導(dǎo)讀:本文為大家介紹了降維的概念及降維技術(shù)主成分分析(PCA)在特征工程中的應(yīng)用。
來(lái)源:數(shù)據(jù)派THU(ID:DatapiTHU)
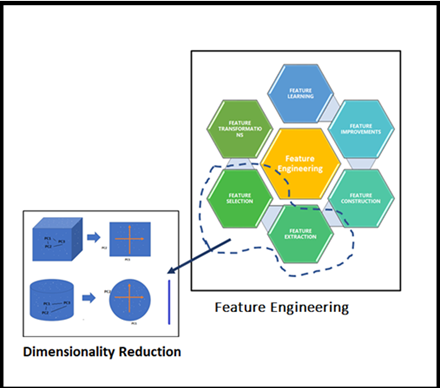
你好!我喜歡分享我作為一個(gè)初級(jí)數(shù)據(jù)科學(xué)家的有趣經(jīng)歷,我甚至可以說(shuō)在那時(shí)我在這個(gè)數(shù)據(jù)科學(xué)領(lǐng)域只是一個(gè)初學(xué)者。有個(gè)客戶來(lái)找我們要用機(jī)器學(xué)習(xí)來(lái)實(shí)現(xiàn)他們的問題,不管以無(wú)監(jiān)督形式還是有監(jiān)督形式。我本以為這將是一如既往的執(zhí)行模式和流程,因?yàn)楦鶕?jù)我小規(guī)模實(shí)現(xiàn)或訓(xùn)練的經(jīng)驗(yàn),我們往往使用25~30個(gè)特征。我們用它來(lái)預(yù)測(cè)、分類或聚類數(shù)據(jù)集,并分享結(jié)果。但這一次,他們提出了成千上萬(wàn)的特征,但我有點(diǎn)驚訝和害怕,開始暈頭轉(zhuǎn)向。與此同時(shí),我的高級(jí)數(shù)據(jù)科學(xué)家把團(tuán)隊(duì)里的每個(gè)人都帶到了會(huì)議室。 我的高級(jí)數(shù)據(jù)科學(xué)家(Senior Data Scientist ,Sr. DS)創(chuàng)造了新單詞,對(duì)我們來(lái)說(shuō),這只不過是降維或維度災(zāi)難的問題,所有的初學(xué)者都認(rèn)為他將解釋物理層面的一些東西,因?yàn)槲覀儙缀醪挥浀梦覀兣嘤?xùn)項(xiàng)目中遇到過這類情況。接下來(lái),他開始在畫板上畫(見圖1)。當(dāng)我們開始看1-D, 2-D時(shí)我們很舒服,但3-D時(shí),我們開始暈頭轉(zhuǎn)向。
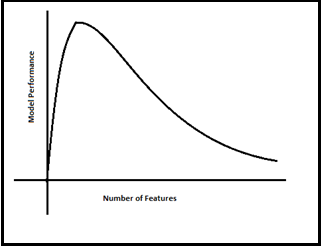
Sr. DS繼續(xù)他的講座,所有這些示例圖片都是顯著的特征,我們可以在實(shí)時(shí)場(chǎng)景中使用它們,許多機(jī)器學(xué)習(xí)問題涉及數(shù)以千計(jì)的特征,所以我們最終訓(xùn)練這些模型的速度會(huì)變得非常慢,以至于不能很好地解決業(yè)務(wù)問題,并且這時(shí)候我們不能凍結(jié)模型,這種情況就是所謂的“維度災(zāi)難”引起的。然后,我們開始思考一個(gè)問題,我們應(yīng)該如何處理這個(gè)“維度災(zāi)難”問題。他深吸了一口氣,繼續(xù)以自己的風(fēng)格分享自己的經(jīng)歷。他從一個(gè)簡(jiǎn)單的定義開始,如下:我們可以說(shuō),我們的數(shù)據(jù)集中特征的數(shù)量被稱為其維數(shù)。降維是對(duì)給定數(shù)據(jù)集進(jìn)行(特征)降維的過程。也就是說(shuō),如果您的數(shù)據(jù)集有100列/特性,并將列數(shù)減少到了20-25列。簡(jiǎn)單地說(shuō),您是在二維空間中將柱面/球體轉(zhuǎn)換成圓或立方體,如下圖所示。他在下面清楚地描繪了模型性能和特征(維度)數(shù)量之間的關(guān)系。隨著特征數(shù)量的增加,數(shù)據(jù)點(diǎn)的數(shù)量也成比例地增加。更直接的說(shuō)法是越多的特征會(huì)帶來(lái)更多的數(shù)據(jù)樣本,所以我們已經(jīng)表示了所有的特征組合及其值。現(xiàn)在房間里的每個(gè)人都從一個(gè)更高的角度領(lǐng)會(huì)到了什么是“維度災(zāi)難”。突然,一個(gè)團(tuán)隊(duì)成員問他能否告訴我們?cè)诮o定數(shù)據(jù)集上進(jìn)行特征降維的好處。我們的前輩并沒有停止進(jìn)一步分享他淵博的知識(shí)。他繼續(xù)如下。如果我們進(jìn)行降維,會(huì)有很多好處。- 它有助于消除冗余的特征和噪聲誤差因素,最終增強(qiáng)給定數(shù)據(jù)集的可視化。
- 由于降低了維度,可以表現(xiàn)出優(yōu)秀的內(nèi)存管理。
- 通過從數(shù)據(jù)集中刪除不必要的特征列表來(lái)選擇正確的特征,從而提高模型的性能。
- 當(dāng)然,更少的維度(強(qiáng)制性的維度列表)需要更少的計(jì)算效率,更快地訓(xùn)練模型,提高模型的準(zhǔn)確性。
- 大大降低了整個(gè)模型及其性能的復(fù)雜性和過擬合。
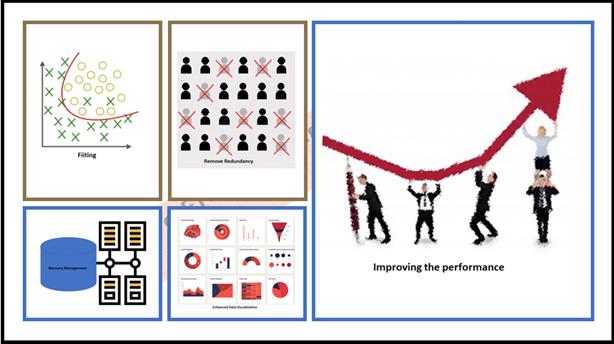
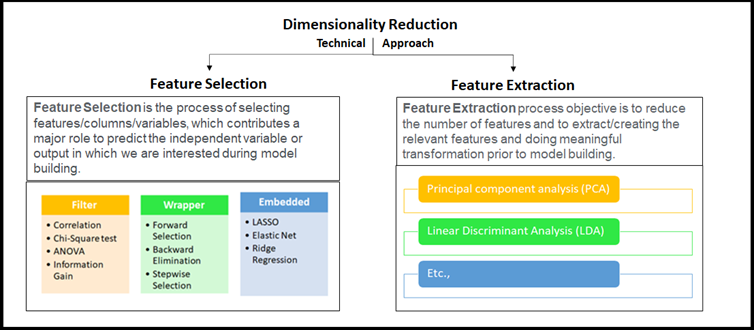
是的!這是一個(gè)令人敬畏的,魯棒的和動(dòng)態(tài)的“降維”。現(xiàn)在,我可以將降維的優(yōu)點(diǎn)總結(jié)如下圖所示。希望對(duì)你也有幫助。當(dāng)然,下一步是什么!我們接下來(lái)探討有哪些技術(shù)可以用于降維。我們的Sr. DS對(duì)數(shù)據(jù)科學(xué)領(lǐng)域中任何可能的技術(shù)非常感興趣,他繼續(xù)他的解釋。降維的方法被籠統(tǒng)地分為兩種,如前面提到,考慮選擇最佳擬合特征或刪除給定高維數(shù)數(shù)據(jù)集中不太重要的特征。一些高級(jí)技術(shù)通常被稱為特征選擇或特征提取,基本上,這是特征工程的一部分。他把這些點(diǎn)講得很清楚。他帶領(lǐng)我們進(jìn)一步深入概念,理解在高維數(shù)據(jù)集上應(yīng)用“降維”的重點(diǎn)。一旦我們看到下圖,我們就可以將特征工程和降維聯(lián)系起來(lái)。看看這個(gè)圖,我們Sr. DS的降維的精髓就在里面!每個(gè)人都想知道如何通過簡(jiǎn)單的編碼來(lái)使用Python庫(kù)來(lái)使用這些降維技術(shù)。我們的Sr. DS要求我拿來(lái)彩色筆和板擦。Sr. DS拿起新的藍(lán)筆,開始用一個(gè)簡(jiǎn)單的例子來(lái)解釋PCA,如下所示,在此之前,他解釋了什么是降維PCA。主成分分析(PCA):主成分分析是一種對(duì)給定數(shù)據(jù)集進(jìn)行降維的技術(shù),在信息損失可忽略的情況下,增加了可解釋性。這里變量的數(shù)量在減少,因此進(jìn)一步的分析更簡(jiǎn)單。它把一組相關(guān)的變量轉(zhuǎn)換成一組不相關(guān)的變量。用于機(jī)器學(xué)習(xí)預(yù)測(cè)建模。他建議我們通過特征向量,特征值分析。他取了熟悉的wine.csv來(lái)快速分析。 # Import all the necessary packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn import metrics
%matplotlib inline
import matplotlib.pyplot as plt
%matplotlib inline
wq_dataset = pd.read_csv('winequality.csv')
1. 對(duì)于給定數(shù)據(jù)集的數(shù)據(jù)分析wq_dataset.isnull().any()
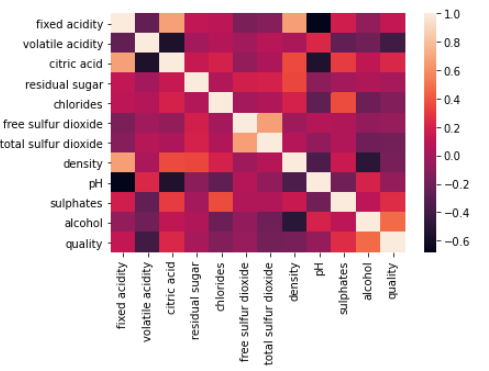
在給定的數(shù)據(jù)集中沒有空值,很好,我們很幸運(yùn)。correlations = wq_dataset.corr()['quality'].drop('quality')
print(correlations)
3. 使用熱力圖進(jìn)行相關(guān)性表示sns.heatmap(wq_dataset.corr())
plt.show()
x = wq_dataset[features]
y = wq_dataset['quality']
[‘fixed acidity’, ‘volatile acidity’, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘a(chǎn)lcohol’]
4. 使用train_test_split創(chuàng)建訓(xùn)練和測(cè)試集x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=3)
print('Traning data shape:', x_train.shape)
print('Testing data shape:', x_test.shape)
Traning data shape: (1199, 8)
Testing data shape: (400, 8)
6. PCA降維實(shí)現(xiàn)(2列)from sklearn.decomposition import PCA
pca_wins = PCA(n_components=2)
principalComponents_wins = pca_wins.fit_transform(x)
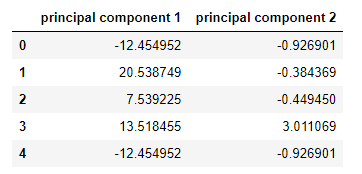
pcs_wins_df = pd.DataFrame(data = principalComponents_wins, columns = ['principal component 1', 'principal component 2'])
當(dāng)我們看到上面兩個(gè)新的列名和值時(shí),我們都感到驚訝,我們問‘fixed acidity’, ‘volatile acidity, ‘citric acid’, ‘chlorides’, ‘total sulfur dioxide’, ‘density’, ‘sulphates’, ‘a(chǎn)lcohol’等列會(huì)發(fā)生什么變化。Sr. DS說(shuō)所有的都沒有了,在應(yīng)用了PCA對(duì)給定數(shù)據(jù)進(jìn)行降維后,我們現(xiàn)在只有兩列特征值,然后我們將實(shí)現(xiàn)很少的模型,這將是正常的方式。他提到了一個(gè)關(guān)鍵詞“每一個(gè)主成分的變化量”。這是由主成分解釋的方差的分?jǐn)?shù)是主成分的方差和總方差之間的比率。print('Explained variation per principal component: {}'.format(pca_wins.explained_variance_ratio_))
Explained variation per principal component: [0.99615166 0.00278501]
這些模型的精度更好,每個(gè)模型之間的差異很小,但他提到這是為了實(shí)現(xiàn)PCA。房間里的每個(gè)人都覺得我們完成了一次很棒的挑戰(zhàn)。他建議我們動(dòng)手嘗試其他的降維技術(shù)。好了,朋友們!感謝你的時(shí)間,希望我能在這里以正確的方式講述我在降維技術(shù)方面的學(xué)習(xí)經(jīng)驗(yàn),我相信這將有助于在機(jī)器學(xué)習(xí)問題陳述中繼續(xù)處理復(fù)雜數(shù)據(jù)集的旅程。加油!Dimensionality Reduction a Descry for Data Scientisthttps://www.analyticsvidhya.com/blog/2021/04/dimensionality-reduction-a-descry-for-data-scientist/本文作為數(shù)據(jù)科學(xué)博客馬拉松的一部分發(fā)表。https://datahack.analyticsvidhya.com/contest/data-science-blogathon-7/關(guān)于譯者:王可汗,清華大學(xué)機(jī)械工程系直博生在讀。曾經(jīng)有著物理專業(yè)的知識(shí)背景,研究生期間對(duì)數(shù)據(jù)科學(xué)產(chǎn)生濃厚興趣,對(duì)機(jī)器學(xué)習(xí)AI充滿好奇。期待著在科研道路上,人工智能與機(jī)械工程、計(jì)算物理碰撞出別樣的火花。希望結(jié)交朋友分享更多數(shù)據(jù)科學(xué)的故事,用數(shù)據(jù)科學(xué)的思維看待世界。
延伸閱讀《Python數(shù)據(jù)分析與數(shù)據(jù)化運(yùn)營(yíng)》直播主題:企業(yè)數(shù)據(jù)價(jià)值現(xiàn)狀及數(shù)據(jù)分析師的價(jià)值提升
直播時(shí)間:4月24日19:00-20:00
主講人:宋天龍,大數(shù)據(jù)技術(shù)專家,觸脈咨詢合伙人兼副總裁,擅長(zhǎng)數(shù)據(jù)挖掘、建模、分析與運(yùn)營(yíng),《Python數(shù)據(jù)分析與數(shù)據(jù)化運(yùn)營(yíng)》作者。
直播介紹:
數(shù)據(jù)在企業(yè)中的真實(shí)定位
是什么導(dǎo)致了數(shù)據(jù)價(jià)值沒有產(chǎn)生理想效果
數(shù)據(jù)分析師改善客觀因素的6種途徑
數(shù)據(jù)分析師改善主觀因素的6個(gè)要素
數(shù)據(jù)分析師如何有效管理“有效建議”
在公眾號(hào)對(duì)話框輸入以下關(guān)鍵詞PPT | 讀書 | 書單 | 硬核 | 干貨 | 講明白 | 神操作大數(shù)據(jù) | 云計(jì)算 | 數(shù)據(jù)庫(kù) | Python | 爬蟲 | 可視化AI | 人工智能 | 機(jī)器學(xué)習(xí) | 深度學(xué)習(xí) | NLP5G | 中臺(tái) | 用戶畫像 | 1024 | 數(shù)學(xué) | 算法 | 數(shù)字孿生據(jù)統(tǒng)計(jì),99%的大咖都關(guān)注了這個(gè)公眾號(hào)