
深度詳解ResNet到底在解決一個(gè)什么問(wèn)題?
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

https://www.zhihu.com/question/64494691
本文僅作為學(xué)術(shù)分享,如果侵權(quán),會(huì)刪文處理
最近看到不少ResNet的變體,比如ResNeSt、IResNet等。雖然ResNet發(fā)布于2015年,但目前仍有大量CV任務(wù)用其作為backbone。
截止2020年5月1日,ResNet的引用量已達(dá)到44224(數(shù)據(jù)來(lái)自谷歌學(xué)術(shù)),本文就來(lái)深入探討一下強(qiáng)悍的ResNet。

既然可以通過(guò)初試化和歸一化(BN層)解決梯度彌散或爆炸的問(wèn)題,那Resnet提出的那條通路是在解決什么問(wèn)題呢?
在He的原文中有提到是解決深層網(wǎng)絡(luò)的一種退化問(wèn)題,但并明確說(shuō)明是什么問(wèn)題!
作者:王峰
https://www.zhihu.com/question/64494691/answer/220989469
17年2月份有篇文章,正好跟這個(gè)問(wèn)題一樣。
The Shattered Gradients Problem: If resnets are the answer, then what is the question?
大意是神經(jīng)網(wǎng)絡(luò)越來(lái)越深的時(shí)候,反傳回來(lái)的梯度之間的相關(guān)性會(huì)越來(lái)越差,最后接近白噪聲。因?yàn)槲覀冎缊D像是具備局部相關(guān)性的,那其實(shí)可以認(rèn)為梯度也應(yīng)該具備類似的相關(guān)性,這樣更新的梯度才有意義,如果梯度接近白噪聲,那梯度更新可能根本就是在做隨機(jī)擾動(dòng)。
有了梯度相關(guān)性這個(gè)指標(biāo)之后,作者分析了一系列的結(jié)構(gòu)和激活函數(shù),發(fā)現(xiàn)resnet在保持梯度相關(guān)性方面很優(yōu)秀(相關(guān)性衰減從  到了
到了  )。這一點(diǎn)其實(shí)也很好理解,從梯度流來(lái)看,有一路梯度是保持原樣不動(dòng)地往回傳,這部分的相關(guān)性是非常強(qiáng)的。
)。這一點(diǎn)其實(shí)也很好理解,從梯度流來(lái)看,有一路梯度是保持原樣不動(dòng)地往回傳,這部分的相關(guān)性是非常強(qiáng)的。
作者:灰灰
https://www.zhihu.com/question/64494691/answer/271335912
一方面: ResNet解決的不是梯度彌散或爆炸問(wèn)題,kaiming的論文中也說(shuō)了:臭名昭著的梯度彌散/爆炸問(wèn)題已經(jīng)很大程度上被normalized initialization and intermediate normalization layers解決了;
另一方面: 由于直接增加網(wǎng)絡(luò)深度的(plain)網(wǎng)絡(luò)在訓(xùn)練集上會(huì)有更高的錯(cuò)誤率,所以更深的網(wǎng)絡(luò)并沒(méi)有過(guò)擬合,也就是說(shuō)更深的網(wǎng)絡(luò)效果不好,是因?yàn)榫W(wǎng)絡(luò)沒(méi)有被訓(xùn)練好,至于為啥沒(méi)有被訓(xùn)練好,個(gè)人很贊同前面王峰的答案中的解釋。
在ResNet中,building block:

H(x)是期望擬合的特征圖,這里叫做desired underlying mapping
一個(gè)building block要擬合的就是這個(gè)潛在的特征圖
當(dāng)沒(méi)有使用殘差網(wǎng)絡(luò)結(jié)構(gòu)時(shí),building block的映射F(x)需要做的就是擬合H(x)
當(dāng)使用了殘差網(wǎng)絡(luò)時(shí),就是加入了skip connection 結(jié)構(gòu),這時(shí)候由一個(gè)building block 的任務(wù)由: F(x) := H(x),變成了F(x) := H(x)-x
對(duì)比這兩個(gè)待擬合的函數(shù),文中說(shuō)假設(shè)擬合殘差圖更容易優(yōu)化,也就是說(shuō):F(x) := H(x)-x比F(x) := H(x)更容易優(yōu)化,接下來(lái)舉了一個(gè)例子,極端情況下:desired underlying mapping要擬合的是identity mapping,這時(shí)候殘差網(wǎng)絡(luò)的任務(wù)就是擬合F(x): 0,而原本的plain結(jié)構(gòu)的話就是F(x) : x,而F(x): 0任務(wù)會(huì)更容易,原因是:resnet(殘差網(wǎng)絡(luò))的F(x)究竟長(zhǎng)什么樣子?中theone的答案:
F是求和前網(wǎng)絡(luò)映射,H是從輸入到求和后的網(wǎng)絡(luò)映射。比如把5映射到5.1,那么引入殘差前是F'(5)=5.1,引入殘差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。這里的F'和F都表示網(wǎng)絡(luò)參數(shù)映射,引入殘差后的映射對(duì)輸出的變化更敏感。比如s輸出從5.1變到5.2,映射F'的輸出增加了1/51=2%,而對(duì)于殘差結(jié)構(gòu)輸出從5.1到5.2,映射F是從0.1到0.2,增加了100%。明顯后者輸出變化對(duì)權(quán)重的調(diào)整作用更大,所以效果更好。殘差的思想都是去掉相同的主體部分,從而突出微小的變化,看到殘差網(wǎng)絡(luò)我第一反應(yīng)就是差分放大器
后續(xù)的實(shí)驗(yàn)也是證明了假設(shè)的, 殘差網(wǎng)絡(luò)比plain網(wǎng)絡(luò)更好訓(xùn)練。因此,ResNet解決的是更好地訓(xùn)練網(wǎng)絡(luò)的問(wèn)題,王峰的答案算是對(duì)ResNet之所以好的一個(gè)理論論證吧.
作者:薰風(fēng)初入弦
https://www.zhihu.com/question/64494691/answer/786270699
看了這個(gè)問(wèn)題之后我思考了很久,于是寫(xiě)出了這篇專欄,現(xiàn)在貼過(guò)來(lái)當(dāng)答案。
首先是跟著論文的思路走,了解作者提出resnet的“心路歷程”,最后也有些個(gè)人整理的理解。
ps:歡迎關(guān)注我的專欄,這段時(shí)間我會(huì)持續(xù)更新,并且在更完約莫十幾篇論文閱讀后,會(huì)再寫(xiě)一些模型實(shí)現(xiàn)/代碼方面的理解。
https://zhuanlan.zhihu.com/IsonomiaCS
一、引言:為什么會(huì)有ResNet?Why ResNet?
神經(jīng)網(wǎng)絡(luò)疊的越深,則學(xué)習(xí)出的效果就一定會(huì)越好嗎?
答案無(wú)疑是否定的,人們發(fā)現(xiàn)當(dāng)模型層數(shù)增加到某種程度,模型的效果將會(huì)不升反降。也就是說(shuō),深度模型發(fā)生了退化(degradation)情況。
那么,為什么會(huì)出現(xiàn)這種情況?
1. 過(guò)擬合?Overfitting?
首先印入腦海的就是Andrew Ng機(jī)器學(xué)習(xí)公開(kāi)課[1]的過(guò)擬合問(wèn)題
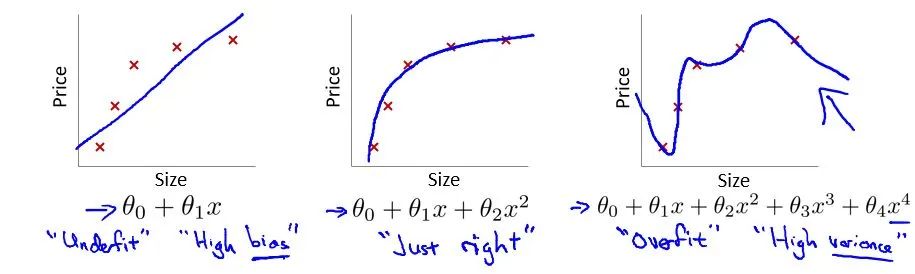
在這個(gè)多項(xiàng)式回歸問(wèn)題中,左邊的模型是欠擬合(under fit)的此時(shí)有很高的偏差(high bias),中間的擬合比較成功,而右邊則是典型的過(guò)擬合(overfit),此時(shí)由于模型過(guò)于復(fù)雜,導(dǎo)致了高方差(high variance)。
然而,很明顯當(dāng)前CNN面臨的效果退化不是因?yàn)檫^(guò)擬合,因?yàn)檫^(guò)擬合的現(xiàn)象是"高方差,低偏差",即測(cè)試誤差大而訓(xùn)練誤差小。但實(shí)際上,深層CNN的訓(xùn)練誤差和測(cè)試誤差都很大。
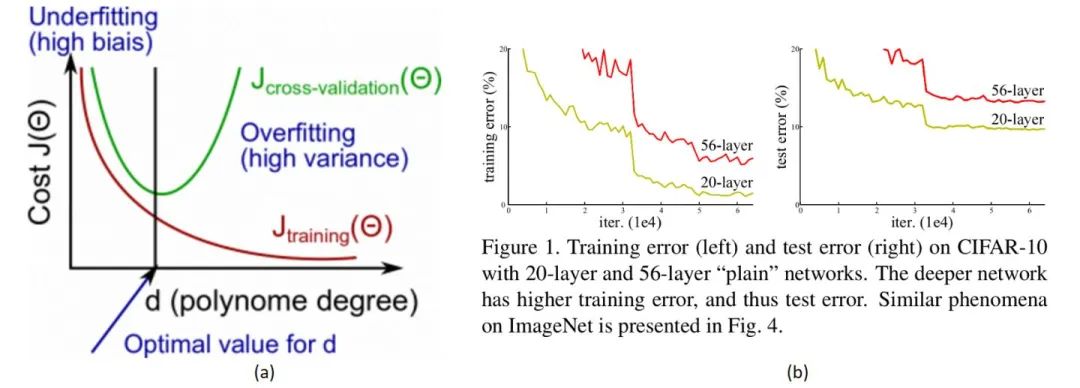
2. 梯度爆炸/消失?Gradient Exploding/Vanishing?
除此之外,最受人認(rèn)可的原因就是“梯度爆炸/消失(彌散)”了。為了理解什么是梯度彌散,首先回顧一下反向傳播的知識(shí)。
假設(shè)我們現(xiàn)在需要計(jì)算一個(gè)函數(shù)  ,
,  ,
, ,
, 在時(shí)的梯度,那么首先可以做出如下所示的計(jì)算圖。
在時(shí)的梯度,那么首先可以做出如下所示的計(jì)算圖。
將 , ,帶入,其中,令  ,一步步計(jì)算,很容易就能得出
,一步步計(jì)算,很容易就能得出  。
。
這就是前向傳播(計(jì)算圖上部分綠色打印字體與藍(lán)色手寫(xiě)字體),即:
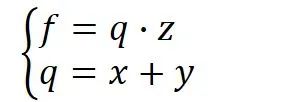
前向傳播是從輸入一步步向前計(jì)算輸出,而反向傳播則是從輸出反向一點(diǎn)點(diǎn)推出輸入的梯度(計(jì)算圖下紅色的部分)。
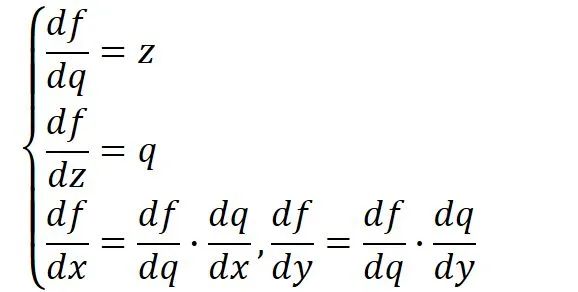
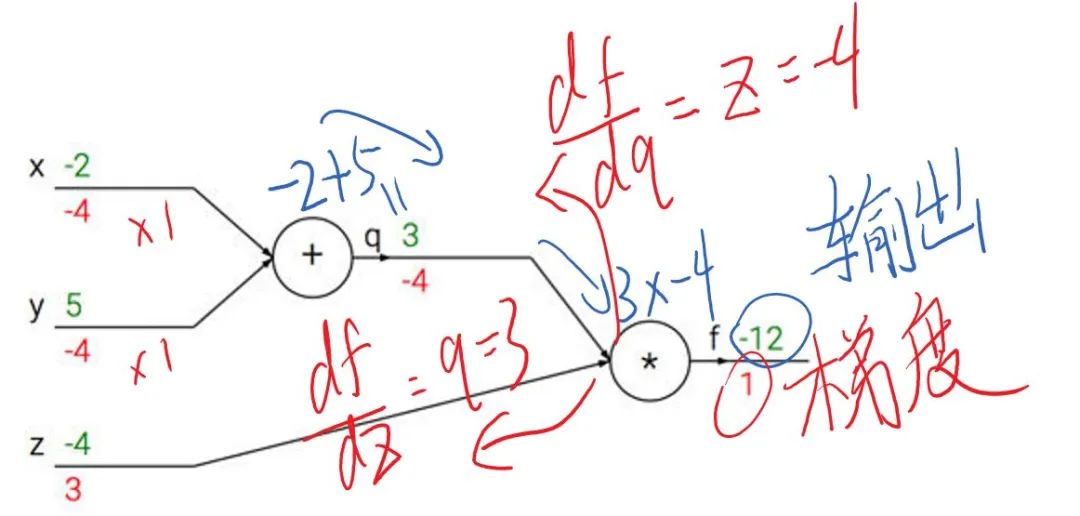
注:這里的反向傳播假設(shè)輸出端接受之前回傳的梯度為1(也可以是輸出對(duì)輸出求導(dǎo)=1)
觀察上述反向傳播,不難發(fā)現(xiàn),在輸出端梯度的模值,經(jīng)過(guò)回傳擴(kuò)大了3~4倍。
這是由于反向傳播結(jié)果的數(shù)值大小不止取決于求導(dǎo)的式子,很大程度上也取決于輸入的模值。當(dāng)計(jì)算圖每次輸入的模值都大于1,那么經(jīng)過(guò)很多層回傳,梯度將不可避免地呈幾何倍數(shù)增長(zhǎng)(每次都變成3~4倍,重復(fù)上萬(wàn)次,想象一下310000有多大……),直到Nan。這就是梯度爆炸現(xiàn)象。
當(dāng)然反過(guò)來(lái),如果我們每個(gè)階段輸入的模恒小于1,那么梯度也將不可避免地呈幾何倍數(shù)下降(比如每次都變成原來(lái)的三分之一,重復(fù)一萬(wàn)次就是3-10000),直到0。這就是梯度消失現(xiàn)象。值得一提的是,由于人為的參數(shù)設(shè)置,梯度更傾向于消失而不是爆炸。
由于至今神經(jīng)網(wǎng)絡(luò)都以反向傳播為參數(shù)更新的基礎(chǔ),所以梯度消失問(wèn)題聽(tīng)起來(lái)很有道理。然而,事實(shí)也并非如此,至少不止如此。
我們現(xiàn)在無(wú)論用Pytorch還是Tensorflow,都會(huì)自然而然地加上Bacth Normalization(簡(jiǎn)稱BN),而B(niǎo)N的作用本質(zhì)上也是控制每層輸入的模值,因此梯度的爆炸/消失現(xiàn)象理應(yīng)在很早就被解決了(至少解決了大半)。
不是過(guò)擬合,也不是梯度消失,這就很尷尬了……CNN沒(méi)有遇到我們熟知的兩個(gè)老大難問(wèn)題,卻還是隨著模型的加深而導(dǎo)致效果退化。無(wú)需任何數(shù)學(xué)論證,我們都會(huì)覺(jué)得這不符合常理。等等,不符合常理……
3. 為什么模型退化不符合常理?
按理說(shuō),當(dāng)我們堆疊一個(gè)模型時(shí),理所當(dāng)然的會(huì)認(rèn)為效果會(huì)越堆越好。因?yàn)椋僭O(shè)一個(gè)比較淺的網(wǎng)絡(luò)已經(jīng)可以達(dá)到不錯(cuò)的效果,那么即使之后堆上去的網(wǎng)絡(luò)什么也不做,模型的效果也不會(huì)變差。
然而事實(shí)上,這卻是問(wèn)題所在。“什么都不做”恰好是當(dāng)前神經(jīng)網(wǎng)絡(luò)最難做到的東西之一。
MobileNet V2的論文[2]也提到過(guò)類似的現(xiàn)象,由于非線性激活函數(shù)Relu的存在,每次輸入到輸出的過(guò)程都幾乎是不可逆的(信息損失)。我們很難從輸出反推回完整的輸入。

也許賦予神經(jīng)網(wǎng)絡(luò)無(wú)限可能性的“非線性”讓神經(jīng)網(wǎng)絡(luò)模型走得太遠(yuǎn),卻也讓它忘記了為什么出發(fā)(想想還挺哲學(xué))。這也使得特征隨著層層前向傳播得到完整保留(什么也不做)的可能性都微乎其微。
用學(xué)術(shù)點(diǎn)的話說(shuō),這種神經(jīng)網(wǎng)絡(luò)丟失的“不忘初心”/“什么都不做”的品質(zhì)叫做恒等映射(identity mapping)。
因此,可以認(rèn)為Residual Learning的初衷,其實(shí)是讓模型的內(nèi)部結(jié)構(gòu)至少有恒等映射的能力。以保證在堆疊網(wǎng)絡(luò)的過(guò)程中,網(wǎng)絡(luò)至少不會(huì)因?yàn)槔^續(xù)堆疊而產(chǎn)生退化!
二、深度殘差學(xué)習(xí) Deep Residual Learning
1. 殘差學(xué)習(xí) Residual Learning
前面分析得出,如果深層網(wǎng)絡(luò)后面的層都是是恒等映射,那么模型就可以轉(zhuǎn)化為一個(gè)淺層網(wǎng)絡(luò)。那現(xiàn)在的問(wèn)題就是如何得到恒等映射了。
事實(shí)上,已有的神經(jīng)網(wǎng)絡(luò)很難擬合潛在的恒等映射函數(shù)H(x) = x。
但如果把網(wǎng)絡(luò)設(shè)計(jì)為H(x) = F(x) + x,即直接把恒等映射作為網(wǎng)絡(luò)的一部分。就可以把問(wèn)題轉(zhuǎn)化為學(xué)習(xí)一個(gè)殘差函數(shù)F(x) = H(x) - x.
只要F(x)=0,就構(gòu)成了一個(gè)恒等映射H(x) = x。而且,擬合殘差至少比擬合恒等映射容易得多。
于是,就有了論文[3]中的Residual block結(jié)構(gòu)

圖中右側(cè)的曲線叫做跳接(shortcut connection),通過(guò)跳接在激活函數(shù)前,將上一層(或幾層)之前的輸出與本層計(jì)算的輸出相加,將求和的結(jié)果輸入到激活函數(shù)中做為本層的輸出。
用數(shù)學(xué)語(yǔ)言描述,假設(shè)Residual Block的輸入為  ,則輸出
,則輸出  等于:
等于:

其中  是我們學(xué)習(xí)的目標(biāo),即輸出輸入的殘差
是我們學(xué)習(xí)的目標(biāo),即輸出輸入的殘差  。以上圖為例,殘差部分是中間有一個(gè)Relu激活的雙層權(quán)重,即:
。以上圖為例,殘差部分是中間有一個(gè)Relu激活的雙層權(quán)重,即:
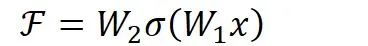
其中  指代Relu,而
指代Relu,而  指代兩層權(quán)重。
指代兩層權(quán)重。
順帶一提,這里一個(gè)Block中必須至少含有兩個(gè)層,否則就會(huì)出現(xiàn)很滑稽的情況:
顯然這樣加了和沒(méi)加差不多……
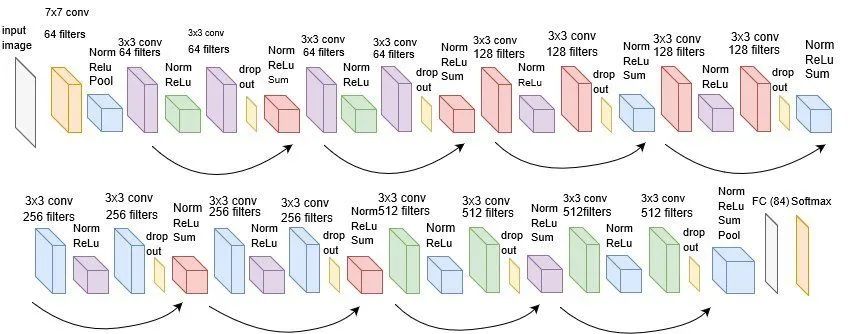
2.網(wǎng)絡(luò)結(jié)構(gòu)與維度問(wèn)題
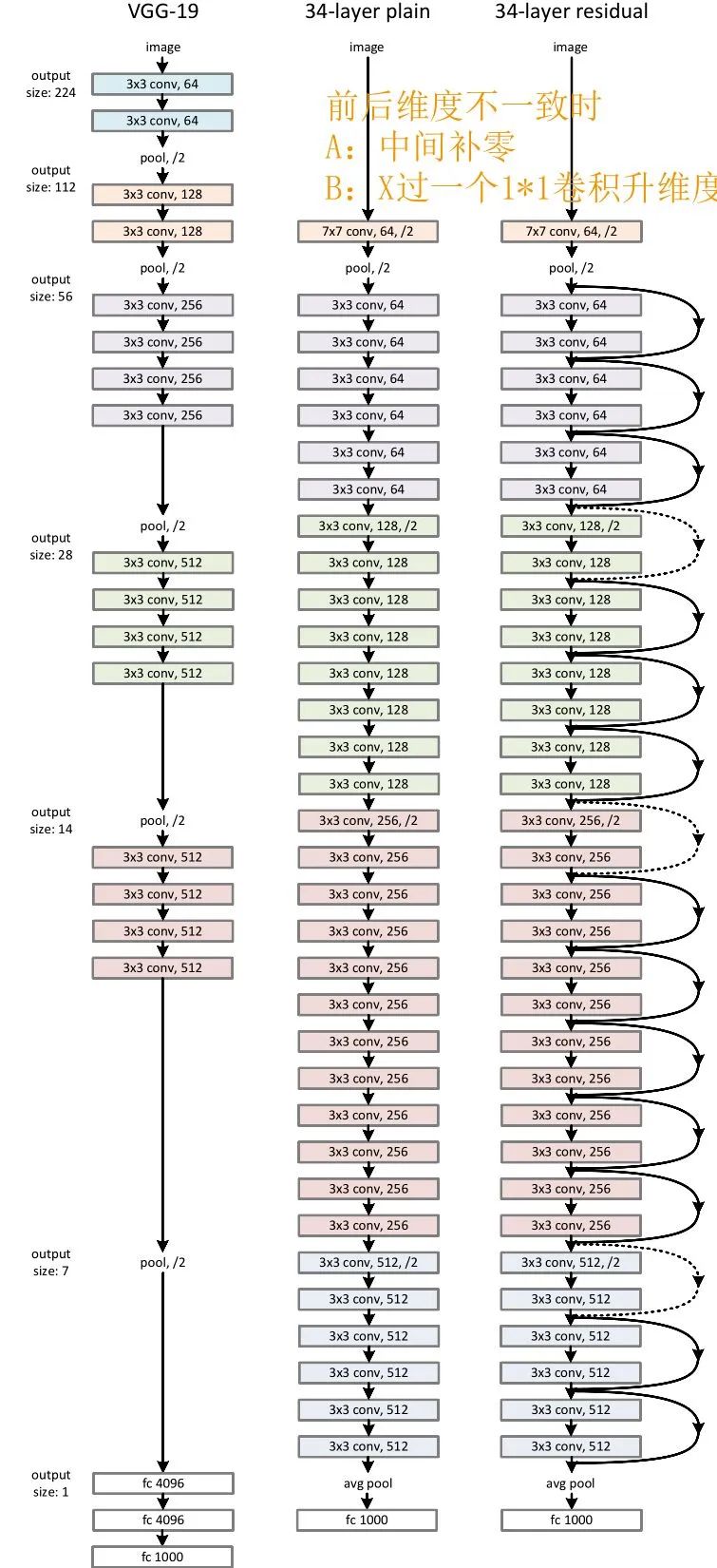
論文中原始的ResNet34與VGG的結(jié)構(gòu)如上圖所示,可以看到即使是當(dāng)年號(hào)稱“Very Deep”的VGG,和最基礎(chǔ)的Resnet在深度上相比都是個(gè)弟弟。
可能有好奇心寶寶發(fā)現(xiàn)了,跳接的曲線中大部分是實(shí)現(xiàn),但也有少部分虛線。這些虛線的代表這些Block前后的維度不一致,因?yàn)槿サ魵埐罱Y(jié)構(gòu)的Plain網(wǎng)絡(luò)還是參照了VGG經(jīng)典的設(shè)計(jì)思路:每隔x層,空間上/2(下采樣)但深度翻倍。
也就是說(shuō),維度不一致體現(xiàn)在兩個(gè)層面:
空間上不一致
深度上不一致
空間上不一致很簡(jiǎn)單,只需要在跳接的部分給輸入x加上一個(gè)線性映射  ,即:
,即:
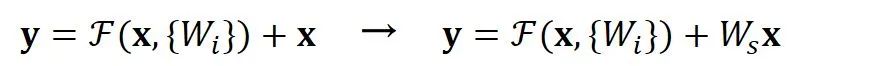
而對(duì)于深度上的不一致,則有兩種解決辦法,一種是在跳接過(guò)程中加一個(gè)1*1的卷積層進(jìn)行升維,另一種則是直接簡(jiǎn)單粗暴地補(bǔ)零。事實(shí)證明兩種方法都行得通。
注:深度上和空間上維度的不一致是分開(kāi)處理的,但很多人將兩者混為一談(包括目前某乎一些高贊文章),這導(dǎo)致了一些人在模型的實(shí)現(xiàn)上感到困惑(比如當(dāng)年的我)。
3. torchvision中的官方實(shí)現(xiàn)
事實(shí)上論文中的ResNet并不是最常用的,我們可以在Torchvision的模型庫(kù)中找到一些很不錯(cuò)的例子,這里拿Resnet18為例:
運(yùn)行代碼:
import torchvisionmodel = torchvision.models.resnet18(pretrained=False) #我們不下載預(yù)訓(xùn)練權(quán)重print(model)
得到輸出:
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(layer4): Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)(fc): Linear(in_features=512, out_features=1000, bias=True))
薰風(fēng)說(shuō) Thinkings
上述的內(nèi)容是我以自己的角度思考作者提出ResNet的心路歷程,我比作者蔡很多,所以難免出現(xiàn)思考不全的地方。
ResNet是如此簡(jiǎn)潔高效,以至于模型提出后還有無(wú)數(shù)論文討論“ResNet到底解決了什么問(wèn)題(The Shattered Gradients Problem: If resnets are the answer, then what is the question?)”[4]
論文[4]認(rèn)為,即使BN過(guò)后梯度的模穩(wěn)定在了正常范圍內(nèi),但梯度的相關(guān)性實(shí)際上是隨著層數(shù)增加持續(xù)衰減的。而經(jīng)過(guò)證明,ResNet可以有效減少這種相關(guān)性的衰減。
對(duì)于  層的網(wǎng)絡(luò)來(lái)說(shuō),沒(méi)有殘差表示的Plain Net梯度相關(guān)性的衰減在 ,而ResNet的衰減卻只有 。這也驗(yàn)證了ResNet論文本身的觀點(diǎn),網(wǎng)絡(luò)訓(xùn)練難度隨著層數(shù)增長(zhǎng)的速度不是線性,而至少是多項(xiàng)式等級(jí)的增長(zhǎng)(如果該論文屬實(shí),則可能是指數(shù)級(jí)增長(zhǎng)的)
層的網(wǎng)絡(luò)來(lái)說(shuō),沒(méi)有殘差表示的Plain Net梯度相關(guān)性的衰減在 ,而ResNet的衰減卻只有 。這也驗(yàn)證了ResNet論文本身的觀點(diǎn),網(wǎng)絡(luò)訓(xùn)練難度隨著層數(shù)增長(zhǎng)的速度不是線性,而至少是多項(xiàng)式等級(jí)的增長(zhǎng)(如果該論文屬實(shí),則可能是指數(shù)級(jí)增長(zhǎng)的)
而對(duì)于“梯度彌散”觀點(diǎn)來(lái)說(shuō),在輸出引入一個(gè)輸入x的恒等映射,則梯度也會(huì)對(duì)應(yīng)地引入一個(gè)常數(shù)1,這樣的網(wǎng)絡(luò)的確不容易出現(xiàn)梯度值異常,在某種意義上,起到了穩(wěn)定梯度的作用。
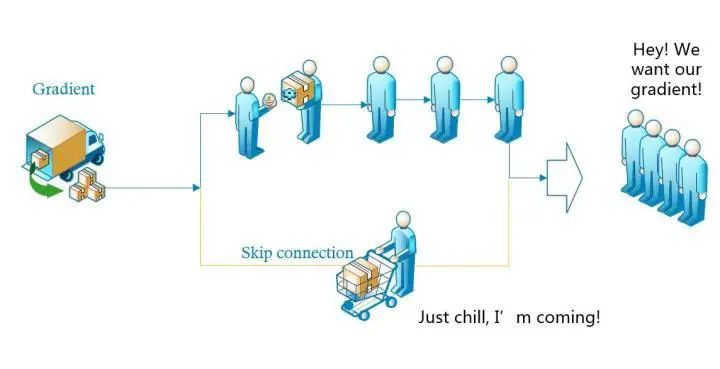
除此之外,shortcut類似的方法也并不是第一次提出,之前就有“Highway Networks”。可以只管理解為,以往參數(shù)要得到梯度,需要快遞員將梯度一層一層中轉(zhuǎn)到參數(shù)手中(就像我取個(gè)快遞,都顯示要從“上海市”發(fā)往“閔行分揀中心”,閔大荒日常被踢出上海籍)。而跳接實(shí)際上給梯度開(kāi)了一條“高速公路”(取快遞可以直接用無(wú)人機(jī)空投到我手里了),效率自然大幅提高,不過(guò)這只是個(gè)比較想當(dāng)然的理由。
上面的理解很多論文都講過(guò),但我個(gè)人最喜歡下面兩個(gè)理解。
第一個(gè)已經(jīng)由Feature Pyramid Network[5]提出了,那就是跳連接相加可以實(shí)現(xiàn)不同分辨率特征的組合,因?yàn)闇\層容易有高分辨率但是低級(jí)語(yǔ)義的特征,而深層的特征有高級(jí)語(yǔ)義,但分辨率就很低了。
第二個(gè)理解則是說(shuō),引入跳接實(shí)際上讓模型自身有了更加“靈活”的結(jié)構(gòu),即在訓(xùn)練過(guò)程本身,模型可以選擇在每一個(gè)部分是“更多進(jìn)行卷積與非線性變換”還是“更多傾向于什么都不做”,抑或是將兩者結(jié)合。模型在訓(xùn)練便可以自適應(yīng)本身的結(jié)構(gòu),這聽(tīng)起來(lái)是多么酷的一件事啊!
有的人也許會(huì)納悶,我們已經(jīng)知道一個(gè)模型的來(lái)龍去脈了,那么在一個(gè)客觀上已經(jīng)十分優(yōu)秀的模型,強(qiáng)加那么多主觀的個(gè)人判斷有意思嗎?
然而筆者還是相信,更多角度的思考有助于我們發(fā)現(xiàn)現(xiàn)有模型的不足,以及值得改進(jìn)的點(diǎn)。比如我最喜歡的兩個(gè)理解就可以引申出這樣的問(wèn)題“雖然跳接可以結(jié)合不同分辨率,但ResNet顯然沒(méi)有充分利用這個(gè)優(yōu)點(diǎn),因?yàn)槊總€(gè)shortcut頂多跨越一種分辨率(大部分還不會(huì)發(fā)生跨越)”。
那么“如果用跳接組合更多分辨率的特征,模型的效果會(huì)不會(huì)更好?”這就是DenseNet回答我們的問(wèn)題了。
[1]https://www.coursera.org/learn/machine-learning
[2]Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[J]. 2018.
[3]He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[J]. 2015.
[4]Balduzzi D , Frean M , Leary L , et al. The Shattered Gradients Problem: If resnets are the answer, then what is the question?[J]. 2017.
[5]Lin T Y , Dollár, Piotr, Girshick R , et al. Feature Pyramid Networks for Object Detection[J]. 2016.
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~