
Python 那些永遠用不到的對象,我們稱之為「垃圾」
我們知道使用 Python 可以創(chuàng)建對象,當我們去引用它的時候,系統會開辟一個內存空間存放對象,不過可能有些對象我們用完之后,永遠再也不會去使用了,那這對象不能一直留在內存里邊吧,對象已經廢了,也就成為了「垃圾」,垃圾要清理掉,內存才能騰出位置給別的程序使用。
那么:
Python是怎么回收垃圾的?
先來了解一下「引用次數」,在 Python 的內置模塊 sys 有一個 getrefcount 方法,通過它我們可以得到對象被引用的次數:

比如我們定義這樣一個「s」:

這里得到的結果為 2 次引用,其中一次是 s,一次是 getrefcount。
接下來我們看看這樣的代碼:
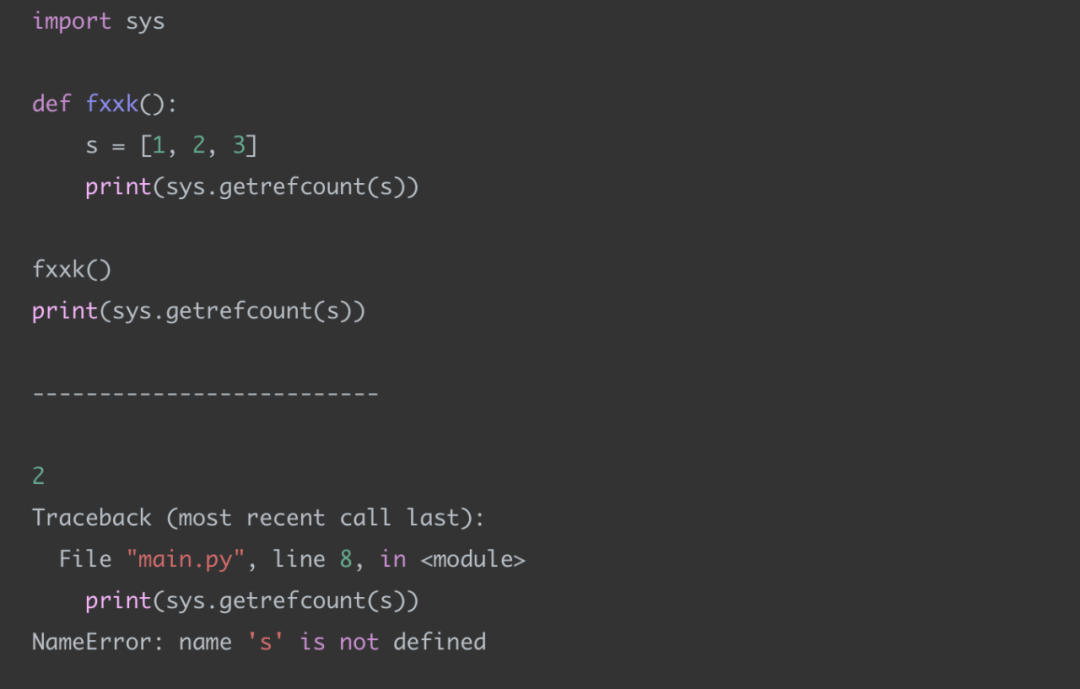
當我們執(zhí)行完 fxxk 方法之后,在它下面的 print 調用會報錯,也就是說我們無法再去引用對象 s 了,因為它已經被回收。
當執(zhí)行完 fxxk() 之后,對象 s 的引用數量為 0,而在 Python 的垃圾回收算法中,一個主要的點就是,當對象的引用數量為 0,說明這個對象已經成為「垃圾」了,Python 會將這個對象回收掉,從而釋放資源。
通過統計引用次數來釋放資源,是相對高效可行的,不過也有存在這樣的現象:對象之間相互循環(huán)引用,會導致引用數量為一直不為 0,那么這樣的垃圾是回收不了的,這就可能會造成內存泄漏。
所以在 Python 新版本中,補充了垃圾回收機制算法——標記清除法和分代收集。
所謂標記清除,就是遍歷所有對象,通過鏈表逐個對象追蹤標記到的這些對象是可達的,那么剩下那些對象就是不可達的,說明它們是垃圾,回收掉,這樣就可以避免對象循環(huán)引用而沒辦法回收的問題了。
因為每次標記清除的時候,肯定是占用系統資源的,這時候就有人想到,是不是可以分代收集,也就是說,分成三代,把第一次遍歷的對象視為第 0 代,那么第一次遍歷完活下來的對象,就把它們放入第二代,第二代就不會被那么「嚴格」的去掃描,如果第二次遍歷,第二代的對象又存活,那么就放入第三代,在第三代里面的對象就更「安全」了。
因為對象活得越久,說明它越不是「垃圾」。
以上,我們說的 Python 垃圾回收機制,都是自動的,不用我們親自來清理垃圾。
那如果我們想自己手動來回收垃圾,可不可以實現呢?
答案是肯定的。
Python手動回收垃圾
我們可以通過 del 命令來刪除對象的引用,然后使用 Python 的 gc 模塊,調用 collect 方法就可以實現。
現在來寫個例子給你參考一下:
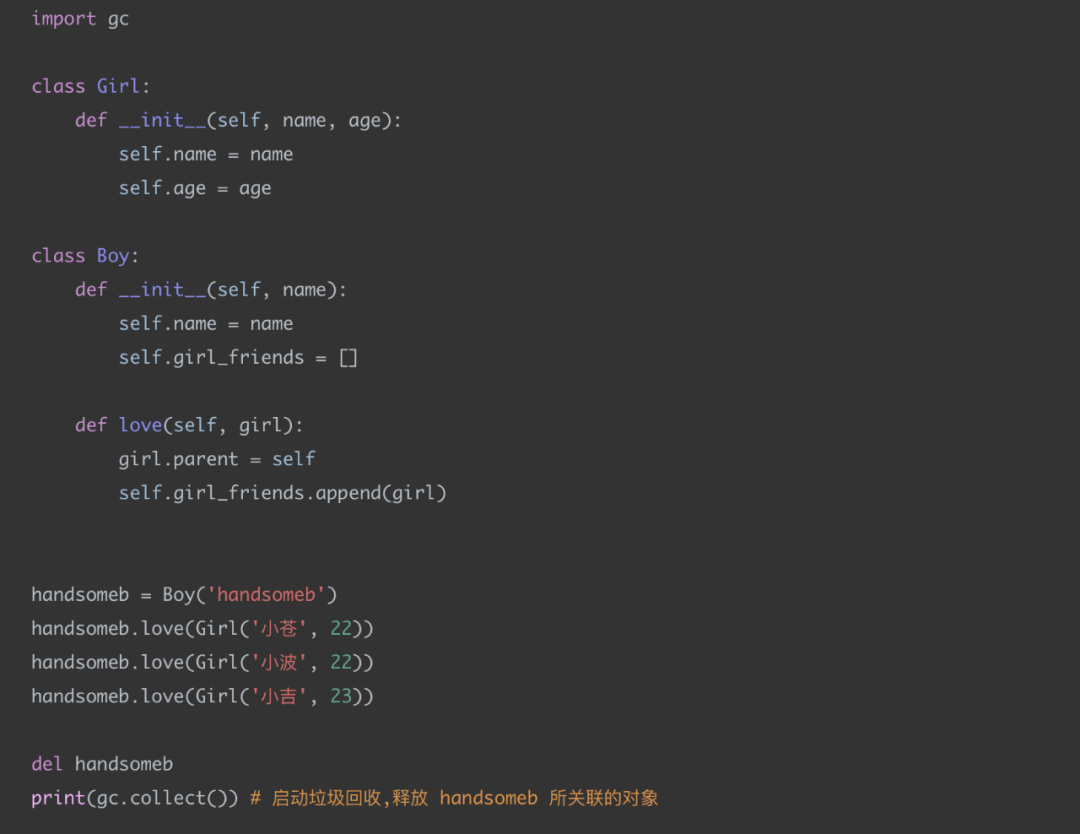
代碼很簡單,這里我們創(chuàng)建了 handsomeb 對象,見一個女生愛一個。。。
主要的是最后兩行代碼,當我們使用 del handsomeb 的時候,實際上就是將 handsomb 這個對象給刪除釋放掉,不過這個時候還存在那些和 handsomeb 的關聯對象 Girl 們,她們已經沒有什么用了,我們可以使用 gc.collect(),將和 handsomeb 關聯的對象們都給釋放掉,這樣就實現了手動回收垃圾。
你還可以到這里了解更多相關內容:
https://docs.python.org/zh-cn/3.8/library/gc.html
ok,以上就是小帥b今天給你帶來的分享,關于 Python 的垃圾回收問題,面試也常常會被問到,希望對你有幫助。
ps:本文為小帥b的VIP私密文章,更多了解可以進去:跟小帥b一起通往「Python高手之路」。
對了,我最近開了個小號,接下來會在這里發(fā)表一些我的觀點、想法等內容,你可以點進去關注一下,在這里可以跟我留言互動,想說一點的是,噴我的,夸我的留言我都會放出來,我不會只放出「好看」的評論,每個人有各自的觀點很正常,我可以接受,但對傻逼可能態(tài)度比較不好,雖然有點真實,但不要怕,我只是對事不對人。
想支持小帥b原創(chuàng)的朋友們,點贊點在看或者轉發(fā)一波就好了,那么我們下回見,peace!