總第523 篇
2022年 第040篇
可觀測性作為系統(tǒng)高可用的重要保障,已經(jīng)成為系統(tǒng)建設(shè)中不可或缺的一環(huán)。然而隨著業(yè)務(wù)邏輯的日益復(fù)雜,傳統(tǒng)的ELK方案在日志搜集、篩選和分析等方面愈加耗時(shí)耗力,而分布式會(huì)話跟蹤方案雖然基于追蹤能力完善了日志的串聯(lián),但更聚焦于調(diào)用鏈路,也難以直接應(yīng)用于高效的業(yè)務(wù)追蹤。
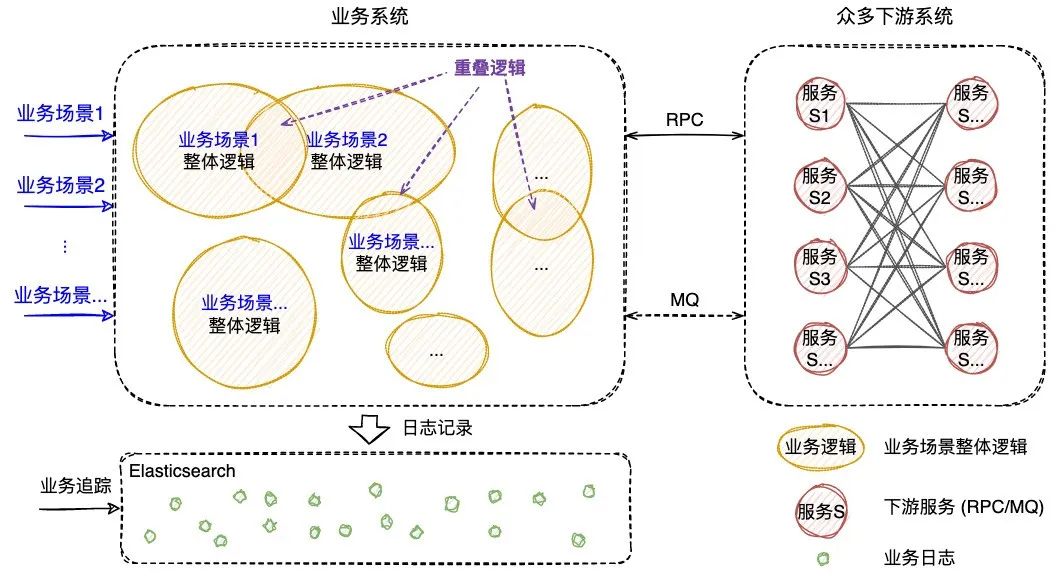
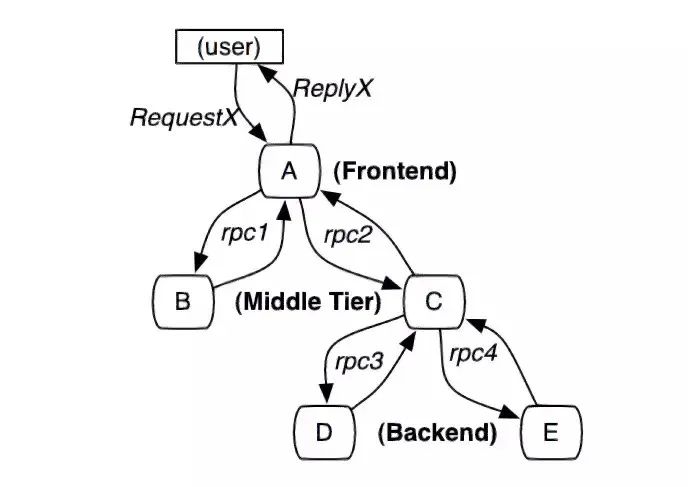
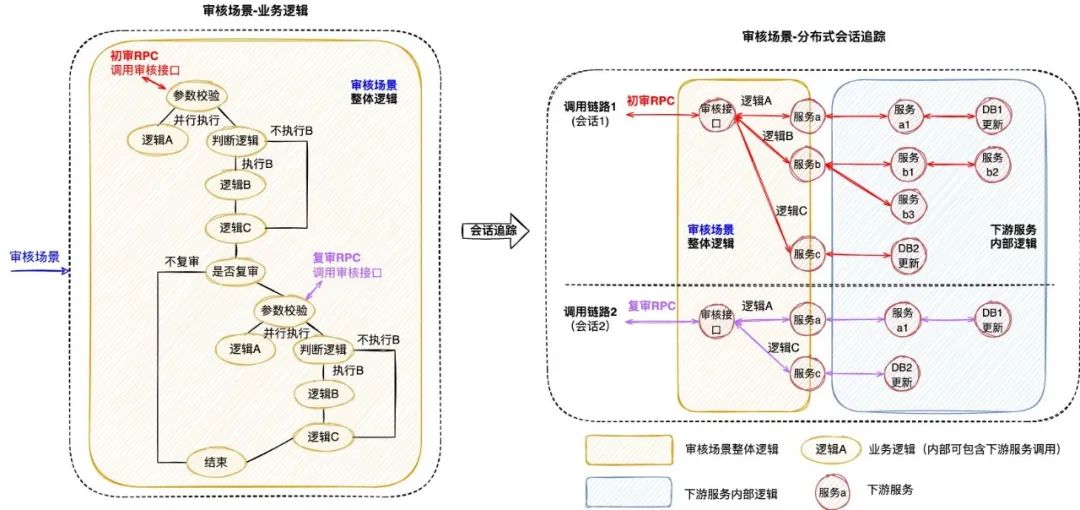
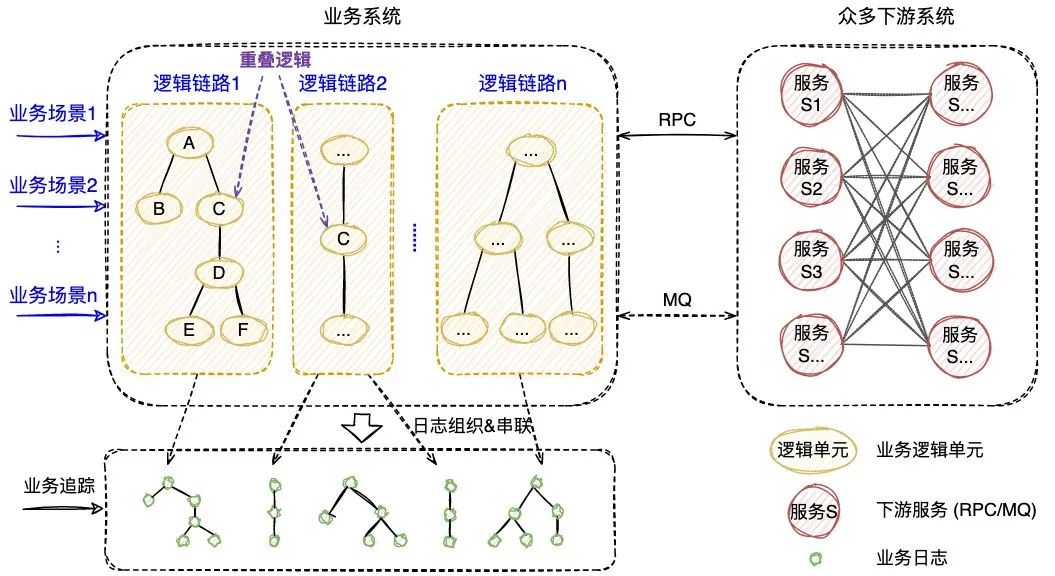
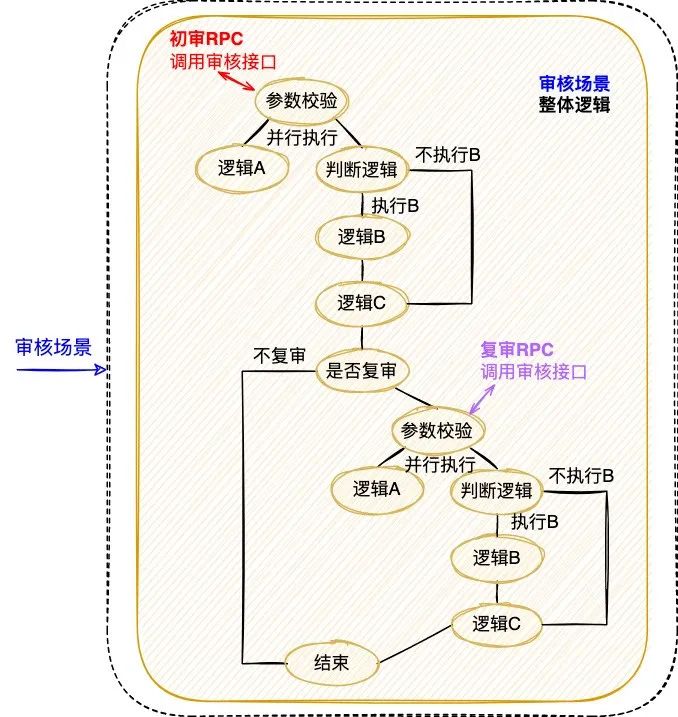
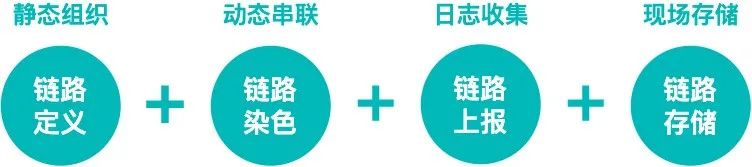
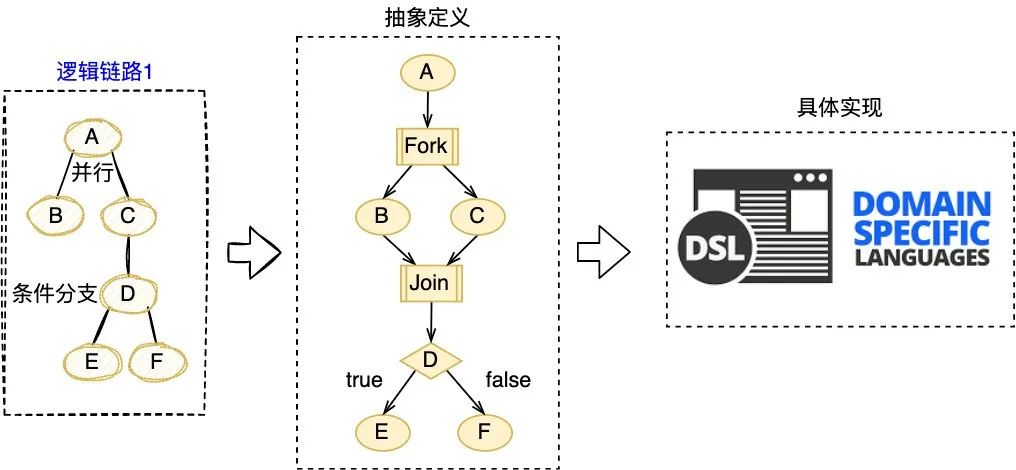
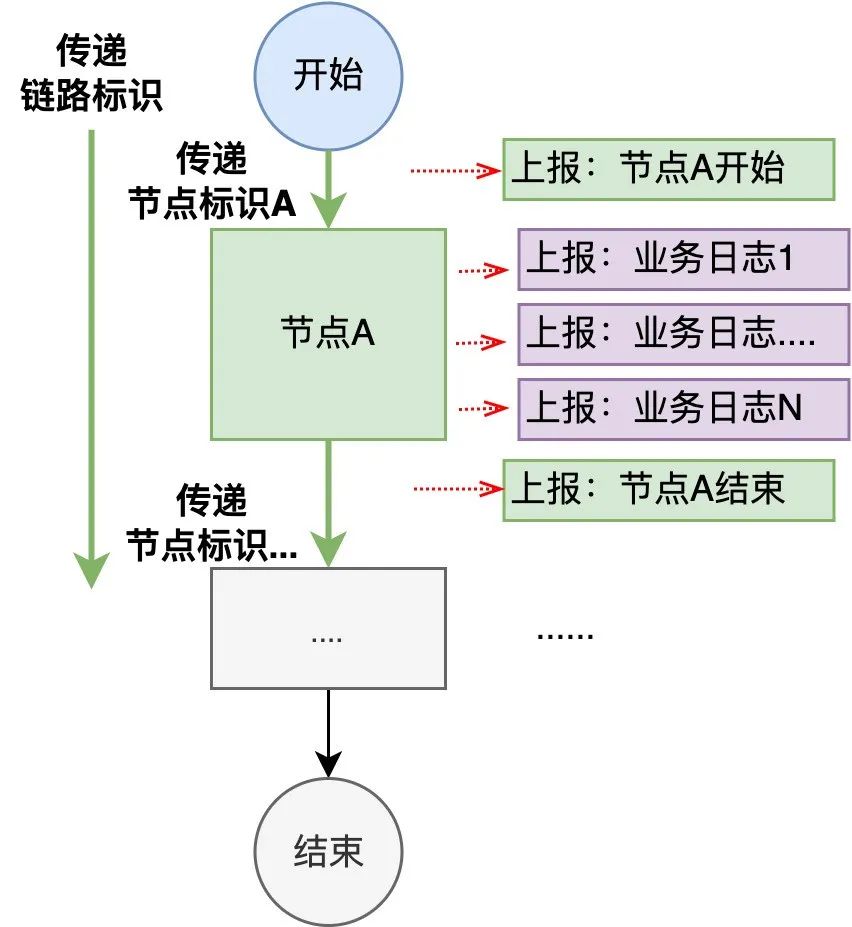
本文介紹了可視化全鏈路日志追蹤的新方案,它以業(yè)務(wù)鏈路為載體,通過有效組織業(yè)務(wù)每次執(zhí)行的日志,實(shí)現(xiàn)了執(zhí)行現(xiàn)場的可視化還原,支持問題的高效定位。 1. 背景 1.1 業(yè)務(wù)系統(tǒng)日益復(fù)雜 隨著互聯(lián)網(wǎng)產(chǎn)品的快速發(fā)展,不斷變化的商業(yè)環(huán)境和用戶訴求帶來了紛繁復(fù)雜的業(yè)務(wù)需求。業(yè)務(wù)系統(tǒng)需要支撐的業(yè)務(wù)場景越來越廣、涵蓋的業(yè)務(wù)邏輯越來越多,系統(tǒng)的復(fù)雜度也跟著快速提升。與此同時(shí),由于微服務(wù)架構(gòu)的演進(jìn),業(yè)務(wù)邏輯的實(shí)現(xiàn)往往需要依賴多個(gè)服務(wù)間的共同協(xié)作。總而言之,業(yè)務(wù)系統(tǒng)的日益復(fù)雜已經(jīng)成為一種常態(tài)。 1.2 業(yè)務(wù)追蹤面臨挑戰(zhàn) 業(yè)務(wù)系統(tǒng)往往面臨著多樣的日常客訴和突發(fā)問題,“業(yè)務(wù)追蹤”就成為了關(guān)鍵的應(yīng)對(duì)手段。業(yè)務(wù)追蹤可以看做一次業(yè)務(wù)執(zhí)行的現(xiàn)場還原過程,通過執(zhí)行中的各種記錄還原出原始現(xiàn)場,可用于業(yè)務(wù)邏輯執(zhí)行情況的分析和問題的定位,是整個(gè)系統(tǒng)建設(shè)中重要的一環(huán)。 目前在分布式場景下,業(yè)務(wù)追蹤的主流實(shí)現(xiàn)方式包括兩類,一類是基于日志的ELK方案,一類是基于單次請(qǐng)求調(diào)用的會(huì)話跟蹤方案。然而隨著業(yè)務(wù)邏輯的日益復(fù)雜,上述方案越來越不適用于當(dāng)下的業(yè)務(wù)系統(tǒng)。 1.2.1 傳統(tǒng)的ELK方案 日志作為業(yè)務(wù)系統(tǒng)的必備能力,職責(zé)就是記錄程序運(yùn)行期間發(fā)生的離散事件,并且在事后階段用于程序的行為分析,比如曾經(jīng)調(diào)用過什么方法、操作過哪些數(shù)據(jù)等等。在分布式系統(tǒng)中,ELK技術(shù)棧已經(jīng)成為日志收集和分析的通用解決方案。如下圖1所示,伴隨著業(yè)務(wù)邏輯的執(zhí)行,業(yè)務(wù)日志會(huì)被打印,統(tǒng)一收集并存儲(chǔ)至Elasticsearch( 下稱ES )[2] 。 圖1 業(yè)務(wù)系統(tǒng)ELK案例 傳統(tǒng)的ELK方案需要開發(fā)者在編寫代碼時(shí)盡可能全地打印日志,再通過關(guān)鍵字段從ES中搜集篩選出與業(yè)務(wù)邏輯相關(guān)的日志數(shù)據(jù),進(jìn)而拼湊出業(yè)務(wù)執(zhí)行的現(xiàn)場信息。然而該方案存在如下的痛點(diǎn): 綜上所述,隨著業(yè)務(wù)邏輯和系統(tǒng)復(fù)雜度的攀升,傳統(tǒng)的ELK方案在日志搜集、日志篩選和日志分析方面愈加的耗時(shí)耗力,很難快速實(shí)現(xiàn)對(duì)業(yè)務(wù)的追蹤。 1.2.2 分布式會(huì)話跟蹤方案 在分布式系統(tǒng),尤其是微服務(wù)系統(tǒng)中,業(yè)務(wù)場景的某次請(qǐng)求往往需要經(jīng)過多個(gè)服務(wù)、多個(gè)中間件、多臺(tái)機(jī)器的復(fù)雜鏈路處理才能完成。為了解決復(fù)雜鏈路排查困難的問題,“分布式會(huì)話跟蹤方案”誕生。該方案的理論知識(shí)由Google在2010年《Dapper》論文[3] 中發(fā)表,隨后Twitter開發(fā)出了一個(gè)開源版本Zipkin[4] 。 市面上的同類型框架幾乎都是以Google Dapper論文為基礎(chǔ)進(jìn)行實(shí)現(xiàn),整體大同小異,都是通過一個(gè)分布式全局唯一的id( 即traceId ),將分布在各個(gè)服務(wù)節(jié)點(diǎn)上的同一次請(qǐng)求串聯(lián)起來,還原調(diào)用關(guān)系、追蹤系統(tǒng)問題、分析調(diào)用數(shù)據(jù)、統(tǒng)計(jì)系統(tǒng)指標(biāo)。分布式會(huì)話跟蹤,是一種會(huì)話級(jí)別 的追蹤能力,如下圖2所示,單個(gè)分布式請(qǐng)求被還原成一條調(diào)用鏈路,從客戶端發(fā)起請(qǐng)求抵達(dá)系統(tǒng)的邊界開始,記錄請(qǐng)求流經(jīng)的每一個(gè)服務(wù),直到向客戶端返回響應(yīng)為止。 圖2 一次典型的請(qǐng)求全過程(摘自《Dapper》) 分布式會(huì)話跟蹤的主要作用是分析分布式系統(tǒng)的調(diào)用行為 ,并不能很好地應(yīng)用于業(yè)務(wù)邏輯的追蹤。下圖3是一個(gè)審核業(yè)務(wù)場景的追蹤案例,業(yè)務(wù)系統(tǒng)對(duì)外提供審核能力,待審對(duì)象的審核需要經(jīng)過“初審”和“復(fù)審”兩個(gè)環(huán)節(jié)( 兩個(gè)環(huán)節(jié)關(guān)聯(lián)相同的taskId ),因此整個(gè)審核環(huán)節(jié)的執(zhí)行調(diào)用了兩次審核接口。如圖左側(cè)所示,完整的審核場景涉及眾多“業(yè)務(wù)邏輯”的執(zhí)行,而分布式會(huì)話跟蹤只是根據(jù)兩次RPC調(diào)用生成了右側(cè)的兩條調(diào)用鏈路,并沒有辦法準(zhǔn)確地描述審核場景業(yè)務(wù)邏輯的執(zhí)行,問題主要體現(xiàn)在以下幾個(gè)方面: 圖3 分布式會(huì)話跟蹤案例 (1) 無法同時(shí)追蹤多條調(diào)用鏈路 分布式會(huì)話跟蹤僅支持單個(gè)請(qǐng)求的調(diào)用追蹤,當(dāng)業(yè)務(wù)場景包含了多個(gè)調(diào)用時(shí),將生成多條調(diào)用鏈路;由于調(diào)用鏈路通過traceId串聯(lián),不同鏈路之間相互獨(dú)立,因此給完整的業(yè)務(wù)追蹤增加了難度。例如當(dāng)排查審核場景的業(yè)務(wù)問題時(shí),由于初審和復(fù)審是不同的RPC請(qǐng)求,所以無法直接同時(shí)獲取到2條調(diào)用鏈路,通常需要額外存儲(chǔ)2個(gè)traceId的映射關(guān)系。 (2) 無法準(zhǔn)確描述業(yè)務(wù)邏輯的全景 分布式會(huì)話跟蹤生成的調(diào)用鏈路,只包含單次請(qǐng)求的實(shí)際調(diào)用情況,部分未執(zhí)行的調(diào)用以及本地邏輯無法體現(xiàn)在鏈路中,導(dǎo)致無法準(zhǔn)確描述業(yè)務(wù)邏輯的全景。例如同樣是審核接口,初審鏈路1包含了服務(wù)b的調(diào)用,而復(fù)審鏈路2卻并沒有包含,這是因?yàn)閷徍藞鼍爸写嬖凇芭袛噙壿嫛保撨壿嫙o法體現(xiàn)在調(diào)用鏈路中,還是需要人工結(jié)合代碼進(jìn)行分析。 (3) 無法聚焦于當(dāng)前業(yè)務(wù)系統(tǒng)的邏輯執(zhí)行 分布式會(huì)話跟蹤覆蓋了單個(gè)請(qǐng)求流經(jīng)的所有服務(wù)、組件、機(jī)器等等,不僅包含當(dāng)前業(yè)務(wù)系統(tǒng),還涉及了眾多的下游服務(wù),當(dāng)接口內(nèi)部邏輯復(fù)雜時(shí),調(diào)用鏈路的深度和復(fù)雜度都會(huì)明顯增加,而業(yè)務(wù)追蹤其實(shí)僅需要聚焦于當(dāng)前業(yè)務(wù)系統(tǒng)的邏輯執(zhí)行情況。例如審核場景生成的調(diào)用鏈路,就涉及了眾多下游服務(wù)的內(nèi)部調(diào)用情況,反而給當(dāng)前業(yè)務(wù)系統(tǒng)的問題排查增加了復(fù)雜度。 1.2.3 總結(jié) 傳統(tǒng)的ELK方案是一種滯后的業(yè)務(wù)追蹤,需要事后從大量離散的日志中搜集和篩選出需要的日志,并人工進(jìn)行日志的串聯(lián)分析,其過程必然耗時(shí)耗力。而分布式會(huì)話跟蹤方案則是在調(diào)用執(zhí)行的同時(shí),實(shí)時(shí)地完成了鏈路的動(dòng)態(tài)串聯(lián),但由于是會(huì)話級(jí)別且僅關(guān)注于調(diào)用關(guān)系等問題,導(dǎo)致其無法很好地應(yīng)用于業(yè)務(wù)追蹤。 因此,無論是傳統(tǒng)的ELK方案還是分布式會(huì)話跟蹤方案,都難以滿足日益復(fù)雜的業(yè)務(wù)追蹤需求。本文希望能夠?qū)崿F(xiàn)聚焦于業(yè)務(wù)邏輯追蹤的高效解決方案,將業(yè)務(wù)執(zhí)行的日志以業(yè)務(wù)鏈路為載體進(jìn)行高效組織和串聯(lián),并支持業(yè)務(wù)執(zhí)行現(xiàn)場的還原和可視化查看,從而提升定位問題的效率,即可視化全鏈路日志追蹤 。 下文將介紹可視化全鏈路日志追蹤 的設(shè)計(jì)思路和通用方案,同時(shí)介紹新方案在大眾點(diǎn)評(píng)內(nèi)容平臺(tái)的落地情況,旨在幫助有類似需求的業(yè)務(wù)系統(tǒng)開發(fā)需求的同學(xué)提供一些思路。 2. 可視化全鏈路日志追蹤 2.1 設(shè)計(jì)思路 可視化全鏈路日志追蹤 考慮在前置階段,即業(yè)務(wù)執(zhí)行的同時(shí)實(shí)現(xiàn)業(yè)務(wù)日志的高效組織和動(dòng)態(tài)串聯(lián),如下圖4所示,此時(shí)離散的日志數(shù)據(jù)將會(huì)根據(jù)業(yè)務(wù)邏輯進(jìn)行組織,繪制出執(zhí)行現(xiàn)場,從而可以實(shí)現(xiàn)高效的業(yè)務(wù)追蹤。圖4 業(yè)務(wù)系統(tǒng)日志追蹤案例 新方案需要回答兩個(gè)關(guān)鍵問題:如何高效組織業(yè)務(wù)日志,以及如何動(dòng)態(tài)串聯(lián)業(yè)務(wù)日志。下文將逐一進(jìn)行回答。 為了實(shí)現(xiàn)高效的業(yè)務(wù)追蹤,首先需要準(zhǔn)確完整地描述出業(yè)務(wù)邏輯,形成業(yè)務(wù)邏輯的全景圖,而業(yè)務(wù)追蹤其實(shí)就是通過執(zhí)行時(shí)的日志數(shù)據(jù),在全景圖中還原出業(yè)務(wù)執(zhí)行的現(xiàn)場。 新方案對(duì)業(yè)務(wù)邏輯進(jìn)行了抽象,定義出業(yè)務(wù)邏輯鏈路,下面還是以“審核業(yè)務(wù)場景”為例,來說明業(yè)務(wù)邏輯鏈路的抽象過程: 一次業(yè)務(wù)追蹤就是邏輯鏈路 的某一次執(zhí)行情況的還原,邏輯鏈路 完整準(zhǔn)確地描述了業(yè)務(wù)邏輯全景,同時(shí)作為載體可以實(shí)現(xiàn)業(yè)務(wù)日志的高效組織。 圖5 業(yè)務(wù)邏輯鏈路案例 問題2:如何動(dòng)態(tài)串聯(lián)業(yè)務(wù)日志? 業(yè)務(wù)邏輯執(zhí)行時(shí)的日志數(shù)據(jù)原本是離散存儲(chǔ)的,而此時(shí)需要實(shí)現(xiàn)的是,隨著業(yè)務(wù)邏輯的執(zhí)行動(dòng)態(tài)串聯(lián)各個(gè)邏輯節(jié)點(diǎn)的日志,進(jìn)而還原出完整的業(yè)務(wù)邏輯執(zhí)行現(xiàn)場。 由于邏輯節(jié)點(diǎn)之間、邏輯節(jié)點(diǎn)內(nèi)部往往通過MQ或者RPC等進(jìn)行交互,新方案可以采用分布式會(huì)話跟蹤提供的分布式參數(shù)透傳能力 [5] 實(shí)現(xiàn)業(yè)務(wù)日志的動(dòng)態(tài)串聯(lián): 與分布式會(huì)話跟蹤方案不同的是,當(dāng)同時(shí)串聯(lián)多次分布式調(diào)用時(shí),新方案需要結(jié)合業(yè)務(wù)邏輯選取一個(gè)公共id作為標(biāo)識(shí),例如圖5的審核場景涉及2次RPC調(diào)用,為了保證2次執(zhí)行被串聯(lián)至同一條邏輯鏈路,此時(shí)結(jié)合審核業(yè)務(wù)場景,選擇初審和復(fù)審相同的“任務(wù)id”作為標(biāo)識(shí),完整地實(shí)現(xiàn)審核場景的邏輯鏈路串聯(lián)和執(zhí)行現(xiàn)場還原。 2.2 通用方案 明確日志的高效組織和動(dòng)態(tài)串聯(lián)這兩個(gè)基本問題后,本文選取圖4業(yè)務(wù)系統(tǒng)中的“邏輯鏈路1”進(jìn)行通用方案的詳細(xì)說明,方案可以拆解為以下步驟: 圖6 通用方案拆解 2.2.1 鏈路定義 “鏈路定義”的含義為:使用特定語言,靜態(tài)描述完整的邏輯鏈路 ,鏈路通常由多個(gè)邏輯節(jié)點(diǎn) ,按照一定的業(yè)務(wù)規(guī)則 組合而成,業(yè)務(wù)規(guī)則 即各個(gè)邏輯節(jié)點(diǎn)之間存在的執(zhí)行關(guān)系,包括串行 、并行 、條件分支 。 DSL(D omain Specific Language )是為了解決某一類任務(wù)而專門設(shè)計(jì)的計(jì)算機(jī)語言,可以通過JSON或XML定義出一系列節(jié)點(diǎn)( 邏輯節(jié)點(diǎn) )的組合關(guān)系( 業(yè)務(wù)規(guī)則 )。因此,本方案選擇使用DSL描述邏輯鏈路,實(shí)現(xiàn)邏輯鏈路從抽象定義 到具體實(shí)現(xiàn) 。 圖7 鏈路的抽象定義和具體實(shí)現(xiàn) 邏輯鏈路1-DSL ["nodeName" : "A" ,"nodeType" : "rpc" "nodeName" : "Fork" ,"nodeType" : "fork" ,"forkNodes" : ["nodeName" : "B" ,"nodeType" : "rpc" "nodeName" : "C" ,"nodeType" : "local" "nodeName" : "Join" ,"nodeType" : "join" ,"joinOnList" : ["B" ,"C" "nodeName" : "D" ,"nodeType" : "decision" ,"decisionCases" : {"true" : ["nodeName" : "E" ,"nodeType" : "rpc" "defaultCase" : ["nodeName" : "F" ,"nodeType" : "rpc" 2.2.2 鏈路染色 “鏈路染色”的含義為:在鏈路執(zhí)行過程中,通過透傳串聯(lián)標(biāo)識(shí),明確具體是哪條鏈路在執(zhí)行,執(zhí)行到了哪個(gè)節(jié)點(diǎn)。 步驟一 :確定串聯(lián)標(biāo)識(shí),當(dāng)邏輯鏈路開啟時(shí),確定唯一標(biāo)識(shí),能夠明確后續(xù)待執(zhí)行的鏈路和節(jié)點(diǎn)。鏈路唯一標(biāo)識(shí) = 業(yè)務(wù)標(biāo)識(shí) + 場景標(biāo)識(shí) + 執(zhí)行標(biāo)識(shí) ( 三個(gè)標(biāo)識(shí)共同決定“某個(gè)業(yè)務(wù)場景下的某次執(zhí)行” ) 業(yè)務(wù)標(biāo)識(shí):賦予鏈路業(yè)務(wù)含義,例如“用戶id”、“活動(dòng)id”等等。
場景標(biāo)識(shí):賦予鏈路場景含義,例如當(dāng)前場景是“邏輯鏈路1”。
執(zhí)行標(biāo)識(shí):賦予鏈路執(zhí)行含義,例如只涉及單次調(diào)用時(shí),可以直接選擇“traceId”;涉及多次調(diào)用時(shí)則,根據(jù)業(yè)務(wù)邏輯選取多次調(diào)用相同的“公共id”。
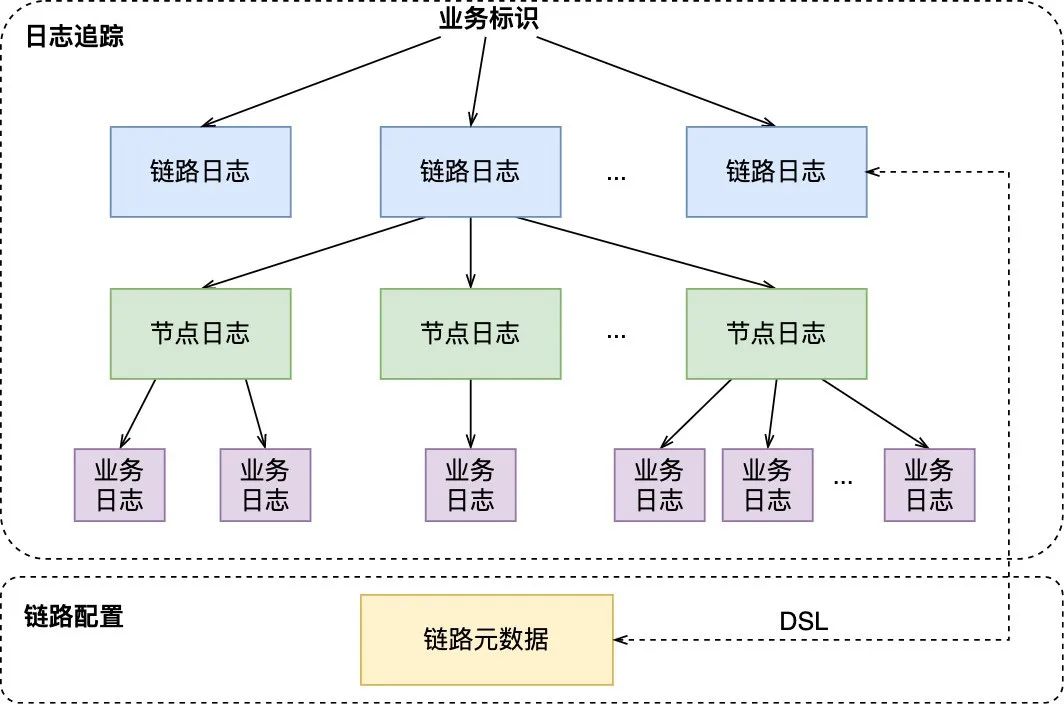
節(jié)點(diǎn)唯一標(biāo)識(shí) = 鏈路唯一標(biāo)識(shí) + 節(jié)點(diǎn)名稱 ( 兩個(gè)標(biāo)識(shí)共同決定“某個(gè)業(yè)務(wù)場景下的某次執(zhí)行中的某個(gè)邏輯節(jié)點(diǎn)” ) 節(jié)點(diǎn)名稱:DSL中預(yù)設(shè)的節(jié)點(diǎn)唯一名稱,如“A”。 步驟二 :傳遞串聯(lián)標(biāo)識(shí),當(dāng)邏輯鏈路執(zhí)行時(shí),在分布式的完整鏈路中透傳串聯(lián)標(biāo)識(shí),動(dòng)態(tài)串聯(lián)鏈路中已執(zhí)行的節(jié)點(diǎn),實(shí)現(xiàn)鏈路的染色。例如在“邏輯鏈路1”中:2.2.3 鏈路上報(bào) “鏈路上報(bào)”的含義為:在鏈路執(zhí)行過程中,將日志以鏈路的組織形式進(jìn)行上報(bào),實(shí)現(xiàn)業(yè)務(wù)現(xiàn)場的準(zhǔn)確保存。 圖8 鏈路上報(bào)圖示 如上圖8所示,上報(bào)的日志數(shù)據(jù)包括:節(jié)點(diǎn)日志 和業(yè)務(wù)日志 。其中節(jié)點(diǎn)日志的作用是繪制鏈路中的已執(zhí)行節(jié)點(diǎn),記錄了節(jié)點(diǎn)的開始、結(jié)束、輸入、輸出;業(yè)務(wù)日志的作用是展示鏈路節(jié)點(diǎn)具體業(yè)務(wù)邏輯的執(zhí)行情況,記錄了任何對(duì)業(yè)務(wù)邏輯起到解釋作用的數(shù)據(jù),包括與上下游交互的入?yún)⒊鰠ⅰ?fù)雜邏輯的中間變量、邏輯執(zhí)行拋出的異常。 2.2.4 鏈路存儲(chǔ) “鏈路存儲(chǔ)”的含義為:將鏈路執(zhí)行中上報(bào)的日志落地存儲(chǔ),并用于后續(xù)的“現(xiàn)場還原”。上報(bào)日志可以拆分為鏈路日志、節(jié)點(diǎn)日志和業(yè)務(wù)日志三類: 鏈路日志 :鏈路單次執(zhí)行中,從開始節(jié)點(diǎn)和結(jié)束節(jié)點(diǎn)的日志中提取的鏈路基本信息,包含鏈路類型、鏈路元信息、鏈路開始/結(jié)束時(shí)間等。
節(jié)點(diǎn)日志 :鏈路單次執(zhí)行中,已執(zhí)行節(jié)點(diǎn)的基本信息,包含節(jié)點(diǎn)名稱、節(jié)點(diǎn)狀態(tài)、節(jié)點(diǎn)開始/結(jié)束時(shí)間等。
業(yè)務(wù)日志 :鏈路單次執(zhí)行中,已執(zhí)行節(jié)點(diǎn)中的業(yè)務(wù)日志信息,包含日志級(jí)別、日志時(shí)間、日志數(shù)據(jù)等。 下圖就是鏈路存儲(chǔ)的存儲(chǔ)模型,包含了鏈路日志,節(jié)點(diǎn)日志,業(yè)務(wù)日志、鏈路元數(shù)據(jù)( 配置數(shù)據(jù) ),并且是如下圖9所示的樹狀結(jié)構(gòu),其中業(yè)務(wù)標(biāo)識(shí)作為根節(jié)點(diǎn),用于后續(xù)的鏈路查詢。 圖9 鏈路的樹狀存儲(chǔ)結(jié)構(gòu) 3. 大眾點(diǎn)評(píng)內(nèi)容平臺(tái)實(shí)踐 3.1 業(yè)務(wù)特點(diǎn)與挑戰(zhàn) 互聯(lián)網(wǎng)時(shí)代,內(nèi)容為王。內(nèi)容型平臺(tái)的核心打法就是搭建內(nèi)容流水線,保障內(nèi)容可持續(xù)、健康且有價(jià)值地流轉(zhuǎn)到內(nèi)容消費(fèi)者,并最終形成內(nèi)容“生產(chǎn)→治理→消費(fèi)→生產(chǎn)”的良性循環(huán)。 大眾點(diǎn)評(píng)和美團(tuán)App擁有豐富多樣的內(nèi)容,站內(nèi)外業(yè)務(wù)方、合作方有著眾多的消費(fèi)場景。對(duì)于內(nèi)容流水線中的三方,分別有如下需求: 生產(chǎn)方的內(nèi)容模型各異、所需處理手段各不相同,消費(fèi)方對(duì)于內(nèi)容也有著個(gè)性化的要求。如果由各個(gè)生產(chǎn)方和消費(fèi)方單獨(dú)對(duì)接,內(nèi)容模型異構(gòu) 、處理流程和輸出門檻各異 的問題將帶來對(duì)接的高成本和低效率。在此背景下,點(diǎn)評(píng)內(nèi)容平臺(tái) 應(yīng)運(yùn)而生,作為內(nèi)容流水線的“治理方”,承上啟下實(shí)現(xiàn)了內(nèi)容的統(tǒng)一接入、統(tǒng)一處理和統(tǒng)一輸出: 圖10 點(diǎn)評(píng)內(nèi)容平臺(tái)業(yè)務(wù)形態(tài) 統(tǒng)一接入 :統(tǒng)一內(nèi)容數(shù)據(jù)模型,對(duì)接不同的內(nèi)容生產(chǎn)方,將異構(gòu)的內(nèi)容轉(zhuǎn)化為內(nèi)容平臺(tái)通用的數(shù)據(jù)模型。
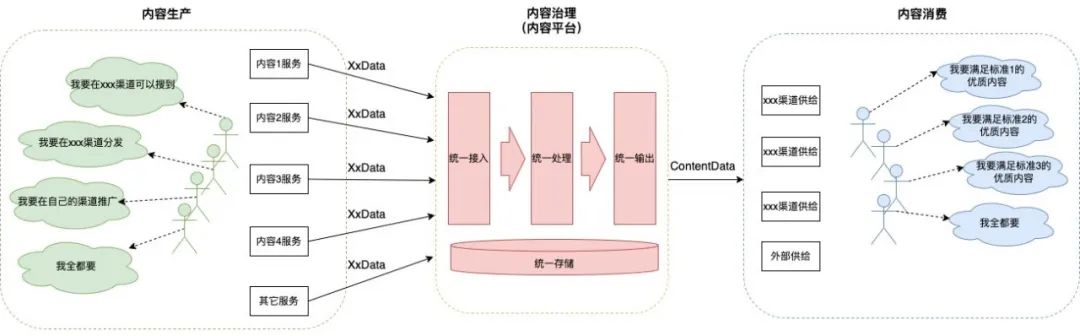
統(tǒng)一處理 :統(tǒng)一處理能力建設(shè),積累并完善通用的機(jī)器處理和人工運(yùn)營能力,保證內(nèi)容合法合規(guī),屬性豐富。
統(tǒng)一輸出 :統(tǒng)一輸出門檻建設(shè),對(duì)接不同的內(nèi)容消費(fèi)方,為下游提供規(guī)范且滿足其個(gè)性化需求的內(nèi)容數(shù)據(jù)。 如下圖11所示,是點(diǎn)評(píng)內(nèi)容平臺(tái)的核心業(yè)務(wù)流程,每一條內(nèi)容都會(huì)經(jīng)過這個(gè)流程,最終決定在各個(gè)渠道下是否分發(fā)。 圖11 點(diǎn)評(píng)內(nèi)容平臺(tái)業(yè)務(wù)流程 內(nèi)容是否及時(shí)、準(zhǔn)確經(jīng)過內(nèi)容平臺(tái)的處理,是內(nèi)容生產(chǎn)方和消費(fèi)方的核心關(guān)注,也是日常值班的主要客訴類型。而內(nèi)容平臺(tái)的業(yè)務(wù)追蹤建設(shè),主要面臨以下的困難與復(fù)雜性: 業(yè)務(wù)場景多 :業(yè)務(wù)流程涉及多個(gè)不同的業(yè)務(wù)場景,且邏輯各異,例如實(shí)時(shí)接入、人工運(yùn)營、分發(fā)重算等圖中列出的部分場景。
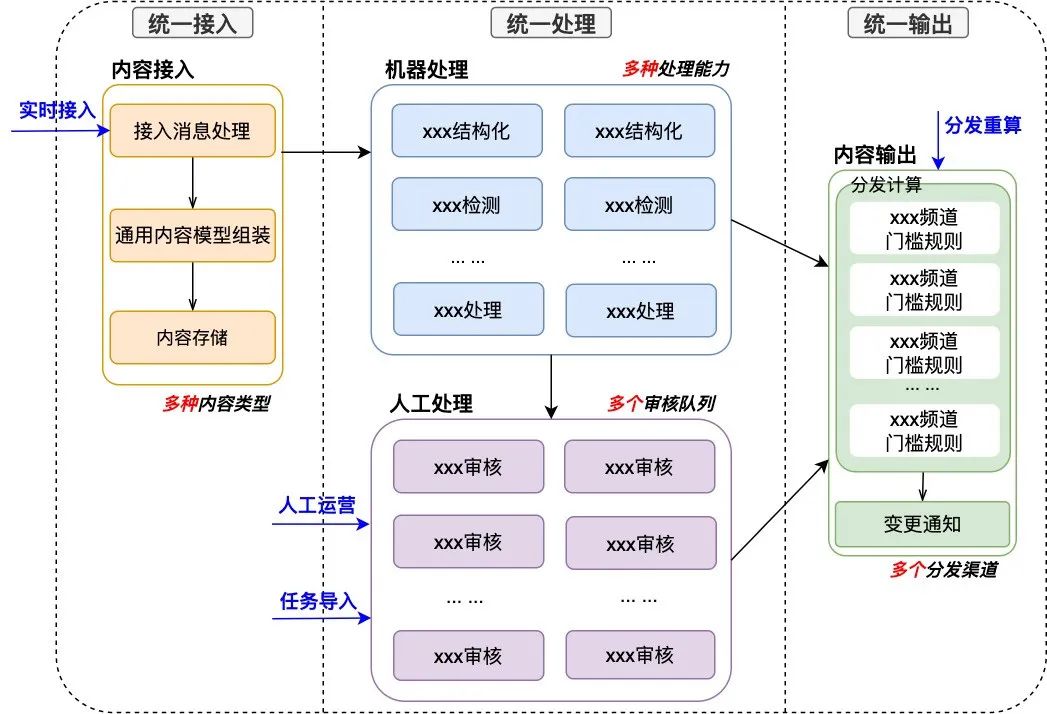
邏輯節(jié)點(diǎn)多 :業(yè)務(wù)場景涉及眾多的邏輯節(jié)點(diǎn),且不同內(nèi)容類型節(jié)點(diǎn)各異,例如同樣是實(shí)時(shí)接入場景,筆記內(nèi)容和直播內(nèi)容在執(zhí)行的邏輯節(jié)點(diǎn)上存在較大差異。
觸發(fā)執(zhí)行多 :業(yè)務(wù)場景會(huì)被多次觸發(fā)執(zhí)行,且由于來源不同,邏輯也會(huì)存在差異,例如筆記內(nèi)容被作者編輯、被系統(tǒng)審核等等后,都會(huì)觸發(fā)實(shí)時(shí)接入場景的重新執(zhí)行。 點(diǎn)評(píng)內(nèi)容平臺(tái)日均處理百萬條內(nèi)容,涉及百萬次業(yè)務(wù)場景的執(zhí)行、高達(dá)億級(jí)的邏輯節(jié)點(diǎn)的執(zhí)行,而業(yè)務(wù)日志分散在不同的應(yīng)用中,并且不同內(nèi)容,不同場景,不同節(jié)點(diǎn)以及多次執(zhí)行的日志混雜在一起,無論是日志的搜集還是現(xiàn)場的還原都相當(dāng)繁瑣耗時(shí),傳統(tǒng)的業(yè)務(wù)追蹤方案越來越不適用于內(nèi)容平臺(tái)。 點(diǎn)評(píng)內(nèi)容平臺(tái)亟需新的解決方案,實(shí)現(xiàn)高效的業(yè)務(wù)追蹤,因此我們進(jìn)行了可視化全鏈路日志追蹤 的建設(shè),下面本文將介紹一下相關(guān)的實(shí)踐和成果。 3.2 實(shí)踐與成果 3.2.1 實(shí)踐 點(diǎn)評(píng)內(nèi)容平臺(tái)是一個(gè)復(fù)雜的業(yè)務(wù)系統(tǒng),對(duì)外支撐著眾多的業(yè)務(wù)場景,通過對(duì)于業(yè)務(wù)場景的梳理和抽象,可以定義出實(shí)時(shí)接入、人工運(yùn)營、任務(wù)導(dǎo)入、分發(fā)重算等多個(gè)業(yè)務(wù)邏輯鏈路。由于點(diǎn)評(píng)內(nèi)容平臺(tái)涉及眾多的內(nèi)部服務(wù)和下游依賴服務(wù),每天支撐著大量的內(nèi)容處理業(yè)務(wù),伴隨著業(yè)務(wù)的執(zhí)行將生成大量的日志數(shù)據(jù),與此同時(shí)鏈路上報(bào)還需要對(duì)眾多的服務(wù)進(jìn)行改造。因此在通用的全鏈路日志追蹤方案的基礎(chǔ)上,點(diǎn)評(píng)內(nèi)容平臺(tái)進(jìn)行了如下的具體實(shí)踐。 (1) 支持大數(shù)據(jù)量日志的上報(bào)和存儲(chǔ) 點(diǎn)評(píng)內(nèi)容平臺(tái)實(shí)現(xiàn)了圖12所示的日志上報(bào)架構(gòu),支持眾多服務(wù)統(tǒng)一的日志收集、處理和存儲(chǔ),能夠很好地支撐大數(shù)據(jù)量下的日志追蹤建設(shè)。 圖12 點(diǎn)評(píng)內(nèi)容平臺(tái)日志上報(bào)架構(gòu) 日志收集 :各應(yīng)用服務(wù)通過機(jī)器上部署的log_agent收集異步上報(bào)的日志數(shù)據(jù),并統(tǒng)一傳輸至Kafka通道中,此外針對(duì)少量不支持log_agent的服務(wù),搭建了如圖所示的中轉(zhuǎn)應(yīng)用。日志解析 :收集的日志通過Kafka接入到Flink中,統(tǒng)一進(jìn)行解析和處理,根據(jù)日志類型對(duì)日志進(jìn)行分類和聚合,解析為鏈路日志、節(jié)點(diǎn)日志和業(yè)務(wù)日志。日志存儲(chǔ) :完成日志解析后,日志會(huì)按照樹狀的存儲(chǔ)模型進(jìn)行落地存儲(chǔ),結(jié)合存儲(chǔ)的需求分析以及各個(gè)存儲(chǔ)選項(xiàng)的特點(diǎn),點(diǎn)評(píng)內(nèi)容平臺(tái)最終選擇HBase 作為存儲(chǔ)選型。
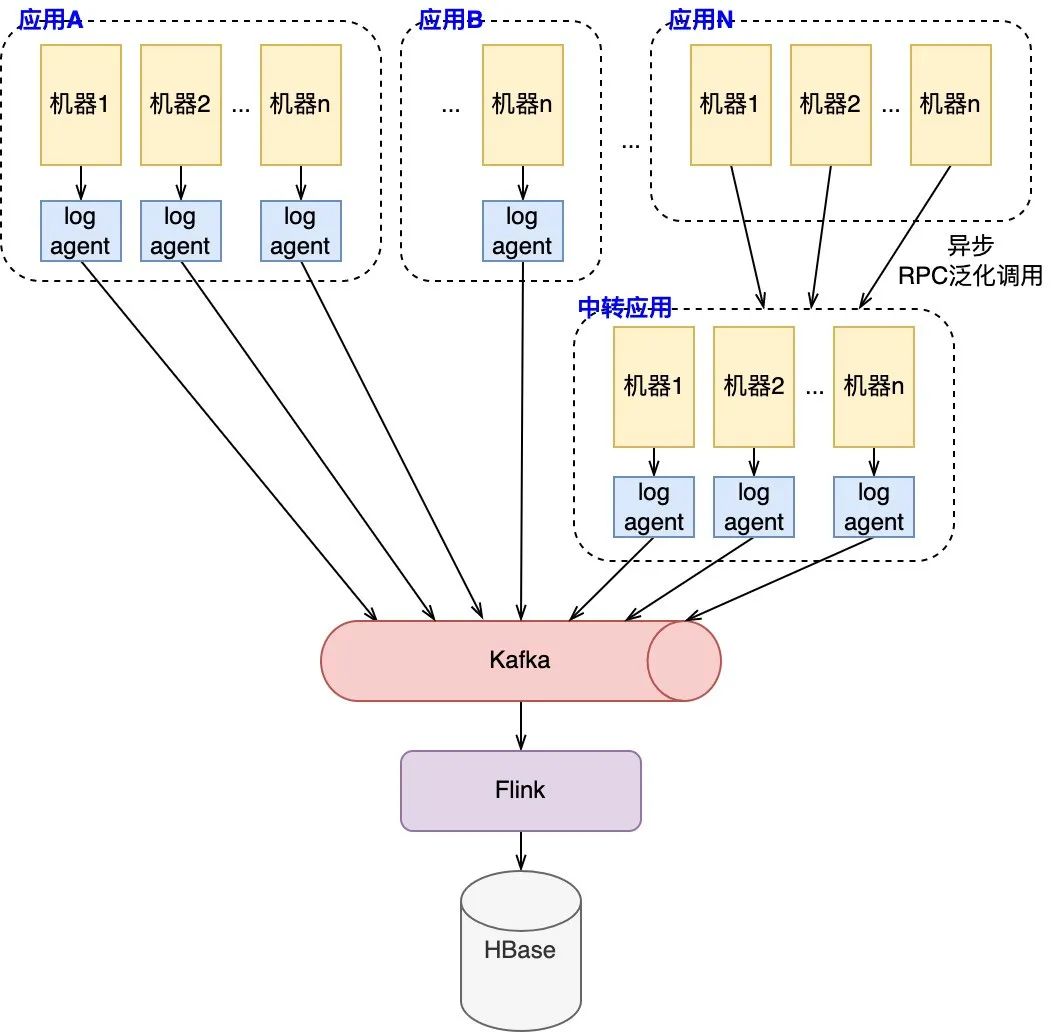
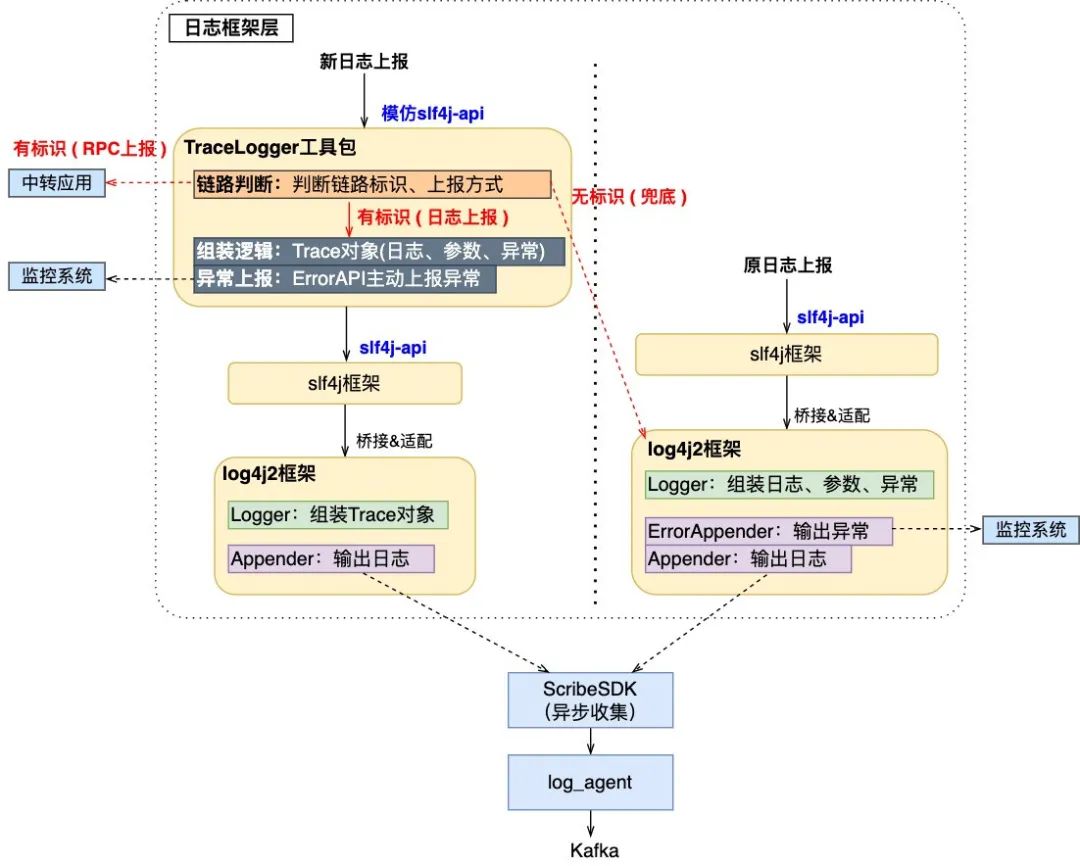
整體而言,log_agent + Kafka + Flink + HBase的日志上報(bào)和存儲(chǔ)架構(gòu)能夠很好地支持復(fù)雜的業(yè)務(wù)系統(tǒng),天然支持分布式場景下眾多應(yīng)用的日志上報(bào),同時(shí)適用于高流量的數(shù)據(jù)寫入。 (2) 實(shí)現(xiàn)眾多后端服務(wù)的低成本改造 點(diǎn)評(píng)內(nèi)容平臺(tái)實(shí)現(xiàn)了“自定義日志工具包”( 即下圖13的TraceLogger工具包 ),屏蔽鏈路追蹤中的上報(bào)細(xì)節(jié),實(shí)現(xiàn)眾多服務(wù)改造的成本最小化。TraceLogger工具包的功能包括: 模仿slf4j-api :工具包的實(shí)現(xiàn)在slf4j框架之上,并模仿slf4j-api對(duì)外提供相同的API,因此使用方無學(xué)習(xí)成本。屏蔽內(nèi)部細(xì)節(jié),內(nèi)部封裝一系列的鏈路日志上報(bào)邏輯,屏蔽染色等細(xì)節(jié),降低使用方的開發(fā)成本。 日志組裝 :實(shí)現(xiàn)參數(shù)占位、異常堆棧輸出等功能,并將相關(guān)數(shù)據(jù)組裝為Trace對(duì)象,便于進(jìn)行統(tǒng)一的收集和處理。 異常上報(bào) :通過ErrorAPI主動(dòng)上報(bào)異常,兼容原日志上報(bào)中ErrorAppender。 日志上報(bào) :適配Log4j2日志框架實(shí)現(xiàn)最終的日志上報(bào)。
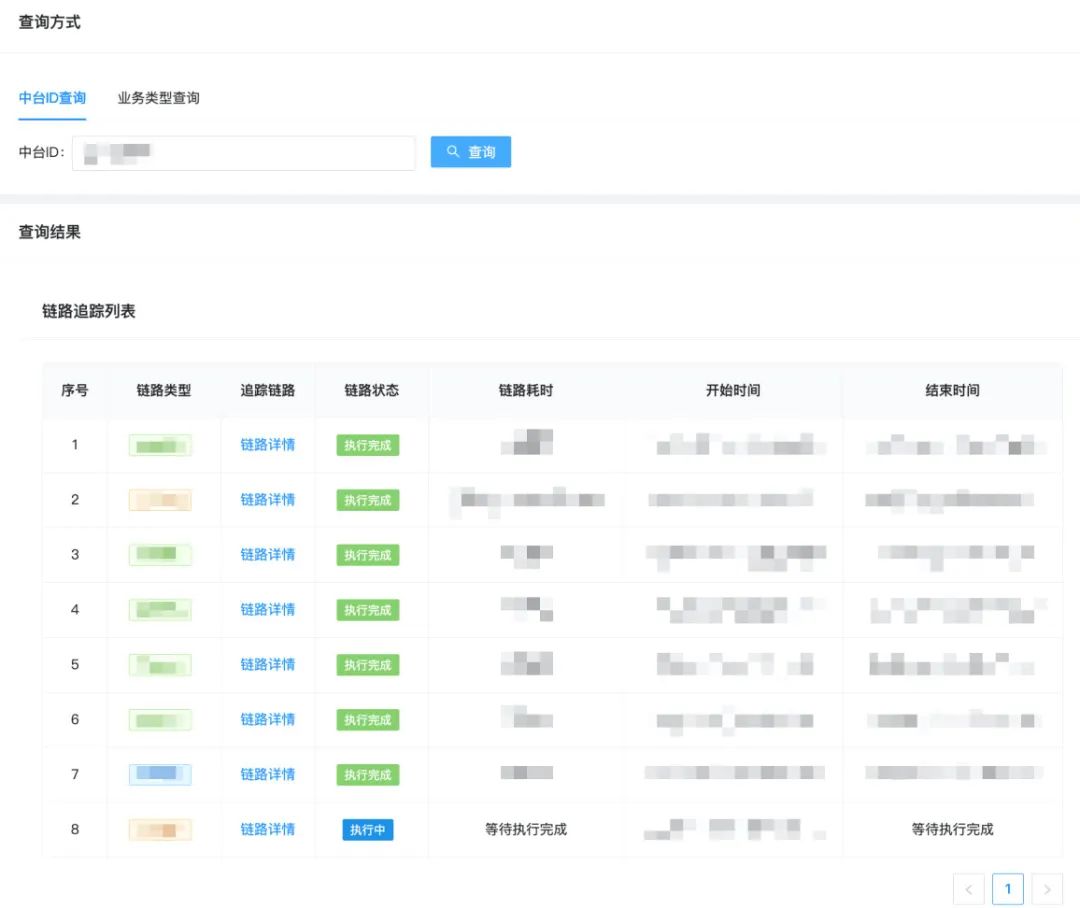
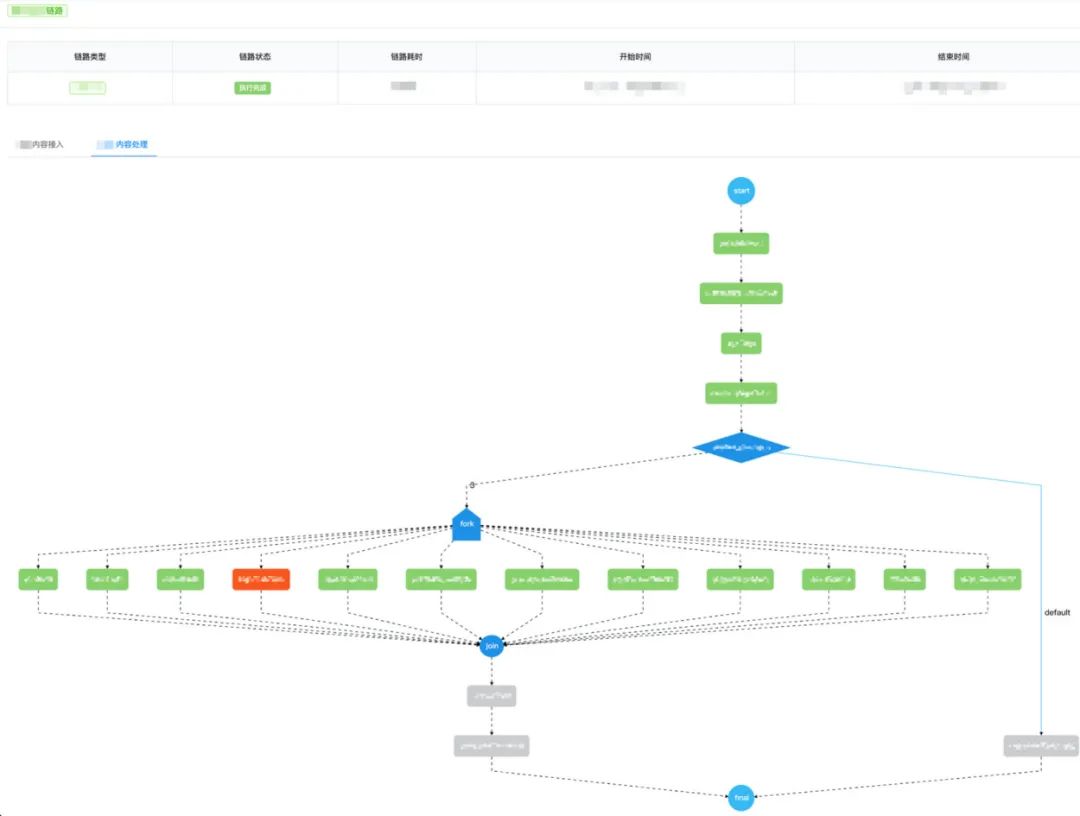
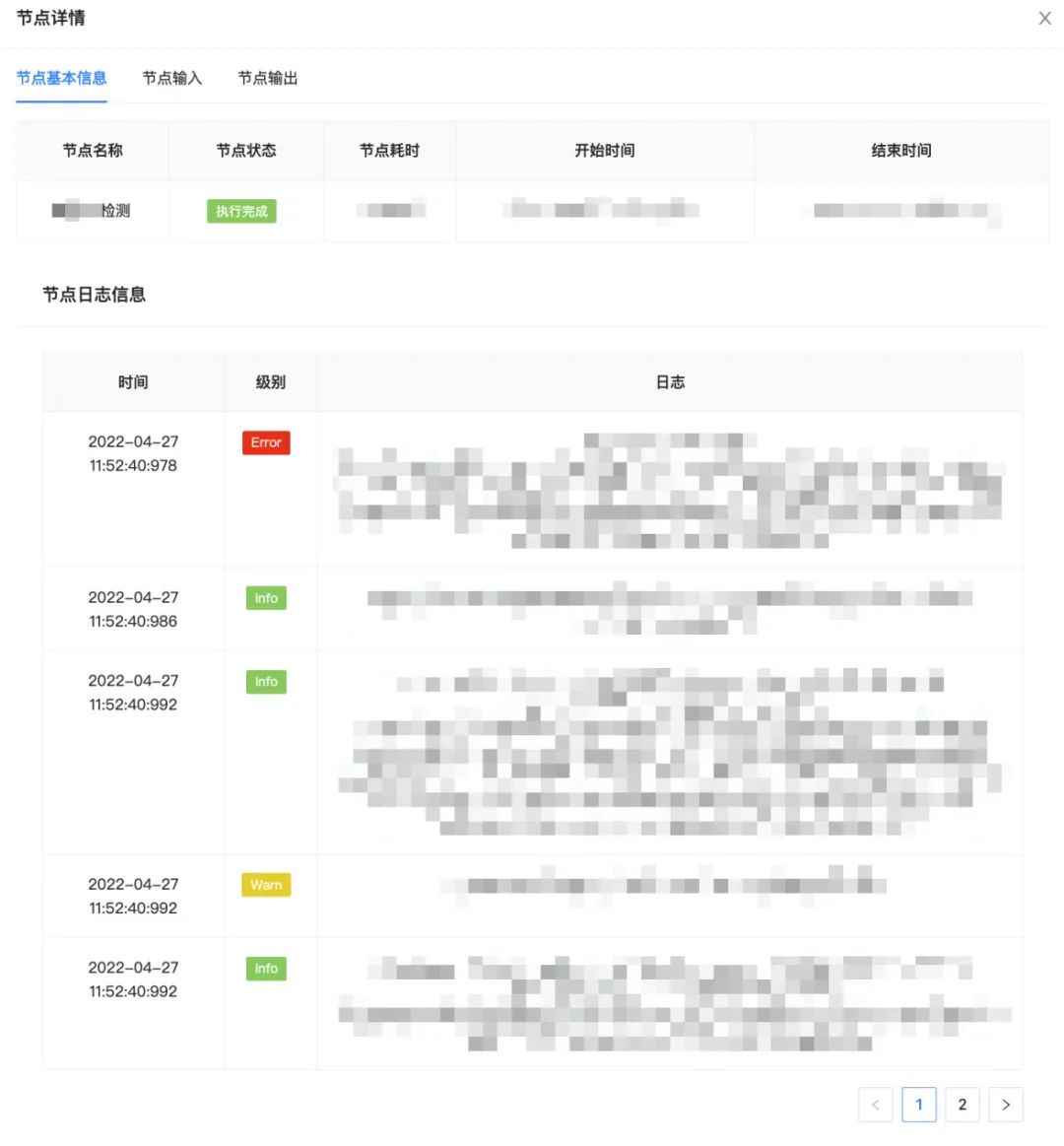
圖13 TraceLogger日志工具包 下面是TraceLogger工具包分別進(jìn)行業(yè)務(wù)日志 和節(jié)點(diǎn)日志 上報(bào)的使用案例,整體的改造成本較低。 業(yè)務(wù)日志上報(bào) :無學(xué)習(xí)成本,基本無改造成本。 // 替換前:原日志上報(bào)"update struct failed, param:{}" , GsonUtils.toJson(structRequest), e);"update struct failed, param:{}" , GsonUtils.toJson(structRequest), e); 節(jié)點(diǎn)日志上報(bào) :支持API、AOP兩種上報(bào)方式,靈活且成本低。案例 :節(jié)點(diǎn)日志上報(bào) "contentId_type_uuid" );"contentStore" , contentId, StatusEnums.RUNNING)"contentStore" , structResp, StatusEnums.COMPLETED)"picProcess" )"picProcess failed, contentId:{}" , contentId);3.2.2 成果 基于上述實(shí)踐,點(diǎn)評(píng)內(nèi)容平臺(tái)實(shí)現(xiàn)了可視化全鏈路日志追蹤,能夠一鍵追蹤任意一條內(nèi)容所有業(yè)務(wù)場景的執(zhí)行,并通過可視化的鏈路進(jìn)行執(zhí)行現(xiàn)場的還原,追蹤效果如下圖所示: 【鏈路查詢功能】 :根據(jù)內(nèi)容id實(shí)時(shí)查詢?cè)搩?nèi)容所有的邏輯鏈路執(zhí)行,覆蓋所有的業(yè)務(wù)場景。圖14 鏈路查詢 【鏈路展示功能】 :通過鏈路圖可視化展示業(yè)務(wù)邏輯的全景,同時(shí)展示各個(gè)節(jié)點(diǎn)的執(zhí)行情況。圖15 鏈路展示 【節(jié)點(diǎn)詳情查詢功能】 :支持展示任意已執(zhí)行節(jié)點(diǎn)的詳情,包括節(jié)點(diǎn)輸入、輸出,以及節(jié)點(diǎn)執(zhí)行過程中的關(guān)鍵業(yè)務(wù)日志。圖16 節(jié)點(diǎn)詳情 目前,可視化全鏈路日志追蹤系統(tǒng)已經(jīng)成為點(diǎn)評(píng)內(nèi)容平臺(tái)的“問題排查工具”,我們可以將問題排查耗時(shí)從小時(shí)級(jí)降低到5分鐘內(nèi);同時(shí)也是“測試輔助工具”,利用可視化的日志串聯(lián)和展示,明顯提升了RD自測、QA測試的效率。最后總結(jié)一下可視化全鏈路日志追蹤的優(yōu)點(diǎn): 4. 總結(jié)與展望 隨著分布式業(yè)務(wù)系統(tǒng)的日益復(fù)雜,可觀測性對(duì)于業(yè)務(wù)系統(tǒng)的穩(wěn)定運(yùn)行也愈發(fā)重要[6] 。作為大眾點(diǎn)評(píng)內(nèi)容流水線中的復(fù)雜業(yè)務(wù)系統(tǒng),為了保障內(nèi)容流轉(zhuǎn)的穩(wěn)定可靠,點(diǎn)評(píng)內(nèi)容平臺(tái)落地了全鏈路的可觀測建設(shè) ,在日志 ( Logging )、指標(biāo) ( Metrics )和追蹤 ( Tracing )的三個(gè)具體方向上都進(jìn)行了一定的探索和建設(shè)。 其中之一就是本文的“可視化全鏈路日志追蹤”,結(jié)合日志 ( Logging )與追蹤 ( Tracing ),我們提出了一套新的業(yè)務(wù)追蹤通用方案,通過在業(yè)務(wù)執(zhí)行階段,結(jié)合完整的業(yè)務(wù)邏輯動(dòng)態(tài)完成日志的組織串聯(lián),替代了傳統(tǒng)方案低效且滯后的人工日志串聯(lián),最終可以實(shí)現(xiàn)業(yè)務(wù)全流程的高效追蹤以及業(yè)務(wù)問題的高效定位。此外,在指標(biāo) ( Metrics )方向上,點(diǎn)評(píng)內(nèi)容平臺(tái)實(shí)踐落地了“可視化全鏈路指標(biāo)監(jiān)控”,支持實(shí)時(shí)、多維度地展示業(yè)務(wù)系統(tǒng)的關(guān)鍵業(yè)務(wù)和技術(shù)指標(biāo),同時(shí)支持相應(yīng)的告警和異常歸因能力,實(shí)現(xiàn)了對(duì)業(yè)務(wù)系統(tǒng)整體運(yùn)行狀況的有效把控。 未來,點(diǎn)評(píng)內(nèi)容平臺(tái)會(huì)持續(xù)深耕,實(shí)現(xiàn)覆蓋告警、概況、排錯(cuò)和剖析等功能的可觀測體系[7] ,持續(xù)沉淀和輸出相關(guān)的通用方案,希望可以為業(yè)務(wù)系統(tǒng)( 特別是復(fù)雜的業(yè)務(wù)系統(tǒng) ),提供一些可觀測性建設(shè)的借鑒和啟發(fā)。 5. 參考文獻(xiàn) [1] Metrics, tracing, and logging [2] ELK Stack: Elasticsearch, Logstash, Kibana | Elastic [3] Dapper, a Large-Scale Distributed Systems Tracing Infrastructure [4] OpenZipkin · A distributed tracing system [5] 分布式會(huì)話跟蹤系統(tǒng)架構(gòu)設(shè)計(jì)與實(shí)踐 6. 作者及團(tuán)隊(duì)簡介 海友、懷宇、亞平、立森等,均來自點(diǎn)評(píng)事業(yè)部/內(nèi)容平臺(tái)技術(shù)團(tuán)隊(duì),負(fù)責(zé)點(diǎn)評(píng)內(nèi)容平臺(tái)的建設(shè)工作。 點(diǎn)評(píng)內(nèi)容平臺(tái)技術(shù)團(tuán)隊(duì),支持點(diǎn)評(píng)內(nèi)容生態(tài)的建設(shè),致力于打造支持億級(jí)內(nèi)容的高吞吐、低延時(shí)、高可用、靈活可擴(kuò)展的內(nèi)容流式處理系統(tǒng),為點(diǎn)評(píng)信息流和搜索等核心內(nèi)容分發(fā)場景提供豐富且優(yōu)質(zhì)的內(nèi)容供給,更好地滿足用戶內(nèi)容消費(fèi)訴求。