
如何正確使用COCO數(shù)據(jù)集
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

COCO數(shù)據(jù)集,意為“Common Objects In Context”,是一組具有挑戰(zhàn)性的、高質量的計算機視覺數(shù)據(jù)集,是最先進的神經(jīng)網(wǎng)絡,此名稱還用于命名這些數(shù)據(jù)集使用的格式。
COCO 是一個大規(guī)模的對象檢測、分割和字幕數(shù)據(jù)集。COCO有幾個特點:
- 對象分割
- 在上下文中識別
- 超像素素材分割
- 330K 圖像(> 200K 標記)
- 150 萬個對象實例
- 80 個對象類別
該數(shù)據(jù)集的格式可以被高級神經(jīng)網(wǎng)絡庫自動理解,例如Facebook的Detectron2,甚至還有專門為處理 COCO 格式的數(shù)據(jù)集而構建的工具,例如COCO- annotator和COCOapi。了解此數(shù)據(jù)集的表示方式將有助于使用和修改現(xiàn)有數(shù)據(jù)集以及創(chuàng)建自定義數(shù)據(jù)集。具體來說,我們對注釋文件感興趣,是因為完整的數(shù)據(jù)集由圖像目錄和注釋文件組成,提供機器學習算法使用的元數(shù)據(jù)。
實際上有多個 COCO 數(shù)據(jù)集,每個數(shù)據(jù)集都是為特定的機器學習任務創(chuàng)建的,并帶有附加數(shù)據(jù)。3個最受歡迎的任務是:
對象檢測——模型應該獲取對象的邊界框,即返回對象類列表和它們周圍矩形的坐標;物體(也稱為“事物”)是離散的、獨立的物體,通常帶有零件,如人和汽車。
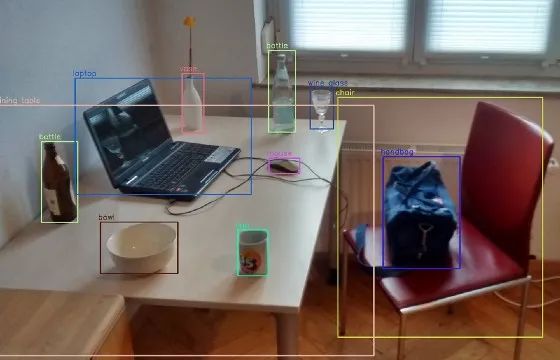
對象分割——模型不僅應該得到對象(實例/“事物”)的邊界框,還應該得到分割掩碼,即圍繞對象的多邊形坐標。

實例分割——模型應該做對象分割,但不是在單獨的對象(“事物”)上,而是在背景連續(xù)模式上,比如草或天空。

在計算機視覺中,這些任務有著巨大的用途,例如用于自動駕駛車輛(檢測人和其他車輛)、基于人工智能的安全性(人體檢測和/或分割)和對象重新識別(對象分割或實例分割去除背景有助于檢查對象身份)。
基本結構和常見元素:COCO 注釋使用的文件格式是 JSON,它有字典(大括號內的鍵值對{…})作為頂部值,它還可以有列表(括號內的有序項目集合,[…])或嵌套在其中的字典。
基本結構如下:
{
"info": {…},
"licenses": […],
"images": […],
"categories": […],
"annotations": […]
}
讓我們仔細看看基本結構中的每一個部分。
“info”部分:
該字典包含有關數(shù)據(jù)集的元數(shù)據(jù),對于官方的 COCO 數(shù)據(jù)集,如下:
{
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
}
如我們所見,它僅包含基本信息,"url"值指向數(shù)據(jù)集官方網(wǎng)站(例如 UCI 存儲庫頁面或在單獨域中),這是機器學習數(shù)據(jù)集中常見的事情,指向他們的網(wǎng)站以獲取更多信息,例如獲取數(shù)據(jù)的方式和時間。
“licenses”部分:
以下是數(shù)據(jù)集中圖像許可的鏈接,例如知識共享許可,具有以下結構:
[
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nc/2.0/",
"id": 2,
"name": "Attribution-NonCommercial License"
},
…
]
這里要注意的重要一點是"id"字段——"images"字典中的每個圖像都應該指定其許可證的“id”。
在使用圖像時,請確保沒有違反其許可——可以在 URL 下找到全文。
如果我們決定創(chuàng)建自己的數(shù)據(jù)集,請為每個圖像分配適當?shù)脑S可——如果我們不確定,最好不要使用該圖像。
“image”部分:
可以說是第二重要的,這本字典包含有關圖像的元數(shù)據(jù):
{
"license": 3,
"file_name": "000000391895.jpg",
"coco_url": "http://images.cocodataset.org/train2017/000000391895.jpg",
"height": 360,
"width": 640,
"date_captured": "2013–11–14 11:18:45",
"flickr_url": "http://farm9.staticflickr.com/8186/8119368305_4e622c8349_z.jpg",
"id": 391895
}
接下來我們看一下這些字段:
"license":來自該"licenses" 部分的圖像許可證的 ID
"file_name": 圖像目錄中的文件名
"coco_url", "flickr_url": 在線托管圖像副本的 URL
"height", "width": 圖像的大小,在像 C 這樣的低級語言中非常方便,在這種語言中獲取矩陣的大小是非常困難的
"date_captured": 拍照的時候
"id"領域是最重要的領域,這是用于"annotations"識別圖像的編號,因此如果我們想識別給定圖像文件的注釋,則必須在"圖像"中檢查相應圖像文檔的“id”,然后在“注釋”中交叉引用它。
在官方COCO數(shù)據(jù)集中"id"與"file_name"相同。需要注意的是,自定義 COCO數(shù)據(jù)集可能不一定是這種情況!這不是強制的規(guī)則,例如由私人照片制成的數(shù)據(jù)集可能具有與沒有共同之處的原始照片名稱"id"。
"categories"部分:
本部分對于對象檢測和分割任務以及對于實例分割任務有點不同。
對象檢測/對象分割:
[
{"supercategory": "person", "id": 1, "name": "person"},
{"supercategory": "vehicle", "id": 2, "name": "bicycle"},
{"supercategory": "vehicle", "id": 3, "name": "car"},
…
{"supercategory": "indoor", "id": 90, "name": "toothbrush"}
]
這些是可以在圖像上檢測到的對象類別("categories"在 COCO 中是類別的另一個名稱,我們可以從監(jiān)督機器學習中了解到)。
每個類別都有一個唯一的"id",它們應該在 [1,number of categories] 范圍內。類別也分為“超類別”,我們可以在程序中使用它們,例如,當我們不關心是自行車、汽車還是卡車時,一般檢測車輛。
實例分割:
[
{"supercategory": "textile", "id": 92, "name": "banner"},
{"supercategory": "textile", "id": 93, "name": "blanket"},
…
{"supercategory": "other", "id": 183, "name": "other"}
]
類別數(shù)從高開始以避免與對象分割沖突,因為有時這些任務可以一起執(zhí)行。從 92 到 182 的 ID 是實際的背景素材,而 ID 183 代表所有其他沒有單獨類的背景紋理。
“annotations”部分:
這是數(shù)據(jù)集最重要的部分,其中包含對特定 COCO 數(shù)據(jù)集的每個任務至關重要的信息。
{
"segmentation":
[[
239.97,
260.24,
222.04,
…
]],
"area": 2765.1486500000005,
"iscrowd": 0,
"image_id": 558840,
"bbox":
[
199.84,
200.46,
77.71,
70.88
],
"category_id": 58,
"id": 156
}
"segmentation":分割掩碼像素列表;這是一個扁平的對列表,因此我們應該采用第一個和第二個值(圖片中的 x 和 y),然后是第三個和第四個值,以獲取坐標;需要注意的是,這些不是圖像索引,因為它們是浮點數(shù)——它們是由 COCO-annotator 等工具從原始像素坐標創(chuàng)建和壓縮的
"area":分割掩碼內的像素數(shù)
"iscrowd":注釋是針對單個對象(值為 0),還是針對彼此靠近的多個對象(值為 1);對于實例分割,此字段始終為 0 并被忽略
"image_id": 'images' 字典中的 'id' 字段;警告:這個值應該用于將圖像與其他字典交叉引用,而不是"id"字段!
"bbox":邊界框,即對象周圍矩形的坐標(左上x,左上y,寬,高);從圖像中提取單個對象非常有用,因為在像 Python 這樣的許多語言中,它可以通過訪問圖像數(shù)組來完成,例如cropped_object = image[bbox[0]:bbox[0] + bbox[2], bbox[1]:bbox[1] + bbox[3]]
"category_id":對象的類,對應"類別"中的"id"字段
"id": 注釋的唯一標識符;警告:這只是注釋ID,這并不指向其他詞典中的特定圖像!
在處理人群圖像 ( "iscrowd": 1) 時,該"segmentation"部分可能會有所不同:
{
"counts": [179,27,392,41,…,55,20],
"size": [426,640]
}
這是因為對于許多像素,明確列出所有像素創(chuàng)建分割掩碼將占用大量空間,相反,COCO使用自定義的運行長度編碼(RLE)壓縮,這是非常有效的,因為分段掩碼是二進制的,僅0和1的RLE可能會將大小減小很多倍。
我們探討了用于最流行任務的COCO數(shù)據(jù)集格式:對象檢測、對象分割和實例分割。COCO官方數(shù)據(jù)集質量高、規(guī)模大,適合初學者項目、生產環(huán)境和最新研究。我希望本文能夠幫助小伙伴理解如何解釋這種格式,并將其用于小伙伴的ML應用程序。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~