
老生常談:如何在MySQL中查找數(shù)據(jù)
頁(yè)的組成部分
數(shù)據(jù)庫(kù)中表的數(shù)據(jù)被劃分為若各個(gè)頁(yè)(page),每個(gè)頁(yè)中又存儲(chǔ)了很多行記錄,而我們往MySQL中插入的每行記錄就放到頁(yè)當(dāng)中的行記錄中,InnoDB的頁(yè)分為以下幾個(gè)部分
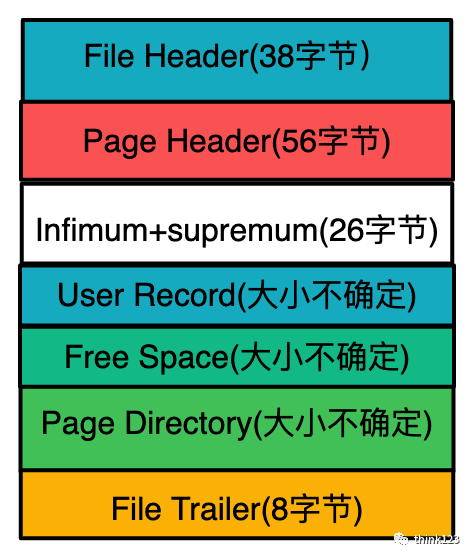
InnoDB的頁(yè)被劃分為了7個(gè)部分,有的部分大小是確定的,有的部分不確定,各個(gè)部分說(shuō)明如下
File Header,表?頁(yè)的?些通?信息,占固定的38字節(jié)。 Page Header,表?數(shù)據(jù)頁(yè)專有的?些信息,占固定的56個(gè)字節(jié)。 Infimum + Supremum,兩個(gè)虛擬的偽記錄,分別表?頁(yè)中的最?和最?記錄,占固定的26個(gè)字節(jié)。 User Records:真實(shí)存儲(chǔ)我們插?的記錄的部分,??不固定。 Free Space:頁(yè)中尚未使?的部分,??不確定。 Page Directory:頁(yè)中的某些記錄相對(duì)位置,也就是各個(gè)槽在頁(yè)?中的地址偏移量,??不固定,插?的記錄越多,這個(gè)部分占?的空間越多。 File Trailer:?于檢驗(yàn)頁(yè)是否完整的部分,占?固定的8個(gè)字節(jié)。
在頁(yè)的7個(gè)組成部分中,我們??存儲(chǔ)的記錄會(huì)按照我們指定的?格式存儲(chǔ)到User Records部分。
但是在?開始?成頁(yè)的時(shí)候,其實(shí)并沒有User Records這個(gè)部分,每當(dāng)我們插??條記錄,都會(huì)從Free Space部分,也就是尚未使?的存儲(chǔ)空間中申請(qǐng)?個(gè)記錄??的空間劃分到User Records部分。
當(dāng)Free Space部分的空間全部被User Records部分替代掉之后,也就意味著這個(gè)頁(yè)使?完了,如果還有新的 記錄插?的話,就需要去申請(qǐng)新的頁(yè)了。
我們往User Records部分插入記錄的時(shí)候,是直接在現(xiàn)有行的末尾(在頂部可用空間部分)或者刪除行留下空間的任何地方插入,而并不是按照主鍵順序插入新行(設(shè)計(jì)到大量數(shù)據(jù)的移動(dòng))。
刪除一條數(shù)據(jù)的時(shí)候mysql并不會(huì)馬上將其中的數(shù)據(jù)回收,而是將這條記錄置為已刪除,下次插入新數(shù)據(jù)的時(shí)候就會(huì)重用這部分空間 但是為了更好的管理頁(yè)中的記錄,MySQL保證了頁(yè)中的記錄在邏輯上是有序的,這是如何做到的呢?
行記錄格式中有一個(gè)next_record字段,它表?從當(dāng)前記錄的真實(shí)數(shù)據(jù)到下?條記錄的真實(shí)數(shù)據(jù)的地址偏移量。
??說(shuō)第?條記錄的next_record值為32,意味著從第?條記錄的真實(shí)數(shù)據(jù)的地址處向后找32個(gè)字節(jié)便是 下?條記錄的真實(shí)數(shù)據(jù)。
關(guān)于行格式可以參見我的上一篇文章
如果你熟悉數(shù)據(jù)結(jié)構(gòu)的話,就?即明?了,這其實(shí)是個(gè)鏈表,可以通過(guò)?條記錄找到它的下?條記錄。但是需要注意注意再注意的?點(diǎn)是,下?條記錄指得并不是按照我們插?順序的下?條記錄,?是按照主鍵值由?到?的順序的下?條記錄。
?且規(guī)定 Infimum記錄(也就是最?記錄) 的下?條記錄就是本頁(yè)中主鍵值最?的?戶記錄,?本頁(yè)中主鍵值最?的?戶記 錄的下?條記錄就是 Supremum記錄(也就是最?記錄) ,為了更形象的表??下這個(gè)next_record起到的作?,我們?箭頭來(lái)替代?下next_record中的地址偏移量
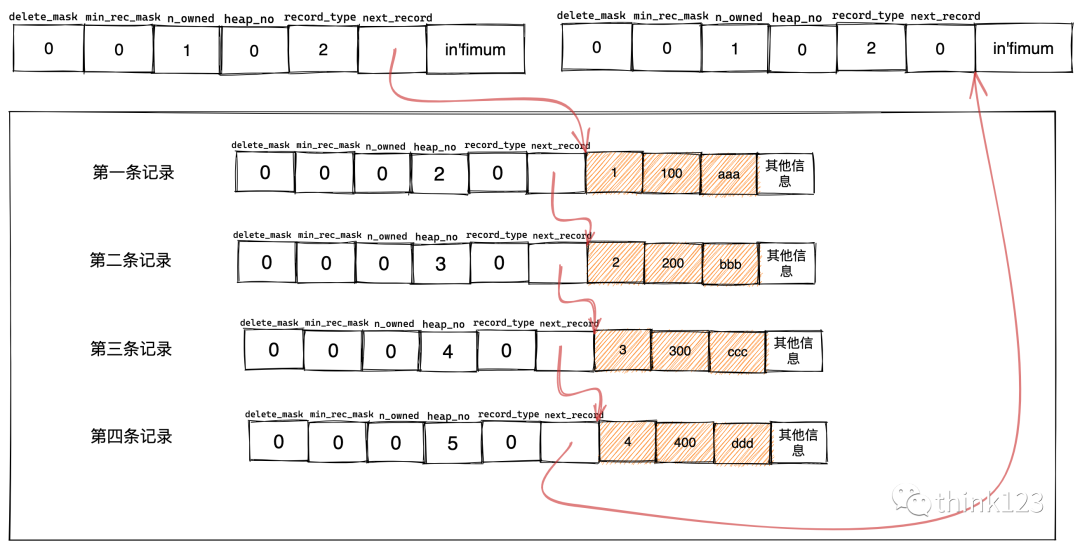
同時(shí)無(wú)論增刪改任何一個(gè)操作,mysql都會(huì)保證這個(gè)鏈表的數(shù)據(jù)是自增的。
頁(yè)目錄
當(dāng)我們?cè)谝粋€(gè)頁(yè)中查詢數(shù)據(jù)的時(shí)候只用從最小記錄開始往后遍歷就能找到我們需要的記錄了,但是如果一個(gè)頁(yè)中記錄數(shù)少還好,如果數(shù)據(jù)比較多,這樣查找下來(lái)就比較耗費(fèi)性能了,mysql當(dāng)然不會(huì)這么干。
我們平常想從?本書中查找某個(gè)內(nèi)容的時(shí)候,?般會(huì)先看?錄,找到需要查找的內(nèi)容對(duì)應(yīng)的書的頁(yè)碼,然后到對(duì)應(yīng)的頁(yè)碼查看內(nèi)容。InnoDB為我們的記錄也制作了?個(gè)類似的?錄,他們的制作過(guò)程是這樣的
將所有正常的記錄(包括最?和最?記錄,不包括標(biāo)記為已刪除的記錄)劃分為?個(gè)組 每個(gè)組的最后?條記錄(也就是組內(nèi)最?的那條記錄)的頭信息中的n_owned屬性表?該記錄擁有多少條記錄,也就是該組內(nèi)共有?條記錄。 將每個(gè)組的最后?條記錄的地址偏移量單獨(dú)提取出來(lái)按順序存儲(chǔ)到靠近?的尾部的地?
這個(gè)地?就是所謂的Page Directory,也就是??錄(此時(shí)應(yīng)該返回頭看看頁(yè)?各個(gè)部分的圖)。頁(yè)??錄中 的這些地址偏移量被稱為槽(英?名:Slot)或者目錄槽,所以這個(gè)頁(yè)??錄就是由槽組成的。
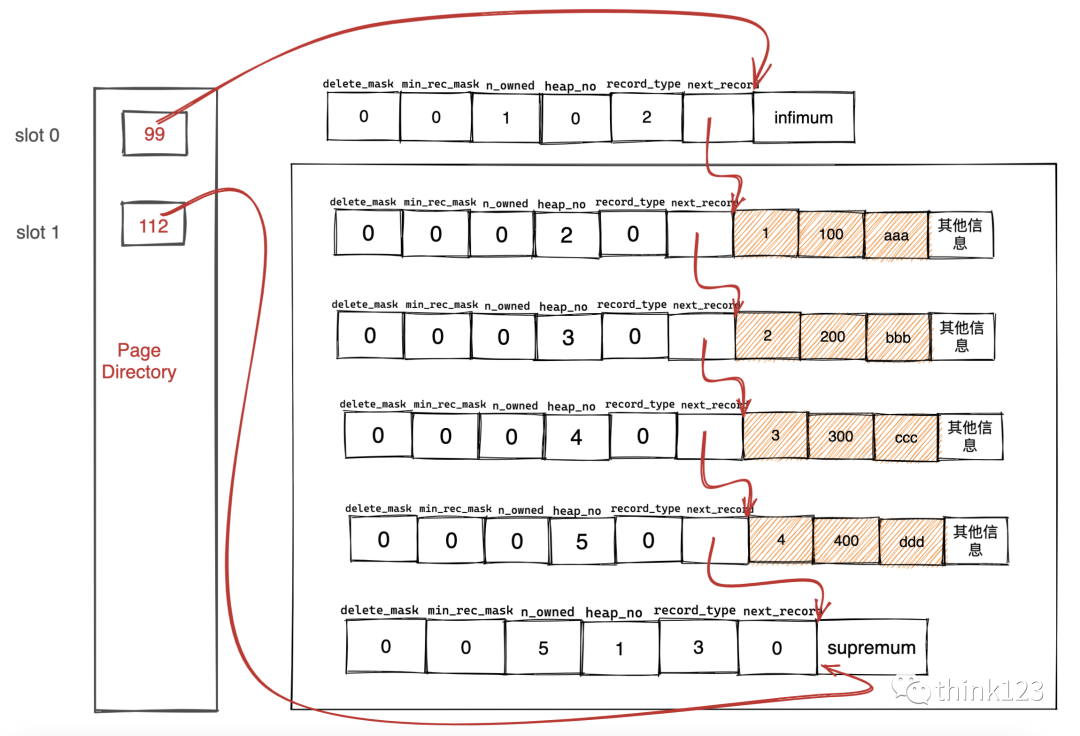
從這個(gè)圖中我們需要注意這么?點(diǎn):
現(xiàn)在??錄部分中有兩個(gè)槽,也就意味著我們的記錄被分成了兩個(gè)組,槽1中的值是112,代表最?記錄的地址偏移量(就是從頁(yè)?的0字節(jié)開始數(shù),數(shù)112個(gè)字節(jié);槽0中的值是99,代表最?記錄的地址偏移量。 注意最?和最?記錄的頭信息中的n_owned屬性 最?記錄的n_owned值為1,這就代表著以最?記錄結(jié)尾的這個(gè)分組中只有1條記錄,也就是最?記錄本?。最?記錄的n_owned值為5,這就代表著以最?記錄結(jié)尾的這個(gè)分組中只有5條記錄,包括最?記錄本?還有我們??插?的4條記錄。
現(xiàn)在我們就可以二分法查找頁(yè)中的記錄了。
比如我想查id=4的數(shù)據(jù),怎么查呢?現(xiàn)在有2個(gè)slot,分別是0和1,所以 設(shè) low = 0, high = 1。
mid = (low + high) /2, 此時(shí)mid=0,查看 slot0對(duì)應(yīng)記錄的主鍵值是最小值,所以 high不變,low = 1 按照第一步公式重新計(jì)算mid=1,此時(shí)查看slot1對(duì)應(yīng)主鍵值為supremum,大于我們要查找的主鍵4,因此數(shù)據(jù)肯定在slot1這個(gè)分組中 現(xiàn)在我們只需要從slot1中最小的記錄開始遍歷鏈表即可找到我們要的那條數(shù)據(jù)了。由于slot都是挨著的,所以slot0的下一條數(shù)據(jù)就是slot1中最小的那條數(shù)據(jù),我們就從這條數(shù)據(jù)開始遍歷就行了。
為了效率,每個(gè)slot組中的記錄數(shù)并不會(huì)太多,關(guān)于分組,innodb有這樣的規(guī)則
對(duì)于最?記錄所在的分組只能有 1 條記錄,最?記錄所在的分組擁有的記錄條數(shù)只能在1到8條之間,剩下的分組中記錄的條數(shù)范圍只能在4到8條之間。
所以分組是按照下邊的步驟進(jìn)?的:初始情況下?個(gè)數(shù)據(jù)頁(yè)?只有最?記錄和最?記錄兩條記錄,它們分屬于兩個(gè)分組。之后每插??條記錄,都會(huì)從??錄中找到主鍵值?本記錄的主鍵值?并且差值最?的槽,然后把該槽對(duì)應(yīng)的記錄的n_owned值加1,表?本組內(nèi)又添加了?條記錄,直到該組中的記錄數(shù)等于8個(gè)。
在?個(gè)組中的記錄數(shù)等于8個(gè)后再插??條記錄時(shí),會(huì)將組中的記錄拆分成兩個(gè)組,?個(gè)組中4條記錄,另?個(gè)5條記錄。這個(gè)過(guò)程會(huì)在??錄中新增?個(gè)槽來(lái)記錄這個(gè)新增分組中最?的那條記錄的偏移量。
Page Header(頁(yè)面頭部)
為了能得到?個(gè)數(shù)據(jù)頁(yè)中存儲(chǔ)的記錄的狀態(tài)信息,?如本頁(yè)中已經(jīng)存儲(chǔ)了多少條記錄,第?條記錄的地址是什么,頁(yè)?錄中存儲(chǔ)了多少個(gè)槽等等,特意在頁(yè)中定義了?個(gè)叫Page Header的部分,它是?結(jié)構(gòu)的第?部分,這個(gè)部分占?固定的56個(gè)字節(jié),專門存儲(chǔ)各種狀態(tài)信息,包括但不限于以下內(nèi)容
頁(yè)目錄中槽數(shù)量 還未使?的空間最?地址,也就是說(shuō)從該地址之后就是Free Space 本頁(yè)中的記錄的數(shù)量(包括最?和最?記錄以及標(biāo)記為刪除的記錄) 第?個(gè)已經(jīng)標(biāo)記為刪除的記錄地址(各個(gè)已刪除的記錄通過(guò)next_record也會(huì)組成?個(gè)單鏈表,這個(gè)單鏈表中的記錄可以被重新利?) 已刪除記錄占?的字節(jié)數(shù) 最后插?記錄的位置 該頁(yè)中記錄的數(shù)量(不包括最?和最?記錄以及被標(biāo)記為刪除的記錄) 當(dāng)前頁(yè)在B+樹中所處的層級(jí) 索引ID,表?當(dāng)前頁(yè)屬于哪個(gè)索引
從這些記錄的內(nèi)容可以看出來(lái),頁(yè)中的狀態(tài)值以及屬性值還是蠻多的,它們占用固定的大小,可見為了充分利用內(nèi)存,大佬們費(fèi)了多少心。
File Header(文件頭部)
File Header針對(duì)各種類型的頁(yè)都通?,也就是說(shuō)不同類型的頁(yè)都會(huì) 以File Header作為第?個(gè)組成部分,它描述了?些針對(duì)各種頁(yè)都通?的?些信息,??說(shuō)這個(gè)頁(yè)的編號(hào)是多少,它的上?個(gè)頁(yè)、下?個(gè)頁(yè)是誰(shuí)等等。
頁(yè)的校驗(yàn)和 當(dāng)前頁(yè)頁(yè)號(hào)(InnoDB通過(guò)頁(yè)號(hào)來(lái)可以唯?定位?個(gè)?) 上一個(gè)頁(yè)頁(yè)號(hào) 下一個(gè)頁(yè)頁(yè)號(hào) 頁(yè)面被最后修改時(shí)對(duì)應(yīng)的日志序列位置(Log Sequence Number) 頁(yè)類型 屬于哪個(gè)表空間
頁(yè)類型分很多種,比如undo日志頁(yè),系統(tǒng)頁(yè),索引頁(yè),blob頁(yè)等,我們存放記錄的數(shù)據(jù)頁(yè)的類型就是所謂的索引?。
而通過(guò)上一頁(yè),下一頁(yè),存儲(chǔ)數(shù)據(jù)的頁(yè)就形成了一個(gè)雙向鏈表了。
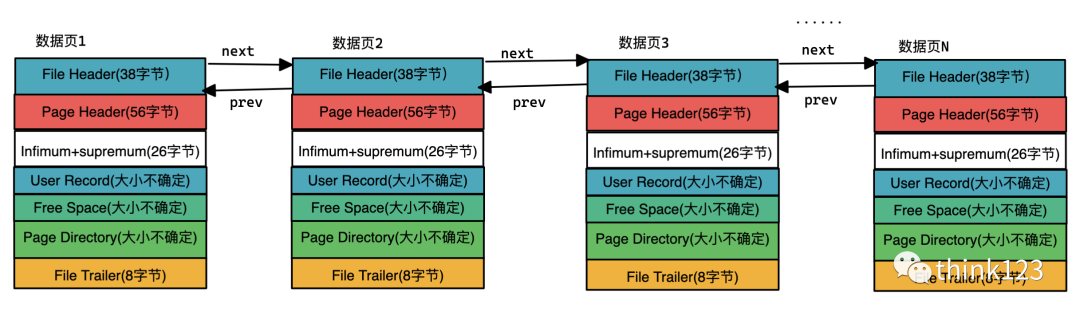
需要注意的是當(dāng)一個(gè)頁(yè)已經(jīng)滿了之后,新插入的記錄就需要插入到新的頁(yè)中,由于必須滿足下?個(gè)數(shù)據(jù)頁(yè)中?戶記錄的主鍵值必須?于上?個(gè)頁(yè)中?戶記錄的主鍵值的要求,所以插入的過(guò)程就會(huì)伴隨著數(shù)據(jù)的移動(dòng)。
假設(shè)頁(yè)A只能插入3條數(shù)據(jù)(注意實(shí)際上能插入很多),分別是1,3,5。現(xiàn)在要插入一條數(shù)據(jù)4,由于頁(yè)A已經(jīng)滿了,所以需要將數(shù)據(jù)插入頁(yè)B中,由于下一個(gè)數(shù)據(jù)頁(yè)的主鍵值必須大于上一頁(yè)的主鍵值,所以要現(xiàn)在5這條數(shù)據(jù)移動(dòng)到頁(yè)B中,然后再把4這條數(shù)據(jù)插入到頁(yè)A中。
File Trailer(文件尾部)
InnoDB存儲(chǔ)引擎會(huì)把數(shù)據(jù)存儲(chǔ)到磁盤上,但是磁盤速度太慢,需要以?為單位把數(shù)據(jù)加載到內(nèi)存中處理,如果該頁(yè)中的數(shù)據(jù)在內(nèi)存中被修改了,那么在修改后的某個(gè)時(shí)間需要把數(shù)據(jù)同步到磁盤 中。但是在同步了?半的時(shí)候中斷電了咋辦,這不是莫名尷尬么?
為了檢測(cè)?個(gè)頁(yè)是否完整(也就是在同步的時(shí)候有沒有發(fā)?只同步?半的尷尬情況),F(xiàn)ile Trailer應(yīng)運(yùn)而生,這個(gè)部分由8個(gè)字節(jié)組成,可以分成2個(gè)?部分:
前4個(gè)字節(jié)代表頁(yè)的校驗(yàn)和 這個(gè)部分是和File Header中的校驗(yàn)和相對(duì)應(yīng)的。
每當(dāng)?個(gè)頁(yè)?在內(nèi)存中修改了,在同步之前就要把它的校驗(yàn)和算出來(lái),因?yàn)镕ile Header在頁(yè)?的前邊,所以校驗(yàn)和會(huì)被?先同步到磁盤,當(dāng)完全寫完時(shí),校驗(yàn)和也會(huì)被寫到頁(yè)的尾部,如果完全同步成功,則頁(yè)的?部和尾部的校驗(yàn)和應(yīng)該是?致的。
如果寫了?半?斷電了,那么在File Header中的校驗(yàn)和就代表著已經(jīng)修改過(guò)的頁(yè),?在File Trialer中的校驗(yàn)和代表著原先的頁(yè),?者不同則意味著同步中間出了錯(cuò)。
后4個(gè)字節(jié)代表頁(yè)?被最后修改時(shí)對(duì)應(yīng)的?志序列位置(LSN) 這個(gè)部分也是為了校驗(yàn)頁(yè)的完整性的,只不過(guò)我們?前還沒說(shuō)LSN是個(gè)什么意思,所以?家可以先不?管這個(gè)屬性。這個(gè)File Trailer與File Header類似,都是所有類型的頁(yè)通?的。
索引
現(xiàn)在我們知道了如何在一個(gè)頁(yè)中快速查找某一條數(shù)據(jù),但是如果我們的數(shù)據(jù)量很大,分散在很多頁(yè)中,那應(yīng)該如何查找呢?只能一頁(yè)一頁(yè)進(jìn)行遍歷嗎?
當(dāng)然不是,我們同樣可以借鑒書本目錄的做法,給數(shù)據(jù)頁(yè)建立一個(gè)索引目錄結(jié)構(gòu)。
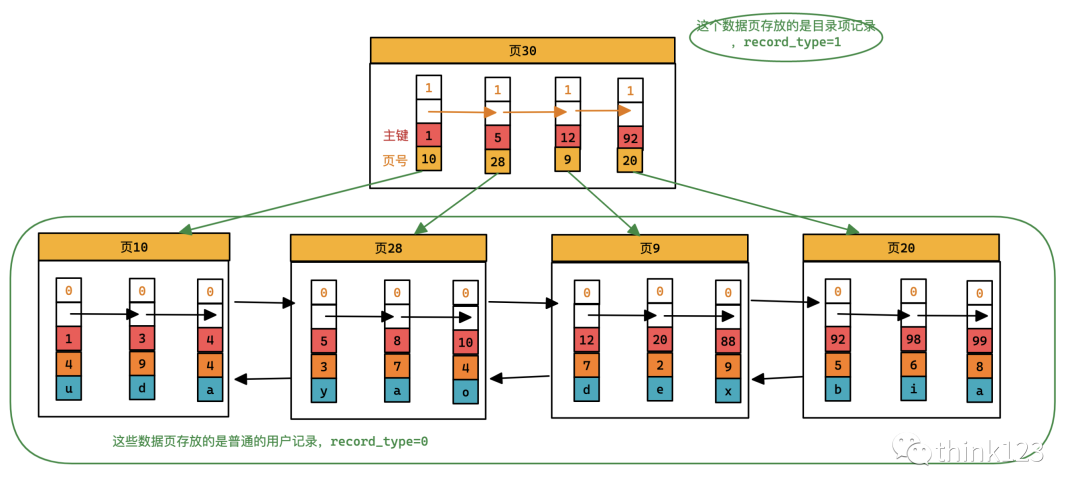
從圖中可以看出來(lái),我們新分配了?個(gè)編號(hào)為30的頁(yè)來(lái)專門存儲(chǔ)?錄項(xiàng)記錄。這?再次強(qiáng)調(diào)?遍?錄項(xiàng)記錄和普通的?戶記錄的不同點(diǎn):
?錄項(xiàng)記錄的record_type值是1,?普通?戶記錄的record_type值是0。 ?錄項(xiàng)記錄只有主鍵值和頁(yè)的編號(hào)兩個(gè)列,?普通的?戶記錄的列是?戶??定義的,可能包含很多列,另外還有InnoDB??添加的隱藏列。
上面的圖中為了簡(jiǎn)單,隱藏了最大最小記錄,沒有畫出來(lái)并不代表沒有哈。
雖然說(shuō)?錄項(xiàng)記錄中只存儲(chǔ)主鍵值和對(duì)應(yīng)的頁(yè)號(hào),??戶記錄需要的存儲(chǔ)空間?多了,但是不論怎么說(shuō)?個(gè)頁(yè)只有16KB??,能存放的?錄項(xiàng)記錄也是有限的,那如果表中的數(shù)據(jù)太多,以?于?個(gè)數(shù)據(jù)頁(yè)不 ?以存放所有的?錄項(xiàng)記錄,該咋辦呢?當(dāng)然是再多整?個(gè)存儲(chǔ)?錄項(xiàng)記錄的頁(yè)
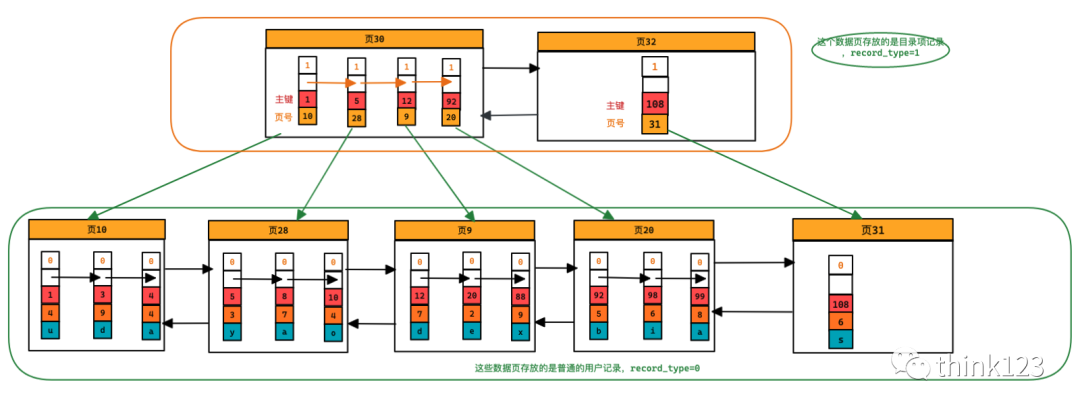
當(dāng)我們存儲(chǔ)的記錄越多,那么目錄項(xiàng)記錄也就越多,存儲(chǔ)目錄項(xiàng)的頁(yè)也就越多,好像這就又回到了最初的問題,那又怎么解決呢?還是同樣的解法,給這些目錄項(xiàng)的頁(yè)生成一個(gè)更高層的目錄就行了,就如下圖
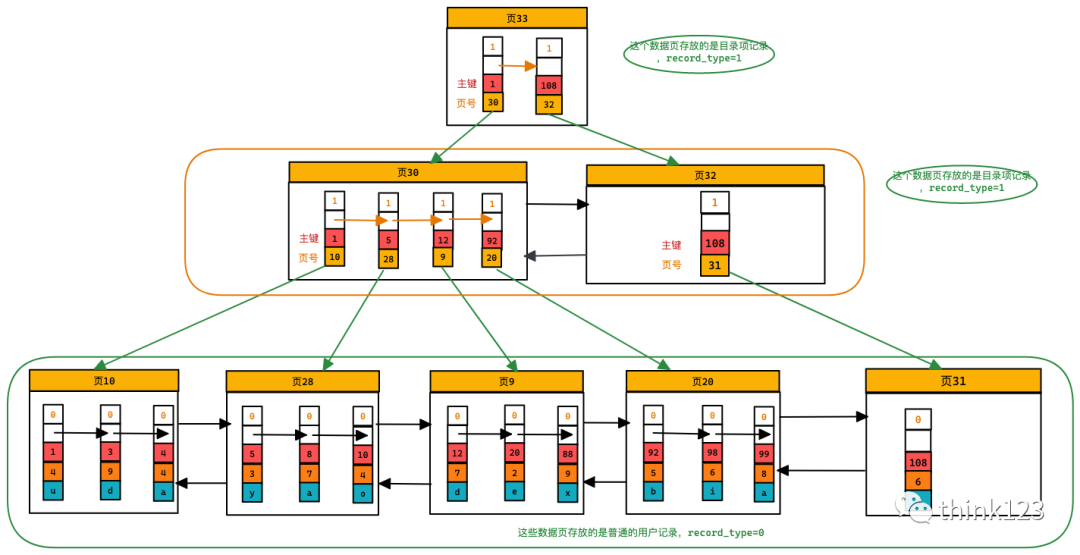
這樣當(dāng)我們要查詢某個(gè)值的時(shí)候,直接從最頂層開始過(guò)濾,然后沿著這個(gè)目錄結(jié)構(gòu)過(guò)濾就行了。
你看看這個(gè)結(jié)構(gòu)是不是很熟悉,就是一顆咱們熟悉的樹嘛,這個(gè)數(shù)據(jù)結(jié)構(gòu)叫B+樹。
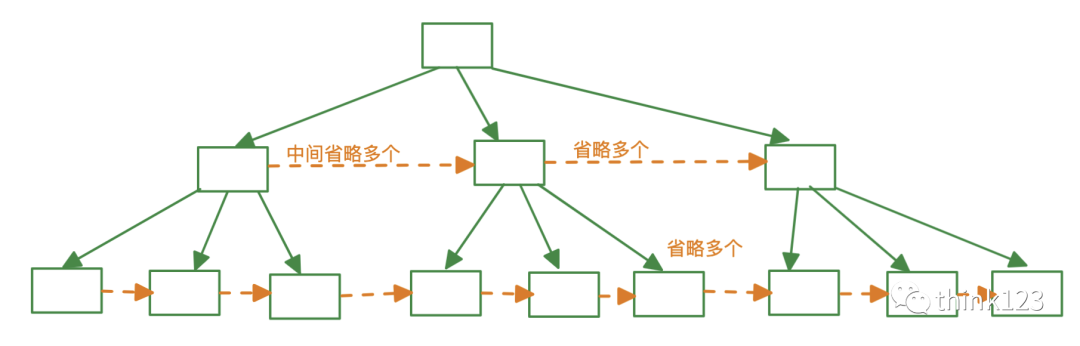
不論是存放?戶記錄的數(shù)據(jù)頁(yè),還是存放?錄項(xiàng)記錄的數(shù)據(jù)頁(yè),我們都把它們存放到B+樹這個(gè)數(shù)據(jù)結(jié)構(gòu)中了,所以我們也稱這些數(shù)據(jù)頁(yè)為節(jié)點(diǎn)。
從圖中可以看出來(lái),我們的實(shí)際?戶記錄其實(shí)都存放在 B+樹的最底層的節(jié)點(diǎn)上,這些節(jié)點(diǎn)也被稱為葉?節(jié)點(diǎn)或葉節(jié)點(diǎn),其余?來(lái)存放?錄項(xiàng)的節(jié)點(diǎn)稱為?葉?節(jié)點(diǎn)或者內(nèi)節(jié)點(diǎn),其中B+樹最上邊的那個(gè)節(jié)點(diǎn)也稱為根節(jié)點(diǎn)。
上面建立的索引有兩個(gè)特點(diǎn)
所有數(shù)據(jù)(包括隱藏列)都存儲(chǔ)在葉子節(jié)點(diǎn)中(最底層節(jié)點(diǎn)) 無(wú)論是頁(yè)內(nèi)的記錄還是頁(yè)都是按照主鍵進(jìn)行排序的
我們把具有這兩種特性的B+樹稱為聚簇索引,所有完整的?戶記錄都存放在這個(gè)聚簇索引的葉?節(jié)點(diǎn)處。InnoDB存儲(chǔ)引擎會(huì)?動(dòng)的為我們創(chuàng)建聚簇索引。
二級(jí)索引
上面的聚簇索引,只有搜索條件是主鍵的時(shí)候才能發(fā)揮作用,因?yàn)锽+樹中數(shù)據(jù)是按照主鍵進(jìn)行排序的。如果我有下面的表,給a建立了一個(gè)索引,應(yīng)該如何處理?
CREATE?TABLE?`test`?(
??`id`?int(11)?NOT?NULL?AUTO_INCREMENT,
??`a`?int(11)?NOT?NULL,
??`b`?char(1)?NOT?NULL,
??PRIMARY?KEY?(`id`),
??KEY?idx_a(a),
??KEY?idx_a_b(a,b)
)
在InnoDB中,會(huì)為每個(gè)索引都創(chuàng)建一個(gè)B+樹,排序規(guī)則則是按照索引列進(jìn)行排序的,比如我們根據(jù)a建立了一個(gè)索引,那么這顆B+樹就長(zhǎng)這樣
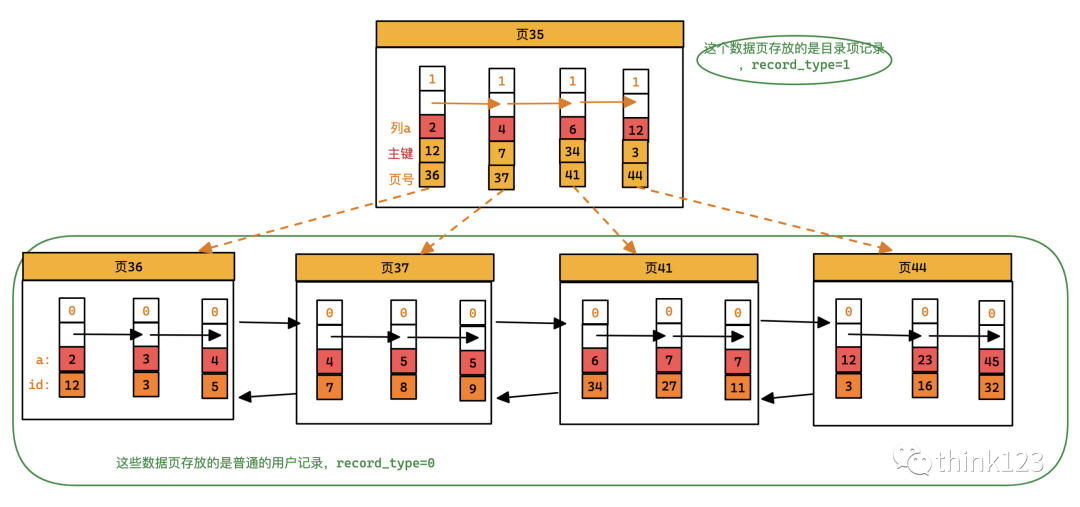
這個(gè)B+樹和上面聚簇索引有幾點(diǎn)不同。
頁(yè)內(nèi)的記錄是按照列a的??順序排成?個(gè)單向鏈表。 各個(gè)存放?戶記錄的頁(yè)也是根據(jù)頁(yè)中記錄的列a??順序排成?個(gè)雙向鏈表。 存放?錄項(xiàng)記錄的頁(yè)分為不同的層次,在同?層次中的頁(yè)也是根據(jù)頁(yè)中?錄項(xiàng)記錄的列a??順序排成?個(gè)雙向鏈表。 B+樹的葉?節(jié)點(diǎn)存儲(chǔ)的并不是完整的?戶記錄,?只是列a+主鍵這兩個(gè)列的值 ?錄項(xiàng)記錄中不再是主鍵+?號(hào)的搭配,?變成了列a+主鍵id+?號(hào)的搭配
目錄項(xiàng)記錄為什么是列a+主鍵id+頁(yè)號(hào),而不是列a+頁(yè)號(hào)呢?
假設(shè)我們目錄項(xiàng)記錄是 列a+頁(yè)號(hào),當(dāng)我們?cè)诓迦胍粭l數(shù)據(jù) (13,4,8)的時(shí)候,這條數(shù)據(jù)應(yīng)該放入到頁(yè)36還是頁(yè)37呢??
這兩個(gè)頁(yè)中都有a=4的數(shù)據(jù)呢,innodb也不知道,所以為了為了讓新插?記錄能找到??在那個(gè)頁(yè)?,我們需要保證在B+樹的同?層節(jié)點(diǎn)的?錄項(xiàng)記錄除?號(hào)這個(gè)字段以外是唯?的。因此目錄項(xiàng)記錄是 列a+id+頁(yè)號(hào)。
我們?cè)俨?記錄(13, 4, 8)時(shí),由于?35中存儲(chǔ)的?錄項(xiàng)記錄是由列a + 主鍵 + ?號(hào)的值構(gòu)成的,可以先把新記錄的列a的值和?35中各?錄項(xiàng)記錄的列a的值作?較,如果列a的值相同的話,可以 接著?較主鍵值,因?yàn)锽+樹同?層中不同?錄項(xiàng)記錄的列a + 主鍵的值肯定是不?樣的,所以最后肯定能定位唯?的?條?錄項(xiàng)記錄,在本例中最后確定新記錄應(yīng)該被插?到?37中。
現(xiàn)在B+樹有了,那么我們應(yīng)該怎么搜索呢?
以查找列a的值為4的記錄為例,查找過(guò)程如下:
確定?錄項(xiàng)記錄頁(yè),根據(jù)根??,也就是?35,可以快速定位到?錄項(xiàng)記錄所在的頁(yè)為?37。 通過(guò)?錄項(xiàng)記錄頁(yè)確定?戶記錄真實(shí)所在的頁(yè)。在?37中可以快速定位到實(shí)際存儲(chǔ)?戶記錄的頁(yè),但是由于列a并沒有唯?性約束,所以列a值為4的記錄可能分布在多個(gè)數(shù)據(jù)頁(yè)中,又因?yàn)? < 4 ≤ 4,所以確定實(shí)際存儲(chǔ)?戶記錄的頁(yè)在?36和? 37中。 在真實(shí)存儲(chǔ)?戶記錄的頁(yè)中定位到具體的記錄。到?36和?37中定位到具體的記錄。 但是這個(gè)B+樹的葉?節(jié)點(diǎn)中的記錄只存儲(chǔ)了a和id(也就是主鍵)兩個(gè)列,所以我們必須再根據(jù)主鍵值去聚簇索引中再查找?遍完整的?戶記錄。
根據(jù)這個(gè)以列a??排序的B+樹只能確定我們要查找記錄的主鍵值,所以如果我們想根據(jù)列a的值查找到完整的?戶記錄的話,仍然需要到聚簇索引中再查?遍,這個(gè)過(guò)程也被稱為回表。?
也就是根據(jù)列a的值查詢?條完整的?戶記錄需要使?到2棵B+樹!!!
為什么我們還需要?次回表操作呢?直接把完整的?戶記錄放到葉?節(jié)點(diǎn)不就好了么?
你說(shuō)的對(duì),如果把完整的?戶記錄放到葉?節(jié)點(diǎn)是可以不?回表,但是太占地?了呀~相當(dāng)于每建??棵B+樹都需要把 所有的?戶記錄再都拷貝?遍,這就有點(diǎn)太浪費(fèi)存儲(chǔ)空間了。因?yàn)檫@種按照?主鍵列建?的B+樹需要?次回表操作才可以定位到完整的?戶記錄,所以這種B+樹也被稱為?級(jí)索引(英?名secondary index),或者輔助索引。
聯(lián)合索引
當(dāng)然也可以同時(shí)以多個(gè)列的??作為排序規(guī)則,也就是同時(shí)為多個(gè)列建?索引,??說(shuō)我們想讓B+樹按照a和b列的??進(jìn)?排序,這個(gè)包含兩層含義:
先把各個(gè)記錄和頁(yè)按照a列進(jìn)?排序。 在記錄的a列相同的情況下,采?b列進(jìn)?排序 為a和b列建?的索引的?意圖如下:
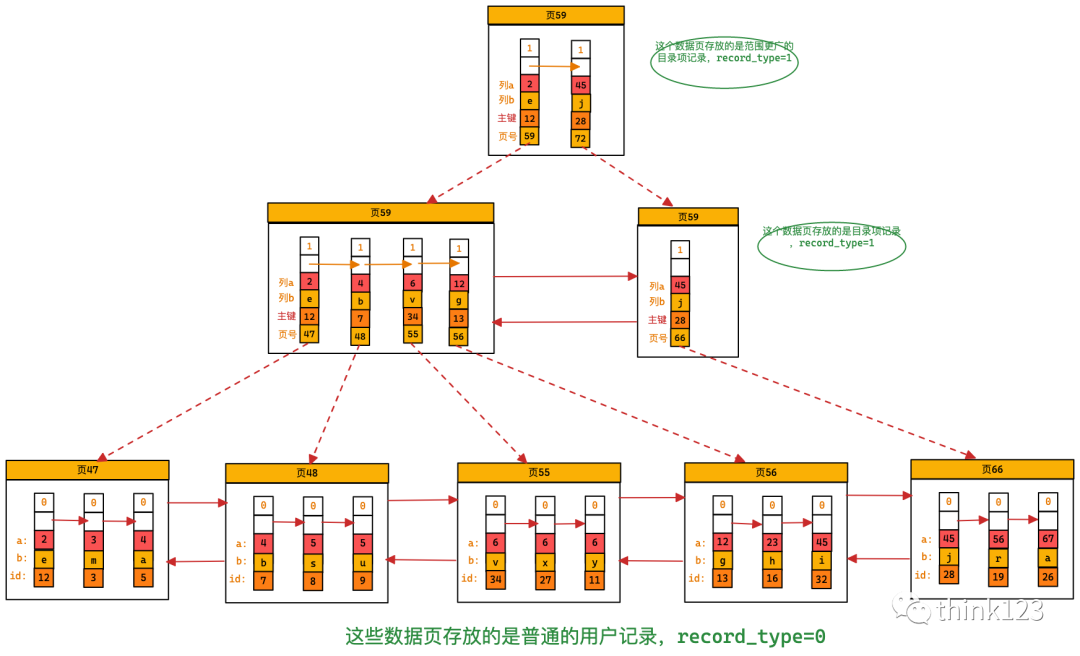
聯(lián)合索引本質(zhì)也是個(gè)二級(jí)索引
B+樹根頁(yè)面
每當(dāng)為某個(gè)表創(chuàng)建?個(gè)B+樹索引(聚簇索引不是?為創(chuàng)建的,默認(rèn)就有)的時(shí)候,都會(huì)為這個(gè)索引創(chuàng)建?個(gè)根節(jié)點(diǎn)頁(yè)?。最開始表中沒有數(shù)據(jù)的時(shí)候,每個(gè)B+樹索引對(duì)應(yīng)的根節(jié)點(diǎn)中既沒有?戶記錄, 也沒有?錄項(xiàng)記錄。 隨后向表中插??戶記錄時(shí),先把?戶記錄存儲(chǔ)到這個(gè)根節(jié)點(diǎn)中。 當(dāng)根節(jié)點(diǎn)中的可?空間?完時(shí)繼續(xù)插?記錄,此時(shí)會(huì)將根節(jié)點(diǎn)中的所有記錄復(fù)制到?個(gè)新分配的頁(yè),?如?a中,然后對(duì)這個(gè)新頁(yè)進(jìn)??分裂的操作,得到另?個(gè)新頁(yè),?如?b。這時(shí)新插?的記錄根據(jù) 鍵值(也就是聚簇索引中的主鍵值,?級(jí)索引中對(duì)應(yīng)的索引列的值)的??就會(huì)被分配到?a或者?b中,?根節(jié)點(diǎn)便升級(jí)為存儲(chǔ)?錄項(xiàng)記錄的頁(yè)。
這個(gè)過(guò)程需要?家特別注意的是:?個(gè)B+樹索引的根節(jié)點(diǎn)?誕?之?起,便不會(huì)再移動(dòng)。這樣只要我們對(duì)某個(gè)表建??個(gè)索引,那么它的根節(jié)點(diǎn)的頁(yè)號(hào)便會(huì)被記錄到某個(gè)地?,然后凡是InnoDB存儲(chǔ)引擎需 要?到這個(gè)索引的時(shí)候,都會(huì)從那個(gè)固定的地?取出根節(jié)點(diǎn)的頁(yè)號(hào),從?來(lái)訪問這個(gè)索引。
這個(gè)固定的地方就是我們之前提到過(guò)的數(shù)據(jù)字典信息
我們平時(shí)是以記錄為單位來(lái)向表中插?數(shù)據(jù)的,這些記錄在磁盤上的存放?式也被稱為?格式或者記錄格式。InnoDB有4種不同類型的?格式,分別 是Compact、Redundant、Dynamic和Compressed?格式,隨著時(shí)間的推移,他們可能會(huì)設(shè)計(jì)出更多的?格式,但是不管怎么變,在原理上?體都是相同的。
MyIsam
InnoDB中聚簇索引葉子節(jié)點(diǎn)會(huì)包含所有數(shù)據(jù),MyISAM索引方案雖然也是使用的樹形結(jié)果,但是其數(shù)據(jù)和索引是分開的。
MyISAM將表中的記錄按照記錄的插?順序單獨(dú)存儲(chǔ)在?個(gè)?件中,稱之為數(shù)據(jù)?件。這個(gè)?件并不劃分為若?個(gè)數(shù)據(jù)頁(yè),有多少記錄就往這個(gè)?件中塞多少記錄就成了。我們可以通過(guò)?號(hào)?快速訪問到? 條記錄.
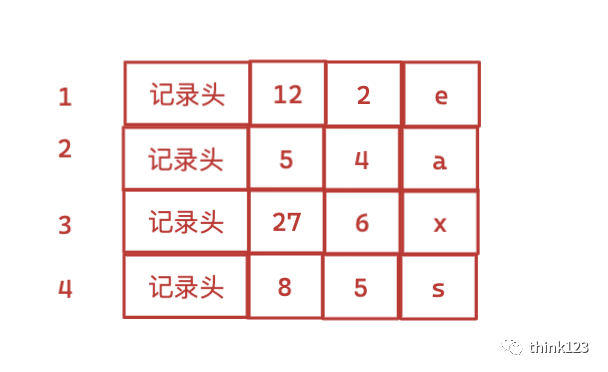
myisam行記錄格式是static(定長(zhǎng))時(shí),可以通過(guò)行號(hào)找到數(shù)據(jù),如果是變長(zhǎng)記錄格式時(shí),那么MyISAM會(huì)直接在索引葉?節(jié)點(diǎn)處存儲(chǔ)該條記錄在數(shù)據(jù)?件中的地址偏移量,可以直接通過(guò)這個(gè)偏移量找到文件中的數(shù)據(jù)
由于在插?數(shù)據(jù)的時(shí)候并沒有刻意按照主鍵??排序,所以我們并不能在這些數(shù)據(jù)上使??分法進(jìn)?查找。?
使?MyISAM存儲(chǔ)引擎的表會(huì)把索引信息另外存儲(chǔ)到?個(gè)稱為索引?件的另?個(gè)?件中。MyISAM會(huì)單獨(dú)為表的主鍵創(chuàng)建?個(gè)索引,只不過(guò)在索引的葉?節(jié)點(diǎn)中存儲(chǔ)的不是完整的?戶記錄,?是主鍵值 + ?號(hào)的組合。也就是先通過(guò)索引找到對(duì)應(yīng)的?號(hào),再通過(guò)?號(hào)去找對(duì)應(yīng)的記錄!
這?點(diǎn)和InnoDB是完全不相同的,在InnoDB存儲(chǔ)引擎中,我們只需要根據(jù)主鍵值對(duì)聚簇索引進(jìn)??次查找就能找到對(duì)應(yīng)的記錄,?在MyISAM中卻需要進(jìn)??次回表操作,意味著MyISAM中建?的索引相 當(dāng)于全部都是?級(jí)索引!
如果有需要的話,我們也可以對(duì)其它的列分別建?索引或者建?聯(lián)合索引,原理和InnoDB中的索引差不多,不過(guò)在葉?節(jié)點(diǎn)處存儲(chǔ)的是相應(yīng)的列 + ?號(hào)。這些索引也全部都是?級(jí)索引。
參考資料
<<從根兒上理解MySQL>>