
Redis 高可用篇:你管這叫主從架構(gòu)數(shù)據(jù)同步原理?
開篇寄語
“ 問題 = 機(jī)會(huì)。遇到問題的時(shí)候,內(nèi)心其實(shí)是開心的,越大的問題意味著越大的機(jī)會(huì)。 任何事情都是有代價(jià)的,有得必有失,有失必有得,所以不必計(jì)較很多東西,我們只要想清楚自己要做什么,并且想清楚自己愿意為之付出什么代價(jià),然后就放手去做吧! ”
1. 主從復(fù)制概述
“ 65 哥:有了 RDB 和 AOF 再也不怕宕機(jī)丟失數(shù)據(jù)了,但是 Redis 實(shí)例宕機(jī)了怎么實(shí)現(xiàn)高可用呢? ”
“ 65 哥:主從之間的數(shù)據(jù)如何保證一致性呢? ”
讀操作:主、從庫都可以執(zhí)行; 寫操作:主庫先執(zhí)行,之后將寫操作同步到從庫;
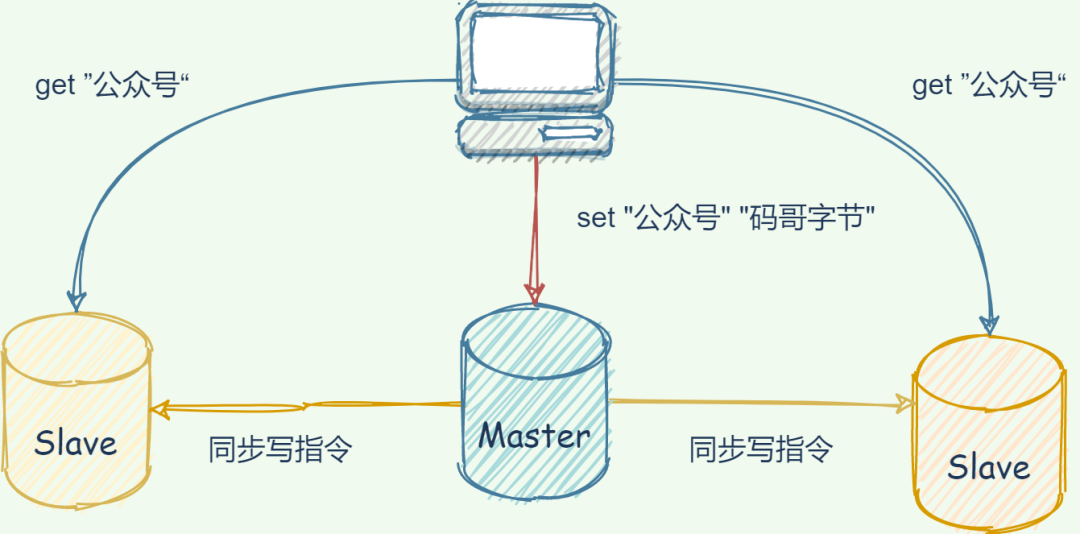
“ 65 哥:為何要采用讀寫分離的方式? ”
“ 65 哥:主從復(fù)制還有其他作用么? ”
故障恢復(fù):當(dāng)主節(jié)點(diǎn)宕機(jī),其他節(jié)點(diǎn)依然可以提供服務(wù); 負(fù)載均衡:Master 節(jié)點(diǎn)提供寫服務(wù),Slave 節(jié)點(diǎn)提供讀服務(wù),分擔(dān)壓力; 高可用基石:是哨兵和 cluster 實(shí)施的基礎(chǔ),是高可用的基石。
2. 搭建主從復(fù)制
“ 65 哥:怎么搭建主從復(fù)制架構(gòu)呀? ”
配置文件 在從服務(wù)器的配置文件中加入 replicaof <masterip> <masterport>啟動(dòng)命令 redis-server 啟動(dòng)命令后面加入 --replicaof <masterip> <masterport>客戶端命令 啟動(dòng)多個(gè) Redis 實(shí)例后,直接通過客戶端執(zhí)行命令: replicaof <masterip> <masterport>,則該 Redis 實(shí)例成為從節(jié)點(diǎn)。
replicaof 172.16.88.1 6379
3. 主從復(fù)制原理
“ 65 哥:主從庫同步是如何完成的呢?主庫數(shù)據(jù)是一次性傳給從庫,還是分批同步?正常運(yùn)行中又怎么同步呢?要是主從庫間的網(wǎng)絡(luò)斷連了,重新連接后數(shù)據(jù)還能保持一致嗎? ”
第一次主從庫全量復(fù)制; 主從正常運(yùn)行期間的同步; 主從庫間網(wǎng)絡(luò)斷開重連同步。
主從庫第一次全量復(fù)制
“ 65 哥:我好暈啊,先從主從庫間第一次同步說起吧。 ”
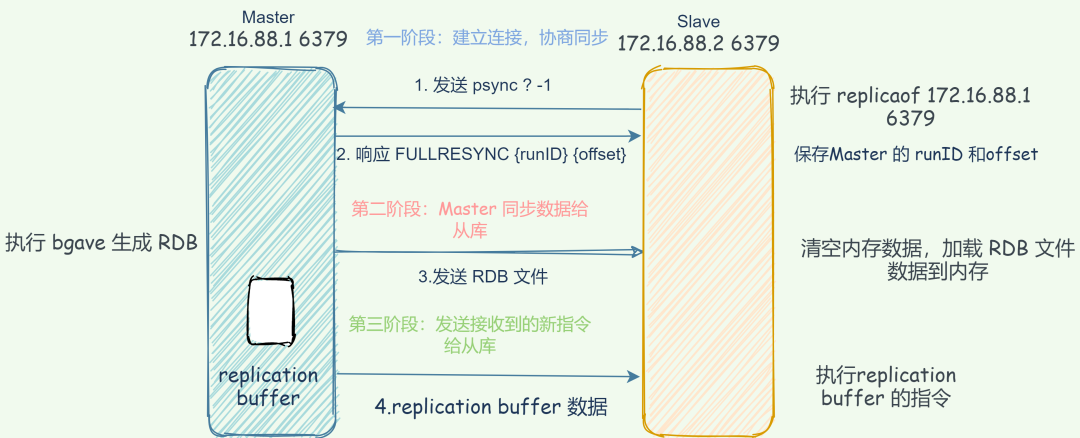
建立連接
“ 65 哥:從庫怎么知道主庫信息并建立連接的呢? ”
replicaof 并發(fā)送 psync 命令,表示要執(zhí)行數(shù)據(jù)同步,主庫收到命令后根據(jù)參數(shù)啟動(dòng)復(fù)制。命令包含了主庫的 runID 和 復(fù)制進(jìn)度 offset 兩個(gè)參數(shù)。runID:每個(gè) Redis 實(shí)例啟動(dòng)都會(huì)自動(dòng)生成一個(gè) 唯一標(biāo)識(shí) ID,第一次主從復(fù)制,還不知道主庫 runID,參數(shù)設(shè)置為 「?」。 offset:第一次復(fù)制設(shè)置為 -1,表示第一次復(fù)制,記錄復(fù)制進(jìn)度偏移量。
主庫同步數(shù)據(jù)給從庫
bgsave命令生成 RDB 文件,并將文件發(fā)送給從庫,同時(shí)主庫為每一個(gè) slave 開辟一塊 replication buffer 緩沖區(qū)記錄從生成 RDB 文件開始收到的所有寫命令。發(fā)送新寫命令到從庫
“ 65 哥:主庫將數(shù)據(jù)同步到從庫過程中,可以正常接受請(qǐng)求么? ”
“ 65 哥:為啥從庫收到 RDB 文件后要清空當(dāng)前數(shù)據(jù)庫? ”
replcaof命令開始和主庫同步前可能保存了其他數(shù)據(jù),防止主從數(shù)據(jù)之間的影響。“ replication buffer 到底是什么玩意? ”
config set client-output-buffer-limit "slave 536870912 536870912 0"
“ 65 哥:主從庫復(fù)制為何不使用 AOF 呢?相比 RDB 來說,丟失的數(shù)據(jù)更少。 ”
RDB 文件是二進(jìn)制文件,網(wǎng)絡(luò)傳輸 RDB 和寫入磁盤的 IO 效率都要比 AOF 高。 從庫進(jìn)行數(shù)據(jù)恢復(fù)的時(shí)候,RDB 的恢復(fù)效率也要高于 AOF。
增量復(fù)制
“ 65 哥:主從庫間的網(wǎng)絡(luò)斷了咋辦?斷開后要重新全量復(fù)制么? ”
repl_backlog_buffer 緩沖區(qū),不管在什么時(shí)候 master 都會(huì)將寫指令操作記錄在 repl_backlog_buffer 中,因?yàn)閮?nèi)存有限, repl_backlog_buffer 是一個(gè)定長的環(huán)形數(shù)組,如果數(shù)組內(nèi)容滿了,就會(huì)從頭開始覆蓋前面的內(nèi)容。master_repl_offset記錄自己寫到的位置偏移量,slave 則使用 slave_repl_offset記錄已經(jīng)讀取到的偏移量。repl_backlog_buffer 的已復(fù)制的偏移量 slave_repl_offset 也在不斷增加。master_repl_offset會(huì)大于 slave_repl_offset。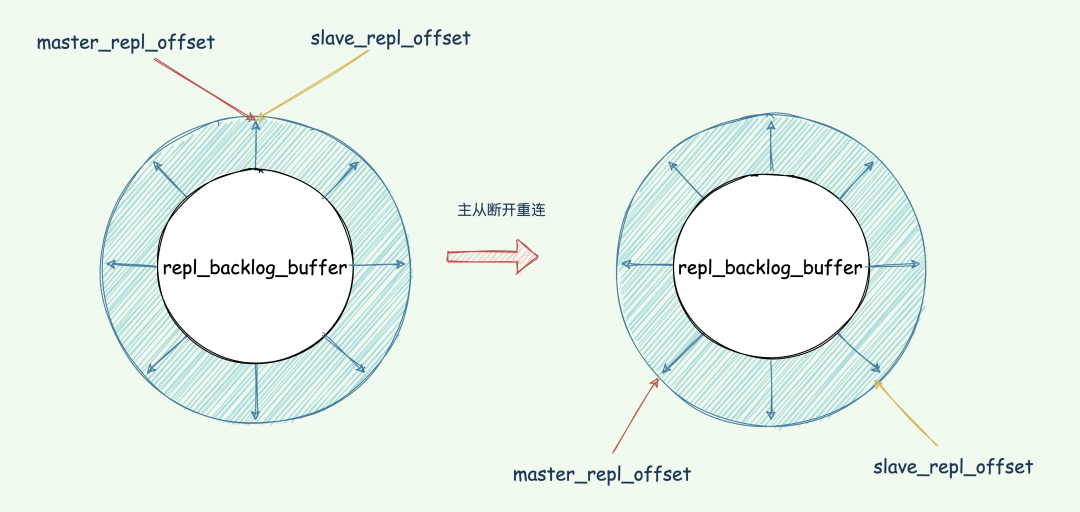
runID,slave_repl_offset發(fā)送給 master。master_repl_offset與 slave_repl_offset之間的命令同步給從庫即可。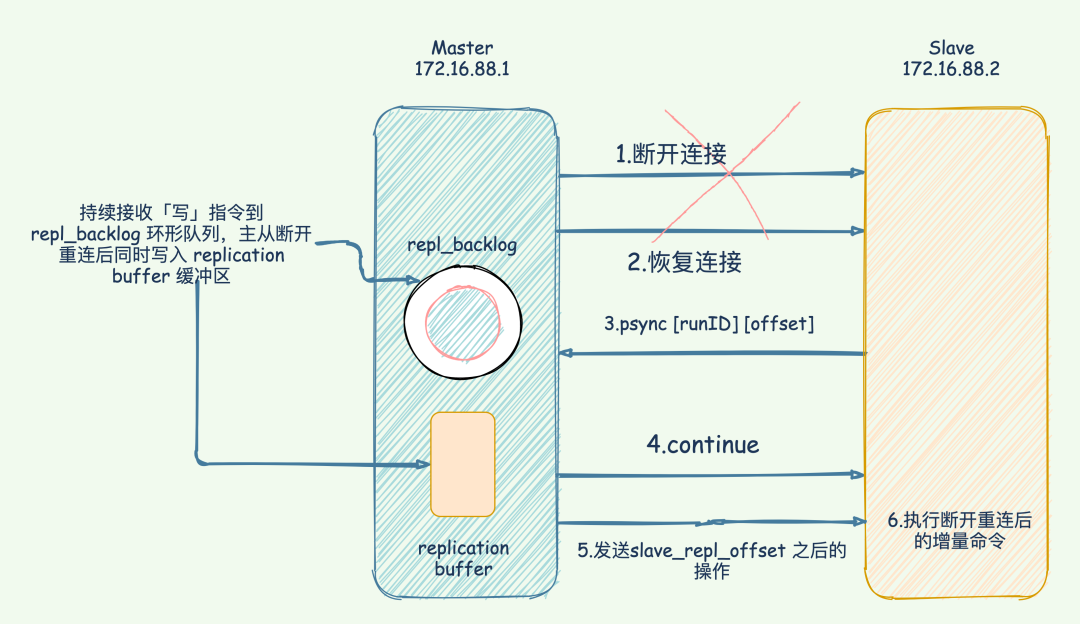
“ 65 哥:repl_backlog_buffer 太小的話從庫還沒讀取到就被 Master 的新寫操作覆蓋了咋辦? ”
repl_backlog_buffer = second * write_size_per_second
second:從服務(wù)器斷開重連主服務(wù)器所需的平均時(shí)間; write_size_per_second:master 平均每秒產(chǎn)生的命令數(shù)據(jù)量大小(寫命令和數(shù)據(jù)大小總和);
2 * second * write_size_per_second,這樣可以保證絕大部分?jǐn)嗑€情況都能用部分重同步來處理。基于長連接的命令傳播
“ 65 哥:完成全量同步后,正常運(yùn)行過程如何同步呢? ”
主->從:PING
從->主:REPLCONF ACK
REPLCONF ACK <replication_offset>
檢測(cè)主從服務(wù)器的網(wǎng)絡(luò)連接狀態(tài)。 輔助實(shí)現(xiàn) min-slaves 選項(xiàng)。 檢測(cè)命令丟失, 從節(jié)點(diǎn)發(fā)送了自身的 slave_replication_offset,主節(jié)點(diǎn)會(huì)用自己的 master_replication_offset 對(duì)比,如果從節(jié)點(diǎn)數(shù)據(jù)缺失,主節(jié)點(diǎn)會(huì)從 repl_backlog_buffer緩沖區(qū)中找到并推送缺失的數(shù)據(jù)。注意,offset 和 repl_backlog_buffer 緩沖區(qū),不僅可以用于部分復(fù)制,也可以用于處理命令丟失等情形;區(qū)別在于前者是在斷線重連后進(jìn)行的,而后者是在主從節(jié)點(diǎn)沒有斷線的情況下進(jìn)行的。
如何確定執(zhí)行全量同步還是部分同步?
psync的執(zhí)行: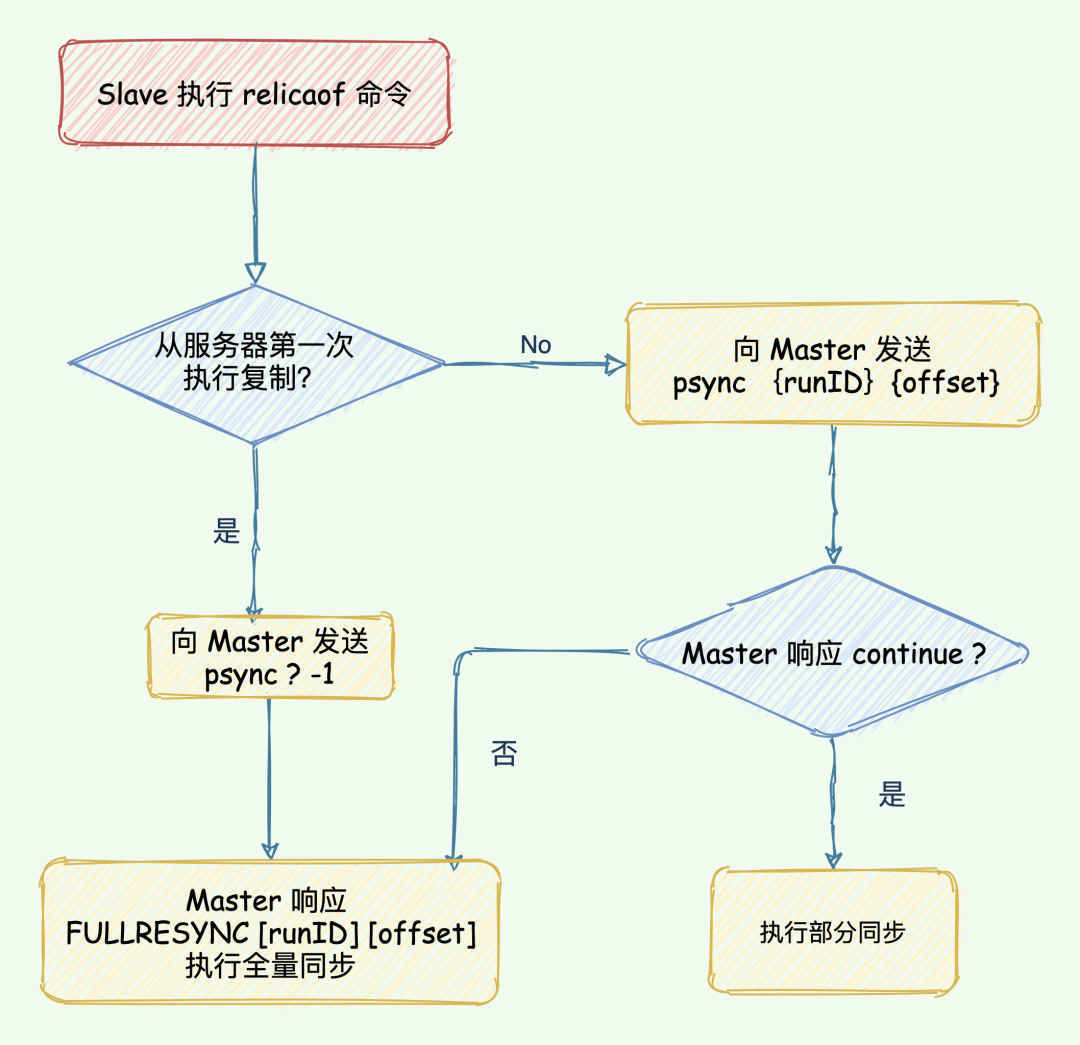
從節(jié)點(diǎn)根據(jù)當(dāng)前狀態(tài),發(fā)送 psync命令給 master:如果從節(jié)點(diǎn)從未執(zhí)行過 replicaof,則從節(jié)點(diǎn)發(fā)送psync ? -1,向主節(jié)點(diǎn)發(fā)送全量復(fù)制請(qǐng)求;如果從節(jié)點(diǎn)之前執(zhí)行過 replicaof則發(fā)送psync <runID> <offset>, runID 是上次復(fù)制保存的主節(jié)點(diǎn) runID,offset 是上次復(fù)制截至?xí)r從節(jié)點(diǎn)保存的復(fù)制偏移量。主節(jié)點(diǎn)根據(jù)接受到的 psync命令和當(dāng)前服務(wù)器狀態(tài),決定執(zhí)行全量復(fù)制還是部分復(fù)制:runID 與從節(jié)點(diǎn)發(fā)送的 runID 相同,且從節(jié)點(diǎn)發(fā)送的 slave_repl_offset之后的數(shù)據(jù)在repl_backlog_buffer緩沖區(qū)中都存在,則回復(fù)CONTINUE,表示將進(jìn)行部分復(fù)制,從節(jié)點(diǎn)等待主節(jié)點(diǎn)發(fā)送其缺少的數(shù)據(jù)即可;runID 與從節(jié)點(diǎn)發(fā)送的 runID 不同,或者從節(jié)點(diǎn)發(fā)送的 slave_repl_offset 之后的數(shù)據(jù)已不在主節(jié)點(diǎn)的 repl_backlog_buffer緩沖區(qū)中 (在隊(duì)列中被擠出了),則回復(fù)從節(jié)點(diǎn)FULLRESYNC <runid> <offset>,表示要進(jìn)行全量復(fù)制,其中 runID 表示主節(jié)點(diǎn)當(dāng)前的 runID,offset 表示主節(jié)點(diǎn)當(dāng)前的 offset,從節(jié)點(diǎn)保存這兩個(gè)值,以備使用。
repl_backlog_buffer的 slave_repl_offset 位置上的數(shù)據(jù)已經(jīng)被覆蓋掉了,此時(shí)從庫和主庫間將進(jìn)行全量復(fù)制。slave_repl_offset,每個(gè)從庫的復(fù)制進(jìn)度也不一定相同。slave_repl_offset發(fā)給主庫,主庫會(huì)根據(jù)從庫各自的復(fù)制進(jìn)度,來決定這個(gè)從庫可以進(jìn)行增量復(fù)制,還是全量復(fù)制。replication buffer 對(duì)應(yīng)于每個(gè) slave,通過 config set client-output-buffer-limit slave設(shè)置。repl_backlog_buffer是一個(gè)環(huán)形緩沖區(qū),整個(gè) master 進(jìn)程中只會(huì)存在一個(gè),所有的 slave 公用。repl_backlog 的大小通過 repl-backlog-size 參數(shù)設(shè)置,默認(rèn)大小是 1M,其大小可以根據(jù)每秒產(chǎn)生的命令、(master 執(zhí)行 rdb bgsave) +( master 發(fā)送 rdb 到 slave) + (slave load rdb 文件)時(shí)間之和來估算積壓緩沖區(qū)的大小,repl-backlog-size 值不小于這兩者的乘積。
replication buffer 是主從庫在進(jìn)行全量復(fù)制時(shí),主庫上用于和從庫連接的客戶端的 buffer,而 repl_backlog_buffer 是為了支持從庫增量復(fù)制,主庫上用于持續(xù)保存寫操作的一塊專用 buffer。repl_backlog_buffer是一塊專用 buffer,在 Redis 服務(wù)器啟動(dòng)后,開始一直接收寫操作命令,這是所有從庫共享的。主庫和從庫會(huì)各自記錄自己的復(fù)制進(jìn)度,所以,不同的從庫在進(jìn)行恢復(fù)時(shí),會(huì)把自己的復(fù)制進(jìn)度(slave_repl_offset)發(fā)給主庫,主庫就可以和它獨(dú)立同步。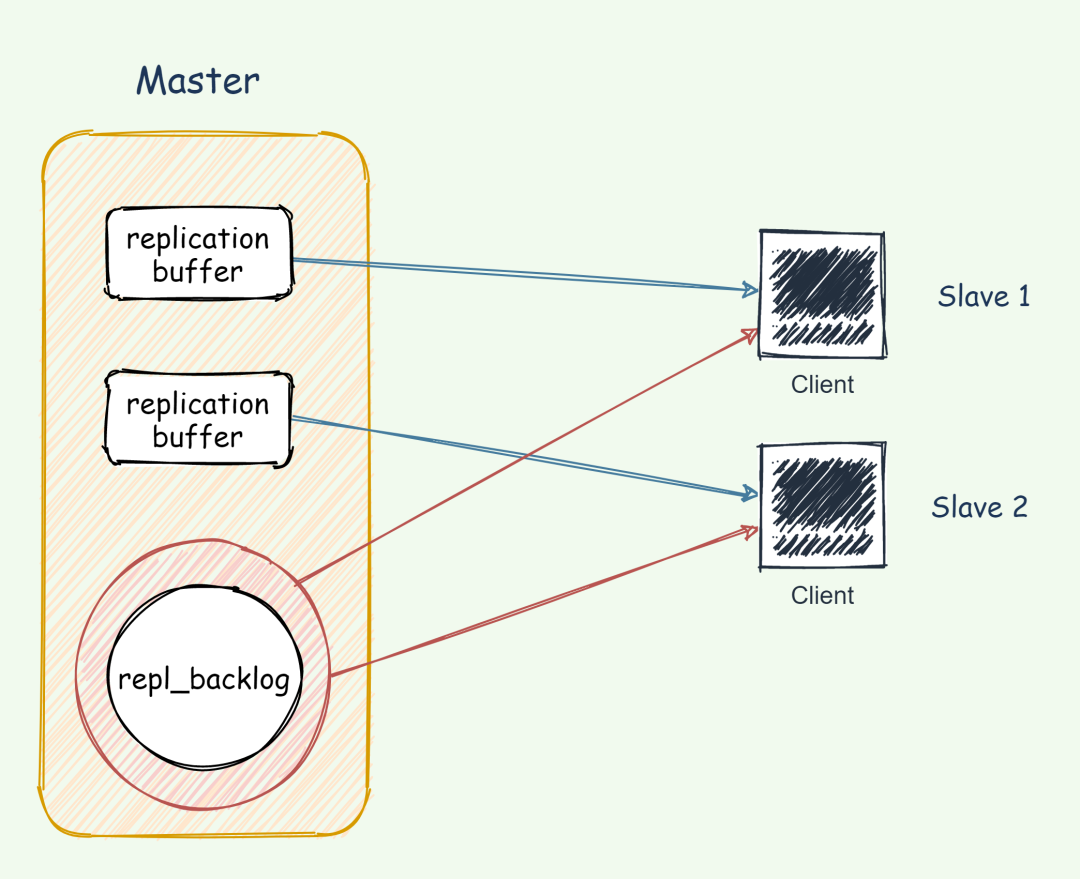
4. 主從應(yīng)用問題
4.1 讀寫分離的問題
“ 65 哥:主從復(fù)制的場(chǎng)景下,從節(jié)點(diǎn)會(huì)刪除過期數(shù)據(jù)么? ”
惰性刪除:當(dāng)客戶端查詢對(duì)應(yīng)的數(shù)據(jù)時(shí),Redis 判斷該數(shù)據(jù)是否過期,過期則刪除。 定期刪除:Redis 通過定時(shí)任務(wù)刪除過期數(shù)據(jù)。
“ 65 哥:那客戶端通過從節(jié)點(diǎn)讀取數(shù)據(jù)會(huì)不會(huì)讀取到過期數(shù)據(jù)? ”
4.2 單機(jī)內(nèi)存大小限制
總結(jié)
主從復(fù)制的作用:AOF 和 RDB 二進(jìn)制文件保證了宕機(jī)快速恢復(fù)數(shù)據(jù),盡可能的防止丟失數(shù)據(jù)。但是宕機(jī)后依然無法提供服務(wù),所以便演化出主從架構(gòu)、讀寫分離。 主從復(fù)制原理:連接建立階段、數(shù)據(jù)同步階段、命令傳播階段;數(shù)據(jù)同步階段又分為 全量復(fù)制和部分復(fù)制;命令傳播階段主從節(jié)點(diǎn)之間有 PING 和 REPLCONF ACK 命令互相進(jìn)行心跳檢測(cè)。 主從復(fù)制雖然解決或緩解了數(shù)據(jù)冗余、故障恢復(fù)、讀負(fù)載均衡等問題,但其缺陷仍很明顯:故障恢復(fù)無法自動(dòng)化;寫操作無法負(fù)載均衡;存儲(chǔ)能力受到單機(jī)的限制;這些問題的解決,需要哨兵和集群的幫助,我將在后面的文章中介紹,歡迎關(guān)注。
“ 65 哥:碼哥你的圖畫的真好看,內(nèi)容好,跟著你的文章我收獲了很多,我要收藏、點(diǎn)贊、在看和分享。讓更多的優(yōu)秀開發(fā)者看到共同進(jìn)步! ”
參考資料:
[1] redis 設(shè)計(jì)與實(shí)現(xiàn)(黃健宏)
[2] redis replication (http://redis.io/topics/replication)
[3] designing redis replication partial resync (http://antirez.com/news/31)
(4) Redis 核心技術(shù)與實(shí)戰(zhàn)(https://time.geekbang.org/column/intro/329)
有道無術(shù),術(shù)可成;有術(shù)無道,止于術(shù)
歡迎大家關(guān)注Java之道公眾號(hào)
好文章,我在看??
評(píng)論
圖片
表情