
一文了解預(yù)訓(xùn)練語言模型!
??關(guān)注“博文視點(diǎn)Broadview”,獲取更多書訊

近年來,在深度學(xué)習(xí)和大數(shù)據(jù)的支撐下,自然語言處理技術(shù)迅猛發(fā)展。
而預(yù)訓(xùn)練語言模型把自然語言處理帶入了一個(gè)新的階段,也得到了工業(yè)界的廣泛關(guān)注。
通過大數(shù)據(jù)預(yù)訓(xùn)練加小數(shù)據(jù)微調(diào),自然語言處理任務(wù)的解決,無須再依賴大量的人工調(diào)參。
借助預(yù)訓(xùn)練語言模型,自然語言處理模型進(jìn)入了可以大規(guī)模復(fù)制的工業(yè)化時(shí)代。
那到底什么是預(yù)訓(xùn)練?為什么需要預(yù)訓(xùn)練呢?
以下內(nèi)容節(jié)選自《預(yù)訓(xùn)練語言模型》一書!
邦學(xué)習(xí)實(shí)戰(zhàn).jpg")
--正文--
預(yù)訓(xùn)練屬于遷移學(xué)習(xí)的范疇。
現(xiàn)有的神經(jīng)網(wǎng)絡(luò)在進(jìn)行訓(xùn)練時(shí),一般基于后向傳播(Back Propagation,BP)算法,先對(duì)網(wǎng)絡(luò)中的參數(shù)進(jìn)行隨機(jī)初始化,再利用隨機(jī)梯度下降(Stochastic Gradient Descent,SGD)等優(yōu)化算法不斷優(yōu)化模型參數(shù)。
而預(yù)訓(xùn)練的思想是,模型參數(shù)不再是隨機(jī)初始化的,而是通過一些任務(wù)進(jìn)行預(yù)先訓(xùn)練,得到一套模型參數(shù),然后用這套參數(shù)對(duì)模型進(jìn)行初始化,再進(jìn)行訓(xùn)練。
在正式探討自然語言處理的預(yù)訓(xùn)練之前,回顧一下計(jì)算機(jī)視覺領(lǐng)域的預(yù)訓(xùn)練過程。
在圖片分類任務(wù)中,常用的深度學(xué)習(xí)模型是卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)。對(duì)于由多個(gè)層級(jí)結(jié)構(gòu)組成的CNN來說,不同層學(xué)到的圖像特征是不一樣的,越淺的層學(xué)到的特征越通用,越深的層學(xué)到的特征和具體任務(wù)的關(guān)聯(lián)性越強(qiáng)。
在圖1中[6],對(duì)基于人臉(Faces)、汽車(Cars)、大象(Elephants)和椅子(Chairs)的任務(wù)而言,最淺層的通用特征“線條”都是一樣的。
因此,在大規(guī)模圖片數(shù)據(jù)上預(yù)先獲取“通用特征”,會(huì)對(duì)下游任務(wù)有非常大的幫助。

圖1 圖像預(yù)訓(xùn)練示例
再舉個(gè)簡單的例子,假設(shè)一個(gè)《怪物獵人:世界》的游戲玩家想給游戲中的怪物(如飛雷龍、浮空龍、風(fēng)漂龍、骨錘龍等)做一個(gè)多分類系統(tǒng),而有標(biāo)注的數(shù)據(jù)只有游戲中的若干圖片,重新訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)模型顯然不太可能。
幸運(yùn)的是,現(xiàn)有的大規(guī)模圖片數(shù)據(jù)庫ImageNet 中一共有20000多類標(biāo)注好的數(shù)據(jù)集,包含超過1400 萬張圖片。
通過ImageNet 訓(xùn)練出來的CNN 網(wǎng)絡(luò)參數(shù),可以遷移至怪物獵人的訓(xùn)練任務(wù)中。
在比較淺層的CNN網(wǎng)絡(luò)初始化時(shí),可以使用已經(jīng)訓(xùn)練好的參數(shù),而在模型的高層,其參數(shù)可以隨機(jī)初始化。
在訓(xùn)練怪物獵人的特定任務(wù)時(shí),既可以采用凍結(jié)(Frozen)參數(shù)的方式,也就是淺層參數(shù)一直保持不變;也可以采用微調(diào)的方式,也就是淺層參數(shù)仍然隨著任務(wù)的訓(xùn)練不斷發(fā)生改變,從而更加適應(yīng)怪物的分類。
將圖片轉(zhuǎn)換為計(jì)算機(jī)可以處理的表示形式(如像素點(diǎn)的RGB 值),就可以輸入至神經(jīng)網(wǎng)絡(luò)進(jìn)行后續(xù)處理。
對(duì)自然語言來說,如何進(jìn)行表示是首先要考慮的問題。
語言是離散的符號(hào),自然語言的表示學(xué)習(xí),就是將人類的語言表示成更易于計(jì)算機(jī)理解的方式。
尤其是在深度神經(jīng)網(wǎng)絡(luò)技術(shù)興起之后,如何在網(wǎng)絡(luò)的輸入層使用更好的自然語言表示,成了值得關(guān)注的問題。
舉例來說,每個(gè)人的名字就是我們作為自然人的一個(gè)“表示”,名字可以是若干個(gè)漢字,也可以是英文或法文單詞。
當(dāng)然,也可以通過一些方法表示成由0 和1 組成的字符串,或者轉(zhuǎn)換為一定長度的向量,讓計(jì)算機(jī)更容易處理。
自然語言的表示有很多方式,圖2 給出了自然語言表示學(xué)習(xí)的發(fā)展路徑。
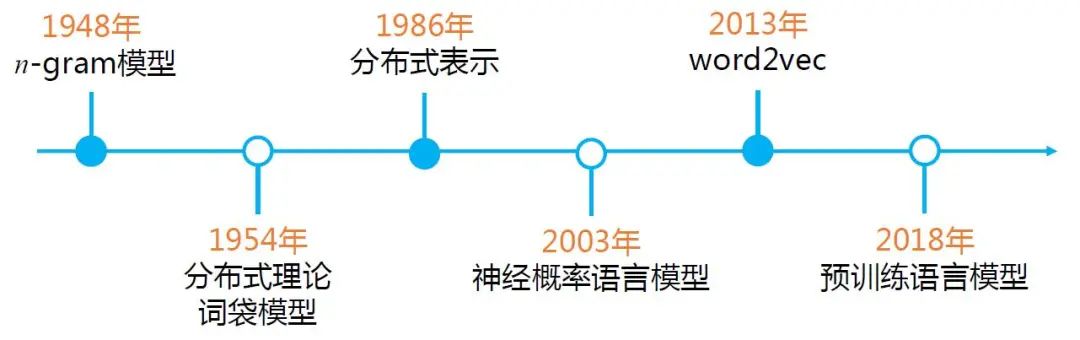
圖2 自然語言表示學(xué)習(xí)的發(fā)展路徑
最早期的n-gram 模型,是基于統(tǒng)計(jì)的語言模型,通過前n個(gè)詞來預(yù)測第n+1個(gè)詞。
分布式理論(Distributional Hypothesis)在20世紀(jì)50年代被提出,這也是近10年,從word2vec到BERT 等一系列預(yù)訓(xùn)練語言模型的自然語言表示的基礎(chǔ)思想。
早期的詞袋模型,雖然能夠方便計(jì)算機(jī)快速處理,卻無法衡量單詞間的語義相似度。
到了1986 年,分布式表示(Distributed Representation)被提出。雖然分布式理論和分布式表示同樣都有“分布式”這個(gè)詞,但其英文表述是不一樣的,含義也不盡相同。
分布式理論的核心思想是:上下文相似的詞,其語義也相似,是一種統(tǒng)計(jì)意義上的分布;而在分布式表示中,并沒有統(tǒng)計(jì)意義上的分布。
分布式表示是指文本的一種表示方式。相比于獨(dú)熱表示,分布式表示將文本在更低的維度進(jìn)行表示。
隨著word2vec和GloVe等基于分布式表示的方法被提出,判斷語義的相似度成為可能。圖3給出了GloVe 詞向量的可視化結(jié)果。
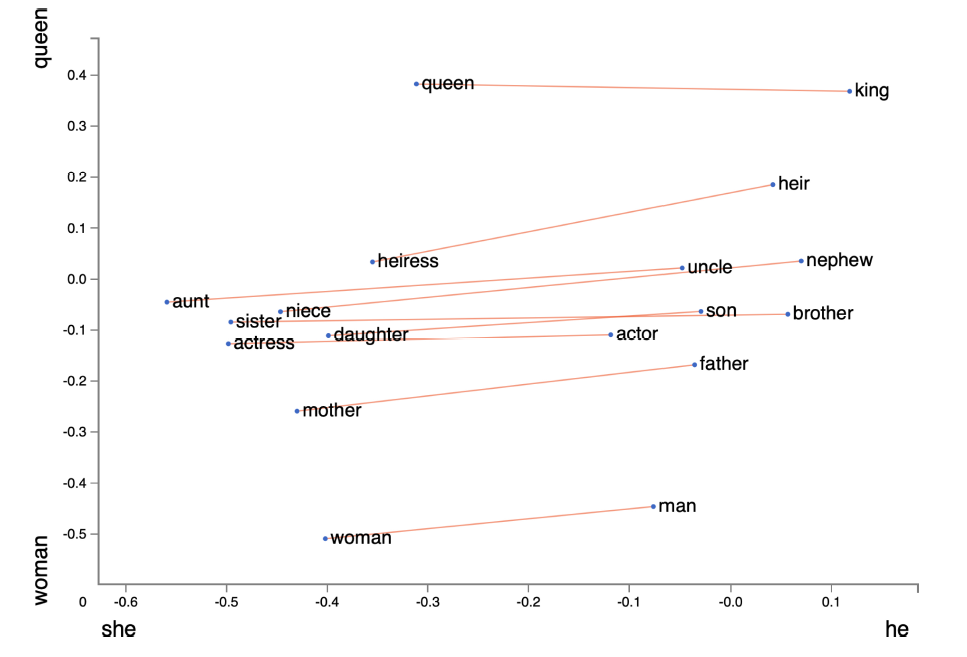
圖3 Glove 詞向量的可視化結(jié)果
2013 年之后,基于大規(guī)模的文本數(shù)據(jù)訓(xùn)練得到的分布式表示,逐漸成了自然語言表示的主流方法。
在這種方式下,每個(gè)單詞都有了一個(gè)固定的詞向量表示,語義相近的單詞,其向量也是相似的。
從圖3中可以看出,queen 和king,以及woman 和man 就是以“性別”為基準(zhǔn)來對(duì)應(yīng)的單詞。
有了自然語言的表示,就可以將表示后的詞向量送入神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練。這就是第一代預(yù)訓(xùn)練語言模型。
一些讀者可能已經(jīng)注意到,word2vec 的提出時(shí)間是2013 年,那么為何在2018 年ELMo出現(xiàn)之后,預(yù)訓(xùn)練語言模型才有了突飛猛進(jìn)的發(fā)展呢?
最重要的原因就是,之前的詞向量表示無法很好地解決一詞多義的問題。
我們都知道,多義詞是自然語言中的常見現(xiàn)象,也體現(xiàn)了語言的靈活性和高效性。
例如,單詞play 可以表示玩游戲,可以表示播放,可以表示做某項(xiàng)運(yùn)動(dòng),還可以表示演奏某個(gè)樂器。但在以word2vec 為代表的第一代預(yù)訓(xùn)練語言模型中,一個(gè)單詞的詞向量是固定不變的,也就是說,在對(duì)單詞play 進(jìn)行向量表示的過程中,不會(huì)區(qū)分單詞的不同含義,這就導(dǎo)致無法區(qū)分多義詞的不同語義。
美國語言學(xué)家Zellig S. Harris 在1954 年的一篇文章[10] 中提到:“在相近上下文中出現(xiàn)的單詞是相似的”(words are similar if they appear in similar contexts)。
英國語言學(xué)家John Rupert Firth 在1957 年的A synopsis of linguistic theory 中提到:“你可以通過單詞的上下文知道其含義”(You shall know a word by the company it keeps)。
EMLo 論文的原始標(biāo)題是Deep contextualized word representation,從“contextualized”一詞可以看出,ELMo 考慮了上下文的詞向量表示方法,以雙向LSTM 作為特征提取器,同時(shí)考慮了上下文的信息,從而較好地解決了多義詞的表示問題,后續(xù)章節(jié)會(huì)詳細(xì)介紹。
ELMo 開啟了第二代預(yù)訓(xùn)練語言模型的時(shí)代,即“預(yù)訓(xùn)練+ 微調(diào)”的范式。
自ELMo 后,Transformer[11] 作為更強(qiáng)大的特征提取器,被應(yīng)用到后續(xù)的各種預(yù)訓(xùn)練語言模型中(如GPT、BERT 等),不斷刷新自然語言處理領(lǐng)域任務(wù)的SOTA(State Of The Art,當(dāng)前最優(yōu)結(jié)果)表現(xiàn)。
Transformer 是由谷歌在2017 年提出的,其創(chuàng)新性地使用了Self-Attention(自注意力),更善于捕捉長距離的特征,同時(shí)其并行能力也非常強(qiáng)大,逐步取代了RNN,成了最主要的自然語言處理特征提取工具。
圖4 給出了預(yù)訓(xùn)練語言模型的發(fā)展史。

圖4 預(yù)訓(xùn)練語言模型的發(fā)展史
可以看到,2013 年,word2vec 開啟了自然語言預(yù)訓(xùn)練的序章。
隨后,Attention的出現(xiàn)使得模型可以關(guān)注更重要的信息,之后的幾年,基于上下文的動(dòng)態(tài)詞向量表示ELMo,以及使用Self-Attention 機(jī)制的特征提取器Transformer的提出,將預(yù)訓(xùn)練語言模型的效果提升到了新的高度。
隨后,BERT、RoBERTa、XLNet、T5、ALBERT、GPT-3 等模型,從自然語言理解及自然語言生成等角度,不斷刷新自然語言處理領(lǐng)域任務(wù)的SOTA 表現(xiàn)。
《預(yù)訓(xùn)練語言模型》一書的后面章節(jié)會(huì)詳細(xì)介紹典型的預(yù)訓(xùn)練語言模型。這里,我們簡單區(qū)分自回歸(Autoregressive)和自編碼(Autoencoder)兩種不同的模型。
簡單來講,自回歸模型可以類比為早期的統(tǒng)計(jì)語言模型(Statistical Language Model),也就是根據(jù)上文預(yù)測下一個(gè)單詞,或者根據(jù)下文預(yù)測前面的單詞。例如,ELMo 是將兩個(gè)方向(從左至右和從右至左)的自回歸模型進(jìn)行了拼接,實(shí)現(xiàn)了雙向語言模型,但本質(zhì)上仍然屬于自回歸模型。
自編碼模型(如BERT),通常被稱為是降噪自編碼(Denosing Autoencoder)模型,可以在輸入中隨機(jī)掩蓋一個(gè)單詞(相當(dāng)于加入噪聲),在預(yù)訓(xùn)練過程中,根據(jù)上下文預(yù)測被掩碼詞,因此可以認(rèn)為是一個(gè)降噪(denosing)的過程。
這種模型的好處是可以同時(shí)利用被預(yù)測單詞的上下文信息,劣勢是在下游的微調(diào)階段不會(huì)出現(xiàn)掩碼詞,因此[MASK] 標(biāo)記會(huì)導(dǎo)致預(yù)訓(xùn)練和微調(diào)階段不一致的問題。
BERT 的應(yīng)對(duì)策略是針對(duì)掩碼詞,以80% 的概率對(duì)這個(gè)單詞進(jìn)行掩碼操作,10% 的概率使用一個(gè)隨機(jī)單詞,而10% 的概率使用原始單詞(即不進(jìn)行任何操作),這樣就可以增強(qiáng)對(duì)上下文的依賴,進(jìn)而提升糾錯(cuò)能力。
XLNet 改進(jìn)了預(yù)訓(xùn)練階段的掩碼模式,使用了自回歸的模式,因此XLNet 被看作廣義的自回歸模型。
國際計(jì)算語言學(xué)協(xié)會(huì)(The Association for Computational Linguistics)主席、微軟亞洲研究院前副院長周明曾給出了一個(gè)關(guān)于自回歸和自編碼模型的示例,如圖5所示。

圖5 自回歸模型和自編碼模型的示例
自回歸模型,就是根據(jù)句子中前面的單詞,預(yù)測下一個(gè)單詞。
例如,通過“LM is a typical task in natural language ____”預(yù)測單詞“processing”;而自編碼模型,則是通過覆蓋句中的單詞,或者對(duì)句子做結(jié)構(gòu)調(diào)整,讓模型復(fù)原單詞和詞序,從而調(diào)節(jié)網(wǎng)絡(luò)參數(shù)。
在圖5 (a) 所示的單詞級(jí)別的例子中,句子中的“natural”被覆蓋,而在圖5 (b) 所示的句子級(jí)別的例子中,不僅有單詞的覆蓋,還有詞序的改變。
可以看出,ELMo、GPT 系列和XLNet 屬于自回歸模型,而BERT、ERINE、RoBERTa 等屬于自編碼模型。
前文提到,在利用CNN 進(jìn)行圖像的預(yù)訓(xùn)練時(shí),淺層特征更加通用,深層特征更加具體。通過對(duì)BERT 的觀察,研究人員發(fā)現(xiàn)預(yù)訓(xùn)練語言模型也有相同的表現(xiàn),隨著模型由淺至深,特征也更具體。
圖6 給出了針對(duì)BERTLARGE提取語義和語法信息的結(jié)果,其中,語法信息(Syntactic Information),如詞性(Part-Of-Speech,POS)、成分(Constituents)、依存(Dependencies)更早出現(xiàn)在BERTLARGE 的淺層,而語義信息(Semantic Information),如共指消解(Coreference)、語義原型角色(Sementic Proto-Roles,SPR)等則出現(xiàn)在BERTLARGE 的深層。
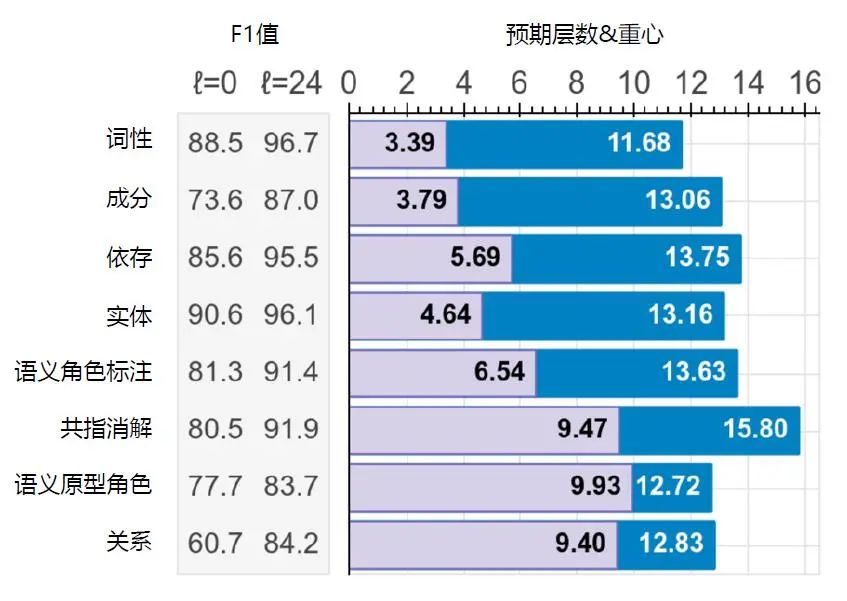
圖6 BERTLARGE 提取語義和語法信息的結(jié)果
目前,預(yù)訓(xùn)練語言模型的通用范式是:
(1)基于大規(guī)模文本,預(yù)訓(xùn)練得出通用的語言表示。
(2)通過微調(diào)的方式,將學(xué)習(xí)到的知識(shí)傳遞到不同的下游任務(wù)中。
在微調(diào)的過程中,每種預(yù)訓(xùn)練語言模型的用法不盡相同,《預(yù)訓(xùn)練語言模型》一書的后面章節(jié)將對(duì)典型的模型進(jìn)行詳細(xì)闡述。
這里以GPT為例,簡單介紹在預(yù)訓(xùn)練之后,在下游,不同的自然語言處理任務(wù)的具體用法如圖7所示。
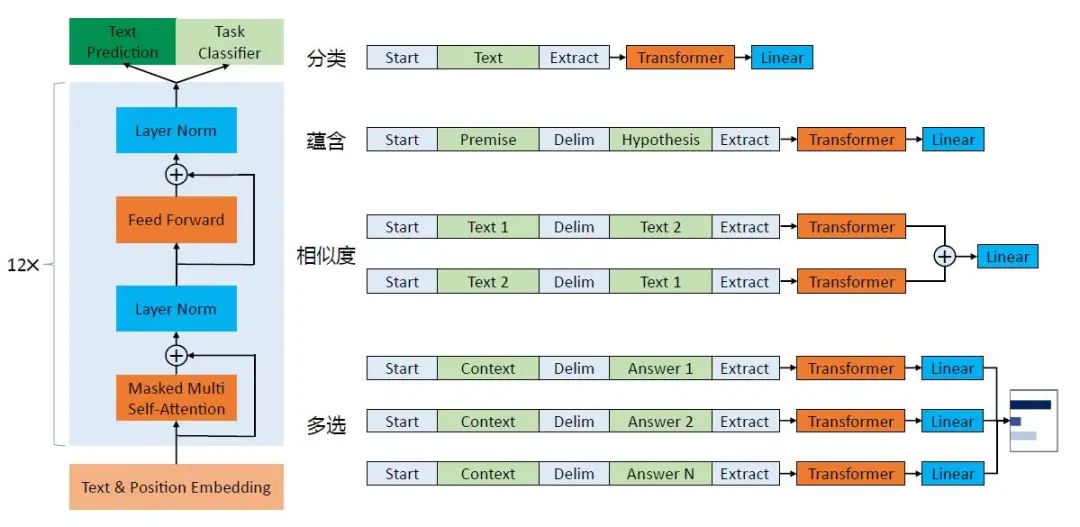
圖7 GPT 架構(gòu)圖及下游任務(wù)
圖7的左邊,是基于Transformer 的GPT 的基本框架,而圖7的右邊則展示了如何將不同的自然語言處理任務(wù)調(diào)整至適應(yīng)GPT 框架的形式。
以分類任務(wù)為例,在一段文本的開頭和結(jié)尾分別加上“Start”和“Extract”標(biāo)示符對(duì)其進(jìn)行改造,然后使用Transformer 進(jìn)行處理,最后通過線性層(Linear)完成監(jiān)督學(xué)習(xí)任務(wù),并輸出分類結(jié)果。
類似地,對(duì)于多選(Multiple Choice)任務(wù),需要根據(jù)上下文(Context)選擇正確答案(Answer)。
具體來說,如圖7所示,將答案“Answer”,與其上下文“Context”通過添加首尾標(biāo)示符及中間分隔符的方式進(jìn)行改造,對(duì)其他答案進(jìn)行相同的操作,然后分別經(jīng)過Transformer,再經(jīng)過線性層,得到每一個(gè)選項(xiàng)的可能性概率值。
由于不同的預(yù)訓(xùn)練語言模型的結(jié)構(gòu)不同、優(yōu)勢不同,在實(shí)際應(yīng)用中,需要根據(jù)具體的任務(wù)選擇不同的模型。例如,BERT 系列模型更適用于理解任務(wù),而GPT 系列模型更適用于生成任務(wù)。
預(yù)訓(xùn)練語言模型在近兩年得到了蓬勃發(fā)展,復(fù)旦大學(xué)的邱錫鵬教授在Pretrained models for natural language processing: A survey這篇綜述論文中整理了一張預(yù)訓(xùn)練語言模型分類體系圖,圖8為筆者翻譯后的版本。
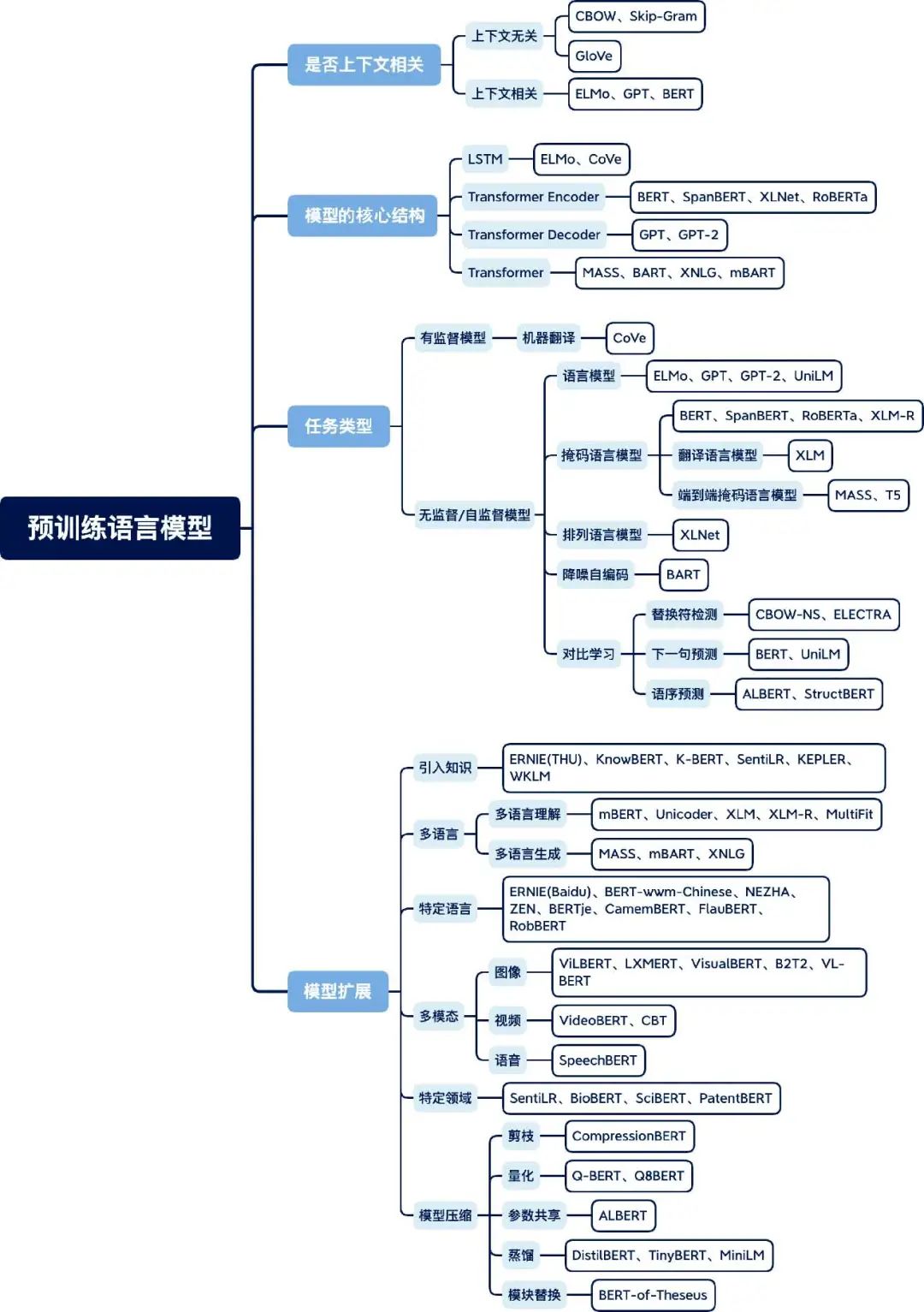
圖8 預(yù)訓(xùn)練語言模型分類體系圖
依據(jù)四種不同的分類標(biāo)準(zhǔn),對(duì)主流預(yù)訓(xùn)練語言模型進(jìn)行了分類整理。
第一個(gè)標(biāo)準(zhǔn)是語言表示是否上下文相關(guān)。正如前文提到的,早期的預(yù)訓(xùn)練語言模型(如word2vec、GloVe)都是上下文無關(guān)的,而ELMo 之后的大多數(shù)預(yù)訓(xùn)練語言模型都是上下文相關(guān)的。
第二個(gè)標(biāo)準(zhǔn)是模型的核心結(jié)構(gòu)。例如,ELMo 使用的是雙向LSTM 結(jié)構(gòu),而BERT 的核心結(jié)構(gòu)是Transformer Encoder,GPT 的核心結(jié)構(gòu)是Transformer Decoder。
第三個(gè)標(biāo)準(zhǔn)是任務(wù)類型,可以分為有監(jiān)督模型和無監(jiān)督/自監(jiān)督模型兩類。例如,機(jī)器翻譯模型(訓(xùn)練數(shù)據(jù)通常是句對(duì))屬于有監(jiān)督模型,如CoVe等,而大多數(shù)預(yù)訓(xùn)練語言模型都屬于無監(jiān)督/自監(jiān)督模型,如ELMo、BERT等。
第四個(gè)標(biāo)準(zhǔn)是模型擴(kuò)展。隨著預(yù)訓(xùn)練語言模型的發(fā)展,出現(xiàn)了不同的擴(kuò)展方向,如模型結(jié)構(gòu)的擴(kuò)展、領(lǐng)域的擴(kuò)展、任務(wù)的擴(kuò)展和模態(tài)的擴(kuò)展等。
每個(gè)模型的細(xì)節(jié),在《預(yù)訓(xùn)練語言模型》一書的后面章節(jié)會(huì)有更詳細(xì)的介紹。

預(yù)訓(xùn)練語言模型為自然語言處理開啟了新的篇章,模型結(jié)構(gòu)和訓(xùn)練方法不斷創(chuàng)新,從單語言到多語言,再到多模態(tài),幾乎支持了所有自然語言處理任務(wù),并可擴(kuò)展到視覺、語音等領(lǐng)域,大大降低了自然語言處理研究和應(yīng)用的門檻。
周明曾提到:“大數(shù)據(jù)預(yù)訓(xùn)練+ 小數(shù)據(jù)微調(diào),標(biāo)志著自然語言處理進(jìn)入了大工業(yè)化的時(shí)代。”但GPT-3 的“大力出奇跡”(有1750 億參數(shù)量)是否真正標(biāo)志著人工智能從感知智能到認(rèn)知智能的跨越?預(yù)訓(xùn)練語言模型的缺陷在哪里?未來的發(fā)展趨勢如何?《預(yù)訓(xùn)練語言模型》一書的第8章對(duì)這些問題進(jìn)行了探討,感興趣的同學(xué)可以閱讀《預(yù)訓(xùn)練語言模型》一書!
▼
參考文獻(xiàn):
[1] MIKOLOV T, CHEN K, CORRADO G S, et al. Efficient estimation of word representations in vector space[C]//ICLR. 2013.
[2] PENNINGTON J, SOCHER R, MANNING C D. Glove: Global vectors for word representation[C]//EMNLP. 2014.
[3] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]//NAACL-HLT. 2018.
[4] TENNEY I, DAS D, PAVLICK E. Bert rediscovers the classical nlp pipeline [C]//ACL. 2019.
[5] RADFORD A. Improving language understanding by generative pretraining[C], 2018.
[6] QIU X, SUN T, XU Y, et al. Pre-trained models for natural language processing:A survey[J]. ArXiv, 2020, abs/2003.08271.

▊《預(yù)訓(xùn)練語言模型》
邵浩 劉一烽 編著
梳理預(yù)訓(xùn)練語言模型的發(fā)展歷史、基本概念
剖析具有代表性的預(yù)訓(xùn)練語言模型的實(shí)現(xiàn)細(xì)節(jié),配代碼
預(yù)訓(xùn)練語言模型的評(píng)測、應(yīng)用及趨勢分析
(京東限時(shí)活動(dòng),快快掃碼搶購吧!)
如果喜歡本文 歡迎 在看丨留言丨分享至朋友圈 三連 熱文推薦
▼點(diǎn)擊閱讀原文,獲取本書詳情~