
全網(wǎng)最硬核 Redis 大廠面試題解析(2021年最新版)
前言
最近囧輝發(fā)現(xiàn)自己的 Java 學(xué)習(xí)交流群 里有不少同學(xué)已經(jīng)“悄悄”的入職了攜程、美團(tuán)、阿里菜鳥等大廠。
有不少同學(xué)也在積極準(zhǔn)備大廠面試中,從聊天中可以看得出來大家都信心滿滿。

其中有一個同學(xué)我印象特別深刻,因?yàn)槲医?jīng)常晚上發(fā)文章,然后隔天早上起來就看到他的點(diǎn)贊了,看得出來是有認(rèn)真在看的同學(xué)。
最近他已經(jīng)入職阿里菜鳥了,可以說是“悄悄的努力,驚艷所有人”的典范。
希望大家都能像他一樣,早日拿下大廠 Offer。
回歸本文,對于 Redis 在面試中的重要程度,一句話描述就是:在當(dāng)前 Java 后端面試中,所有框架/中間件中被問到頻率最高的。
本文按 BAT 面試標(biāo)準(zhǔn)給出解析,有些題你閱讀起來可能會很吃力,建議收藏反復(fù)學(xué)習(xí)。
希望在這金三銀四的日子里,祝你一臂之力,拿下大廠 Offer。
面試系列
我自己前前后后加起來總共應(yīng)該參加了不下四五十次的面試,拿到過幾乎所有一線大廠的 offer:阿里、字節(jié)、美團(tuán)、快手、拼多多等等。
每次面試后我都會將面試的題目進(jìn)行記錄,并整理成自己的題庫,最近我將這些題目整理出來,并按大廠的標(biāo)準(zhǔn)給出自己的解析,希望在這金三銀四的季節(jié)里,能助你一臂之力。
面試文章持續(xù)更新中...
正文
1、Redis 是單線程還是多線程?
這個問題應(yīng)該已經(jīng)看到過無數(shù)次了,最近 redis 6 出來之后又被翻出來了。
redis 4.0 之前,redis 是完全單線程的。
redis 4.0 時,redis 引入了多線程,但是額外的線程只是用于后臺處理,例如:刪除對象,核心流程還是完全單線程的。這也是為什么有些人說 4.0 是單線程的,因?yàn)樗麄冎傅氖呛诵牧鞒淌菃尉€程的。
這邊的核心流程指的是 redis 正常處理客戶端請求的流程,通常包括:接收命令、解析命令、執(zhí)行命令、返回結(jié)果等。
而在最近,redis 6.0 版本又一次引入了多線程概念,與 4.0 不同的是,這次的多線程會涉及到上述的核心流程。
redis 6.0 中,多線程主要用于網(wǎng)絡(luò) I/O 階段,也就是接收命令和寫回結(jié)果階段,而在執(zhí)行命令階段,還是由單線程串行執(zhí)行。由于執(zhí)行時還是串行,因此無需考慮并發(fā)安全問題。
值得注意的時,redis 中的多線程組不會同時存在“讀”和“寫”,這個多線程組只會同時“讀”或者同時“寫”。
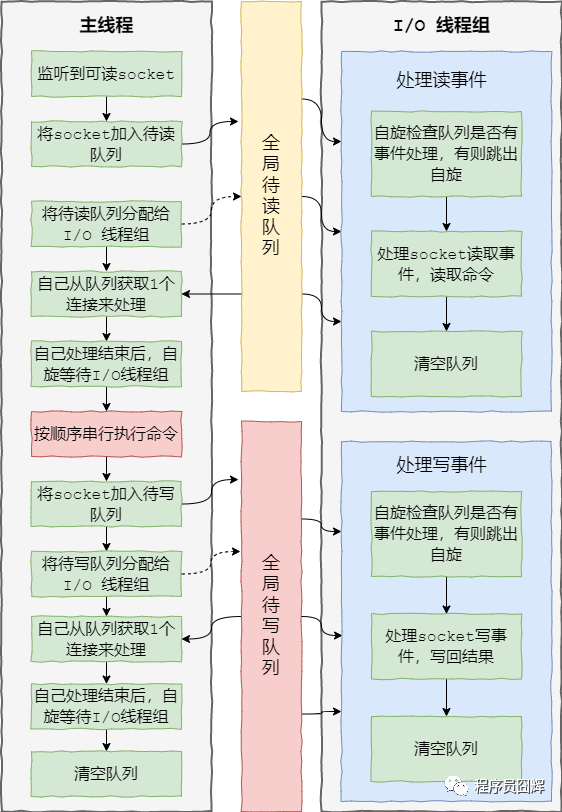
redis 6.0 加入多線程 I/O 之后,處理命令的核心流程如下:
1、當(dāng)有讀事件到來時,主線程將該客戶端連接放到全局等待讀隊列
2、讀取數(shù)據(jù):1)主線程將等待讀隊列的客戶端連接通過輪詢調(diào)度算法分配給 I/O 線程處理;2)同時主線程也會自己負(fù)責(zé)處理一個客戶端連接的讀事件;3)當(dāng)主線程處理完該連接的讀事件后,會自旋等待所有 I/O 線程處理完畢
3、命令執(zhí)行:主線程按照事件被加入全局等待讀隊列的順序(這邊保證了執(zhí)行順序是正確的),串行執(zhí)行客戶端命令,然后將客戶端連接放到全局等待寫隊列
4、寫回結(jié)果:跟等待讀隊列處理類似,主線程將等待寫隊列的客戶端連接使用輪詢調(diào)度算法分配給 I/O 線程處理,同時自己也會處理一個,當(dāng)主線程處理完畢后,會自旋等待所有 I/O 線程處理完畢,最后清空隊列。
大致流程圖如下:
2、為什么 Redis 是單線程?
在 redis 6.0 之前,redis 的核心操作是單線程的。
因?yàn)?redis 是完全基于內(nèi)存操作的,通常情況下CPU不會是redis的瓶頸,redis 的瓶頸最有可能是機(jī)器內(nèi)存的大小或者網(wǎng)絡(luò)帶寬。
既然CPU不會成為瓶頸,那就順理成章地采用單線程的方案了,因?yàn)槿绻褂枚嗑€程的話會更復(fù)雜,同時需要引入上下文切換、加鎖等等,會帶來額外的性能消耗。
而隨著近些年互聯(lián)網(wǎng)的不斷發(fā)展,大家對于緩存的性能要求也越來越高了,因此 redis 也開始在逐漸往多線程方向發(fā)展。
最近的 6.0 版本就對核心流程引入了多線程,主要用于解決 redis 在網(wǎng)絡(luò) I/O 上的性能瓶頸。而對于核心的命令執(zhí)行階段,目前還是單線程的。
3、Redis 為什么使用單進(jìn)程、單線程也很快
主要有以下幾點(diǎn):
1、基于內(nèi)存的操作
2、使用了 I/O 多路復(fù)用模型,select、epoll 等,基于 reactor 模式開發(fā)了自己的網(wǎng)絡(luò)事件處理器
3、單線程可以避免不必要的上下文切換和競爭條件,減少了這方面的性能消耗。
4、以上這三點(diǎn)是 redis 性能高的主要原因,其他的還有一些小優(yōu)化,例如:對數(shù)據(jù)結(jié)構(gòu)進(jìn)行了優(yōu)化,簡單動態(tài)字符串、壓縮列表等。
4、Redis 在項(xiàng)目中的使用場景
緩存(核心)、分布式鎖(set + lua 腳本)、排行榜(zset)、計數(shù)(incrby)、消息隊列(stream)、地理位置(geo)、訪客統(tǒng)計(hyperloglog)等。
5、Redis 常見的數(shù)據(jù)結(jié)構(gòu)
基礎(chǔ)的5種:
String:字符串,最基礎(chǔ)的數(shù)據(jù)類型。
List:列表。
Hash:哈希對象。
Set:集合。
Sorted Set:有序集合,Set 的基礎(chǔ)上加了個分值。
高級的4種:
HyperLogLog:通常用于基數(shù)統(tǒng)計。使用少量固定大小的內(nèi)存,來統(tǒng)計集合中唯一元素的數(shù)量。統(tǒng)計結(jié)果不是精確值,而是一個帶有0.81%標(biāo)準(zhǔn)差(standard error)的近似值。所以,HyperLogLog適用于一些對于統(tǒng)計結(jié)果精確度要求不是特別高的場景,例如網(wǎng)站的UV統(tǒng)計。
Geo:redis 3.2 版本的新特性。可以將用戶給定的地理位置信息儲存起來, 并對這些信息進(jìn)行操作:獲取2個位置的距離、根據(jù)給定地理位置坐標(biāo)獲取指定范圍內(nèi)的地理位置集合。
Bitmap:位圖。
Stream:主要用于消息隊列,類似于 kafka,可以認(rèn)為是 pub/sub 的改進(jìn)版。提供了消息的持久化和主備復(fù)制功能,可以讓任何客戶端訪問任何時刻的數(shù)據(jù),并且能記住每一個客戶端的訪問位置,還能保證消息不丟失。
6、Redis 的字符串(SDS)和C語言的字符串區(qū)別
C字符串 | SDS |
|---|---|
獲取字符串長度的復(fù)雜度為O(N) | 獲取字符串長度的復(fù)雜度為O(1) |
API是不安全的,可能會造成緩沖區(qū)溢出 | API是安全的,不會造成緩沖區(qū)溢出 |
修改字符串長度N次必然需要執(zhí)行N次內(nèi)存重分配 | 修改字符串長度N次最多需要執(zhí)行N次內(nèi)存重分配 |
只能保存文本數(shù)據(jù) | 可以保存文本數(shù)據(jù)或者二進(jìn)制數(shù)據(jù) |
可以使用所有的<string.h>庫中的函數(shù) | 可以使用一部分<string.h>庫中的函數(shù) |
7、Sorted Set底層數(shù)據(jù)結(jié)構(gòu)
Sorted Set(有序集合)當(dāng)前有兩種編碼:ziplist、skiplist
ziplist:使用壓縮列表實(shí)現(xiàn),當(dāng)保存的元素長度都小于64字節(jié),同時數(shù)量小于128時,使用該編碼方式,否則會使用 skiplist。這兩個參數(shù)可以通過 zset-max-ziplist-entries、zset-max-ziplist-value 來自定義修改。

skiplist:zset實(shí)現(xiàn),一個zset同時包含一個字典(dict)和一個跳躍表(zskiplist)
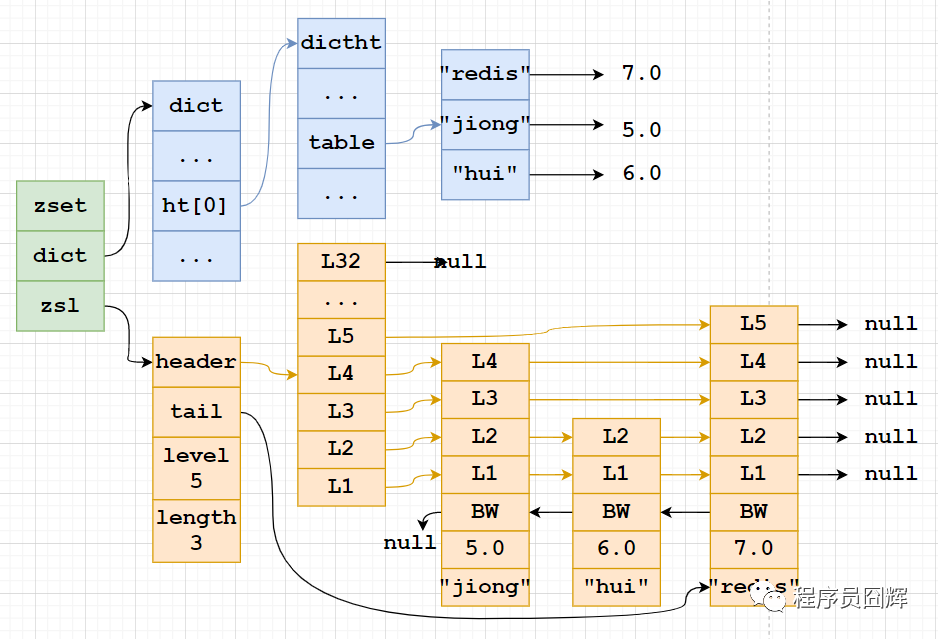
8、Sorted Set 為什么同時使用字典和跳躍表?
主要是為了提升性能。
單獨(dú)使用字典:在執(zhí)行范圍型操作,比如 zrank、zrange,字典需要進(jìn)行排序,至少需要 O(NlogN) 的時間復(fù)雜度及額外 O(N) 的內(nèi)存空間。
單獨(dú)使用跳躍表:根據(jù)成員查找分值操作的復(fù)雜度從 O(1) 上升為 O(logN)。
9、Sorted Set 為什么使用跳躍表,而不是紅黑樹?
主要有以下幾個原因:
1)跳表的性能和紅黑樹差不多。
2)跳表更容易實(shí)現(xiàn)和調(diào)試。
網(wǎng)上有同學(xué)說是因?yàn)樽髡卟粫t黑樹,我覺得挺有可能的。

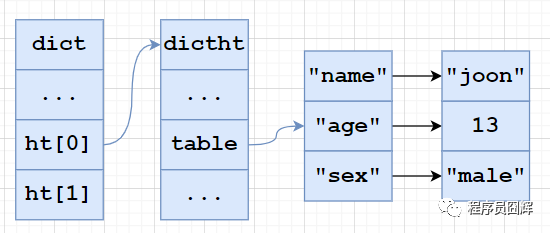
10、Hash 對象底層結(jié)構(gòu)
Hash 對象當(dāng)前有兩種編碼:ziplist、hashtable
ziplist:使用壓縮列表實(shí)現(xiàn),每當(dāng)有新的鍵值對要加入到哈希對象時,程序會先將保存了鍵的節(jié)點(diǎn)推入到壓縮列表的表尾,然后再將保存了值的節(jié)點(diǎn)推入到壓縮列表表尾。
因此:1)保存了同一鍵值對的兩個節(jié)點(diǎn)總是緊挨在一起,保存鍵的節(jié)點(diǎn)在前,保存值的節(jié)點(diǎn)在后;2)先添加到哈希對象中的鍵值對會被放在壓縮列表的表頭方向,而后來添加的會被放在表尾方向。

hashtable:使用字典作為底層實(shí)現(xiàn),哈希對象中的每個鍵值對都使用一個字典鍵值來保存,跟 java 中的 HashMap 類似。
11、Hash 對象的擴(kuò)容流程
hash 對象在擴(kuò)容時使用了一種叫“漸進(jìn)式 rehash”的方式,步驟如下:
1)計算新表 size、掩碼,為新表 ht[1] 分配空間,讓字典同時持有 ht[0] 和 ht[1] 兩個哈希表。
2)將 rehash 索引計數(shù)器變量 rehashidx 的值設(shè)置為0,表示 rehash 正式開始。
3)在 rehash 進(jìn)行期間,每次對字典執(zhí)行添加、刪除、査找、更新操作時,程序除了執(zhí)行指定的操作以外,還會觸發(fā)額外的 rehash 操作,在源碼中的 _dictRehashStep 方法。
_dictRehashStep:從名字也可以看出來,大意是 rehash 一步,也就是 rehash 一個索引位置。
該方法會從 ht[0] 表的 rehashidx 索引位置上開始向后查找,找到第一個不為空的索引位置,將該索引位置的所有節(jié)點(diǎn) rehash 到 ht[1],當(dāng)本次 rehash 工作完成之后,將 ht[0] 索引位置為 rehashidx 的節(jié)點(diǎn)清空,同時將 rehashidx 屬性的值加一。
4)將 rehash 分?jǐn)偟矫總€操作上確實(shí)是非常妙的方式,但是萬一此時服務(wù)器比較空閑,一直沒有什么操作,難道 redis 要一直持有兩個哈希表嗎?
答案當(dāng)然不是的。我們知道,redis 除了文件事件外,還有時間事件,redis 會定期觸發(fā)時間事件,這些時間事件用于執(zhí)行一些后臺操作,其中就包含 rehash 操作:當(dāng) redis 發(fā)現(xiàn)有字典正在進(jìn)行 rehash 操作時,會花費(fèi)1毫秒的時間,一起幫忙進(jìn)行 rehash。
5)隨著操作的不斷執(zhí)行,最終在某個時間點(diǎn)上,ht[0] 的所有鍵值對都會被 rehash 至 ht[1],此時 rehash 流程完成,會執(zhí)行最后的清理工作:釋放 ht[0] 的空間、將 ht[0] 指向 ht[1]、重置 ht[1]、重置 rehashidx 的值為 -1。
12、漸進(jìn)式 rehash 的優(yōu)點(diǎn)
漸進(jìn)式 rehash 的好處在于它采取分而治之的方式,將 rehash 鍵值對所需的計算工作均攤到對字典的每個添加、刪除、查找和更新操作上,從而避免了集中式 rehash 而帶來的龐大計算量。
在進(jìn)行漸進(jìn)式 rehash 的過程中,字典會同時使用 ht[0] 和 ht[1] 兩個哈希表, 所以在漸進(jìn)式 rehash 進(jìn)行期間,字典的刪除、査找、更新等操作會在兩個哈希表上進(jìn)行。例如,要在字典里面査找一個鍵的話,程序會先在 ht[0] 里面進(jìn)行査找,如果沒找到的話,就會繼續(xù)到 ht[1] 里面進(jìn)行査找,諸如此類。
另外,在漸進(jìn)式 rehash 執(zhí)行期間,新增的鍵值對會被直接保存到 ht[1], ht[0] 不再進(jìn)行任何添加操作,這樣就保證了 ht[0] 包含的鍵值對數(shù)量會只減不增,并隨著 rehash 操作的執(zhí)行而最終變成空表。
13、rehash 流程在數(shù)據(jù)量大的時候會有什么問題嗎(Hash 對象的擴(kuò)容流程在數(shù)據(jù)量大的時候會有什么問題嗎)
1)擴(kuò)容期開始時,會先給 ht[1] 申請空間,所以在整個擴(kuò)容期間,會同時存在 ht[0] 和 ht[1],會占用額外的空間。
2)擴(kuò)容期間同時存在 ht[0] 和 ht[1],查找、刪除、更新等操作有概率需要操作兩張表,耗時會增加。
3)redis 在內(nèi)存使用接近 maxmemory 并且有設(shè)置驅(qū)逐策略的情況下,出現(xiàn) rehash 會使得內(nèi)存占用超過 maxmemory,觸發(fā)驅(qū)逐淘汰操作,導(dǎo)致 master/slave 均有有大量的 key 被驅(qū)逐淘汰,從而出現(xiàn) master/slave 主從不一致。
14、Redis 的網(wǎng)絡(luò)事件處理器(Reactor 模式)
redis 基于 reactor 模式開發(fā)了自己的網(wǎng)絡(luò)事件處理器,由4個部分組成:套接字、I/O 多路復(fù)用程序、文件事件分派器(dispatcher)、以及事件處理器。
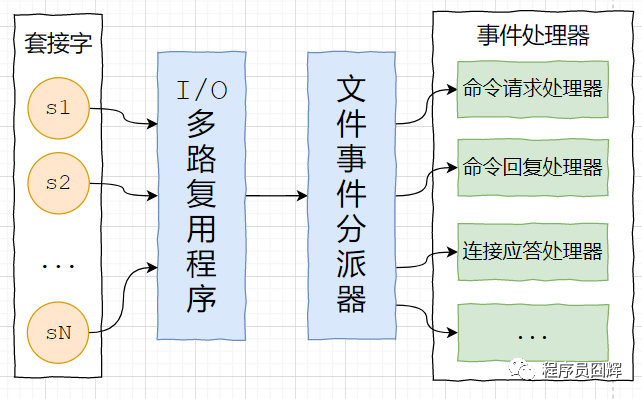
套接字:socket 連接,也就是客戶端連接。當(dāng)一個套接字準(zhǔn)備好執(zhí)行連接、寫入、讀取、關(guān)閉等操作時, 就會產(chǎn)生一個相應(yīng)的文件事件。因?yàn)橐粋€服務(wù)器通常會連接多個套接字, 所以多個文件事件有可能會并發(fā)地出現(xiàn)。
I/O 多路復(fù)用程序:提供 select、epoll、evport、kqueue 的實(shí)現(xiàn),會根據(jù)當(dāng)前系統(tǒng)自動選擇最佳的方式。負(fù)責(zé)監(jiān)聽多個套接字,當(dāng)套接字產(chǎn)生事件時,會向文件事件分派器傳送那些產(chǎn)生了事件的套接字。當(dāng)多個文件事件并發(fā)出現(xiàn)時, I/O 多路復(fù)用程序會將所有產(chǎn)生事件的套接字都放到一個隊列里面,然后通過這個隊列,以有序、同步、每次一個套接字的方式向文件事件分派器傳送套接字:當(dāng)上一個套接字產(chǎn)生的事件被處理完畢之后,才會繼續(xù)傳送下一個套接字。
文件事件分派器:接收 I/O 多路復(fù)用程序傳來的套接字, 并根據(jù)套接字產(chǎn)生的事件的類型, 調(diào)用相應(yīng)的事件處理器。
事件處理器:事件處理器就是一個個函數(shù), 定義了某個事件發(fā)生時, 服務(wù)器應(yīng)該執(zhí)行的動作。例如:建立連接、命令查詢、命令寫入、連接關(guān)閉等等。
15、Redis 刪除過期鍵的策略(緩存失效策略、數(shù)據(jù)過期策略)
定時刪除:在設(shè)置鍵的過期時間的同時,創(chuàng)建一個定時器,讓定時器在鍵的過期時間來臨時,立即執(zhí)行對鍵的刪除操作。對內(nèi)存最友好,對 CPU 時間最不友好。
惰性刪除:放任鍵過期不管,但是每次獲取鍵時,都檢査鍵是否過期,如果過期的話,就刪除該鍵;如果沒有過期,就返回該鍵。對 CPU 時間最優(yōu)化,對內(nèi)存最不友好。
定期刪除:每隔一段時間,默認(rèn)100ms,程序就對數(shù)據(jù)庫進(jìn)行一次檢査,刪除里面的過期鍵。至 于要刪除多少過期鍵,以及要檢査多少個數(shù)據(jù)庫,則由算法決定。前兩種策略的折中,對 CPU 時間和內(nèi)存的友好程度較平衡。
Redis 使用惰性刪除和定期刪除。
16、Redis 的內(nèi)存淘汰(驅(qū)逐)策略
當(dāng) redis 的內(nèi)存空間(maxmemory 參數(shù)配置)已經(jīng)用滿時,redis 將根據(jù)配置的驅(qū)逐策略(maxmemory-policy 參數(shù)配置),進(jìn)行相應(yīng)的動作。
網(wǎng)上很多資料都是寫 6 種,但是其實(shí)當(dāng)前 redis 的淘汰策略已經(jīng)有 8 種了,多余的兩種是 Redis 4.0 新增的,基于 LFU(Least Frequently Used)算法實(shí)現(xiàn)的。
noeviction:默認(rèn)策略,不淘汰任何 key,直接返回錯誤
allkeys-lru:在所有的 key 中,使用 LRU 算法淘汰部分 key
allkeys-lfu:在所有的 key 中,使用 LFU 算法淘汰部分 key,該算法于 Redis 4.0 新增
allkeys-random:在所有的 key 中,隨機(jī)淘汰部分 key
volatile-lru:在設(shè)置了過期時間的 key 中,使用 LRU 算法淘汰部分 key
volatile-lfu:在設(shè)置了過期時間的 key 中,使用 LFU 算法淘汰部分 key,該算法于 Redis 4.0 新增
volatile-random:在設(shè)置了過期時間的 key 中,隨機(jī)淘汰部分 key
volatile-ttl:在設(shè)置了過期時間的 key 中,挑選 TTL(time to live,剩余時間)短的 key 淘汰
17、Redis 的 LRU 算法怎么實(shí)現(xiàn)的?
Redis 在 redisObject 結(jié)構(gòu)體中定義了一個長度 24 bit 的 unsigned 類型的字段(unsigned lru:LRU_BITS),在 LRU 算法中用來存儲對象最后一次被命令程序訪問的時間。
具體的 LRU 算法經(jīng)歷了兩個版本。
版本1:隨機(jī)選取 N 個淘汰法。
最初 Redis 是這樣實(shí)現(xiàn)的:隨機(jī)選 N(默認(rèn)5) 個 key,把空閑時間(idle time)最大的那個 key 移除。這邊的 N 可通過 maxmemory-samples 配置項(xiàng)修改。
就是這么簡單,簡單得讓人不敢相信了,而且十分有效。
但是這個算法有個明顯的缺點(diǎn):每次都是隨機(jī)從 N 個里選擇 1 個,并沒有利用前一輪的歷史信息。其實(shí)在上一輪移除 key 的過程中,其實(shí)是知道了 N 個 key 的 idle time 的情況的,那在下一輪移除 key 時,其實(shí)可以利用上一輪的這些信息。這也是 Redis 3.0 的優(yōu)化思想。
版本2:Redis 3.0 對 LRU 算法進(jìn)行改進(jìn),引入了緩沖池(pool,默認(rèn)16)的概念。
當(dāng)每一輪移除 key 時,拿到了 N(默認(rèn)5)個 key 的 idle time,遍歷處理這 N 個 key,如果 key 的 idle time 比 pool 里面的 key 的 idle time 還要大,就把它添加到 pool 里面去。
當(dāng) pool 放滿之后,每次如果有新的 key 需要放入,需要將 pool 中 idle time 最小的一個 key 移除。這樣相當(dāng)于 pool 里面始終維護(hù)著還未被淘汰的 idle time 最大的 16 個 key。
當(dāng)我們每輪要淘汰的時候,直接從 pool 里面取出 idle time 最大的 key(只取1個),將之淘汰掉。
整個流程相當(dāng)于隨機(jī)取 5 個 key 放入 pool,然后淘汰 pool 中空閑時間最大的 key,然后再隨機(jī)取 5 個 key放入 pool,繼續(xù)淘汰 pool 中空閑時間最大的 key,一直持續(xù)下去。
在進(jìn)入淘汰前會計算出需要釋放的內(nèi)存大小,然后就一直循環(huán)上述流程,直至釋放足夠的內(nèi)存。
18、Redis 的持久化機(jī)制有哪幾種,各自的實(shí)現(xiàn)原理和優(yōu)缺點(diǎn)?
Redis 的持久化機(jī)制有:RDB、AOF、混合持久化(RDB+AOF,Redis 4.0引入)。
1)RDB
描述:類似于快照。在某個時間點(diǎn),將 Redis 在內(nèi)存中的數(shù)據(jù)庫狀態(tài)(數(shù)據(jù)庫的鍵值對等信息)保存到磁盤里面。RDB 持久化功能生成的 RDB 文件是經(jīng)過壓縮的二進(jìn)制文件。
命令:有兩個 Redis 命令可以用于生成 RDB 文件,一個是 SAVE,另一個是 BGSAVE。
開啟:使用 save point 配置,滿足 save point 條件后會觸發(fā) BGSAVE 來存儲一次快照,這邊的 save point 檢查就是在上文提到的 serverCron 中進(jìn)行。
save point 格式:save <seconds> <changes>,含義是 Redis 如果在 seconds 秒內(nèi)數(shù)據(jù)發(fā)生了 changes 次改變,就保存快照文件。例如 Redis 默認(rèn)就配置了以下3個:
save 900 1 #900秒內(nèi)有1個key發(fā)生了變化,則觸發(fā)保存RDB文件save 300 10 #300秒內(nèi)有10個key發(fā)生了變化,則觸發(fā)保存RDB文件save 60 10000 #60秒內(nèi)有10000個key發(fā)生了變化,則觸發(fā)保存RDB文件
關(guān)閉:1)注釋掉所有save point 配置可以關(guān)閉 RDB 持久化。2)在所有 save point 配置后增加:save "",該配置可以刪除所有之前配置的 save point。
save ""
SAVE:生成 RDB 快照文件,但是會阻塞主進(jìn)程,服務(wù)器將無法處理客戶端發(fā)來的命令請求,所以通常不會直接使用該命令。
BGSAVE:fork 子進(jìn)程來生成 RDB 快照文件,阻塞只會發(fā)生在 fork 子進(jìn)程的時候,之后主進(jìn)程可以正常處理請求,詳細(xì)過程如下圖:
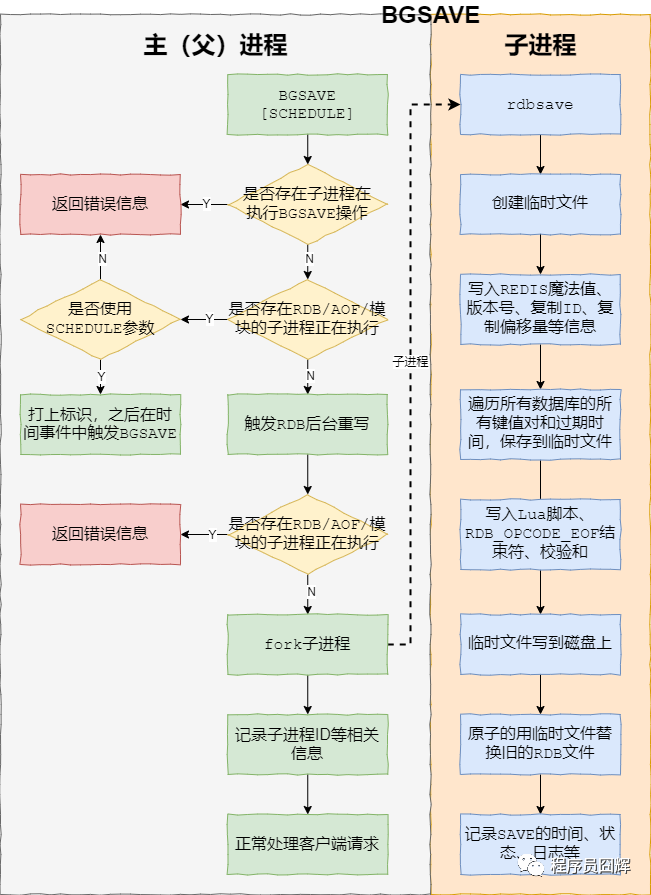
fork:在 Linux 系統(tǒng)中,調(diào)用 fork() 時,會創(chuàng)建出一個新進(jìn)程,稱為子進(jìn)程,子進(jìn)程會拷貝父進(jìn)程的 page table。如果進(jìn)程占用的內(nèi)存越大,進(jìn)程的 page table 也會越大,那么 fork 也會占用更多的時間。如果 Redis 占用的內(nèi)存很大,那么在 fork 子進(jìn)程時,則會出現(xiàn)明顯的停頓現(xiàn)象。
RDB 的優(yōu)點(diǎn)
1)RDB 文件是是經(jīng)過壓縮的二進(jìn)制文件,占用空間很小,它保存了 Redis 某個時間點(diǎn)的數(shù)據(jù)集,很適合用于做備份。 比如說,你可以在最近的 24 小時內(nèi),每小時備份一次 RDB 文件,并且在每個月的每一天,也備份一個 RDB 文件。這樣的話,即使遇上問題,也可以隨時將數(shù)據(jù)集還原到不同的版本。
2)RDB 非常適用于災(zāi)難恢復(fù)(disaster recovery):它只有一個文件,并且內(nèi)容都非常緊湊,可以(在加密后)將它傳送到別的數(shù)據(jù)中心。
3)RDB 可以最大化 redis 的性能。父進(jìn)程在保存 RDB 文件時唯一要做的就是 fork 出一個子進(jìn)程,然后這個子進(jìn)程就會處理接下來的所有保存工作,父進(jìn)程無須執(zhí)行任何磁盤 I/O 操作。
4)RDB 在恢復(fù)大數(shù)據(jù)集時的速度比 AOF 的恢復(fù)速度要快。
RDB 的缺點(diǎn)
1)RDB 在服務(wù)器故障時容易造成數(shù)據(jù)的丟失。RDB 允許我們通過修改 save point 配置來控制持久化的頻率。但是,因?yàn)?RDB 文件需要保存整個數(shù)據(jù)集的狀態(tài), 所以它是一個比較重的操作,如果頻率太頻繁,可能會對 Redis 性能產(chǎn)生影響。所以通常可能設(shè)置至少5分鐘才保存一次快照,這時如果 Redis 出現(xiàn)宕機(jī)等情況,則意味著最多可能丟失5分鐘數(shù)據(jù)。
2)RDB 保存時使用 fork 子進(jìn)程進(jìn)行數(shù)據(jù)的持久化,如果數(shù)據(jù)比較大的話,fork 可能會非常耗時,造成 Redis 停止處理服務(wù)N毫秒。如果數(shù)據(jù)集很大且 CPU 比較繁忙的時候,停止服務(wù)的時間甚至?xí)揭幻搿?/span>
3)Linux fork 子進(jìn)程采用的是 copy-on-write 的方式。在 Redis 執(zhí)行 RDB 持久化期間,如果 client 寫入數(shù)據(jù)很頻繁,那么將增加 Redis 占用的內(nèi)存,最壞情況下,內(nèi)存的占用將達(dá)到原先的2倍。剛 fork 時,主進(jìn)程和子進(jìn)程共享內(nèi)存,但是隨著主進(jìn)程需要處理寫操作,主進(jìn)程需要將修改的頁面拷貝一份出來,然后進(jìn)行修改。極端情況下,如果所有的頁面都被修改,則此時的內(nèi)存占用是原先的2倍。
2)AOF
描述:保存 Redis 服務(wù)器所執(zhí)行的所有寫操作命令來記錄數(shù)據(jù)庫狀態(tài),并在服務(wù)器啟動時,通過重新執(zhí)行這些命令來還原數(shù)據(jù)集。
開啟:AOF 持久化默認(rèn)是關(guān)閉的,可以通過配置:appendonly yes 開啟。
關(guān)閉:使用配置 appendonly no 可以關(guān)閉 AOF 持久化。
AOF 持久化功能的實(shí)現(xiàn)可以分為三個步驟:命令追加、文件寫入、文件同步。
命令追加:當(dāng) AOF 持久化功能打開時,服務(wù)器在執(zhí)行完一個寫命令之后,會將被執(zhí)行的寫命令追加到服務(wù)器狀態(tài)的 aof 緩沖區(qū)(aof_buf)的末尾。
文件寫入與文件同步:可能有人不明白為什么將 aof_buf 的內(nèi)容寫到磁盤上需要兩步操作,這邊簡單解釋一下。
Linux 操作系統(tǒng)中為了提升性能,使用了頁緩存(page cache)。當(dāng)我們將 aof_buf 的內(nèi)容寫到磁盤上時,此時數(shù)據(jù)并沒有真正的落盤,而是在 page cache 中,為了將 page cache 中的數(shù)據(jù)真正落盤,需要執(zhí)行 fsync / fdatasync 命令來強(qiáng)制刷盤。這邊的文件同步做的就是刷盤操作,或者叫文件刷盤可能更容易理解一些。
在文章開頭,我們提過 serverCron 時間事件中會觸發(fā) flushAppendOnlyFile 函數(shù),該函數(shù)會根據(jù)服務(wù)器配置的 appendfsync 參數(shù)值,來決定是否將 aof_buf 緩沖區(qū)的內(nèi)容寫入和保存到 AOF 文件。
appendfsync 參數(shù)有三個選項(xiàng):
always:每處理一個命令都將 aof_buf 緩沖區(qū)中的所有內(nèi)容寫入并同步到AOF 文件,即每個命令都刷盤。
everysec:將 aof_buf 緩沖區(qū)中的所有內(nèi)容寫入到 AOF 文件,如果上次同步 AOF 文件的時間距離現(xiàn)在超過一秒鐘, 那么再次對 AOF 文件進(jìn)行同步, 并且這個同步操作是異步的,由一個后臺線程專門負(fù)責(zé)執(zhí)行,即每秒刷盤1次。
no:將 aof_buf 緩沖區(qū)中的所有內(nèi)容寫入到 AOF 文件, 但并不對 AOF 文件進(jìn)行同步, 何時同步由操作系統(tǒng)來決定。即不執(zhí)行刷盤,讓操作系統(tǒng)自己執(zhí)行刷盤。
AOF 的優(yōu)點(diǎn)
AOF 比 RDB可靠。你可以設(shè)置不同的 fsync 策略:no、everysec 和 always。默認(rèn)是 everysec,在這種配置下,redis 仍然可以保持良好的性能,并且就算發(fā)生故障停機(jī),也最多只會丟失一秒鐘的數(shù)據(jù)。
AOF文件是一個純追加的日志文件。即使日志因?yàn)槟承┰蚨宋磳懭胪暾拿睿ū热鐚懭霑r磁盤已滿,寫入中途停機(jī)等等), 我們也可以使用 redis-check-aof 工具也可以輕易地修復(fù)這種問題。
當(dāng) AOF文件太大時,Redis 會自動在后臺進(jìn)行重寫:重寫后的新 AOF 文件包含了恢復(fù)當(dāng)前數(shù)據(jù)集所需的最小命令集合。整個重寫是絕對安全,因?yàn)橹貙懯窃谝粋€新的文件上進(jìn)行,同時 Redis 會繼續(xù)往舊的文件追加數(shù)據(jù)。當(dāng)新文件重寫完畢,Redis 會把新舊文件進(jìn)行切換,然后開始把數(shù)據(jù)寫到新文件上。
AOF 文件有序地保存了對數(shù)據(jù)庫執(zhí)行的所有寫入操作以 Redis 協(xié)議的格式保存, 因此 AOF 文件的內(nèi)容非常容易被人讀懂, 對文件進(jìn)行分析(parse)也很輕松。如果你不小心執(zhí)行了 FLUSHALL 命令把所有數(shù)據(jù)刷掉了,但只要 AOF 文件沒有被重寫,那么只要停止服務(wù)器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重啟 Redis , 就可以將數(shù)據(jù)集恢復(fù)到 FLUSHALL 執(zhí)行之前的狀態(tài)。
AOF 的缺點(diǎn)
對于相同的數(shù)據(jù)集,AOF 文件的大小一般會比 RDB 文件大。
根據(jù)所使用的 fsync 策略,AOF 的速度可能會比 RDB 慢。通常 fsync 設(shè)置為每秒一次就能獲得比較高的性能,而關(guān)閉 fsync 可以讓 AOF 的速度和 RDB 一樣快。
AOF 在過去曾經(jīng)發(fā)生過這樣的 bug :因?yàn)閭€別命令的原因,導(dǎo)致 AOF 文件在重新載入時,無法將數(shù)據(jù)集恢復(fù)成保存時的原樣。(舉個例子,阻塞命令 BRPOPLPUSH 就曾經(jīng)引起過這樣的 bug ) 。雖然這種 bug 在 AOF 文件中并不常見, 但是相較而言, RDB 幾乎是不可能出現(xiàn)這種 bug 的。
3)混合持久化
描述:混合持久化并不是一種全新的持久化方式,而是對已有方式的優(yōu)化。混合持久化只發(fā)生于 AOF 重寫過程。使用了混合持久化,重寫后的新 AOF 文件前半段是 RDB 格式的全量數(shù)據(jù),后半段是 AOF 格式的增量數(shù)據(jù)。
整體格式為:[RDB file][AOF tail]
開啟:混合持久化的配置參數(shù)為 aof-use-rdb-preamble,配置為 yes 時開啟混合持久化,在 redis 4 剛引入時,默認(rèn)是關(guān)閉混合持久化的,但是在 redis 5 中默認(rèn)已經(jīng)打開了。
關(guān)閉:使用 aof-use-rdb-preamble no 配置即可關(guān)閉混合持久化。
混合持久化本質(zhì)是通過 AOF 后臺重寫(bgrewriteaof 命令)完成的,不同的是當(dāng)開啟混合持久化時,fork 出的子進(jìn)程先將當(dāng)前全量數(shù)據(jù)以 RDB 方式寫入新的 AOF 文件,然后再將 AOF 重寫緩沖區(qū)(aof_rewrite_buf_blocks)的增量命令以 AOF 方式寫入到文件,寫入完成后通知主進(jìn)程將新的含有 RDB 格式和 AOF 格式的 AOF 文件替換舊的的 AOF 文件。
優(yōu)點(diǎn):結(jié)合 RDB 和 AOF 的優(yōu)點(diǎn), 更快的重寫和恢復(fù)。
缺點(diǎn):AOF 文件里面的 RDB 部分不再是 AOF 格式,可讀性差。
19、為什么需要 AOF 重寫
AOF 持久化是通過保存被執(zhí)行的寫命令來記錄數(shù)據(jù)庫狀態(tài)的,隨著寫入命令的不斷增加,AOF 文件中的內(nèi)容會越來越多,文件的體積也會越來越大。
如果不加以控制,體積過大的 AOF 文件可能會對 Redis 服務(wù)器、甚至整個宿主機(jī)造成影響,并且 AOF 文件的體積越大,使用 AOF 文件來進(jìn)行數(shù)據(jù)還原所需的時間就越多。
舉個例子, 如果你對一個計數(shù)器調(diào)用了 100 次 INCR , 那么僅僅是為了保存這個計數(shù)器的當(dāng)前值, AOF 文件就需要使用 100 條記錄。
然而在實(shí)際上, 只使用一條 SET 命令已經(jīng)足以保存計數(shù)器的當(dāng)前值了, 其余 99 條記錄實(shí)際上都是多余的。
為了處理這種情況, Redis 引入了 AOF 重寫:可以在不打斷服務(wù)端處理請求的情況下, 對 AOF 文件進(jìn)行重建(rebuild)。
20、介紹下 AOF 重寫的過程、AOF 后臺重寫存在的問題、如何解決 AOF 后臺重寫存在的數(shù)據(jù)不一致問題
描述:Redis 生成新的 AOF 文件來代替舊 AOF 文件,這個新的 AOF 文件包含重建當(dāng)前數(shù)據(jù)集所需的最少命令。具體過程是遍歷所有數(shù)據(jù)庫的所有鍵,從數(shù)據(jù)庫讀取鍵現(xiàn)在的值,然后用一條命令去記錄鍵值對,代替之前記錄這個鍵值對的多條命令。
命令:有兩個 Redis 命令可以用于觸發(fā) AOF 重寫,一個是 BGREWRITEAOF 、另一個是 REWRITEAOF 命令;
開啟:AOF 重寫由兩個參數(shù)共同控制,auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size,同時滿足這兩個條件,則觸發(fā) AOF 后臺重寫 BGREWRITEAOF。
// 當(dāng)前AOF文件比上次重寫后的AOF文件大小的增長比例超過100auto-aof-rewrite-percentage 100// 當(dāng)前AOF文件的文件大小大于64MBauto-aof-rewrite-min-size 64mb
關(guān)閉:auto-aof-rewrite-percentage 0,指定0的百分比,以禁用自動AOF重寫功能。
auto-aof-rewrite-percentage 0
REWRITEAOF:進(jìn)行 AOF 重寫,但是會阻塞主進(jìn)程,服務(wù)器將無法處理客戶端發(fā)來的命令請求,通常不會直接使用該命令。
BGREWRITEAOF:fork 子進(jìn)程來進(jìn)行 AOF 重寫,阻塞只會發(fā)生在 fork 子進(jìn)程的時候,之后主進(jìn)程可以正常處理請求。
REWRITEAOF 和 BGREWRITEAOF 的關(guān)系與 SAVE 和 BGSAVE 的關(guān)系類似。
AOF 后臺重寫存在的問題
AOF 后臺重寫使用子進(jìn)程進(jìn)行從寫,解決了主進(jìn)程阻塞的問題,但是仍然存在另一個問題:子進(jìn)程在進(jìn)行 AOF 重寫期間,服務(wù)器主進(jìn)程還需要繼續(xù)處理命令請求,新的命令可能會對現(xiàn)有的數(shù)據(jù)庫狀態(tài)進(jìn)行修改,從而使得當(dāng)前的數(shù)據(jù)庫狀態(tài)和重寫后的 AOF 文件保存的數(shù)據(jù)庫狀態(tài)不一致。
如何解決 AOF 后臺重寫存在的數(shù)據(jù)不一致問題
為了解決上述問題,Redis 引入了 AOF 重寫緩沖區(qū)(aof_rewrite_buf_blocks),這個緩沖區(qū)在服務(wù)器創(chuàng)建子進(jìn)程之后開始使用,當(dāng) Redis 服務(wù)器執(zhí)行完一個寫命令之后,它會同時將這個寫命令追加到 AOF 緩沖區(qū)和 AOF 重寫緩沖區(qū)。
這樣一來可以保證:
1、現(xiàn)有 AOF 文件的處理工作會如常進(jìn)行。這樣即使在重寫的中途發(fā)生停機(jī),現(xiàn)有的 AOF 文件也還是安全的。
2、從創(chuàng)建子進(jìn)程開始,也就是 AOF 重寫開始,服務(wù)器執(zhí)行的所有寫命令會被記錄到 AOF 重寫緩沖區(qū)里面。
這樣,當(dāng)子進(jìn)程完成 AOF 重寫工作后,父進(jìn)程會在 serverCron 中檢測到子進(jìn)程已經(jīng)重寫結(jié)束,則會執(zhí)行以下工作:
1、將 AOF 重寫緩沖區(qū)中的所有內(nèi)容寫入到新 AOF 文件中,這時新 AOF 文件所保存的數(shù)據(jù)庫狀態(tài)將和服務(wù)器當(dāng)前的數(shù)據(jù)庫狀態(tài)一致。
2、對新的 AOF 文件進(jìn)行改名,原子的覆蓋現(xiàn)有的 AOF 文件,完成新舊兩個 AOF 文件的替換。
之后,父進(jìn)程就可以繼續(xù)像往常一樣接受命令請求了。
21、RDB、AOF、混合持久,我應(yīng)該用哪一個?
一般來說, 如果想盡量保證數(shù)據(jù)安全性, 你應(yīng)該同時使用 RDB 和 AOF 持久化功能,同時可以開啟混合持久化。
如果你非常關(guān)心你的數(shù)據(jù), 但仍然可以承受數(shù)分鐘以內(nèi)的數(shù)據(jù)丟失, 那么你可以只使用 RDB 持久化。
如果你的數(shù)據(jù)是可以丟失的,則可以關(guān)閉持久化功能,在這種情況下,Redis 的性能是最高的。
使用 Redis 通常都是為了提升性能,而如果為了不丟失數(shù)據(jù)而將 appendfsync 設(shè)置為 always 級別時,對 Redis 的性能影響是很大的,在這種不能接受數(shù)據(jù)丟失的場景,其實(shí)可以考慮直接選擇 MySQL 等類似的數(shù)據(jù)庫。
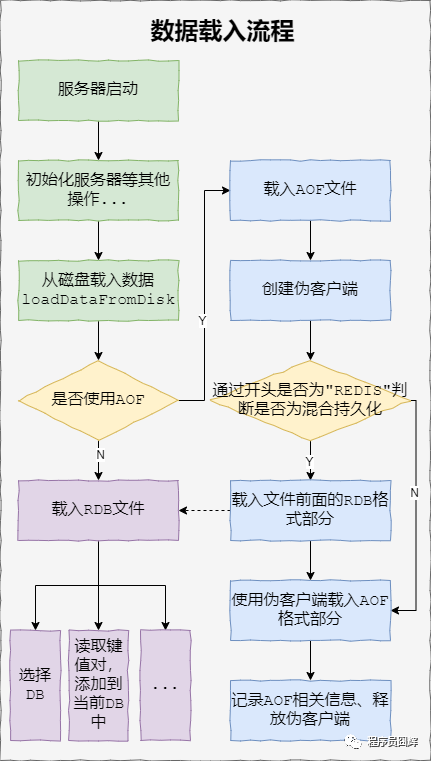
22、同時開啟RDB和AOF,服務(wù)重啟時如何加載
簡單來說,如果同時啟用了 AOF 和 RDB,Redis 重新啟動時,會使用 AOF 文件來重建數(shù)據(jù)集,因?yàn)橥ǔ碚f, AOF 的數(shù)據(jù)會更完整。
而在引入了混合持久化之后,使用 AOF 重建數(shù)據(jù)集時,會通過文件開頭是否為“REDIS”來判斷是否為混合持久化。
完整流程如下圖所示:
23、Redis 怎么保證高可用、有哪些集群模式
主從復(fù)制、哨兵模式、集群模式。
24、主從復(fù)制
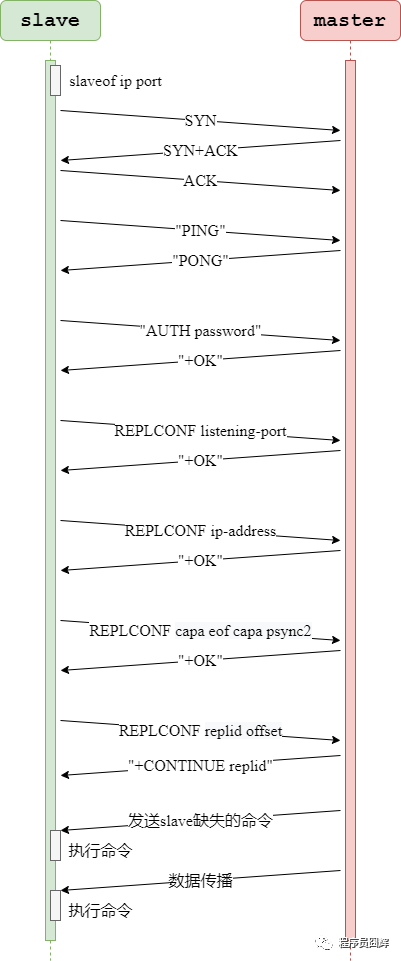
在當(dāng)前最新的 Redis 6.0 中,主從復(fù)制的完整過程如下:
1)開啟主從復(fù)制
通常有以下三種方式:
在 slave 直接執(zhí)行命令:slaveof <masterip> <masterport>
在 slave 配置文件中加入:slaveof <masterip> <masterport>
使用啟動命令:--slaveof <masterip> <masterport>
注:在 Redis 5.0 之后,slaveof 相關(guān)命令和配置已經(jīng)被替換成 replicaof,例如 replicaof <masterip> <masterport>。為了兼容舊版本,通過配置的方式仍然支持 slaveof,但是通過命令的方式則不行了。
2)建立套接字(socket)連接
slave 將根據(jù)指定的 IP 地址和端口,向 master 發(fā)起套接字(socket)連接,master 在接受(accept) slave 的套接字連接之后,為該套接字創(chuàng)建相應(yīng)的客戶端狀態(tài),此時連接建立完成。
3)發(fā)送PING命令
slave 向 master 發(fā)送一個 PING 命令,以檢査套接字的讀寫狀態(tài)是否正常、 master 能否正常處理命令請求。
4)身份驗(yàn)證
slave 向 master 發(fā)送 AUTH password 命令來進(jìn)行身份驗(yàn)證。
5)發(fā)送端口信息
在身份驗(yàn)證通過后后, slave 將向 master 發(fā)送自己的監(jiān)聽端口號, master 收到后記錄在 slave 所對應(yīng)的客戶端狀態(tài)的 slave_listening_port 屬性中。
6)發(fā)送IP地址
如果配置了 slave_announce_ip,則 slave 向 master 發(fā)送 slave_announce_ip 配置的 IP 地址, master 收到后記錄在 slave 所對應(yīng)的客戶端狀態(tài)的 slave_ip 屬性。
該配置是用于解決服務(wù)器返回內(nèi)網(wǎng) IP 時,其他服務(wù)器無法訪問的情況。可以通過該配置直接指定公網(wǎng) IP。
7)發(fā)送CAPA
CAPA 全稱是 capabilities,這邊表示的是同步復(fù)制的能力。slave 會在這一階段發(fā)送 capa 告訴 master 自己具備的(同步)復(fù)制能力, master 收到后記錄在 slave 所對應(yīng)的客戶端狀態(tài)的 slave_capa 屬性。
8)數(shù)據(jù)同步
slave 將向 master 發(fā)送 PSYNC 命令, master 收到該命令后判斷是進(jìn)行部分重同步還是完整重同步,然后根據(jù)策略進(jìn)行數(shù)據(jù)的同步。
9)命令傳播
當(dāng)完成了同步之后,就會進(jìn)入命令傳播階段,這時 master 只要一直將自己執(zhí)行的寫命令發(fā)送給 slave ,而 slave 只要一直接收并執(zhí)行 master 發(fā)來的寫命令,就可以保證 master 和 slave 一直保持一致了。
以部分重同步為例,主從復(fù)制的核心步驟流程圖如下:
25、哨兵
哨兵(Sentinel) 是 Redis 的高可用性解決方案:由一個或多個 Sentinel 實(shí)例組成的 Sentinel 系統(tǒng)可以監(jiān)視任意多個主服務(wù)器,以及這些主服務(wù)器屬下的所有從服務(wù)器。
Sentinel 可以在被監(jiān)視的主服務(wù)器進(jìn)入下線狀態(tài)時,自動將下線主服務(wù)器的某個從服務(wù)器升級為新的主服務(wù)器,然后由新的主服務(wù)器代替已下線的主服務(wù)器繼續(xù)處理命令請求。
1)哨兵故障檢測
檢查主觀下線狀態(tài)
在默認(rèn)情況下,Sentinel 會以每秒一次的頻率向所有與它創(chuàng)建了命令連接的實(shí)例(包括主服務(wù)器、從服務(wù)器、其他 Sentinel 在內(nèi))發(fā)送 PING 命令,并通過實(shí)例返回的 PING 命令回復(fù)來判斷實(shí)例是否在線。
如果一個實(shí)例在 down-after-miliseconds 毫秒內(nèi),連續(xù)向 Sentinel 返回?zé)o效回復(fù),那么 Sentinel 會修改這個實(shí)例所對應(yīng)的實(shí)例結(jié)構(gòu),在結(jié)構(gòu)的 flags 屬性中設(shè)置 SRI_S_DOWN 標(biāo)識,以此來表示這個實(shí)例已經(jīng)進(jìn)入主觀下線狀態(tài)。
檢查客觀下線狀態(tài)
當(dāng) Sentinel 將一個主服務(wù)器判斷為主觀下線之后,為了確定這個主服務(wù)器是否真的下線了,它會向同樣監(jiān)視這一服務(wù)器的其他 Sentinel 進(jìn)行詢問,看它們是否也認(rèn)為主服務(wù)器已經(jīng)進(jìn)入了下線狀態(tài)(可以是主觀下線或者客觀下線)。
當(dāng) Sentinel 從其他 Sentinel 那里接收到足夠數(shù)量(quorum,可配置)的已下線判斷之后,Sentinel 就會將服務(wù)器置為客觀下線,在 flags 上打上 SRI_O_DOWN 標(biāo)識,并對主服務(wù)器執(zhí)行故障轉(zhuǎn)移操作。
2)哨兵故障轉(zhuǎn)移流程
當(dāng)哨兵監(jiān)測到某個主節(jié)點(diǎn)客觀下線之后,就會開始故障轉(zhuǎn)移流程。核心流程如下:
發(fā)起一次選舉,選舉出領(lǐng)頭 Sentinel
領(lǐng)頭 Sentinel 在已下線主服務(wù)器的所有從服務(wù)器里面,挑選出一個從服務(wù)器,并將其升級為新的主服務(wù)器。
領(lǐng)頭 Sentinel 將剩余的所有從服務(wù)器改為復(fù)制新的主服務(wù)器。
領(lǐng)頭 Sentinel 更新相關(guān)配置信息,當(dāng)這個舊的主服務(wù)器重新上線時,將其設(shè)置為新的主服務(wù)器的從服務(wù)器。
26、集群模式
哨兵模式最大的缺點(diǎn)就是所有的數(shù)據(jù)都放在一臺服務(wù)器上,無法較好的進(jìn)行水平擴(kuò)展。
為了解決哨兵模式存在的問題,集群模式應(yīng)運(yùn)而生。在高可用上,集群基本是直接復(fù)用的哨兵模式的邏輯,并且針對水平擴(kuò)展進(jìn)行了優(yōu)化。
集群模式具備的特點(diǎn)如下:
采取去中心化的集群模式,將數(shù)據(jù)按槽存儲分布在多個 Redis 節(jié)點(diǎn)上。集群共有 16384 個槽,每個節(jié)點(diǎn)負(fù)責(zé)處理部分槽。
使用 CRC16 算法來計算 key 所屬的槽:crc16(key,keylen) & 16383。
所有的 Redis 節(jié)點(diǎn)彼此互聯(lián),通過 PING-PONG 機(jī)制來進(jìn)行節(jié)點(diǎn)間的心跳檢測。
分片內(nèi)采用一主多從保證高可用,并提供復(fù)制和故障恢復(fù)功能。在實(shí)際使用中,通常會將主從分布在不同機(jī)房,避免機(jī)房出現(xiàn)故障導(dǎo)致整個分片出問題,下面的架構(gòu)圖就是這樣設(shè)計的。
客戶端與 Redis 節(jié)點(diǎn)直連,不需要中間代理層(proxy)。客戶端不需要連接集群所有節(jié)點(diǎn),連接集群中任何一個可用節(jié)點(diǎn)即可。
集群的架構(gòu)圖如下所示:

27、集群選舉
故障轉(zhuǎn)移的第一步就是選舉出新的主節(jié)點(diǎn),以下是集群選舉新的主節(jié)點(diǎn)的方法:
1)當(dāng)從節(jié)點(diǎn)發(fā)現(xiàn)自己正在復(fù)制的主節(jié)點(diǎn)進(jìn)入已下線狀態(tài)時,會發(fā)起一次選舉:將 currentEpoch(配置紀(jì)元)加1,然后向集群廣播一條 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息,要求所有收到這條消息、并且具有投票權(quán)的主節(jié)點(diǎn)向這個從節(jié)點(diǎn)投票。
2)其他節(jié)點(diǎn)收到消息后,會判斷是否要給發(fā)送消息的節(jié)點(diǎn)投票,判斷流程如下:
當(dāng)前節(jié)點(diǎn)是 slave,或者當(dāng)前節(jié)點(diǎn)是 master,但是不負(fù)責(zé)處理槽,則當(dāng)前節(jié)點(diǎn)沒有投票權(quán),直接返回。
請求節(jié)點(diǎn)的 currentEpoch 小于當(dāng)前節(jié)點(diǎn)的 currentEpoch,校驗(yàn)失敗返回。因?yàn)榘l(fā)送者的狀態(tài)與當(dāng)前集群狀態(tài)不一致,可能是長時間下線的節(jié)點(diǎn)剛剛上線,這種情況下,直接返回即可。
當(dāng)前節(jié)點(diǎn)在該 currentEpoch 已經(jīng)投過票,校驗(yàn)失敗返回。
請求節(jié)點(diǎn)是 master,校驗(yàn)失敗返回。
請求節(jié)點(diǎn)的 master 為空,校驗(yàn)失敗返回。
請求節(jié)點(diǎn)的 master 沒有故障,并且不是手動故障轉(zhuǎn)移,校驗(yàn)失敗返回。因?yàn)槭謩庸收限D(zhuǎn)移是可以在 master 正常的情況下直接發(fā)起的。
上一次為該master的投票時間,在cluster_node_timeout的2倍范圍內(nèi),校驗(yàn)失敗返回。這個用于使獲勝從節(jié)點(diǎn)有時間將其成為新主節(jié)點(diǎn)的消息通知給其他從節(jié)點(diǎn),從而避免另一個從節(jié)點(diǎn)發(fā)起新一輪選舉又進(jìn)行一次沒必要的故障轉(zhuǎn)移
請求節(jié)點(diǎn)宣稱要負(fù)責(zé)的槽位,是否比之前負(fù)責(zé)這些槽位的節(jié)點(diǎn),具有相等或更大的 configEpoch,如果不是,校驗(yàn)失敗返回。
如果通過以上所有校驗(yàn),那么主節(jié)點(diǎn)將向要求投票的從節(jié)點(diǎn)返回一條 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,表示這個主節(jié)點(diǎn)支持從節(jié)點(diǎn)成為新的主節(jié)點(diǎn)。
3)每個參與選舉的從節(jié)點(diǎn)都會接收 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,并根據(jù)自己收到了多少條這種消息來統(tǒng)計自己獲得了多少個主節(jié)點(diǎn)的支持。
4)如果集群里有N個具有投票權(quán)的主節(jié)點(diǎn),那么當(dāng)一個從節(jié)點(diǎn)收集到大于等于N/2+1 張支持票時,這個從節(jié)點(diǎn)就會當(dāng)選為新的主節(jié)點(diǎn)。因?yàn)樵诿恳粋€配置紀(jì)元里面,每個具有投票權(quán)的主節(jié)點(diǎn)只能投一次票,所以如果有 N個主節(jié)點(diǎn)進(jìn)行投票,那么具有大于等于 N/2+1 張支持票的從節(jié)點(diǎn)只會有一個,這確保了新的主節(jié)點(diǎn)只會有一個。
5)如果在一個配置紀(jì)元里面沒有從節(jié)點(diǎn)能收集到足夠多的支持票,那么集群進(jìn)入一個新的配置紀(jì)元,并再次進(jìn)行選舉,直到選出新的主節(jié)點(diǎn)為止。
這個選舉新主節(jié)點(diǎn)的方法和選舉領(lǐng)頭 Sentinel 的方法非常相似,因?yàn)閮烧叨际腔?Raft 算法的領(lǐng)頭選舉(leader election)方法來實(shí)現(xiàn)的。
28、如何保證集群在線擴(kuò)容的安全性?(Redis 集群要增加分片,槽的遷移怎么保證無損)
例如:集群已經(jīng)對外提供服務(wù),原來有3分片,準(zhǔn)備新增2個分片,怎么在不下線的情況下,無損的從原有的3個分片指派若干個槽給這2個分片?
Redis 使用了 ASK 錯誤來保證在線擴(kuò)容的安全性。
在槽的遷移過程中若有客戶端訪問,依舊先訪問源節(jié)點(diǎn),源節(jié)點(diǎn)會先在自己的數(shù)據(jù)庫里面査找指定的鍵,如果找到的話,就直接執(zhí)行客戶端發(fā)送的命令。
如果沒找到,說明該鍵可能已經(jīng)被遷移到目標(biāo)節(jié)點(diǎn)了,源節(jié)點(diǎn)將向客戶端返回一個 ASK 錯誤,該錯誤會指引客戶端轉(zhuǎn)向正在導(dǎo)入槽的目標(biāo)節(jié)點(diǎn),并再次發(fā)送之前想要執(zhí)行的命令,從而獲取到結(jié)果。
ASK錯誤
在進(jìn)行重新分片期間,源節(jié)點(diǎn)向目標(biāo)節(jié)點(diǎn)遷移一個槽的過程中,可能會出現(xiàn)這樣一種情況:屬于被遷移槽的一部分鍵值對保存在源節(jié)點(diǎn)里面,而另一部分鍵值對則保存在目標(biāo)節(jié)點(diǎn)里面。
當(dāng)客戶端向源節(jié)點(diǎn)發(fā)送一個與數(shù)據(jù)庫鍵有關(guān)的命令,并且命令要處理的數(shù)據(jù)庫鍵恰好就屬于正在被遷移的槽時。源節(jié)點(diǎn)會先在自己的數(shù)據(jù)庫里面査找指定的鍵,如果找到的話,就直接執(zhí)行客戶端發(fā)送的命令。
否則,這個鍵有可能已經(jīng)被遷移到了目標(biāo)節(jié)點(diǎn),源節(jié)點(diǎn)將向客戶端返回一個 ASK 錯誤,指引客戶端轉(zhuǎn)向正在導(dǎo)入槽的目標(biāo)節(jié)點(diǎn),并再次發(fā)送之前想要執(zhí)行的命令,從而獲取到結(jié)果。
29、Redis 事務(wù)的實(shí)現(xiàn)
一個事務(wù)從開始到結(jié)束通常會經(jīng)歷以下3個階段:
1)事務(wù)開始:multi 命令將執(zhí)行該命令的客戶端從非事務(wù)狀態(tài)切換至事務(wù)狀態(tài),底層通過 flags 屬性標(biāo)識。
2)命令入隊:當(dāng)客戶端處于事務(wù)狀態(tài)時,服務(wù)器會根據(jù)客戶端發(fā)來的命令執(zhí)行不同的操作:
exec、discard、watch、multi 命令會被立即執(zhí)行
其他命令不會立即執(zhí)行,而是將命令放入到一個事務(wù)隊列,然后向客戶端返回 QUEUED 回復(fù)。
3)事務(wù)執(zhí)行:當(dāng)一個處于事務(wù)狀態(tài)的客戶端向服務(wù)器發(fā)送 exec 命令時,服務(wù)器會遍歷事務(wù)隊列,執(zhí)行隊列中的所有命令,最后將結(jié)果全部返回給客戶端。
不過 redis 的事務(wù)并不推薦在實(shí)際中使用,如果要使用事務(wù),推薦使用 Lua 腳本,redis 會保證一個 Lua 腳本里的所有命令的原子性。
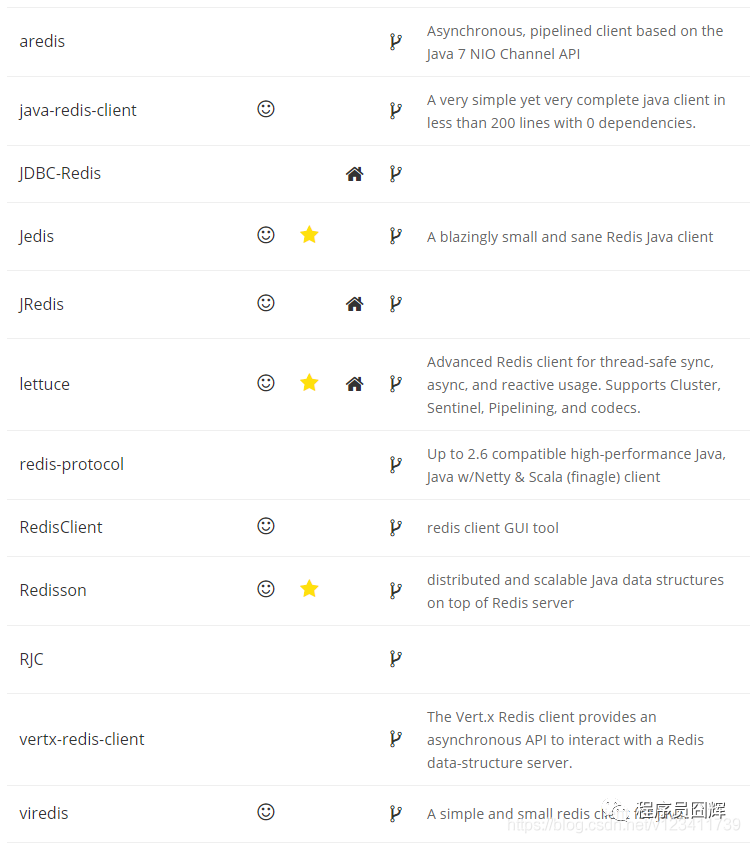
30、Redis 的 Java 客戶端有哪些?官方推薦哪個?
Redis 官網(wǎng)展示的 Java 客戶端如下圖所示,其中官方推薦的是標(biāo)星的3個:Jedis、Redisson 和 lettuce。
31、Redis 里面有1億個 key,其中有 10 個 key 是包含 java,如何將它們?nèi)空页鰜恚?/span>
1)keys *java* 命令,該命令性能很好,但是在數(shù)據(jù)量特別大的時候會有性能問題
2)scan 0 MATCH *java* 命令,基于游標(biāo)的迭代器,更好的選擇
SCAN 命令是一個基于游標(biāo)的迭代器(cursor based iterator):SCAN 命令每次被調(diào)用之后, 都會向用戶返回一個新的游標(biāo), 用戶在下次迭代時需要使用這個新游標(biāo)作為 SCAN 命令的游標(biāo)參數(shù), 以此來延續(xù)之前的迭代過程。
當(dāng) SCAN 命令的游標(biāo)參數(shù)被設(shè)置為 0 時, 服務(wù)器將開始一次新的迭代, 而當(dāng)服務(wù)器向用戶返回值為 0 的游標(biāo)時, 表示迭代已結(jié)束。
32、使用過 Redis 做消息隊列么?
Redis 本身提供了一些組件來實(shí)現(xiàn)消息隊列的功能,但是多多少少都存在一些缺點(diǎn),相比于市面上成熟的消息隊列,例如 Kafka、Rocket MQ 來說并沒有優(yōu)勢,因此目前我們并沒有使用 Redis 來做消息隊列。
關(guān)于 Redis 做消息隊列的常見方案主要有以下:
1)Redis 5.0 之前可以使用 List(blocking)、Pub/Sub 等來實(shí)現(xiàn)輕量級的消息發(fā)布訂閱功能組件,但是這兩種實(shí)現(xiàn)方式都有很明顯的缺點(diǎn),兩者中相對完善的 Pub/Sub 的主要缺點(diǎn)就是消息無法持久化,如果出現(xiàn)網(wǎng)絡(luò)斷開、Redis 宕機(jī)等,消息就會被丟棄。
2)為了解決 Pub/Sub 模式等的缺點(diǎn),Redis 在 5.0 引入了全新的 Stream,Stream 借鑒了很多 Kafka 的設(shè)計思想,有以下幾個特點(diǎn):
提供了消息的持久化和主備復(fù)制功能,可以讓任何客戶端訪問任何時刻的數(shù)據(jù),并且能記住每一個客戶端的訪問位置,還能保證消息不丟失。
引入了消費(fèi)者組的概念,不同組接收到的數(shù)據(jù)完全一樣(前提是條件一樣),但是組內(nèi)的消費(fèi)者則是競爭關(guān)系。
Redis Stream 相比于 pub/sub 已經(jīng)有很明顯的改善,但是相比于 Kafka,其實(shí)沒有優(yōu)勢,同時存在:尚未經(jīng)過大量驗(yàn)證、成本較高、不支持分區(qū)(partition)、無法支持大規(guī)模數(shù)據(jù)等問題。
33、Redis 和 Memcached 的比較
1)數(shù)據(jù)結(jié)構(gòu):memcached 支持簡單的 key-value 數(shù)據(jù)結(jié)構(gòu),而 redis 支持豐富的數(shù)據(jù)結(jié)構(gòu):String、List、Set、Hash、SortedSet 等。
2)數(shù)據(jù)存儲:memcached 和 redis 的數(shù)據(jù)都是全部在內(nèi)存中。
網(wǎng)上有一種說法 “當(dāng)物理內(nèi)存用完時,Redis可以將一些很久沒用到的 value 交換到磁盤,同時在內(nèi)存中清除”,這邊指的是 redis 里的虛擬內(nèi)存(Virtual Memory)功能,該功能在 Redis 2.0 被引入,但是在 Redis 2.4 中被默認(rèn)關(guān)閉,并標(biāo)記為廢棄,而在后續(xù)版中被完全移除。
3)持久化:memcached 不支持持久化,redis 支持將數(shù)據(jù)持久化到磁盤
4)災(zāi)難恢復(fù):實(shí)例掛掉后,memcached 數(shù)據(jù)不可恢復(fù),redis 可通過 RDB、AOF 恢復(fù),但是還是會有數(shù)據(jù)丟失問題
5)事件庫:memcached 使用 Libevent 事件庫,redis 自己封裝了簡易事件庫 AeEvent
6)過期鍵刪除策略:memcached 使用惰性刪除,redis 使用惰性刪除+定期刪除
7)內(nèi)存驅(qū)逐(淘汰)策略:memcached 主要為 LRU 算法,redis 當(dāng)前支持8種淘汰策略,見本文第16題
8)性能比較
按“CPU 單核” 維度比較:由于 Redis 只使用單核,而 Memcached 可以使用多核,所以在比較上:在處理小數(shù)據(jù)時,平均每一個核上 Redis 比 Memcached 性能更高,而在 100k 左右的大數(shù)據(jù)時, Memcached 性能要高于 Redis。
按“實(shí)例”維度進(jìn)行比較:由于 Memcached 多線程的特性,在 Redis 6.0 之前,通常情況下 Memcached 性能是要高于 Redis 的,同時實(shí)例的 CPU 核數(shù)越多,Memcached 的性能優(yōu)勢越大。
至于網(wǎng)上說的 redis 的性能比 memcached 快很多,這個說法就離譜。

34、Redis 實(shí)現(xiàn)分布式鎖
1)加鎖
加鎖通常使用 set 命令來實(shí)現(xiàn),偽代碼如下:
set key value PX milliseconds NX幾個參數(shù)的意義如下:
key、value:鍵值對
PX milliseconds:設(shè)置鍵的過期時間為 milliseconds 毫秒。
NX:只在鍵不存在時,才對鍵進(jìn)行設(shè)置操作。SET key value NX 效果等同于 SETNX key value。
PX、expireTime 參數(shù)則是用于解決沒有解鎖導(dǎo)致的死鎖問題。因?yàn)槿绻麤]有過期時間,萬一程序員寫的代碼有 bug 導(dǎo)致沒有解鎖操作,則就出現(xiàn)了死鎖,因此該參數(shù)起到了一個“兜底”的作用。
NX 參數(shù)用于保證在多個線程并發(fā) set 下,只會有1個線程成功,起到了鎖的“唯一”性。
2)解鎖
解鎖需要兩步操作:
1)查詢當(dāng)前“鎖”是否還是我們持有,因?yàn)榇嬖谶^期時間,所以可能等你想解鎖的時候,“鎖”已經(jīng)到期,然后被其他線程獲取了,所以我們在解鎖前需要先判斷自己是否還持有“鎖”
2)如果“鎖”還是我們持有,則執(zhí)行解鎖操作,也就是刪除該鍵值對,并返回成功;否則,直接返回失敗。
由于當(dāng)前 Redis 還沒有原子命令直接支持這兩步操作,所以當(dāng)前通常是使用 Lua 腳本來執(zhí)行解鎖操作,Redis 會保證腳本里的內(nèi)容執(zhí)行是一個原子操作。
腳本代碼如下,邏輯比較簡單:
if redis.call("get",KEYS[1]) == ARGV[1]thenreturn redis.call("del",KEYS[1])elsereturn 0end
兩個參數(shù)的意義如下:
KEYS[1]:我們要解鎖的 key
ARGV[1]:我們加鎖時的 value,用于判斷當(dāng)“鎖”是否還是我們持有,如果被其他線程持有了,value 就會發(fā)生變化。
上述方法是 Redis 當(dāng)前實(shí)現(xiàn)分布式鎖的主流方法,可能會有一些小優(yōu)區(qū)別,但是核心都是這個思路。看著好像沒啥毛病,但是真的是這個樣子嗎?讓我們繼續(xù)往下看。
35、Redis 分布式鎖過期了,還沒處理完怎么辦
為了防止死鎖,我們會給分布式鎖加一個過期時間,但是萬一這個時間到了,我們業(yè)務(wù)邏輯還沒處理完,怎么辦?
首先,我們在設(shè)置過期時間時要結(jié)合業(yè)務(wù)場景去考慮,盡量設(shè)置一個比較合理的值,就是理論上正常處理的話,在這個過期時間內(nèi)是一定能處理完畢的。
之后,我們再來考慮對這個問題進(jìn)行兜底設(shè)計。
關(guān)于這個問題,目前常見的解決方法有兩種:
守護(hù)線程“續(xù)命”:額外起一個線程,定期檢查線程是否還持有鎖,如果有則延長過期時間。Redisson 里面就實(shí)現(xiàn)了這個方案,使用“看門狗”定期檢查(每1/3的鎖時間檢查1次),如果線程還持有鎖,則刷新過期時間。
超時回滾:當(dāng)我們解鎖時發(fā)現(xiàn)鎖已經(jīng)被其他線程獲取了,說明此時我們執(zhí)行的操作已經(jīng)是“不安全”的了,此時需要進(jìn)行回滾,并返回失敗。
同時,需要進(jìn)行告警,人為介入驗(yàn)證數(shù)據(jù)的正確性,然后找出超時原因,是否需要對超時時間進(jìn)行優(yōu)化等等。
36、守護(hù)線程續(xù)命的方案有什么問題嗎
Redisson 使用看門狗(守護(hù)線程)“續(xù)命”的方案在大多數(shù)場景下是挺不錯的,也被廣泛應(yīng)用于生產(chǎn)環(huán)境,但是在極端情況下還是會存在問題。
問題例子如下:
線程1首先獲取鎖成功,將鍵值對寫入 redis 的 master 節(jié)點(diǎn)
在 redis 將該鍵值對同步到 slave 節(jié)點(diǎn)之前,master 發(fā)生了故障
redis 觸發(fā)故障轉(zhuǎn)移,其中一個 slave 升級為新的 master
此時新的 master 并不包含線程1寫入的鍵值對,因此線程2嘗試獲取鎖也可以成功拿到鎖
此時相當(dāng)于有兩個線程獲取到了鎖,可能會導(dǎo)致各種預(yù)期之外的情況發(fā)生,例如最常見的臟數(shù)據(jù)
解決方法:上述問題的根本原因主要是由于 redis 異步復(fù)制帶來的數(shù)據(jù)不一致問題導(dǎo)致的,因此解決的方向就是保證數(shù)據(jù)的一致。
當(dāng)前比較主流的解法和思路有兩種:
1)Redis 作者提出的 RedLock;2)Zookeeper 實(shí)現(xiàn)的分布式鎖。
37、RedLock
首先,該方案也是基于文章開頭的那個方案(set加鎖、lua腳本解鎖)進(jìn)行改良的,所以 antirez 只描述了差異的地方,大致方案如下。
假設(shè)我們有 N 個 Redis 主節(jié)點(diǎn),例如 N = 5,這些節(jié)點(diǎn)是完全獨(dú)立的,我們不使用復(fù)制或任何其他隱式協(xié)調(diào)系統(tǒng),為了取到鎖,客戶端應(yīng)該執(zhí)行以下操作:
獲取當(dāng)前時間,以毫秒為單位。
依次嘗試從5個實(shí)例,使用相同的 key 和隨機(jī)值(例如UUID)獲取鎖。當(dāng)向Redis 請求獲取鎖時,客戶端應(yīng)該設(shè)置一個超時時間,這個超時時間應(yīng)該小于鎖的失效時間。例如你的鎖自動失效時間為10秒,則超時時間應(yīng)該在 5-50 毫秒之間。這樣可以防止客戶端在試圖與一個宕機(jī)的 Redis 節(jié)點(diǎn)對話時長時間處于阻塞狀態(tài)。如果一個實(shí)例不可用,客戶端應(yīng)該盡快嘗試去另外一個Redis實(shí)例請求獲取鎖。
客戶端通過當(dāng)前時間減去步驟1記錄的時間來計算獲取鎖使用的時間。當(dāng)且僅當(dāng)從大多數(shù)(N/2+1,這里是3個節(jié)點(diǎn))的Redis節(jié)點(diǎn)都取到鎖,并且獲取鎖使用的時間小于鎖失效時間時,鎖才算獲取成功。
如果取到了鎖,其真正有效時間等于初始有效時間減去獲取鎖所使用的時間(步驟3計算的結(jié)果)。
如果由于某些原因未能獲得鎖(無法在至少N/2+1個Redis實(shí)例獲取鎖、或獲取鎖的時間超過了有效時間),客戶端應(yīng)該在所有的Redis實(shí)例上進(jìn)行解鎖(即便某些Redis實(shí)例根本就沒有加鎖成功,防止某些節(jié)點(diǎn)獲取到鎖但是客戶端沒有得到響應(yīng)而導(dǎo)致接下來的一段時間不能被重新獲取鎖)。
可以看出,該方案為了解決數(shù)據(jù)不一致的問題,直接舍棄了異步復(fù)制,只使用 master 節(jié)點(diǎn),同時由于舍棄了 slave,為了保證可用性,引入了 N 個節(jié)點(diǎn),官方建議是 5。
該方案看著挺美好的,但是實(shí)際上我所了解到的在實(shí)際生產(chǎn)上應(yīng)用的不多,主要有兩個原因:1)該方案的成本似乎有點(diǎn)高,需要使用5個實(shí)例;2)該方案一樣存在問題。
該方案主要存以下問題:
嚴(yán)重依賴系統(tǒng)時鐘。如果線程1從3個實(shí)例獲取到了鎖,但是這3個實(shí)例中的某個實(shí)例的系統(tǒng)時間走的稍微快一點(diǎn),則它持有的鎖會提前過期被釋放,當(dāng)他釋放后,此時又有3個實(shí)例是空閑的,則線程2也可以獲取到鎖,則可能出現(xiàn)兩個線程同時持有鎖了。
如果線程1從3個實(shí)例獲取到了鎖,但是萬一其中有1臺重啟了,則此時又有3個實(shí)例是空閑的,則線程2也可以獲取到鎖,此時又出現(xiàn)兩個線程同時持有鎖了。
針對以上問題其實(shí)后續(xù)也有人給出一些相應(yīng)的解法,但是整體上來看還是不夠完美,所以目前實(shí)際應(yīng)用得不是那么多。
38、使用緩存時,先操作數(shù)據(jù)庫 or 先操作緩存
1)先操作數(shù)據(jù)庫
案例如下,有兩個并發(fā)的請求,一個寫請求,一個讀請求,流程如下:
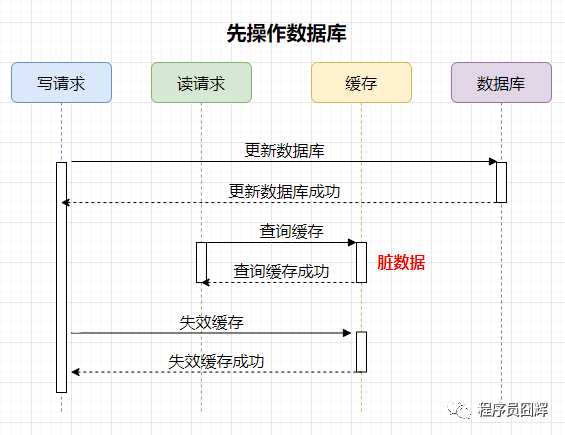
可能存在的臟數(shù)據(jù)時間范圍:更新數(shù)據(jù)庫后,失效緩存前。這個時間范圍很小,通常不會超過幾毫秒。
2)先操作緩存
案例如下,有兩個并發(fā)的請求,一個寫請求,一個讀請求,流程如下:
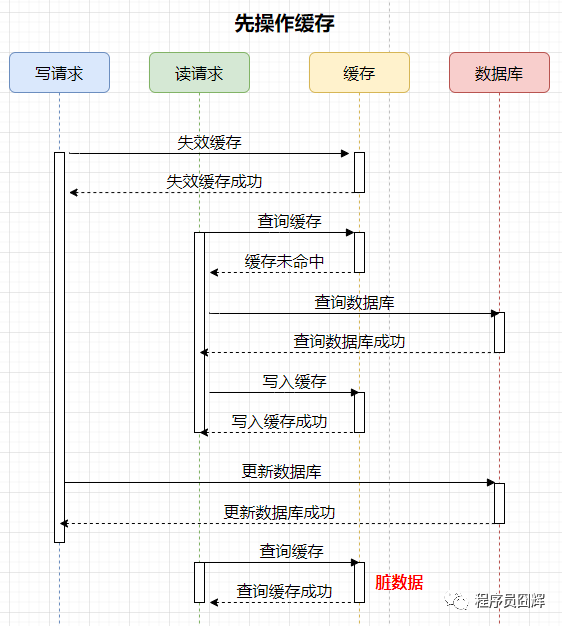
可能存在的臟數(shù)據(jù)時間范圍:更新數(shù)據(jù)庫后,下一次對該數(shù)據(jù)的更新前。這個時間范圍不確定性很大,情況如下:
如果下一次對該數(shù)據(jù)的更新馬上就到來,那么會失效緩存,臟數(shù)據(jù)的時間就很短。
如果下一次對該數(shù)據(jù)的更新要很久才到來,那這期間緩存保存的一直是臟數(shù)據(jù),時間范圍很長。
結(jié)論:通過上述案例可以看出,先操作數(shù)據(jù)庫和先操作緩存都會存在臟數(shù)據(jù)的情況。但是相比之下,先操作數(shù)據(jù)庫,再操作緩存是更優(yōu)的方式,即使在并發(fā)極端情況下,也只會出現(xiàn)很小量的臟數(shù)據(jù)。
39、為什么是讓緩存失效,而不是更新緩存
1)更新緩存
案例如下,有兩個并發(fā)的寫請求,流程如下:
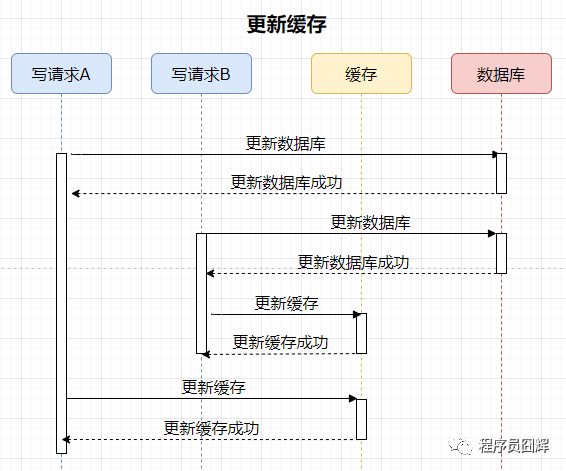
分析:數(shù)據(jù)庫中的數(shù)據(jù)是請求B的,緩存中的數(shù)據(jù)是請求A的,數(shù)據(jù)庫和緩存存在數(shù)據(jù)不一致。
2)失效(刪除)緩存
案例如下,有兩個并發(fā)的寫請求,流程如下:
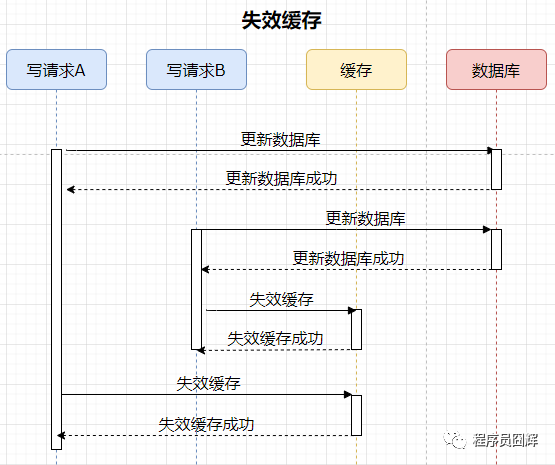
分析:由于是刪除緩存,所以不存在數(shù)據(jù)不一致的情況。
結(jié)論:通過上述案例,可以很明顯的看出,失效緩存是更優(yōu)的方式。
40、如何保證數(shù)據(jù)庫和緩存的數(shù)據(jù)一致性
在上文的案例中,無論是先操作數(shù)據(jù)庫,還是先操作緩存,都會存在臟數(shù)據(jù)的情況,有辦法避免嗎?
答案是有的,由于數(shù)據(jù)庫和緩存是兩個不同的數(shù)據(jù)源,要保證其數(shù)據(jù)一致性,其實(shí)就是典型的分布式事務(wù)場景,可以引入分布式事務(wù)來解決,常見的有:2PC、TCC、MQ事務(wù)消息等。
但是引入分布式事務(wù)必然會帶來性能上的影響,這與我們當(dāng)初引入緩存來提升性能的目的是相違背的。
所以在實(shí)際使用中,通常不會去保證緩存和數(shù)據(jù)庫的強(qiáng)一致性,而是做出一定的犧牲,保證兩者數(shù)據(jù)的最終一致性。
如果是實(shí)在無法接受臟數(shù)據(jù)的場景,則比較合理的方式是放棄使用緩存,直接走數(shù)據(jù)庫。
保證數(shù)據(jù)庫和緩存數(shù)據(jù)最終一致性的常用方案如下:
1)更新數(shù)據(jù)庫,數(shù)據(jù)庫產(chǎn)生 binlog。
2)監(jiān)聽和消費(fèi) binlog,執(zhí)行失效緩存操作。
3)如果步驟2失效緩存失敗,則引入重試機(jī)制,將失敗的數(shù)據(jù)通過MQ方式進(jìn)行重試,同時考慮是否需要引入冪等機(jī)制。
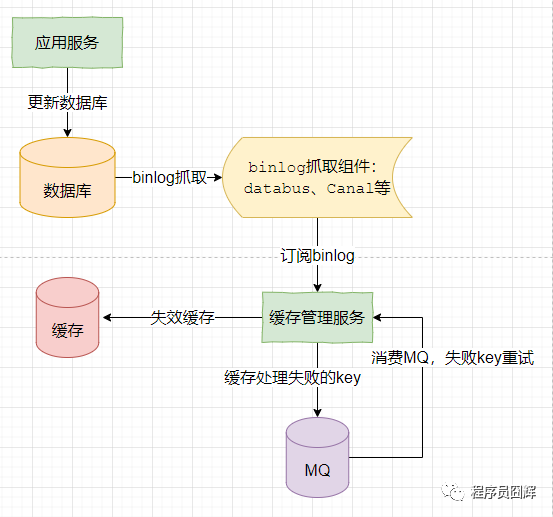
兜底:當(dāng)出現(xiàn)未知的問題時,及時告警通知,人為介入處理。
人為介入是終極大法,那些外表看著光鮮艷麗的應(yīng)用,其背后大多有一群苦逼的程序員,在不斷的修復(fù)各種臟數(shù)據(jù)和bug。

41、緩存穿透
描述:訪問一個緩存和數(shù)據(jù)庫都不存在的 key,此時會直接打到數(shù)據(jù)庫上,并且查不到數(shù)據(jù),沒法寫緩存,所以下一次同樣會打到數(shù)據(jù)庫上。
此時,緩存起不到作用,請求每次都會走到數(shù)據(jù)庫,流量大時數(shù)據(jù)庫可能會被打掛。此時緩存就好像被“穿透”了一樣,起不到任何作用。
解決方案:
1)接口校驗(yàn)。在正常業(yè)務(wù)流程中可能會存在少量訪問不存在 key 的情況,但是一般不會出現(xiàn)大量的情況,所以這種場景最大的可能性是遭受了非法攻擊。可以在最外層先做一層校驗(yàn):用戶鑒權(quán)、數(shù)據(jù)合法性校驗(yàn)等,例如商品查詢中,商品的ID是正整數(shù),則可以直接對非正整數(shù)直接過濾等等。
2)緩存空值。當(dāng)訪問緩存和DB都沒有查詢到值時,可以將空值寫進(jìn)緩存,但是設(shè)置較短的過期時間,該時間需要根據(jù)產(chǎn)品業(yè)務(wù)特性來設(shè)置。
3)布隆過濾器。使用布隆過濾器存儲所有可能訪問的 key,不存在的 key 直接被過濾,存在的 key 則再進(jìn)一步查詢緩存和數(shù)據(jù)庫。
42、布隆過濾器
布隆過濾器的特點(diǎn)是判斷不存在的,則一定不存在;判斷存在的,大概率存在,但也有小概率不存在。并且這個概率是可控的,我們可以讓這個概率變小或者變高,取決于用戶本身的需求。
布隆過濾器由一個 bitSet 和 一組 Hash 函數(shù)(算法)組成,是一種空間效率極高的概率型算法和數(shù)據(jù)結(jié)構(gòu),主要用來判斷一個元素是否在集合中存在。
在初始化時,bitSet 的每一位被初始化為0,同時會定義 Hash 函數(shù),例如有3組 Hash 函數(shù):hash1、hash2、hash3。
寫入流程
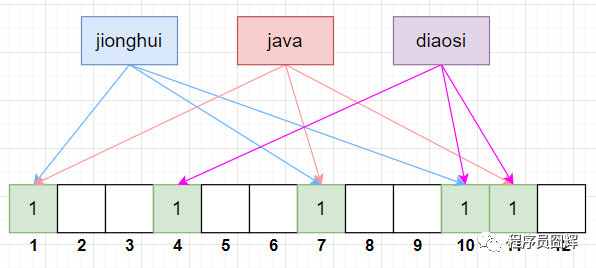
當(dāng)我們要寫入一個值時,過程如下,以“jionghui”為例:
1)首先將“jionghui”跟3組 Hash 函數(shù)分別計算,得到 bitSet 的下標(biāo)為:1、7、10。
2)將 bitSet 的這3個下標(biāo)標(biāo)記為1。
假設(shè)我們還有另外兩個值:java 和 diaosi,按上面的流程跟 3組 Hash 函數(shù)分別計算,結(jié)果如下:
java:Hash 函數(shù)計算 bitSet 下標(biāo)為:1、7、11
diaosi:Hash 函數(shù)計算 bitSet 下標(biāo)為:4、10、11
查詢流程
當(dāng)我們要查詢一個值時,過程如下,同樣以“jionghui”為例::
1)首先將“jionghui”跟3組 Hash 函數(shù)分別計算,得到 bitSet 的下標(biāo)為:1、7、10。
2)查看 bitSet 的這3個下標(biāo)是否都為1,如果這3個下標(biāo)不都為1,則說明該值必然不存在,如果這3個下標(biāo)都為1,則只能說明可能存在,并不能說明一定存在。
其實(shí)上圖的例子已經(jīng)說明了這個問題了,當(dāng)我們只有值“jionghui”和“diaosi”時,bitSet 下標(biāo)為1的有:1、4、7、10、11。
當(dāng)我們又加入值“java”時,bitSet 下標(biāo)為1的還是這5個,所以當(dāng) bitSet 下標(biāo)為1的為:1、4、7、10、11 時,我們無法判斷值“java”存不存在。
其根本原因是,不同的值在跟 Hash 函數(shù)計算后,可能會得到相同的下標(biāo),所以某個值的標(biāo)記位,可能會被其他值給標(biāo)上了。
這也是為啥布隆過濾器只能判斷某個值可能存在,無法判斷必然存在的原因。但是反過來,如果該值根據(jù) Hash 函數(shù)計算的標(biāo)記位沒有全部都為1,那么則說明必然不存在,這個是肯定的。
降低這種誤判率的思路也比較簡單:
一個是加大 bitSet 的長度,這樣不同的值出現(xiàn)“沖突”的概率就降低了,從而誤判率也降低。
提升 Hash 函數(shù)的個數(shù),Hash 函數(shù)越多,每個值對應(yīng)的 bit 越多,從而誤判率也降低。
布隆過濾器的誤判率還有專門的推導(dǎo)公式,有興趣的可以去搜相關(guān)的文章和論文查看。
43、緩存擊穿
描述:某一個熱點(diǎn) key,在緩存過期的一瞬間,同時有大量的請求打進(jìn)來,由于此時緩存過期了,所以請求最終都會走到數(shù)據(jù)庫,造成瞬時數(shù)據(jù)庫請求量大、壓力驟增,甚至可能打垮數(shù)據(jù)庫。
解決方案:
1)加互斥鎖。在并發(fā)的多個請求中,只有第一個請求線程能拿到鎖并執(zhí)行數(shù)據(jù)庫查詢操作,其他的線程拿不到鎖就阻塞等著,等到第一個線程將數(shù)據(jù)寫入緩存后,直接走緩存。
關(guān)于互斥鎖的選擇,網(wǎng)上看到的大部分文章都是選擇 Redis 分布式鎖(可以參考我之前的文章:面試必問的分布式鎖,你懂了嗎?),因?yàn)檫@個可以保證只有一個請求會走到數(shù)據(jù)庫,這是一種思路。
但是其實(shí)仔細(xì)想想的話,這邊其實(shí)沒有必要保證只有一個請求走到數(shù)據(jù)庫,只要保證走到數(shù)據(jù)庫的請求能大大降低即可,所以還有另一個思路是 JVM 鎖。
JVM 鎖保證了在單臺服務(wù)器上只有一個請求走到數(shù)據(jù)庫,通常來說已經(jīng)足夠保證數(shù)據(jù)庫的壓力大大降低,同時在性能上比分布式鎖更好。
需要注意的是,無論是使用“分布式鎖”,還是“JVM 鎖”,加鎖時要按 key 維度去加鎖。
我看網(wǎng)上很多文章都是使用一個“固定的 key”加鎖,這樣會導(dǎo)致不同的 key 之間也會互相阻塞,造成性能嚴(yán)重?fù)p耗。
使用 redis 分布式鎖的偽代碼,僅供參考:
public Object getData(String key) throws InterruptedException {Object value = redis.get(key);// 緩存值過期if (value == null) {// lockRedis:專門用于加鎖的redis;// "empty":加鎖的值隨便設(shè)置都可以if (lockRedis.set(key, "empty", "PX", lockExpire, "NX")) {try {// 查詢數(shù)據(jù)庫,并寫到緩存,讓其他線程可以直接走緩存value = getDataFromDb(key);redis.set(key, value, "PX", expire);} catch (Exception e) {// 異常處理} finally {// 釋放鎖lockRedis.delete(key);}} else {// sleep50ms后,進(jìn)行重試Thread.sleep(50);return getData(key);}}return value;}
2)熱點(diǎn)數(shù)據(jù)不過期。直接將緩存設(shè)置為不過期,然后由定時任務(wù)去異步加載數(shù)據(jù),更新緩存。
這種方式適用于比較極端的場景,例如流量特別特別大的場景,使用時需要考慮業(yè)務(wù)能接受數(shù)據(jù)不一致的時間,還有就是異常情況的處理,不要到時候緩存刷新不上,一直是臟數(shù)據(jù),那就涼了。
44、緩存雪崩
描述:大量的熱點(diǎn) key 設(shè)置了相同的過期時間,導(dǎo)在緩存在同一時刻全部失效,造成瞬時數(shù)據(jù)庫請求量大、壓力驟增,引起雪崩,甚至導(dǎo)致數(shù)據(jù)庫被打掛。
緩存雪崩其實(shí)有點(diǎn)像“升級版的緩存擊穿”,緩存擊穿是一個熱點(diǎn) key,緩存雪崩是一組熱點(diǎn) key。
解決方案:
1)過期時間打散。既然是大量緩存集中失效,那最容易想到就是讓他們不集中生效。可以給緩存的過期時間時加上一個隨機(jī)值時間,使得每個 key 的過期時間分布開來,不會集中在同一時刻失效。
2)熱點(diǎn)數(shù)據(jù)不過期。該方式和緩存擊穿一樣,也是要著重考慮刷新的時間間隔和數(shù)據(jù)異常如何處理的情況。
3)加互斥鎖。該方式和緩存擊穿一樣,按 key 維度加鎖,對于同一個 key,只允許一個線程去計算,其他線程原地阻塞等待第一個線程的計算結(jié)果,然后直接走緩存即可。
最后
恭喜你老哥,能看到這邊你已經(jīng)超越了不少人了,文中有些題目還是有點(diǎn)深度的,但是如能掌握相信定能助你在對線大廠面試官時不落下風(fēng),建議收藏反復(fù)閱讀。
有疑問的地方歡迎留言,我看到后都會回復(fù)。
我是囧輝,一個堅持分享原創(chuàng)技術(shù)干貨的程序員,我的目標(biāo)是幫助大家拿到心儀的大廠 Offer,我們下期見。
推薦閱讀
兩年Java開發(fā)工作經(jīng)驗(yàn)面試總結(jié)
4 年 Java 經(jīng)驗(yàn)面試總結(jié)、心得體會
5 年 Java 經(jīng)驗(yàn)字節(jié)、美團(tuán)、快手核心部門面試總結(jié)(真題解析)