
你的消息隊列如何保證消息不丟失,且只被消費一次,這篇就教會你
我們將消息隊列這個組件加入到了我們的商城系統(tǒng)里,并且通過秒殺這個實際的案例進(jìn)行了實際演練,知道了它對高并發(fā)寫流量做削峰填谷,對非關(guān)鍵業(yè)務(wù)邏輯做異步處理,對不同的業(yè)務(wù)系統(tǒng)做解耦合。 場景:現(xiàn)在我們的電商系統(tǒng)中上了一個新產(chǎn)品發(fā)紅包的功能,即當(dāng)用戶在我們商城消費了一定的額度之后,我們系統(tǒng)就給用戶發(fā)送一個現(xiàn)金紅包,用來答謝用戶并且促進(jìn)用戶消費。
場景:現(xiàn)在我們的電商系統(tǒng)中上了一個新產(chǎn)品發(fā)紅包的功能,即當(dāng)用戶在我們商城消費了一定的額度之后,我們系統(tǒng)就給用戶發(fā)送一個現(xiàn)金紅包,用來答謝用戶并且促進(jìn)用戶消費。
前面我們說到過,由于這個發(fā)紅包的動作并不屬于當(dāng)前下單的主流程,所以我們就使用消息隊列來異步處理。這個時候,就會有個隱藏問題:
我們在投遞消息的過程中消息可能會丟失,那我們的用戶就來打客服電話投訴我們說沒有得到紅包,甚至于有關(guān)部門投訴我們。
另一個問題,就是如果我們將消息重復(fù)發(fā)送了,那么用戶就會得到兩個紅包,這樣會造成我們公司的損失。
所以,現(xiàn)在我們要確保,系統(tǒng)生產(chǎn)的消息一定要被消費到,并且只能被消費一次,這個到底該怎么做呢?接下來,我們就來深入學(xué)習(xí)下。
要想保證消息只被消費一次,那么首先就得要保證消息不丟失。我們先來看看,消息從被寫入消息隊列,到被消費完成,這整個鏈路上會有哪些地方可能會導(dǎo)致消息丟失?我們不難看出,其實主要有三個地方:
消息從生產(chǎn)者到消息隊列的過程。
消息在消息隊列存儲的過程。
消息在被消費的過程。
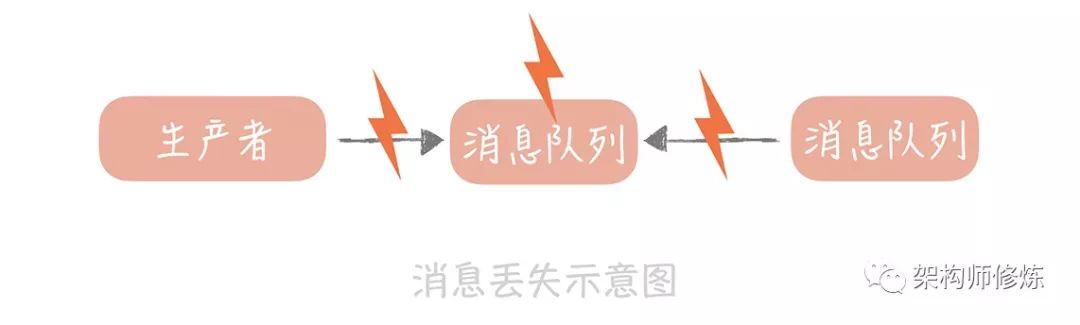
如上,我們分析了共有 3 個消息可能丟失的地方,接下來,我們就具體來分析下每一種情況。
一般這種情況,我們可以采用消息重傳的方案,即當(dāng)我們發(fā)現(xiàn)發(fā)送的消息超時后,我們就重新發(fā)送一次,但是不能一直無限制的重傳消息。按照經(jīng)驗來說,如果不是消息隊列本身故障,或者是網(wǎng)絡(luò)斷開了,一般重試個 2 到 3 次就行了。
但是,這種方案就有可能造成消息的重復(fù),這樣就會導(dǎo)致消費者消費到重復(fù)的消息。
例如,消息發(fā)送到消息隊列中,但是由于消息隊列處理消息較慢或者網(wǎng)絡(luò)抖動,這個時候,其實消息是寫入成功的,但是對于生產(chǎn)端就認(rèn)為超時了,那么生產(chǎn)者就會重傳當(dāng)前消息,則會出現(xiàn)消息重復(fù)。對于我們上面案例中,就是用戶會收到兩個紅包。
即使消息發(fā)送到了消息隊列,消息也不會萬無一失,還是會面臨丟失的風(fēng)險。
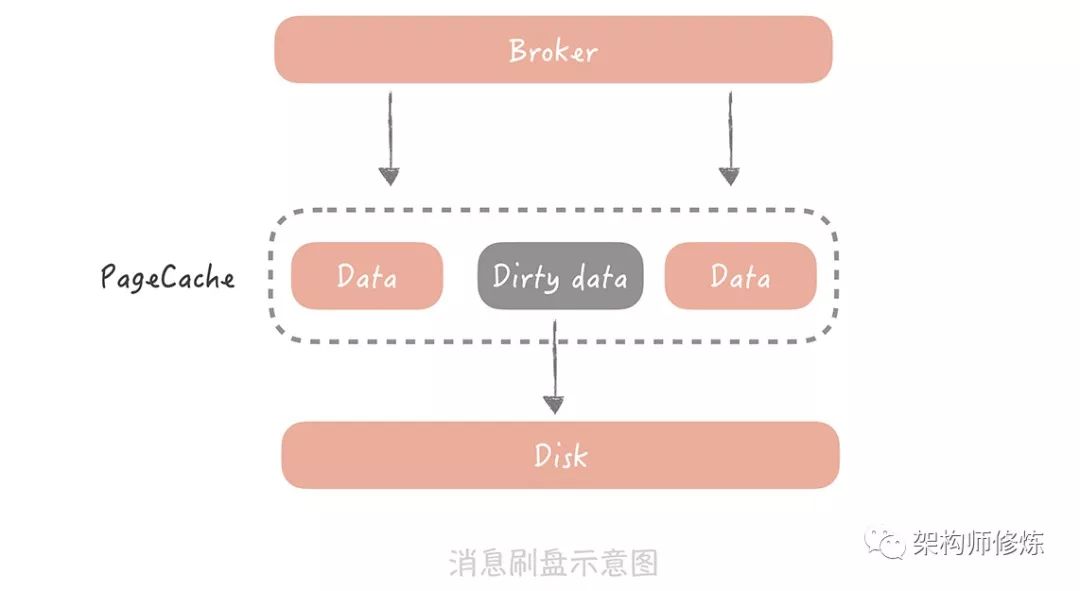
我們以 Kafka 為例,消息在Kafka 中是存儲在本地磁盤上的, 為了減少消息存儲對磁盤的隨機(jī) I/O,一般我們會將消息寫入到操作系統(tǒng)的 Page Cache 中,然后在合適的時間將消息刷新到磁盤上。
例如,Kafka 可以配置當(dāng)達(dá)到某一時間間隔,或者累積一定的消息數(shù)量的時候再刷盤,也就是所謂的異步刷盤。
不過,如果發(fā)生機(jī)器掉電或者機(jī)器異常重啟,那么 Page Cache 中還沒有來得及刷盤的消息就會丟失了。那么怎么解決呢?你可能會把刷盤的間隔設(shè)置很短,或者設(shè)置累積一條消息就就刷盤。
但這樣頻繁刷盤會對性能有比較大的影響,而且從經(jīng)驗來看,出現(xiàn)機(jī)器宕機(jī)或者掉電的幾率也不高,所以我不建議你這樣做。
 如果你的電商系統(tǒng)對消息丟失的容忍度很低,那么你可以考慮以集群方式部署 Kafka 服務(wù),通過部署多個副本備份數(shù)據(jù),保證消息盡量不丟失。
如果你的電商系統(tǒng)對消息丟失的容忍度很低,那么你可以考慮以集群方式部署 Kafka 服務(wù),通過部署多個副本備份數(shù)據(jù),保證消息盡量不丟失。那么它是怎么實現(xiàn)的呢?Kafka 集群中有一個 Leader 負(fù)責(zé)消息的寫入和消費,可以有多個 Follower 負(fù)責(zé)數(shù)據(jù)的備份。Follower 中有一個特殊的集合叫做 ISR(in-sync replicas),當(dāng) Leader 故障時,新選舉出來的 Leader 會從 ISR 中選擇,默認(rèn) Leader 的數(shù)據(jù)會異步地復(fù)制給 Follower,這樣在 Leader 發(fā)生掉電或者宕機(jī)時,Kafka 會從 Follower 中消費消息,減少消息丟失的可能。
由于默認(rèn)消息是異步地從 Leader 復(fù)制到 Follower 的,所以一旦 Leader 宕機(jī),那些還沒有來得及復(fù)制到 Follower 的消息還是會丟失。
為了解決這個問題,Kafka 為生產(chǎn)者提供一個選項叫做“acks”,當(dāng)這個選項被設(shè)置為“all”時,生產(chǎn)者發(fā)送的每一條消息除了發(fā)給 Leader 外還會發(fā)給所有的 ISR,并且必須得到 Leader 和所有 ISR 的確認(rèn)后才被認(rèn)為發(fā)送成功。這樣,只有 Leader 和所有的 ISR 都掛了,消息才會丟失。
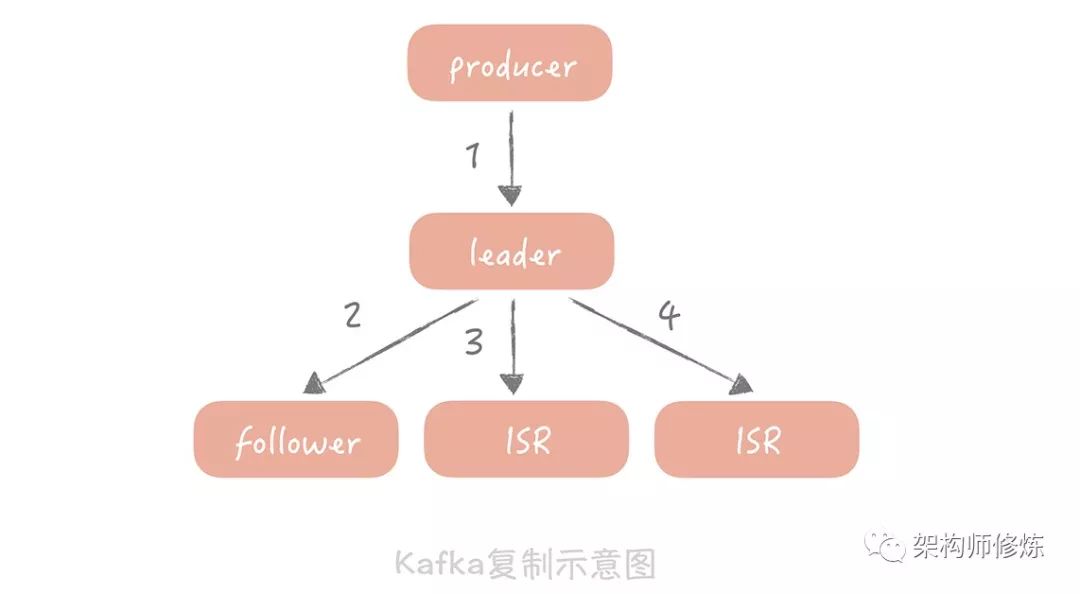
從上面這張圖來看,當(dāng)設(shè)置“acks=all”時,需要同步執(zhí)行 1,3,4 三個步驟,對于消息生產(chǎn)的性能來說也是有比較大的影響的,所以你在實際應(yīng)用中需要仔細(xì)地權(quán)衡考量。這里建議是:
如果你需要確保消息一條都不能丟失,那么建議不要開啟消息隊列的同步刷盤,而是需要使用集群的方式來解決,可以配置當(dāng)所有 ISR Follower 都接收到消息才返回成功。
如果對消息的丟失有一定的容忍度,那么建議不部署集群,即使以集群方式部署,也建議配置只發(fā)送給一個 Follower 就可以返回成功了。
我們的業(yè)務(wù)系統(tǒng)一般對于消息的丟失有一定的容忍度,比如說以上面的紅包系統(tǒng)為例,如果紅包消息丟失了,我們只要后續(xù)給沒有發(fā)送紅包的用戶補發(fā)紅包就好了。
3. 在消費的過程中存在消息丟失的可能
還是以 Kafka 為例來說明。一個消費者消費消息的進(jìn)度是記錄在消息隊列集群中的,而消費的過程分為三步:接收消息、處理消息、更新消費進(jìn)度。
這里面接收消息和處理消息的過程都可能會發(fā)生異常或者失敗,比如說,消息接收時網(wǎng)絡(luò)發(fā)生抖動,導(dǎo)致消息并沒有被正確的接收到;處理消息時可能發(fā)生一些業(yè)務(wù)的異常導(dǎo)致處理流程未執(zhí)行完成,這時如果更新消費進(jìn)度,那么這條失敗的消息就永遠(yuǎn)不會被處理了,也可以認(rèn)為是丟失了。
所以,在這里你需要注意的是,一定要等到消息接收和處理完成后才能更新消費進(jìn)度,但是這也會造成消息重復(fù)的問題,比方說某一條消息在處理之后,消費者恰好宕機(jī)了,那么因為沒有更新消費進(jìn)度,所以當(dāng)這個消費者重啟之后,還會重復(fù)地消費這條消息。
從上面的分析中,你能發(fā)現(xiàn),為了避免消息丟失,我們需要付出兩方面的代價:一方面是性能的損耗;一方面可能造成消息重復(fù)消費。
性能的損耗我們還可以接受,因為一般業(yè)務(wù)系統(tǒng)只有在寫請求時才會有發(fā)送消息隊列的操作,而一般系統(tǒng)的寫請求的量級并不高,但是消息一旦被重復(fù)消費,就會造成業(yè)務(wù)邏輯處理的錯誤。那么我們要如何避免消息的重復(fù)呢?
想要完全的避免消息重復(fù)的發(fā)生是很難做到的,因為網(wǎng)絡(luò)的抖動、機(jī)器的宕機(jī)和處理的異常都是比較難以避免的,在工業(yè)上并沒有成熟的方法,因此我們會把要求放寬,只要保證即使消費到了重復(fù)的消息,從消費的最終結(jié)果來看和只消費一次是等同的就好了,也就是保證在消息的生產(chǎn)和消費的過程是“冪等”的。
1. 什么是冪等
冪等是一個數(shù)學(xué)上的概念,它的含義是多次執(zhí)行同一個操作和執(zhí)行一次操作,最終得到的結(jié)果是相同的,說起來可能有些抽象,我給你舉個例子:比如,男生和女生吵架,女生抓住一個點不放,傳遞“你不在乎我了嗎?”(生產(chǎn)消息)的信息。那么當(dāng)多次埋怨“你不在乎我了嗎?”的時候(多次生產(chǎn)相同消息),她不知道的是,男生的耳朵(消息處理)會自動把 N 多次的信息屏蔽,就像只聽到一次一樣,這就是冪等性。
如果我們消費一條消息的時候,要給現(xiàn)有的庫存數(shù)量減 1,那么如果消費兩條相同的消息就會給庫存數(shù)量減 2,這就不是冪等的。而如果消費一條消息后,處理邏輯是將庫存的數(shù)量設(shè)置為 0,或者是如果當(dāng)前庫存數(shù)量是 10 時則減 1,這樣在消費多條消息時,所得到的結(jié)果就是相同的,這就是冪等的。
說白了,你可以這么理解“冪等”:一件事兒無論做多少次都和做一次產(chǎn)生的結(jié)果是一樣的,那么這件事兒就具有冪等性。
2. 在生產(chǎn)、消費過程中增加消息冪等性的保證
消息在生產(chǎn)和消費的過程中都可能會產(chǎn)生重復(fù),所以你要做的是,在生產(chǎn)過程和消費過程中增加消息冪等性的保證,這樣就可以認(rèn)為從“最終結(jié)果上來看”,消息實際上是只被消費了一次的。
它的做法是給每一個生產(chǎn)者一個唯一的 ID,并且為生產(chǎn)的每一條消息賦予一個唯一 ID,消息隊列的服務(wù)端會存儲 < 生產(chǎn)者 ID,最后一條消息 ID> 的映射。當(dāng)某一個生產(chǎn)者產(chǎn)生新的消息時,消息隊列服務(wù)端會比對消息 ID 是否與存儲的最后一條 ID 一致,如果一致,就認(rèn)為是重復(fù)的消息,服務(wù)端會自動丟棄。
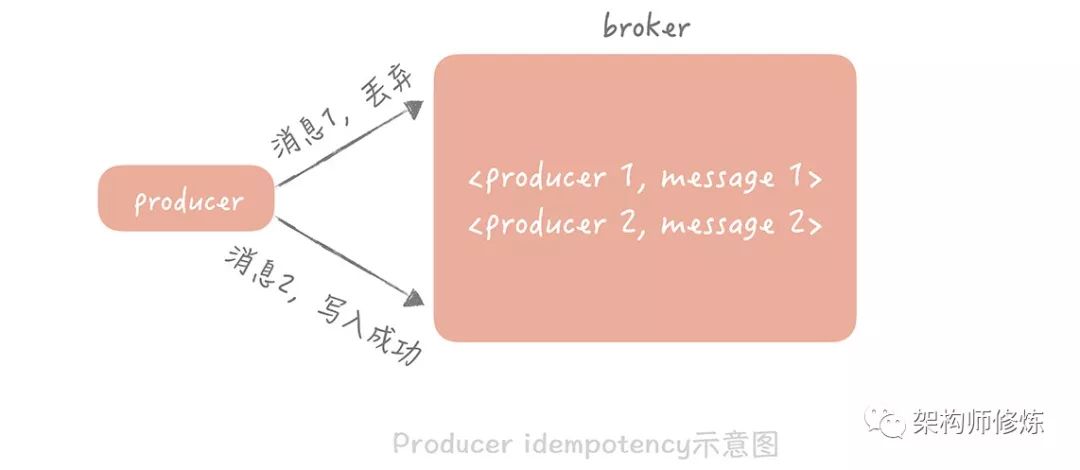 而在消費端,冪等性的保證會稍微復(fù)雜一些,你可以從通用層和業(yè)務(wù)層兩個層面來考慮。
而在消費端,冪等性的保證會稍微復(fù)雜一些,你可以從通用層和業(yè)務(wù)層兩個層面來考慮。你可以看到,無論是生產(chǎn)端的冪等性保證方式,還是消費端通用的冪等性保證方式,它們的共同特點都是為每一個消息生成一個唯一的 ID,然后在使用這個消息的時候,先比對這個 ID 是否已經(jīng)存在,如果存在,則認(rèn)為消息已經(jīng)被使用過。
所以這種方式是一種標(biāo)準(zhǔn)的實現(xiàn)冪等的方式,你在項目之中可以拿來直接使用,它在邏輯上的偽代碼就像下面這樣:
boolean isIDExisted = selectByID(ID); // 判斷ID是否存在if(isIDExisted) {return; //存在則直接返回} else {process(message); //不存在,則處理消息saveID(ID); //存儲ID}
這時你就需要引入事務(wù)機(jī)制,保證消息處理和寫入數(shù)據(jù)庫必須同時成功或者同時失敗,但是這樣消息處理的成本就更高了,所以,如果對于消息重復(fù)沒有特別嚴(yán)格的要求,可以直接使用這種通用的方案,而不考慮引入事務(wù)。
在業(yè)務(wù)層面怎么處理呢?這里有很多種處理方式,其中有一種是增加樂觀鎖的方式。比如,你的消息處理程序需要給一個人的賬號加錢,那么你可以通過樂觀鎖的方式來解決。
具體的操作方式是這樣的:你給每個人的賬號數(shù)據(jù)中增加一個版本號的字段,在生產(chǎn)消息時先查詢這個賬戶的版本號,并且將版本號連同消息一起發(fā)送給消息隊列。消費端在拿到消息和版本號后,在執(zhí)行更新賬戶金額 SQL 的時候帶上版本號,類似于執(zhí)行:
update user set amount = amount + 20, version=version+1where userId=1 and version=1;
你看,我們在更新數(shù)據(jù)時給數(shù)據(jù)加了樂觀鎖,這樣在消費第一條消息時,version 值為 1,SQL 可以執(zhí)行成功,并且同時把 version 值改為了 2;在執(zhí)行第二條相同的消息時,由于 version 值不再是 1,所以這條 SQL 不能執(zhí)行成功,也就保證了消息的冪等性。
總結(jié),今天我們主要學(xué)習(xí)了在消息隊列中,消息可能會發(fā)生丟失的場景,和我們的應(yīng)對方法,以及在消息重復(fù)的場景下,我們要如何保證,盡量不影響消息最終的處理結(jié)果。
有道無術(shù),術(shù)可成;有術(shù)無道,止于術(shù)
歡迎大家關(guān)注Java之道公眾號
好文章,我在看??