
我用Python爬取800只基金數(shù)據(jù),發(fā)現(xiàn)……
作者:數(shù)據(jù)科學(xué)家聯(lián)盟
來源:知乎
本文涉及到的知識(shí)點(diǎn)
網(wǎng)站分析
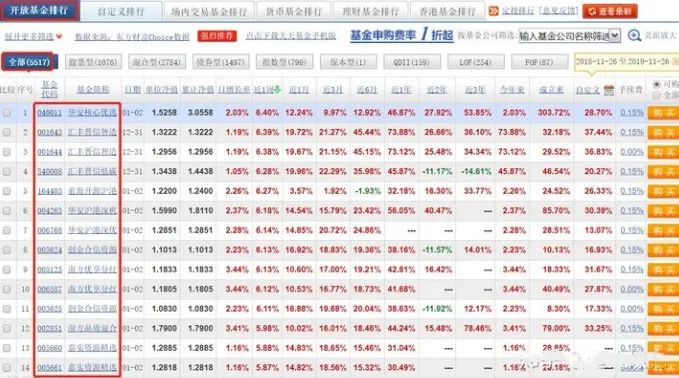
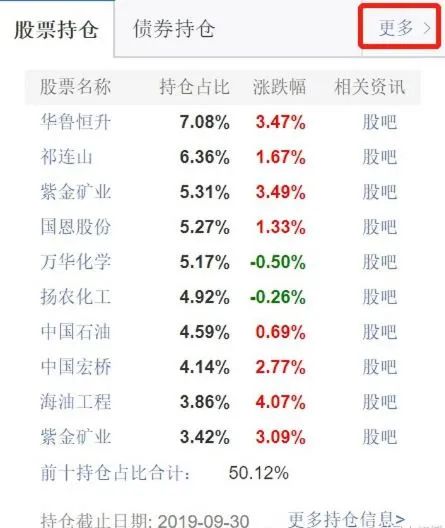
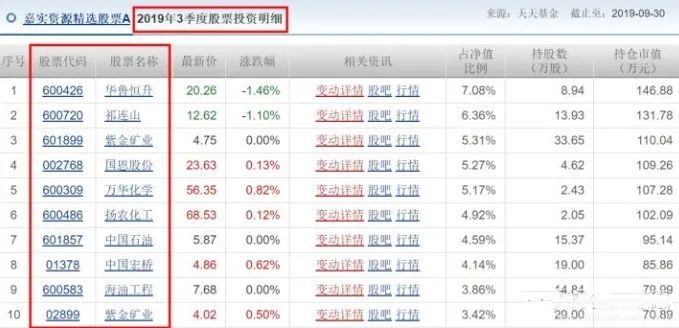
爬取流程
代碼講解——數(shù)據(jù)爬取
import re
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pymongo
def is_contain_chinese(check_str):
"""
判斷字符串中是否包含中文
:param check_str: {str} 需要檢測(cè)的字符串
:return: {bool} 包含返回True, 不包含返回False
"""
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return True
return False
#selenium通過class name判斷元素是否存在,用于判斷基金持倉(cāng)股票詳情頁(yè)中該基金是否有持倉(cāng)股票;
def is_element(driver,element_class):
try:
WebDriverWait(driver,2).until(EC.presence_of_element_located((By.CLASS_NAME,element_class)))
except:
return False
else:
return True
#requests請(qǐng)求url的方法,處理后返回text文本
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
proxies = {
"http": "http://XXX.XXX.XXX.XXX:XXXX"
}
response = requests.get(url,headers=headers,proxies=proxies)
response.encoding = 'utf-8'
if response.status_code == 200:
return response.text
else:
print("請(qǐng)求狀態(tài)碼 != 200,url錯(cuò)誤.")
return None
#該方法直接將首頁(yè)的數(shù)據(jù)請(qǐng)求、返回、處理,組成持倉(cāng)信息url和股票名字并存儲(chǔ)到數(shù)組中;
def page_url():
stock_url = [] #定義一個(gè)數(shù)組,存儲(chǔ)基金持倉(cāng)股票詳情頁(yè)面的url
stock_name = [] #定義一個(gè)數(shù)組,存儲(chǔ)基金的名稱
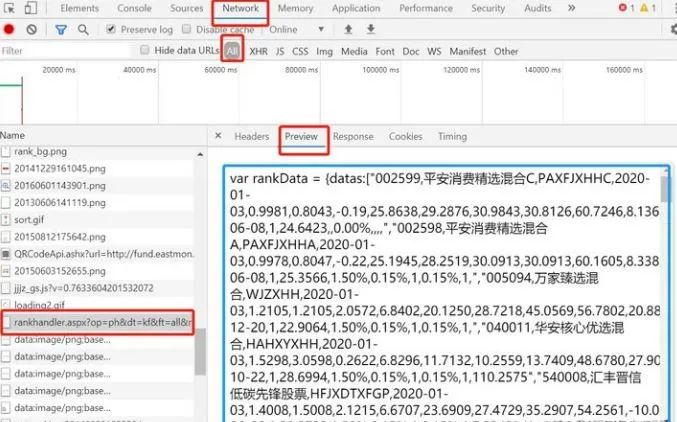
url = "http://fund.eastmoney.com/data/rankhandler.aspx?op=ph&dt=kf&ft=all&rs=&gs=0&sc=zzf&st=desc&sd=2018-11-26&ed=2019-11-26&qdii=&tabSubtype=,,,,,&pi=1&pn=10000&dx=1&v=0.234190661250681"
result_text = get_one_page(url)
# print(result_text.replace('\"',',')) #將"替換為,
# print(result_text.replace('\"',',').split(',')) #以,為分割
# print(re.findall(r"\d{6}",result_text)) #輸出股票的6位代碼返回?cái)?shù)組;
for i in result_text.replace('\"',',').split(','): #將"替換為,再以,進(jìn)行分割,遍歷篩選出含有中文的字符(股票的名字)
result_chinese = is_contain_chinese(i)
if result_chinese == True:
stock_name.append(i)
for numbers in re.findall(r"\d{6}",result_text):
stock_url.append("http://fundf10.eastmoney.com/ccmx_%s.html" % (numbers)) #將拼接后的url存入列表;
return stock_url,stock_name
#selenium請(qǐng)求[基金持倉(cāng)股票詳情頁(yè)面url]的方法,爬取基金的持倉(cāng)股票名稱;
def hold_a_position(url):
driver.get(url) # 請(qǐng)求基金持倉(cāng)的信息
element_result = is_element(driver, "tol") # 是否存在這個(gè)元素,用于判斷是否有持倉(cāng)信息;
if element_result == True: # 如果有持倉(cāng)信息則爬取;
wait = WebDriverWait(driver, 3) # 設(shè)置一個(gè)等待時(shí)間
input = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'tol'))) # 等待這個(gè)class的出現(xiàn);
ccmx_page = driver.page_source # 獲取頁(yè)面的源碼
ccmx_xpath = etree.HTML(ccmx_page) # 轉(zhuǎn)換成成 xpath 格式
ccmx_result = ccmx_xpath.xpath("http://div[@class='txt_cont']//div[@id='cctable']//div[@class='box'][1]//td[3]//text()")
return ccmx_result
else: #如果沒有持倉(cāng)信息,則返回null字符;
return "null"
if __name__ == '__main__':
# 創(chuàng)建連接mongodb數(shù)據(jù)庫(kù)
client = pymongo.MongoClient(host='XXX.XXX.XXX.XXX', port=XXXXX) # 連接mongodb,host是ip,port是端口
db = client.db_spider # 使用(創(chuàng)建)數(shù)據(jù)庫(kù)
db.authenticate("用戶名", "密碼") # mongodb的用戶名、密碼連接;
collection = db.tb_stock # 使用(創(chuàng)建)一個(gè)集合(表)
stock_url, stock_name = page_url() #獲取首頁(yè)數(shù)據(jù),返回基金url的數(shù)組和基金名稱的數(shù)組;
#瀏覽器動(dòng)作
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options) #初始化瀏覽器,無瀏覽器界面的;
if len(stock_url) == len(stock_name): #判斷獲取的基金url和基金名稱數(shù)量是否一致
for i in range(len(stock_url)):
return_result = hold_a_position(stock_url[i]) # 遍歷持倉(cāng)信息,返回持倉(cāng)股票的名稱---數(shù)組
dic_data = {
'fund_url':stock_url[i],
'fund_name':stock_name[i],
'stock_name':return_result
} #dic_data 為組成的字典數(shù)據(jù),為存儲(chǔ)到mongodb中做準(zhǔn)備;
print(dic_data)
collection.insert_one(dic_data) #將dic_data插入mongodb數(shù)據(jù)庫(kù)
else:
print("基金url和基金name數(shù)組數(shù)量不一致,退出。")
exit()
driver.close() #關(guān)閉瀏覽器
#查詢:過濾出非null的數(shù)據(jù)
find_stock = collection.find({'stock_name': {'$ne': 'null'}}) # 查詢 stock_name 不等于 null 的數(shù)據(jù)(排除那些沒有持倉(cāng)股票的基金機(jī)構(gòu));
for i in find_stock:
print(i)
代碼講解——數(shù)據(jù)處理
import pymongo
#一、數(shù)據(jù)庫(kù):連接庫(kù)、使用集合、創(chuàng)建文檔;#
client = pymongo.MongoClient(host='XXX.XXX.XXX.XXX',port=XXXXX) #連接mongodb數(shù)據(jù)庫(kù)
db = client.db_spider #使用(創(chuàng)建)數(shù)據(jù)庫(kù)
db.authenticate("用戶名","密碼") #認(rèn)證用戶名、密碼
collection = db.tb_stock #使用(創(chuàng)建)一個(gè)集合(表),里面已經(jīng)存儲(chǔ)著上面程序爬取的數(shù)據(jù)了;
tb_result = db.tb_data #使用(創(chuàng)建)一個(gè)集合(表),用于存儲(chǔ)最后處理完畢的數(shù)據(jù);
#查詢 stock_name 不等于 null 的數(shù)據(jù),即:排除那些沒有持倉(cāng)股票的基金;
find_stock = collection.find({'stock_name':{'$ne':'null'}})
#二、處理數(shù)據(jù),將所有的股票數(shù)組累加成一個(gè)數(shù)組---list_stock_all #
list_stock_all = [] #定義一個(gè)數(shù)組,存儲(chǔ)所有的股票名稱,包括重復(fù)的;
for i in find_stock:
print(i['stock_name']) #輸出基金的持倉(cāng)股票(類型為數(shù)組)
list_stock_all = list_stock_all + i['stock_name'] #綜合所有的股票數(shù)組為一個(gè)數(shù)組;
print("股票總數(shù):" + str(len(list_stock_all)))
#三、處理數(shù)據(jù),股票去重#
list_stock_repetition = [] #定義一個(gè)數(shù)組,存放去重之后的股票
for n in list_stock_all:
if n not in list_stock_repetition: #如果不存在
list_stock_repetition.append(n) #則添加進(jìn)該數(shù)組,去重;
print("去重后的股票數(shù)量:" + str(len(list_stock_repetition)))
#四、綜合二、三中的得出的兩個(gè)數(shù)組進(jìn)行數(shù)據(jù)篩選#
for u in list_stock_repetition: #遍歷去重后股票的數(shù)組
if list_stock_all.count(u) > 10: #在未去重股票的數(shù)組中查找股票的重復(fù)數(shù),如果重復(fù)數(shù)大于10
#將數(shù)據(jù)組成字典,用于存儲(chǔ)到mongodb中;
data_stock = {
"name":u,
"numbers":list_stock_all.count(u)
}
insert_result = tb_result.insert_one(data_stock) #存儲(chǔ)至mongodb中
print("股票名稱:" + u + " , 重復(fù)數(shù):" + str(list_stock_all.count(u)))
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62c9'), 'name': '水晶光電', 'numbers': 61}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62ca'), 'name': '老百姓', 'numbers': 77}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cb'), 'name': '北方華創(chuàng)', 'numbers': 52}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cc'), 'name': '金風(fēng)科技', 'numbers': 84}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cd'), 'name': '天順風(fēng)能', 'numbers': 39}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62ce'), 'name': '石大勝華', 'numbers': 13}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62cf'), 'name': '國(guó)投電力', 'numbers': 55}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d0'), 'name': '中國(guó)石化', 'numbers': 99}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d1'), 'name': '中國(guó)石油', 'numbers': 54}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d2'), 'name': '中國(guó)平安', 'numbers': 1517}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d3'), 'name': '貴州茅臺(tái)', 'numbers': 1573}
{'_id': ObjectId('5e0b5ecc7479db5ac2ec62d4'), 'name': '招商銀行', 'numbers': 910}
總結(jié)
- EOF -
推薦閱讀:
評(píng)論
圖片
表情