
炸了!一口氣問(wèn)了我18個(gè)JVM問(wèn)題!
前言
GC 對(duì)于Java 來(lái)說(shuō)重要性不言而喻,不論是平日里對(duì) JVM 的調(diào)優(yōu)還是面試中的無(wú)情轟炸。
這篇文章我會(huì)以一問(wèn)一答的方式來(lái)展開(kāi)有關(guān) GC 的內(nèi)容。
不過(guò)在此之前強(qiáng)烈建議先看這篇文章深度揭秘垃圾回收底層。
因?yàn)檫@篇文章解釋了很多有關(guān)垃圾回收的基本知識(shí),能從源頭上理解垃圾回收和日益發(fā)展的垃圾收集器演進(jìn)的方向,這很重要。
本文章所說(shuō)的 GC 實(shí)現(xiàn)沒(méi)有特殊說(shuō)明的話,默認(rèn)指的是 HotSpot 的。
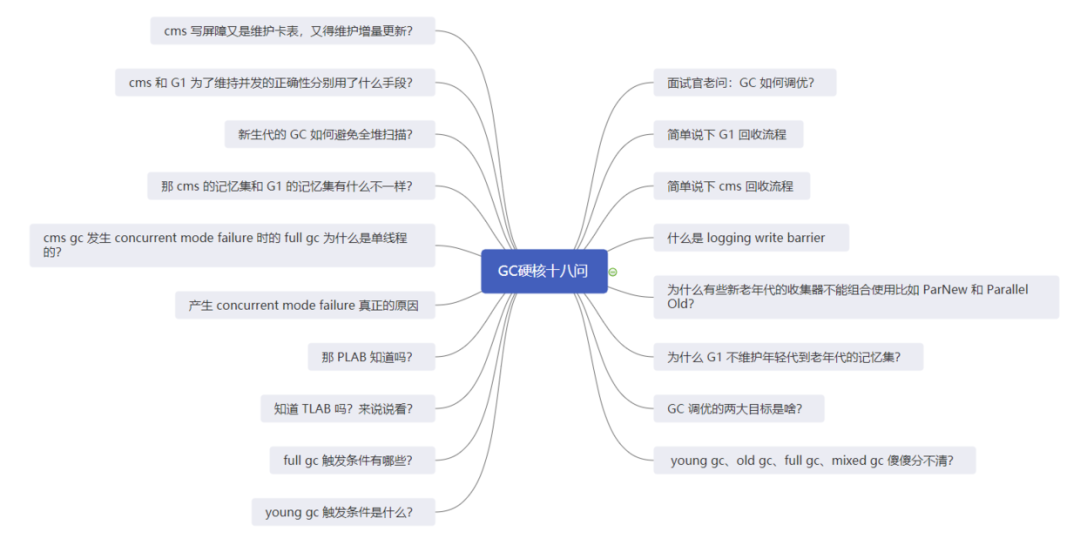
我先將十八個(gè)問(wèn)題都列出來(lái),大家可以先思考下能答出幾道。
好了,開(kāi)始表演。
young gc、old gc、full gc、mixed gc 傻傻分不清?
這個(gè)問(wèn)題的前置條件是你得知道 GC 分代,為什么分代。這個(gè)在之前文章提了,不清楚的可以去看看。
現(xiàn)在我們來(lái)回答一下這個(gè)問(wèn)題。
其實(shí) GC 分為兩大類(lèi),分別是 Partial GC 和 Full GC。
Partial GC 即部分收集,分為 young gc、old gc、mixed gc。
young gc:指的是單單收集年輕代的 GC。 old gc:指的是單單收集老年代的 GC。 mixed gc:這個(gè)是 G1 收集器特有的,指的是收集整個(gè)年輕代和部分老年代的 GC。
Full GC 即整堆回收,指的是收取整個(gè)堆,包括年輕代、老年代,如果有永久代的話還包括永久代。
其實(shí)還有 Major GC 這個(gè)名詞,在《深入理解Java虛擬機(jī)》中這個(gè)名詞指代的是單單老年代的 GC,也就是和 old gc 等價(jià)的,不過(guò)也有很多資料認(rèn)為其是和 full gc 等價(jià)的。
還有 Minor GC,其指的就是年輕代的 gc。
young gc 觸發(fā)條件是什么?
大致上可以認(rèn)為在年輕代的 eden 快要被占滿的時(shí)候會(huì)觸發(fā) young gc。
為什么要說(shuō)大致上呢?因?yàn)橛幸恍┦占鞯幕厥諏?shí)現(xiàn)是在 full gc 前會(huì)讓先執(zhí)行以下 young gc。
比如 Parallel Scavenge,不過(guò)有參數(shù)可以調(diào)整讓其不進(jìn)行 young gc。
可能還有別的實(shí)現(xiàn)也有這種操作,不過(guò)正常情況下就當(dāng)做 eden 區(qū)快滿了即可。
eden 快滿的觸發(fā)因素有兩個(gè),一個(gè)是為對(duì)象分配內(nèi)存不夠,一個(gè)是為 TLAB 分配內(nèi)存不夠。
full gc 觸發(fā)條件有哪些?
這個(gè)觸發(fā)條件稍微有點(diǎn)多,我們來(lái)看下。
在要進(jìn)行 young gc 的時(shí)候,根據(jù)之前統(tǒng)計(jì)數(shù)據(jù)發(fā)現(xiàn)年輕代平均晉升大小比現(xiàn)在老年代剩余空間要大,那就會(huì)觸發(fā) full gc。 有永久代的話如果永久代滿了也會(huì)觸發(fā) full gc。 老年代空間不足,大對(duì)象直接在老年代申請(qǐng)分配,如果此時(shí)老年代空間不足則會(huì)觸發(fā) full gc。 擔(dān)保失敗即 promotion failure,新生代的 to 區(qū)放不下從 eden 和 from 拷貝過(guò)來(lái)對(duì)象,或者新生代對(duì)象 gc 年齡到達(dá)閾值需要晉升這兩種情況,老年代如果放不下的話都會(huì)觸發(fā) full gc。 執(zhí)行 System.gc()、jmap -dump 等命令會(huì)觸發(fā) full gc。
知道 TLAB 嗎?來(lái)說(shuō)說(shuō)看
這個(gè)得從內(nèi)存申請(qǐng)說(shuō)起。
一般而言生成對(duì)象需要向堆中的新生代申請(qǐng)內(nèi)存空間,而堆又是全局共享的,像新生代內(nèi)存又是規(guī)整的,是通過(guò)一個(gè)指針來(lái)劃分的。

內(nèi)存是緊湊的,新對(duì)象創(chuàng)建指針就右移對(duì)象大小 size 即可,這叫指針加法(bump [up] the pointer)。
可想而知如果多個(gè)線程都在分配對(duì)象,那么這個(gè)指針就會(huì)成為熱點(diǎn)資源,需要互斥那分配的效率就低了。
于是搞了個(gè) TLAB(Thread Local Allocation Buffer),為一個(gè)線程分配的內(nèi)存申請(qǐng)區(qū)域。
這個(gè)區(qū)域只允許這一個(gè)線程申請(qǐng)分配對(duì)象,允許所有線程訪問(wèn)這塊內(nèi)存區(qū)域。
TLAB 的思想其實(shí)很簡(jiǎn)單,就是劃一塊區(qū)域給一個(gè)線程,這樣每個(gè)線程只需要在自己的那畝地申請(qǐng)對(duì)象內(nèi)存,不需要爭(zhēng)搶熱點(diǎn)指針。
當(dāng)這塊內(nèi)存用完了之后再去申請(qǐng)即可。
這種思想其實(shí)很常見(jiàn),比如分布式發(fā)號(hào)器,每次不會(huì)一個(gè)一個(gè)號(hào)的取,會(huì)取一批號(hào),用完之后再去申請(qǐng)一批。

可以看到每個(gè)線程有自己的一塊內(nèi)存分配區(qū)域,短一點(diǎn)的箭頭代表 TLAB 內(nèi)部的分配指針。
如果這塊區(qū)域用完了再去申請(qǐng)即可。
不過(guò)每次申請(qǐng)的大小不固定,會(huì)根據(jù)該線程啟動(dòng)到現(xiàn)在的歷史信息來(lái)調(diào)整,比如這個(gè)線程一直在分配內(nèi)存那么 TLAB 就大一些,如果這個(gè)線程基本上不會(huì)申請(qǐng)分配內(nèi)存那 TLAB 就小一些。
還有 TLAB 會(huì)浪費(fèi)空間,我們來(lái)看下這個(gè)圖。
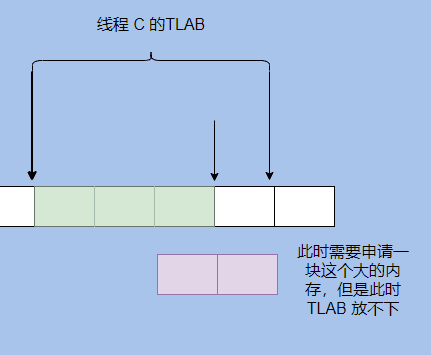
可以看到 TLAB 內(nèi)部只剩一格大小,申請(qǐng)的對(duì)象需要兩格,這時(shí)候需要再申請(qǐng)一塊 TLAB ,之前的那一格就浪費(fèi)了。
在 HotSpot 中會(huì)生成一個(gè)填充對(duì)象來(lái)填滿這一塊,因?yàn)槎研枰€性遍歷,遍歷的流程是通過(guò)對(duì)象頭得知對(duì)象的大小,然后跳過(guò)這個(gè)大小就能找到下一個(gè)對(duì)象,所以不能有空洞。
當(dāng)然也可以通過(guò)空閑鏈表等外部記錄方式來(lái)實(shí)現(xiàn)遍歷。
還有 TLAB 只能分配小對(duì)象,大的對(duì)象還是需要在共享的 eden 區(qū)分配。
所以總的來(lái)說(shuō) TLAB 是為了避免對(duì)象分配時(shí)的競(jìng)爭(zhēng)而設(shè)計(jì)的。
那 PLAB 知道嗎?
可以看到和 TLAB 很像,PLAB 即 Promotion Local Allocation Buffers。
用在年輕代對(duì)象晉升到老年代時(shí)。
在多線程并行執(zhí)行 YGC 時(shí),可能有很多對(duì)象需要晉升到老年代,此時(shí)老年代的指針就“熱”起來(lái)了,于是搞了個(gè) PLAB。
先從老年代 freelist(空閑鏈表) 申請(qǐng)一塊空間,然后在這一塊空間中就可以通過(guò)指針加法(bump the pointer)來(lái)分配內(nèi)存,這樣對(duì) freelist 競(jìng)爭(zhēng)也少了,分配空間也快了。

大致就是上圖這么個(gè)思想,每個(gè)線程先申請(qǐng)一塊作為 PLAB ,然后在這一塊內(nèi)存里面分配晉升的對(duì)象。
這和 TLAB 的思想相似。
產(chǎn)生 concurrent mode failure 真正的原因
《深入理解Java虛擬機(jī)》:由于CMS收集器無(wú)法處理“浮動(dòng)垃圾”(FloatingGarbage),有可能出現(xiàn)“Con-current Mode Failure”失敗進(jìn)而導(dǎo)致另一次完全“Stop The World”的Full GC的產(chǎn)生。
這段話的意思是因?yàn)閽佭@個(gè)錯(cuò)而導(dǎo)致一次 Full GC。
而實(shí)際上是 Full GC 導(dǎo)致拋這個(gè)錯(cuò),我們來(lái)看一下源碼,版本是 openjdk-8。
首先搜一下這個(gè)錯(cuò)。
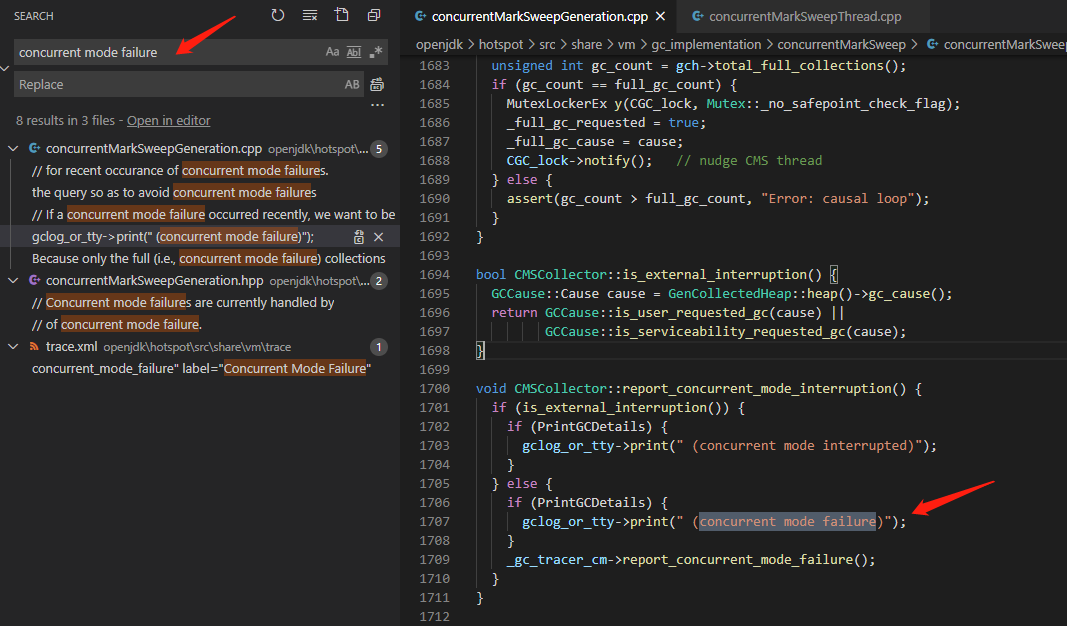
再找找看 ?report_concurrent_mode_interruption 被誰(shuí)調(diào)用。
查到是在 void CMSCollector::acquire_control_and_collect(...) 這個(gè)方法中被調(diào)用的。
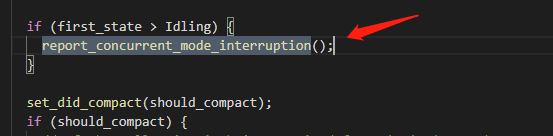
再來(lái)看看 first_state :CollectorState first_state = _collectorState;
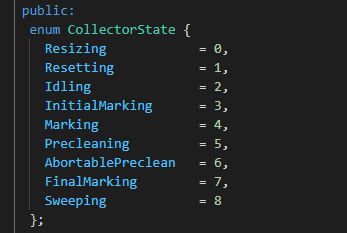
看枚舉已經(jīng)很清楚了,就是在 cms gc 還沒(méi)結(jié)束的時(shí)候。
而 acquire_control_and_collect 這個(gè)方法是 cms 執(zhí)行 foreground gc 的。
cms 分為 ?foreground gc 和 background gc。
foreground 其實(shí)就是 Full gc。
因此是 full gc 的時(shí)候 cms gc 還在進(jìn)行中導(dǎo)致拋這個(gè)錯(cuò)。
究其原因是因?yàn)榉峙渌俾侍鞂?dǎo)致堆不夠用,回收不過(guò)來(lái)因此產(chǎn)生 full gc。
也有可能是發(fā)起 cms gc 設(shè)置的堆的閾值太高。
CMS GC 發(fā)生 concurrent mode failure 時(shí)的 full GC 為什么是單線程的?
以下的回答來(lái)自 R 大。
因?yàn)闆](méi)足夠開(kāi)發(fā)資源,偷懶了。就這么簡(jiǎn)單。沒(méi)有任何技術(shù)上的問(wèn)題。大公司都自己內(nèi)部做了優(yōu)化。
所以最初怎么會(huì)偷這個(gè)懶的呢?多災(zāi)多難的CMS GC經(jīng)歷了多次動(dòng)蕩。它最初是作為Sun Labs的Exact VM的低延遲GC而設(shè)計(jì)實(shí)現(xiàn)的。
但 Exact VM在與 HotSpot VM爭(zhēng)搶 Sun 的正牌 JVM 的內(nèi)部斗爭(zhēng)中失利,CMS GC 后來(lái)就作為 Exact VM 的技術(shù)遺產(chǎn)被移植到了 HotSpot VM上。
就在這個(gè)移植還在進(jìn)行中的時(shí)候,Sun 已經(jīng)開(kāi)始略顯疲態(tài);到 CMS GC 完全移植到 HotSpot VM 的時(shí)候,Sun 已經(jīng)處于快要不行的階段了。
開(kāi)發(fā)資源減少,開(kāi)發(fā)人員流失,當(dāng)時(shí)的 HotSpot VM 開(kāi)發(fā)組能夠做的事情并不多,只能挑重要的來(lái)做。而這個(gè)時(shí)候 Sun Labs 的另一個(gè) GC 實(shí)現(xiàn),Garbage-First GC(G1 GC)已經(jīng)面世。
相比可能在長(zhǎng)時(shí)間運(yùn)行后受碎片化影響的 CMS,G1 會(huì)增量式的整理/壓縮堆里的數(shù)據(jù),避免受碎片化影響,因而被認(rèn)為更具潛力。
于是當(dāng)時(shí)本來(lái)就不多的開(kāi)發(fā)資源,一部分還投給了把G1 GC產(chǎn)品化的項(xiàng)目上——結(jié)果也是進(jìn)展緩慢。
畢竟只有一兩個(gè)人在做。所以當(dāng)時(shí)就沒(méi)能有足夠開(kāi)發(fā)資源去打磨 CMS GC 的各種配套設(shè)施的細(xì)節(jié),配套的備份 full GC 的并行化也就耽擱了下來(lái)。
但肯定會(huì)有同學(xué)抱有疑問(wèn):HotSpot VM不是已經(jīng)有并行GC了么?而且還有好幾個(gè)?
讓我們來(lái)看看:
ParNew:并行的young gen GC,不負(fù)責(zé)收集old gen。 Parallel GC(ParallelScavenge):并行的young gen GC,與ParNew相似但不兼容;同樣不負(fù)責(zé)收集old gen。 ParallelOld GC(PSCompact):并行的full GC,但與ParNew / CMS不兼容。
所以…就是這么一回事。
HotSpot VM 確實(shí)是已經(jīng)有并行 GC 了,但兩個(gè)是只負(fù)責(zé)在 young GC 時(shí)收集 young gen 的,這倆之中還只有 ParNew 能跟 CMS 搭配使用;
而并行 full GC 雖然有一個(gè) ParallelOld,但卻與 CMS GC 不兼容所以無(wú)法作為它的備份 full GC使用。
為什么有些新老年代的收集器不能組合使用比如 ParNew 和 Parallel Old?

這張圖是 2008 年 HostSpot 一位 GC 組成員畫(huà)的,那時(shí)候 G1 還沒(méi)問(wèn)世,在研發(fā)中,所以畫(huà)了個(gè)問(wèn)號(hào)在上面。
里面的回答是 :
"ParNew" is written in a style... "Parallel Old" is not written in the "ParNew" style
HotSpot VM 自身的分代收集器實(shí)現(xiàn)有一套框架,只有在框架內(nèi)的實(shí)現(xiàn)才能互相搭配使用。
而有個(gè)開(kāi)發(fā)他不想按照這個(gè)框架實(shí)現(xiàn),自己寫(xiě)了個(gè),測(cè)試的成績(jī)還不錯(cuò)后來(lái)被 ?HotSpot VM 給吸收了,這就導(dǎo)致了不兼容。
我之前看到一個(gè)回答解釋的很形象:就像動(dòng)車(chē)組車(chē)頭帶不了綠皮車(chē)廂一樣,電氣,掛鉤啥的都不匹配。
新生代的 GC 如何避免全堆掃描?
在常見(jiàn)的分代 GC 中就是利用記憶集來(lái)實(shí)現(xiàn)的,記錄可能存在的老年代中有新生代的引用的對(duì)象地址,來(lái)避免全堆掃描。
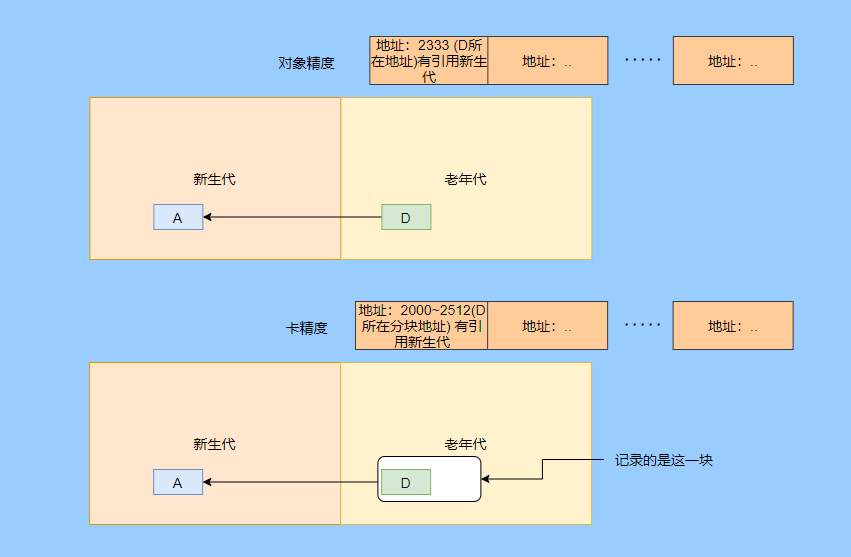
上圖有個(gè)對(duì)象精度的,一個(gè)是卡精度的,卡精度的叫卡表。
把堆中分為很多塊,每塊 512 字節(jié)(卡頁(yè)),用字節(jié)數(shù)組中的一個(gè)元素來(lái)表示某一塊,1表示臟塊,里面存在跨代引用。
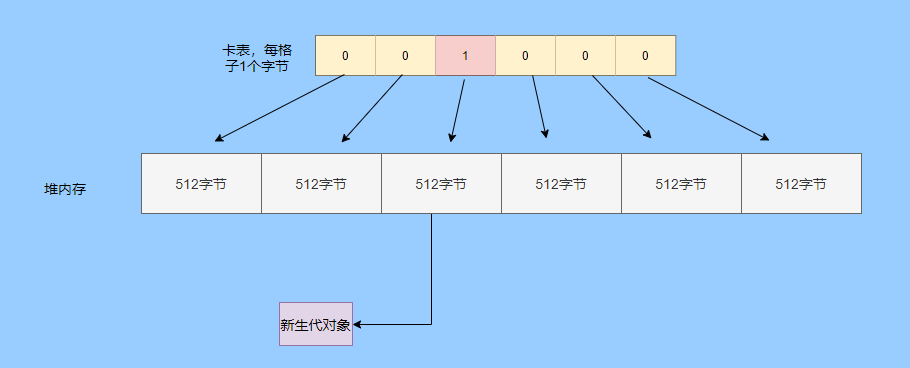
在 Hotspot 中的實(shí)現(xiàn)是卡表,是通過(guò)寫(xiě)后屏障維護(hù)的,偽代碼如下。

cms 中需要記錄老年代指向年輕代的引用,但是寫(xiě)屏障的實(shí)現(xiàn)并沒(méi)有做任何條件的過(guò)濾。
即不判斷當(dāng)前對(duì)象是老年代對(duì)象且引用的是新生代對(duì)象才會(huì)標(biāo)記對(duì)應(yīng)的卡表為臟。
只要是引用賦值都會(huì)把對(duì)象的卡標(biāo)記為臟,當(dāng)然YGC掃描的時(shí)候只會(huì)掃老年代的卡表。
這樣做是減少寫(xiě)屏障帶來(lái)的消耗,畢竟引用的賦值非常的頻繁。
那 cms 的記憶集和 G1 的記憶集有什么不一樣?
cms 的記憶集的實(shí)現(xiàn)是卡表即 card table。
通常實(shí)現(xiàn)的記憶集是 points-out 的,我們知道記憶集是用來(lái)記錄非收集區(qū)域指向收集區(qū)域的跨代引用,它的主語(yǔ)其實(shí)是非收集區(qū)域,所以是 points-out 的。
在 cms 中只有老年代指向年輕代的卡表,用于年輕代 gc。
而 G1 是基于 region 的,所以在 points-out 的卡表之上還加了個(gè) points-into 的結(jié)構(gòu)。
因?yàn)橐粋€(gè) region 需要知道有哪些別的 region 有指向自己的指針,然后還需要知道這些指針在哪些 card 中。
其實(shí) G1 的記憶集就是個(gè) hash table,key 就是別的 region 的起始地址,然后 value 是一個(gè)集合,里面存儲(chǔ)這 card table 的 index。
我們來(lái)看下這個(gè)圖就很清晰了。
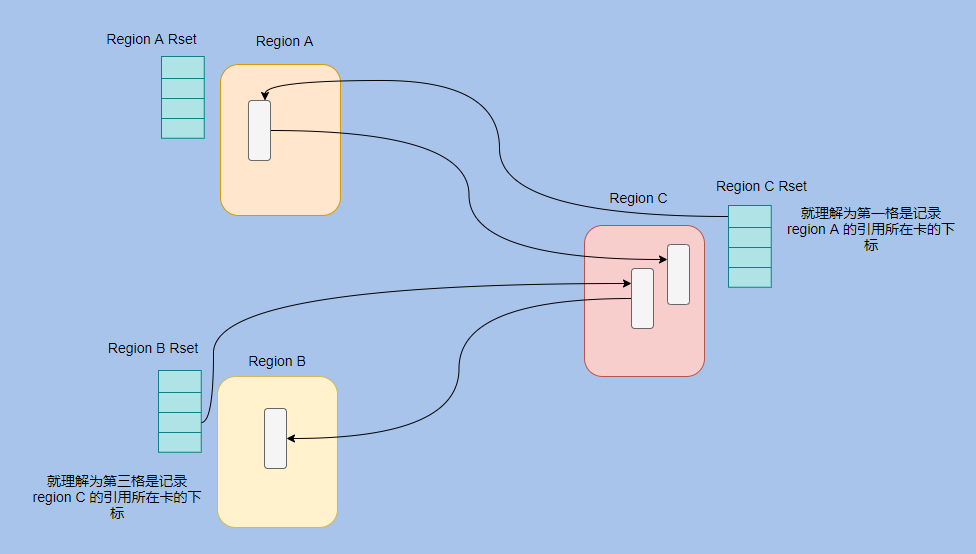
像每次引用字段的賦值都需要維護(hù)記憶集開(kāi)銷(xiāo)很大,所以 G1 的實(shí)現(xiàn)利用了 logging write barrier(下文會(huì)介紹)。
也是異步思想,會(huì)先將修改記錄到隊(duì)列中,當(dāng)隊(duì)列超過(guò)一定閾值由后臺(tái)線程取出遍歷來(lái)更新記憶集。
為什么 G1 不維護(hù)年輕代到老年代的記憶集?
G1 分了 young GC 和 mixed gc。
young gc 會(huì)選取所有年輕代的 region 進(jìn)行收集。
midex gc 會(huì)選取所有年輕代的 region 和一些收集收益高的老年代 region 進(jìn)行收集。
所以年輕代的 region 都在收集范圍內(nèi),所以不需要額外記錄年輕代到老年代的跨代引用。
cms 和 G1 為了維持并發(fā)的正確性分別用了什么手段?
之前文章分析到了并發(fā)執(zhí)行漏標(biāo)的兩個(gè)充分必要條件是:
將新對(duì)象插入已掃描完畢的對(duì)象中,即插入黑色對(duì)象到白色對(duì)象的引用。
刪除了灰色對(duì)象到白色對(duì)象的引用。
cms 和 g1 分別通過(guò)增量更新和 SATB 來(lái)打破這兩個(gè)充分必要條件,維持了 GC 線程與應(yīng)用線程并發(fā)的正確性。
cms 用了增量更新(Incremental update),打破了第一個(gè)條件,通過(guò)寫(xiě)屏障將插入的白色對(duì)象標(biāo)記成灰色,即加入到標(biāo)記棧中,在 remark 階段再掃描,防止漏標(biāo)情況。
G1 用了 SATB(snapshot-at-the-beginning),打破了第二個(gè)條件,會(huì)通過(guò)寫(xiě)屏障把舊的引用關(guān)系記下來(lái),之后再把舊引用關(guān)系再掃描過(guò)。
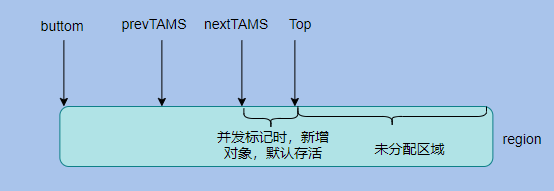
這個(gè)從英文名詞來(lái)看就已經(jīng)很清晰了。講白了就是在 GC 開(kāi)始時(shí)候如果對(duì)象是存活的就認(rèn)為其存活,等于拍了個(gè)快照。
而且 gc 過(guò)程中新分配的對(duì)象也都認(rèn)為是活的。每個(gè) region 會(huì)維持 TAMS (top at mark start)指針,分別是 prevTAMS 和 nextTAMS 分別標(biāo)記兩次并發(fā)標(biāo)記開(kāi)始時(shí)候 Top 指針的位置。
Top 指針就是 region 中最新分配對(duì)象的位置,所以 nextTAMS 和 Top 之間區(qū)域的對(duì)象都是新分配的對(duì)象都認(rèn)為其是存活的即可。
而利用增量更新的 cms 在 remark 階段需要重新所有線程棧和整個(gè)年輕代,因?yàn)榈扔谥暗母行略觯孕枰匦聮呙柽^(guò),如果年輕代的對(duì)象很多的話會(huì)比較耗時(shí)。
要注意這階段是 STW 的,很關(guān)鍵,所以 CMS 也提供了一個(gè) CMSScavengeBeforeRemark 參數(shù),來(lái)強(qiáng)制 remark 階段之前來(lái)一次 YGC。
而 g1 通過(guò) SATB 的話在最終標(biāo)記階段只需要掃描 SATB 記錄的舊引用即可,從這方面來(lái)說(shuō)會(huì)比 cms 快,但是也因?yàn)檫@樣浮動(dòng)垃圾會(huì)比 cms 多。
什么是 logging write barrier ?
寫(xiě)屏障其實(shí)耗的是應(yīng)用程序的性能,是在引用賦值的時(shí)候執(zhí)行的邏輯,這個(gè)操作非常的頻繁,因此就搞了個(gè) logging write barrier。
把寫(xiě)屏障要執(zhí)行的一些邏輯搬運(yùn)到后臺(tái)線程執(zhí)行,來(lái)減輕對(duì)應(yīng)用程序的影響。
在寫(xiě)屏障里只需要記錄一個(gè) log 信息到一個(gè)隊(duì)列中,然后別的后臺(tái)線程會(huì)從隊(duì)列中取出信息來(lái)完成后續(xù)的操作,其實(shí)就是異步思想。
像 SATB write barrier ,每個(gè) Java 線程有一個(gè)獨(dú)立的、定長(zhǎng)的 SATBMarkQueue,在寫(xiě)屏障里只把舊引用壓入該隊(duì)列中。滿了之后會(huì)加到全局 SATBMarkQueueSet。
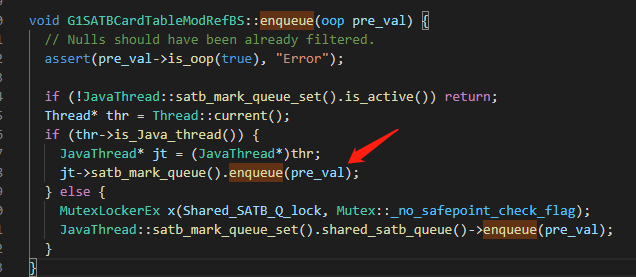
后臺(tái)線程會(huì)掃描,如果超過(guò)一定閾值就會(huì)處理,開(kāi)始 tracing。
在維護(hù)記憶集的寫(xiě)屏障也用了 logging write barrier 。
簡(jiǎn)單說(shuō)下 G1 回收流程
G1 從大局上看分為兩大階段,分別是并發(fā)標(biāo)記和對(duì)象拷貝。
并發(fā)標(biāo)記是基于 STAB 的,可以分為四大階段:
1、初始標(biāo)記(initial marking),這個(gè)階段是 STW 的,掃描根集合,標(biāo)記根直接可達(dá)的對(duì)象即可。在G1中標(biāo)記對(duì)象是利用外部的bitmap來(lái)記錄,而不是對(duì)象頭。
2、并發(fā)階段(concurrent marking),這個(gè)階段和應(yīng)用線程并發(fā),從上一步標(biāo)記的根直接可達(dá)對(duì)象開(kāi)始進(jìn)行 tracing,遞歸掃描所有可達(dá)對(duì)象。STAB 也會(huì)在這個(gè)階段記錄著變更的引用。
3、最終標(biāo)記(final marking), 這個(gè)階段是 STW 的,處理 STAB 中的引用。
4、清理階段(clenaup),這個(gè)階段是 STW 的,根據(jù)標(biāo)記的 bitmap 統(tǒng)計(jì)每個(gè) region 存活對(duì)象的多少,如果有完全沒(méi)存活的 region 則整體回收。
對(duì)象拷貝階段(evacuation),這個(gè)階段是 STW 的。
根據(jù)標(biāo)記結(jié)果選擇合適的 reigon 組成收集集合(collection set 即 CSet),然后將 CSet 存活對(duì)象拷貝到新 region 中。
G1 的瓶頸在于對(duì)象拷貝階段,需要花較多的瓶頸來(lái)轉(zhuǎn)移對(duì)象。
簡(jiǎn)單說(shuō)下 cms 回收流程
其實(shí)從之前問(wèn)題的 CollectorState 枚舉可以得知幾個(gè)流程了。
1、初始標(biāo)記(initial mark),這個(gè)階段是 STW 的,掃描根集合,標(biāo)記根直接可達(dá)的對(duì)象即可。
2、并發(fā)標(biāo)記(Concurrent marking),這個(gè)階段和應(yīng)用線程并發(fā),從上一步標(biāo)記的根直接可達(dá)對(duì)象開(kāi)始進(jìn)行 tracing,遞歸掃描所有可達(dá)對(duì)象。
3、并發(fā)預(yù)清理(Concurrent precleaning),這個(gè)階段和應(yīng)用線程并發(fā),就是想幫重新標(biāo)記階段先做點(diǎn)工作,掃描一下卡表臟的區(qū)域和新晉升到老年代的對(duì)象等,因?yàn)橹匦聵?biāo)記是 STW 的,所以分擔(dān)一點(diǎn)。
4、可中斷的預(yù)清理階段(AbortablePreclean),這個(gè)和上一個(gè)階段基本上一致,就是為了分擔(dān)重新標(biāo)記標(biāo)記的工作。
5、重新標(biāo)記(remark),這個(gè)階段是 STW 的,因?yàn)椴l(fā)階段引用關(guān)系會(huì)發(fā)生變化,所以要重新遍歷一遍新生代對(duì)象、Gc Roots、卡表等,來(lái)修正標(biāo)記。
6、并發(fā)清理(Concurrent sweeping),這個(gè)階段和應(yīng)用線程并發(fā),用于清理垃圾。
7、并發(fā)重置(Concurrent reset),這個(gè)階段和應(yīng)用線程并發(fā),重置 cms 內(nèi)部狀態(tài)。
cms 的瓶頸就在于重新標(biāo)記階段,需要較長(zhǎng)花費(fèi)時(shí)間來(lái)進(jìn)行重新掃描。
cms 寫(xiě)屏障又是維護(hù)卡表,又得維護(hù)增量更新?
卡表其實(shí)只有一份,又得用來(lái)支持 YGC 又得支持 CMS 并發(fā)時(shí)的增量更新肯定是不夠的。
每次 YGC 都會(huì)掃描重置卡表,這樣增量更新的記錄就被清理了。
所以還搞了個(gè) mod-union table,在并發(fā)標(biāo)記時(shí),如果發(fā)生 YGC 需要重置卡表的記錄時(shí),就會(huì)更新 ?mod-union table 對(duì)應(yīng)的位置。
這樣 cms 重新標(biāo)記階段就能結(jié)合當(dāng)時(shí)的卡表和 ?mod-union table 來(lái)處理增量更新,防止漏標(biāo)對(duì)象了。
GC 調(diào)優(yōu)的兩大目標(biāo)是啥?
分別是最短暫停時(shí)間和吞吐量。
最短暫停時(shí)間:因?yàn)?GC 會(huì) STW 暫停所有應(yīng)用線程,這時(shí)候?qū)τ谟脩舳跃偷扔诳D了,因此對(duì)于時(shí)延敏感的應(yīng)用來(lái)說(shuō)減少 STW 的時(shí)間是關(guān)鍵。
吞吐量:對(duì)于一些對(duì)時(shí)延不敏感的應(yīng)用比如一些后臺(tái)計(jì)算應(yīng)用來(lái)說(shuō),吞吐量是關(guān)注的重點(diǎn),它們不關(guān)注每次 GC 停頓的時(shí)間,只關(guān)注總的停頓時(shí)間少,吞吐量高。
舉個(gè)例子:
方案一:每次 GC 停頓 100 ms,每秒停頓 5 次。
方案二:每次 GC 停頓 200 ms,每秒停頓 2 次。
兩個(gè)方案相對(duì)而言第一個(gè)時(shí)延低,第二個(gè)吞吐高,基本上兩者不可兼得。
所以調(diào)優(yōu)時(shí)候需要明確應(yīng)用的目標(biāo)。
GC 如何調(diào)優(yōu)
這個(gè)問(wèn)題在面試中很容易問(wèn)到,抓住核心回答。
現(xiàn)在都是分代 GC,調(diào)優(yōu)的思路就是盡量讓對(duì)象在新生代就被回收,防止過(guò)多的對(duì)象晉升到老年代,減少大對(duì)象的分配。
需要平衡分代的大小、垃圾回收的次數(shù)和停頓時(shí)間。
需要對(duì) GC 進(jìn)行完整的監(jiān)控,監(jiān)控各年代占用大小、YGC 觸發(fā)頻率、Full GC 觸發(fā)頻率,對(duì)象分配速率等等。
然后根據(jù)實(shí)際情況進(jìn)行調(diào)優(yōu)。
比如進(jìn)行了莫名其妙的 Full GC,有可能是某個(gè)第三方庫(kù)調(diào)了 System.gc。
Full GC 頻繁可能是 CMS GC 觸發(fā)內(nèi)存閾值過(guò)低,導(dǎo)致對(duì)象分配不過(guò)來(lái)。
還有對(duì)象年齡晉升的閾值、survivor 過(guò)小等等,具體情況還是得具體分析,反正核心是不變的。
完
? ? ? ?
 ???
???覺(jué)得不錯(cuò),點(diǎn)個(gè)在看~
