
爬蟲篇 | 工欲善其事,必先利其器
點(diǎn)擊上方“Python編程學(xué)堂”,關(guān)注公眾號并“星標(biāo)”
獲取新朋友福利

前面一個(gè)【爬蟲篇】的文章分享了網(wǎng)絡(luò)爬蟲的含義、分類、組成、思路以及網(wǎng)絡(luò)爬蟲協(xié)議(Robots協(xié)議),對爬蟲有了初步的了解,本節(jié)重點(diǎn)分享學(xué)習(xí)爬蟲,你需要學(xué)會(huì)選擇。(詳見:爬蟲篇 | 這是你了解的爬蟲嗎?——爬蟲概述)
一、編程語言的選擇
能夠做網(wǎng)絡(luò)爬蟲的編程語言很多,包括PHP、Java、C/C++、Python等都能做爬蟲,都能達(dá)到抓取想要的數(shù)據(jù)資源。那我們該怎么選擇編程語言呢?首先我們需要了解他們做爬蟲的優(yōu)缺點(diǎn),才能選出合適的開發(fā)環(huán)境。
(一)PHP
網(wǎng)絡(luò)爬蟲需要快速的從服務(wù)器中抓取需要的數(shù)據(jù),有時(shí)數(shù)據(jù)量較大時(shí)需要進(jìn)行多線程抓取。PHP雖然是世界上最好的語言,但是PHP對多線程、異步支持不足,并發(fā)不足,而爬蟲程序?qū)λ俣群托室髽O高,所以說PHP天生不是做爬蟲的。
(二)C/C++
C語言是一門面向過程、抽象化的通用程序設(shè)計(jì)語言,廣泛應(yīng)用于底層開發(fā),運(yùn)行效率和性能是最強(qiáng)大的,但是它的學(xué)習(xí)成本非常高,需要有很好地編程知識基礎(chǔ),對于初學(xué)者或者編程知識不是很好地程序員來說,不是一個(gè)很好的選擇。當(dāng)然,能夠用C/C++編寫爬蟲程序,足以說明能力很強(qiáng),但是絕不是最正確的選擇。
(三)Java
在網(wǎng)絡(luò)爬蟲方面,作為Python最大的對手Java,擁有強(qiáng)大的生態(tài)圈。但是Java本身很笨重,代碼量大。由于爬蟲與反爬蟲的較量是持久的,也是頻繁的,剛寫好的爬蟲程序很可能就不能用了。爬蟲程序需要經(jīng)常性的修改部分代碼。而Java的重構(gòu)成本比較高,任何修改都會(huì)導(dǎo)致大量代碼的變動(dòng)。
(四)Python
Python在設(shè)計(jì)上堅(jiān)持了清晰劃一的風(fēng)格,易讀、易維護(hù),語法優(yōu)美、代碼簡潔、開發(fā)效率高、第三方模塊多。并且擁有強(qiáng)大的爬蟲Scrapy,以及成熟高效的scrapy-redis分布式策略。實(shí)現(xiàn)同樣的爬蟲功能,代碼量少,而且維護(hù)方便,開發(fā)效率高。
通過以上比較,各種編程語言各有優(yōu)缺點(diǎn),但對于初學(xué)者來說,用Python進(jìn)行網(wǎng)絡(luò)爬蟲開發(fā),無疑是一個(gè)非常棒的選擇。本人今后對爬蟲篇分享的內(nèi)容就是使用Python 3 編程語言進(jìn)行的。
二、集成開發(fā)工具的選擇
Python的集成開發(fā)環(huán)境有很多,這里推薦兩款不錯(cuò)的 Python集成開發(fā)工具,一個(gè)是PyCharm,一個(gè)是 Sublime Text,當(dāng)然適合自己的 Python IDE才是最好用的。
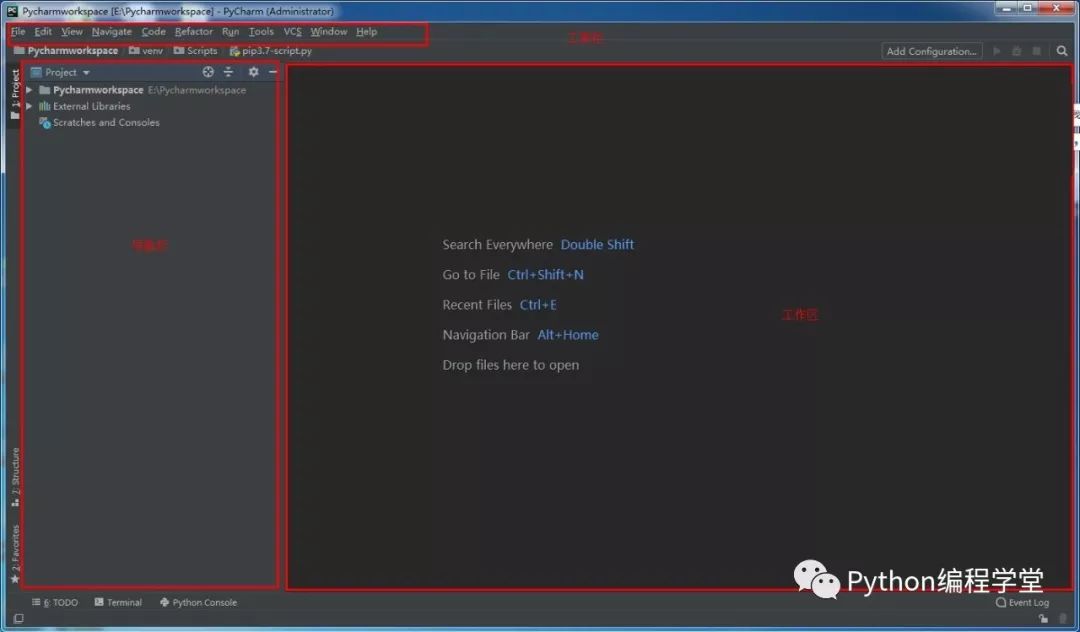
(一)PyCharm
PyCharm 是由 JetBrains 打造的一款 Python IDE。具備一般 Python IDE 的功能,比如:調(diào)試、語法高亮、項(xiàng)目管理、代碼跳轉(zhuǎn)、智能提示、自動(dòng)完成、單元測試、版本控制等。其提供了一個(gè)帶編碼補(bǔ)全,代碼片段,支持代碼折疊和分割窗口的智能、可配置的編輯器,可幫助用戶更快更輕松的完成編碼工作。
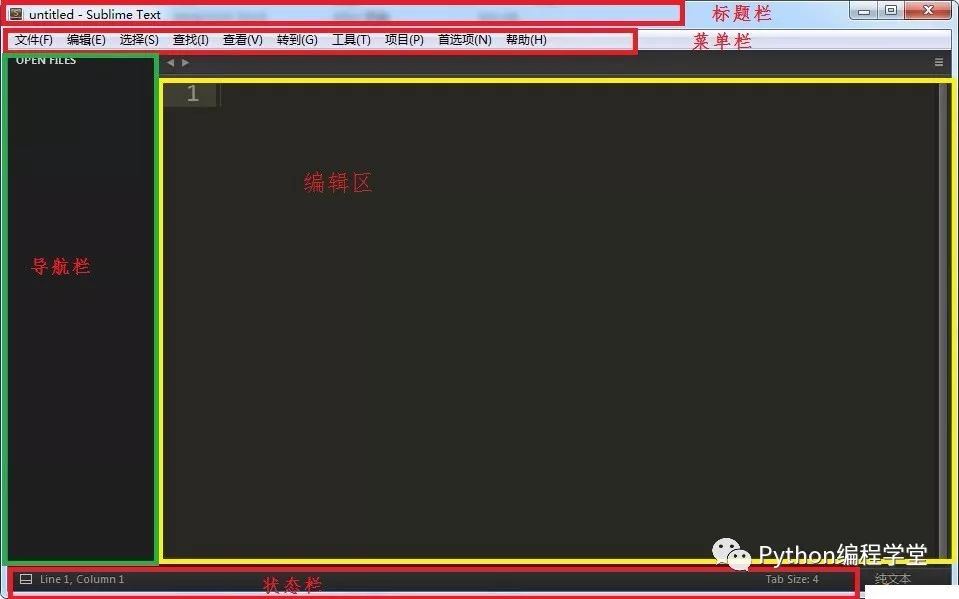
(二)Sublime Text
Sublime Text 具有漂亮的用戶界面和強(qiáng)大的功能,例如代碼縮略圖,Python 的插件,代碼段等。還可自定義鍵綁定,菜單和工具欄。主要功能包括:拼寫檢查,書簽,完整的 Python API , Goto 功能,即時(shí)項(xiàng)目切換,多選擇,多窗口等等。
Sublime Text 是一個(gè)跨平臺的編輯器,同時(shí)支持 Windows、Linux、Mac OS X等操作系統(tǒng)。
對于集成開發(fā)工具,沒有絕對的好,適合自己的就是最好的。這里推薦使用小巧、便捷的Sublime Text編輯器。
三、需要的技能
(一)Python基本語法
這里就不再贅述,如有不懂得建議關(guān)注公眾號參考之前的文章或者網(wǎng)上搜索教程。
(二)了解HTTP協(xié)議,會(huì)使用urllib庫
HTTP是一個(gè)簡單的請求-響應(yīng)協(xié)議,它通常運(yùn)行在TCP之上。它指定了客戶端可能發(fā)送給服務(wù)器什么樣的消息以及得到什么樣的響應(yīng)。會(huì)使用urllib庫模擬瀏覽器發(fā)送請求,獲取服務(wù)器響應(yīng)的數(shù)據(jù)。
(三)解析響應(yīng)內(nèi)容
Python強(qiáng)大的庫提供豐富的解析庫,會(huì)使用re、xpath、BeautifulSoup4、jsonpath、pyquery等中的一種或幾種。目的是使用某種描述性語法來提取匹配規(guī)則的數(shù)據(jù)。
(四)動(dòng)態(tài)頁面及驗(yàn)證碼的處理
有些網(wǎng)頁的內(nèi)容是非靜態(tài)的頁面數(shù)據(jù),需要懂得如何動(dòng)態(tài)加載網(wǎng)頁內(nèi)容。為了防止惡意的爬蟲,有的網(wǎng)頁提供了驗(yàn)證碼的處理,需要能獲取驗(yàn)證碼并機(jī)器識別出內(nèi)容,實(shí)現(xiàn)自動(dòng)化處理。
(五)會(huì)使用抓包工具
瀏覽器自帶的“開發(fā)人員工具”雖然也能夠?qū)崿F(xiàn)抓包,但是對于一些復(fù)雜的網(wǎng)頁,簡單的這個(gè)抓包工具是不行的,你需要會(huì)使用Flidder、Httpwatch、Charles等抓包工具,會(huì)使用一到兩個(gè)就可以。
總結(jié)
以上內(nèi)容看著摸不著頭腦,感覺挺難的,但是由于Python簡潔的語法、強(qiáng)大的第三方庫,使得Python做爬蟲很方便、便捷。下期內(nèi)容將讓你見識Python爬蟲簡單到不能再簡單,讓你愛不釋手。


推薦閱讀:
喜歡的話,請給我個(gè)好看吧!![]()