
用 Python 刪除文件中的亂碼

當(dāng)我們用 Python 來(lái)處理有亂碼的文件時(shí),經(jīng)常會(huì)遇到編碼錯(cuò)誤,有時(shí)候不得不加一個(gè) errors = 'ignore' 參數(shù)來(lái)忽略錯(cuò)誤,今天分享一下如何用 Python 來(lái)刪除這些亂碼,得到一個(gè)干凈的文件。
先說(shuō)下思路:用二進(jìn)制方式打開文件,這樣就不會(huì)出現(xiàn)編碼問題,然后讀取每一個(gè)字節(jié),只要這個(gè)字節(jié)不在我們使用編碼的范圍內(nèi),就把它踢掉,然后保存剩下的字節(jié),我們得到的就是一個(gè)干凈的文件。
比如說(shuō)這樣 ascii 編碼的文件,它含有亂碼:
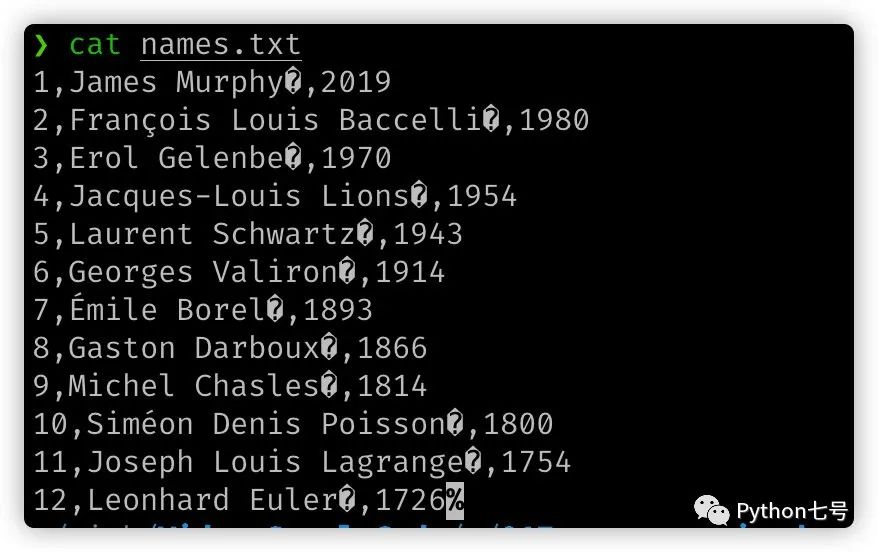
處理之后是這樣的:
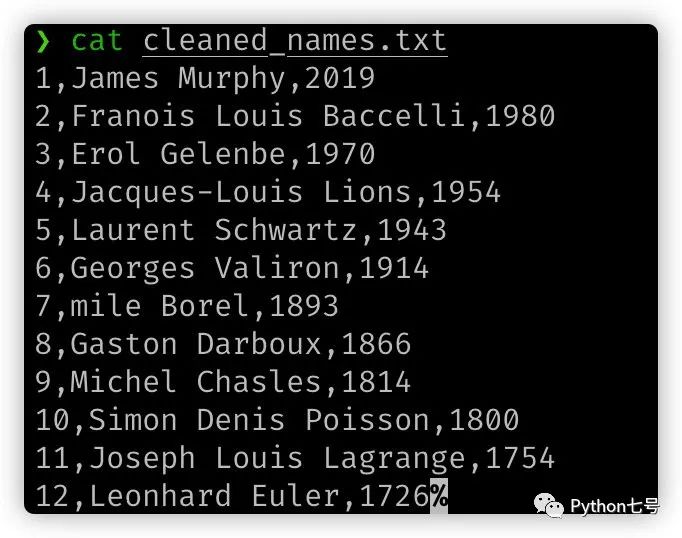
代碼是這樣寫的:
import?struct?
def?is_good_byte(b):
????"""
????可以自定義什么是好字節(jié),比如?GBK?的字節(jié)范圍可以在這里定義好
????"""
????return?b?<=?127
def?clean_bytes(bs):
????return?filter(is_good_byte,?bs)
def?clean_file_bin():
????with?open("names.txt",?mode?=?"rb")?as?reader:
????????with?open("cleaned_names.txt",?mode?=?"wb")?as?writer:
????????????for?line?in?reader:
????????????????for?byte?in?clean_bytes(line):
????????????????????writer.write(struct.pack('B',byte))
if?__name__?==?'__main__':
????clean_file_bin()
上面這段代碼是一個(gè)字節(jié)一個(gè)字節(jié)來(lái)處理的,如果是多字節(jié)編碼,可以自行修改代碼邏輯,比如一次讀取 3 個(gè)字節(jié),判斷這三個(gè)字節(jié)是否一個(gè)合法的字節(jié)組合。
對(duì)于中英文混合的,比如:
>>>?x
'abc中國(guó)'
>>>?x.encode("GBK")
b'abc\xd6\xd0\xb9\xfa'
>>>?for?i?in?x.encode("GBK"):
...?????print(i)
...
97
98
99
214
208
185
250
>>>
需要綜合判斷,先判斷是否英文字母,是的就放行,然后看接下來(lái)的兩個(gè)字節(jié)是否在 GBK 的編碼范圍之內(nèi),是的就放行,不是就要?jiǎng)h除,看看是刪除一個(gè)字節(jié),還是兩個(gè)字節(jié)就要繼續(xù)判斷了。刪除的依據(jù)就是不會(huì)造成更多亂碼。
今天的分享就到這里,如果有收獲請(qǐng)點(diǎn)贊哦。


評(píng)論
圖片
表情