
從R-CNN到Y(jié)OLO,2020 圖像目標(biāo)檢測算法綜述

極市導(dǎo)讀
?本文從Two-stage和One-stage兩個(gè)類別出發(fā),詳細(xì)的介紹總結(jié)了9種重要的圖像目標(biāo)檢測算法,并總結(jié)了目標(biāo)檢測模型的改進(jìn)思路。>>極市福利贈書活動(dòng):機(jī)器學(xué)習(xí)“蜥蜴書”最新版來了!豆瓣評分9.9!
基于CNN 的目標(biāo)檢測是通過CNN 作為特征提取器,并對得到的圖像的帶有位置屬性的特征進(jìn)行判斷,從而產(chǎn)出一個(gè)能夠圈定出特定目標(biāo)或者物體(Object)的限定框(Bounding-box,下面簡寫為bbox)。和low-level任務(wù)不同,目標(biāo)檢測需要預(yù)測物體類別及其覆蓋的范圍,因此需關(guān)注高階語義信息。傳統(tǒng)的非CNN 的方法也可以實(shí)現(xiàn)這個(gè)任務(wù),比如Selective Search 或者DPM。在初始的CNN 中,也采用了傳統(tǒng)方法生成備選框。
Contents
R-CNN SPP-net Fast R-CNN Faster R-CNN YOLO v1~v3 SSD FPN RetinaNet Mask R-CNN
傳統(tǒng)目標(biāo)檢測方法
Selective Search
Deformable Part Model
基于CNN 的目標(biāo)檢測
1. Two-stage 方法
所謂Two-stage 的方法,指的是先通過某種方式生成一些備選框,然后對備選框里的內(nèi)容進(jìn)行分類,并修正備選框的位置的方法。由于包含了region proposal 和detection 兩個(gè)步驟,因此稱為two-stage(兩階段)方法。最開始的CNN 目標(biāo)檢測就是兩階段的。
R-CNN
R-CNN 是最早利用CNN 實(shí)現(xiàn)目標(biāo)檢測任務(wù)的方法,由rbg(Ross Girshick)等人提出。這里的R 指的是Region,R-CNN 即“Regions with CNN features”,即對不同的區(qū)域進(jìn)行CNN 特征提取和分類。
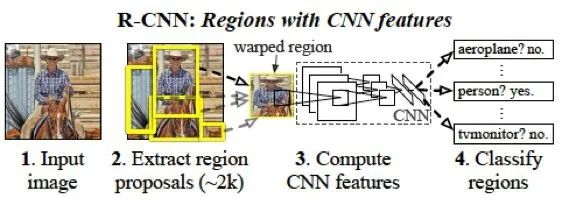
圖1.1: R-CNN 方法pipeline
鑒于CNN 在整圖分類任務(wù)中的優(yōu)異性能,很自然的想法是將其用于目標(biāo)檢測領(lǐng)域,將CNN 強(qiáng)大的數(shù)據(jù)驅(qū)動(dòng)的特征提取能力遷移到比整圖分類更細(xì)致和復(fù)雜的任務(wù)中。R-CNN 的思路相對容易理解,它主要有以下幾個(gè)步驟:
1. 通過Selective Search(SS)方法篩選出一些備選的區(qū)域框(Region proposal)。
2. 將這些備選的proposal 縮放到指定尺寸,用于輸入CNN 進(jìn)行分類(根據(jù)某種規(guī)則將各個(gè)proposal 分成正負(fù)樣本)。其目的在于通過訓(xùn)練CNN,得到每個(gè)region proposal 的定長特征向量。
3. 用每個(gè)proposal 中提取的特征向量訓(xùn)練SVM,得到最終的分類結(jié)果。
4. 利用非極大值抑制(Non-Maximun Suppresion) 方法,對最終得到的bbox 進(jìn)行篩選。
5. 分類完成后,對bbox 進(jìn)行回歸,修正bbox 中的坐標(biāo)的值,得到更精確的bbox。
詳細(xì)來說,第一步中,SS 可以得到大量的備選框,這些框中都有可能有某個(gè)類別的目標(biāo),因此都需要進(jìn)行后續(xù)的處理。這個(gè)步驟是不區(qū)分類別的。第二步驟中,由于第一步SS 得到的proposal 沒有指定大小和比例(長寬比),因此用普通的CNN(R-CNN 中用的是AlexNet)無法得到一樣長度的特征向量。R-CNN 采取的對策是直接用縮放的方式將所有proposal 強(qiáng)行整理成同樣的大小。這里的縮放并不確切,實(shí)際上是某種形變(warp),因?yàn)檫@種操作可能會導(dǎo)致proposal 的長寬比例發(fā)生改變,導(dǎo)致目標(biāo)物體也發(fā)生形變。縮放完成后,剩下的步驟就是普通的整圖分類時(shí)的結(jié)果,即輸入CNN,輸出每個(gè)類別的概率的向量。由于這個(gè)任務(wù)上(Image classification)已經(jīng)有了很多在ImageNet 這種大數(shù)據(jù)集上預(yù)訓(xùn)練好的模型,因此可以直接借用,進(jìn)行微調(diào)(fine-tune)。這個(gè)過程并不是最終的分類結(jié)果,而是只用來得到最后一層的特征向量。然后,將特征向量用來訓(xùn)練SVM,得到最終的分類。(這種先CNN 再SVM 的方法,僅僅將CNN 作為feature extractor,這種策略在有些場景下效果要比直接CNN 輸出結(jié)果要好。這個(gè)實(shí)際上就是用SVM 替換了CNN 的最后一個(gè)LR。)
這里有一個(gè)注意點(diǎn),即正負(fù)樣本如何確定(CNN 和SVM 都需要有監(jiān)督的樣本)。這里,也是采用了groundtruth(GT)和SS 的proposal 之間的IoU 來進(jìn)行確定。如果一個(gè)proposal 和某個(gè)類別的GT 的IoU 大于某個(gè)閾值,那么,這個(gè)proposal 的樣本就被視為該類別的正樣本。
最后要進(jìn)行的是NMS 操作,這個(gè)是為了避免很多大小類似且只有微小位移的框(它們實(shí)際上框定的是同一個(gè)object)都被輸出,導(dǎo)致框的重疊和冗余。NMS 的過程如下:
輸入:所有預(yù)測結(jié)果大于閾值的bbox,包含四個(gè)位置坐標(biāo)(角點(diǎn)的x 和y,以及長w 寬h),以及一個(gè)置信度c。
輸出:過濾了重復(fù)和冗余后的bbox 列表。
過程:
首先,將所有預(yù)測出的bbox 按照c 進(jìn)行降序排列。另外,維護(hù)一個(gè)輸出列表list,初始化為空。然后進(jìn)行遍歷,每次取出一個(gè)bbox。如果該bbox 與list 中的某個(gè)bbox 具有超過閾值thr 的IoU,那么不輸出該bbox。否則,將該bbox 加入list。當(dāng)所有預(yù)測的bbox 都被遍歷完后,NMS 算法結(jié)束。
可以看出,如果bbox 和list 中的某個(gè)已有的決定輸出的bbox 重疊較大,那么說明它們只需要留下一個(gè)即可。根據(jù)置信度,我們肯定選擇留下置信度高的那個(gè)。由于已經(jīng)按照置信度排好序了,所以先進(jìn)入list 的自然置信度更高,所以直接舍棄后面的即可。
最后一步,利用特征預(yù)測邊框的位置,即bbox 回歸。該過程的輸入是CNN 的特征,這里用的是pool5 的特征,需要回歸的目標(biāo)值并不是實(shí)際的x,y,w,h。由于我們已經(jīng)用SS 給出了一個(gè)位置,所以只需要預(yù)測兩者的差異即可。具體公式為:
tx = (Gx ? Px)/Pw
tx = (Gy ? Py)/Ph
tw = log(Gw/Pw)
th = log(Gh/Ph)
公式中G 表示ground-truth,P 表示predict。根據(jù)公式,這樣的目標(biāo)變量相對比較穩(wěn)定,便于回歸。R-CNN 在SS 過程中需要花費(fèi)較多時(shí)間,且對每個(gè)proposal 都要過一遍CNN,因此效率較低。基于R-CNN的一些問題和缺陷,后面的方法做了不同程度不同方向的修正,從而形成了以R-CNN 為源頭的一條清晰的研究線路。
SPP-net
SPP-net 是何愷明、孫健等人的作品。SPP-net 的主要?jiǎng)?chuàng)新點(diǎn)就是SPP,即Spatial pyramid pooling,空間金字塔池化。該方案解決了R-CNN 中每個(gè)region proposal 都要過一次CNN 的缺點(diǎn),從而提升了效率,并且避免了為了適應(yīng)CNN 的輸入尺寸而圖像縮放導(dǎo)致的目標(biāo)形狀失真的問題。
在R-CNN 中,整個(gè)處理流程是這樣的:
圖像- 候選區(qū)域-CNN - 特征- 輸出
而對于SSP-net 來說,上面的過程變成了:
圖像- CNN -SPP - 特征- 輸出
可以看出,R-CNN 中,每個(gè)區(qū)域都要過一次CNN 提取特征。而SPP-net 中,一張圖片只需要過一次CNN,特征提取是針對整張圖進(jìn)行的,候選區(qū)域的框定以及特征向量化是在CNN 的feature map 層面進(jìn)行的,而非直接在原始圖像上進(jìn)行(R-CNN)。
R-CNN 之所以要對候選框進(jìn)行縮放后再輸入CNN,是為了保證輸入圖片尺寸一致,從而得到定長特征向量(全連接層的存在使得CNN 需要輸入同樣大小的圖像)。如果直接用不同的region proposal 的框來限定某個(gè)區(qū)域,就需要有某種辦法保證也能得到不受輸入尺寸影響的定長向量。這種辦法就是SPP。
SPP 實(shí)際上是一種自適應(yīng)的池化方法,它分別對輸入的feature map(可以由不定尺寸的輸入圖像進(jìn)CNN得到,也可由region proposal 框定后進(jìn)CNN 得到)進(jìn)行多個(gè)尺度(實(shí)際上就是改變pooling 的size 和stride)的池化,分別得到特征,并進(jìn)行向量化后拼接起來。如圖。
和普通的pooling 固定size 不同(一般池化的size 和stride 相等,即每一步不重疊),SPP 固定的是池化過后的結(jié)果的尺寸,而size 則是根據(jù)尺寸計(jì)算得到的自適應(yīng)數(shù)值。這樣一來,可以保證不論輸入是什么尺寸,輸出的尺寸都是一致的,從而最終得到定長的特征向量。
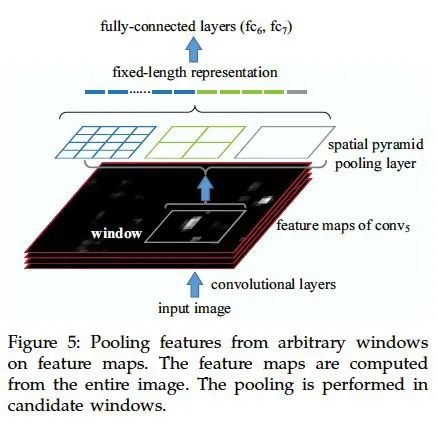
圖1.2: SPP 結(jié)構(gòu)
SPP 的window size 和stride 的計(jì)算如下:
win = ceil(a/n), str = floor(a/n)
除了SPP 外,SPP-net 也沿用了hard negative sampling 和NMS 等技術(shù)。
Fast R-CNN
Fast R-CNN 是rbg 對之前提出的R-CNN 的改進(jìn)版。主要結(jié)構(gòu)如下:
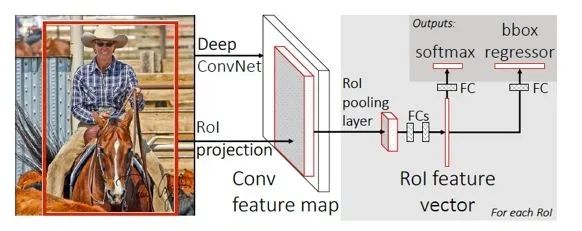
圖1.3: Fast R-CNN 結(jié)構(gòu)
從SPP-net 的分析中其實(shí)可以看出,制約R-CNN 速度的實(shí)際上就是對一張圖片的多個(gè)ROI 進(jìn)行的很多重復(fù)的CNN 計(jì)算。因此,只需要對一張圖片計(jì)算一遍CNN 的feature map,然后對各個(gè)ROI 分別整理出特征就可以了。SPP 中的所謂“金字塔”結(jié)構(gòu)和解決R-CNN 的速度問題關(guān)系不太大,主要還是由于SPP 對各個(gè)ROI的feature map 直接提特征導(dǎo)致了效率的提高。因此,F(xiàn)ast R-CNN 也沿用這個(gè)思路進(jìn)行了改造升級,變成了Fast R-CNN。
Fast R-CNN 提出了ROI pooling 的結(jié)構(gòu),實(shí)際上就是一種特殊的SPP(相當(dāng)于SPP 的金字塔層數(shù)設(shè)置為了1,即只計(jì)算一次池化)。
Fast R-CNN 的另一個(gè)改造是,將最終的SVM 分類去掉了,直接做成了端到端的一個(gè)網(wǎng)絡(luò)結(jié)構(gòu)。對這個(gè)網(wǎng)絡(luò)進(jìn)行多任務(wù)訓(xùn)練,即分類和回歸,得到物體類別和bbox 的位置。這個(gè)多任務(wù)的損失函數(shù)如下:
L = losscls(p, u) + [u ≥ 1]lossloc(tu, v) (1.3)
其中,losscls 為分類損失,形式為?log pu,pu 為真實(shí)類別上的預(yù)測概率。而lossloc 為位置損失,只在非背景(u=0 是背景,u ≥ 1 表示非背景的類別)才進(jìn)行位置損失的優(yōu)化。位置損失的函數(shù)形式為smooth-L1 損失,即在自變量小于1 的時(shí)候?yàn)槠椒巾?xiàng),而大于1 的時(shí)候?yàn)長1 損失。之所以采用L1 損失,是因?yàn)榛貧w的預(yù)測沒有范圍限制,L1 函數(shù)可以較好地抑制異常點(diǎn)的影響。
Faster R-CNN
Faster R-CNN 在Fast R-CNN 的基礎(chǔ)上又進(jìn)行了改進(jìn)。主要的改進(jìn)點(diǎn)是利用RPN 網(wǎng)絡(luò)(Region Proposal Network)代替了Selective Search 生成備選框。另外,引入了anchor 的概念,anchor 方法在后面的模型中也一直被沿用了下來。
首先介紹RPN 網(wǎng)絡(luò)。在前面的模型中,計(jì)算時(shí)間效率的時(shí)候都排除了預(yù)先SS 生成候選框的過程的時(shí)間消耗。但是實(shí)際上這一部分占據(jù)了較多的時(shí)間。因此,在Faster R-CNN 中,不再預(yù)先利用SS 生成候選框,而是利用一個(gè)與檢測器共享部分權(quán)重的RPN 網(wǎng)絡(luò)來直接對圖片生成候選框,然后基于RPN 得到的候選框進(jìn)行分類和位置回歸。
基于RPN 的Faster R-CNN 網(wǎng)絡(luò)的結(jié)構(gòu)如下:
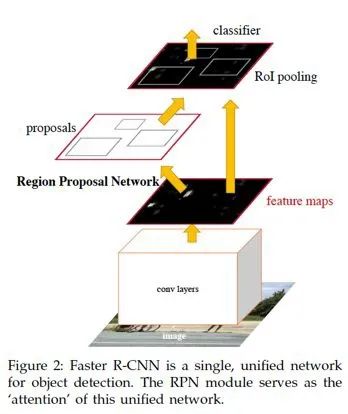
圖1.4: Faster R-CNN 結(jié)構(gòu)
可以看出,RPN 的region proposal 也是基于前面的CNN backbone 提取的feature map 進(jìn)行的,而檢測則是基于ROI pooling,和之前一樣。整個(gè)過程中,原始圖像過了一遍CNN,所有的操作都是基于整圖的featuremap 進(jìn)行的。
RPN 網(wǎng)絡(luò)是基于anchor box 的方式進(jìn)行的。過程示意圖:
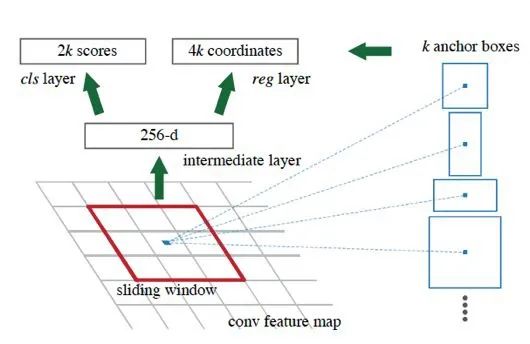
圖1.5: RPN 的過程
首先,定義anchor box 的尺寸(scale)和比例(aspect ratio)。按上圖,預(yù)先定義了k 個(gè)anchor box。在實(shí)際的RPN 網(wǎng)絡(luò)實(shí)現(xiàn)中,共采用了3 個(gè)不同的scale(大中小)和3 種不同的比例(寬中窄)。然后通過組合,得到了9 個(gè)anchor box,即k=9。在訓(xùn)練RPN 的過程中,對于每個(gè)feature map 上的像素點(diǎn),都生成k 個(gè)anchorbox 的預(yù)測。由于預(yù)測需要有兩個(gè)輸出用來分類(前景/背景),以及4 個(gè)用來定位(x,y,w,h),所以RPN 的分類層生成的是2k 維度的向量,RPN 的回歸層生成的是4k 維度的向量。
既然要訓(xùn)練RPN 的分類,就需要定義正負(fù)樣本。在RPN 中,正樣本被定義為滿足如下條件之一的那些anchor box:1. 在anchor box 中具有最高的GT IoU;2. GT IoU 大于0.7。而對于負(fù)樣本來說,只要滿足GTIoU 小于0.3,即被認(rèn)定為負(fù)樣本。除了上面的正負(fù)樣本以外,其他的anchor box(即不滿足正樣本也不滿足負(fù)樣本條件的)不參與訓(xùn)練,對損失函數(shù)優(yōu)化沒有貢獻(xiàn)。
RPN 的損失函數(shù)和Fast R-CNN 的類似,分類損失根據(jù)預(yù)測和GT 的類別計(jì)算,回歸損失只用label=1,即有object 的那些預(yù)測結(jié)果的框計(jì)算。回歸仍然用的是smooth L1 損失。基于anchor box 回歸邊框的目標(biāo)值和基于SS 的類似,也是用proposal 的值作為基準(zhǔn),只回歸一個(gè)位移和縮放。由于Faster R-CNN 中采用了網(wǎng)絡(luò)做region proposal 和檢測,所以訓(xùn)練方式與之前有所不同。在實(shí)現(xiàn)中,首先用ImageNet 預(yù)訓(xùn)練做初始化,然后訓(xùn)練RPN,訓(xùn)練好RPN 后就可以生成region proposal 了,然后用RPN 的proposal 單獨(dú)訓(xùn)練Fast R-CNN,即檢測網(wǎng)絡(luò)。然后再用檢測網(wǎng)絡(luò)初始化RPN,并保持公共的層的權(quán)重固定,對檢測網(wǎng)絡(luò)的非共享層進(jìn)行微調(diào)。
Faster R-CNN 由于可以端到端的進(jìn)行,無需SS 提前準(zhǔn)備備選框,因此可以做到近實(shí)時(shí)的速度(near real time),所有過程可以5fps 的速度實(shí)現(xiàn)。
2. One-stage 方法
與two-stage 方法不同,one-stage 的思路是直接對圖像進(jìn)行各個(gè)位置上的候選框的預(yù)測和分類,不需要預(yù)先生成一些備選框。以YOLO 和SSD 等方法為代表的就是one-stage(單階段)方法。
YOLO (v1)
“YOLO”是一句美語俚語“you live only once”的縮寫,字面意思是“人生只有一次”,引申義即“及時(shí)行樂”,表達(dá)一種人生態(tài)度。本模型的名稱借鑒了YOLO 這個(gè)說法,全名是:You Only Look Once,表示只需要看一次即可完成識別,主要是為了與之前的兩階段(看兩次)進(jìn)行區(qū)分。我們?nèi)祟惪吹侥硞€(gè)場景時(shí),并不會先看一下有沒有物體,物體在哪,然后再確定這個(gè)物體是什么,而是“只看一次”,就完成目標(biāo)位置和內(nèi)容的判斷。
YOLO 的模型結(jié)構(gòu)和之前的以R-CNN 為基礎(chǔ)的模型差別較大,整個(gè)過程如下所示:
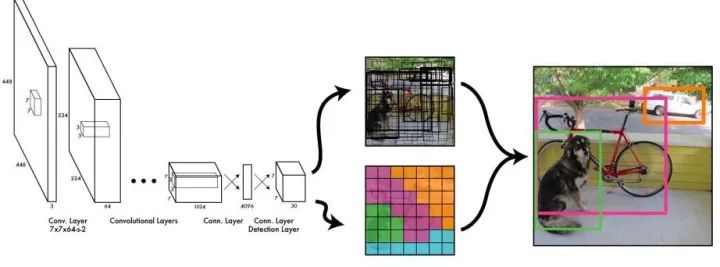
圖1.6: YOLO v1 網(wǎng)絡(luò)結(jié)構(gòu)
YOLO 的過程如下:首先,將整個(gè)圖像分成S × S 的小格子(cell),對于每個(gè)格子,分別預(yù)測B 個(gè)bbox,以及C 個(gè)類別的條件概率(注意是條件概率,即已經(jīng)確定有目標(biāo)的情況下,該目標(biāo)屬于哪個(gè)類別的概率,因此不需要對每個(gè)bbox 分別預(yù)測類別,每個(gè)格子只預(yù)測一個(gè)概率向量即可)。每個(gè)bbox 都有5 個(gè)變量,分別是四個(gè)描述位置坐標(biāo)的值,以及一個(gè)objectness,即是否有目標(biāo)(相當(dāng)于RPN 網(wǎng)絡(luò)里的那個(gè)前景/背景預(yù)測)。這樣一來,每個(gè)格子需要輸出5B+C 維度的向量,因此,CNN 最終的輸出的tensor 的形態(tài)為S × S × (5B + C)。
在YOLO v1 的實(shí)現(xiàn)中,采用了7*7 的cell 劃分,每個(gè)cell 預(yù)測2 個(gè)bbox,在Pascal VOC 數(shù)據(jù)集上,共有20 類,因此C=20。所以輸出的結(jié)果是一個(gè)7 × 7 × 30 的tensor。
YOLO 的訓(xùn)練過程如下:首先,對于每個(gè)GT bbox,找到它的中心位置,該中心位置所在的cell 負(fù)責(zé)該物體的預(yù)測。因此,對于該cell 中的輸出,其objectness 應(yīng)該盡可能的增加,同時(shí)其位置坐標(biāo)盡可能擬合GTbbox(注意,由于每個(gè)cell 可以輸出多個(gè)備選的bbox,因此這里需要選擇和GT 最相近的那個(gè)預(yù)測的bbox 進(jìn)行調(diào)優(yōu))。另外,根據(jù)其實(shí)際的類別,對類別概率向量進(jìn)行優(yōu)化,使其輸出真實(shí)的類別。對于不負(fù)責(zé)任何類別的那些cell 的預(yù)測值,不必進(jìn)行優(yōu)化。
YOLO 的損失函數(shù)如下:
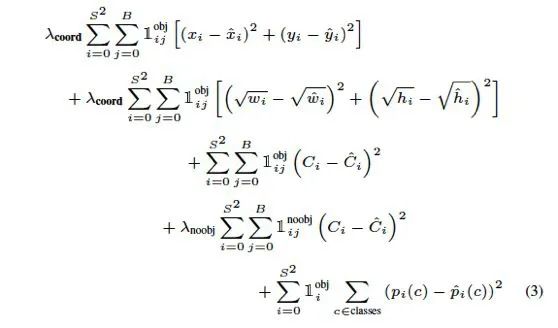
圖1.7: YOLO 損失函數(shù)
YOLO 模型雖然速度快,但是對于小物體檢測不敏感,以及具有一些固有的缺陷,如定位準(zhǔn)確性差等等。在YOLO v1 的訓(xùn)練過程中,還用到了dropout 和一些數(shù)據(jù)增廣的策略方法。這個(gè)是YOLO 的初版,后續(xù)還有很多改進(jìn)版本。
SSD
SSD 的全稱是Single Shot MultiBox Detector。SSD 也是一種one-stage 的直接檢測的模型。它相比起YOLO v1 主要的改進(jìn)點(diǎn)在于兩個(gè)方面:1. 利用了先驗(yàn)框(Prior Box)的方法,預(yù)先給定scale 和aspect ratio,實(shí)際上就是之前Faster R-CNN 中的anchor box 的概念。2. 多尺度(multi-scale)預(yù)測,即對CNN 輸出的后面的多個(gè)不同尺度的feature map 都進(jìn)行預(yù)測。下圖是SSD 論文作者給出的SSD 與YOLO 的結(jié)構(gòu)的比較:
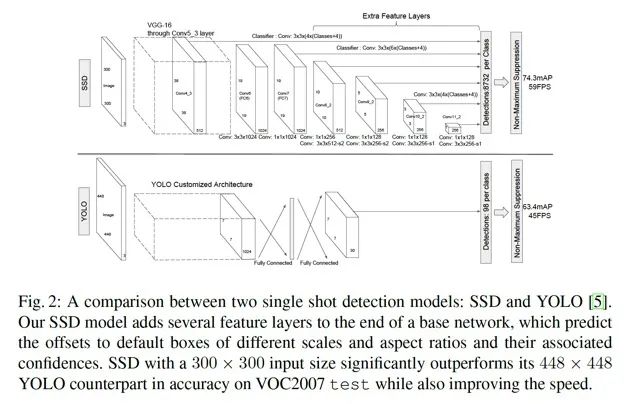
圖1.8: SSD 的結(jié)構(gòu)及其與YOLO 的區(qū)別
可以看出,相比于YOLO,SSD 在不同尺度上進(jìn)行預(yù)測,這個(gè)過程的具體操作如下:首先,根據(jù)不同feature map 的尺寸,或者說縮放比例,找到每個(gè)feature map 和原圖的尺寸的對應(yīng)關(guān)系。然后,設(shè)計(jì)不同比例的先驗(yàn)框。對于每個(gè)GT bbox,分別在不同尺度下考察各個(gè)點(diǎn)上的各個(gè)比例的先驗(yàn)框,找到最相似的,用來負(fù)責(zé)預(yù)測。
如下圖中,狗的尺寸較大,因此用到了更靠后的feature map(越靠后所代表的原圖中的比例越大),而貓的尺寸較小,用的是前面的feature map。同時(shí),還要適配各自的長寬比。
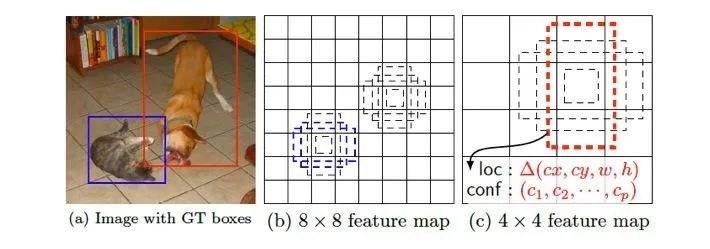
圖1.9: SSD 的多尺度先驗(yàn)框預(yù)測
通過上面的改進(jìn),SSD 提高了速度,同時(shí)也提升了準(zhǔn)確率,另外還對于低分辨率圖像也能有較好的預(yù)測結(jié)果。
YOLO v2
YOLO v2 是對YOLO v1 的改進(jìn)版本。論文中叫做YOLO9000,因?yàn)樗梢宰R別9000+ 的類別的物體。
YOLO v2 的主要改進(jìn)為以下幾個(gè)方面:
對所有卷積層增加了BN(BatchNorm)層。 用高分辨率的圖片fine-tune 網(wǎng)絡(luò)10 個(gè)epoch。 通過k-means 進(jìn)行聚類,得到k 個(gè)手工選擇的先驗(yàn)框(Prior anchor box)。這里的聚類用到的距離函數(shù)為1 - IoU,這個(gè)距離函數(shù)可以很直接地反映出IoU 的情況。 直接預(yù)測位置坐標(biāo)。之前的坐標(biāo)回歸實(shí)際上回歸的不是坐標(biāo)點(diǎn),而是需要對預(yù)測結(jié)果做一個(gè)變換才能得到坐標(biāo)點(diǎn),即x = tx × wa ? xa (縱坐標(biāo)同理),其中tx 為預(yù)測的直接結(jié)果。從該變換的形式可以看出,對于坐標(biāo)點(diǎn)的預(yù)測不僅和直接預(yù)測位置結(jié)果相關(guān),還和預(yù)測的寬和高也相關(guān)。因此,這樣的預(yù)測方式可以使得任何anchor box 可以出現(xiàn)在圖像中的任意位置,導(dǎo)致模型可能不穩(wěn)定。在YOLO v2 中,中心點(diǎn)預(yù)測結(jié)果為相對于該cell 的角點(diǎn)的坐標(biāo)(0-1 之間),如下: 多尺度訓(xùn)練(隨機(jī)選擇一個(gè)縮放尺度)、跳連層(paththrough layer)將前面的fine-grained 特征直接拼接到后面的feature map 中。
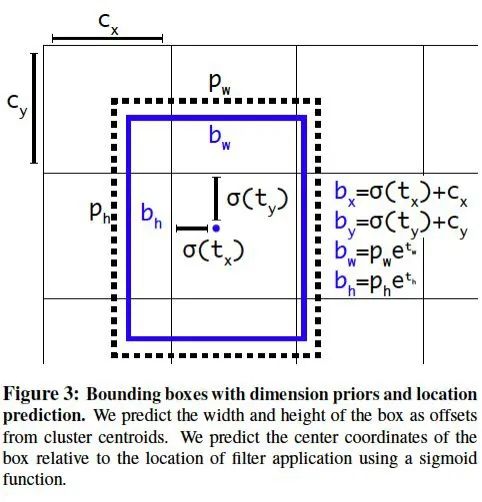
圖1.10: YOLO v2 預(yù)測bbox 的坐標(biāo)
YOLO v2 的backbone 被稱為Darknet-19,共有19 個(gè)卷積層,間以Maxpool。其中,3*3 conv filter 和1*1 conv filter 交替的方式被采用。最后利用一個(gè)Avgpool(GAP,Global Average Pooling)輸出預(yù)測結(jié)果。
除了上述對于模型結(jié)構(gòu)以及訓(xùn)練過程的改進(jìn),YOLO9000 的另一個(gè)亮點(diǎn)在于它利用了標(biāo)簽的層級結(jié)構(gòu)(Hierarchy)。由于ImageNet 的label 來自于WordNet,作者將WordNet 轉(zhuǎn)化為了WordTree,預(yù)測的時(shí)候?qū)嶋H上預(yù)測的是條件概率,即如果屬于父節(jié)點(diǎn)的概念(標(biāo)簽),那么他屬于子節(jié)點(diǎn)的概率為多大。所以,對于某個(gè)葉子節(jié)點(diǎn)的類別,他的實(shí)際的預(yù)測概率是整個(gè)路徑的預(yù)測值的乘積。
由于每個(gè)條件概率在對應(yīng)的節(jié)點(diǎn)上應(yīng)該歸一(sum to one),所以,softmax 應(yīng)該對該節(jié)點(diǎn)的所有類別進(jìn)行,而非全部類別做softmax。這是利用WordTree 做標(biāo)簽訓(xùn)練的一個(gè)注意點(diǎn)。
FPN
FPN 全稱Feature Pyramid Network,其主要思路是通過特征層面(即feature map)的轉(zhuǎn)換,生成語義和低層信息都很豐富的特征金字塔,用于預(yù)測。
如圖所示,(a) 表示的是圖像金字塔(image pyramid),即對圖像進(jìn)行放縮,不同的尺度分別進(jìn)行預(yù)測。這種方法在目標(biāo)檢測里較為常用,但是速度較慢,因?yàn)槊看涡枰獙Σ煌叨鹊膱D像分別過一次CNN 進(jìn)行訓(xùn)練。(b)表示的是單一feature map 的預(yù)測。由于圖像金字塔速度太慢,索性直接只采用最后一層輸出進(jìn)行預(yù)測,但這樣做同時(shí)也丟失了很多信息。(c) 表示的是各個(gè)scale 的feature map 分別進(jìn)行預(yù)測,但是各個(gè)層次之間(不同scale)沒有交互。SSD 模型中就是采用了這種策略,將不同尺度的bbox 分配到代表不同scale 的feature map上。(d) 即為這里要將的FPN 網(wǎng)絡(luò),即特征金字塔。這種方式通過將所有scale 的feature map 進(jìn)行打通和結(jié)合,兼顧了速度和準(zhǔn)確率。
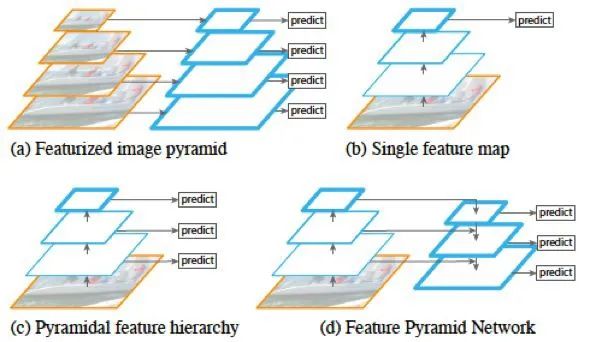
圖1.11: 圖像、特征金字塔的處理方式對比
FPN 在每兩層之間為一個(gè)buiding block,結(jié)構(gòu)如下:
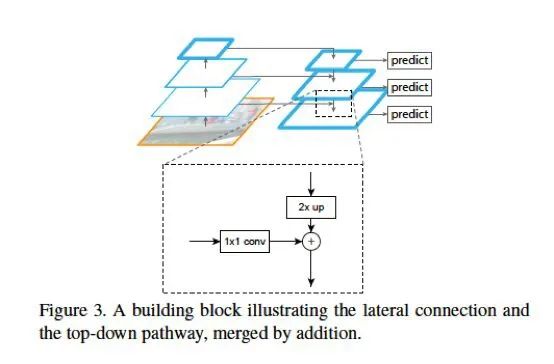
圖1.12: FPN 特征金字塔結(jié)構(gòu)
FPN 的block 結(jié)構(gòu)分為兩個(gè)部分,一個(gè)自頂向下通路(top-down pathway),另一個(gè)是側(cè)邊通路(lateral pathway)。所謂自頂向下通路,具體指的是上一個(gè)小尺寸的feature map(語義更高層)做2 倍上采樣,并連接到下一層。而側(cè)邊通路則指的是下面的feature map(高分辨率低語義)先利用一個(gè)1x1 的卷積核進(jìn)行通道壓縮,然后和上面下來的采樣后結(jié)果進(jìn)行合并。合并方式為逐元素相加(element-wise addition)。合并之后的結(jié)果在通過一個(gè)3x3 的卷積核進(jìn)行處理,得到該scale 下的feature map。
RetinaNet
RetinaNet 的最大的貢獻(xiàn)不在于網(wǎng)絡(luò)結(jié)構(gòu),而是在于提出了一個(gè)one-stage 檢測的重要的問題,及其對應(yīng)的解決方案。這個(gè)問題就是one-stage 為何比two-stage 的準(zhǔn)確率低,兩者的區(qū)別在哪里?解決方案就是平衡正負(fù)樣本+ 平衡難易樣本的focal loss。下面詳細(xì)介紹。
首先,RetinaNet 的作者發(fā)現(xiàn),two-stage 和one-stage 的目標(biāo)檢測方法的一個(gè)很大的區(qū)別在于:two-stage的方法通過SS 或者RPN 給出了一些預(yù)先選好的先驗(yàn)框,這個(gè)數(shù)量一般是1 2k 左右,從而保證正負(fù)樣本的比例大概在1:3 左右。而在one-stage 方法中,這個(gè)過程被省略了,導(dǎo)致負(fù)樣本比例大約為100k 的量級。這樣懸殊的正負(fù)樣本比例,使得在訓(xùn)練one-stage 模型的過程中,那些容易區(qū)分的負(fù)樣本占據(jù)了主導(dǎo)地位,而難分的正樣本(我們更關(guān)注的)則不太容易得到較好地訓(xùn)練。
基于這個(gè)發(fā)現(xiàn),作者設(shè)計(jì)了一種新的損失函數(shù)的形式,以取代普通的分類問題中的交叉熵?fù)p失。Focal loss 的數(shù)學(xué)形式如下:
FocalLoss(pt) = ?αt(1 ? pt) ^γ log(pt)
其中,αt 表示正負(fù)樣本的權(quán)重系數(shù),這個(gè)在處理正負(fù)樣本不均衡的情況下是常用的方法。
pt 當(dāng)實(shí)際label 為1 時(shí),取值為p(即輸出的正樣本預(yù)測概率),當(dāng)實(shí)際label 為0 時(shí),取值為1-p(實(shí)際上表示負(fù)樣本的概率)。可以看出,pt 表示的是預(yù)測出的真實(shí)值的概率。因此,(1 ? pt) 表示的就是預(yù)測結(jié)果距離真實(shí)結(jié)果的差距。比如,本來應(yīng)該是正樣本,預(yù)測應(yīng)該為1,此時(shí)如果p=0.8,那么說明還有0.2 的差距。類似地,對于負(fù)樣本,應(yīng)該預(yù)測為0,如果此時(shí)p=0.3,則差距為0.3。
這個(gè)差距實(shí)際上度量的就是該樣本可分性的難易程度。差距越大,說明該樣本越難分。于是,我們將該差距作為系數(shù)(進(jìn)行了冪次處理后),和前面的正負(fù)樣本權(quán)重系數(shù)一起,組成新的權(quán)重。這樣一來,這個(gè)損失函數(shù)一方面調(diào)整了正/負(fù)樣本之間的不均衡,還兼顧了難/易樣本之間的不均衡。
指數(shù)參數(shù)γ 叫做聚焦參數(shù)(focusing parameter),它控制著難易樣本權(quán)重的差別程度。比如,當(dāng)γ = 2 時(shí),預(yù)測結(jié)果為0.9 的正樣本的系數(shù)僅為0.01,而預(yù)測結(jié)果為0.6 的正樣本的系數(shù)為0.16。相差16 倍。如果指數(shù)為1,那么差距僅為4 倍。
RetinaNet 的網(wǎng)絡(luò)結(jié)構(gòu)沿用了FPN 的基本構(gòu)件,并且設(shè)計(jì)了分類子網(wǎng)絡(luò)和回歸自網(wǎng)絡(luò),分別進(jìn)行類別預(yù)測和bbox 回歸。如圖:
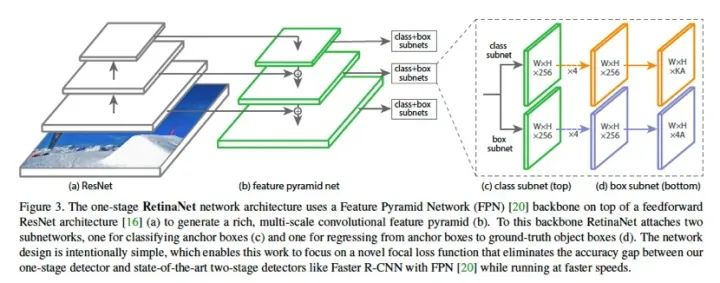
圖1.13: RetinaNet 網(wǎng)絡(luò)結(jié)構(gòu)
Mask R-CNN
Mask R-CNN 顧名思義,是為每個(gè)目標(biāo)物體生成一個(gè)mask。本模型將實(shí)例分割(instance segmentation)與目標(biāo)檢測(object detection)兩個(gè)任務(wù)相結(jié)合,并在兩個(gè)任務(wù)上都達(dá)到了SOTA。
Mask R-CNN 的基本結(jié)構(gòu)如下:
整個(gè)過程的pipeline 如下:首先,輸入圖片,根據(jù)RoI 進(jìn)行RoIAlign 操作,得到該區(qū)域內(nèi)的特征,然后將該特征feature map 進(jìn)行逐點(diǎn)sigmoid(pixel-wise sigmoid),用于產(chǎn)生mask。另外,還有一個(gè)支路用于分類和回歸。
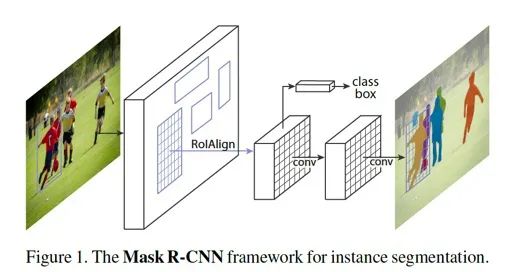
圖1.14: Mask R-CNN 網(wǎng)絡(luò)結(jié)構(gòu)
Mask R-CNN 中的分類和mask 生成之間是解耦的。這種方式和常見的直接對所有類別做逐像素的softmax不同。
下面介紹ROIAlign。ROIAlign 的基本出發(fā)點(diǎn)是在ROI pooling 中的兩次量化(quantization)。第一次是從原圖的bbox 映射到feature map 的時(shí)候,由于尺寸不一致,需要縮放,并對準(zhǔn)像素點(diǎn)(取整),此為第一次量化。第二次是根據(jù)fixed length 特征向量,計(jì)算pooling 的步長的過程中,由于可能會除不盡,從而需要再一次地取整。這兩次量化使得最終的結(jié)果與原圖差異較大,位置不準(zhǔn)。因此,提出RoIAlign 進(jìn)行改進(jìn)。
ROIAlign 的基本過程如下:如圖,首先對一個(gè)不定尺寸的ROI 進(jìn)行切分,完全平均分為四塊,此時(shí)可能分割點(diǎn)不是整數(shù)(沒有落在某個(gè)像素上),然后,在每個(gè)小塊內(nèi)平均地取四個(gè)點(diǎn),這四個(gè)點(diǎn)也不需要是整數(shù)。取出這四個(gè)點(diǎn)的值,對于不落在實(shí)際像素點(diǎn)上的點(diǎn)的情況,通過插值方法根據(jù)四周像素點(diǎn)的值進(jìn)行計(jì)算。計(jì)算完畢后,每個(gè)塊內(nèi)取其四個(gè)值的max,類似max pool,得到每個(gè)塊的輸出值。這樣即可得到一個(gè)2x2 的輸出結(jié)果。
Mask R-CNN 的損失函數(shù)由三個(gè)部分構(gòu)成,分別是cls、reg 和mask。
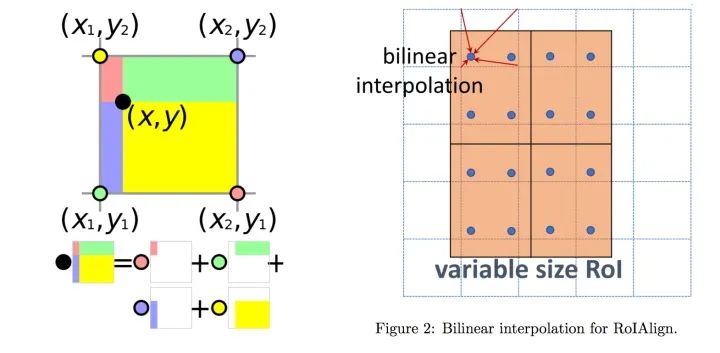
圖1.15: ROIAlign 原理(https://tjmachinelearning.com/lectures/1718/instance/instance.pdf)
YOLO v3
YOLO v3 是針對YOLO 模型的又一次改進(jìn)版本,如作者自稱,是一個(gè)incremental improvement,并無太大創(chuàng)新,基本都是一些調(diào)優(yōu)和trick。主要包括以下幾個(gè)方面。
1. 用單類別的binary logistic 作為分類方式,代替全類別的softmax(和mask R-CNN 的mask 生成方式類似)。這樣的好處在于可以處理有些數(shù)據(jù)集中有目標(biāo)重疊的情況。
2. YOLO v3 采用了FPN 網(wǎng)絡(luò)做預(yù)測,并且沿用了k-means 聚類選擇先驗(yàn)框,v3 中選擇了9 個(gè)prior box,并選擇了三個(gè)尺度。
3. backbone 做了改進(jìn),從darknet-19 變成了darknet-53,darknet-53 除了3x3 和1x1 的交替以外,還加入了residual 方法,因此層數(shù)得到擴(kuò)展。
目標(biāo)檢測模型改進(jìn)思路總結(jié)
最早的目標(biāo)檢測方法實(shí)際上就是圖像分類方法,只是以ROI 中的區(qū)域代替整圖進(jìn)行,如R-CNN,過程為:選區(qū)域-CNN 提取特征-SVM 分類。然后,考慮到重復(fù)計(jì)算的冗余,SPP-net 提出,用空間金字塔池化,即自適應(yīng)stride 的池化,保證任意大小都能得到定長特征向量。然后是Fast R-CNN,沿用了ROI pooling 的思路,并且加入了新的改進(jìn),即多任務(wù)學(xué)習(xí),直接網(wǎng)絡(luò)端到端回歸bbox,并進(jìn)行分類,去掉了SVM。到此為止,模型已經(jīng)確定了,只是ROI 的方法還是利用Selective Search,導(dǎo)致預(yù)處理速度較慢,拖慢了整體的速度。因此,F(xiàn)aster R-CNN 引入了一個(gè)和檢測網(wǎng)絡(luò)共享部分權(quán)重的RPN 網(wǎng)絡(luò),用網(wǎng)絡(luò)進(jìn)行region proposal,從而提高了整體的效率,去掉了Selective Search。
上述的方法都是two-stage,即先給出候選框,然后在進(jìn)行分類和微調(diào)位置。于是,另一種新的思路,即直接進(jìn)行預(yù)測bbox 和類別,這就是one-stage 的方法。代表就是YOLO 模型,通過對圖像劃分成多個(gè)區(qū)塊,直接輸出一個(gè)和區(qū)塊數(shù)相同的tensor,每個(gè)區(qū)塊的預(yù)測向量里包含了其是否有目標(biāo),是什么類別,以及具體位置的修正。SSD 基于YOLO 的基本思路,考慮了多尺度的情況,將不同尺度的GT bbox 分配到不同尺度去預(yù)測,不同尺度的預(yù)測即通過不同層的feature map 進(jìn)行。后續(xù)的YOLO v2 提出了對位置的直接預(yù)測方法,以及用k-means 聚類來手工得到先驗(yàn)框的方法,并利用darknet-19 作為backbone 網(wǎng)絡(luò)。FPN 網(wǎng)絡(luò)的基本思路是將不同尺度的feature map 通過網(wǎng)絡(luò)連接的方式進(jìn)行融合,并在每一層進(jìn)行預(yù)測,從而可以利用不同尺度的信息。
RetinaNet 基本沿用了FPN 的思路,但是提出了focal loss 來處理樣本比例不均衡的問題,對數(shù)量較少的正樣本,以及難分樣本給予較多的關(guān)注。Mask R-CNN 將實(shí)例分割與目標(biāo)檢測進(jìn)行結(jié)合,融合了分類、回歸、mask三個(gè)損失進(jìn)行優(yōu)化。YOLO v3 采用了具有residual 模塊的darknet-53 作為backbone,并且用了binary logistic代替全局softmax,以及FPN 網(wǎng)絡(luò)等trick,提升了性能。
?ACCV 2020國際細(xì)粒度網(wǎng)絡(luò)圖像識別競賽正式開賽!
