
scikit-learn 1.0 版本重要新特性一覽
1 簡(jiǎn)介
就在幾天前,著名的機(jī)器學(xué)習(xí)框架scikit-learn在pypi上釋放了其1.0rc1版本,這里給大家科普一下,版本號(hào)中的rc是Release Candidate的簡(jiǎn)稱(chēng),代表當(dāng)前的版本是一個(gè)候選發(fā)布版本,一旦到了這個(gè)階段,scikit-learn對(duì)于1.0版本的開(kāi)發(fā)設(shè)計(jì)就基本上不會(huì)再新增功能,而是全力投入到查缺補(bǔ)漏的測(cè)試中去也就意味著:
?經(jīng)歷了十余年的開(kāi)發(fā)進(jìn)程,
?scikit-learn即將迎來(lái)其頗具里程碑意義的一次大版本發(fā)布!

在這次大版本更新中,scikit-learn也很有誠(chéng)意地帶來(lái)了諸多新特性,下面我們就來(lái)對(duì)其中一些關(guān)鍵性的內(nèi)容進(jìn)行簡(jiǎn)單的介紹。
2 scikit-learn 1.0 版本重要特性一覽
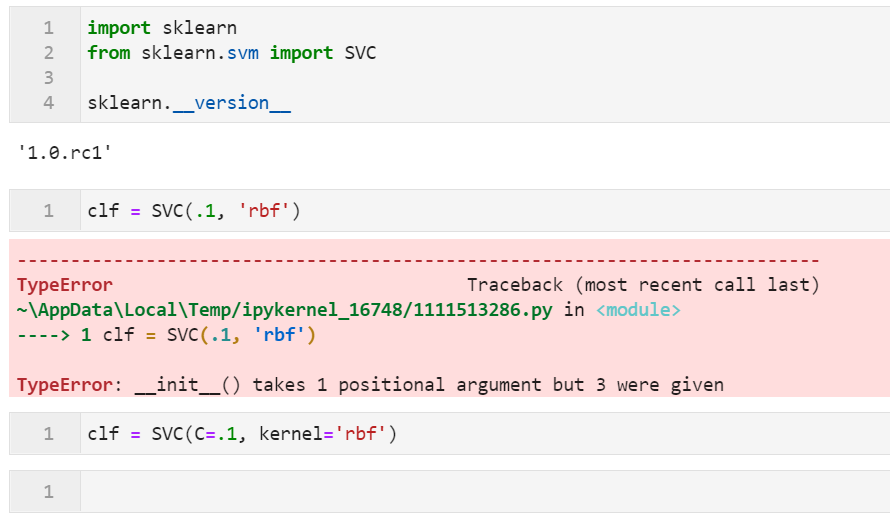
2.1 強(qiáng)制要求使用關(guān)鍵詞參數(shù)傳參
按照scikit-learn官方的說(shuō)法,為了更加清楚明確地構(gòu)建機(jī)器學(xué)習(xí)代碼,在之后的版本中,絕大部分API都將逐漸轉(zhuǎn)換為強(qiáng)制使用「關(guān)鍵詞參數(shù)」,使用「位置參數(shù)」則會(huì)直接拋出TypeError錯(cuò)誤,以SVC為例:
2.2 新增r_regression()
在新版本中新增了sklearn.feature_selection.r_regression(),可以用來(lái)快速計(jì)算各個(gè)自變量與因變量之間的皮爾遜簡(jiǎn)單相關(guān)系數(shù)來(lái)輔助特征工程過(guò)程。
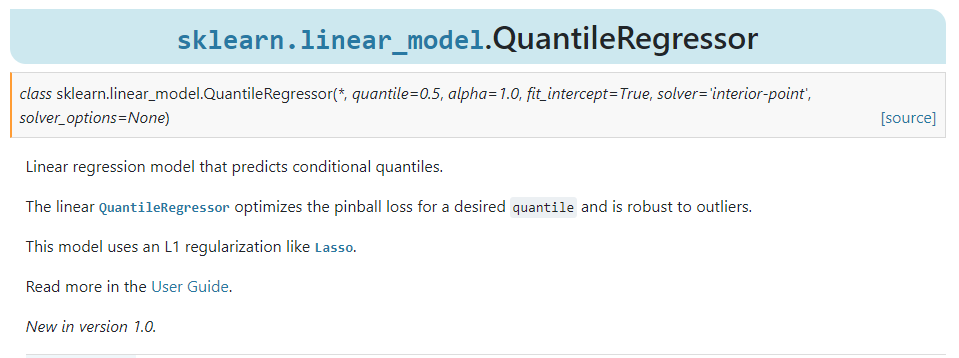
2.3 新增線性分位數(shù)回歸模型QuantileRegressor()
新版本中在sklearn.linear_model下添加了線性分位數(shù)回歸模型QuantileRegressor(),可用于構(gòu)建回歸模型由自變量求出因變量的條件分位數(shù),近年來(lái)在計(jì)量經(jīng)濟(jì)學(xué)中應(yīng)用廣泛。
2.4 新增基于隨機(jī)梯度下降的OneClassSvm模型
在sklearn.linear_model中新增了基于隨機(jī)梯度下降法的異常檢測(cè)模型SGDOneClassSVM():

2.5 帶交叉驗(yàn)證的Lasso回歸與ElasticNet新增sample_weight參數(shù)
為sklearn.linear_model中的LassoCV()與ElasticNetCV()新增參數(shù)sample_weight,可幫助我們?cè)谀P徒⒌倪^(guò)程中通過(guò)構(gòu)建權(quán)重提升部分樣本的重要性。
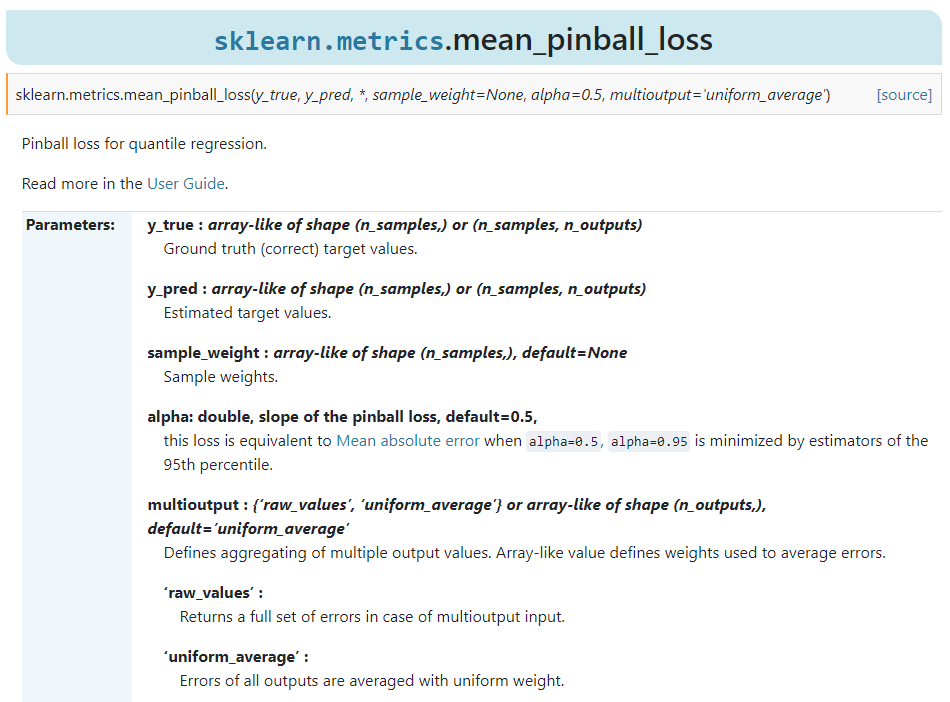
2.6 為分位數(shù)回歸模型新增模型性能度量指標(biāo)
伴隨著新的分位數(shù)回歸模型,scikit-learn也順勢(shì)新增了專(zhuān)門(mén)用于度量分位數(shù)回歸模型性能的Pinball loss系數(shù):
2.7 模型選擇新增StratifiedGroupKFold()
新版中將sklearn.model_selection中常用的StratifiedKFold()與GroupKFold()進(jìn)行結(jié)合,使得我們可以快速構(gòu)建分層分組K折交叉驗(yàn)證流程,詳情參考:https://scikit-learn.org/dev/modules/generated/sklearn.model_selection.StratifiedGroupKFold.html#sklearn.model_selection.StratifiedGroupKFold
2.8 KMeans聚類(lèi)中的k-means++初始化方法運(yùn)算速度提升
新版本中cklearn.cluster中常用的KMeans()與MiniBatchKMeans()聚類(lèi)模型,在默認(rèn)的k-means++簇心初始化方法下運(yùn)算速度獲得大幅度提高,尤其是在多核機(jī)器上表現(xiàn)更佳。
2.9 多項(xiàng)式&交互項(xiàng)特征生成速度提升
新版本中sklearn.preprocessing中用于快速合成多項(xiàng)式&交互項(xiàng)特征的PolynomialFeatures()的運(yùn)算速度更快了,且在輸入為大型稀疏特征時(shí)效果更為明顯。
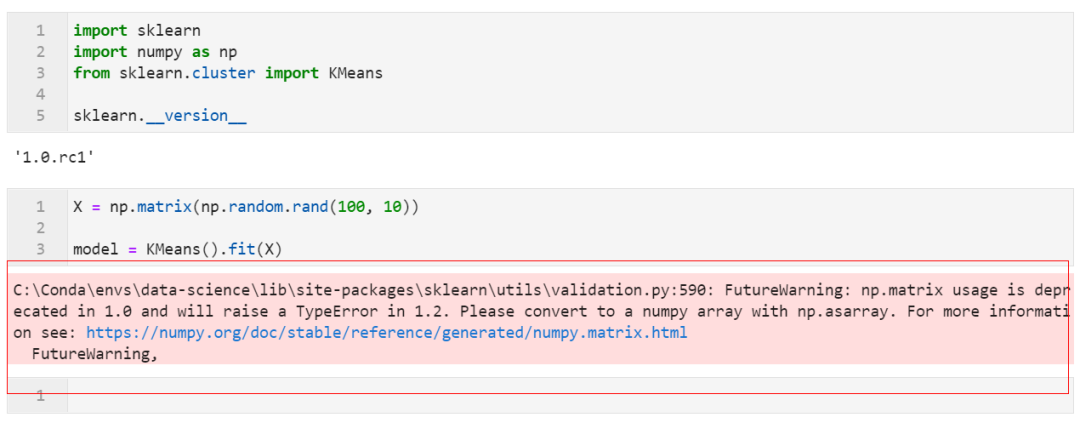
2.10 np.matrix型輸入即將棄用
從1.0版本開(kāi)始,scikit-learn中的各種算法模型在接受numpy中的matrix類(lèi)型輸入時(shí),會(huì)打印「棄用警告」,且從未來(lái)的1.2版本開(kāi)始,當(dāng)用戶輸入np.matrix類(lèi)型時(shí)將會(huì)直接報(bào)錯(cuò):
2.11 利用feature_names_in_獲取pandas數(shù)據(jù)框輸入下的特征名稱(chēng)
當(dāng)輸入的特征為pandas中的DataFrame類(lèi)型時(shí),對(duì)于訓(xùn)練好的模型,可以使用feature_names_in_屬性獲取到對(duì)應(yīng)輸入特征的字段名稱(chēng):

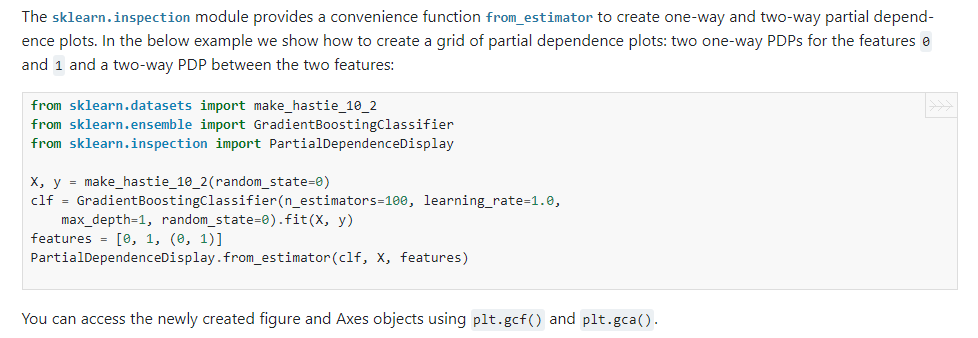
2.12 繪制局部依賴圖的方式變化
在我們?cè)噲D對(duì)模型進(jìn)行解釋時(shí),局部依賴圖是一個(gè)比較經(jīng)典的工具,在以前的版本中我們可以使用sklearn.inspection中的plot_partial_dependence()來(lái)繪制局部依賴圖,而在新版本中將會(huì)棄用這種方式,并且在1.2版本開(kāi)始正式移除這個(gè)API,新的替代方案是使用sklearn.inspection.PartialDependenceDisplay的from_estimator():
除了這些之外,在scikit-learn新版本中還有眾多的細(xì)碎的更新與調(diào)整內(nèi)容,感興趣的朋友可以前往https://scikit-learn.org/dev/whats_new/v1.0.html自行瀏覽學(xué)習(xí)。
相關(guān)閱讀: