
支付寶架構(gòu)真牛逼
2010 年雙 11 的支付峰值為 2 萬筆/分鐘,到 2017 年雙 11 時這個數(shù)字變?yōu)榱?25.6 萬筆/秒。
2018 年雙 11 的支付峰值為 48 萬筆/秒,2019 年雙 11 支付峰值為 54.4 萬筆/秒,創(chuàng)下新紀(jì)錄,是 2009 年第一次雙 11 的 1360?倍。
在如此之大的支付 TPS 背后除了削峰等錦上添花的應(yīng)用級優(yōu)化,最解渴最實質(zhì)的招數(shù)當(dāng)數(shù)基于分庫分表的單元化了,螞蟻技術(shù)稱之為 LDC(邏輯數(shù)據(jù)中心)。
本文不打算討論具體到代碼級的分析,而是嘗試用最簡單的描述來說明其中最大快人心的原理。
我想關(guān)心分布式系統(tǒng)設(shè)計的人都曾被下面這些問題所困擾過:
支付寶海量支付背后最解渴的設(shè)計是啥?換句話說,實現(xiàn)支付寶高 TPS 的最關(guān)鍵的設(shè)計是啥?
LDC 是啥?LDC 怎么實現(xiàn)異地多活和異地災(zāi)備的?
CAP 魔咒到底是啥?P 到底怎么理解?
什么是腦裂?跟 CAP 又是啥關(guān)系?
什么是 PAXOS,它解決了啥問題?
PAXOS 和 CAP 啥關(guān)系?PAXOS 可以逃脫 CAP 魔咒么?
Oceanbase 能逃脫 CAP 魔咒么?
如果你對這些感興趣,不妨看一場赤裸裸的論述,拒絕使用晦澀難懂的詞匯,直面最本質(zhì)的邏輯。
LDC?和單元化
這句話暗含的是強大的體系設(shè)計,分布式系統(tǒng)的挑戰(zhàn)就在于整體協(xié)同工作(可用性,分區(qū)容忍性)和統(tǒng)一(一致性)。
單元化是大型互聯(lián)網(wǎng)系統(tǒng)的必然選擇趨勢,舉個最最通俗的例子來說明單元化。
我們總是說 TPS 很難提升,確實任何一家互聯(lián)網(wǎng)公司(比如淘寶、攜程、新浪)它的交易 TPS 頂多以十萬計量(平均水平),很難往上串了。
因為數(shù)據(jù)庫存儲層瓶頸的存在再多水平擴展的服務(wù)器都無法繞開,而從整個互聯(lián)網(wǎng)的視角看,全世界電商的交易 TPS 可以輕松上億。
這個例子帶給我們一些思考:為啥幾家互聯(lián)網(wǎng)公司的 TPS 之和可以那么大,服務(wù)的用戶數(shù)規(guī)模也極為嚇人,而單個互聯(lián)網(wǎng)公司的 TPS 卻很難提升?
究其本質(zhì),每家互聯(lián)網(wǎng)公司都是一個獨立的大型單元,他們各自服務(wù)自己的用戶互不干擾。
這就是單元化的基本特性,任何一家互聯(lián)網(wǎng)公司,其想要成倍的擴大自己系統(tǒng)的服務(wù)能力,都必然會走向單元化之路。
它的本質(zhì)是分治,我們把廣大的用戶分為若干部分,同時把系統(tǒng)復(fù)制多份,每一份都獨立部署,每一份系統(tǒng)都服務(wù)特定的一群用戶。
以淘寶舉例,這樣之后,就會有很多個淘寶系統(tǒng)分別為不同的用戶服務(wù),每個淘寶系統(tǒng)都做到十萬 TPS 的話,N 個這樣的系統(tǒng)就可以輕松做到 N*十萬的 TPS 了。
LDC 實現(xiàn)的關(guān)鍵就在于單元化系統(tǒng)架構(gòu)設(shè)計,所以在螞蟻內(nèi)部,LDC 和單元化是不分家的,這也是很多同學(xué)比較困擾的地方,看似沒啥關(guān)系,實則是單元化體系設(shè)計成就了 LDC。
小結(jié):分庫分表解決的最大痛點是數(shù)據(jù)庫單點瓶頸,這個瓶頸的產(chǎn)生是由現(xiàn)代二進制數(shù)據(jù)存儲體系決定的(即 I/O 速度)。
單元化只是分庫分表后系統(tǒng)部署的一種方式,這種部署模式在災(zāi)備方面也發(fā)揮了極大的優(yōu)勢。
系統(tǒng)架構(gòu)演化史
幾乎任何規(guī)模的互聯(lián)網(wǎng)公司,都有自己的系統(tǒng)架構(gòu)迭代和更新,大致的演化路徑都大同小異。
最早一般為了業(yè)務(wù)快速上線,所有功能都會放到一個應(yīng)用里,系統(tǒng)架構(gòu)如下圖所示:
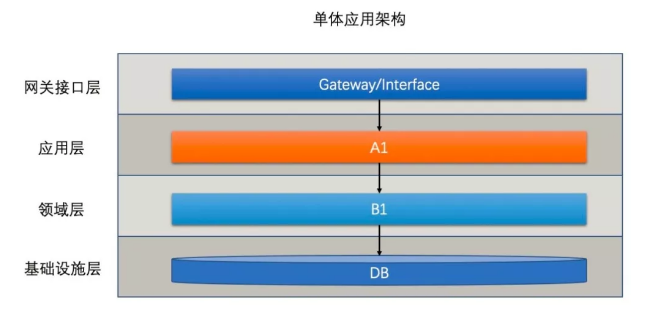
這樣的架構(gòu)顯然是有問題的,單機有著明顯的單點效應(yīng),單機的容量和性能都是很局限的,而使用中小型機會帶來大量的浪費。
隨著業(yè)務(wù)發(fā)展,這個矛盾逐漸轉(zhuǎn)變?yōu)橹饕埽虼斯こ處焸儾捎昧艘韵录軜?gòu):
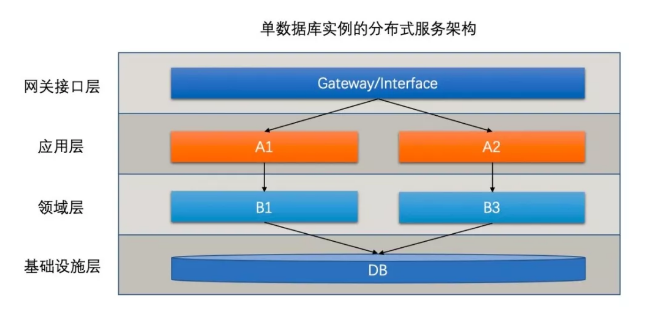
這是整個公司第一次觸碰到分布式,也就是對某個應(yīng)用進行了水平擴容,它將多個微機的計算能力團結(jié)了起來,可以完勝同等價格的中小型機器。
慢慢的,大家發(fā)現(xiàn),應(yīng)用服務(wù)器 CPU 都很正常了,但是還是有很多慢請求,究其原因,是因為單點數(shù)據(jù)庫帶來了性能瓶頸。
于是程序員們決定使用主從結(jié)構(gòu)的數(shù)據(jù)庫集群,如下圖所示:

其中大部分讀操作可以直接訪問從庫,從而減輕主庫的壓力。然而這種方式還是無法解決寫瓶頸,寫依舊需要主庫來處理,當(dāng)業(yè)務(wù)量量級再次增高時,寫已經(jīng)變成刻不容緩的待處理瓶頸。
這時候,分庫分表方案出現(xiàn)了:
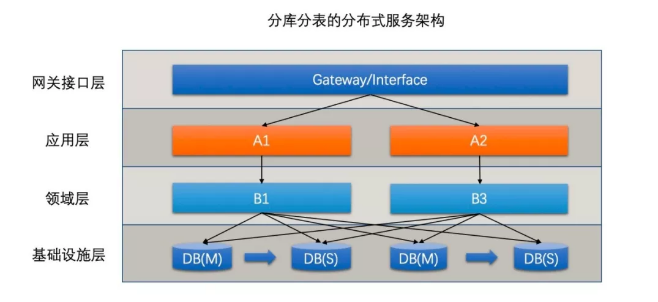
分庫分表不僅可以對相同的庫進行拆分,還可以對相同的表進行拆分,對表進行拆分的方式叫做水平拆分。
不同功能的表放到不同的庫里,一般對應(yīng)的是垂直拆分(按照業(yè)務(wù)功能進行拆分),此時一般還對應(yīng)了微服務(wù)化。
這種方法做到極致基本能支撐 TPS 在萬級甚至更高的訪問量了。然而隨著相同應(yīng)用擴展的越多,每個數(shù)據(jù)庫的鏈接數(shù)也巨量增長,這讓數(shù)據(jù)庫本身的資源成為了瓶頸。
這個問題產(chǎn)生的本質(zhì)是全量數(shù)據(jù)無差別的分享了所有的應(yīng)用資源,比如 A 用戶的請求在負(fù)載均衡的分配下可能分配到任意一個應(yīng)用服務(wù)器上,因而所有應(yīng)用全部都要鏈接 A 用戶所在的分庫,數(shù)據(jù)庫連接數(shù)就變成笛卡爾乘積了。
在本質(zhì)點說,這種模式的資源隔離性還不夠徹底。要解決這個問題,就需要把識別用戶分庫的邏輯往上層移動,從數(shù)據(jù)庫層移動到路由網(wǎng)關(guān)層。
這樣一來,從應(yīng)用服務(wù)器 a 進來的來自 A 客戶的所有請求必然落庫到 DB-A,因此 a 也不用鏈接其他的數(shù)據(jù)庫實例了,這樣一個單元化的雛形就誕生了。
思考一下,應(yīng)用間其實也存在交互(比如 A 轉(zhuǎn)賬給 B),也就意味著,應(yīng)用不需要鏈接其他的數(shù)據(jù)庫了,但是還需要鏈接其他應(yīng)用。
如果是常見的 RPC 框架如 Dubbo 等,使用的是 TCP/IP 協(xié)議,那么等同于把之前與數(shù)據(jù)庫建立的鏈接,換成與其他應(yīng)用之間的鏈接了。
為啥這樣就消除瓶頸了呢?首先由于合理的設(shè)計,應(yīng)用間的數(shù)據(jù)交互并不巨量,其次應(yīng)用間的交互可以共享 TCP 鏈接,比如 A->B 之間的 Socket 鏈接可以被 A 中的多個線程復(fù)用。
而一般的數(shù)據(jù)庫如 MySQL 則不行,所以 MySQL 才需要數(shù)據(jù)庫鏈接池。
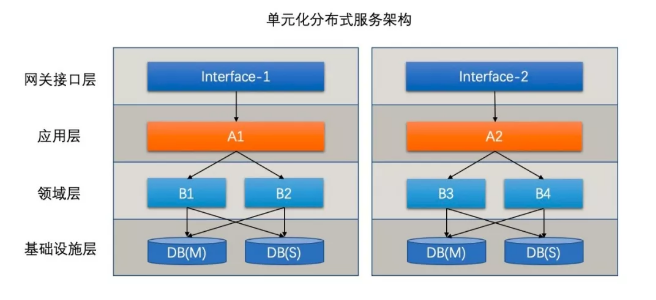
如上圖所示,但我們把整套系統(tǒng)打包為單元化時,每一類的數(shù)據(jù)從進單元開始就注定在這個單元被消化,由于這種徹底的隔離性,整個單元可以輕松的部署到任意機房而依然能保證邏輯上的統(tǒng)一。
下圖為一個三地五機房的部署方式:

螞蟻單元化架構(gòu)實踐
螞蟻支付寶應(yīng)該是國內(nèi)最大的支付工具,其在雙 11 等活動日當(dāng)日的支付 TPS 可達(dá)幾十萬級,未來這個數(shù)字可能會更大,這決定了螞蟻單元化架構(gòu)從容量要求上看必然從單機房走向多機房。
另一方面,異地災(zāi)備也決定了這些 IDC 機房必須是異地部署的。整體上支付寶也采用了三地五中心(IDC 機房)來保障系統(tǒng)的可用性。
跟上文中描述的有所不同的是,支付寶將單元分成了三類(也稱 CRG 架構(gòu)):
RZone(Region Zone):直譯可能有點反而不好理解。實際上就是所有可以分庫分表的業(yè)務(wù)系統(tǒng)整體部署的最小單元。每個 RZone 連上數(shù)據(jù)庫就可以撐起一片天空,把業(yè)務(wù)跑的溜溜的。
GZone(Global Zone):全局單元,意味著全局只有一份。部署了不可拆分的數(shù)據(jù)和服務(wù),比如系統(tǒng)配置等。
實際情況下,GZone 異地也會部署,不過僅是用于災(zāi)備,同一時刻,只有一地 GZone 進行全局服務(wù)。GZone 一般被 RZone 依賴,提供的大部分是讀取服務(wù)。
CZone(City Zone):顧名思義,這是以城市為單位部署的單元。同樣部署了不可拆分的數(shù)據(jù)和服務(wù),比如用戶賬號服務(wù),客戶信息服務(wù)等。理論上 CZone 會被 RZone 以比訪問 GZone 高很多的頻率進行訪問。
“寫讀時間差現(xiàn)象”是螞蟻架構(gòu)師們根據(jù)實踐統(tǒng)計總結(jié)的,他們發(fā)現(xiàn)大部分情況下,一個數(shù)據(jù)被寫入后,都會過足夠長的時間后才會被訪問。
生活中這種例子很常見,我們辦完銀行卡后可能很久才會存第一筆錢;我們創(chuàng)建微博賬號后,可能想半天才會發(fā)微博;我們下載創(chuàng)建淘寶賬號后,可能得瀏覽好幾分鐘才會下單買東西。
當(dāng)然了這些例子中的時間差遠(yuǎn)遠(yuǎn)超過了系統(tǒng)同步時間。一般來說異地的延時在 100ms 以內(nèi),所以只要滿足某地 CZone 寫入數(shù)據(jù)后 100ms 以后才用這個數(shù)據(jù),這樣的數(shù)據(jù)和服務(wù)就適合放到 CZone 中。
相信大家看到這都會問:為啥分這三種單元?其實其背后對應(yīng)的是不同性質(zhì)的數(shù)據(jù),而服務(wù)不過是對數(shù)據(jù)的操作集。
下面我們來根據(jù)數(shù)據(jù)性質(zhì)的不同來解釋支付寶的 CRG 架構(gòu)。當(dāng)下幾乎所有互聯(lián)網(wǎng)公司的分庫分表規(guī)則都是根據(jù)用戶 ID 來制定的。
而圍繞用戶來看整個系統(tǒng)的數(shù)據(jù)可以分為以下兩類:
用戶流水型數(shù)據(jù):典型的有用戶的訂單、用戶發(fā)的評論、用戶的行為記錄等。
這些數(shù)據(jù)都是用戶行為產(chǎn)生的流水型數(shù)據(jù),具備天然的用戶隔離性,比如 A 用戶的 App 上絕對看不到 B 用戶的訂單列表。所以此類數(shù)據(jù)非常適合分庫分表后獨立部署服務(wù)。
用戶間共享型數(shù)據(jù):這種類型的數(shù)據(jù)又分兩類。一類共享型數(shù)據(jù)是像賬號、個人博客等可能會被所有用戶請求訪問的用戶數(shù)據(jù)。
比如 A 向 B 轉(zhuǎn)賬,A 給 B 發(fā)消息,這時候需要確認(rèn) B 賬號是否存在;又比如 A 想看 B 的個人博客之類的。
另外一類是用戶無關(guān)型數(shù)據(jù),像商品、系統(tǒng)配置(匯率、優(yōu)惠政策)、財務(wù)統(tǒng)計等這些非用戶緯度的數(shù)據(jù),很難說跟具體的某一類用戶掛鉤,可能涉及到所有用戶。
比如商品,假設(shè)按商品所在地來存放商品數(shù)據(jù)(這需要雙維度分庫分表),那么上海的用戶仍然需要訪問杭州的商品。
這就又構(gòu)成跨地跨 Zone 訪問了,還是達(dá)不到單元化的理想狀態(tài),而且雙維度分庫分表會給整個 LDC 運維帶來復(fù)雜度提升。
注:網(wǎng)上和支付寶內(nèi)部有另外一些分法,比如流水型和狀態(tài)性,有時候還會分為三類:流水型、狀態(tài)型和配置型。
個人覺得這些分法雖然嘗試去更高層次的抽象數(shù)據(jù)分類,但實際上邊界很模糊,適得其反。
直觀的類比,我們可以很輕易的將上述兩類數(shù)據(jù)對應(yīng)的服務(wù)劃分為 RZone 和 GZone,RZone 包含的就是分庫分表后負(fù)責(zé)固定客戶群體的服務(wù),GZone 則包含了用戶間共享的公共數(shù)據(jù)對應(yīng)的服務(wù)。
到這里為止,一切都很完美,這也是主流的單元化話題了。對比支付寶的 CRG 架構(gòu),我們一眼就發(fā)現(xiàn)少了 C(City Zone),CZone 確實是螞蟻在單元化實踐領(lǐng)域的一個創(chuàng)新點。
再來分析下 GZone,GZone 之所以只能單地部署,是因為其數(shù)據(jù)要求被所有用戶共享,無法分庫分表,而多地部署會帶來由異地延時引起的不一致。
比如實時風(fēng)控系統(tǒng),如果多地部署,某個 RZone 直接讀取本地的話,很容易讀取到舊的風(fēng)控狀態(tài),這是很危險的。
這時螞蟻架構(gòu)師們問了自己一個問題——難道所有數(shù)據(jù)受不了延時么?這個問題像是打開了新世界的大門,通過對 RZone 已有業(yè)務(wù)的分析,架構(gòu)師們發(fā)現(xiàn) 80%?甚至更高的場景下,數(shù)據(jù)更新后都不要求立馬被讀取到。
也就是上文提到的”寫讀時間差現(xiàn)象”,那么這就好辦了,對于這類數(shù)據(jù),我們允許每個地區(qū)的 RZone 服務(wù)直接訪問本地,為了給這些 RZone 提供這些數(shù)據(jù)的本地訪問能力,螞蟻架構(gòu)師設(shè)計出了 CZone。
在 CZone 的場景下,寫請求一般從 GZone 寫入公共數(shù)據(jù)所在庫,然后同步到整個 OB 集群,然后由 CZone 提供讀取服務(wù)。比如支付寶的會員服務(wù)就是如此。
即便架構(gòu)師們設(shè)計了完美的 CRG,但即便在螞蟻的實際應(yīng)用中,各個系統(tǒng)仍然存在不合理的 CRG 分類,尤其是 CG 不分的現(xiàn)象很常見。
支付寶單元化的異地多活和災(zāi)備
流量挑撥技術(shù)探秘簡介
單元化后,異地多活只是多地部署而已。比如上海的兩個單元為 ID 范圍為 [00~19],[40~59]?的用戶服務(wù)。
而杭州的兩個單元為 ID 為 [20~39]和[60,79]的用戶服務(wù),這樣上海和杭州就是異地雙活的。
支付寶對單元化的基本要求是每個單元都具備服務(wù)所有用戶的能力,即——具體的那個單元服務(wù)哪些用戶是可以動態(tài)配置的。所以異地雙活的這些單元還充當(dāng)了彼此的備份。
發(fā)現(xiàn)工作中冷備熱備已經(jīng)被用的很亂了。最早冷備是指數(shù)據(jù)庫在備份數(shù)據(jù)時需要關(guān)閉后進行備份(也叫離線備份),防止數(shù)據(jù)備份過程中又修改了,不需要關(guān)閉即在運行過程中進行數(shù)據(jù)備份的方式叫做熱備(也叫在線備份)。
也不知道從哪一天開始,冷備在主備系統(tǒng)里代表了這臺備用機器是關(guān)閉狀態(tài)的,只有主服務(wù)器掛了之后,備服務(wù)器才會被啟動。
而相同的熱備變成了備服務(wù)器也是啟動的,只是沒有流量而已,一旦主服務(wù)器掛了之后,流量自動打到備服務(wù)器上。本文不打算用第二種理解,因為感覺有點野。
為了做到每個單元訪問哪些用戶變成可配置,支付寶要求單元化管理系統(tǒng)具備流量到單元的可配置以及單元到 DB 的可配置能力。
如下圖所示:

其中 Spanner 是螞蟻基于 Nginx 自研的反向代理網(wǎng)關(guān),也很好理解,有些請求我們希望在反向代理層就被轉(zhuǎn)發(fā)至其他 IDC 的 Spanner 而無需進入后端服務(wù),如圖箭頭 2 所示。
那么對于應(yīng)該在本 IDC 處理的請求,就直接映射到對應(yīng)的 RZ 即可,如圖箭頭 1。
進入后端服務(wù)后,理論上如果請求只是讀取用戶流水型數(shù)據(jù),那么一般不會再進行路由了。
然而,對于有些場景來說,A 用戶的一個請求可能關(guān)聯(lián)了對 B 用戶數(shù)據(jù)的訪問,比如 A 轉(zhuǎn)賬給 B,A 扣完錢后要調(diào)用賬務(wù)系統(tǒng)去增加 B 的余額。
這時候就涉及到再次的路由,同樣有兩個結(jié)果:跳轉(zhuǎn)到其他 IDC(如圖箭頭 3)或是跳轉(zhuǎn)到本 IDC 的其他 RZone(如圖箭頭 4)。
RZone 到 DB 數(shù)據(jù)分區(qū)的訪問這是事先配置好的,上圖中 RZ 和 DB 數(shù)據(jù)分區(qū)的關(guān)系為:
RZ0*?-->?a
RZ1*?-->?b
RZ2*?-->?c
RZ3*?-->?d
下面我們舉個例子來說明整個流量挑撥的過程,假設(shè) C 用戶所屬的數(shù)據(jù)分區(qū)是 c,而 C 用戶在杭州訪問了 cashier.alipay.com(隨便編的)。
①目前支付寶默認(rèn)會按照地域來路由流量,具體的實現(xiàn)承載者是自研的 GLSB(Global Server Load Balancing):
https:
它會根據(jù)請求者的 IP,自動將 cashier.alipay.com 解析為杭州 IDC 的 IP 地址(或者跳轉(zhuǎn)到 IDC 所在的域名)。
大家自己搞過網(wǎng)站的化應(yīng)該知道大部分 DNS 服務(wù)商的地址都是靠人去配置的,GLSB 屬于動態(tài)配置域名的系統(tǒng),網(wǎng)上也有比較火的類似產(chǎn)品,比如花生殼之類(建過私站的同學(xué)應(yīng)該很熟悉)的。
②好了,到此為止,用戶的請求來到了 IDC-1 的 Spanner 集群服務(wù)器上,Spanner 從內(nèi)存中讀取到了路由配置,知道了這個請求的主體用戶 C 所屬的 RZ3* 不再本 IDC,于是直接轉(zhuǎn)到了 IDC-2 進行處理。
③進入 IDC-2 之后,根據(jù)流量配比規(guī)則,該請求被分配到了 RZ3B 進行處理。
④RZ3B 得到請求后對數(shù)據(jù)分區(qū) c 進行訪問。
⑤處理完畢后原路返回。
大家應(yīng)該發(fā)現(xiàn)問題所在了,如果再來一個這樣的請求,豈不是每次都要跨地域進行調(diào)用和返回體傳遞?
確實是存在這樣的問題的,對于這種問題,支付寶架構(gòu)師們決定繼續(xù)把決策邏輯往用戶終端推移。
比如,每個 IDC 機房都會有自己的域名(真實情況可能不是這樣命名的):?
IDC-1?對應(yīng)?cashieridc-1.alipay.com
IDC-2 對應(yīng)?cashieridc-2.alipay.com
那么請求從 IDC-1 涮過一遍返回時會將前端請求跳轉(zhuǎn)到 cashieridc-2.alipay.com 去(如果是 App,只需要替換 rest 調(diào)用的接口域名),后面所有用戶的行為都會在這個域名上發(fā)生,就避免了走一遍 IDC-1 帶來的延時。
支付寶災(zāi)備機制
流量挑撥是災(zāi)備切換的基礎(chǔ)和前提條件,發(fā)生災(zāi)難后的通用方法就是把陷入災(zāi)難的單元的流量重新打到正常的單元上去,這個流量切換的過程俗稱切流。
支付寶 LDC 架構(gòu)下的災(zāi)備有三個層次:
同機房單元間災(zāi)備
同城機房間災(zāi)備
異地機房間災(zāi)備
同機房單元間災(zāi)備:災(zāi)難發(fā)生可能性相對最高(但其實也很小)。對 LDC 來說,最小的災(zāi)難就是某個單元由于一些原因(局部插座斷開、線路老化、人為操作失誤)宕機了。
從上節(jié)里的圖中可以看到每組 RZ 都有 A,B 兩個單元,這就是用來做同機房災(zāi)備的,并且 AB 之間也是雙活雙備的。
正常情況下 AB 兩個單元共同分擔(dān)所有的請求,一旦 A 單元掛了,B 單元將自動承擔(dān) A 單元的流量份額。這個災(zāi)備方案是默認(rèn)的。
同城機房間災(zāi)備:災(zāi)難發(fā)生可能性相對更小。這種災(zāi)難發(fā)生的原因一般是機房電線網(wǎng)線被挖斷,或者機房維護人員操作失誤導(dǎo)致的。
在這種情況下,就需要人工的制定流量挑撥(切流)方案了。下面我們舉例說明這個過程,如下圖所示為上海的兩個 IDC 機房。

整個切流配置過程分兩步,首先需要將陷入災(zāi)難的機房中 RZone 對應(yīng)的數(shù)據(jù)分區(qū)的訪問權(quán)配置進行修改。
假設(shè)我們的方案是由 IDC-2 機房的 RZ2 和 RZ3 分別接管 IDC-1 中的 RZ0 和 RZ1。
那么首先要做的是把數(shù)據(jù)分區(qū) a,b 對應(yīng)的訪問權(quán)從 RZ0 和 RZ1 收回,分配給 RZ2 和 RZ3。
即將(如上圖所示為初始映射):
RZ0*?-->?a
RZ1*?-->?b
RZ2*?-->?c
RZ3*?-->?d
變?yōu)椋?/span>
RZ0*?-->?/
RZ1*?-->?/
RZ2*?-->?a
RZ2*?-->?c
RZ3*?-->?b
RZ3*?-->?d
然后再修改用戶 ID 和 RZ 之間的映射配置。假設(shè)之前為:
[00-24]?-->?RZ0A(50%),RZOB(50%)
[25-49]?-->?RZ1A(50%),RZ1B(50%)
[50-74]?-->?RZ2A(50%),RZ2B(50%)
[75-99]?-->?RZ3A(50%),RZ3B(50%)
那么按照災(zāi)備方案的要求,這個映射配置將變?yōu)椋?/span>
[00-24]?-->?RZ2A(50%),RZ2B(50%)
[25-49]?-->?RZ3A(50%),RZ3B(50%)
[50-74]?-->?RZ2A(50%),RZ2B(50%)
[75-99]?-->?RZ3A(50%),RZ3B(50%)
這樣之后,所有流量將會被打到 IDC-2 中,期間部分已經(jīng)向 IDC-1 發(fā)起請求的用戶會收到失敗并重試的提示。
實際情況中,整個過程并不是災(zāi)難發(fā)生后再去做的,整個切換的流程會以預(yù)案配置的形式事先準(zhǔn)備好,推送給每個流量挑撥客戶端(集成到了所有的服務(wù)和 Spanner 中)。
這里可以思考下,為何先切數(shù)據(jù)庫映射,再切流量呢?這是因為如果先切流量,意味著大量注定失敗的請求會被打到新的正常單元上去,從而影響系統(tǒng)的穩(wěn)定性(數(shù)據(jù)庫還沒準(zhǔn)備好)。
異地機房間災(zāi)備:這個基本上跟同城機房間災(zāi)備一致(這也是單元化的優(yōu)點),不再贅述。
螞蟻單元化架構(gòu)的?CAP?分析
回顧 CAP
①CAP 的定義
CAP 原則是指任意一個分布式系統(tǒng),同時最多只能滿足其中的兩項,而無法同時滿足三項。
所謂的分布式系統(tǒng),說白了就是一件事一個人做的,現(xiàn)在分給好幾個人一起干。
我們先簡單回顧下 CAP 各個維度的含義:
Consistency(一致性),這個理解起來很簡單,就是每時每刻每個節(jié)點上的同一份數(shù)據(jù)都是一致的。
這就要求任何更新都是原子的,即要么全部成功,要么全部失敗。想象一下使用分布式事務(wù)來保證所有系統(tǒng)的原子性是多么低效的一個操作。
Availability(可用性),這個可用性看起來很容易理解,但真正說清楚的不多。我更愿意把可用性解釋為:任意時刻系統(tǒng)都可以提供讀寫服務(wù)。
舉個例子,當(dāng)我們用事務(wù)將所有節(jié)點鎖住來進行某種寫操作時,如果某個節(jié)點發(fā)生不可用的情況,會讓整個系統(tǒng)不可用。
對于分片式的 NoSQL 中間件集群(Redis,Memcached)來說,一旦一個分片歇菜了,整個系統(tǒng)的數(shù)據(jù)也就不完整了,讀取宕機分片的數(shù)據(jù)就會沒響應(yīng),也就是不可用了。
需要說明一點,哪些選擇 CP 的分布式系統(tǒng),并不是代表可用性就完全沒有了,只是可用性沒有保障了。
為了增加可用性保障,這類中間件往往都提供了”分片集群+復(fù)制集”的方案。
Partition tolerance(分區(qū)容忍性),這個可能也是很多文章都沒說清楚的。P 并不是像 CA 一樣是一個獨立的性質(zhì),它依托于 CA 來進行討論。
參考文獻中的解釋:”除非整個網(wǎng)絡(luò)癱瘓,否則任何時刻系統(tǒng)都能正常工作”,言下之意是小范圍的網(wǎng)絡(luò)癱瘓,節(jié)點宕機,都不會影響整個系統(tǒng)的 CA。
我感覺這個解釋聽著還是有點懵逼,所以個人更愿意解釋為當(dāng)節(jié)點之間網(wǎng)絡(luò)不通時(出現(xiàn)網(wǎng)絡(luò)分區(qū)),可用性和一致性仍然能得到保障。
從個人角度理解,分區(qū)容忍性又分為“可用性分區(qū)容忍性”和“一致性分區(qū)容忍性”。
出現(xiàn)分區(qū)時會不會影響可用性的關(guān)鍵在于需不需要所有節(jié)點互相溝通協(xié)作來完成一次事務(wù),不需要的話是鐵定不影響可用性的。
慶幸的是應(yīng)該不太會有分布式系統(tǒng)會被設(shè)計成完成一次事務(wù)需要所有節(jié)點聯(lián)動,一定要舉個例子的話,全同步復(fù)制技術(shù)下的 MySQL 是一個典型案例。
出現(xiàn)分區(qū)時會不會影響一致性的關(guān)鍵則在于出現(xiàn)腦裂時有沒有保證一致性的方案,這對主從同步型數(shù)據(jù)庫(MySQL、SQL Server)是致命的。
一旦網(wǎng)絡(luò)出現(xiàn)分區(qū),產(chǎn)生腦裂,系統(tǒng)會出現(xiàn)一份數(shù)據(jù)兩個值的狀態(tài),誰都不覺得自己是錯的。
需要說明的是,正常來說同一局域網(wǎng)內(nèi),網(wǎng)絡(luò)分區(qū)的概率非常低,這也是為啥我們最熟悉的數(shù)據(jù)庫(MySQL、SQL Server 等)也是不考慮 P 的原因。
下圖為 CAP 之間的經(jīng)典關(guān)系圖:
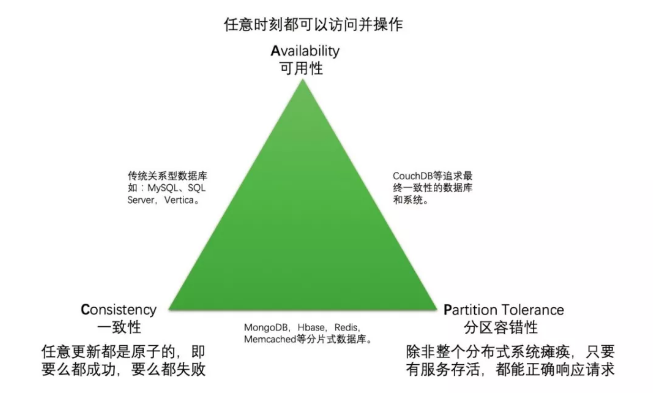
還有個需要說明的地方,其實分布式系統(tǒng)很難滿足 CAP 的前提條件是這個系統(tǒng)一定是有讀有寫的,如果只考慮讀,那么 CAP 很容易都滿足。
比如一個計算器服務(wù),接受表達(dá)式請求,返回計算結(jié)果,搞成水平擴展的分布式,顯然這樣的系統(tǒng)沒有一致性問題,網(wǎng)絡(luò)分區(qū)也不怕,可用性也是很穩(wěn)的,所以可以滿足 CAP。
②CAP 分析方法
先說下 CA 和 P 的關(guān)系,如果不考慮 P 的話,系統(tǒng)是可以輕松實現(xiàn) CA 的。
而 P 并不是一個單獨的性質(zhì),它代表的是目標(biāo)分布式系統(tǒng)有沒有對網(wǎng)絡(luò)分區(qū)的情況做容錯處理。
如果做了處理,就一定是帶有 P 的,接下來再考慮分區(qū)情況下到底選擇了 A 還是 C。所以分析 CAP,建議先確定有沒有對分區(qū)情況做容錯處理。
以下是個人總結(jié)的分析一個分布式系統(tǒng) CAP 滿足情況的一般方法:
if( 不存在分區(qū)的可能性 ||?分區(qū)后不影響可用性或一致性 ||?有影響但考慮了分區(qū)情況-P){
????if(可用性分區(qū)容忍性-A under P))
??????return?"AP";
????else?if(一致性分區(qū)容忍性-C under P)
??????return?"CP";
}
else{ //分區(qū)有影響但沒考慮分區(qū)情況下的容錯
?????if(具備可用性-A && 具備一致性-C){
?????????return?AC;
?????}
}這里說明下,如果考慮了分區(qū)容忍性,就不需要考慮不分區(qū)情況下的可用性和一致性了(大多是滿足的)。
水平擴展應(yīng)用+單數(shù)據(jù)庫實例的 CAP?分析
讓我們再來回顧下分布式應(yīng)用系統(tǒng)的來由,早年每個應(yīng)用都是單體的,跑在一個服務(wù)器上,服務(wù)器一掛,服務(wù)就不可用了。
另外一方面,單體應(yīng)用由于業(yè)務(wù)功能復(fù)雜,對機器的要求也逐漸變高,普通的微機無法滿足這種性能和容量的要求。
所以要拆!還在 IBM 大賣小型商用機的年代,阿里巴巴就提出要以分布式微機替代小型機。
所以我們發(fā)現(xiàn),分布式系統(tǒng)解決的最大的痛點,就是單體單機系統(tǒng)的可用性問題。
要想高可用,必須分布式。一家互聯(lián)網(wǎng)公司的發(fā)展之路上,第一次與分布式相遇應(yīng)該都是在單體應(yīng)用的水平擴展上。
也就是同一個應(yīng)用啟動了多個實例,連接著相同的數(shù)據(jù)庫(為了簡化問題,先不考慮數(shù)據(jù)庫是否單點),如下圖所示:
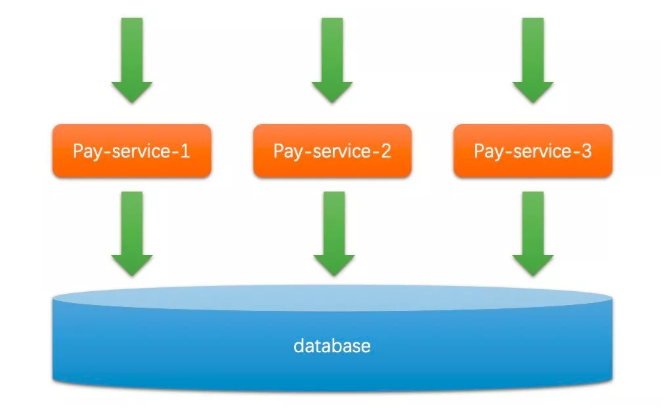
這樣的系統(tǒng)天然具有的就是 AP(可用性和分區(qū)容忍性):
一方面解決了單點導(dǎo)致的低可用性問題。
另一方面無論這些水平擴展的機器間網(wǎng)絡(luò)是否出現(xiàn)分區(qū),這些服務(wù)器都可以各自提供服務(wù),因為他們之間不需要進行溝通。
然而,這樣的系統(tǒng)是沒有一致性可言的,想象一下每個實例都可以往數(shù)據(jù)庫 insert 和 update(注意這里還沒討論到事務(wù)),那還不亂了套。
于是我們轉(zhuǎn)向了讓 DB 去做這個事,這時候”數(shù)據(jù)庫事務(wù)”就被用上了。用大部分公司會選擇的 MySQL 來舉例,用了事務(wù)之后會發(fā)現(xiàn)數(shù)據(jù)庫又變成了單點和瓶頸。
單點就像單機一樣(本例子中不考慮從庫模式),理論上就不叫分布式了,如果一定要分析其 CAP 的話,根據(jù)上面的步驟分析過程應(yīng)該是這樣的:
分區(qū)容忍性:先看有沒有考慮分區(qū)容忍性,或者分區(qū)后是否會有影響。單臺 MySQL 無法構(gòu)成分區(qū),要么整個系統(tǒng)掛了,要么就活著。
可用性分區(qū)容忍性:分區(qū)情況下,假設(shè)恰好是該節(jié)點掛了,系統(tǒng)也就不可用了,所以可用性分區(qū)容忍性不滿足。
一致性分區(qū)容忍性:分區(qū)情況下,只要可用,單點單機的最大好處就是一致性可以得到保障。
因此這樣的一個系統(tǒng),個人認(rèn)為只是滿足了 CP。A 有但不出色,從這點可以看出,CAP 并不是非黑即白的。
包括常說的 BASE (最終一致性)方案,其實只是 C 不出色,但最終也是達(dá)到一致性的,BASE 在一致性上選擇了退讓。
關(guān)于分布式應(yīng)用+單點數(shù)據(jù)庫的模式算不算純正的分布式系統(tǒng),這個可能每個人看法有點差異,上述只是我個人的一種理解,是不是分布式系統(tǒng)不重要,重要的是分析過程。
其實我們討論分布式,就是希望系統(tǒng)的可用性是多個系統(tǒng)多活的,一個掛了另外的也能頂上,顯然單機單點的系統(tǒng)不具備這樣的高可用特性。
所以在我看來,廣義的說 CAP 也適用于單點單機系統(tǒng),單機系統(tǒng)是 CP 的。
說到這里,大家似乎也發(fā)現(xiàn)了,水平擴展的服務(wù)應(yīng)用+數(shù)據(jù)庫這樣的系統(tǒng)的 CAP 魔咒主要發(fā)生在數(shù)據(jù)庫層。
因為大部分這樣的服務(wù)應(yīng)用都只是承擔(dān)了計算的任務(wù)(像計算器那樣),本身不需要互相協(xié)作,所有寫請求帶來的數(shù)據(jù)的一致性問題下沉到了數(shù)據(jù)庫層去解決。
想象一下,如果沒有數(shù)據(jù)庫層,而是應(yīng)用自己來保障數(shù)據(jù)一致性,那么這樣的應(yīng)用之間就涉及到狀態(tài)的同步和交互了,ZooKeeper 就是這么一個典型的例子。
水平擴展應(yīng)用+主從數(shù)據(jù)庫集群的CAP分析
上一節(jié)我們討論了多應(yīng)用實例+單數(shù)據(jù)庫實例的模式,這種模式是分布式系統(tǒng)也好,不是分布式系統(tǒng)也罷,整體是偏 CP 的。
現(xiàn)實中,技術(shù)人員們也會很快發(fā)現(xiàn)這種架構(gòu)的不合理性——可用性太低了。于是如下圖所示的模式成為了當(dāng)下大部分中小公司所使用的架構(gòu):
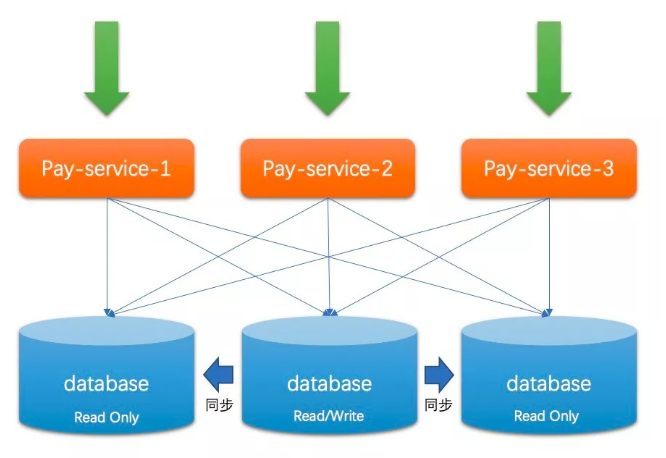
從上圖我可以看到三個數(shù)據(jù)庫實例中只有一個是主庫,其他是從庫。
一定程度上,這種架構(gòu)極大的緩解了”讀可用性”問題,而這樣的架構(gòu)一般會做讀寫分離來達(dá)到更高的”讀可用性”,幸運的是大部分互聯(lián)網(wǎng)場景中讀都占了 80% 以上,所以這樣的架構(gòu)能得到較長時間的廣泛應(yīng)用。
寫可用性可以通過 Keepalived 這種 HA(高可用)框架來保證主庫是活著的,但仔細(xì)一想就可以明白,這種方式并沒有帶來性能上的可用性提升。還好,至少系統(tǒng)不會因為某個實例掛了就都不可用了。
可用性勉強達(dá)標(biāo)了,這時候的 CAP 分析如下:
分區(qū)容忍性:依舊先看分區(qū)容忍性,主從結(jié)構(gòu)的數(shù)據(jù)庫存在節(jié)點之間的通信,他們之間需要通過心跳來保證只有一個 Master。
然而一旦發(fā)生分區(qū),每個分區(qū)會自己選取一個新的 Master,這樣就出現(xiàn)了腦裂,常見的主從數(shù)據(jù)庫(MySQL,Oracle 等)并沒有自帶解決腦裂的方案。所以分區(qū)容忍性是沒考慮的。
一致性:不考慮分區(qū),由于任意時刻只有一個主庫,所以一致性是滿足的。
可用性:不考慮分區(qū),HA 機制的存在可以保證可用性,所以可用性顯然也是滿足的。
所以這樣的一個系統(tǒng),我們認(rèn)為它是 AC 的。我們再深入研究下,如果發(fā)生腦裂產(chǎn)生數(shù)據(jù)不一致后有一種方式可以仲裁一致性問題,是不是就可以滿足 P 了呢。
還真有嘗試通過預(yù)先設(shè)置規(guī)則來解決這種多主庫帶來的一致性問題的系統(tǒng),比如 CouchDB,它通過版本管理來支持多庫寫入,在其仲裁階段會通過 DBA 配置的仲裁規(guī)則(也就是合并規(guī)則,比如誰的時間戳最晚誰的生效)進行自動仲裁(自動合并),從而保障最終一致性(BASE),自動規(guī)則無法合并的情況則只能依賴人工決策了。
螞蟻單元化 LDC 架構(gòu) CAP 分析
①戰(zhàn)勝分區(qū)容忍性
在討論螞蟻 LDC 架構(gòu)的 CAP 之前,我們再來想想分區(qū)容忍性有啥值得一提的,為啥很多大名鼎鼎的 BASE(最終一致性)體系系統(tǒng)都選擇損失實時一致性,而不是丟棄分區(qū)容忍性呢?
分區(qū)的產(chǎn)生一般有兩種情況:
某臺機器宕機了,過一會兒又重啟了,看起來就像失聯(lián)了一段時間,像是網(wǎng)絡(luò)不可達(dá)一樣。
異地部署情況下,異地多活意味著每一地都可能會產(chǎn)生數(shù)據(jù)寫入,而異地之間偶爾的網(wǎng)絡(luò)延時尖刺(網(wǎng)絡(luò)延時曲線圖陡增)、網(wǎng)絡(luò)故障都會導(dǎo)致小范圍的網(wǎng)絡(luò)分區(qū)產(chǎn)生。
前文也提到過,如果一個分布式系統(tǒng)是部署在一個局域網(wǎng)內(nèi)的(一個物理機房內(nèi)),那么個人認(rèn)為分區(qū)的概率極低,即便有復(fù)雜的拓?fù)洌埠苌贂性谕粋€機房里出現(xiàn)網(wǎng)絡(luò)分區(qū)的情況。
而異地這個概率會大大增高,所以螞蟻的三地五中心必須需要思考這樣的問題,分區(qū)容忍不能丟!
同樣的情況還會發(fā)生在不同 ISP 的機房之間(想象一下你和朋友組隊玩 DOTA,他在電信,你在聯(lián)通)。
為了應(yīng)對某一時刻某個機房突發(fā)的網(wǎng)絡(luò)延時尖刺活著間歇性失聯(lián),一個好的分布式系統(tǒng)一定能處理好這種情況下的一致性問題。
那么螞蟻是怎么解決這個問題的呢?我們在上文討論過,其實 LDC 機房的各個單元都由兩部分組成:負(fù)責(zé)業(yè)務(wù)邏輯計算的應(yīng)用服務(wù)器和負(fù)責(zé)數(shù)據(jù)持久化的數(shù)據(jù)庫。
大部分應(yīng)用服務(wù)器就像一個個計算器,自身是不對寫一致性負(fù)責(zé)的,這個任務(wù)被下沉到了數(shù)據(jù)庫。所以螞蟻解決分布式一致性問題的關(guān)鍵就在于數(shù)據(jù)庫!
想必螞蟻的讀者大概猜到下面的討論重點了——OceanBase(下文簡稱OB),中國第一款自主研發(fā)的分布式數(shù)據(jù)庫,一時間也確實獲得了很多光環(huán)。
在討論 OB 前,我們先來想想 Why not MySQL?
首先,就像 CAP 三角圖中指出的,MySQL 是一款滿足 AC 但不滿足 P 的分布式系統(tǒng)。
試想一下,一個 MySQL 主從結(jié)構(gòu)的數(shù)據(jù)庫集群,當(dāng)出現(xiàn)分區(qū)時,問題分區(qū)內(nèi)的 Slave 會認(rèn)為主已經(jīng)掛了,所以自己成為本分區(qū)的 Master(腦裂)。
等分區(qū)問題恢復(fù)后,會產(chǎn)生 2 個主庫的數(shù)據(jù),而無法確定誰是正確的,也就是分區(qū)導(dǎo)致了一致性被破壞。這樣的結(jié)果是嚴(yán)重的,這也是螞蟻寧愿自研 OceanBase 的原動力之一。
那么如何才能讓分布式系統(tǒng)具備分區(qū)容忍性呢?按照老慣例,我們從”可用性分區(qū)容忍”和”一致性分區(qū)容忍”兩個方面來討論:
可用性分區(qū)容忍性保障機制:可用性分區(qū)容忍的關(guān)鍵在于別讓一個事務(wù)一來所有節(jié)點來完成,這個很簡單,別要求所有節(jié)點共同同時參與某個事務(wù)即可。
一致性分區(qū)容忍性保障機制:老實說,都產(chǎn)生分區(qū)了,哪還可能獲得實時一致性。
但要保證最終一致性也不簡單,一旦產(chǎn)生分區(qū),如何保證同一時刻只會產(chǎn)生一份提議呢?
換句話說,如何保障仍然只有一個腦呢?下面我們來看下 PAXOS 算法是如何解決腦裂問題的。
這里可以發(fā)散下,所謂的“腦”其實就是具備寫能力的系統(tǒng),“非腦”就是只具備讀能力的系統(tǒng),對應(yīng)了 MySQL 集群中的從庫。
下面是一段摘自維基百科的 PAXOS 定義:
Paxos is a family of protocols for solving consensus in a network of unreliable processors (that is, processors that may fail).
大致意思就是說,PAXOS 是在一群不是特別可靠的節(jié)點組成的集群中的一種共識機制。
Paxos 要求任何一個提議,至少有 (N/2)+1 的系統(tǒng)節(jié)點認(rèn)可,才被認(rèn)為是可信的,這背后的一個基礎(chǔ)理論是少數(shù)服從多數(shù)。
想象一下,如果多數(shù)節(jié)點認(rèn)可后,整個系統(tǒng)宕機了,重啟后,仍然可以通過一次投票知道哪個值是合法的(多數(shù)節(jié)點保留的那個值)。
這樣的設(shè)定也巧妙的解決了分區(qū)情況下的共識問題,因為一旦產(chǎn)生分區(qū),勢必最多只有一個分區(qū)內(nèi)的節(jié)點數(shù)量會大于等于 (N/2)+1。
通過這樣的設(shè)計就可以巧妙的避開腦裂,當(dāng)然 MySQL 集群的腦裂問題也是可以通過其他方法來解決的,比如同時 Ping 一個公共的 IP,成功者繼續(xù)為腦,顯然這就又制造了另外一個單點。
如果你了解過比特幣或者區(qū)塊鏈,你就知道區(qū)塊鏈的基礎(chǔ)理論也是 PAXOS。區(qū)塊鏈借助 PAXOS 對最終一致性的貢獻來抵御惡意篡改。
而本文涉及的分布式應(yīng)用系統(tǒng)則是通過 PAXOS 來解決分區(qū)容忍性。再說本質(zhì)一點,一個是抵御部分節(jié)點變壞,一個是防范部分節(jié)點失聯(lián)。
大家一定聽說過這樣的描述:PAXOS 是唯一能解決分布式一致性問題的解法。
這句話越是理解越發(fā)覺得詭異,這會讓人以為 PAXOS 逃離于 CAP 約束了,所以個人更愿意理解為:PAXOS 是唯一一種保障分布式系統(tǒng)最終一致性的共識算法(所謂共識算法,就是大家都按照這個算法來操作,大家最后的結(jié)果一定相同)。
PAXOS 并沒有逃離 CAP 魔咒,畢竟達(dá)成共識是 (N/2)+1 的節(jié)點之間的事,剩下的 (N/2)-1 的節(jié)點上的數(shù)據(jù)還是舊的,這時候仍然是不一致的。
所以 PAXOS 對一致性的貢獻在于經(jīng)過一次事務(wù)后,這個集群里已經(jīng)有部分節(jié)點保有了本次事務(wù)正確的結(jié)果(共識的結(jié)果),這個結(jié)果隨后會被異步的同步到其他節(jié)點上,從而保證最終一致性。
以下摘自維基百科:
Paxos is a family of protocols for solving consensus in a network of unreliable processors (that is, processors that may fail).Quorums express the safety (or consistency) properties of Paxos by ensuring at least some surviving processor retains knowledge of the results.
另外 PAXOS 不要求對所有節(jié)點做實時同步,實質(zhì)上是考慮到了分區(qū)情況下的可用性,通過減少完成一次事務(wù)需要的參與者個數(shù),來保障系統(tǒng)的可用性。
②OceanBase 的 CAP 分析
上文提到過,單元化架構(gòu)中的成千山萬的應(yīng)用就像是計算器,本身無 CAP 限制,其 CAP 限制下沉到了其數(shù)據(jù)庫層,也就是螞蟻自研的分布式數(shù)據(jù)庫 OceanBase(本節(jié)簡稱 OB)。
在 OB 體系中,每個數(shù)據(jù)庫實例都具備讀寫能力,具體是讀是寫可以動態(tài)配置(參考第二部分)。
實際情況下大部分時候,對于某一類數(shù)據(jù)(固定用戶號段的數(shù)據(jù))任意時刻只有一個單元會負(fù)責(zé)寫入某個節(jié)點,其他節(jié)點要么是實時庫間同步,要么是異步數(shù)據(jù)同步。
OB 也采用了 PAXOS 共識協(xié)議。實時庫間同步的節(jié)點(包含自己)個數(shù)至少需要 (N/2)+1 個,這樣就可以解決分區(qū)容忍性問題。
下面我們舉個馬老師改英文名的例子來說明 OB 設(shè)計的精妙之處:
假設(shè)數(shù)據(jù)庫按照用戶 ID 分庫分表,馬老師的用戶 ID 對應(yīng)的數(shù)據(jù)段在 [0-9],開始由單元 A 負(fù)責(zé)數(shù)據(jù)寫入。
假如馬老師(用戶 ID 假設(shè)為 000)正在用支付寶 App 修改自己的英文名,馬老師一開始打錯了,打成了 Jason Ma,A 單元收到了這個請求。
這時候發(fā)生了分區(qū)(比如 A 網(wǎng)絡(luò)斷開了),我們將單元 A 對數(shù)據(jù)段 [0,9] 的寫入權(quán)限轉(zhuǎn)交給單元 B(更改映射),馬老師這次寫對了,為 Jack Ma。
而在網(wǎng)絡(luò)斷開前請求已經(jīng)進入了 A,寫權(quán)限轉(zhuǎn)交給單元 B 生效后,A 和 B 同時對 [0,9] 數(shù)據(jù)段進行寫入馬老師的英文名。
假如這時候都允許寫入的話就會出現(xiàn)不一致,A 單元說我看到馬老師設(shè)置了 Jason Ma,B 單元說我看到馬老師設(shè)置了 Jack Ma。
然而這種情況不會發(fā)生的,A 提議說我建議把馬老師的英文名設(shè)置為 Jason Ma 時,發(fā)現(xiàn)沒人回應(yīng)它。
因為出現(xiàn)了分區(qū),其他節(jié)點對它來說都是不可達(dá)的,所以這個提議被自動丟棄,A 心里也明白是自己分區(qū)了,會有主分區(qū)替自己完成寫入任務(wù)的。
同樣的,B 提出了將馬老師的英文名改成 Jack Ma 后,大部分節(jié)點都響應(yīng)了,所以 B 成功將 Jack Ma 寫入了馬老師的賬號記錄。
假如在寫權(quán)限轉(zhuǎn)交給單元 B 后 A 突然恢復(fù)了,也沒關(guān)系,兩筆寫請求同時要求獲得 (N/2)+1 個節(jié)點的事務(wù)鎖,通過 no-wait 設(shè)計,在 B 獲得了鎖之后,其他爭搶該鎖的事務(wù)都會因為失敗而回滾。
下面我們分析下 OB 的 CAP:
分區(qū)容忍性:OB 節(jié)點之間是有互相通信的(需要相互同步數(shù)據(jù)),所以存在分區(qū)問題,OB 通過僅同步到部分節(jié)點來保證可用性。這一點就說明 OB 做了分區(qū)容錯。
可用性分區(qū)容忍性:OB 事務(wù)只需要同步到?(N/2)+1 個節(jié)點,允許其余的一小半節(jié)點分區(qū)(宕機、斷網(wǎng)等),只要 (N/2)+1 個節(jié)點活著就是可用的。
極端情況下,比如 5 個節(jié)點分成 3 份(2:2:1),那就確實不可用了,只是這種情況概率比較低。
一致性分區(qū)容忍性:分區(qū)情況下意味著部分節(jié)點失聯(lián)了,一致性顯然是不滿足的。但通過共識算法可以保證當(dāng)下只有一個值是合法的,并且最終會通過節(jié)點間的同步達(dá)到最終一致性。
所以 OB 仍然沒有逃脫 CAP 魔咒,產(chǎn)生分區(qū)的時候它變成 AP+最終一致性(C)。整體來說,它是 AP 的,即高可用和分區(qū)容忍。
結(jié)語
個人感覺本文涉及到的知識面確實不少,每個點單獨展開都可以討論半天。回到我們緊扣的主旨來看,雙十一海量支付背后技術(shù)上大快人心的設(shè)計到底是啥?
我想無非是以下幾點:
基于用戶分庫分表的 RZone 設(shè)計。每個用戶群獨占一個單元給整個系統(tǒng)的容量帶來了爆發(fā)式增長。
RZone 在網(wǎng)絡(luò)分區(qū)或災(zāi)備切換時 OB 的防腦裂設(shè)計(PAXOS)。我們知道 RZone 是單腦的(讀寫都在一個單元對應(yīng)的庫),而網(wǎng)絡(luò)分區(qū)或者災(zāi)備時熱切換過程中可能會產(chǎn)生多個腦,OB 解決了腦裂情況下的共識問題(PAXOS 算法)。
基于 CZone 的本地讀設(shè)計。這一點保證了很大一部分有著“寫讀時間差”現(xiàn)象的公共數(shù)據(jù)能被高速本地訪問。
剩下的那一丟丟不能本地訪問只能實時訪問 GZone 的公共配置數(shù)據(jù),也興不起什么風(fēng),作不了什么浪。
比如用戶創(chuàng)建這種 TPS,不會高到哪里去。再比如對于實時庫存數(shù)據(jù),可以通過“頁面展示查詢走應(yīng)用層緩存”+“實際下單時再校驗”的方式減少其 GZone 調(diào)用量。
而這就是螞蟻 LDC 的 CRG 架構(gòu),相信 54.4 萬筆/秒還遠(yuǎn)沒到 LDC 的上限,這個數(shù)字可以做到更高。
當(dāng)然雙 11 海量支付的成功不單單是這么一套設(shè)計所決定的,還有預(yù)熱削峰等運營+技術(shù)的手段,以及成百上千的兄弟姐妹共同奮戰(zhàn),特此在這向各位雙 11 留守同學(xué)致敬。
感謝大家的閱讀,文中可能存在不足或遺漏之處,歡迎批評指正。
參考文獻:
Practice of Cloud System Administration, The: DevOps and SRE Practices for Web Services, Volume 2. Thomas A. Limoncelli, Strata R. Chalup, Christina J. Hogan.
MySQL 5.7 半同步復(fù)制技術(shù):https://www.cnblogs.com/zero-gg/p/9057092.html
BASE 理論分析:https://www.jianshu.com/p/f6157118e54b
Keepalived:https://baike.baidu.com/item/Keepalived/10346758?fr=aladdin
PAXOS:https://en.wikipedia.org/wiki/Paxos_(computer_science)
OceanBase 支撐 2135 億成交額背后的技術(shù)原理
https://www.cnblogs.com/antfin/articles/10299396.html
Backup:https://en.wikipedia.org/wiki/Backup
【END】