
這三個NLP項目寫進簡歷,網(wǎng)申通過率提高50%


01
三大企業(yè)級項目
項目一
京東智能對話系統(tǒng)項目
項目簡介:智能客服機器人已經(jīng)成為了客服系統(tǒng)的重要組成部分,幫助人工客服提升工作效率,為企業(yè)降低人工成本。作為智能客服的行業(yè)先驅(qū),京東多年來致力打造全鏈路的客服機器人,最大化提升商家的接待效率和用戶體驗。目前智能機器人的對話生成策略已經(jīng)在“京小智”、“京東JIMI“等智能客服機器廣泛應用,在用戶購買商品的售前以及售后環(huán)節(jié),為數(shù)千萬用戶以及數(shù)十萬商家進行服務,為商家降本增效,為用戶提升購物客服體驗。
項目二
京東智能營銷文本生成項目
項目三
京東同類商品競價搜索項目
對課程有意向的同學
可掃描二維碼咨詢
??????
課程覆蓋了從經(jīng)典的機器學習、文本處理技術、序列模型、深度學習、預訓練模型、知識圖譜、圖神經(jīng)網(wǎng)絡所有必要的技術,30+項目案例幫助你在實戰(zhàn)中學習成長。5個月時間博導級大咖全程輔導答疑、幫你告別疑難困惑。
?第二部分:文本處理篇
第5章:分詞、詞的標準化、過濾 文本分析流程 中英文的分詞 最大匹配算法 基于語言模型的分詞 Stemming和Lemmazation 停用詞的使用 拼寫糾錯問題 編輯距離的實現(xiàn) 暴力搜索法 基于后驗概率的糾錯 | 第6章:文本的表示 單詞的獨熱編碼表示 句子的獨熱編碼表示 tf-idf表示 句子相似度比較 獨熱編碼下的單詞語義相似度 從獨熱編碼到詞向量 詞向量的可視化、句子向量 |
第7章:【項目作業(yè)】豆瓣電影評分預測 數(shù)據(jù)描述以及任務 中文分詞 獨熱編碼、tf-idf 分布式表示與Word2Vec BERT向量 句子向量 | 第8章:詞向量技術 獨熱編碼表示的優(yōu)缺點 獨熱編碼與分布式表示的比較 靜態(tài)詞向量與動態(tài)詞向量 學習詞向量 - 分布式假設 SkipGram與CBOW SkipGram模型的目標 負采樣(Negative Sampling) 基于矩陣分解的詞向量學習 基于Glove的詞向量學習 在非歐式空間中的詞向量學習 |
第9章:【項目作業(yè)】智能客服問答系統(tǒng) 問答系統(tǒng)和應用場景 問答系統(tǒng)搭建流程 文本的向量化表示 FastText 倒排表技術 問答系統(tǒng)中的召回、排序 | 第10章:語言模型 語言模型的必要性 馬爾科夫假設 Unigram語言模型 Bigram、Trigram語言模型 語言模型的評估 語言模型的平滑技術 |
?第三部分:自然語言處理與深度學習
第11章:深度學習基礎 理解神經(jīng)網(wǎng)絡 各類常見的激活函數(shù) 理解多層神經(jīng)網(wǎng)絡 反向傳播算法 神經(jīng)網(wǎng)絡中的過擬合 淺層模型與深層模型對比 深度學習中的層次表示 | 第12章:Pytorch的使用 環(huán)境安裝 Pytorch與Numpy的語法比較 Pytorch中的Autograd用法 Pytorch的Forward函數(shù) |
第13章:RNN與LSTM 從HMM到RNN模型 RNN中的梯度問題 解決梯度爆炸問題 梯度消失與LSTM LSTM到GRU 雙向LSTM模型 基于LSTM的生成 練習:利用Pytorch實現(xiàn)RNN/LSTM | 第14章:Seq2Seq模型與注意力機制 Seq2Seq模型 Greedy Decoding Beam Search 長依賴所存在的問題 注意力機制 注意力機制的不同實現(xiàn) |
第15章:【項目實戰(zhàn)】京東智能營銷文案生成 構建Seq2Seq模型 Beam Search的改造 模型調(diào)優(yōu) Length Normalization Coverage Normalization 評估標準 Rouge Pointer-Generator Network PGN與Seq2Seq的融合 | 第16章:動態(tài)詞向量與ELMo技術 基于上下文的詞向量技術 圖像識別中的層次表示 文本領域中的層次表示 深度BI-LSTM ELMo模型簡介及優(yōu)缺點 ELMo的訓練與測試 |
第17章:自注意力機制與Transformer 基于LSTM模型的缺點 Transformer結構概覽 理解自注意力機制 位置信息的編碼 理解Encoder與Decoder區(qū)別 理解Transformer的訓練和預測 Transformer的缺點 | 第18章:BERT與ALBERT 自編碼器介紹 Transformer Encoder Masked LM BERT模型及其不同訓練方式 ALBERT |
第19章:【項目實戰(zhàn)】京東智能客服系統(tǒng)項目 對話系統(tǒng)的分類方法 檢索方式與生成方式 對話系統(tǒng)架構 意圖識別分類器 閑聊引擎的搭建 Transformer與BERT的使用 | 第20章:GPT與XLNet Transformer Encoder回顧 GPT-1,GPT-2,GPT-3 ELMo的缺點 語言模型下同時考慮上下文 Permutation LM 雙流自注意力機制 Transformer-XL |
?第四部分、信息抽取
第21章:命名實體識別與實體消歧 信息抽取的應用和關鍵技術 命名實體識別 NER識別常用技術 實體消歧技術 實體消歧常用技術 實體統(tǒng)一技術 指代消解 | 第22章:關系抽取 關系抽取的應用 基于規(guī)則的方法 基于監(jiān)督學習方法 Bootstrap方法 Distant Supervision方法 |
第23章:依存文法分析 從語法分析到依存文法分析 依存文法分析的應用 使用依存文法分析 基于圖算法的依存文法分析 基于Transtion-based的依存文法分析 其他依存文法分析方法論 | 第24章:知識圖譜 知識圖譜以及重要性 知識圖譜中的實體和關系 利用非結構化數(shù)據(jù)構造知識圖譜 知識圖譜的設計 |
第25章:【項目實戰(zhàn)】京東同類商品競價搜索項目 Entity Linking介紹 Entity Linking技術概覽 從商品描述、商品標題中抽取關鍵實體 搭建商品知識圖譜 基于GNN學習商品的詞嵌入 商品的ranking以及相似度計算 |
?第五部分:圖神經(jīng)網(wǎng)絡以及其他前沿主題
第26章:模型的壓縮 模型壓縮的必要性 常見的模型壓縮算法總覽 基于矩陣分解的壓縮技術 從BERT到ALBERT的壓縮 基于貝葉斯模型的壓縮技術 模型的量化 模型的蒸餾方法 | 第27章:圖神經(jīng)網(wǎng)絡 卷積神經(jīng)網(wǎng)絡的回顧 圖神經(jīng)網(wǎng)絡發(fā)展歷程 圖卷積神經(jīng)網(wǎng)絡(GCN) GAT詳解 |
對課程有意向的同學
可掃描二維碼咨詢
??????
03
教學體系
?01 項目講解&實戰(zhàn)幫助
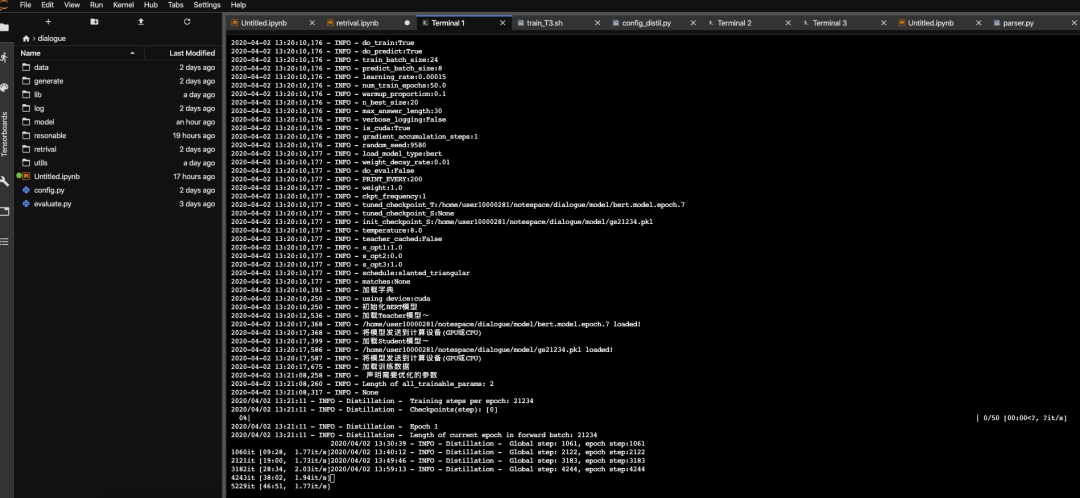
▲節(jié)選往期部分課程安排
?02最佳工業(yè)實戰(zhàn)
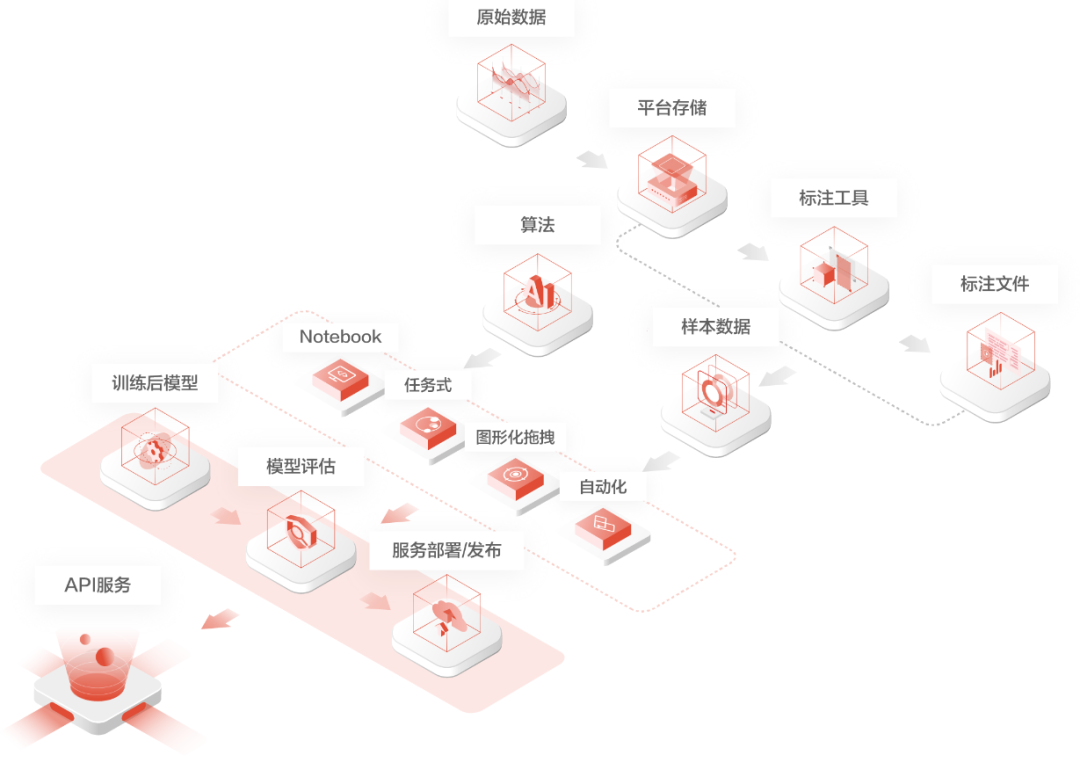
▲源自京東智聯(lián)云AI某模塊架構圖
?03專業(yè)的論文解讀

▲節(jié)選往期部分論文安排
?04代碼解讀&實戰(zhàn)

▲BERT模型代碼實戰(zhàn)講解
?05行業(yè)案例分享

▲專家分享
?06日常社群答疑
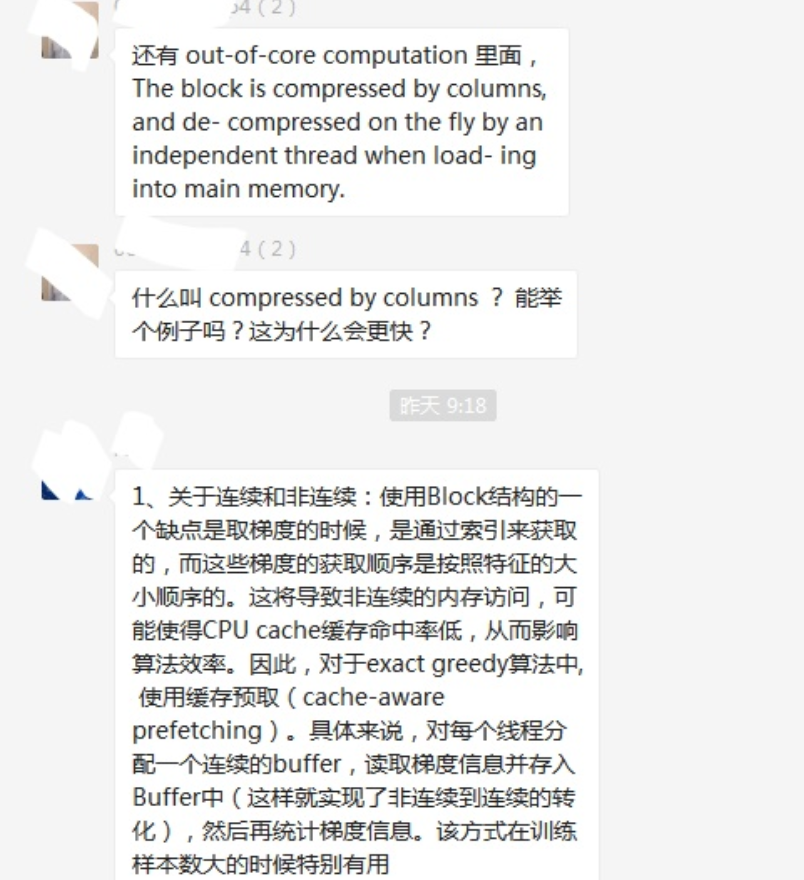
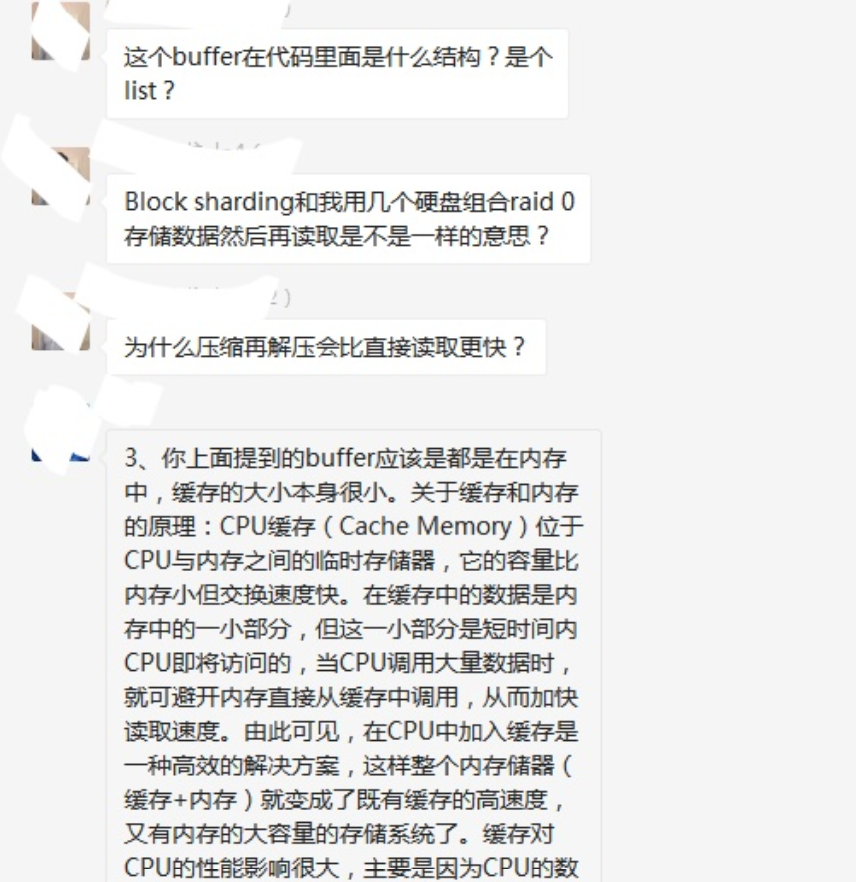
▲社群內(nèi)老師專業(yè)的解答
?07日常作業(yè)&講解

▲課程學習中的小作業(yè)
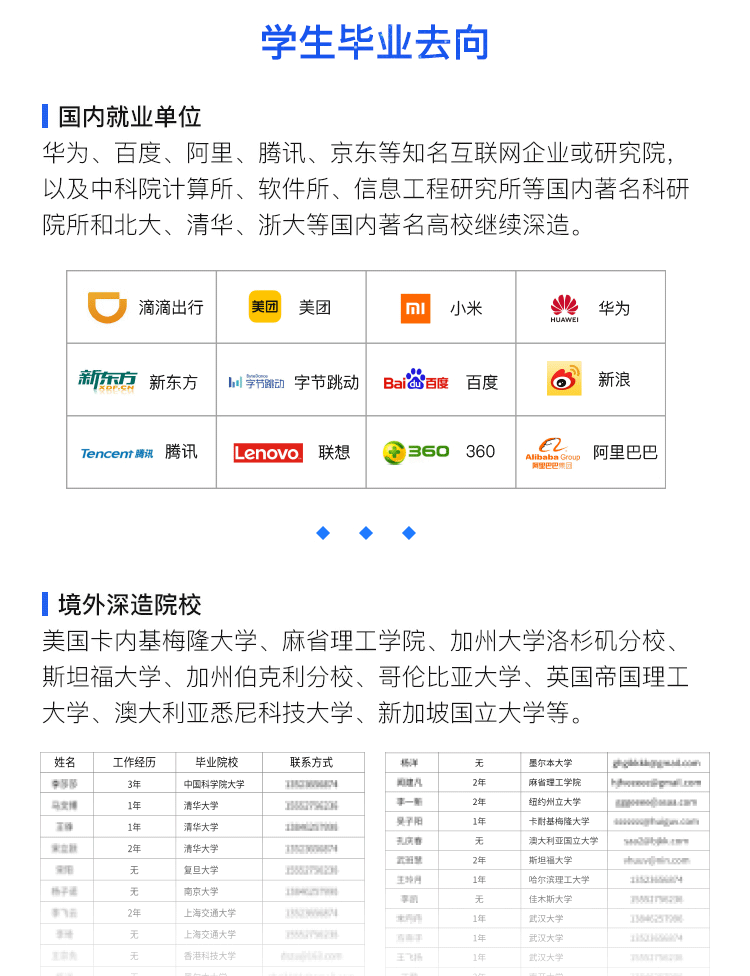
?08學員畢業(yè)去向
04
課程適合哪些學員吶?
大學生:
計算機或者信息領域相關的本科/研究/博士生,畢業(yè)后希望從事AI相關的工作;
希望在真實工業(yè)場景中磨煉技術,提升職場競爭力;
畢業(yè)之后希望申請國內(nèi)外名校的碩士或者博士。
在職人士:
具備良好的工程研發(fā)背景,希望從事AI相關的項目或者工作;
從事AI工作,希望進一步提升NLP實戰(zhàn)經(jīng)驗;
從事NLP工作,希望深入了解模型機理;
AI developer, 希望突破技術瓶頸, 了解NLP前沿信息。
入學標準
1.理工科專業(yè)相關本科生,碩士生或博士生或者IT領域的在職人士;
2.具備很強的動手能力、熟練使用Python編程;
3.具備良好的英文文獻閱讀能力,至少達到CET-4級水平。
對課程有意向的同學
可掃描二維碼咨詢
??????