(1)什么時(shí)候才需要分庫(kù)分表呢?我們的評(píng)判標(biāo)準(zhǔn)是什么?
(2)一張表存儲(chǔ)了多少數(shù)據(jù)的時(shí)候,才需要考慮分庫(kù)分表?
(3)數(shù)據(jù)增長(zhǎng)速度很快,每天產(chǎn)生多少數(shù)據(jù),才需要考慮做分庫(kù)分表?
這些問題你都搞清楚了嗎?相信看完這篇文章會(huì)有答案。
為什么要分庫(kù)分表? 首先回答一下為什么要分庫(kù)分表,答案很簡(jiǎn)單: 數(shù)據(jù)庫(kù)出現(xiàn)性能瓶頸 。用大白話來說就是數(shù)據(jù)庫(kù)快扛不住了。
數(shù)據(jù)庫(kù)出現(xiàn)性能瓶頸,對(duì)外表現(xiàn)有幾個(gè)方面:
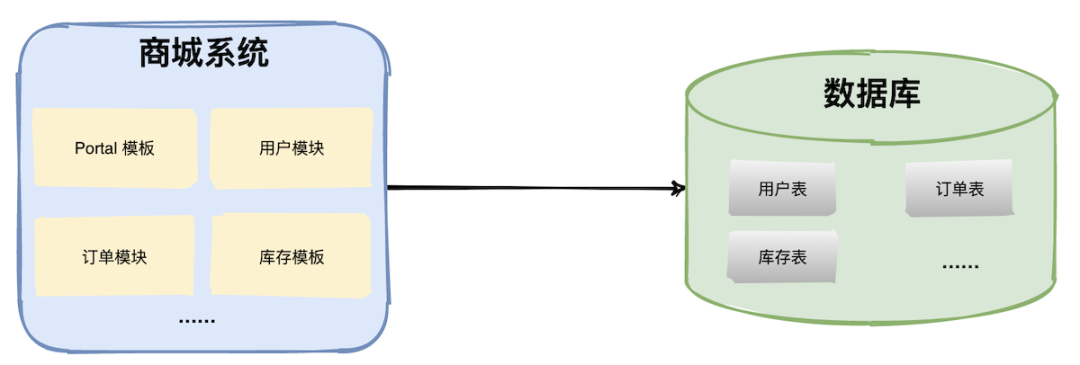
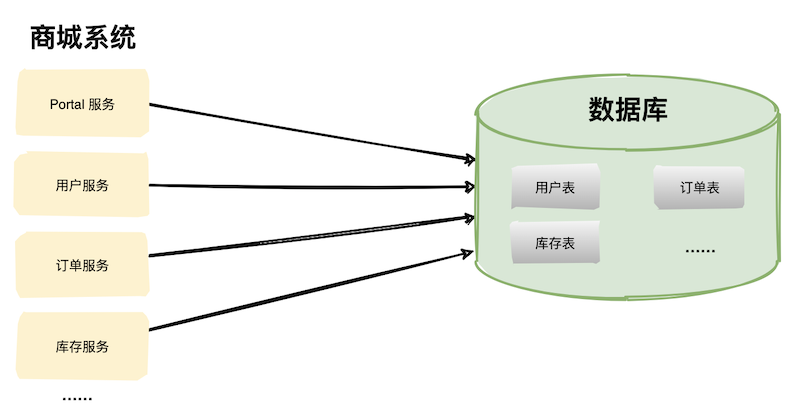
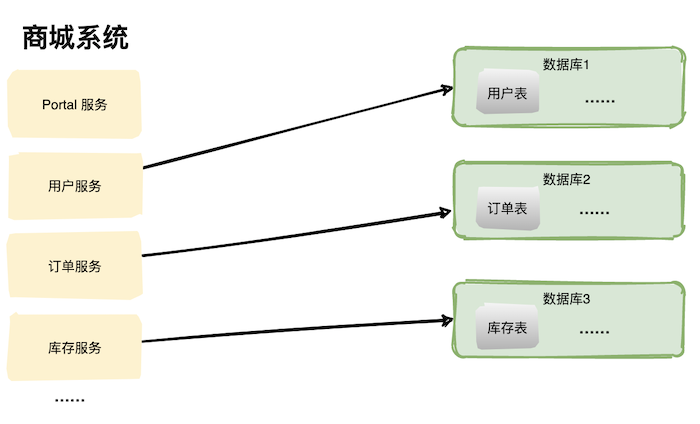
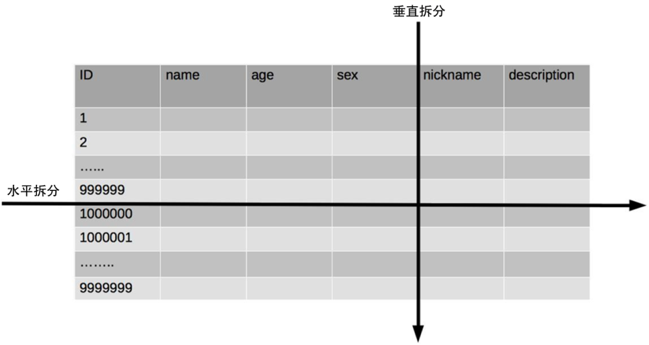
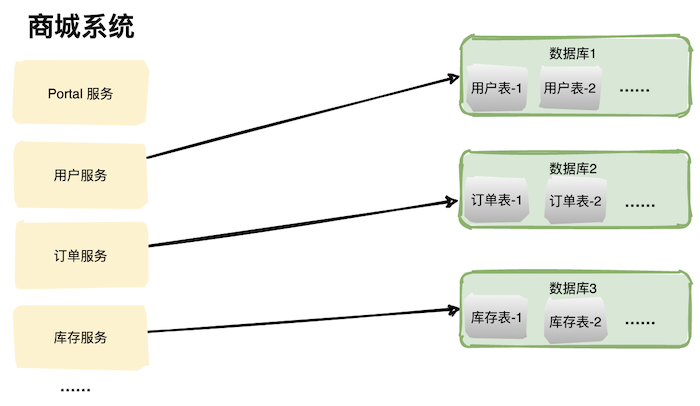
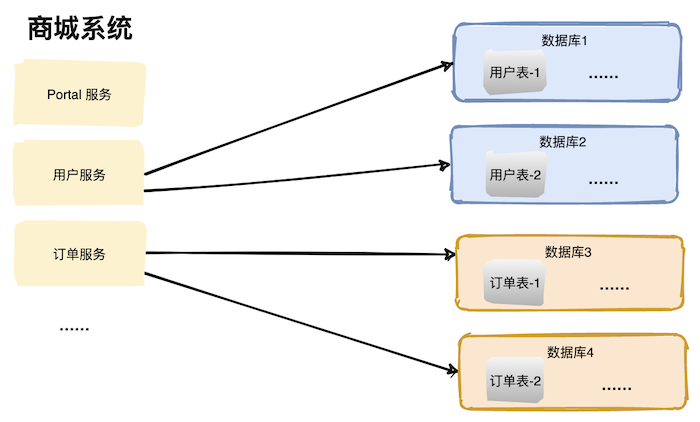
在高并發(fā)場(chǎng)景下,大量請(qǐng)求都需要操作數(shù)據(jù)庫(kù),導(dǎo)致連接數(shù)不夠了,請(qǐng)求處于阻塞狀態(tài)。 如果數(shù)據(jù)庫(kù)中存在一張上億數(shù)據(jù)量的表,一條 SQL 沒有命中索引會(huì)全表掃描,這個(gè)查詢耗時(shí)會(huì)非常久。 業(yè)務(wù)量劇增,單庫(kù)數(shù)據(jù)量越來越大,給存儲(chǔ)造成巨大壓力。 從機(jī)器的角度看,性能瓶頸無非就是CPU、內(nèi)存、磁盤、網(wǎng)絡(luò)這些,要解決性能瓶頸最簡(jiǎn)單粗暴的辦法就是提升機(jī)器性能,但是通過這種方法成本和收益投入比往往又太高了,不劃算,所以重點(diǎn)還是要從軟件角度入手。 數(shù)據(jù)庫(kù)相關(guān)優(yōu)化方案 數(shù)據(jù)庫(kù)優(yōu)化方案很多,主要分為兩大類:軟件層面、硬件層面。 軟件層面包括:SQL 調(diào)優(yōu)、表結(jié)構(gòu)優(yōu)化、讀寫分離、數(shù)據(jù)庫(kù)集群、分庫(kù)分表等; SQL 調(diào)優(yōu) SQL 調(diào)優(yōu)往往是解決數(shù)據(jù)庫(kù)問題的第一步,往往投入少部分精力就能獲得較大的收益。 SQL 調(diào)優(yōu)主要目的是盡可能的讓那些慢 SQL 變快,手段其實(shí)也很簡(jiǎn)單就是讓 SQL 執(zhí)行盡量命中索引。 如果你使用的是 Mysql,需要在 Mysql 配置文件中配置幾個(gè)參數(shù)即可。 slow_query_log=on
常常會(huì)用到 explain 這個(gè)命令來查看 SQL 語句的執(zhí)行計(jì)劃,通過觀察執(zhí)行結(jié)果很容易就知道該 SQL 語句是不是全表掃描、有沒有命中索引。 select id, age, gender from user where name = 'AAA'; ALL、index、range、 ref、eq_ref、const、system、NULL(從左到右,性能從差到好) ALL 代表這條 SQL 語句全表掃描了,需要優(yōu)化。一般來說需要達(dá)到range 級(jí)別及以上。 表結(jié)構(gòu)優(yōu)化 “user”表中有 user_id、nickname 等字段,“order”表中有order_id、user_id等字段,如果想拿到用戶昵稱怎么辦?一般情況是通過 join 關(guān)聯(lián)表操作,在查詢訂單表時(shí)關(guān)聯(lián)查詢用戶表,從而獲取導(dǎo)用戶昵稱。 但是隨著業(yè)務(wù)量增加,訂單表和用戶表肯定也是暴增,這時(shí)候通過兩個(gè)表關(guān)聯(lián)數(shù)據(jù)就比較費(fèi)力了,為了取一個(gè)昵稱字段而不得不關(guān)聯(lián)查詢幾十上百萬的用戶表,其速度可想而知。 這個(gè)時(shí)候可以嘗試將 nickname 這個(gè)字段加到 order 表中(order_id、user_id、nickname),這種做法通常叫做數(shù)據(jù)庫(kù)表冗余字段。這樣做的好處展示訂單列表時(shí)不需要再關(guān)聯(lián)查詢用戶表了。 冗余字段的做法也有一個(gè)弊端,如果這個(gè)字段更新會(huì)同時(shí)涉及到多個(gè)表的更新,因此在選擇冗余字段時(shí)要盡量選擇不經(jīng)常更新的字段。 架構(gòu)優(yōu)化 當(dāng)單臺(tái)數(shù)據(jù)庫(kù)實(shí)例扛不住,我們可以增加實(shí)例組成集群對(duì)外服務(wù)。 當(dāng)發(fā)現(xiàn)讀請(qǐng)求明顯多于寫請(qǐng)求時(shí),我們可以讓主實(shí)例負(fù)責(zé)寫,從實(shí)例對(duì)外提供讀的能力; 如果讀實(shí)例壓力依然很大,可以在數(shù)據(jù)庫(kù)前面加入緩存如 redis,讓請(qǐng)求優(yōu)先從緩存取數(shù)據(jù)減少數(shù)據(jù)庫(kù)訪問。 緩存分擔(dān)了部分壓力后,數(shù)據(jù)庫(kù)依然是瓶頸,這個(gè)時(shí)候就可以考慮分庫(kù)分表的方案了,后面會(huì)詳細(xì)介紹。 硬件優(yōu)化 硬件成本非常高,一般來說不可能遇到數(shù)據(jù)庫(kù)性能瓶頸就去升級(jí)硬件。 在前期業(yè)務(wù)量比較小的時(shí)候,升級(jí)硬件數(shù)據(jù)庫(kù)性能可以得到較大提升;但是在后期,升級(jí)硬件得到的收益就不那么明顯了。 分庫(kù)分表詳解 下面我們以一個(gè)商城系統(tǒng)為例逐步講解數(shù)據(jù)庫(kù)是如何一步步演進(jìn)。 單應(yīng)用單數(shù)據(jù)庫(kù) 在早期創(chuàng)業(yè)階段想做一個(gè)商城系統(tǒng),基本就是一個(gè)系統(tǒng)包含多個(gè)基礎(chǔ)功能模塊,最后打包成一個(gè) war 包部署,這就是典型的單體架構(gòu)應(yīng)用。 商城項(xiàng)目使用單數(shù)據(jù)庫(kù) 如上圖,商城系統(tǒng)包括主頁(yè) Portal 模板、用戶模塊、訂單模塊、庫(kù)存模塊等,所有的模塊都共有一個(gè)數(shù)據(jù)庫(kù),通常數(shù)據(jù)庫(kù)中有非常多的表。 因?yàn)橛脩袅坎淮螅@樣的架構(gòu)在早期完全適用,開發(fā)者可以拿著 demo到處找(騙)投資人。 一旦拿到投資人的錢,業(yè)務(wù)就要開始大規(guī)模推廣,同時(shí)系統(tǒng)架構(gòu)也要匹配業(yè)務(wù)的快速發(fā)展。 多應(yīng)用單數(shù)據(jù)庫(kù) 在前期為了搶占市場(chǎng),這一套系統(tǒng)不停地迭代更新,代碼量越來越大,架構(gòu)也變得越來越臃腫,現(xiàn)在隨著系統(tǒng)訪問壓力逐漸增加,系統(tǒng)拆分就勢(shì)在必行了。 為了保證業(yè)務(wù)平滑,系統(tǒng)架構(gòu)重構(gòu)也是分了幾個(gè)階段進(jìn)行。 第一個(gè)階段將商城系統(tǒng)單體架構(gòu)按照功能模塊拆分為子服務(wù),比如:Portal 服務(wù)、用戶服務(wù)、訂單服務(wù)、庫(kù)存服務(wù)等。 多應(yīng)用單數(shù)據(jù)庫(kù) 如上圖,多個(gè)服務(wù)共享一個(gè)數(shù)據(jù)庫(kù),這樣做的目的是底層數(shù)據(jù)庫(kù)訪問邏輯可以不用動(dòng),將影響降到最低。 多應(yīng)用多數(shù)據(jù)庫(kù) 隨著業(yè)務(wù)推廣力度加大,數(shù)據(jù)庫(kù)終于成為了瓶頸,這個(gè)時(shí)候多個(gè)服務(wù)共享一個(gè)數(shù)據(jù)庫(kù)基本不可行了。我們需要將每個(gè)服務(wù)相關(guān)的表拆出來單獨(dú)建立一個(gè)數(shù)據(jù)庫(kù),這其實(shí)就是“分庫(kù)”了。 單數(shù)據(jù)庫(kù)的能夠支撐的并發(fā)量是有限的,拆成多個(gè)庫(kù)可以使服務(wù)間不用競(jìng)爭(zhēng),提升服務(wù)的性能。 多應(yīng)用多數(shù)據(jù)庫(kù) 如上圖,從一個(gè)大的數(shù)據(jù)中分出多個(gè)小的數(shù)據(jù)庫(kù),每個(gè)服務(wù)都對(duì)應(yīng)一個(gè)數(shù)據(jù)庫(kù),這就是系統(tǒng)發(fā)展到一定階段必要要做的“分庫(kù)”操作。 現(xiàn)在非常火的微服務(wù)架構(gòu)也是一樣的,如果只拆分應(yīng)用不拆分?jǐn)?shù)據(jù)庫(kù),不能解決根本問題,整個(gè)系統(tǒng)也很容易達(dá)到瓶頸。 分表 如果系統(tǒng)處于高速發(fā)展階段,拿商城系統(tǒng)來說,一天下單量可能幾十萬,那數(shù)據(jù)庫(kù)中的訂單表增長(zhǎng)就特別快,增長(zhǎng)到一定階段數(shù)據(jù)庫(kù)查詢效率就會(huì)出現(xiàn)明顯下降。 因此,當(dāng)單表數(shù)據(jù)增量過快,業(yè)界流傳是超過500萬的數(shù)據(jù)量就要考慮分表了。當(dāng)然500萬只是一個(gè)經(jīng)驗(yàn)值,大家可以根據(jù)實(shí)際情況做出決策。 分表有幾個(gè)維度,一是水平切分和垂直切分,二是單庫(kù)內(nèi)分表和多庫(kù)內(nèi)分表。 就拿用戶表(user)來說,表中有7個(gè)字段:id,name,age,sex,nickname,description,如果 nickname 和 description 不常用,我們可以將其拆分為另外一張表:用戶詳細(xì)信息表,這樣就由一張用戶表拆分為了用戶基本信息表+用戶詳細(xì)信息表,兩張表結(jié)構(gòu)不一樣相互獨(dú)立。但是從這個(gè)角度來看垂直拆分并沒有從根本上解決單表數(shù)據(jù)量過大的問題,因此我們還是需要做一次水平拆分。 拆分表 還有一種拆分方法,比如表中有一萬條數(shù)據(jù),我們拆分為兩張表,id 為奇數(shù)的:1,3,5,7……放在 user1, id 為偶數(shù)的:2,4,6,8……放在 user2中,這樣的拆分辦法就是水平拆分了。 水平拆分的方式也很多,除了上面說的按照 id 拆表,還可以按照時(shí)間維度取拆分,比如訂單表,可以按每日、每月等進(jìn)行拆分。 每日表:只存儲(chǔ)當(dāng)天的數(shù)據(jù)。 每月表:可以起一個(gè)定時(shí)任務(wù)將前一天的數(shù)據(jù)全部遷移到當(dāng)月表。 歷史表:同樣可以用定時(shí)任務(wù)把時(shí)間超過 30 天的數(shù)據(jù)遷移到 history表。 總結(jié)一下水平拆分和垂直拆分的特點(diǎn): 垂直切分:基于表或字段劃分,表結(jié)構(gòu)不同。 水平切分:基于數(shù)據(jù)劃分,表結(jié)構(gòu)相同,數(shù)據(jù)不同。 拿水平拆分為例,每張表都拆分為了多個(gè)子表,多個(gè)子表存在于同一數(shù)據(jù)庫(kù)中。比如下面用戶表拆分為用戶1表、用戶2表。 單庫(kù)拆分 在一個(gè)數(shù)據(jù)庫(kù)中將一張表拆分為幾個(gè)子表在一定程度上可以解決單表查詢性能的問題,但是也會(huì)遇到一個(gè)問題:?jiǎn)螖?shù)據(jù)庫(kù)存儲(chǔ)瓶頸。 所以在業(yè)界用的更多的還是將子表拆分到多個(gè)數(shù)據(jù)庫(kù)中。比如下圖中,用戶表拆分為兩個(gè)子表,兩個(gè)子表分別存在于不同的數(shù)據(jù)庫(kù)中。 多庫(kù)拆分 一句話總結(jié):分表主要是為了減少單張表的大小,解決單表數(shù)據(jù)量帶來的性能問題。 分庫(kù)分表帶來的復(fù)雜性 既然分庫(kù)分表這么好,那我們是不是在項(xiàng)目初期就應(yīng)該采用這種方案呢?不要激動(dòng),冷靜一下,分庫(kù)分表的確解決了很多問題,但是也給系統(tǒng)帶來了很多復(fù)雜性,下面簡(jiǎn)要說一說。 (1)跨庫(kù)關(guān)聯(lián)查詢 在單庫(kù)未拆分表之前,我們可以很方便使用 join 操作關(guān)聯(lián)多張表查詢數(shù)據(jù),但是經(jīng)過分庫(kù)分表后兩張表可能都不在一個(gè)數(shù)據(jù)庫(kù)中,如何使用 join 呢? 字段冗余:把需要關(guān)聯(lián)的字段放入主表中,避免 join 操作; 數(shù)據(jù)抽象:通過ETL等將數(shù)據(jù)匯合聚集,生成新的表; 全局表:比如一些基礎(chǔ)表可以在每個(gè)數(shù)據(jù)庫(kù)中都放一份; 應(yīng)用層組裝:將基礎(chǔ)數(shù)據(jù)查出來,通過應(yīng)用程序計(jì)算組裝; 單數(shù)據(jù)庫(kù)可以用本地事務(wù)搞定,使用多數(shù)據(jù)庫(kù)就只能通過分布式事務(wù)解決了。 常用解決方案有:基于可靠消息(MQ)的解決方案、兩階段事務(wù)提交、柔性事務(wù)等。 (3)排序、分頁(yè)、函數(shù)計(jì)算問題 在使用 SQL 時(shí) order by, limit 等關(guān)鍵字需要特殊處理,一般來說采用分片的思路: 先在每個(gè)分片上執(zhí)行相應(yīng)的函數(shù),然后將各個(gè)分片的結(jié)果集進(jìn)行匯總和再次計(jì)算,最終得到結(jié)果。 如果使用 Mysql 數(shù)據(jù)庫(kù)在單庫(kù)單表可以使用 id 自增作為主鍵,分庫(kù)分表了之后就不行了,會(huì)出現(xiàn)id 重復(fù)。 基于數(shù)據(jù)庫(kù)自增單獨(dú)維護(hù)一張 ID表 這些方案后面會(huì)寫文章專門介紹,這里不再展開。 分庫(kù)分表之后可能會(huì)面臨從多個(gè)數(shù)據(jù)庫(kù)或多個(gè)子表中獲取數(shù)據(jù),一般的解決思路有:客戶端適配和代理層適配。 shardingsphere(前身 sharding-jdbc) 總結(jié) 如果出現(xiàn)數(shù)據(jù)庫(kù)問題不要著急分庫(kù)分表,先看一下使用常規(guī)手段是否能夠解決。 分庫(kù)分表會(huì)給系統(tǒng)帶來巨大的復(fù)雜性,不是萬不得已建議不要提前使用。作為系統(tǒng)架構(gòu)師可以讓系統(tǒng)靈活性和可擴(kuò)展性強(qiáng),但是不要過度設(shè)計(jì)和超前設(shè)計(jì)。在這一點(diǎn)上,架構(gòu)師一定要有前瞻性,提前做好預(yù)判。大家學(xué)會(huì)了嗎? 有道無術(shù),術(shù)可成;有術(shù)無道,止于術(shù)
歡迎大家關(guān)注 Java之道 公眾號(hào)
好文章,我 在看 ??