
掌握 40 道實(shí)戰(zhàn)練習(xí)題,讓你輕松玩轉(zhuǎn) Python !
Pandas 是使用最廣泛的數(shù)據(jù)分析和操作庫之一。它提供了許多功能和方法來清理、處理、操作和分析數(shù)據(jù)。
本文我將列出 40 個(gè)示例,不僅包括常用函數(shù)和操作技巧,還包括一些功能強(qiáng)大卻非常低調(diào)的技巧,這些示例讓你輕松玩轉(zhuǎn) Python。文中數(shù)據(jù)文末可以獲取!
1、讀取 csv 文件
read_csv 提供了將 csv 文件讀取到 Pandas 數(shù)據(jù)幀的靈活方式。
import?numpy?as?np
import?pandas?as?pd
marketing?=?pd.read_csv("DirectMarketing.csv")
groceries?=?pd.read_csv("Groceries_dataset.csv")
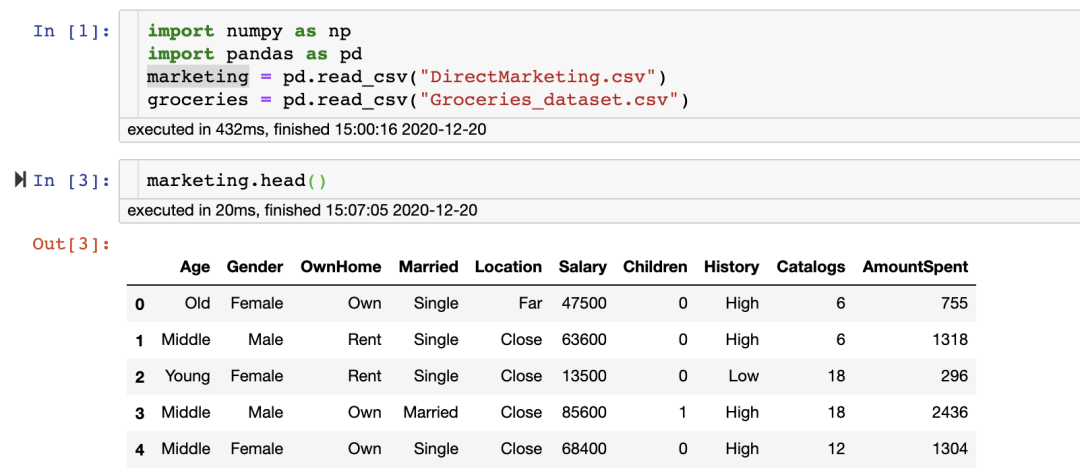
2、使用 astype 更改數(shù)據(jù)類型
日期需要存儲(chǔ)在日期時(shí)間數(shù)據(jù)類型中,以便使用 pandas 的日期時(shí)間函數(shù),查看數(shù)據(jù)框的數(shù)據(jù)類型。
groceries.dtypes
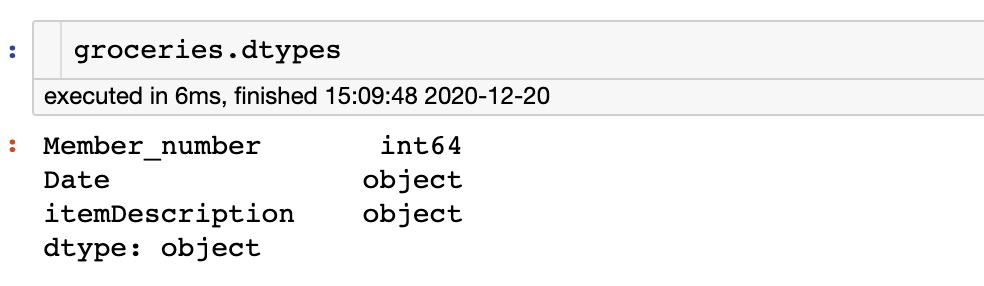
我們也可以使用 astype 函數(shù)更改數(shù)據(jù)類型。
groceries['Date']?=?groceries['Date'].astype("datetime64")
groceries.dtypes
Member_number???????????????int64
Date???????????????datetime64[ns]
itemDescription????????????object
3、使用 to_datetime 更改數(shù)據(jù)類型
我們還可以使用 to_datetime 為日期分配適當(dāng)?shù)臄?shù)據(jù)類型。語法與 astype 函數(shù)略有不同。
groceries['Date']?=?pd.to_datetime(groceries['Date'])
4、分析日期
在第一個(gè)示例中,我提到 read_csv 在讀取 csv 文件方面非常靈活。它還可以處理日期。我們可以在讀取數(shù)據(jù)時(shí)為日期分配適當(dāng)?shù)臄?shù)據(jù)類型。這將使我們不必在以后更改數(shù)據(jù)類型。
groceries?=?pd.read_csv("Groceries_dataset.csv",?parse_dates=['Date'])
groceries.dtypes
Member_number???????????????int64
Date???????????????datetime64[ns]
itemDescription????????????object
5、使用 isin 方法進(jìn)行篩選
有許多方法可以基于值篩選數(shù)據(jù)框。我們可以使用邏輯運(yùn)算符。
isin 方法允許基于一組特定的值進(jìn)行篩選。我們可以只傳遞要篩選的值的列表。
groceries[groceries.Member_number.isin([3737,?2433,?3915,?2625])].shape
6、~ 操作符
波浪(~)運(yùn)算符可理解為"不"。例如,我們可以在上一示例中找到篩選行的補(bǔ)充,只需在開頭添加波浪線運(yùn)算符。
groceries[~groceries.Member_number.isin([3737,?2433,?3915,?2625])].shape
(38639,?3)
7、值計(jì)數(shù)與規(guī)范化
value_counts是最常用的函數(shù)之一。它計(jì)算每個(gè)值的匹配次數(shù)并返回一個(gè)序列。如果與規(guī)范化參數(shù)一起使用,我們會(huì)獲得發(fā)生百分比的概覽。
marketing.Catalogs.value_counts(normalize=True)
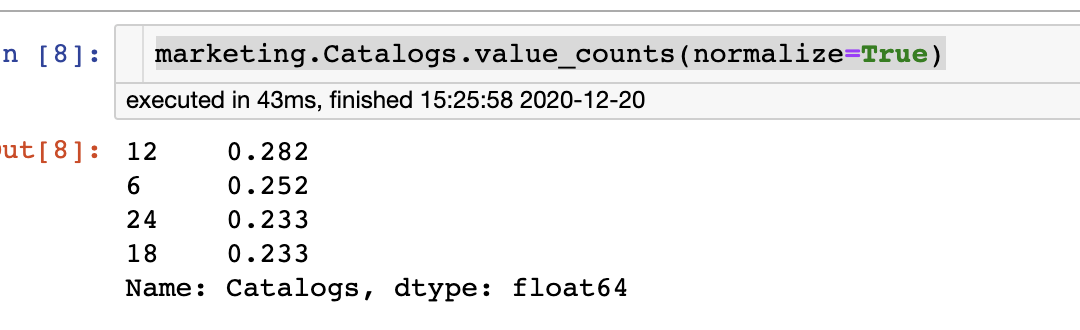
8、將列設(shè)置為索引
默認(rèn)情況下,Pandas 會(huì)為數(shù)據(jù)框分配整數(shù)索引,但我們也可以使用"索引"函數(shù)set_index。
例如,我們可以將日期列設(shè)置為數(shù)據(jù)框的索引。
groceries.set_index('Date',?inplace=True)
9、重置索引
刪除某些行時(shí),pandas 不會(huì)自動(dòng)重置索引。同樣,當(dāng)兩個(gè)數(shù)據(jù)框串聯(lián)時(shí),不會(huì)重置索引。在這種情況下,新數(shù)據(jù)框?qū)⒉痪哂羞B續(xù)索引值。
在這種情況下,可以實(shí)用 reset_index 函數(shù)。
groceries.reset_index(drop=True,?inplace=True)
如果我們不設(shè)置為 True,則舊索引將作為數(shù)據(jù)幀中的新列保留。
10、unique
unique 函數(shù)返回列中唯一值的數(shù)組。
groceries['itemDescription'].unique()[:5]
array(['tropical?fruit',?'whole?milk',?'pip?fruit',?'other?vegetables','rolls/buns'],?dtype=object)
11、創(chuàng)建較大尺寸的隨機(jī)樣本
sample 函數(shù)可用于創(chuàng)建數(shù)據(jù)幀的隨機(jī)樣本。在機(jī)器學(xué)習(xí)中處理不平衡數(shù)據(jù)集時(shí),它會(huì)派上用場。
我們只能創(chuàng)建小于原始樣本的樣本,除非替換參數(shù)更改為 true。讓我們只使用花費(fèi)少于 300 的來創(chuàng)建數(shù)據(jù)框的隨機(jī)樣本。
less?=?marketing[marketing.AmountSpent?300].sample(n=400,?replace=True)
less.shape
(400,?10)
12、組合數(shù)據(jù)框
我們可以水平或垂直地將數(shù)據(jù)幀與串聯(lián)函數(shù)串聯(lián)。
less.shape,?marketing.shape
((400,?10),?(1000,?10))
new?=?pd.concat([marketing,?less])
new.shape
(1400,?10)
13、按索引選擇行和列的范圍
我們可以使用 iloc 函數(shù)選擇行和列的范圍。它接受所需行和列的索引。
例如,我們可以選擇前 4 行和前 3 列,如下所示:
marketing.iloc[:4,:3]
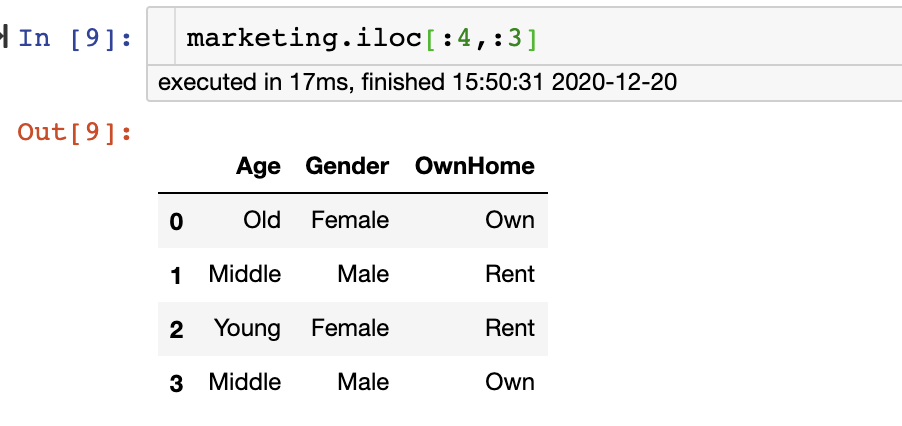
14、按索引選擇特定行和列
iloc 函數(shù)還接受值數(shù)組而不是范圍。我們可以傳遞一個(gè)列表或數(shù)字?jǐn)?shù)組。
toselect?=?np.random.randint(100,?size=7)
marketing.iloc[toselect,?[2,4,6]]
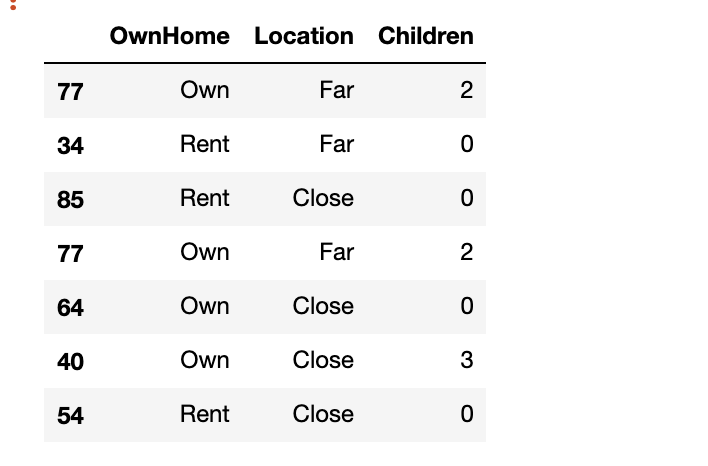
15、按標(biāo)簽選擇行和列
loc 函數(shù)與 iloc 函數(shù)一樣,但它接受標(biāo)簽而不是索引
marketing.loc[toselect,['Gender','Age','Age','Catalogs']]
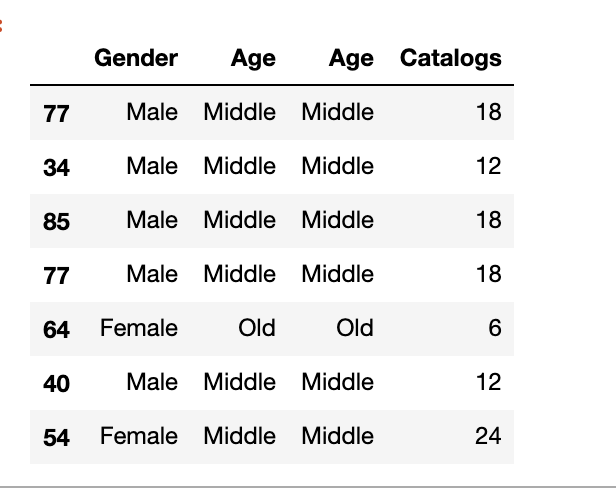
16、從日期提取年和月
pandas 提供了許多功能,在日期操作上,可以通過 dt 進(jìn)行操作使用。
我們可以輕松地從日期中提取日期和月份,如下所示:
groceries['Year']?=?groceries['Date'].dt.year
groceries['Month']?=?groceries['Date'].dt.month
17、刪除列和行
在上一個(gè)示例中,我們創(chuàng)建了兩個(gè)新列。默認(rèn)情況下,panas 在數(shù)據(jù)框的末尾添加新列,但我們可以更改它。
我們將在下一個(gè)示例中在特定位置添加新列。但是,我們首先需要?jiǎng)h除它們,這可以通過使用 drop 函數(shù)完成。
groceries.drop(['Year','Month'],?axis=1,?inplace=True)
18、插入列
如果將年和月份列放在日期列之前,則它們可能更好。我們可以使用插入函數(shù)來完成此任務(wù)
year?=?groceries['Date'].dt.year
month?=?groceries['Date'].dt.month
groceries.insert(1,?'Month',?month)
groceries.insert(2,?'Year',?year)
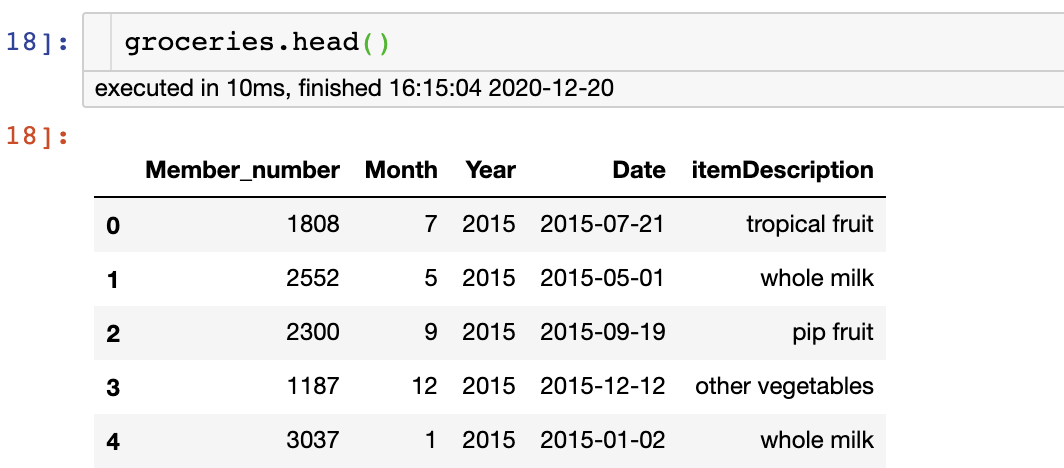
19、替換值
在上一個(gè)示例中,我們創(chuàng)建了一個(gè)包含表示月數(shù)的月份列。你可能希望此列包含月份的名稱(即 1 月、2 月等)。
有多種方法可以執(zhí)行此操作。我先告訴你更困難的方式。在下面的示例中,我們將看到一個(gè)更簡單的方法。
我們可以使用替換函數(shù)將整數(shù)替換為月份名稱字符串。
month_names?=?{1:'January',?2:'February',?3:'March',?4:'April',5:?'May',?6:'June',?7:'July',?8:'August',?9:'September',10:'October',?11:'November',?12:'December'}
groceries.Month.replace(month_names,?inplace=True)
我們創(chuàng)建了一個(gè)字典,然后將其傳遞給替換函數(shù)。
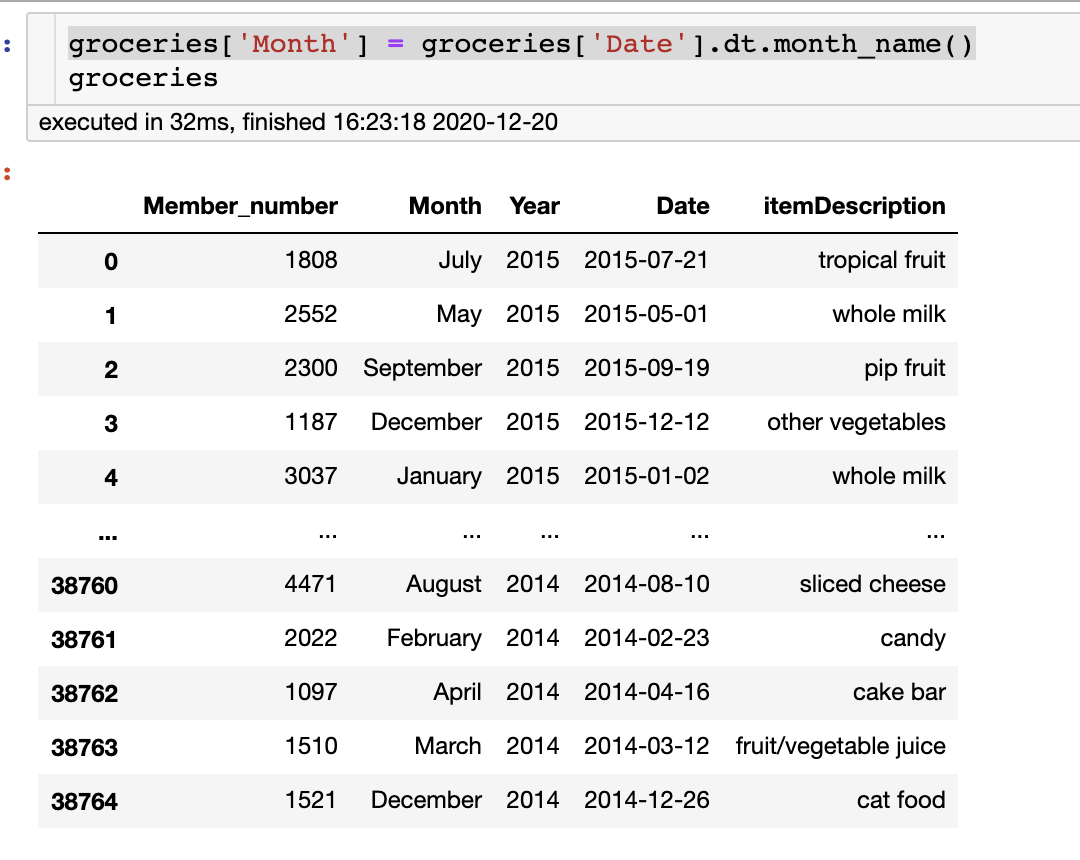
20、month_name
執(zhí)行上一步有更簡單的方法。
groceries['Month']?=?groceries['Date'].dt.month_name()
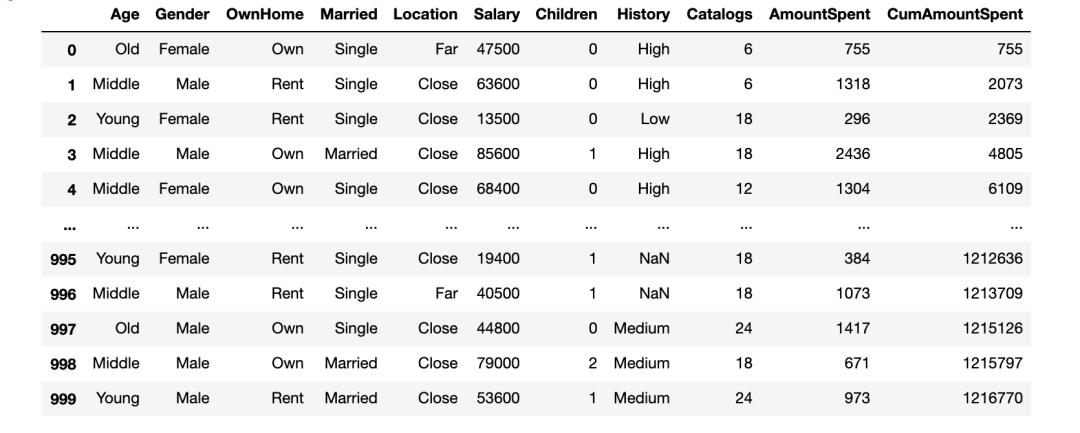
21、累計(jì)和
累積函數(shù)允許基于另一列的累積總和創(chuàng)建列。
marketing['CumAmountSpent']?=?marketing['AmountSpent'].cumsum()
marketing
22、字符串篩選
str提供了許多功能和方法,可以加快處理文本數(shù)據(jù)。
例如,我們可以檢查字符串是否包含一組特定的字符。典型的用法是否包含單詞。
groceries.itemDescription.str.contains('milk').sum()
groceries.itemDescription.str.contains('whole?milk').sum()
23、根據(jù)長度字符串篩選
我們還可以根據(jù)長度(即字符數(shù))篩選字符串。
groceries[groceries.itemDescription.str.len()?>?20]\
.itemDescription.unique()
array(['fruit/vegetable?juice',?'packaged?fruit/vegetables','frozen?potato?products',?'Instant?food?products','female?sanitary?products',?'house?keeping?products','chocolate?marshmallow',?'long?life?bakery?product','flower?soil/fertilizer',?'preservation?products'],?dtype=object)
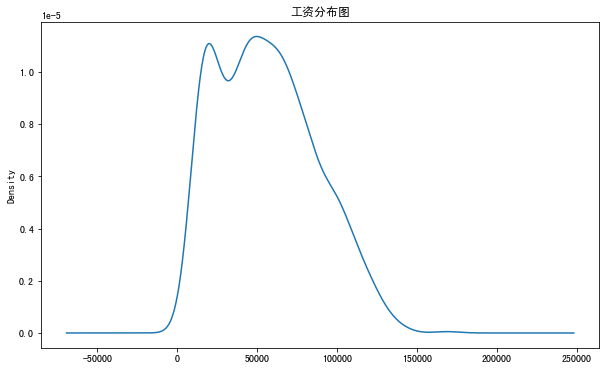
24、繪制變量的分布
pandas 不是數(shù)據(jù)可視化庫,因此未針對(duì)可視化任務(wù)進(jìn)行優(yōu)化。然而,它提供了繪圖函數(shù),我認(rèn)為這使得它非常方便地生成基本繪圖。
例如,我們可以創(chuàng)建 kde 繪圖以查看工資列的分布。
marketing.Salary.plot(kind='kde',?title='Distribution?of?Salary',figsize=(10,6))
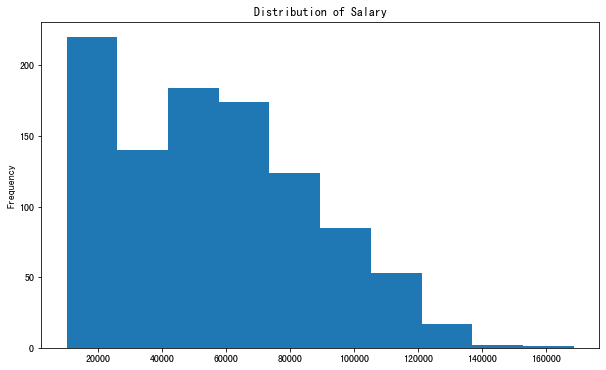
25、創(chuàng)建直方圖
我們也可以使用繪圖函數(shù)來生成直方圖。
marketing.Salary.plot(kind='hist',?title='Distribution?of?Salary',figsize=(10,6))
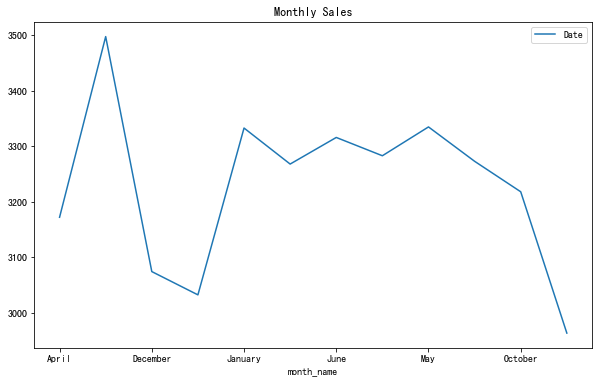
26、月銷售額趨勢
在此示例中,我們將合并幾個(gè)操作以創(chuàng)建顯示月銷售額趨勢的繪圖。
groceries['month_name']?=?groceries['Date'].dt.month_name()
groceries[['month_name','Date']].groupby('month_name').count().plot(title="Monthly?Sales",?figsize=(10,6))
27、不同列的不同聚合功能
可以按函數(shù)對(duì)組中的不同列應(yīng)用不同的聚合函數(shù)。我們可以傳遞一個(gè)字典來指示哪些函數(shù)將應(yīng)用于哪些列。
marketing[['Married','Salary','AmountSpent']].groupby(['Married']).agg({'Salary':'mean',?'AmountSpent':'sum'})
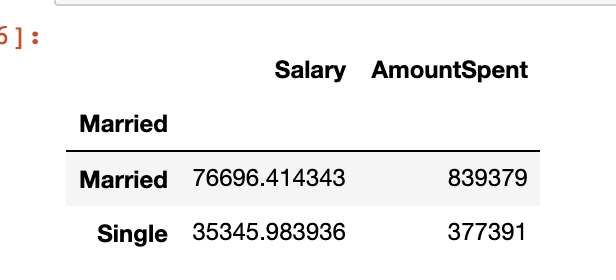
28、NamedAgg
我們將執(zhí)行與上一示例中相同的操作,更改結(jié)果中的列名稱。
marketing[['Married','Salary','AmountSpent']].groupby(['Married']).agg(
????Average_salary?=?pd.NamedAgg('Salary',?'mean'),
????Total_spent?=?pd.NamedAgg('AmountSpent',?'sum'))
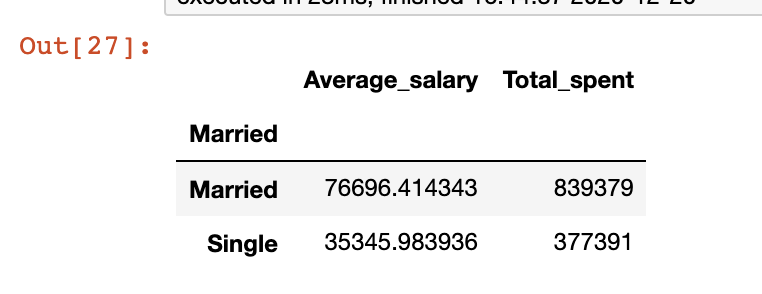
29、交叉表功能
交叉選項(xiàng)卡函數(shù)用于基于指定的列、值和聚合函數(shù)創(chuàng)建交叉表。它類似于數(shù)據(jù)透視表。
例如,我們可以計(jì)算年齡和性別列之間交叉類別的平均工資。
pd.crosstab(index=marketing.Age,?columns=marketing.Gender,?values=marketing.Salary,?aggfunc='mean').round(1)
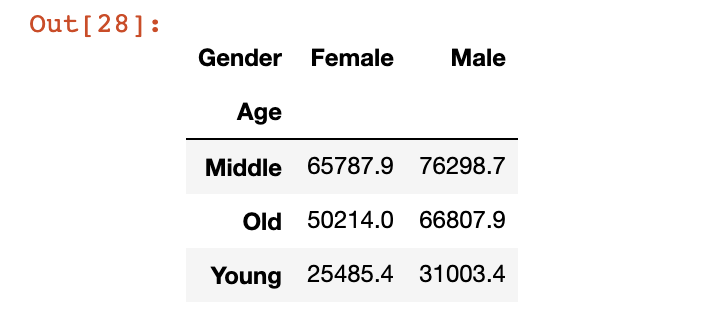
30、交叉表函數(shù)-2
我們將使用交叉表函數(shù)執(zhí)行一個(gè)稍微復(fù)雜一些的示例。我們可以傳遞多個(gè)列,并顯示總體值。
pd.crosstab(index=[marketing.Age,?marketing.Married],?columns=marketing.Gender,values=marketing.Salary,?aggfunc='mean',margins=True).round(1)
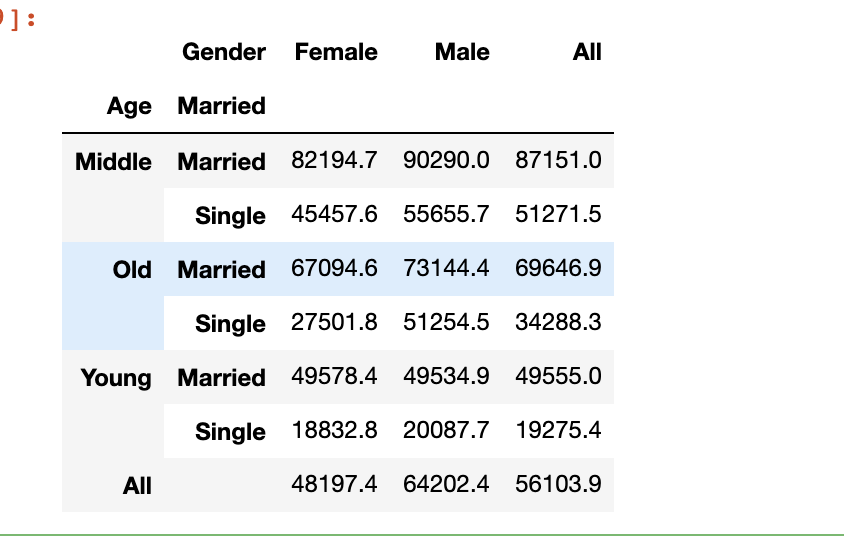
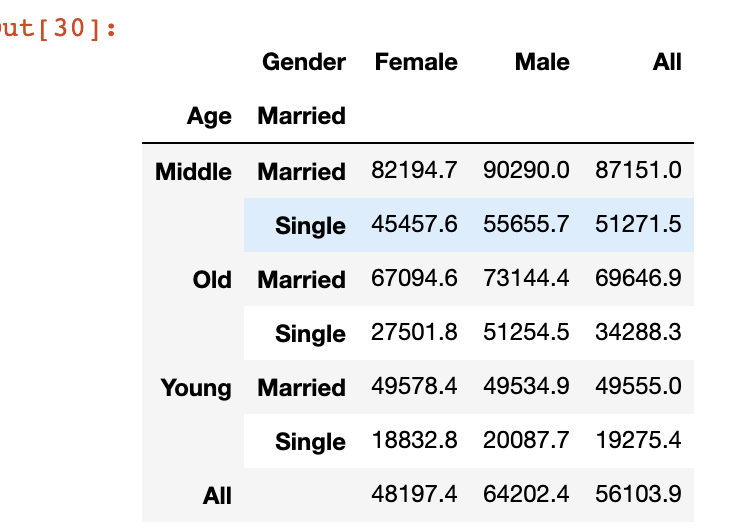
31、Pivot_table
它非常類似于交叉表函數(shù),語法上存在一些小差異。我將創(chuàng)建與上一個(gè)示例相同的表,使用 pivot_table 函數(shù)。
pd.pivot_table(data=marketing,?index=['Age',?'Married'],?columns='Gender',?values='Salary',?aggfunc='mean',margins=True).round(1)
32、拆分字符串
字符串訪問器可用于拆分或合并字符串。例如,我們可以拆分?jǐn)?shù)據(jù)框中日期的部分以獲取日期、月份和年。
請注意,數(shù)據(jù)類型應(yīng)為對(duì)象或字符串,以便能夠應(yīng)用 str。
groceries['month']?=?groceries['Date'].str.split('-',?expand=True)[1]
33、在字符級(jí)別拆分字符串
我們可以根據(jù)字符的位置選擇字符串的一部分。考慮前面的示例。我們可能想要檢索這些年的最后兩個(gè)字符。str 訪問器允許在字符串上編制索引。
groceries['year']?=?groceries['Date'].str.split('-',?expand=True)[2].str[-2:]
34、sidetable 側(cè)表
sidetable是 pandas 的附加組件,它使得創(chuàng)建數(shù)據(jù)框摘要更加容易。它可以被視為值計(jì)數(shù)和交叉選項(xiàng)卡函數(shù)的組合。
pip?install?sidetable
import?sidetable
groceries.stb.freq(['itemDescription'],?thresh=25)
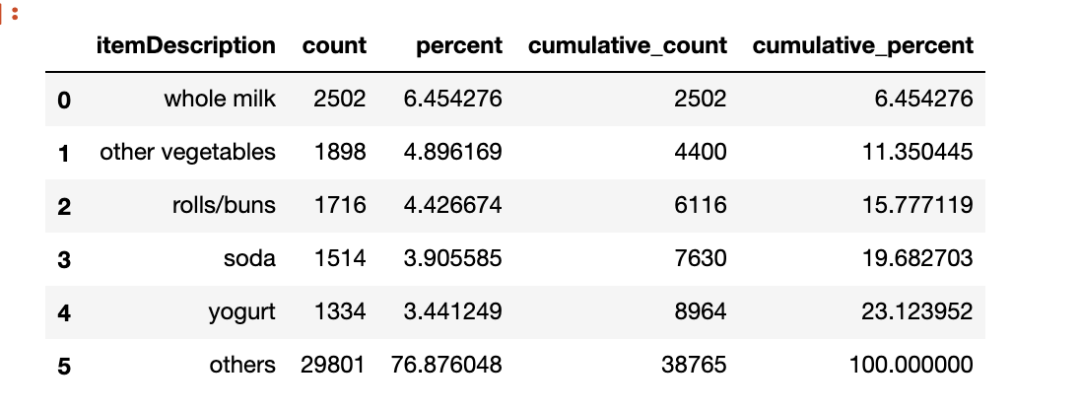
Freq 函數(shù)返回一個(gè)數(shù)據(jù)幀,該數(shù)據(jù)框傳達(dá)了 3 條信息。
每個(gè)類別(或value_counts)的觀測值數(shù)(即行)。 整個(gè)列(下列(正常=true)中每個(gè)value_counts的百分比。 上述兩個(gè)的累積版本。
sidetable 提供了更多的功能。如果你剛興趣可以進(jìn)一步了解。
35、查找缺失值
缺少值需要非常仔細(xì)地處理,以便進(jìn)行準(zhǔn)確和可靠的分析。
isna 函數(shù)可以使用 查找數(shù)據(jù)幀中缺失的值。如果缺少該值,則返回 true。因此,我們可以通過應(yīng)用 sum 函數(shù)來計(jì)算缺失值的總數(shù)。
groceries.isna().sum()
Member_number??????0
Date???????????????0
itemDescription????0
36、處理缺失值
填充函數(shù)可用于處理缺失值。它提供了許多選項(xiàng)來填充缺失的值,如平均值、中位數(shù)或常量值。
我們還可以使用上一個(gè)或下一個(gè)值來填充缺失的值。
讓我們首先將幾個(gè)值更改為數(shù)據(jù)幀中的缺失值。
groceries.iloc[[1,10,30],?[1,2]]?=?np.nan
groceries.isna().sum()
Member_number??????0
Date???????????????3
itemDescription????3
我們可以使用最常見的項(xiàng)來填充項(xiàng)目描述列中缺少的值。對(duì)于日期列,我們將使用上一個(gè)值替換缺失值。
groceries['itemDescription'].fillna(value=groceries['itemDescription'].mode()[0],?inplace=True)
groceries['Date'].fillna(method='ffill',?inplace=True)
groceries.isna().sum()
Member_number??????0
Date???????????????0
itemDescription????0
37、選擇數(shù)據(jù)類型
可以使用select_dtypes函數(shù)選擇屬于或不屬于特定數(shù)據(jù)類型的列。
marketing.select_dtypes(include='object').columns
Index(['Age',?'Gender',?'OwnHome',?'Married',?'Location',?'History'],?dtype='object')
marketing.select_dtypes(exclude='object').columns
Index(['Salary',?'Children',?'Catalogs',?'AmountSpent'],?dtype='object')
38、創(chuàng)建數(shù)據(jù)幀
DataFrame 函數(shù)可用于創(chuàng)建數(shù)據(jù)幀。字典可以傳遞到 DataFrame 函數(shù)。鍵將是列名稱,值將表示行值。
讓我們創(chuàng)建一個(gè)數(shù)據(jù)框。
unique_items?=?groceries.itemDescription.unique()
prices?=?pd.DataFrame({
????'itemDescription':?unique_items,
????'prices':np.random.randint(10,?size=len(unique_items))})
39、合并數(shù)據(jù)幀
合并函數(shù)可用于基于共享列或列合并兩個(gè)數(shù)據(jù)框。例如,我們可以根據(jù)物料描述列合并數(shù)據(jù)框。
merged_df?=?groceries.merge(prices,?on='itemDescription')
40、相關(guān)性
在執(zhí)行機(jī)器學(xué)習(xí)任務(wù)時(shí),需要考慮數(shù)值變量之間的相關(guān)性。
corr 函數(shù)計(jì)算相關(guān)性并返回包含變量之間相關(guān)系數(shù)的矩陣。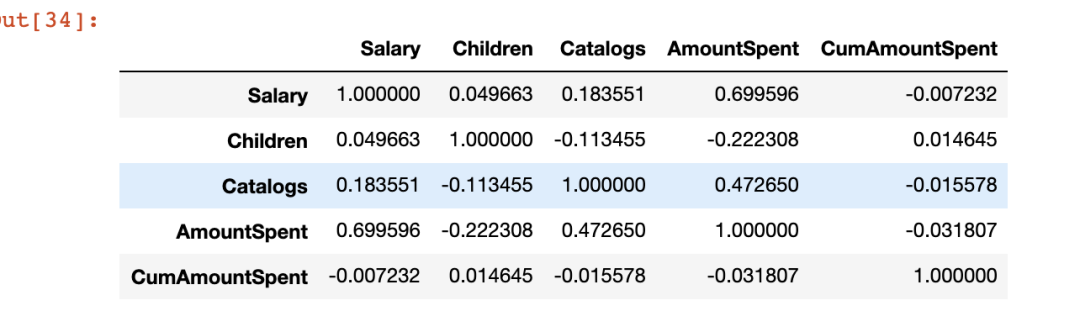
文中數(shù)據(jù)領(lǐng)取方式:
長按掃碼,發(fā)消息?[40]