
一次 Spark SQL 性能提升10倍的經(jīng)歷




1. 遇到了啥問題
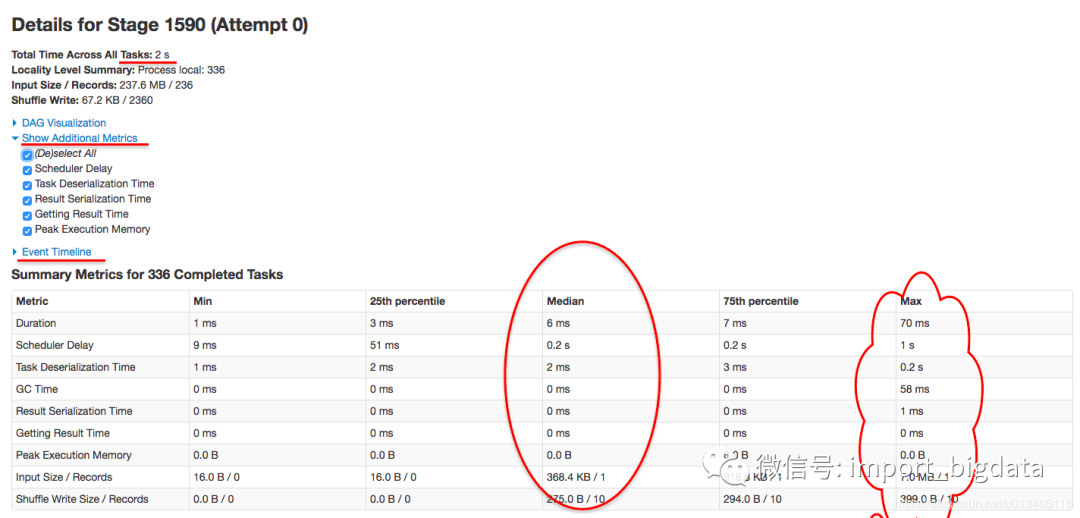
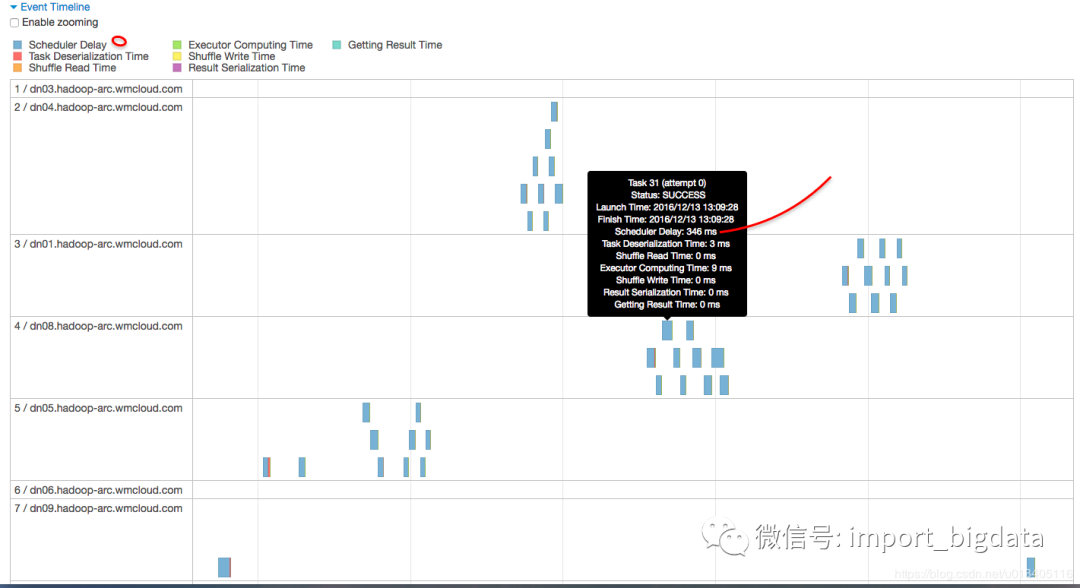
2. 原因排查
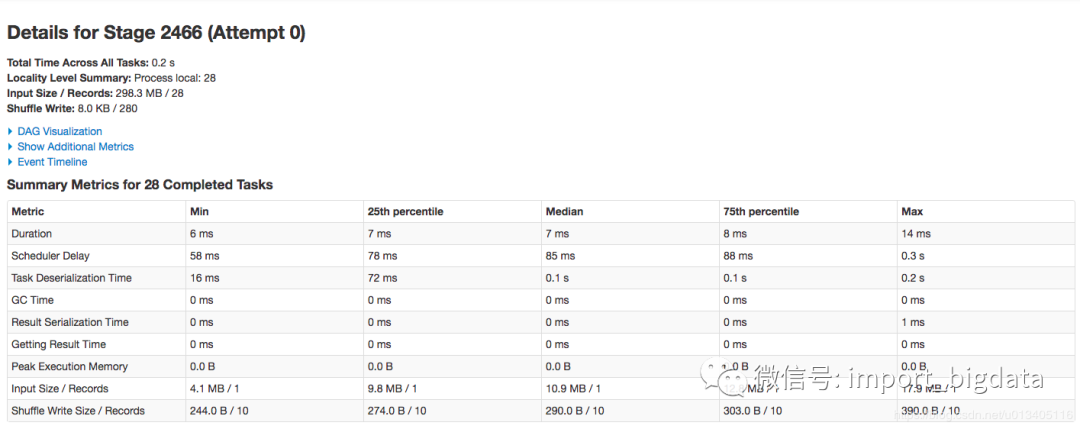
該 stage 內(nèi)一共有 336 個(gè)task
3. 如何解決
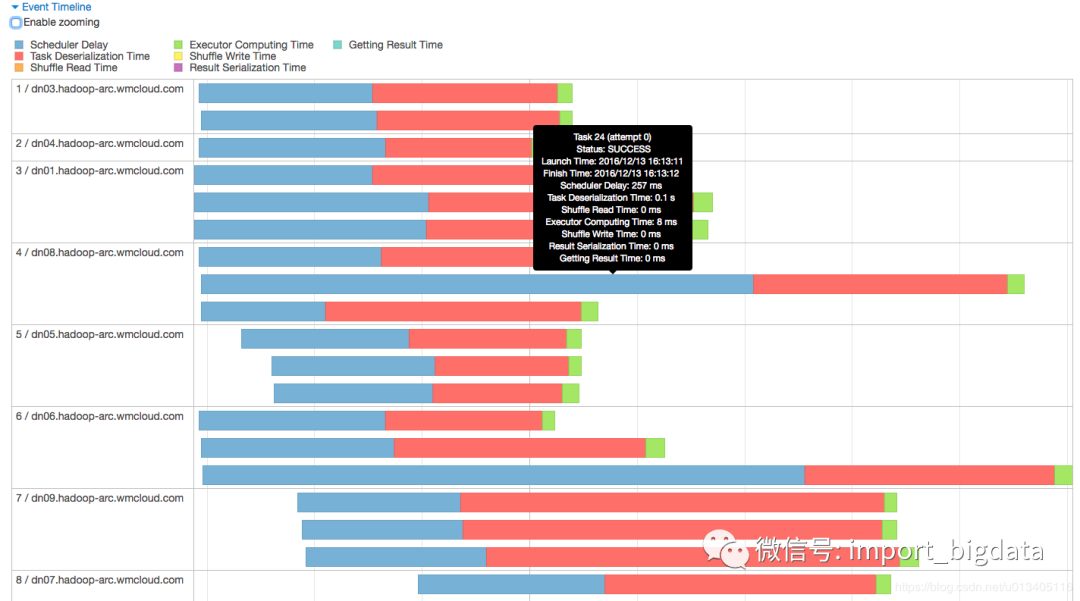
為什么 scheduler delay 會(huì)這么大
降低 average delay time:目前來(lái)看似乎唯一的方法是砸錢加資源
降低 task 數(shù):粗略來(lái)看,簡(jiǎn)單的降低 task 數(shù)的話,應(yīng)該是能減少 total delay time 的,但是如果task 數(shù)降低了,意味著每個(gè) task 需要處理的數(shù)據(jù)量就多了,那其他的時(shí)間應(yīng)該是會(huì)增加一些的,比如說(shuō)?
Task Deserialization Time, Result Serialization Time, GC Time, Duration?等。減少 task 數(shù)究竟能不能提高整體運(yùn)行速度,似乎乍一看還真不好確定。
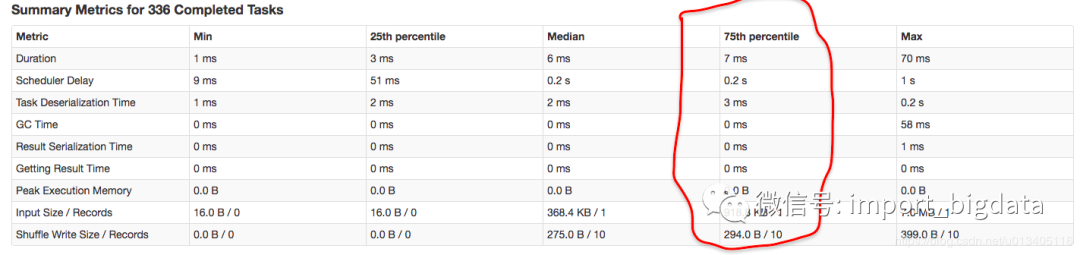
Duration: 擴(kuò)大到 10 倍,14ms
Scheduler Delay: 這個(gè)指標(biāo)不用估計(jì)
Task Deserialization Time: 擴(kuò)大到 10 倍,6ms
GC Time: 擴(kuò)大到 10 倍,最多1ms
Result Serialization Time: 擴(kuò)大到 10 倍,最多1ms
Getting Result Time: 擴(kuò)大到 10 倍,最多1ms
Peak Execution Memory: 擴(kuò)大到 10 倍,最多 1b
Input Size / Records: 擴(kuò)大到 10 倍,918.8 KB * 2 / 2
Shuffle Write Size / Records 0: 擴(kuò)大到 10 倍,294.0 B * 2/ 20
@mac007:~/Desktop/dyes/git-mercury/mercury-computing$hadoop fs -ls -h hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ | cat -n | tail
317 -rw-r--r-- 3 taotao hfmkt 1.3 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00310-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
318 -rw-r--r-- 3 taotao hfmkt 1.4 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00311-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
319 -rw-r--r-- 3 taotao hfmkt 2.9 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00312-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
320 -rw-r--r-- 3 taotao hfmkt 1.2 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00313-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
321 -rw-r--r-- 3 taotao hfmkt 1.9 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00314-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
322 -rw-r--r-- 3 taotao hfmkt 1.7 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00315-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
323 -rw-r--r-- 3 taotao hfmkt 899.4 K 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00316-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
324 -rw-r--r-- 3 taotao hfmkt 2.3 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00317-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
325 -rw-r--r-- 3 taotao hfmkt 1.0 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00318-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
326 -rw-r--r-- 3 taotao hfmkt 460.9 K 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00319-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
4. 效果對(duì)比
20161117 這天
taotao@mac007:~/Desktop/dyes/git-mercury/mercury-computing$hadoop fs -ls -h hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_S* | cat -n | tail -n 5
342 -rw-r--r-- 3 taotao hfmkt 1.7 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00315-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
343 -rw-r--r-- 3 taotao hfmkt 899.4 K 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00316-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
344 -rw-r--r-- 3 taotao hfmkt 2.3 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00317-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
345 -rw-r--r-- 3 taotao hfmkt 1.0 M 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00318-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
346 -rw-r--r-- 3 taotao hfmkt 460.9 K 2016-11-17 16:37 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161117/20161117_Transaction_SZ/part-r-00319-38d7cc53-60d2-40b3-a945-0cb5832f30de.gz.parquet
20161212 這天
taotao@mac007:~/Desktop/dyes/git-mercury/mercury-computing$hadoop fs -ls -h hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161212/20161212_Transaction_S* | cat -n | tail -n 5
34 -rw-r--r-- 3 taotao hfmkt 19.2 M 2016-12-12 15:49 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161212/20161212_Transaction_SZ/part-r-00013-686bbce5-a7a1-4b5d-b25c-14cd9ddae283.gz.parquet
35 -rw-r--r-- 3 taotao hfmkt 10.7 M 2016-12-12 15:49 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161212/20161212_Transaction_SZ/part-r-00014-686bbce5-a7a1-4b5d-b25c-14cd9ddae283.gz.parquet
36 -rw-r--r-- 3 taotao hfmkt 26.0 M 2016-12-12 15:49 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161212/20161212_Transaction_SZ/part-r-00015-686bbce5-a7a1-4b5d-b25c-14cd9ddae283.gz.parquet
37 -rw-r--r-- 3 taotao hfmkt 20.1 M 2016-12-12 15:49 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161212/20161212_Transaction_SZ/part-r-00016-686bbce5-a7a1-4b5d-b25c-14cd9ddae283.gz.parquet
38 -rw-r--r-- 3 taotao hfmkt 8.7 M 2016-12-12 15:49 hdfs://hadoop-archive-cluster/hfmkt/level2/datayes/parquet/20161212/20161212_Transaction_SZ/part-r-00017-686bbce5-a7a1-4b5d-b25c-14cd9ddae283.gz.parquet
20161117 這天:99s
20161212 這天:16s
20161117 這天
20161212 這天
5. 總結(jié)

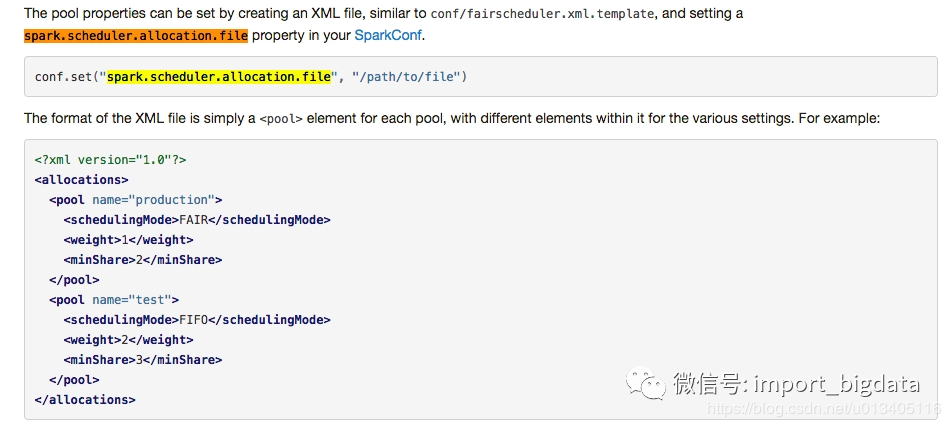
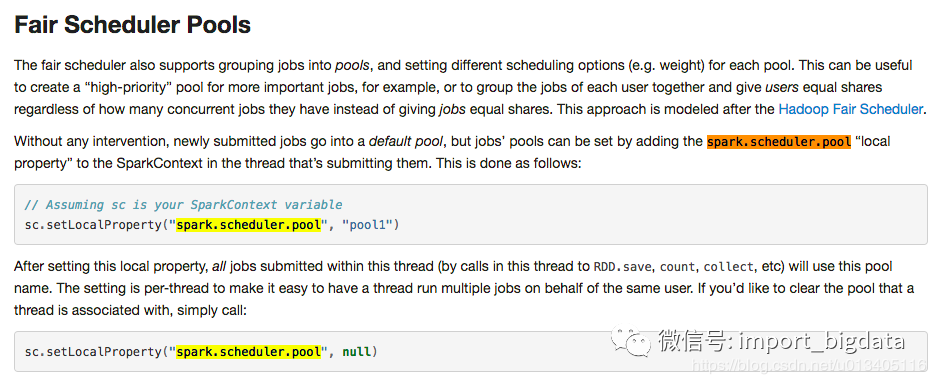

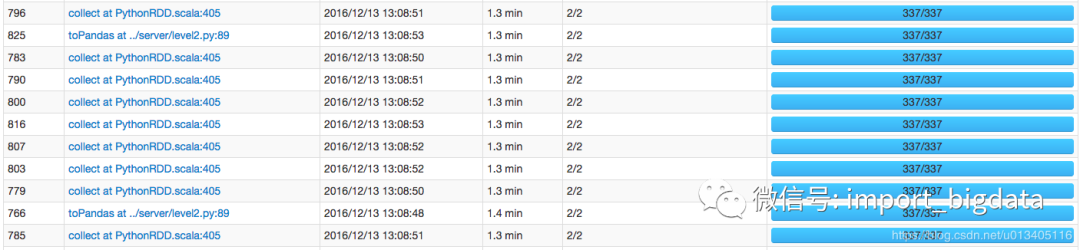
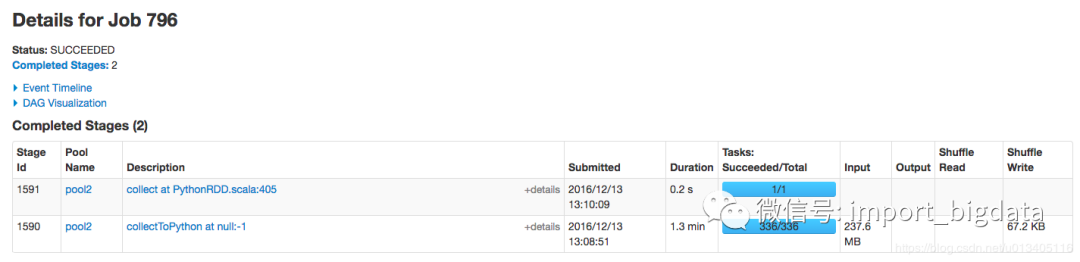


超全Spark性能優(yōu)化總結(jié)
一次SparkSQL性能分析與優(yōu)化之旅及相關(guān)工具小結(jié)
基于 Spark 技術(shù)快速構(gòu)建數(shù)倉(cāng)項(xiàng)目

