
【Python】用于在 Python 中處理 PDF 文件的 PyPDF2 庫
編譯 | Flin
來源 | analyticsvidhya
介紹
PDF 代表便攜式文檔格式。它使用 .pdf 擴(kuò)展名。這種類型的文件主要用于共享目的。它們不能被修改,從而完整地保留了文件的格式。
因此,它們可以輕松共享和下載。它們用于閱讀而不是編輯。它們?cè)讵?dú)立于硬件、軟件和操作系統(tǒng)打開的任何設(shè)備上看起來都相似。因此,它們是最廣泛使用的格式。它是由Adobe發(fā)明的。現(xiàn)在是國際標(biāo)準(zhǔn)化組織 (ISO)的開放標(biāo)準(zhǔn)。
在本教程中,我們將學(xué)習(xí)如何在 Python 中處理 PDF 文件。將涵蓋以下主題:
如何從 PDF 文件中提取文本。
如何旋轉(zhuǎn) PDF 文件的頁面。
如何從 PDF 文件中提取文檔信息。
如何從 PDF 文件中拆分頁面。
如何合并 PDF 文件的頁面。
如何加密PDF文件。
如何為 PDF 文件添加水印。
Python 中 PDF 的一些常用庫
有許多庫可免費(fèi)用于處理 PDF:
PDFMiner:它是一個(gè)用于從PDF中提取文本的開源工具。它用于對(duì)數(shù)據(jù)進(jìn)行分析。它也可以用作 PDF 轉(zhuǎn)換器或 PDF 解析器。
PDFQuery:它是一個(gè)圍繞 PDFMiner、Ixml 和 PyQuery 的輕量級(jí) Python 包裝器。它是一個(gè)快速、用戶友好的 PDF 抓取庫。
Tabula.py:它是tabula.java的 Python 包裝器。它將 PDF 文件轉(zhuǎn)換為 Pandas 的數(shù)據(jù)框,并且所有數(shù)據(jù)操作都可以在數(shù)據(jù)框上執(zhí)行。
Xpdf : 它允許將 PDF 轉(zhuǎn)換為文本。
pdflib:它是 poppler 庫的擴(kuò)展,其中包含 python 綁定。
Slate:它是一個(gè)基于PDFMiner 的Python 包,用于從PDF 中提取文本。
PyPDF2:它是一個(gè) Python 庫,用于對(duì) PDF 文件執(zhí)行主要任務(wù),例如提取文檔特定信息、合并 PDF 文件、拆分 PDF 文件的頁面、為文件添加水印、加密和解密 PDF文件等。
我們將在本教程中使用 PyPDF2 庫。它是一個(gè)純 python 庫,因此它可以在任何平臺(tái)上運(yùn)行,而無需對(duì)任何外部庫產(chǎn)生任何與平臺(tái)相關(guān)的依賴。
安裝 PyPDF2 庫
要安裝 PyPDF2,請(qǐng)?jiān)诿钐崾痉袕?fù)制以下命令并運(yùn)行:
pip?install?PyPDF2
獲取文檔詳細(xì)信息
PyPDF2 提供有關(guān) PDF 文檔的元數(shù)據(jù)。這可能是有關(guān) PDF 文件的有用信息。可以直接獲得文檔作者、標(biāo)題、制作人、主題等信息。
.jpg)
要提取上述信息,請(qǐng)運(yùn)行以下代碼:
from?PyPDF2?import?PdfFileReader
pdf_path=r"C:UsersDellDesktopTesting?Tesseractexample.pdf"
with?open(pdf_path,?'rb')?as?f:
????????pdf?=?PdfFileReader(f)
????????information?=?pdf.getDocumentInfo()
????????number_of_pages?=?pdf.getNumPages()
????????print(information)
上述代碼的輸出如下:

讓我們格式化輸出:
print("Author"?+':?'?+?information.author)
print("Creator"?+':?'?+?information.creator)
print("Producer"?+':?'?+?information.producer)

從 PDF 中提取文本
為了提取文本,我們將讀取文件并創(chuàng)建文件的 PDF 對(duì)象。
#?creating?a?pdf?file?object
pdfFileObject?=?open(pdf_path,?'rb')
然后我們將創(chuàng)建一個(gè) PDFReader 類對(duì)象并將 PDF 文件對(duì)象傳遞給它。
# 創(chuàng)建一個(gè)pdf閱讀器對(duì)象
pdfReader?=?PyPDF2.PdfFileReader(pdfFileObject)
最后,我們將提取每個(gè)頁面并連接每個(gè)頁面的文本。
text=''
for?i?in?range(0,pdfReader.numPages):
????#?creating?a?page?object
????pageObj?=?pdfReader.getPage(i)
????#?extracting?text?from?page
????text=text+pageObj.extractText()
print(text)
輸出文本如下:
旋轉(zhuǎn) PDF 的頁面
要旋轉(zhuǎn) PDF 文件的頁面并將其另存為另一個(gè)文件,請(qǐng)復(fù)制以下代碼并運(yùn)行它。
pdf_read?=?PdfFileReader(r"C:UsersDellDesktopstory.pdf")
pdf_write?=?PdfFileWriter()
#?Rotate?page?90?degrees?to?the?right
page1?=?pdf_read.getPage(0).rotateClockwise(90)
pdf_write.addPage(page1)
with?open(r'C:UsersDellDesktoprotate_pages.pdf',?'wb')?as?fh:
????pdf_write.write(fh)

在 Python 中合并 PDF 文件
我們還可以使用以下命令合并兩個(gè)或多個(gè) PDF 文件:
pdf_read = PdfFileReader(r”C:UsersDellDesktopstory.pdf”)
pdf_write?=?PdfFileWriter()
#?Rotate?page?90?degrees?to?the?right
page1?=?pdf_read.getPage(0).rotateClockwise(90)
pdf_write.addPage(page1)
with?open(r'C:UsersDellDesktoprotate_pages.pdf',?'wb')?as?fh:
????pdf_write.write(fh)
輸出PDF如下所示:

拆分PDF頁面
我們可以將 PDF 拆分為單獨(dú)的頁面,然后將它們?cè)俅伪4鏋?PDF。
fname?=?os.path.splitext(os.path.basename(pdf_path))[0]
????for?page?in?range(pdf.getNumPages()):
????????pdfwrite?=?PdfFileWriter()
????????pdfwrite.addPage(pdf.getPage(page))
????????outputfilename?=?'{}_page_{}.pdf'.format(
????????????fname,?page+1)
????????with?open(outputfilename,?'wb')?as?out:
????????????pdfwrite.write(out)
????????print('Created:?{}'.format(outputfilename))
pdf?=?PdfFileReader(pdf_path)
加密 PDF 文件
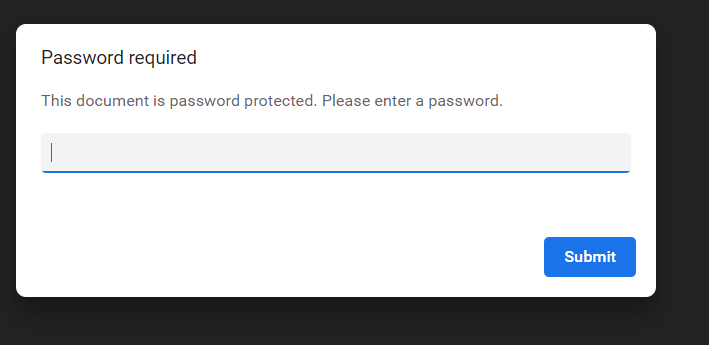
加密 PDF 文件意味著向文件添加密碼。每次打開文件時(shí),它都會(huì)提示輸入文件的密碼。它允許對(duì)內(nèi)容進(jìn)行密碼保護(hù)。出現(xiàn)以下彈出窗口:
我們可以使用以下代碼:
for?page?in?range(pdf.getNumPages()):
????????pdfwrite.addPage(pdf.getPage(page))
????pdfwrite.encrypt(user_pwd=password,?owner_pwd=None,
??????????????????????use_128bit=True)
????with?open(outputpdf,?'wb')?as?fh:
????????pdfwrite.write(fh)
為 PDF 文件添加水印
水印是出現(xiàn)在每一頁上的識(shí)別圖像或圖案。它可以是公司徽標(biāo)或任何要反映在每個(gè)頁面上的重要信息。
要為 PDF 的每一頁添加水印,請(qǐng)復(fù)制以下代碼并運(yùn)行。
originalfile?=?r"C:UsersDellDesktopTesting?Tesseractexample.pdf"
watermark?=?r"C:UsersDellDesktopTesting?Tesseractwatermark.pdf"
watermarkedfile?=?r"C:UsersDellDesktopTesting?Tesseractwatermarkedfile.pdf"
watermark?=?PdfFileReader(watermark)
watermarkpage?=?watermark.getPage(0)
pdf?=?PdfFileReader(originalfile)
pdfwrite?=?PdfFileWriter()
for?page?in?range(pdf.getNumPages()):
????pdfpage?=?pdf.getPage(page)
????pdfpage.mergePage(watermarkpage)
????pdfwrite.addPage(pdfpage)
with?open(watermarkedfile,?'wb')?as?fh:
????pdfwrite.write(fh)
上面的代碼讀取兩個(gè)文件——輸入文件和水印。然后在閱讀每一頁后,它將水印附加到每一頁并將新文件保存在同一位置。

尾注
正如我們?cè)谏厦婵吹降模锌梢栽?PDF 文件中想到的操作都可以使用 PyPDF2 庫在 Python 中輕松執(zhí)行。它純粹是用 Python 編寫的。因此它是完全獨(dú)立于平臺(tái)的。它易于使用并提供了極大的靈活性。
圖片來源
圖 1:https://monkeypen.com/pages/free-childrens-books
往期精彩回顧 本站qq群554839127,加入微信群請(qǐng)掃碼: