【齊活】Python 正則表達(dá)式大全,必要時(shí)一定用得上哦

來(lái)源:博客園-Huny
鏈接:https://www.cnblogs.com/huny/p/14040416.html
1 前言
正則表達(dá)式是對(duì)字符串(包括普通字符(例如,a 到 z 之間的字母)和特殊字符(稱為“元字符”))操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個(gè)“規(guī)則字符串”,這個(gè)“規(guī)則字符串”用來(lái)表達(dá)對(duì)字符串的一種過(guò)濾邏輯。正則表達(dá)式是一種文本模式,該模式描述在搜索文本時(shí)要匹配的一個(gè)或多個(gè)字符串。
上面都是官方的說(shuō)明,博主自己的理解是(僅供參考):通過(guò)事先規(guī)定好一些特殊字符的匹配規(guī)則,然后利用這些字符進(jìn)行組合來(lái)匹配各種復(fù)雜的字符串場(chǎng)景。比如現(xiàn)在的爬蟲(chóng)和數(shù)據(jù)分析,字符串校驗(yàn)等等都需要用到正則表達(dá)式來(lái)處理數(shù)據(jù)。
python的正則表達(dá)式則是re模塊了:
re 模塊使 Python 語(yǔ)言擁有全部的正則表達(dá)式功能。
re 模塊也提供了與這些方法功能完全一致的函數(shù),這些函數(shù)使用一個(gè)模式字符串做為它們的第一個(gè)參數(shù)。
2 基本語(yǔ)法
2.1?match函數(shù)
只從字符串的最開(kāi)始與pattern進(jìn)行匹配,下面是函數(shù)的語(yǔ)法 :
re.match(pattern, string, flags = 0)這里是參數(shù)的描述 :
pattern - 這是要匹配的正則表達(dá)式。
string - 這是字符串,它將被搜索用于匹配字符串開(kāi)頭的模式。
flags - 可以使用按位OR(|)指定不同的標(biāo)志。這些是修飾符,如下表所列。
re.match 函數(shù)在成功時(shí)返回匹配對(duì)象,失敗時(shí)返回None。使用match(num)或groups()函數(shù)匹配對(duì)象來(lái)獲取匹配的表達(dá)式。

示例
#未從初始位置匹配,會(huì)返回None
import re
line = 'i can speak good english'
matchObj = re.match(r'\s(\w*)\s(\w*).*',line)
if matchObj:
print('matchObj.group() :',matchObj.group())
print('matchObj.group() :',matchObj.group(1))
print('matchObj.group() :',matchObj.group(2))
print('matchObj.group() :',matchObj.group(3))
else:
print('no match!')
#從初始位置開(kāi)始匹配
import re
line = 'i can speak good english'
matchObj = re.match(r'(i)\s(\w*)\s(\w*).*',line)
if matchObj:
print('matchObj.group() :',matchObj.group())
print('matchObj.group() :',matchObj.group(1))
print('matchObj.group() :',matchObj.group(2))
print('matchObj.group() :',matchObj.group(3))
else:
print('no match!')
2.2 search 函數(shù)
與match()工作的方式一樣,但是search()不是從最開(kāi)始匹配的,而是從任意位置查找第一次匹配的內(nèi)容。下面是這個(gè)函數(shù)的語(yǔ)法?:
re.search(pattern, string, flags = 0)這里是參數(shù)的描述 :
pattern - 這是要匹配的正則表達(dá)式。
string - 這是字符串,它將被搜索用于匹配字符串開(kāi)頭的模式。
flags - 可以使用按位OR(|)指定不同的標(biāo)志。這些是修飾符,如下表所列。
re.search函數(shù)在成功時(shí)返回匹配對(duì)象,否則返回None。使用match對(duì)象的group(num)或groups()函數(shù)來(lái)獲取匹配的表達(dá)式。

示例
import re
line = 'i can speak good english'
matchObj = re.search('(.*) (.*?) (.*)',line)
if matchObj:
print('matchObj.group() :',matchObj.group())
print('matchObj.group() :',matchObj.group(1))
print('matchObj.group() :',matchObj.group(2))
print('matchObj.group() :',matchObj.group(3))
else:
print('no match!')2.3 sub?函數(shù)
使用正則表達(dá)式re模塊中的最重要的之一是sub。
re.sub(pattern, repl, string, max=0)此方法使用repl替換所有出現(xiàn)在RE模式的字符串,替換所有出現(xiàn),除非提供max。此方法返回修改的字符串。
示例
import re
line = 'i can speak good english'
speak = re.sub(r'can','not',line)
print(speak)
speak1 = re.sub(r'\s','',line) #替換所有空格
print(speak1)3 特殊類語(yǔ)法
3.1 字符類
3.2 特殊字符類
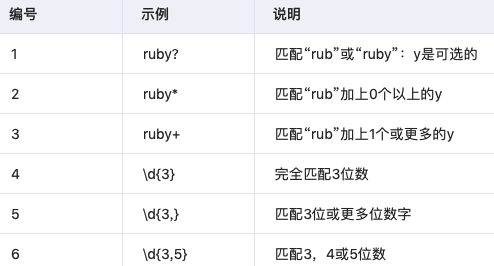
3.3 重復(fù)匹配
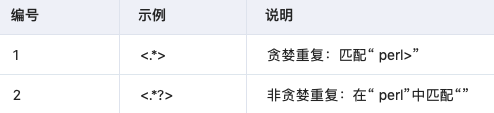
3.4 非貪婪重復(fù)
這匹配最小的重復(fù)次數(shù):
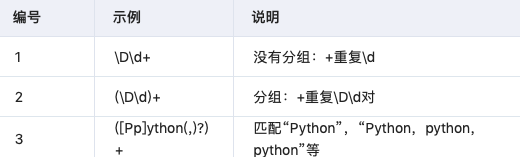
3.5?圓括號(hào)分組
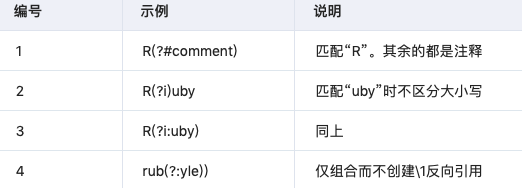
3.6 反向引用
與以前匹配的組再次匹配?

3.7?錨點(diǎn)
需要指定匹配位置。
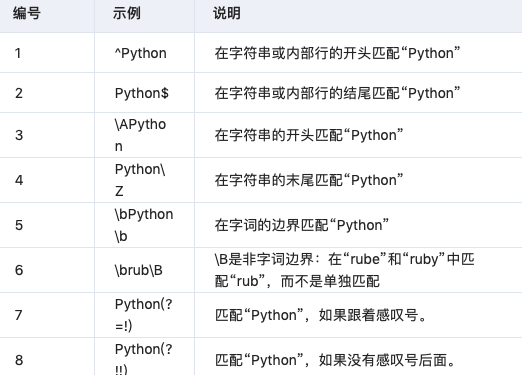
3.8 帶括號(hào)的特殊語(yǔ)法