
Google新作 | 詳細(xì)解讀 Transformer那些有趣的特性
點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

本文發(fā)現(xiàn)了Transformer的一些重要特性,如Transformer對嚴(yán)重的遮擋,擾動和域偏移具有很高的魯棒性、與CNN相比,ViT更符合人類視覺系統(tǒng),泛化性更強(qiáng),等等... 代碼即將開源!
作者單位:澳大利亞國立大學(xué), 蒙納士大學(xué), 谷歌等7家高校/企業(yè)
1簡介
近期Vision Transformer(ViT)在各個垂直任務(wù)上均表現(xiàn)出非常不錯的性能。這些模型基于multi-head自注意力機(jī)制,該機(jī)制可以靈活地處理一系列圖像patches以對上下文cues進(jìn)行編碼。


一個重要的問題是,在以給定patch為條件的圖像范圍內(nèi),如何靈活地處理圖像中的干擾,例如嚴(yán)重的遮擋問題、域偏移問題、空間排列問題、對抗性和自然擾動等等問題。作者通過涵蓋3個ViT系列的大量實驗,以及與高性能卷積神經(jīng)網(wǎng)絡(luò)(CNN)的比較,系統(tǒng)地研究了這些問題。并通過分析得出了ViT的以下的特性:
Transformer對嚴(yán)重的遮擋,擾動和域偏移具有很高的魯棒性,例如,即使隨機(jī)遮擋80%的圖像內(nèi)容,其在ImageNet上仍可保持高達(dá)60%的top-1精度;
Transformer對于遮擋的良好表現(xiàn)并不是由于依賴局部紋理信息,與CNN相比,ViT對紋理的依賴要小得多。當(dāng)經(jīng)過適當(dāng)訓(xùn)練以對基于shape的特征進(jìn)行編碼時,ViT可以展現(xiàn)出與人類視覺系統(tǒng)相當(dāng)?shù)膕hape識別能力;
使用ViT對shape進(jìn)行編碼會產(chǎn)生有趣的現(xiàn)象,在即使沒有像素級監(jiān)督的情況下也可以進(jìn)行精確的語義分割;
可以將單個ViT模型提取的特征進(jìn)行組合以創(chuàng)建特征集合,從而在傳統(tǒng)學(xué)習(xí)模型和少量學(xué)習(xí)模型中的一系列分類數(shù)據(jù)集上實現(xiàn)較高的準(zhǔn)確率。實驗表明,ViT的有效特征是由于通過自注意力機(jī)制可以產(chǎn)生的靈活和動態(tài)的感受野所帶來的。
2本文討論主題
2.1 ViT對遮擋魯棒否?
這里假設(shè)有一個網(wǎng)絡(luò)模型,它通過處理一個輸入圖像來預(yù)測一個標(biāo)簽,其中可以表示為一個patch 的序列,是圖像patch的總數(shù)。
雖然可以有很多種方法來建模遮擋,但本文還是選擇了采用一個簡單的掩蔽策略,選擇整個圖像patch的一個子集,,并將這些patch的像素值設(shè)為0,這樣便創(chuàng)建一個遮擋圖像。
作者將上述方法稱為PatchDrop。目的是觀察魯棒性。
作者總共實驗了3種遮擋方法:
Random PatchDrop Salient(foreground) PatchDrop Non-salient (background) PatchDrop

1、Random PatchDrop
ViT通常將圖像劃分為196個patch,每個patch為14x14網(wǎng)格,這樣一幅224x224x3大小的圖像分割成196個patches,每個patch的大小為16x16x3。例如,隨機(jī)從輸入中刪除100個這樣的補(bǔ)丁就相當(dāng)于丟失了51%的圖像內(nèi)容。而這個隨機(jī)刪除的過程即為Random PatchDrop。
2、Salient(foreground) PatchDrop
對于分類器來說,并不是所有的像素都具有相同的值。為了估計顯著區(qū)域,作者利用了一個自監(jiān)督的ViT模型DINO,該模型使用注意力分割圖像中的顯著目標(biāo)。按照這種方法可以從196個包含前n個百分比的前景信息的patches中選擇一個子集并刪除它們。而這種通過自監(jiān)督模型刪除顯著區(qū)域的過程即為Salient (foreground) PatchDrop。
3、Non-salient(background) PatchDrop
采用與SP(Salient(foreground) PatchDrop)相同的方法選擇圖像中最不顯著的區(qū)域。包含前景信息中最低n%的patch被選中并刪除。同樣,而這種通過自監(jiān)督模型刪除非顯著區(qū)域的過程即為Non-salient(background) PatchDrop。
魯棒性分析
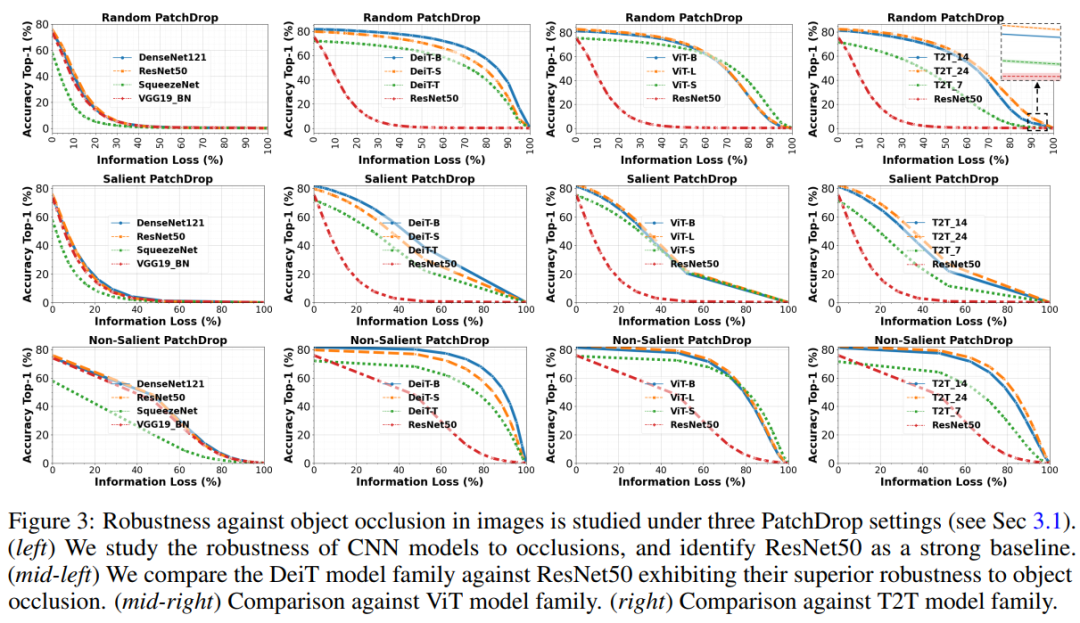
以Random PatchDrop為例,作者給出5次測試的平均值和標(biāo)準(zhǔn)偏差。對于顯著性和非顯著性Patchdrop,由于獲得的遮擋掩模是確定性的,作者只給出了1次運(yùn)行的精度值。
Random PatchDrop 50%的圖像信息幾乎完全破壞了CNN的識別能力。例如,當(dāng)去掉50%的圖像內(nèi)容時ResNet50的準(zhǔn)確率為0.1%,而DeiT-S的準(zhǔn)確率為70%。一個極端的例子可以觀察到,當(dāng)90%的圖像信息丟失,但Deit-B仍然顯示出37%的識別精度。這個結(jié)果在不同的ViT體系結(jié)構(gòu)中是一致的。同樣,ViT對前景(顯著)和背景(非顯著)內(nèi)容的去除也有很不錯的表現(xiàn)。
Class Token Preserves Information
為了更好地理解模型在這種遮擋下的性能魯棒的原有,作者將不同層的注意力可視化(圖4)。通過下圖可以看出淺層更關(guān)注遮擋區(qū)域,而較深的層更關(guān)注圖像中的遮擋以外的信息。

然后作者還研究這種從淺層到更深層次的變化是否是導(dǎo)致針對遮擋的Token不變性的原因,而這對分類是非常重要的。作者測量了原始圖像和遮擋圖像的特征/標(biāo)記之間的相關(guān)系數(shù)。在ResNet50的情況下測試在logit層之前的特性,對于ViT模型,Class Token從最后一個Transformer block中提取。與ResNet50特性相比,來自Transformer的Class Token明顯更魯棒,也不會遭受太多信息損失(表1)。
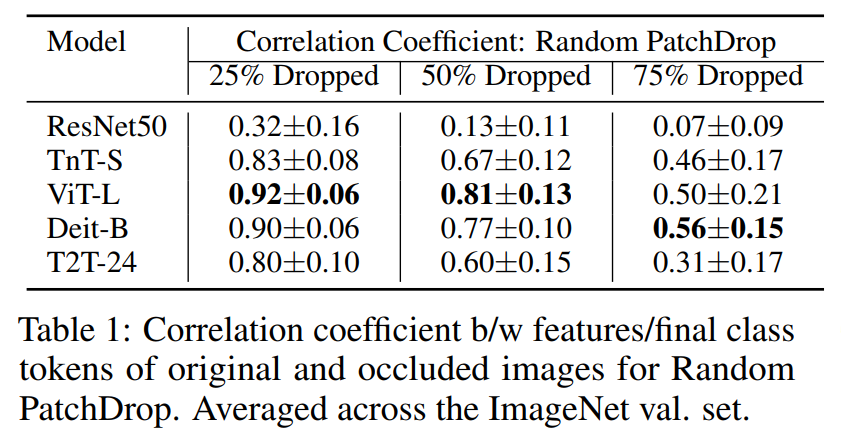
此外,作者還可視化了ImageNet中12個選擇的超類的相關(guān)系數(shù),并注意到這種趨勢在不同的類類型中都存在,即使是相對較小的對象類型,如昆蟲,食物和鳥類。

2.2 ViT能否同時學(xué)習(xí)Shape和Texture這2種特性?
Geirhos等人引入了Shape vs Texture的假設(shè),并提出了一種訓(xùn)練框架來增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)(CNNs)中的shape偏差。
首先,作者對ViT模型進(jìn)行了類似的分析,得出了比CNN更強(qiáng)的shape偏差,與人類視覺系統(tǒng)識別形狀的能力相當(dāng)。然而,這種方法會導(dǎo)致自然圖像的精度顯著下降。
為了解決這種問題,在第2種方法中,作者將shape token引入到Transformer體系結(jié)構(gòu)中,專門學(xué)習(xí)shape信息,使用一組不同的Token在同一體系結(jié)構(gòu)中建模Shape和Texture相關(guān)的特征。為此,作者從預(yù)訓(xùn)練的高shape偏差CNN模型中提取shape信息。而作者的這種蒸餾方法提供了一種平衡,既保持合理的分類精度,又提供比原始ViT模型更好的shape偏差。
Training without Local Texture
在訓(xùn)練中首先通過創(chuàng)建一個SIN風(fēng)格化的ImageNet數(shù)據(jù)(從訓(xùn)練數(shù)據(jù)中刪除局部紋理信息)。在這個數(shù)據(jù)集上訓(xùn)練非常小的DeiT模型。通常情況下,vit在訓(xùn)練期間需要大量的數(shù)據(jù)增強(qiáng)。然而,由于較少的紋理細(xì)節(jié),使用SIN進(jìn)行學(xué)習(xí)是一項困難的任務(wù),并且在風(fēng)格化樣本上進(jìn)行進(jìn)一步的擴(kuò)展會破壞shape信息,使訓(xùn)練不穩(wěn)定。因此,在SIN上訓(xùn)練模型不使用任何augmentation、label smoothing或Mixup。
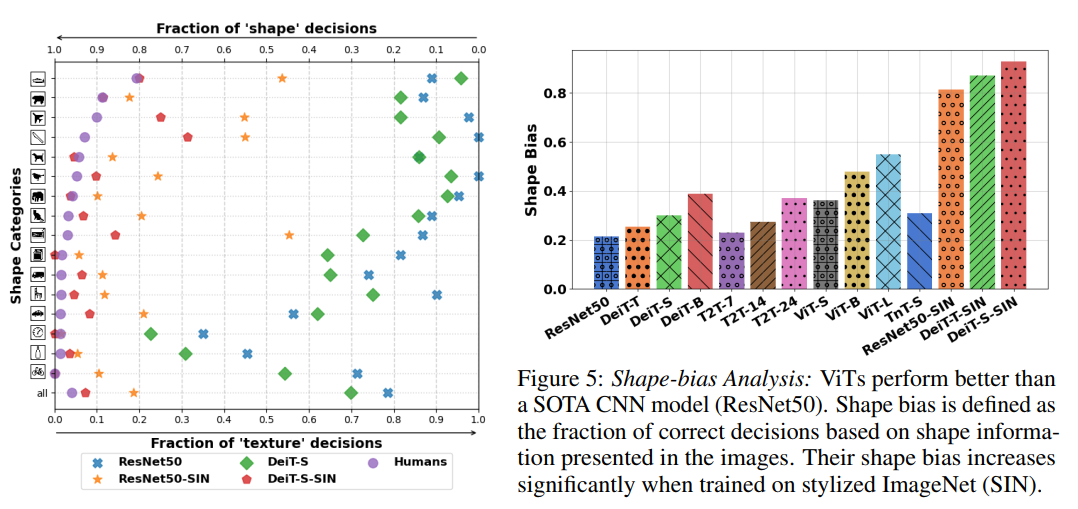
作者觀察到,在ImageNet上訓(xùn)練的ViT模型比類似參數(shù)量的CNN模型表現(xiàn)出更高的shape偏差,例如,具有2200萬個參數(shù)的DeiT-S比ResNet50表現(xiàn)更好(右圖)。當(dāng)比較SIN訓(xùn)練模型時,ViT模型始終優(yōu)于cnn模型。有趣的是,DeiT-S在SIN數(shù)據(jù)集上訓(xùn)練時達(dá)到了人類水平(左圖)。
Shape Distillation
通過學(xué)習(xí)Teacher models 提供的soft labels,知識蒸餾可以將大teacher models壓縮成較小的Student Model。本文作者引入了一種新的shape token,并采用 Adapt Attentive Distillation從SIN dataset(ResNet50-SIN)訓(xùn)練的CNN中提取Shape特征。作者注意到,ViT特性本質(zhì)上是動態(tài)的,可以通過Auxiliary Token來控制其學(xué)習(xí)所需的特征。這意味著單個ViT模型可以同時使用單獨(dú)的標(biāo)記顯示high shape和texture bias(下表)。
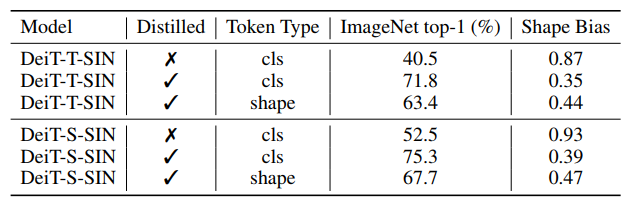
當(dāng)引入shape token時在分類和形狀偏差度量方面獲得了更平衡的性能(圖6)。為了證明這些不同的token(用于分類和shape)可以確實模型獨(dú)特的特征,作者計算了所蒸餾的模型DeiT-T-SIN和DeiT-S-SIN的class和shape token之間的余弦相似度,結(jié)果分別是0.35和0.68。這明顯低于class和distill token之間的相似性;DeiT-T和Deit-S分別為0.96和0.94。這證實了關(guān)于在Transformer中使用單獨(dú)的Token可以用來建模不同特征的假設(shè),這是一種獨(dú)特的能力,但是不能直接用在CNN模型中。
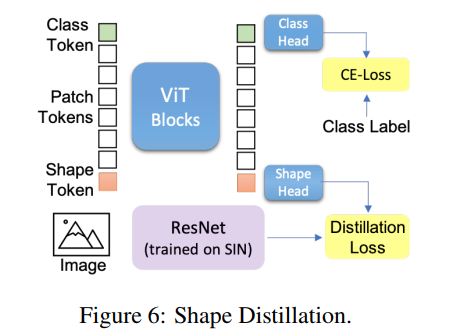
Shape-biased ViT Offers Automated Object Segmentation
有趣的是,沒有局部紋理或形狀蒸餾的訓(xùn)練可以讓ViT專注于場景中的前景物體而忽略背景(圖4)。這為圖像提供了自動語義分割的特征,盡管該模型從未顯示像素級對象標(biāo)簽。這也表明,在ViT中促進(jìn)shape偏差作為一個自監(jiān)督信號,模型可以學(xué)習(xí)不同shape相關(guān)的特征,這有助于定位正確的前景對象。值得注意的是,沒有使用shape token的訓(xùn)練中ViT表現(xiàn)得比較差(Table 3)。

2.3 位置編碼是否真的可以表征Global Context?
Transformer使用self-attention(而不是RNN中的順序設(shè)計)并行處理長序列,其序列排序是不變的。但是它的明顯缺點(diǎn)是忽略了輸入序列元素的順序,這可能很重要。
在視覺領(lǐng)域patch的排列順序代表了圖像的整體結(jié)構(gòu)和整體構(gòu)成。由于ViT對圖像塊進(jìn)行序列處理,改變序列的順序,例如對圖像塊進(jìn)行shuffle操作但是該操作會破壞圖像結(jié)構(gòu)。
當(dāng)前的ViT使用位置編碼來保存Context。在這里問題是,如果序列順序建模的位置編碼允許ViT在遮擋處理是否依然有效?
然而,分析表明,Transformer顯示排列不變的patch位置。位置編碼對向ViT模型注入圖像結(jié)構(gòu)信息的作用是有限的。這一觀察結(jié)果也與語言領(lǐng)域的發(fā)現(xiàn)相一致。
Sensitivity to Spatial Structure
通過對輸入圖像patch使用shuffle操作來消除下圖所示的圖像(空間關(guān)系)中的結(jié)構(gòu)信息。

作者觀察到,當(dāng)輸入圖像的空間結(jié)構(gòu)受到干擾時,DeiT模型比CNN模型保持了更高程度的準(zhǔn)確性。這也一方面證明了位置編碼對于做出正確的分類決策并不是至關(guān)重要的,并且該模型并沒有使用位置編碼中保存的patch序列信息來恢復(fù)全局圖像context。即使在沒有這種編碼的情況下,與使用位置編碼的ViT相比,ViT也能夠保持其性能,并表現(xiàn)出更好的排列不變性(下圖)。
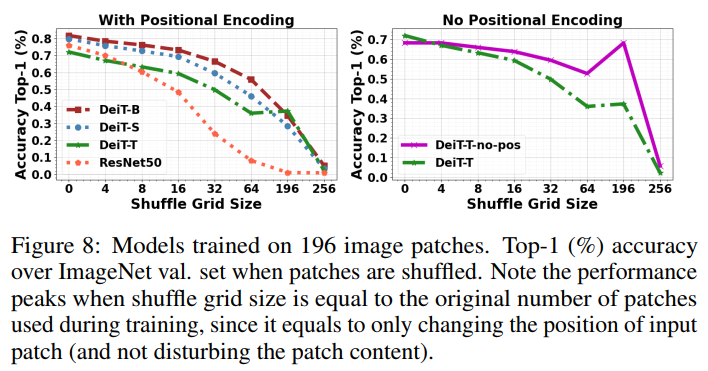
最后,在ViT訓(xùn)練過程中,當(dāng)patch大小發(fā)生變化時,對自然圖像進(jìn)行非混疊處理時,其排列不變性也會隨著精度的降低而降低(下圖)。作者將ViT的排列不變性歸因于它們的動態(tài)感受野,該感受野依賴于輸入小patch,可以與其他序列元素調(diào)整注意,從而在中等變換速率下,改變小patch的順序不會顯著降低表現(xiàn)。
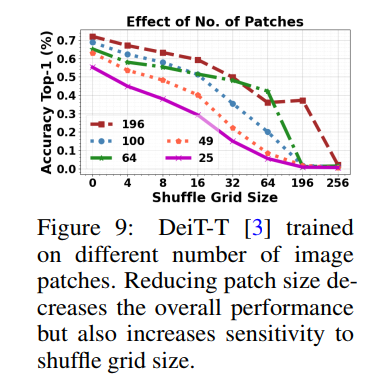
從上面的分析可以看出,就像texture bias假設(shè)是錯誤的一樣,依賴位置編碼來在遮擋下表現(xiàn)良好也是不準(zhǔn)確的。作者得出這樣的結(jié)論,這種魯棒性可能只是由于ViT靈活和動態(tài)的感受野所帶來的,這同時也取決于輸入圖像的內(nèi)容。
2.4 ViT對對抗信息和自然擾動的魯棒性又如何?
作者通過計算針對雨、霧、雪和噪聲等多種綜合常見干擾的平均損壞誤差(mCE)來研究這一問題。具有類似CNN參數(shù)的ViT(例如,DeiT-S)比經(jīng)過增強(qiáng)訓(xùn)練的ResNet50(Augmix)對圖像干擾更加魯棒。有趣的是,在ImageNet或SIN上未經(jīng)增強(qiáng)訓(xùn)練的卷積和Transformer模型更容易受到圖像干擾的影響(表6)。這些發(fā)現(xiàn)與此一致,表明數(shù)據(jù)增強(qiáng)對于提高常見干擾的魯棒性是很必要的。

作者還觀察到adversarial patch攻擊的類似問題。ViT的魯棒性高于CNN,通用adversarial patch在白盒設(shè)置(完全了解模型參數(shù))。在SIN上訓(xùn)練的ViT和CNN比在ImageNet上訓(xùn)練的模型更容易受到adversarial patch攻擊(圖10),這是由于shape偏差與魯棒性權(quán)衡導(dǎo)致的。
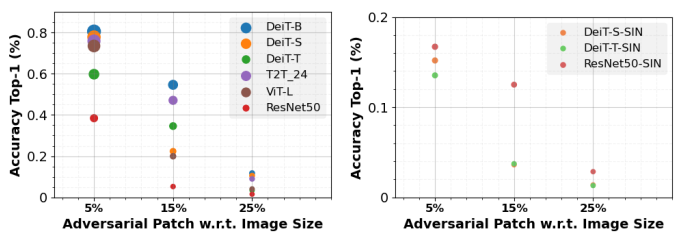
2.5 當(dāng)前ViT的最佳Token是什么?
ViT模型的一個獨(dú)特特征是模型中的每個patch產(chǎn)生一個class token,class head可以單獨(dú)處理該class token(下圖所示)。
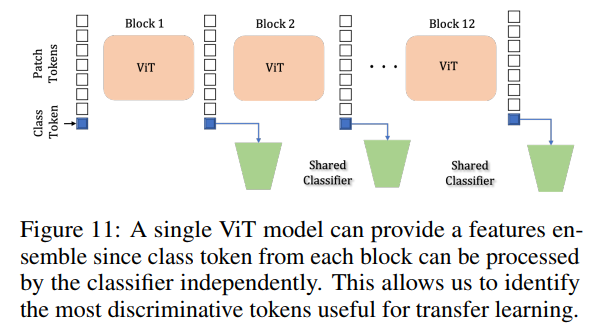
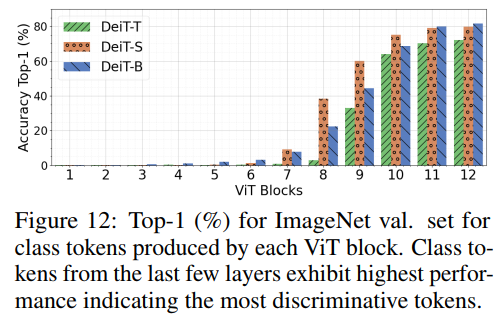
使得可以測量一個ImageNet預(yù)先訓(xùn)練的ViT的每個單獨(dú)patch的區(qū)分能力,如圖12所示,由更深的區(qū)塊產(chǎn)生的class token更具鑒別性,作者利用這一結(jié)果來識別其token具有best downstream transferability最優(yōu)patch token集合。
Transfer Methodology
如圖12所示,作者分析了DeiT模型的block的分類精度,發(fā)現(xiàn)在最后幾個block的class token中捕獲了最優(yōu)的判別信息。為了驗證是否可以將這些信息組合起來以獲得更好的性能,作者使用DeiT-S對細(xì)粒度分類數(shù)據(jù)集上現(xiàn)成的遷移學(xué)習(xí)進(jìn)行了消融研究(CUB),如下表所示。
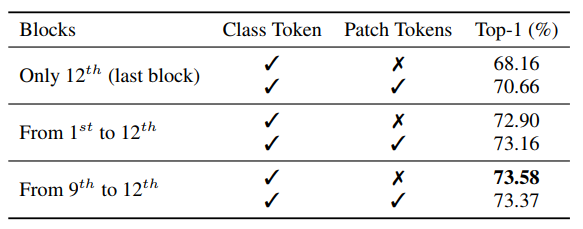
在這里,作者從不同的塊連接class token(可選地結(jié)合平均補(bǔ)丁標(biāo)記),并訓(xùn)練一個線性分類器來將特征轉(zhuǎn)移到下游任務(wù)。
請注意,一個patch token是通過沿著patch維度進(jìn)行平均生成的。最后4個塊的class token連接得到了最好的遷移學(xué)習(xí)性能。
作者將這種遷移方法稱為DeiT-S(ensemble)。來自所有塊的class token和averaged patch tokens的拼接表現(xiàn)出與來自最后4個塊的token相似的性能,但是需要顯著的大參數(shù)來訓(xùn)練。作者進(jìn)一步在更大范圍的任務(wù)中使用DeiT-S(集成)進(jìn)行進(jìn)一步實驗,以驗證假設(shè)。在接下來的實驗中,同時還將CNN Baseline與在預(yù)訓(xùn)練的ResNet50的logit層之前提取的特征進(jìn)行比較。
General Classification
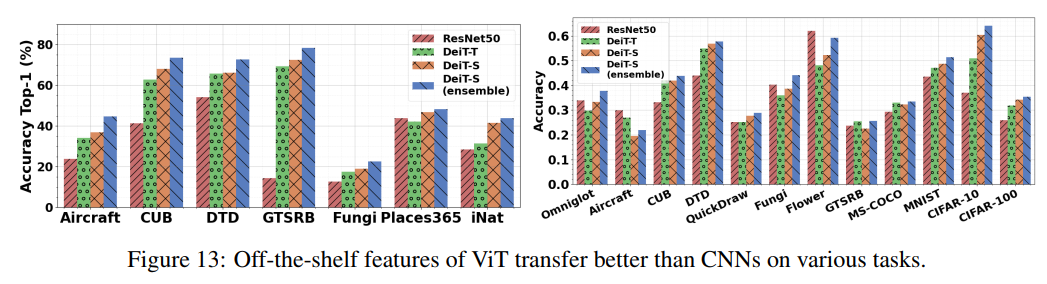
作者還研究了幾個數(shù)據(jù)集的現(xiàn)成特征的可遷移性,包括Aircraft, CUB, DTD, GTSRB, Fungi, Places365和iNaturalist數(shù)據(jù)集。這些數(shù)據(jù)集分別用于細(xì)粒度識別、紋理分類、交通標(biāo)志識別、真菌種類分類和場景識別,分別有100、200、47、43、1394、365和1010類。在每個數(shù)據(jù)集上訓(xùn)練一個線性分類器,并在測試分割上評估其性能。與CNN Baseline相比,ViT特征有了明顯的改善(圖13)。事實上,參數(shù)比ResNet50少5倍左右的DeiT-T性能更好。此外,本文提出的集成策略在所有數(shù)據(jù)集上都獲得了最好的結(jié)果。
Few-Shot Learning
在few-shot learning的情況下,元數(shù)據(jù)集是一個大規(guī)模的benchmark,包含一個不同的數(shù)據(jù)集集覆蓋多個領(lǐng)域。作者使用提取的特征為每個query學(xué)習(xí)support set上的線性分類器,并使用標(biāo)準(zhǔn)FSL協(xié)議評估。ViT特征在這些不同的領(lǐng)域之間轉(zhuǎn)移得更好(圖13)。作者還強(qiáng)調(diào)了QuickDraw的一個改進(jìn),包含手繪草圖的數(shù)據(jù)集,這與研究結(jié)果一致。
3參考
[1].Intriguing Properties of Vision Transformers.
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
點(diǎn)亮  ,告訴大家你也在看
,告訴大家你也在看