
面試官:Kafka 為什么會丟消息?
點擊關(guān)注公眾號,Java干貨 及時送達(dá) ??
 來源
:
juejin.cn/post/7135101805179961352
來源
:
juejin.cn/post/7135101805179961352
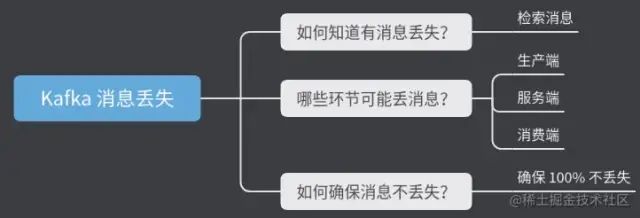
- 1、如何知道有消息丟失?
- 2、哪些環(huán)節(jié)可能丟消息?
- 3、如何確保消息不丟失?
引入 MQ 消息中間件最直接的目的:系統(tǒng)解耦以及流量控制(削峰填谷)
-
系統(tǒng)解耦: 上下游系統(tǒng)之間的通信相互依賴,利用
MQ消息隊列可以隔離上下游環(huán)境變化帶來的不穩(wěn)定因素。 -
流量控制: 超高并發(fā)場景中,引入
MQ可以實現(xiàn)流量 “削峰填谷” 的作用以及服務(wù)異步處理,不至于打崩服務(wù)。
引入 MQ 同樣帶來其他問題:數(shù)據(jù)一致性。
在分布式系統(tǒng)中,如果兩個節(jié)點之間存在數(shù)據(jù)同步,就會帶來數(shù)據(jù)一致性的問題。消息生產(chǎn)端發(fā)送消息到
MQ再到消息消費端需要保證消息不丟失。

所以在使用 MQ 消息隊列時,需要考慮這 3 個問題:
-
如何知道有消息丟失?
-
哪些環(huán)節(jié)可能丟消息?
-
如何確保消息不丟失?
 圖片
圖片
1、如何知道有消息丟失?
如何感知消息是否丟失了?可總結(jié)如下:
-
他人反饋: 運營、
PM反饋消息丟失。 -
監(jiān)控報警: 監(jiān)控指定指標(biāo),即時報警人工調(diào)整。
Kafka集群異常、Broker宕機、Broker磁盤掛載問題、消費者異常導(dǎo)致消息積壓等都會給用戶直接感覺是消息丟失了。
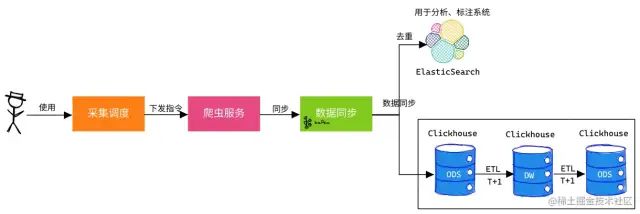
案例:輿情分析中數(shù)據(jù)采集同步
-
PM可自己下發(fā)采集調(diào)度指令,去采集特定數(shù)據(jù)。 -
PM可通過ES近實時查詢對應(yīng)數(shù)據(jù),若沒相應(yīng)數(shù)據(jù)可再次下發(fā)指令。
當(dāng)感知消息丟失了,那就需要一種機制來檢查消息是否丟失。
檢索消息
運維工具有:
-
查看
Kafka消費位置:
>?基于?Spring?Boot?+?MyBatis?Plus?+?Vue?&?Element?實現(xiàn)的后臺管理系統(tǒng)?+?用戶小程序,支持?RBAC?動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
>
>?*?項目地址:<https://gitee.com/zhijiantianya/ruoyi-vue-pro>
>?*?視頻教程:<https://doc.iocoder.cn/video/>
#?查看某個topic的message數(shù)量
$?./kafka-run-class.sh?kafka.tools.GetOffsetShell?--broker-list?localhost:9092?--topic?test_topic
>?基于?Spring?Cloud?Alibaba?+?Gateway?+?Nacos?+?RocketMQ?+?Vue?&?Element?實現(xiàn)的后臺管理系統(tǒng)?+?用戶小程序,支持?RBAC?動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
>
>?*?項目地址:<https://gitee.com/zhijiantianya/yudao-cloud>
>?*?視頻教程:<https://doc.iocoder.cn/video/>
#?查看consumer?Group列表
$?./kafka-consumer-groups.sh??--list??--bootstrap-server?192.168.88.108:9092
#?查看?offset?消費情況
$?./kafka-consumer-groups.sh?--bootstrap-server?localhost:9092?--group?console-consumer-1152?--describe
GROUP?????????????????TOPIC???????????PARTITION??CURRENT-OFFSET??LOG-END-OFFSET??LAG?????????????CONSUMER-ID???????????????????????????????????????????????????????????HOST????????????CLIENT-ID
console-consumer-1152?test_topic??????0??????????-???????????????4???????????????-???????????????consumer-console-consumer-1152-1-2703ea2b-b62d-4cfd-8950-34e8c321b942?/127.0.0.1??????consumer-console-consumer-1152-1
-
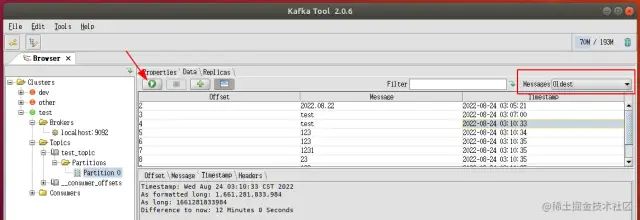
利用工具:
Kafka Tools
- 其他可見化界面工具
2、哪些環(huán)節(jié)可能丟消息?
一條消息從生產(chǎn)到消費完成經(jīng)歷 3 個環(huán)節(jié):消息生產(chǎn)者、消息中間件、消息消費者。
哪個環(huán)節(jié)都有可能出現(xiàn)消息丟失問題。
1)生產(chǎn)端
首先要認(rèn)識到 Kafka 生產(chǎn)端發(fā)送消息流程:
調(diào)用
send()方法時,不會立刻把消息發(fā)送出去,而是緩存起來,選擇恰當(dāng)時機把緩存里的消息劃分成一批數(shù)據(jù),通過Sender線程按批次發(fā)送給服務(wù)端Broker。
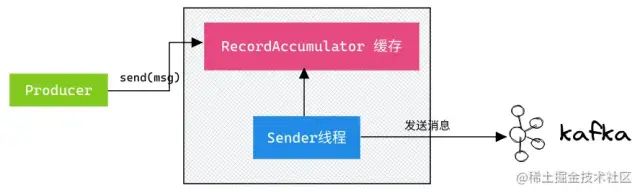
此環(huán)節(jié)丟失消息的場景有: 即導(dǎo)致 Producer 消息沒有發(fā)送成功
-
網(wǎng)絡(luò)波動: 生產(chǎn)者與服務(wù)端之間的鏈路不可達(dá),發(fā)送超時。現(xiàn)象是:各端狀態(tài)正常,但消費端就是沒有消費消息,就像丟失消息一樣。
-
-
*解決措施: *重試
props.put("retries", "10");
不恰當(dāng)配置: 發(fā)送消息無 ack 確認(rèn); 發(fā)送消息失敗無回調(diào),無日志。
producer.send(new?ProducerRecord<>(topic,?messageKey,?messageStr),?
??????????????????????????new?CallBack(){...});
-
*解決措施: *設(shè)置
acks=1或者acks=all。發(fā)送消息設(shè)置回調(diào)。
回顧下重要的參數(shù): acks
-
acks=0:不需要等待服務(wù)器的確認(rèn). 這是retries設(shè)置無效. 響應(yīng)里來自服務(wù)端的offset總是-1,producer只管發(fā)不管發(fā)送成功與否。延遲低,容易丟失數(shù)據(jù)。 -
acks=1:表示leader寫入成功(但是并沒有刷新到磁盤)后即向producer響應(yīng)。延遲中等,一旦leader副本掛了,就會丟失數(shù)據(jù)。 -
acks=all:等待數(shù)據(jù)完成副本的復(fù)制, 等同于-1. 假如需要保證消息不丟失, 需要使用該設(shè)置. 同時需要設(shè)置unclean.leader.election.enable為true, 保證當(dāng)ISR列表為空時, 選擇其他存活的副本作為新的leader.
2)服務(wù)端
先來了解下 Kafka Broker 寫入數(shù)據(jù)的過程:
-
Broker接收到一批數(shù)據(jù),會先寫入內(nèi)存PageCache(OS Cache)中。 -
操作系統(tǒng)會隔段時間把
OS Cache中數(shù)據(jù)進行刷盤,這個過程會是 「異步批量刷盤」 。
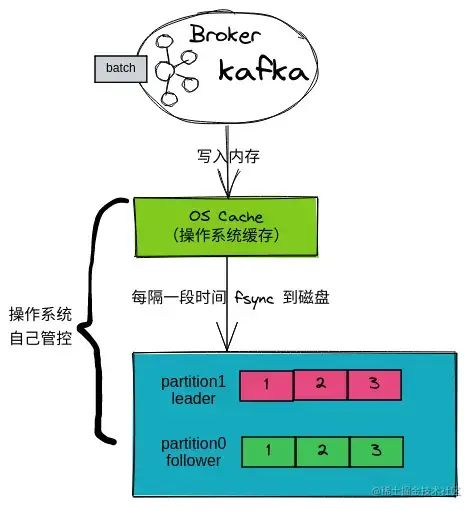
這里就有個隱患,如果數(shù)據(jù)寫入 PageCache 后 Kafka Broker宕機會怎樣?機子宕機/掉電?
-
Kafka Broker宕機: 消息不會丟失。因為數(shù)據(jù)已經(jīng)寫入PageCache,只等待操作系統(tǒng)刷盤即可。 -
機子宕機/掉電: 消息會丟失。因為數(shù)據(jù)仍在內(nèi)存里,內(nèi)存
RAM掉電后就會丟失數(shù)據(jù)。
- 解決方案 :使用帶蓄電池后備電源的緩存
cache,防止系統(tǒng)斷電異常。
- 對比學(xué)習(xí)
MySQL的 “雙1” 策略,基本不使用這個策略,因為 “雙1” 會導(dǎo)致頻繁的I/O操作,也是最慢的一種。- 對比學(xué)習(xí)
Redis的AOF策略,默認(rèn)且推薦的策略:**Everysec(AOF_FSYNC_EVERYSEC) 每一秒鐘保存一次(默認(rèn)):** 。每個寫命令執(zhí)行完, 只是先把日志寫到AOF文件的內(nèi)存緩沖區(qū), 每隔一秒把緩沖區(qū)中的內(nèi)容寫入磁盤。
拓展:Kafka 日志刷盤機制
#?推薦采用默認(rèn)值,即不配置該配置,交由操作系統(tǒng)自行決定何時落盤,以提升性能。
#?針對 broker 配置:
log.flush.interval.messages=10000?#?日志落盤消息條數(shù)間隔,即每接收到一定條數(shù)消息,即進行l(wèi)og落盤。
log.flush.interval.ms=1000????????#?日志落盤時間間隔,單位ms,即每隔一定時間,即進行l(wèi)og落盤。
#?針對 topic 配置:
flush.messages.flush.ms=1000??#?topic下每1s刷盤
flush.messages=1??????????????#?topic下每個消息都落盤
#?查看?Linux?后臺線程執(zhí)行配置
$?sysctl?-a?|?grep?dirty
vm.dirty_background_bytes?=?0
vm.dirty_background_ratio?=?10??????#?表示當(dāng)臟頁占總內(nèi)存的的百分比超過這個值時,后臺線程開始刷新臟頁。
vm.dirty_bytes?=?0
vm.dirty_expire_centisecs?=?3000????#?表示臟數(shù)據(jù)多久會被刷新到磁盤上(30秒)。
vm.dirty_ratio?=?20
vm.dirty_writeback_centisecs?=?500??#?表示多久喚醒一次刷新臟頁的后臺線程(5秒)。
vm.dirtytime_expire_seconds?=?43200
Broker 的可靠性需要依賴其多副本機制: 一般副本數(shù) 3 個(配置參數(shù):replication.factor=3)
-
Leader Partition副本:提供對外讀寫機制。 -
Follower Partition副本:同步Leader數(shù)據(jù)。
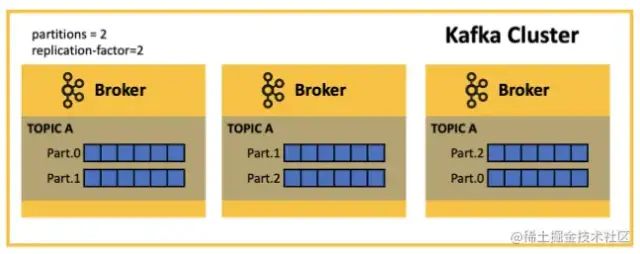
副本之間的數(shù)據(jù)同步也可能出現(xiàn)問題:數(shù)據(jù)丟失問題和數(shù)據(jù)不一致問題。
解決方案:ISR 和 Epoch 機制
-
ISR(In-Sync Replicas) : 當(dāng)Le``ader宕機,可以從ISR中選擇一個Follower作為Leader。 -
Epoch機制: 解決Leader副本高水位更新和Follower副本高水位更新在時間上是存在錯配問題。Tips:Kafka 0.11.x版本才引入leader epoch機制解決高水位機制弊端。
對應(yīng)需要的配置參數(shù)如下:
-
acks=-1或者acks=all: 必須所有副本均同步到消息,才能表明消息發(fā)送成功。 -
replication.factor >= 3: 副本數(shù)至少有 3 個。 -
min.insync.replicas > 1: 代表消息至少寫入 2個副本才算發(fā)送成功。前提需要acks=-1。舉個栗子:
Leader宕機了,至少要保證ISR中有一個Follower,這樣這個Follwer被選舉為Leader且不會丟失數(shù)據(jù)。公式:
replication.factor = min.insync.replicas + 1 -
unclean.leader.election.enable=false: 防止不在ISR中的Follower被選舉為Leader。Kafka 0.11.0.0版本開始默認(rèn)
unclean.leader.election.enable=false
3)消費端
消費端消息丟失場景有:
-
消息堆積: 幾個分區(qū)的消息都沒消費,就跟丟消息一樣。
-
- 解決措施: 一般問題都出在消費端,盡量提高客戶端的消費速度,消費邏輯另起線程進行處理。
自動提交: 消費端拉下一批數(shù)據(jù),正在處理中自動提交了 offset,這時候消費端宕機了; 重啟后,拉到新一批數(shù)據(jù),而上一批數(shù)據(jù)卻沒處理完。
-
解決措施: 取消自動提交
auto.commit = false,改為手動ack。
心跳超時,引發(fā) Rebalance: 客戶端心跳超時,觸發(fā) Rebalance被踢出消費組。如果只有這一個客戶端,那消息就不會被消費了。
同時避免兩次
poll的間隔時間超過閾值:
-
max.poll.records:降低該參數(shù)值,建議遠(yuǎn)遠(yuǎn)小于<單個線程每秒消費的條數(shù)> * <消費線程的個數(shù)> * <max.poll.interval.ms>的積。 -
max.poll.interval.ms: 該值要大于<max.poll.records> / (<單個線程每秒消費的條數(shù)> * <消費線程的個數(shù)>)的值。 -
解決措施: 客戶端版本升級至
0.10.2以上版本。
案例:凡凡曾遇到數(shù)據(jù)同步時,消息中的文本需經(jīng)過 NLP 的 NER 分析,再同步到 ES。
這個過程的主要流程是:
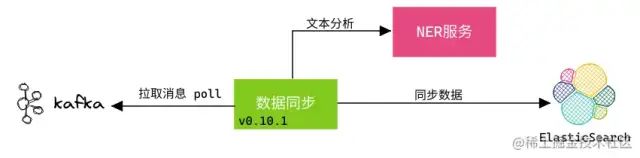
-
數(shù)據(jù)同步程序從
Kafka中拉取消息。 -
數(shù)據(jù)同步程序?qū)⑾?nèi)的文本發(fā)送的
NER進行分析,得到特征數(shù)組。 -
數(shù)據(jù)同步程序?qū)⑾⑼浇o
ES。
現(xiàn)象:線上數(shù)據(jù)同步程序運行一段時間后,消息就不消費了。
-
排查日志: 發(fā)現(xiàn)有
Rebalance日志,懷疑是客戶端消費太慢被踢出了消費組。 -
本地測試: 發(fā)現(xiàn)運行一段時間也會出現(xiàn)
Rebalance,且NLP的NER服務(wù)訪問HTTP 500報錯。 -
得出結(jié)論: 因
NER服務(wù)異常,導(dǎo)致數(shù)據(jù)同步程序消費超時。且當(dāng)時客戶端版本為v0.10.1,Consumer沒有獨立線程維持心跳,而是把心跳維持與poll接口耦合在一起,從而也會造成心跳超時。
當(dāng)時解決措施是:
-
session.timeout.ms: 設(shè)置為25s,當(dāng)時沒有升級客戶端版本,怕帶來其他問題。 -
熔斷機制: 增加
Hystrix,超過 3 次服務(wù)調(diào)用異常就熔斷,保護客戶端正常消費數(shù)據(jù)。
3、如何確保消息不丟失?
掌握這些技能:
- 熟悉消息從發(fā)送到消費的每個階段
-
監(jiān)控報警
Kafka集群 - 熟悉方案 “MQ 可靠消息投遞”
怎么確保消息 100% 不丟失?
到這,總結(jié)下:
- 生產(chǎn)端:
-
設(shè)置重試:
props.put("retries", "10"); -
設(shè)置
acks=all -
設(shè)置回調(diào):
producer.send(msg, new CallBack(){...});
- Broker:
-
內(nèi)存:使用帶蓄電池后備電源的緩存
cache。 -
Kafka版本0.11.x以上:支持Epoch機制。 -
replication.factor >= 3: 副本數(shù)至少有 3 個。 -
min.insync.replicas > 1: 代表消息至少寫入 2個副本才算發(fā)送成功。前提需要acks=-1。 -
unclean.leader.election.enable=false: 防止不在ISR中的Follower被選舉為Leader。
- 消費端
-
客戶端版本升級至
0.10.2以上版本。 -
取消自動提交
auto.commit = false,改為手動ack。 - 盡量提高客戶端的消費速度,消費邏輯另起線程進行處理。
1.?小公司里用SpringBoot做MySQL分庫分表,踩了一些坑!
3.?互聯(lián)網(wǎng)最值得加入的173家國企匯總!!
最近面試BAT,整理一份面試資料 《Java面試BATJ通關(guān)手冊》 ,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。
獲取方式:點“ 在看 ”,關(guān)注公眾號并回復(fù)? Java ?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。
PS:因公眾號平臺更改了推送規(guī)則,如果不想錯過內(nèi)容,記得讀完點一下 “在看” ,加個 “星標(biāo)” ,這樣每次新文章推送才會第一時間出現(xiàn)在你的訂閱列表里。
點“在看”支持小哈呀,謝謝啦