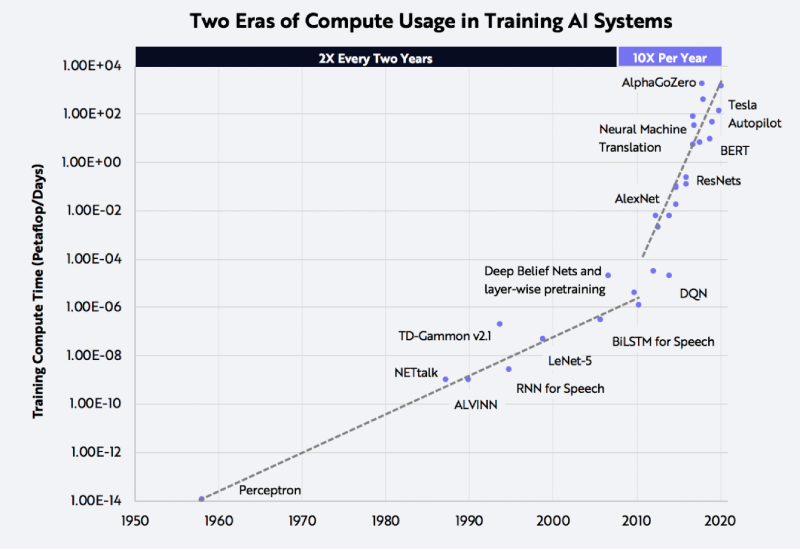
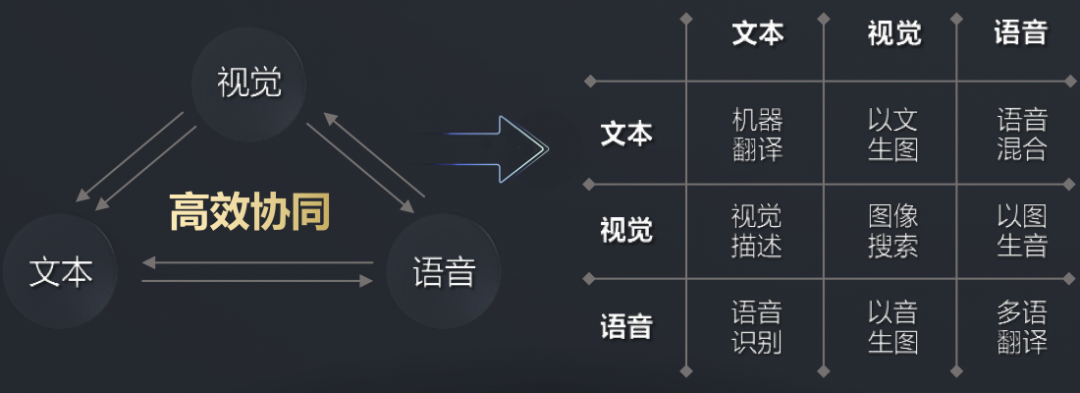
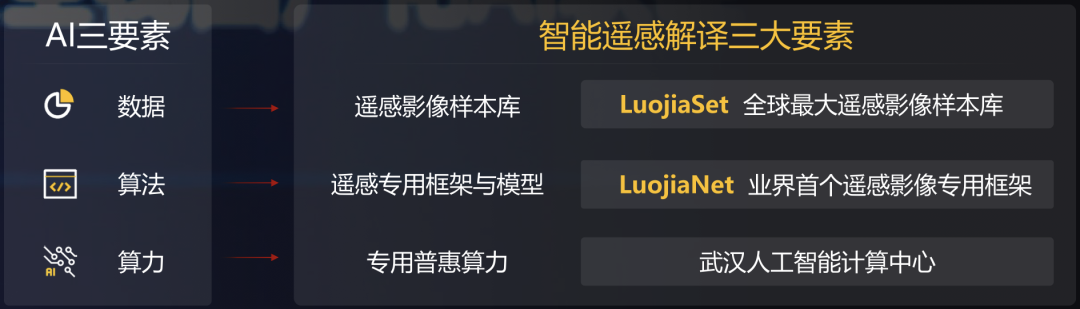
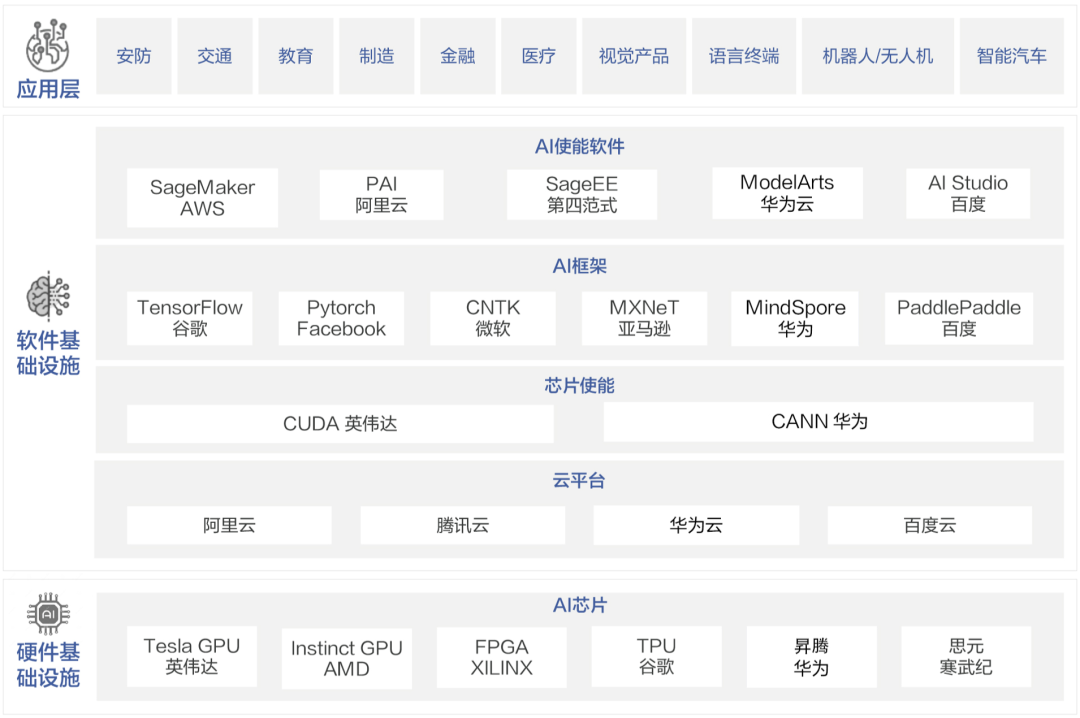
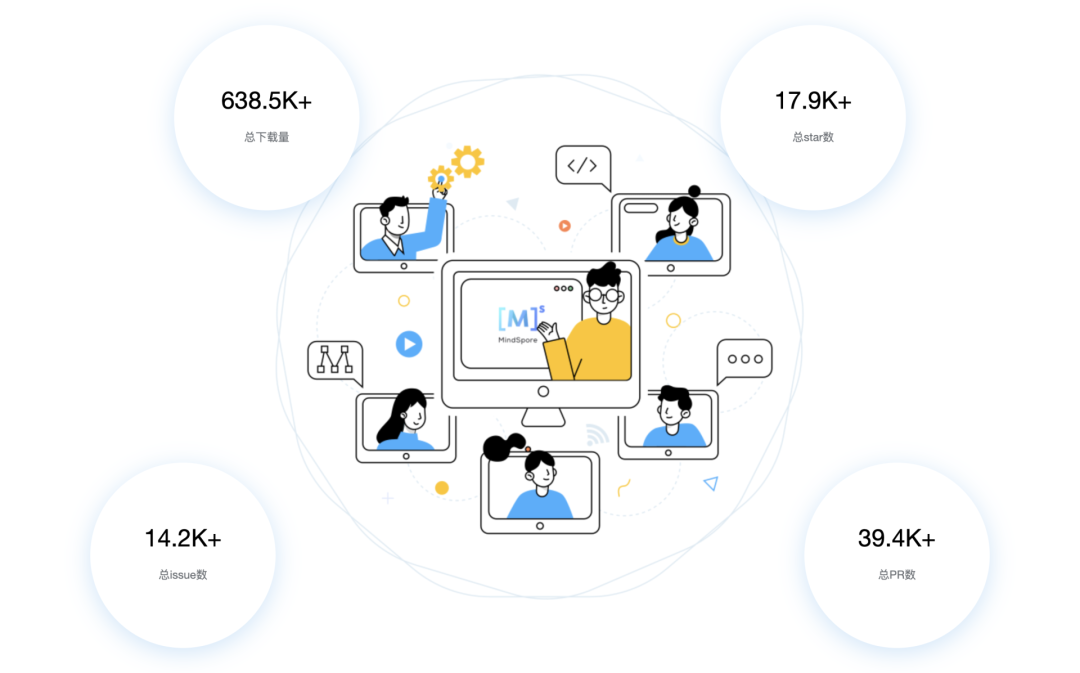
為了訓練GPT-3,微軟新建了一個搭載了1萬張顯卡,價值5億美元的算力中心。模型在訓練上則消耗了355個GPU年的算力,而成本超過460萬美元。其成果是顯而易見的,GPT-3不僅在NLP方面取得了驚人的成就。其衍生版,側(cè)重于代碼生成Codex,不僅僅是模仿以前見過的代碼,而且還會分析文檔中的字符串、注釋、函數(shù)名稱以及代碼本身,從而生成新的匹配代碼,包括之前調(diào)用的特定函數(shù)。此外,DALL·E作為另一個GPT-3的120億參數(shù)衍生版本,它能創(chuàng)建繪畫、照片、草圖等等,基本上涵蓋了所有可以用文字描述的東西。GP從11億參數(shù)的GPT到150億參數(shù)的GPT-2,再到1750億參數(shù)的GPT-3。至少在目前這個階段,大規(guī)模預訓練模型就是好使!今年1月,2000億參數(shù)的鵬程.盤古發(fā)布。通過自動混合并行模式實現(xiàn)了在2048卡算力集群上的大規(guī)模分布式訓練。在預訓練階段,模型學習了40TB中文文本數(shù)據(jù),并通過行業(yè)數(shù)據(jù)的樣本調(diào)優(yōu)提升模型在場景中的應用性能。視覺方面則包含超過30億參數(shù),兼顧了圖像判別與生成能力,從而能夠同時滿足底層圖像處理與高層語義理解需求。模型在16個下游任務中大部分指標優(yōu)于SOTA模型,其中零樣本學習任務11個任務領先,單樣本學習任務12個任務領先,小樣本學習任務13個任務領先。除了大規(guī)模,多模態(tài)也是人工智能發(fā)展的重要方向。現(xiàn)實中的網(wǎng)絡數(shù)據(jù),有90%以上是圖像與視頻,其中蘊含了更多的知識。而人類的信息獲取、環(huán)境感知、知識學習與表達,都是采用跨模態(tài)的輸入輸出方式。為此,中科院自動化所推出了全球首個三模態(tài)大模型:紫東.太初。其兼具跨模態(tài)理解和生成能力,可以同時應對文本、視覺、語音三個方向的問題。與單模態(tài)和圖文兩模態(tài)相比,其采用一個大模型就可以靈活支撐圖-文-音全場景AI應用。具有了在無監(jiān)督情況下多任務聯(lián)合學習、并快速遷移到不同領域數(shù)據(jù)的強大能力。此外,紫東.太初還獲得了MM2021視頻描述國際競賽的第一名,ICCV2021視頻理解國際競賽第一名。在圖文跨模態(tài)理解與生成方面的性能領先SOTA,而在視頻理解與描述上甚至可以稱得上世界第一的水平。與此同時,在1960到2010年間,人工智能的計算復雜度每兩年翻一番;在2010到2020年間,人工智能的計算復雜度每年猛增10倍。那么該如何面對如此之大的模型和如此之復雜的計算呢?畢竟,人工智能發(fā)展的三要素:數(shù)據(jù)、算法和算力中,無論是數(shù)據(jù)還是算法,都離不開算力的支撐。隨著人工智能模型的逐漸成熟,以及各個行業(yè)的智能化轉(zhuǎn)型,越來越多的企業(yè)都體驗到了AI帶來的便捷。AI的應用必定會涉及到算力的需求,然而讓每個企業(yè)都去搭建「人工智能計算中心」顯然是不現(xiàn)實的。因此,建造標準化且自主可控的「人工智能計算中心」的需求也就迫在眉睫了。除了需求的牽引之外,再加上政策扶持,人工智能計算中心「落地潮」也在深圳、武漢、西安等地被快速掀起。作為全國第三個人工智能計算中心,它的應用場景更為廣泛——自動駕駛、智慧醫(yī)療、智慧城市、智慧交通、智慧礦山等多種場景。西安電子科技大學人工智能研究院院長焦李成院士被聘為該人工智能計算中心專家。他并表示:未來人工智能計算中心的上線,能夠加快實現(xiàn)人工智能對經(jīng)濟社會發(fā)展的帶動和支撐作用,能夠更快形成國家新一代人工智能試驗區(qū)的西安方案。據(jù)悉,西安未來人工智能計算中心算力規(guī)模一期在300P FLOPS FP16,具備每秒30億億次半精度浮點計算的能力。相當于24小時內(nèi)能處理30億張圖像或3000萬人DNA,或300萬小時語音,或10年自動駕駛數(shù)據(jù)。此外,西安未來人工智能計算中心上線之初,便簽約了眾多項目。如西安電子科技大學遙感項目、西北工業(yè)大學語音大模型項目、陜西師范大學「MindSpore研究室」等。而早在5月底已經(jīng)投入運營的武漢人工智能計算中心,則提供了高達100P的算力,相當于每秒10億億次的計算速度。僅在試運行期間,就有聯(lián)影、興圖新科等企業(yè)發(fā)出了算力申請,而人工智能計算中心也幫助企業(yè)完成了圖像識別、語音識別等場景的應用。在科研創(chuàng)新方面,依托武漢人工智能計算中心的算力,武漢大學打造了全球首個遙感專用框架武漢.LuojiaNet。LuojiaNet針對「大幅面、多通道」遙感影像,在整圖分析和數(shù)據(jù)集極簡讀取處理等方面實現(xiàn)了重大突破。在產(chǎn)業(yè)方面,倍特威視已經(jīng)開發(fā)了170多種算法,可以應用在工地、水利、農(nóng)業(yè)等多種復雜的環(huán)境。通過將模型迭代訓練任務遷移到武漢人工智能計算中心,在算法的迭代速度上比獨立部署訓練服務器提升10倍。目前,武漢人工智能計算中心已為40家企業(yè)、4家高校與科研院所提供算力和產(chǎn)業(yè)服務,而這些僅僅是一個開始。往大了說是讓人工智能產(chǎn)業(yè)能有進一步的發(fā)展,往小了說是讓大家能夠更好地體驗到人工智能帶來的便利,這些都離不開人工智能計算中心的算力。那么再具體一點,又是什么給這些「人工智能計算中心」提供這些算力的?還是回到最初的模型上,這其中主要涉及到的有三個大類:圖像處理,決策和自然語言處理。那么在復雜模型的訓練過程中,需對上千億個浮點參數(shù)進行微調(diào)數(shù)十萬步,需要精細的浮點表達能力。因此,人工智能計算中心在「訓練」模型階段,就需要極高的計算性能和較高的精度,需要能處理海量的數(shù)據(jù),以便完成各種各樣的學習任務。而在「推理」階段,則是利用訓練好的模型,使用新數(shù)據(jù)推理出各種結(jié)論。也就是借助現(xiàn)有神經(jīng)網(wǎng)絡模型進行運算,利用新的輸入數(shù)據(jù)來一次性獲得正確結(jié)論的過程。推理相對來說對性能的要求并不高,對精度要求也要更低,在特定的場景下,對通用性要求也低,能完成特定任務即可。但因為推理的結(jié)果直接提供給終端用戶,所以更關注用戶體驗方面的優(yōu)化。這也就意味著人工智能計算中心需要具有全棧性這個特點,覆蓋到各種不同的算力需求。此外,人工智能計算中心的建設還需要形成一個生態(tài)。當實現(xiàn)了從建造到維護,再到日常運營這樣的「一站式服務」,才能讓大家把人工智能計算中心真正的用起來。然而,中國科學技術(shù)信息研究所在《人工智能計算中心發(fā)展白皮書》里指出,目前我國在人工智能計算中心的發(fā)展上遇到的一個重要的問題是:不管是作為算力的AI芯片,還是實現(xiàn)算法的模塊化封裝的AI開發(fā)框架,95%以上都被外國的公司所壟斷。而這其中的AI開發(fā)框架,在人工智能領域是相當于一個操作系統(tǒng)的存在。AI開發(fā)框架是所有算法模型的開發(fā)基礎,其中有90%的人工智能應用開發(fā)是在AI框架上進行的。因此,開發(fā)一個自主可控的AI框架在這個處處都有可能被「卡脖子」的領域就顯得尤為重要了。以MindSpore(昇思)來說,作為一個自研的AI框架,已經(jīng)在2020年3月全面開源。MindSpore(昇思)提供了一個統(tǒng)一的API,為全場景Al的模型開發(fā)、模型運行、模型部署提供端到端能力。MindSpore(昇思)可以支持數(shù)據(jù)并行、模型并行和混合并行訓練,具有很強的靈活性。而且還有「自動并行」能力,它通過在龐大的策略空間中進行高效搜索來找到一種快速的并行策略。除了支持模型跨平臺免轉(zhuǎn)換以外,MindSpore(昇思)還可以讓并行代碼數(shù)量下降80%,調(diào)優(yōu)時間降低60%。此外,它最重要的特點就是具備安全可信、高效執(zhí)行、一次開發(fā)多次部署的能力。越來越多的企業(yè)和開發(fā)者開始采用MindSpore(昇思),開源社區(qū)累計下載量超過60萬,有超過百家高校選擇昇思進行教學。人工智能計算中心具有了訓練、推理能力以及供AI開發(fā)的平臺,自然也就有了能夠向外輸出的強大算力了。那么問題又來了,建設這么一堆人工智能計算中心就夠了么?
其實就像是電網(wǎng)和天然氣網(wǎng),算力對于有些地方來說是完全不夠用的,而對于有的地方則是空有一手的「算力」卻無處使。簡單來說,興建人工智能計算中心之后會面臨三點問題:不同區(qū)域AI算力使用存在波峰波谷,各地獨立的人工智能計算中心無法實現(xiàn)跨域的動態(tài)調(diào)配;
全國人工智能發(fā)展不均衡,不同區(qū)域有各自優(yōu)勢,各地獨立的人工智能計算中心無法實現(xiàn)跨區(qū)域的聯(lián)合科研和應用創(chuàng)新、資源互補;
各地獨立的人工智能計算中心產(chǎn)生的AI模型、數(shù)據(jù),難以實現(xiàn)全國范圍內(nèi)順暢流動、交易,以產(chǎn)生更大的價值。
那么,既然有「西氣東輸」和「西電東送」的成功經(jīng)驗,為何不把「算力」也連點成線,編織成一個人工智能算力網(wǎng)絡呢?
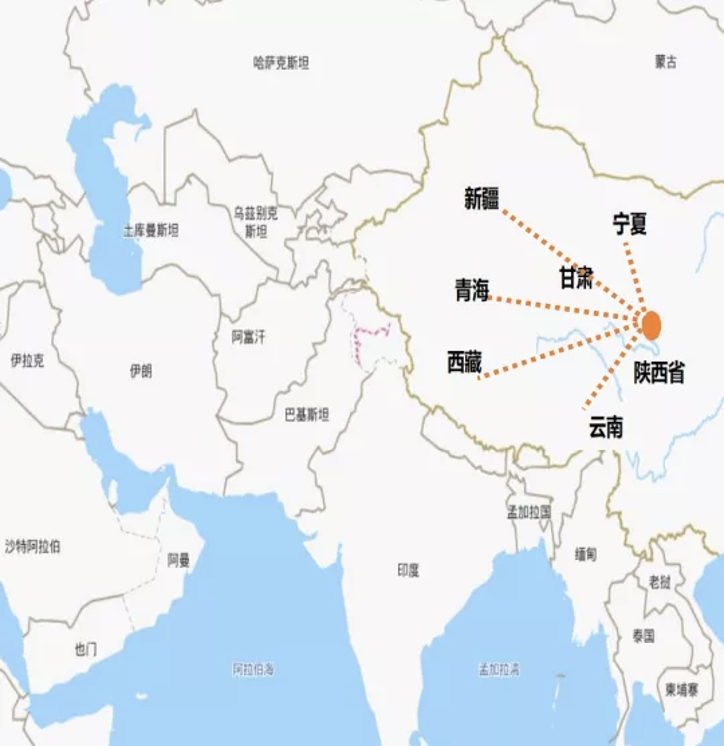
人工智能算力網(wǎng)絡可以將各地分布的人工智能計算中心節(jié)點連接起來,動態(tài)實時感知算力資源狀態(tài)。進而實現(xiàn)統(tǒng)籌分配和調(diào)度計算任務,構(gòu)成全國范圍內(nèi)感知、分配、調(diào)度人工智能算力的網(wǎng)絡,在此基礎上匯聚和共享算力、數(shù)據(jù)、算法資源。例如,在西安建設的未來人工智能計算中心可以輻射寧夏、甘肅、新疆、青海、云南五省,從而推動西部整體的人工智能產(chǎn)業(yè)發(fā)展。那么具體來說,構(gòu)建人工智能算力網(wǎng)絡最終要實現(xiàn)的是「一網(wǎng)絡,三匯聚」。網(wǎng)絡:將人工智能計算中心的節(jié)點通過專線連接起來形成人工智能算力網(wǎng)絡。三匯聚分別是算力匯聚、數(shù)據(jù)匯聚和生態(tài)匯聚。算力匯聚:連接不同節(jié)點的高速網(wǎng)絡,實現(xiàn)跨節(jié)點之間的算力合理調(diào)度,資源彈性分配,從而提升各個人工智能計算中心的利用率,實現(xiàn)對于整體能耗的節(jié)省,后續(xù)可支持跨節(jié)點分布學習,為大模型的研究提供超級算力。數(shù)據(jù)匯聚:政府和企業(yè)共同推進人工智能領域的公共數(shù)據(jù)開放,基于人工智能計算中心匯聚高質(zhì)量的開源開放的人工智能數(shù)據(jù)集,促進算法開發(fā)和行業(yè)落地。生態(tài)匯聚:采用節(jié)點互聯(lián)標準、應用接口標準,實現(xiàn)網(wǎng)絡內(nèi)大模型能力開放與應用創(chuàng)新成果共享,強化跨區(qū)域科研和產(chǎn)業(yè)協(xié)作。各地算力中心就像大腦中數(shù)億個突觸,人工智能算力網(wǎng)絡正如神經(jīng)網(wǎng)絡。如此看來,算力網(wǎng)絡的重要意義之一便是通過匯聚大數(shù)據(jù)+大算力,使能了大模型和重大科研創(chuàng)新,孵化新應用。進而實現(xiàn)算力網(wǎng)絡化,降低算力成本,提升計算能效。最終打造一張覆蓋全國的算力網(wǎng)絡,實現(xiàn)算力匯聚、生態(tài)匯聚、數(shù)據(jù)匯聚,進而達到各產(chǎn)業(yè)共融共生。
參考資料:
http://gov.cnwest.com/jczw/a/2021/09/09/19944392.html
https://mp.weixin.qq.com/s/6oX0FdnIeyWGX5iXlmauew
https://mp.weixin.qq.com/s/M2oN3-MdaffnpiygrkBg3g
https://mp.weixin.qq.com/s/VQnPpyFprfFeYCBm_wE0wg
https://www.bilibili.com/read/cv12369433
https://www.istic.ac.cn/isticcms/html/1/istic-ai/result4.html
https://www.mindspore.cn/