
如何讓你的 Python 代碼經(jīng)得起時(shí)間檢驗(yàn)?
之前一篇文章里我們介紹了 Python 架構(gòu)模式[1],其中包含了非常多如何設(shè)計(jì)大型 Python 項(xiàng)目架構(gòu)的思考和實(shí)踐方式。不過在日常工作中,除了整體架構(gòu)外,對于代碼本身的工程質(zhì)量也同樣非常重要。
之前給朋友推薦這方面 Python 相關(guān)的書籍,一般都是《Fluent Python》或者《Effective Python》這兩本,前者相對比較關(guān)注 Python 的內(nèi)部原理,如何靈活應(yīng)用需要不淺的功力;而后者是相對零散的最佳實(shí)踐,缺乏一種體系性的感覺。
今年讀了一本比較新出的《Robust Python[2]》,發(fā)現(xiàn)很好的填補(bǔ)了 Python 在工程質(zhì)量話題方面的空白,能為維護(hù)大型的 Python 項(xiàng)目打下非常好的基礎(chǔ)。這篇文章就來簡單介紹一下這本書的內(nèi)容。
背景總覽
由于近些年在數(shù)據(jù)科學(xué),機(jī)器學(xué)習(xí)方面的大量應(yīng)用,Python 已經(jīng)成為這個(gè)星球上最流行的編程語言之一。隨著數(shù)據(jù)智能、機(jī)器學(xué)習(xí)算法類應(yīng)用的爆發(fā),整個(gè)領(lǐng)域也逐漸從之前的“小作坊實(shí)驗(yàn)室”模式往“工業(yè)化大規(guī)模生產(chǎn)”模式轉(zhuǎn)變。這也是為啥 MLOps 這兩年越來越成為一個(gè)熱門話題的原因。隨著算法類軟件逐漸走向“工業(yè)化”,擁有良好工程能力的算法工程師越來越成為企業(yè)急需的人才類型。就拿我們公司來說,之前也考慮過要不要招聘專職的 Python 開發(fā)工程師來做 AI 相關(guān)產(chǎn)品的研發(fā)。
不過嘛,算法類的 Python 開發(fā)跟傳統(tǒng)的 Web 開發(fā)在知識領(lǐng)域上的需求還是有很大區(qū)別的,所以絕大多數(shù)情況下還是算法工程師補(bǔ)充更多的代碼工程技能會(huì)更有優(yōu)勢。這也是為什么我非常推薦從事算法工作的同學(xué)也可以多學(xué)習(xí)一下這本書的原因。
Robust Python,顧名思義,就是教我們?nèi)绾螌懗龈印敖选钡拇a,不易出錯(cuò),且能長時(shí)間的進(jìn)行修改和維護(hù)。Python 本身的語法和概念非常簡單,我有很長一段時(shí)間甚至都覺得這是一門不需要刻意學(xué)習(xí)的語言(相比 Rust,Scala 等)。但看了這本書才發(fā)現(xiàn)原來寫出高質(zhì)量的工程代碼有這么多的講究,以前好像自己都是“沒有穿褲子在上班”那樣不專業(yè)。
1 Introduction to Robust Python
這一章主要是介紹了一下什么是健壯的代碼以及我們?yōu)槭裁葱枰绻嬖囍杏信龅健澳阏J(rèn)為什么樣的代碼是好的代碼”之類的問題,那么主要就是在考察你有沒有過這方面軟件工程的思考,而不僅僅是只把當(dāng)前的功能完成就好。概括來說,編寫健壯的代碼,能讓整個(gè)軟件系統(tǒng)更加容易修改和維護(hù),且出錯(cuò)的概率更低。如果你的項(xiàng)目能夠持續(xù)做快速的更新發(fā)布,每次迭代的交付質(zhì)量還很高,沒什么 bug,新加入的工程師也能很快理解和上手做功能開發(fā),甚至出現(xiàn)了 bug 也很容易排查,那么就是一個(gè)比較理想的軟件項(xiàng)目,能帶來非常可觀的價(jià)值回報(bào)。
這一章的大部分內(nèi)容在很多經(jīng)典著作中都有提到,比如《Clean Code》等,所以熟悉的同學(xué)可以快速瀏覽過去。有兩個(gè)個(gè)人覺得比較有意思的觀點(diǎn)在這里 highlight 一下。
健壯性的核心是溝通
其他大佬也發(fā)表過一些類似觀點(diǎn),如代碼應(yīng)該是寫給人看的,而不是寫給機(jī)器;沒有測試的代碼都屬于“遺留代碼”。文中作者進(jìn)一步結(jié)構(gòu)化了這個(gè)觀點(diǎn),從溝通所需要的“即時(shí)性”(是否能跟未來的開發(fā)者進(jìn)行溝通)和投入成本兩個(gè)維度來考察各種軟件工程中的“溝通手段”:
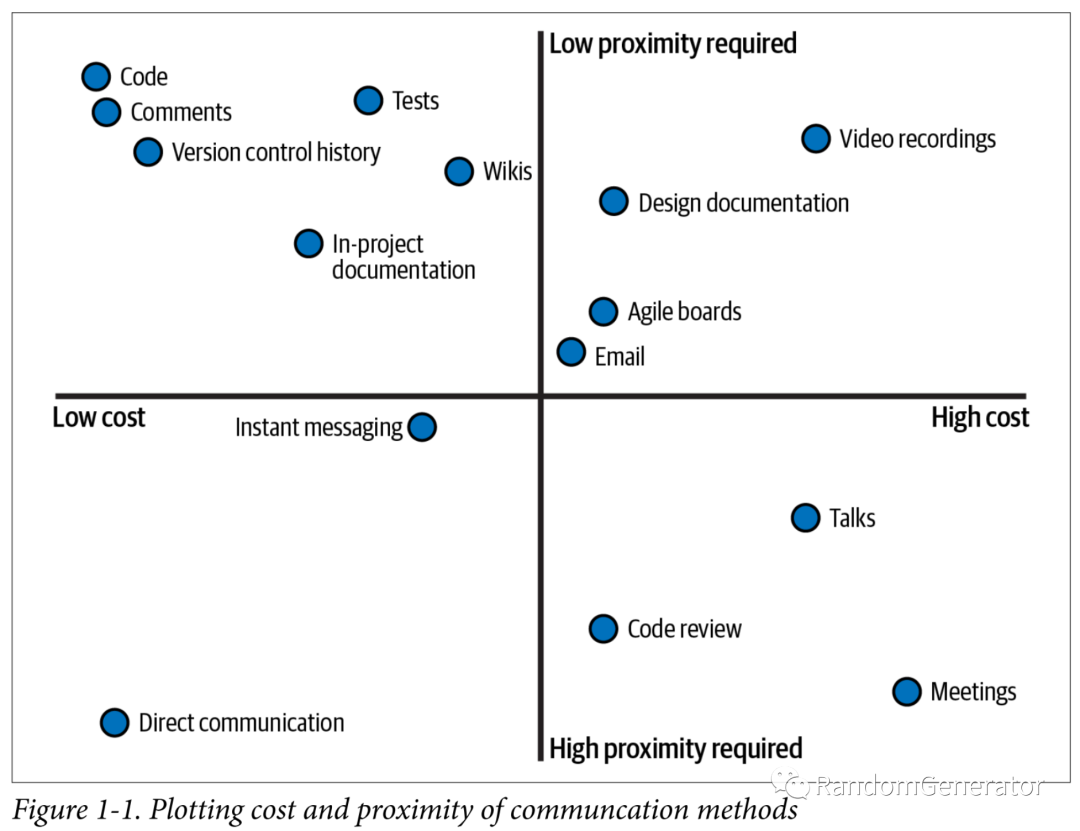
本書中提到的大部分方法都集中在左上象限,即那些不需要投入太高的維護(hù)、使用成本,同時(shí)在時(shí)間維度上沒有即時(shí)性要求的方法,如清晰的代碼,注釋,測試等。
約定俗成的意圖
從溝通角度看,我們在寫代碼時(shí)使用的各種語言特性,應(yīng)該傳達(dá)一種約定俗成的意圖,以降低理解成本。文中作者舉了很多 Python 中的實(shí)際例子,例如當(dāng)你使用list時(shí),想要存儲的是有順序,可重復(fù)的,并且內(nèi)容可變的元素集合,而且一般來說這些元素都是同一種類型。當(dāng)你使用不同的循環(huán)方法,class 或者 dataclass,不同的編程 pattern 時(shí),其實(shí)背后都應(yīng)該有相應(yīng)的意圖共識。遵守這些約定能最大程度上減少對其他維護(hù)者造成的“意外”感覺,我們說的“Pythonic”也大致是這個(gè)意思。
2 Introduction to Python Types
本書的第一部分主要都在講類型方面的最佳實(shí)踐。Python 支持類型注解也有些年頭了,不過絕大多數(shù)的學(xué)習(xí)資料里都沒有強(qiáng)調(diào)這個(gè)特性,導(dǎo)致大家對 Python 的理解都停留在這是一門腳本語言,寫起來比較快捷靈活,但非常容易出線上報(bào)錯(cuò),且理解代碼時(shí)也經(jīng)常不知道參數(shù)是個(gè)什么類型這種問題。個(gè)人建議如果是工作中使用維護(hù)周期超過 1 年的項(xiàng)目,都應(yīng)該考慮增加類型注解的最佳實(shí)踐。
回到這一章里,作者對類型系統(tǒng)做了個(gè)入門介紹,Python 屬于強(qiáng)類型(比較少隱式轉(zhuǎn)換),但又是動(dòng)態(tài)類型的語言,順帶還可以復(fù)習(xí)一下 duck typing。
3 Type Annotations
這一章開頭就引用了一下 Python 之父的話,大意是 喜歡是放肆,但愛是克制 寫腳本可以為所欲為,但做項(xiàng)目就要按規(guī)矩來。寫 Python 時(shí)加上類型注解,就是一種成熟穩(wěn)重負(fù)責(zé)任的表現(xiàn) :) 本章內(nèi)容也比較基礎(chǔ),對類型注解做了基本的介紹,并引入了mypy這類類型檢查工具。例如對于下面的代碼:
def read_file_and_reverse_it(filename: str) -> str:
with open(filename) as f:
return f.read().encode("utf-8")[::-1]
我們就可以使用mypy來做檢查,并發(fā)現(xiàn)其中的問題:
? mypy chapter3/invalid/invalid_example1.py
chapter3/invalid/invalid_example1.py:3: error: Incompatible return value type (got "bytes", expected "str")
Found 1 error in 1 file (checked 1 source file)
對于什么時(shí)候需要加類型注解,作者也給出了一些建議:
其他用戶會(huì)調(diào)用的接口,尤其是 public APIs。 當(dāng)需要處理的數(shù)據(jù)類型比較復(fù)雜時(shí),比如有嵌套結(jié)構(gòu)。 類型檢查工具有提示時(shí)。
4 Constraining Types
本章介紹了一些相對“高級”一些的限制類型。比如我們經(jīng)常在代碼中碰到一些異常情況,最簡單的做法就是在碰到異常時(shí)返回一個(gè)None,然后程序在后面運(yùn)行時(shí)指不定哪里就出現(xiàn)了一個(gè)錯(cuò)誤:
AttributeError: 'NoneType' object has no attribute '...'
對于這種問題,我們可以在程序的 return type 上指定Optional類型的注解,這樣就能通過類型檢查工具來幫我們盡量避免上述報(bào)錯(cuò)的出現(xiàn)。
此外還有很多非常實(shí)用的類型,如特定場景下,Union相比 dataclass 或者Tuple這些類型,能把 Product Type 轉(zhuǎn)為 Sum Type,大大減少的表達(dá)空間的可能性,也降低了犯錯(cuò)的幾率。Literal可以指定相應(yīng)的取值范圍(當(dāng)然Enum可能更強(qiáng)大一些)。NewType可以對同一種類型的“狀態(tài)”做區(qū)分,Final可以用于構(gòu)造不變量等。
5 Collection Types
對于 collections 的注解,我們建議應(yīng)該把集合里的元素類型也加上,便于用戶理解。比如用list[str]這樣的形式,而不只是list。這里也順帶引出了一個(gè)最佳實(shí)踐,就是對于各種集合,絕大多數(shù)情況下我們應(yīng)該保存“同質(zhì)”的類型。只有少數(shù)的例外情況:
使用 tuple 來存放不同字段信息,例如 Cookbook = tuple[str, int] # name, page count。這也是 tuple 約定俗成的用法,當(dāng)然為了增加可讀性,后續(xù)會(huì)提到的 dataclass 更為合適。使用 dict 來存放一些參數(shù),配置信息,相比 tuple 來說可以支持更復(fù)雜的嵌套結(jié)構(gòu)。事實(shí)上很多 json,yaml 庫都是這么做的。
對于后者,作者建議可以使用 TypedDict 來做,可以更多的利用類型檢查來幫助減少錯(cuò)誤發(fā)生的可能,同時(shí)也能幫助其他開發(fā)者理解復(fù)雜數(shù)據(jù)結(jié)構(gòu)。例如:
from typing import TypedDict
class Song(TypedDict):
name : str
year : int
song: Song = {'name': 'We Will Rock You' , 'year': 1977}
不過個(gè)人覺得這個(gè)注解對于復(fù)雜類型用起來還是挺麻煩的,還是 dataclass 更實(shí)用些。
接下來作者介紹了 Python 中的 Generics,說實(shí)話我之前還真不知道 Python 還有“泛型”的支持……例如:
from typing import TypeVar
T = TypeVar("T")
APIResponse = Union[T, APIError]
def get_nutrition_info(recipe: str) -> APIResponse[NutritionInfo]:
# ...
def get_ingredients(recipe: str) -> APIResponse[list[Ingredient]]:
#...
def get_restaurants_serving(recipe: str) -> APIResponse[list[Restaurant]]:
# ...
后面還介紹了如何在 Python 中擴(kuò)展或構(gòu)建自定義的集合類型,提到了兩種方法,一種是繼承已有類型,但注意如果涉及到魔法方法的修改,應(yīng)該使用collections.UserDict而不是dict,因?yàn)楹笳叩暮芏喾椒ǘ甲隽朔椒▋?nèi)聯(lián);另一種是使用collections.abc里提供的抽象類。
6 Customizing Your Typechecker
講完了具體的類型,這一章主要介紹了各種類型檢查工具及相應(yīng)的配置。包括mypy,pyre,和pyright。其中mypy屬于 Python 官方開發(fā)維護(hù),是目前應(yīng)用最廣的一個(gè)庫。不過其它幾個(gè)來頭也不小,比如pyre來自 Facebook,pyright來自 Microsoft。根據(jù)我參與過的一些開源項(xiàng)目,絕大多數(shù)用的都是mypy,像pandas也用了pyright來進(jìn)行補(bǔ)充。從作者的介紹來看,pyright因?yàn)槭俏④洺銎罚€提供了非常棒的 VS Code 集成,實(shí)時(shí)的檢查與提示能夠讓問題更快暴露,提升開發(fā)效率。如果有用 VS Code 的同學(xué)可以嘗試一下。
7 Adopting Typechecking Practically
很多歷史項(xiàng)目在開始時(shí)并沒有做類型注解的意識,或者因?yàn)殚_始的比較早,當(dāng)時(shí)的 Python 版本還不支持,所以我們在實(shí)際應(yīng)用時(shí)需要制定一些策略來注解應(yīng)用類型注解和檢查的最佳實(shí)踐。相比測試來說,類型注解更大的問題在于只針對一兩個(gè)數(shù)據(jù)結(jié)構(gòu),函數(shù)做注解,能獲得的收益并不明顯,書中給出了一個(gè)示意圖:
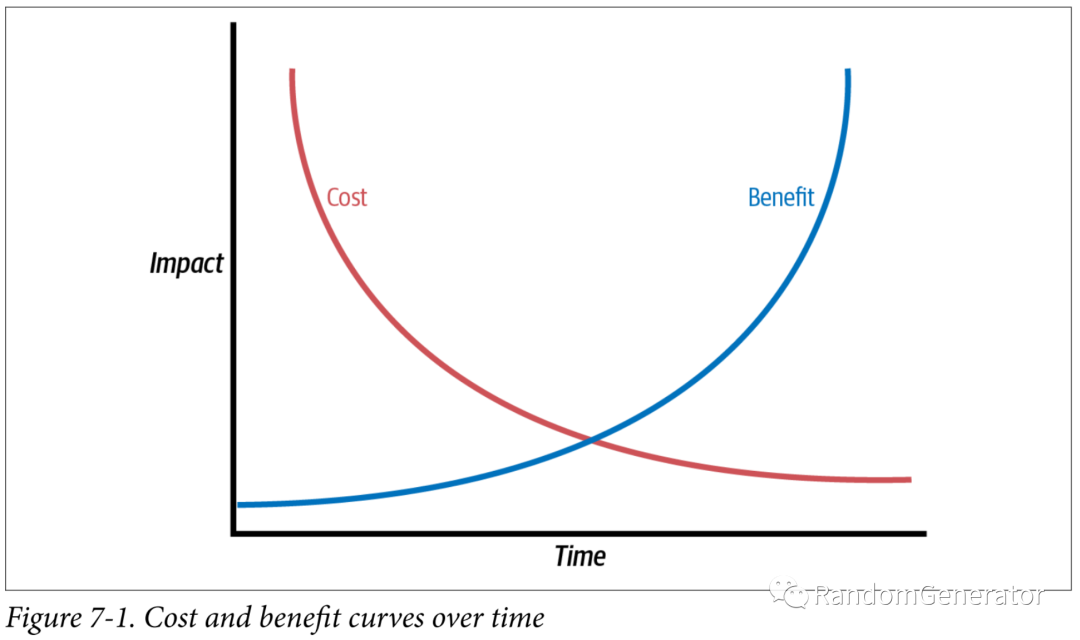
為了能盡快達(dá)到一個(gè)有顯著產(chǎn)出,且投入開銷可控的狀態(tài),書中建議針對項(xiàng)目痛點(diǎn)來進(jìn)行開展,并提供了一套行動(dòng)建議:
新寫的代碼,都加上類型注解。 對于經(jīng)常被 import 的項(xiàng)目通用代碼添加類型注解。 對于產(chǎn)生業(yè)務(wù)價(jià)值的核心代碼添加類型注解。 針對變化比較頻繁的代碼來添加類型注解。 對邏輯復(fù)雜的代碼添加類型注解。
這里有個(gè)小彩蛋,可以通過以下命令來尋找 commit 最頻繁的代碼文件:
git rev-list --objects --all | awk '$2' | sort -k2 | uniq -cf1 | sort -rn | grep "\.py" | head
最后作者還建議可以利用一些工具來幫助自動(dòng)生成代碼中的類型注解,如 Instagram 的 MonkeyType[3] 和來自 Google 的 pytype[4],大家也可以一試。
8 User-Defined Types: Enums
從這一章開始進(jìn)入了第二部分,創(chuàng)建自定義的類型。為什么自定義類型對健壯性有幫助呢,書中舉了個(gè)非常生動(dòng)的例子:
def calculate_total_with_tax(restaurant: tuple[str, str, str, int],
subtotal: float) -> float:
return subtotal * (1 + tax_lookup[restaurant[2]])
和
def calculate_total_with_tax(restaurant: Restaurant,
subtotal: decimal.Decimal) -> decimal.Decimal:
return subtotal * (1 + tax_lookup[restaurant.zip_code])
這兩段代碼是在做同一件事情,但從可讀性來說,后面這段通過有意義的類別名稱,大大降低了理解的難度。從 DDD 的角度來看,領(lǐng)域類型抽象是非常重要的一環(huán)。
回到這一章的重點(diǎn),主要介紹了Enum類型。這跟前面提到過的Literal類型在用途上很相似,不過Enum提供了更多的高級功能。比如支持多選的Flag類型,支持做數(shù)值比較的IntEnum,或者通過unique裝飾器來保證 key 的唯一性等。
9 User-Defined Types: Data Classes
前面在講集合類型時(shí)有提到過 TypedDict,但類似場景下的默認(rèn)選址應(yīng)該還是本章介紹的 dataclass。相比 dict,dataclass 能更好的指定各個(gè)成員變量的類型,還能提供字段名的檢查,大大減少了出錯(cuò)可能。相比原版的 class,dataclass 在定義時(shí)更加簡單,不用寫一堆的__init__方法,只需要直接列出成員變量即可:
from dataclasses import dataclass
@dataclass
class MyFraction:
numerator: int = 0
denominator: int = 1
此外 dataclass 還有很多便利功能,如默認(rèn)提供了更好可讀性的 string representation,可以直接做相等,大小比較等。甚至跟 class 一樣,dataclass 中也可以定義各種方法,這就是 dict 等完全不具備的能力了。
文中還給出了 dataclass 與其它類型如 dict, TypedDict,namedtuple 之間的用途比較,基本上結(jié)論也是在處理異構(gòu)數(shù)據(jù)的集合(一般就是領(lǐng)域模型)時(shí),優(yōu)先使用 dataclass。
10 User-Defined Types: Classes
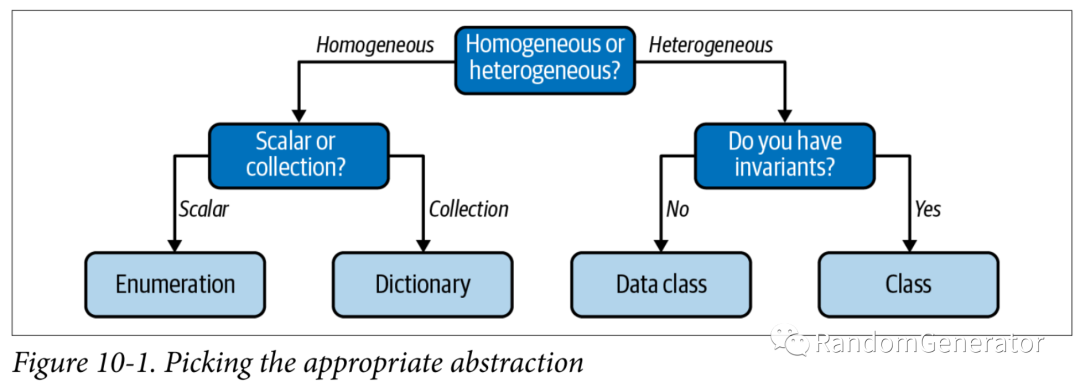
看完 dataclass,一個(gè)很自然的想法是感覺 dataclass 功能已經(jīng)很全了,好像沒有啥時(shí)候需要用到傳統(tǒng)的 class 了?作者給出的解答是,class 最大的作用是可以維護(hù)不變性。在做類的初始化時(shí),我們可以在__init__方法中加入各種檢查,來確保創(chuàng)建的對象是符合業(yè)務(wù)邏輯的。而在類的實(shí)例使用過程中,我們也同樣需要維護(hù)這些不變性,作者建議我們可以用私有變量結(jié)合 setter 方法來實(shí)現(xiàn)。對于如何做 class 的抽象,文中也簡單介紹了一下 SOLID 原則。本章的結(jié)尾,作者還對上面提到的一系列自定義類型的選用總結(jié)了一張決策圖:
11 Defining Your Interfaces
這一章主要介紹了如何來設(shè)計(jì)好用的接口,這其實(shí)是一個(gè)非常重要的話題,尤其很多新手都會(huì)覺得設(shè)計(jì)個(gè)函數(shù)簽名是很簡單直白的事情。但稍微做過一些實(shí)際的大型項(xiàng)目就會(huì)發(fā)現(xiàn),要設(shè)計(jì)好的 API 相當(dāng)?shù)睦щy。沒有好的 API,用戶/維護(hù)者就容易誤用你的代碼,或者僅使用一小部分功能,自己再“重建”一些相關(guān)接口,讓代碼庫中出現(xiàn)各種重復(fù)的功能點(diǎn),進(jìn)一步加大了開發(fā)者選擇正確接口的難度。而且對于用戶基數(shù)大的庫,要做 API 設(shè)計(jì)的變動(dòng)也是非常麻煩的一件事情,因此在這個(gè)問題上,必須投入足夠的精力進(jìn)行重視。
文中給出的建議是可以通過 test-driven development 或者 README-driven development 的方法代入用戶視角,更早的發(fā)現(xiàn) API 設(shè)計(jì)的問題。文中還通過一個(gè)實(shí)例介紹了“Natural Interfaces”的設(shè)計(jì)方法,穿插介紹了一下 Python 中的魔法方法,以及利用 contextmanager 來讓代碼“不容易被誤用”(這里主要是處理失敗路徑)。不過總體來說,接口設(shè)計(jì)是一門挺大的學(xué)問,文中簡短的例子也看不出多少系統(tǒng)性的方法論。如果有這方面比較好的學(xué)習(xí)資料,也歡迎大家推薦。
12 Subtyping
這又是一個(gè)值得好好討論的話題,因?yàn)楹芏嘈氯酥懒死^承的用法之后,就會(huì)在各種不管合適不合適的地方進(jìn)行使用,造就了很多難以維護(hù)的代碼庫。比如最常見的誤區(qū),只要復(fù)用了方法,就可以用繼承。還有很多文章給出的建議是,只要滿足了“is-a”關(guān)系的,就可以用繼承,但這個(gè)定義其實(shí)并不清晰。文中用正方形和長方形的例子對此進(jìn)行了反駁,并提出了更加規(guī)范化的“里氏替換原則”:
如果在使用父類的任何情況下,你都可以傳遞一個(gè)子類進(jìn)去而不出現(xiàn)問題,那么理論上來說就可以用繼承。 子類必須保留所有父類中的“不變性”,比如長方形的長和寬兩個(gè)變量是獨(dú)立的,但正方形并不是,所以就打破了這個(gè)不變性。 子類的前置條件不能比父類的前置條件更嚴(yán)格。 子類的后置條件不能比父類的后置條件更寬松。
對于這些原則,書中還給出了一系列檢查點(diǎn),比如前置的if條件,是否提早return了,有沒有拋出不同的 exception,沒有調(diào)用super等。
在大多數(shù)情況下,composition 都比 subtyping 更好,更容易維護(hù),書中也對 Mixin 等手段做了簡單的介紹。
13 Protocols
前面提到的一系列自定義類型,繼承與組合等都可以更好的利用類型檢查系統(tǒng)來減少程序出錯(cuò)的概率,但這些手段看起來都比較偏向傳統(tǒng)的靜態(tài)類型系統(tǒng)語言的做法。Python 里也提供了非常靈活的 duck typing 的支持,那么我們能不能把類型檢查跟 duck typing 結(jié)合起來呢?這就引出了這一章要講的 protocols。利用 protocol 的定義,我們可以很方便的在實(shí)現(xiàn) duck typing 支持的同時(shí),也能利用上類型檢查的保護(hù)。例如:
from typing import Protocol
class Flyer(Protocol):
def fly(self) -> None:
"""A Flyer can fly"""
class FlyingHero:
"""This hero can fly, which is BEAST."""
def fly(self):
# Do some flying...
class RunningHero:
"""This hero can run. Better than nothing!"""
def run(self):
# Run for your life!
class Board:
"""An imaginary game board that doesn't do anything."""
def make_fly(self, obj: Flyer) -> None: # <- Here's the magic
"""Make an object fly."""
return obj.fly()
def main() -> None:
board = Board()
board.make_fly(FlyingHero())
board.make_fly(RunningHero()) # <- Fails mypy type-checking!
可以看到只需要在 class 中實(shí)現(xiàn)了 protocol 中定義的方法就可以了,如果沒有,則mypy之類的工具能夠檢查出不符合 duck typing 要求的實(shí)例。在此基礎(chǔ)上,本章也介紹了 Protocols 的一些高級功能,如組合,runtime check,針對 module 的 protocol 等。
14 Runtime Checking With pydantic
前面提到的很多類型檢查大多只能滿足靜態(tài)代碼檢查,但在 Python 中還有很多運(yùn)行時(shí)出現(xiàn)的問題,最典型的場景就是用戶傳入的接口請求,配置讀取或者數(shù)據(jù)庫內(nèi)容獲取等。通常來說最直接的防范方式是寫很多檢查邏輯。本章主要介紹了一個(gè)強(qiáng)大的工具pydantic,能夠在基礎(chǔ)的類型檢查的基礎(chǔ)上支持更多的業(yè)務(wù)邏輯檢查,非常的好用,例如:
from pydantic.dataclasses import dataclass
from pydantic import conlist, constr
from pydantic import validator
@dataclass
class Restaurant:
name: constr(regex=r'^[a-zA-Z0-9 ]*$',
min_length=1, max_length=16)
owner: constr(min_length=1)
address: constr(min_length=1)
employees: conlist(Employee, min_items=2)
dishes: conlist(Dish, min_items=3)
number_of_seats: PositiveInt
to_go: bool
delivery: bool
@validator('employees')
def check_chef_and_server(cls, employees):
if (any(e for e in employees if e.position == 'Chef') and
any(e for e in employees if e.position == 'Server')):
return employees
raise ValueError('Must have at least one chef and one server')
這本書介紹了不少這類好用的工具,實(shí)用性滿分!
15 Extensibility
這里開始進(jìn)入了第三部分,講可擴(kuò)展的 Python,即應(yīng)對不斷變化的需求,如何讓我們的代碼更容易拓展與變更。這一章以一個(gè)發(fā)送消息通知的例子來進(jìn)行了介紹,同時(shí)也講了一下“開放封閉原則”。個(gè)人比較有收獲的是在最后作者也提了一下我們并不是一味的追求可擴(kuò)展性,如果針對可擴(kuò)展性做了過度的設(shè)計(jì),可能會(huì)導(dǎo)致抽象層次過多,可讀性下降,且模塊的耦合度變高的問題。所以在實(shí)際項(xiàng)目中,還是需要根據(jù)業(yè)務(wù)變化的頻率來決定具體的代碼結(jié)構(gòu)設(shè)計(jì)。
16 Dependencies
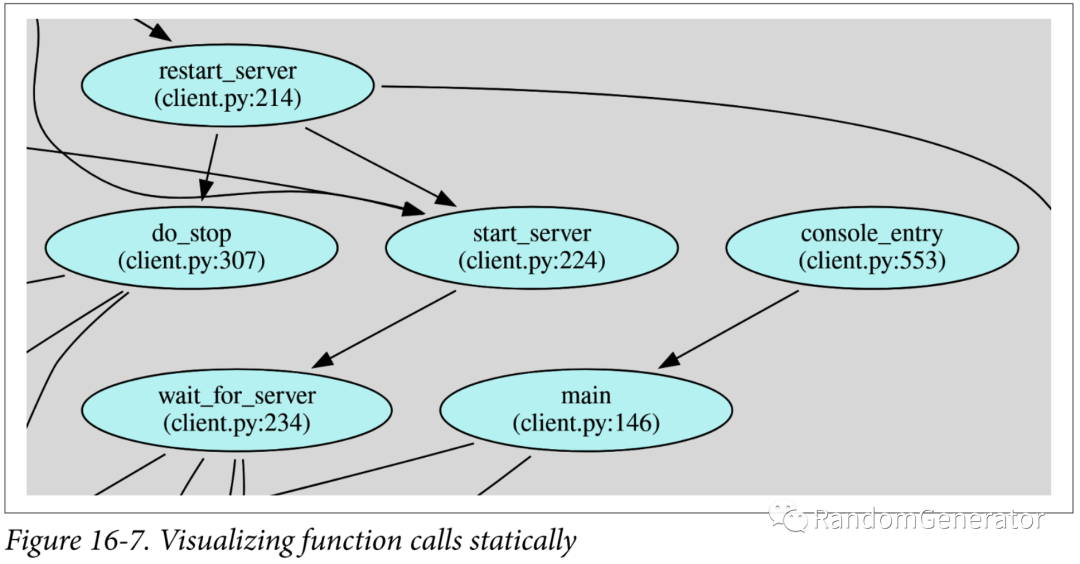
這一章主要介紹了各種依賴,作者分成了三類,包括物理的,邏輯的和時(shí)序的,并討論了一些其中的取舍。比較有意思的后半部分對于各種依賴的可視化展示的工具,包括pipdeptree:
pydeps:
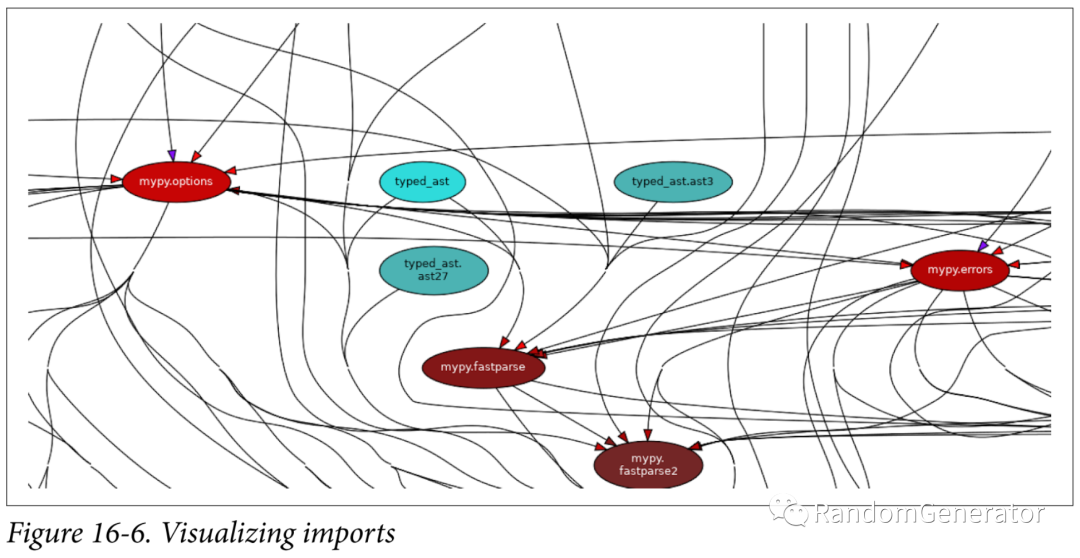
pyan3:
cProfile結(jié)合gprof2dot:
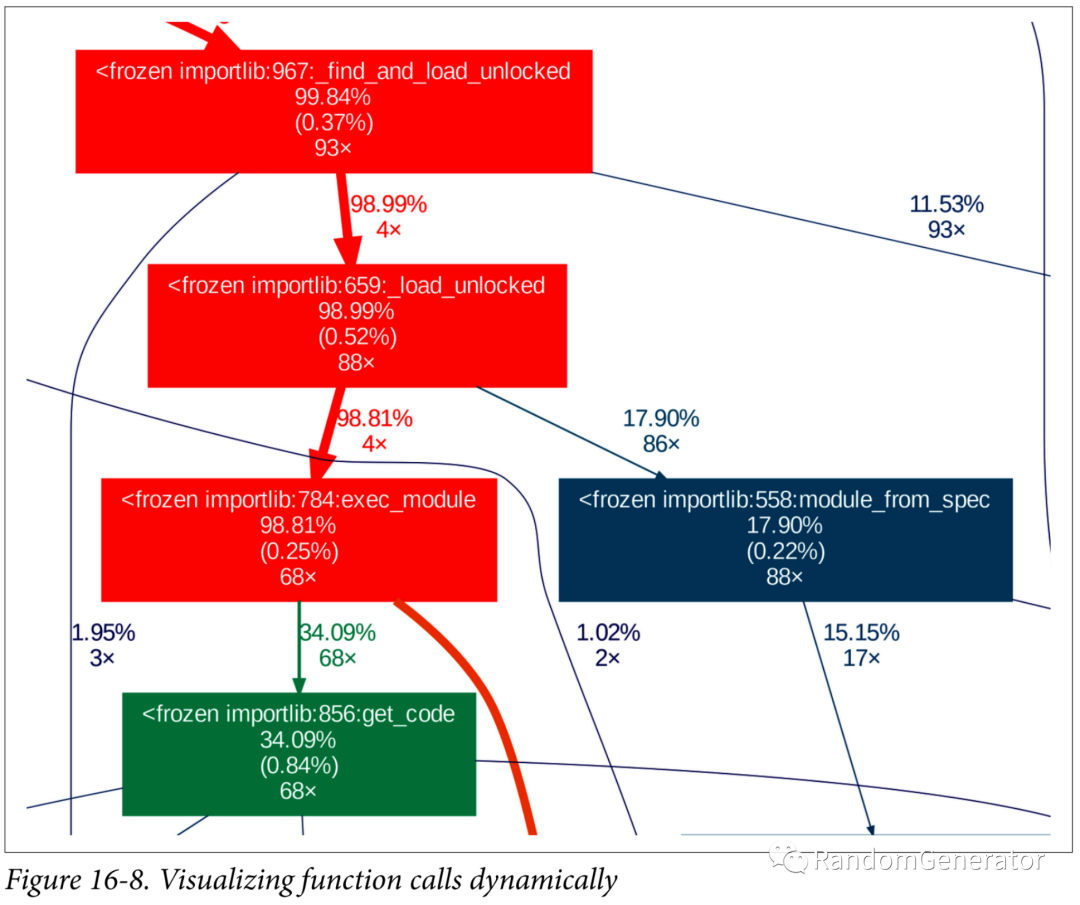
上面這個(gè)功能在 PyCharm 里也有。通過可視化,可以檢查代碼依賴是否清晰。
17 Composability
作者在這一章里繼續(xù)通過例子來說明如何實(shí)踐“可組合”的編程,提出了把 policy 和 mechanism 分離的原則,以及函數(shù)組合,裝飾器,算法組合等話題。這章的內(nèi)容讓我聯(lián)想到在算法領(lǐng)域很多計(jì)算圖定義和具體計(jì)算執(zhí)行引擎分離的設(shè)計(jì)方式,不知道有沒有特定的名稱來描述這種 pattern。
18 Event-Driven Architecture
前面幾章描述的可擴(kuò)展性實(shí)踐主要聚焦在項(xiàng)目代碼層面,這一章把視角拉高了一些,從整體架構(gòu)的角度來看這個(gè)問題,并介紹了可擴(kuò)展性、可組合性非常優(yōu)異的事件驅(qū)動(dòng)架構(gòu)。具體包括了基礎(chǔ)的 PubSub 模式,觀察者模式,和更復(fù)雜的 streaming event 模式。這本書里介紹的架構(gòu)相對簡單一些,額外介紹了一些 Python 相關(guān)的庫的支持,如PyPubSub和RxPy。之前介紹的 Python 架構(gòu)模式里則介紹了更加復(fù)雜和完整的消息驅(qū)動(dòng)架構(gòu),不過 Python 庫這塊則用的相對比較基礎(chǔ)一些。
19 Pluggable Python
延續(xù)上一章介紹了 plug-in 相關(guān)的設(shè)計(jì)模式和系統(tǒng)架構(gòu),包括 template pattern 和 startegy pattern。個(gè)人對設(shè)計(jì)模式這塊不是很感冒(雖然這本書講的還算挺 practical,沒有硬套一堆 class),不過后面這個(gè) plug-in 架構(gòu)里作者介紹了一個(gè)很強(qiáng)大的 Python 庫 stevedore[5],感覺很有意思。例如:
import itertools
from stevedore import extension
Recipe = str
Dish = str
def get_inventory():
return {}
# 遍歷所有 plug-in 來獲取菜譜
def get_all_recipes() -> list[Recipe]:
mgr = extension.ExtensionManager(
namespace='ultimate_kitchen_assistant.recipe_maker',
invoke_on_load=True,
)
def get_recipes(extension):
return extension.obj.get_recipes()
return list(itertools.chain.from_iterable(mgr.map(get_recipes)))
# 調(diào)用具體的 plug-in 來執(zhí)行 prepare_dish 操作
from stevedore import driver
def make_dish(recipe: Recipe, module_name: str) -> Dish:
mgr = driver.DriverManager(
namespace='ultimate_kitchen_assistant.recipe_maker',
name=module_name,
invoke_on_load=True,
)
return mgr.driver.prepare_dish(get_inventory(), recipe)
20 Static Analysis
進(jìn)入到了全書的最后一部分,通過構(gòu)建“安全網(wǎng)”來促進(jìn)軟件的健壯性。這一章先介紹了各種代碼靜態(tài)檢查。我觀察到很多研發(fā)人員在使用 PyCharm 之類的 IDE 做開發(fā)時(shí),并不會(huì)注意各種代碼 warning 的提示,這些其實(shí)就是通過靜態(tài)分析得出的潛在問題。例如代碼沒有符合 PEP 8 的編碼規(guī)范,有些申明的變量并沒有使用,調(diào)用了私有方法等。實(shí)際上在大多數(shù)的標(biāo)準(zhǔn)工程實(shí)踐中,應(yīng)該把這類靜態(tài)檢查加到 CI 流程中,如果沒有通過相關(guān)檢查,不允許做代碼的合并。書中作者主要介紹了pylint的使用,另外項(xiàng)目中使用flake8也挺常見的。此外還有一系列針對專門用途的檢查工具:
代碼復(fù)雜度檢查工具: mccabe,或者也可以通過檢查“空格”的數(shù)量來評估代碼復(fù)雜度密碼泄露檢查工具:dodgy[6] 安全缺陷檢查工具:Bandit[7]
21 Testing Strategy
接下來的幾章都跟測試有關(guān),這一章先起個(gè)頭對測試做個(gè)總體介紹。比如各種不同的測試類型:
Unit test Integration test Acceptance test Performance test Load test Security test Usability test
對于不同測試的數(shù)量的闡釋,把經(jīng)典的測試三角(界面,集成,單元測試)進(jìn)一步泛化了一下:
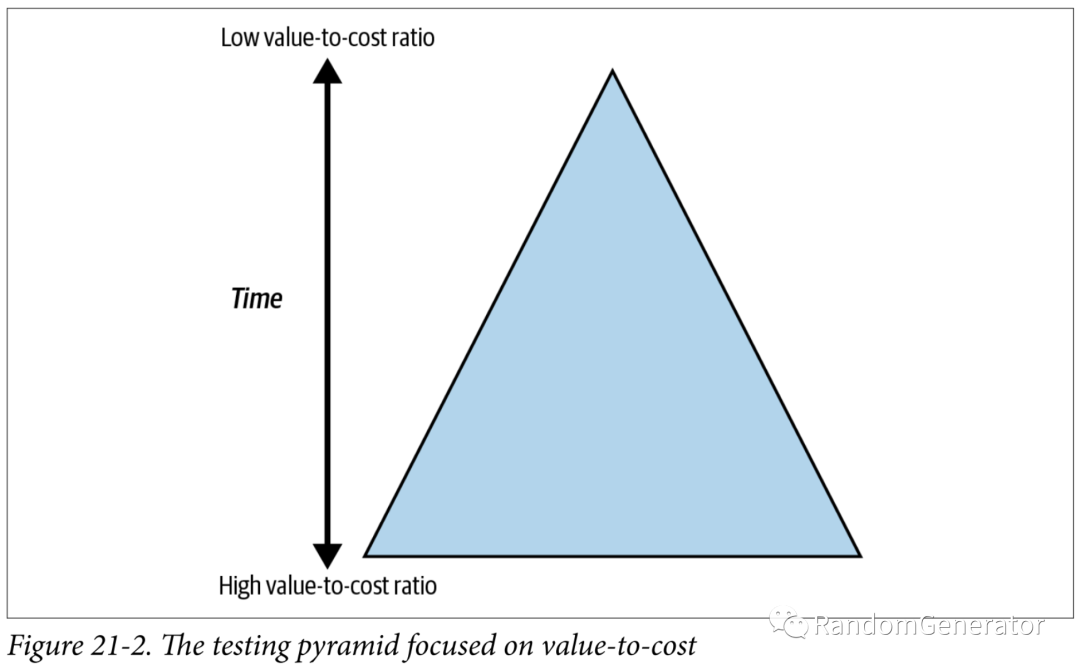
這里的 cost 主要指的是撰寫,維護(hù)和執(zhí)行測試所需要的開銷。所以也比較好理解,UI 測試一般來說要么使用手工測試,執(zhí)行成本較高,或者做自動(dòng)化的話維護(hù)成本就很高,一般來說都屬于測試數(shù)量最少的那一類,位于三角形的頂端。而單元測試這類執(zhí)行速度快,維護(hù)成本低,一般就會(huì)數(shù)量較多,位于三角形的底部。
后面的部分以pytest為工具,介紹了最常見的 AAA(Arrange-Act-Assert)測試模式,以及其中的一些降低測試成本的技巧,如 fixture,mocking,參數(shù)化,Hamcrest matchers[8] 等。個(gè)人建議如果不知道如何入手來寫測試的話,也可以去參考一些開源項(xiàng)目里的做法,比如 sklearn,pandas 等。
22 Acceptance Testing
前面的pytest比較適用于研發(fā)人員對于各種功能 spec 的測試,這一章里作者提出更重要的是我們需要交付符合業(yè)務(wù)需求的軟件,這就需要適用 acceptance 測試來支持了。這章主要介紹的是 Behavior-driven development,包括使用 Gherkin 語言來描述需求,使用behave框架來執(zhí)行相關(guān)的需求驗(yàn)證測試。相應(yīng)的需求描述長這樣:
Feature: Vegan-friendly menu
Scenario: Can substitute for vegan alternatives
Given an order containing a Cheeseburger with Fries
When I ask for vegan substitutions
Then I receive the meal with no animal products
對應(yīng)的測試:
from behave import given, when, then
@given("an order containing {dish_name}")
def setup_order(ctx, dish_name):
if dish_name == "a Cheeseburger with Fries":
ctx.dish = CheeseburgerWithFries()
elif dish_name == "Meatloaf":
ctx.dish = Meatloaf()
ctx.dish = Meatloaf()
@when("I ask for vegan substitutions")
def substitute_vegan(ctx):
if isinstance(ctx.dish, Meatloaf):
return
ctx.dish.substitute_vegan_ingredients()
@then("I receive the meal with no animal products")
def check_all_vegan(ctx):
if isinstance(ctx.dish, Meatloaf):
return
assert all(is_vegan(ing) for ing in ctx.dish.ingredients())
behave框架還支持生成 junit 格式的 report,然后再通過junit2html轉(zhuǎn)化為 html 格式的報(bào)告:
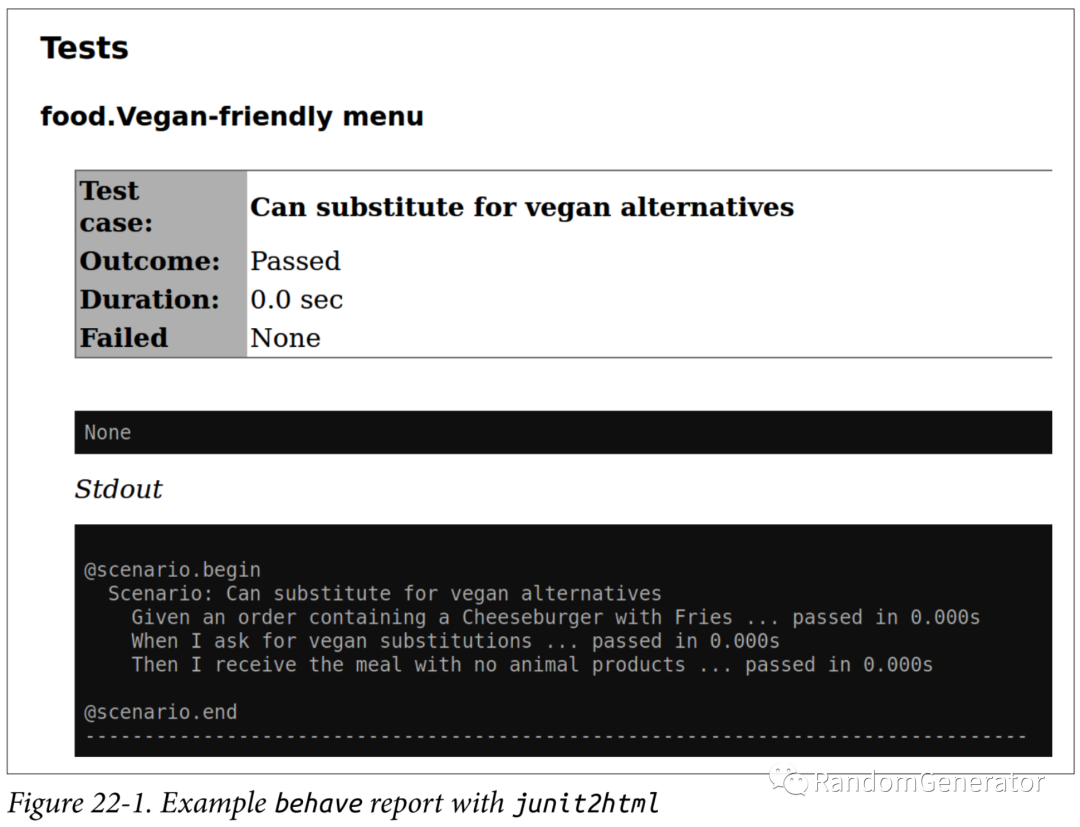
不過個(gè)人經(jīng)歷過的項(xiàng)目里,基本沒有見過實(shí)踐 BDD 方法的,不知道各位小伙伴們有沒有了解過這方面應(yīng)用比較好的場景和最佳實(shí)踐?
23 Property-Based Testing
這一章要介紹的工具有點(diǎn)厲害了,可以自動(dòng)幫助我們來生成測試!傳統(tǒng)的測試中,我們一般是自己構(gòu)造數(shù)據(jù),然后執(zhí)行測試,最后驗(yàn)證對應(yīng)的結(jié)果符合某個(gè)具體數(shù)值的預(yù)期。而在 property-based 測試中,我們可以指定一些數(shù)據(jù)的 spec,然后hypothesis這個(gè)庫會(huì)幫忙來生成符合 spec 的隨機(jī)數(shù)據(jù),執(zhí)行測試,最后我們驗(yàn)證結(jié)果符合預(yù)期。例如下面這個(gè)例子,我們讓hypothesis來生成具體的 calories 值,然后測試生成的 meal 推薦符合預(yù)期:
from hypothesis import given, example
from hypothesis.strategies import integers
def get_recommended_meal(Recommendation, calories: int) -> list[Meal]:
return [Meal("Spring Roll", 120),
Meal("Green Papaya Salad", 230),
Meal("Larb Chicken", 500)]
@given(integers(min_value=900))
def test_meal_recommendation_under_specific_calories(calories):
meals = get_recommended_meal(Recommendation.BY_CALORIES, calories)
assert len(meals) == 3
assert is_appetizer(meals[0])
assert is_salad(meals[1])
assert is_main_dish(meals[2])
assert sum(meal.calories for meal in meals) < calories
書中還有更多的拓展功能介紹和代碼案例,感興趣的同學(xué)可以學(xué)習(xí)一下。這個(gè)庫讓我想起之前還有個(gè) model-based testing 方法,通過構(gòu)建應(yīng)用的狀態(tài)機(jī)模型,來遍歷所有狀態(tài)組合生成各種測試用例。不過這個(gè)建模本身的成本有點(diǎn)高,所以見到的應(yīng)用好像也比較少。
24 Mutation Testing
最后一章也介紹了一種非常有意思的測試類型,“變異測試”。大概的原理就是隨機(jī)改動(dòng)原始的代碼文件,應(yīng)該會(huì)讓原有的測試用例失敗,如果沒有的話,則表明改動(dòng)的那一行代碼缺少相應(yīng)的測試來覆蓋。例如書中給出的例子:
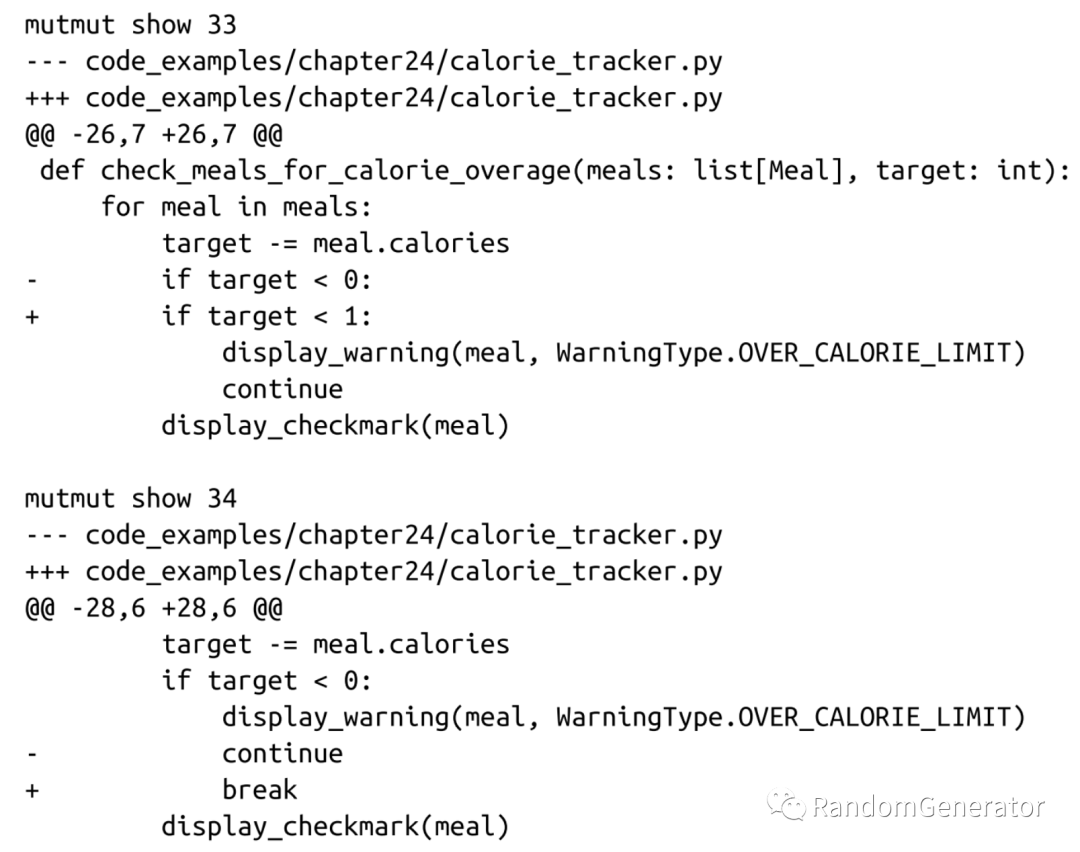
可以看到某些明顯改變軟件行為的代碼當(dāng)前是缺少測試覆蓋的,我們應(yīng)該進(jìn)行補(bǔ)充。這個(gè)方法對于幫助補(bǔ)充測試用例還是有一定作用的,不過主要問題還是執(zhí)行這類測試的代價(jià)會(huì)比較高,而且更適合于已經(jīng)有比較完善測試覆蓋的代碼庫。書中也給出了一些建議,比如可以根據(jù) code coverage 來執(zhí)行對應(yīng)的變異測試。
最后作者還批評了一下各種軟件工程中的指標(biāo),尤其是通過 code coverage 來代表軟件質(zhì)量的高低。他也建議可以通過變異測試來檢查一下高代碼覆蓋率的測試集是否真的都有效。
參考資料
Python 架構(gòu)模式: https://zhuanlan.zhihu.com/p/257281522
[2]Robust Python: https://book.douban.com/subject/35553532/
[3]MonkeyType: https://github.com/Instagram/MonkeyType
[4]pytype: https://github.com/google/pytype
[5]stevedore: https://github.com/openstack/stevedore
[6]dodgy: https://github.com/landscapeio/dodgy
[7]Bandit: https://bandit.readthedocs.io/en/latest/
[8]Hamcrest matchers: https://github.com/hamcrest/PyHamcrest

還不過癮?試試它們
▲源碼探秘:Python 中對象是如何被調(diào)用的?
▲終于,Python 標(biāo)準(zhǔn)庫要做“瘦身手術(shù)”了!