
DiffusionDet: Diffusion Model for Object Detection
1. 論文信息
標(biāo)題:DiffusionDet: Diffusion Model for Object Detection
作者:Shoufa Chen, Peize Sun, Yibing Song, Ping Luo
原文鏈接:https://arxiv.org/abs/2211.09788
代碼鏈接:https://github.com/ShoufaChen/DiffusionDet
2. 引言
擴(kuò)散模型(diffusion models)在利用深度網(wǎng)絡(luò)的生成模型中,取得了非常不錯的成績,達(dá)到了SOTA的水準(zhǔn)。而且擴(kuò)散模型在圖片生成任務(wù)中超越了原SOTA:GAN,并且在諸多應(yīng)用領(lǐng)域都有出色的表現(xiàn)。而擴(kuò)散模型在生成模型中的成功經(jīng)驗不禁讓人好奇,其能否在計算機(jī)視覺的判別模型中,同樣發(fā)揮出較好的效果。最近來自騰訊和HKU的一份工作給出了肯定的答案。
首先簡單回顧下最近目標(biāo)檢測(object detection)的趨勢。目標(biāo)檢測的目的是在一個圖像中,預(yù)測一組bounding box和相關(guān)的class label。作為一項基本的視覺識別任務(wù),它已經(jīng)成為許多相關(guān)識別場景的基石。現(xiàn)有的目標(biāo)檢測方法隨著候選的bounding box的選取方式的發(fā)展而不斷發(fā)展,即從經(jīng)驗的先驗知識到設(shè)立參數(shù)來進(jìn)行回歸目標(biāo)的學(xué)習(xí)。在CNN時代,大多數(shù)檢測器通過在經(jīng)驗設(shè)計的候選對象上定義回歸和分類來解決檢測任務(wù)。最近,DETR提出了可學(xué)習(xí)對象query,消除手工設(shè)計的組件,在我的觀點里,這是第一次成功建立端到端目標(biāo)檢測的方法。
本文就提出了一個新的疑問:: is there a simpler approach that does not even need the surrogate of learnable queries? 就是能不能有一種簡單的方法來完成科學(xué)系的查詢,同時也不需要生成surrogate。基于diffusion的相關(guān)知識,論文通過設(shè)計一個新穎的框架來回答這個問題,該框架可以直接從一組隨機(jī)框中檢測object。我們希望從純隨機(jī)的box中(如純粹的高斯噪聲)開始,逐步refine這些boxes的位置和大小,直到它們完美地覆蓋目標(biāo)對象。這種從噪聲到盒子的方法不需要啟發(fā)式的對象先驗,也不需要可學(xué)習(xí)的查詢,進(jìn)一步簡化了對象候選。從完全隨機(jī)的noise到盒范式的原理類似于去噪擴(kuò)散模型中的噪聲到圖像過程[15,35,79],這是一類基于似然的模型,通過學(xué)習(xí)到的去噪模型逐步去除圖像中的噪聲來生成圖像。
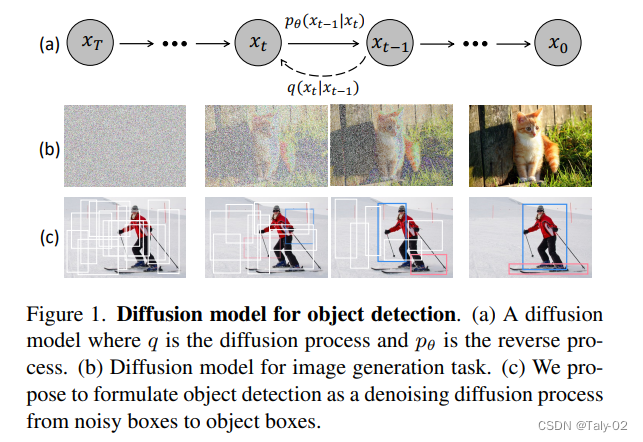
從下圖可以看出來,由于采用了diffusion的結(jié)構(gòu),這個模型沒有利用任何anchor選取上的先驗,也不是像完全的可學(xué)習(xí)參數(shù)一樣,需要進(jìn)行相應(yīng)的初始化,再消耗較長的時間來進(jìn)行調(diào)整。
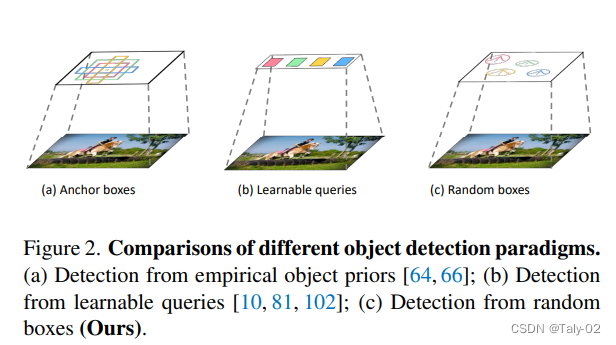
其實論文提出的模型非常簡單但經(jīng)典,就是目標(biāo)檢測中常用的backbone+neck。論文主要聚焦于訓(xùn)練策略與推理策略上的調(diào)整和改進(jìn),其實可以視為在給定現(xiàn)有檢測網(wǎng)絡(luò)的前提下所探索的新的網(wǎng)絡(luò)優(yōu)化方式。
3. 方法
首先論文回顧了目標(biāo)檢測和diffusion model的基礎(chǔ)知識。目標(biāo)檢測的內(nèi)容應(yīng)該大家都比較熟悉,就不再回顧了。而diffusion model的形式如下:

擴(kuò)散模型是一類受非平衡熱力學(xué)啟發(fā)的基于likelihood的模型。這些模型通過逐漸向樣本數(shù)據(jù)添加噪聲,定義了馬爾可夫擴(kuò)散前向過程鏈。
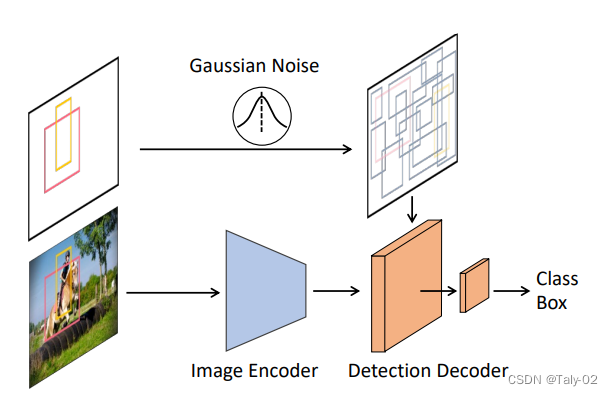
如上圖,論文的結(jié)構(gòu)其實非常的簡單。首先利用image的encoder從輸入image中提取相應(yīng)的特征。檢測的decoder則是以noise的boxes為輸入,來預(yù)測類別的label和目標(biāo)檢測框的坐標(biāo)。在訓(xùn)練過程中,將高斯噪聲添加到ground-truth的noise box中,來構(gòu)造相應(yīng)的結(jié)構(gòu)。在inference中,噪聲的框則從高斯噪聲采樣中得到。
其實結(jié)構(gòu)很簡單,關(guān)鍵是訓(xùn)練和測試的算法步驟,這篇論文的寫作同樣值得學(xué)習(xí),組織的非常好,來看偽代碼:
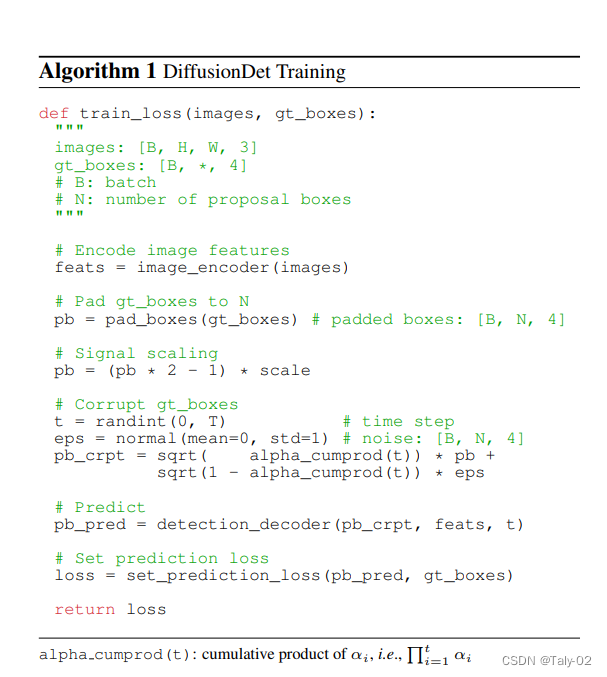

在訓(xùn)練階段:
Ground truth boxes padding. ROI的數(shù)量在不同圖像中也不完全一致。因此,本文首先將一些額外的框填充到原始真值框中,使所有框相加為固定數(shù)量。
Box corruption. 我們將高斯噪聲添加到填充的真值框中。噪聲尺度由α控制,α在不同的時間步長t中采用單調(diào)遞減的cosine值。
Training losses. 目標(biāo)檢測器將N個框作為輸入,并預(yù)測類別分類和框坐標(biāo)。論文將set prediction loss應(yīng)用于預(yù)測集合。我們通過最優(yōu)運輸分配方法選擇成本最小的前k個預(yù)測,為每個真值框分配多個預(yù)測。
在推理階段:
Sampling step. 在每個采樣步驟中,來自最后采樣步驟的隨機(jī)框或估計框被送到檢測解碼器,以預(yù)測類別和邊界框坐標(biāo)。
Box renewal. 在每個采樣步驟之后,可以將預(yù)測的框粗略地分類為兩種類型,期望的和不期望的預(yù)測。期望的預(yù)測包含正確定位在相應(yīng)對象上的框,而不期望的預(yù)測任意分布。
Once-for-all. 由于隨機(jī)框的設(shè)計,方法可以使用任意數(shù)量的隨機(jī)框和采樣步驟來評估DiffusionDet。
4. Experiments
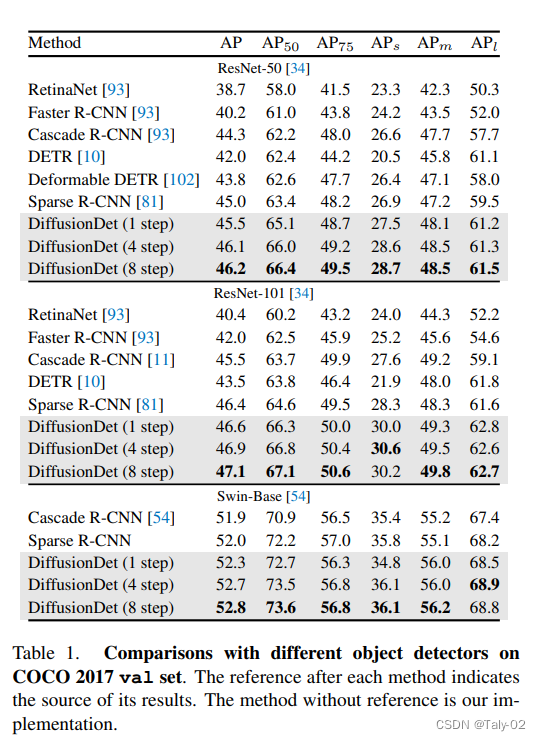
論文的結(jié)果似乎也很讓人滿意,成功地展示了diffusion model在感知任務(wù)上的優(yōu)化也是可行的。而ResNet-50的最好結(jié)果為46.2,似乎也說明了對于感知任務(wù),似乎特征才是最為最為關(guān)鍵的,優(yōu)化方式的改進(jìn)似乎沒有想象中的那么有效果。
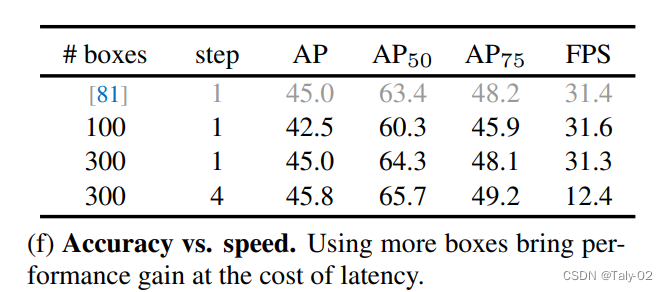
消融實驗中值得關(guān)注的是,不同于其他的目標(biāo)檢測方法,本文提出的方法如果增加step,速度顯著變慢的情況瞎,AP上漲的幅度也不大,所以這個trade-off做的可能不是特別到位。
5. Conclusion
在這項工作中,論文提出了一種新的檢測范式DiffusionDet,通過將目標(biāo)檢測視為從噪聲框到目標(biāo)框的去噪擴(kuò)散過程。我們的noise-to-box框架具有幾個吸引人的特性。在標(biāo)準(zhǔn)檢測baseline上進(jìn)行充足的實驗后,可以發(fā)現(xiàn)DiffusionDet實現(xiàn)了良好的性能。為了進(jìn)一步探索擴(kuò)散模型解決對象級識別任務(wù)的潛力,未來的幾項工作是有益的。
