
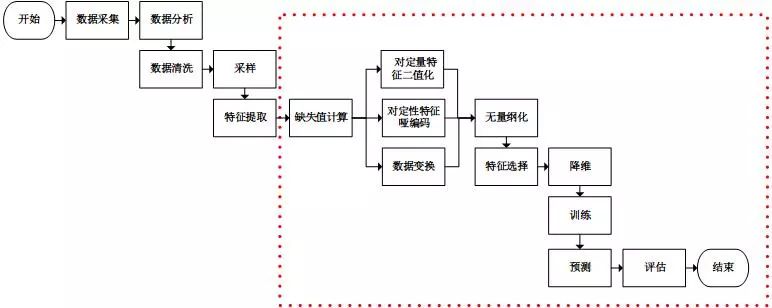
干貨!如何使用 sklearn 優(yōu)雅地進(jìn)行數(shù)據(jù)挖掘?

一、使用sklearn數(shù)據(jù)挖掘

def?fit(self,?X,?y=None):????????
"""Do?nothing?and?return?the?estimator?unchanged????????
This?method?is?just?there?to?implement?the?usual?API?and?hence????????
work?in?pipelines."""????????
??X?=?check_array(X,?accept_sparse='csr')????????
??return?self
在此,我們?nèi)匀皇褂肐RIS數(shù)據(jù)集來進(jìn)行說明。為了適應(yīng)提出的場景,對原數(shù)據(jù)集需要稍微加工:
ffrom?numpy?import?hstack,?vstack,?array,?median,?nan
from?numpy.random?import?choice
from?sklearn.datasets?import?load_iris
iris?=?load_iris()
#特征矩陣加工
#使用vstack增加一行含缺失值的樣本(nan,?nan,?nan,?nan)
#使用hstack增加一列表示花的顏色(0-白、1-黃、2-紅),花的顏色是隨機的,意味著顏色并不影響花的分類
iris.data?=?hstack((choice([0,?1,?2],?size=iris.data.shape[0]+1).reshape(-1,1),?vstack((iris.data,?array([nan,?nan,?nan,?nan]).reshape(1,-1)))))
#目標(biāo)值向量加工
#增加一個目標(biāo)值,對應(yīng)含缺失值的樣本,值為眾數(shù)
iris.target?=?hstack((iris.target,?array([median(iris.target)])))
并行處理,流水線處理,自動化調(diào)參,持久化是使用sklearn優(yōu)雅地進(jìn)行數(shù)據(jù)挖掘的核心。并行處理和流水線處理將多個特征處理工作,甚至包括模型訓(xùn)練工作組合成一個工作(從代碼的角度來說,即將多個對象組合成了一個對象)。
在組合的前提下,自動化調(diào)參技術(shù)幫我們省去了人工調(diào)參的反鎖。訓(xùn)練好的模型是貯存在內(nèi)存中的數(shù)據(jù),持久化能夠?qū)⑦@些數(shù)據(jù)保存在文件系統(tǒng)中,之后使用時無需再進(jìn)行訓(xùn)練,直接從文件系統(tǒng)中加載即可。
二、并行處理
pipeline包提供了FeatureUnion類來進(jìn)行整體并行處理:
from?numpy?import?log1p
from?sklearn.preprocessing?import?FunctionTransformer
from?sklearn.preprocessing?import?Binarizer
from?sklearn.pipeline?import?FeatureUnion
#新建將整體特征矩陣進(jìn)行對數(shù)函數(shù)轉(zhuǎn)換的對象
step2_1?=?('ToLog',?FunctionTransformer(log1p))
#新建將整體特征矩陣進(jìn)行二值化類的對象
step2_2?=?('ToBinary',?Binarizer())
#新建整體并行處理對象
#該對象也有fit和transform方法,fit和transform方法均是并行地調(diào)用需要并行處理的對象的fit和transform方法
#參數(shù)transformer_list為需要并行處理的對象列表,該列表為二元組列表,第一元為對象的名稱,第二元為對象
step2?=?('FeatureUnion',?FeatureUnion(transformer_list=[step2_1,?step2_2]))
from?sklearn.pipeline?import?FeatureUnion,?_fit_one_transformer,?_fit_transform_one,?_transform_one?
from?sklearn.externals.joblib?import?Parallel,?delayed
from?scipy?import?sparse
import?numpy?as?np
?
#部分并行處理,繼承FeatureUnion
class?FeatureUnionExt(FeatureUnion):
?????#相比FeatureUnion,多了idx_list參數(shù),其表示每個并行工作需要讀取的特征矩陣的列
?????def?__init__(self,?transformer_list,?idx_list,?n_jobs=1,?transformer_weights=None):
?????????self.idx_list?=?idx_list
?????????FeatureUnion.__init__(self,?transformer_list=map(lambda?trans:(trans[0],?trans[1]),?transformer_list),?n_jobs=n_jobs,?transformer_weights=transformer_weights)
?
?????#由于只部分讀取特征矩陣,方法fit需要重構(gòu)
?????def?fit(self,?X,?y=None):
?????????transformer_idx_list?=?map(lambda?trans,?idx:(trans[0],?trans[1],?idx),?self.transformer_list,?self.idx_list)
?????????transformers?=?Parallel(n_jobs=self.n_jobs)(
?????????????#從特征矩陣中提取部分輸入fit方法
?????????????delayed(_fit_one_transformer)(trans,?X[:,idx],?y)
?????????????for?name,?trans,?idx?in?transformer_idx_list)
?????????self._update_transformer_list(transformers)
?????????return?self
?
?????#由于只部分讀取特征矩陣,方法fit_transform需要重構(gòu)
?????def?fit_transform(self,?X,?y=None,?**fit_params):
?????????transformer_idx_list?=?map(lambda?trans,?idx:(trans[0],?trans[1],?idx),?self.transformer_list,?self.idx_list)
?????????result?=?Parallel(n_jobs=self.n_jobs)(
?????????????#從特征矩陣中提取部分輸入fit_transform方法
?????????????delayed(_fit_transform_one)(trans,?name,?X[:,idx],?y,
?????????????????????????????????????????self.transformer_weights,?**fit_params)
?????????????for?name,?trans,?idx?in?transformer_idx_list)
?
?????????Xs,?transformers?=?zip(*result)
?????????self._update_transformer_list(transformers)
?????????if?any(sparse.issparse(f)?for?f?in?Xs):
?????????????Xs?=?sparse.hstack(Xs).tocsr()
?????????else:
?????????????Xs?=?np.hstack(Xs)
?????????return?Xs
?
?????#由于只部分讀取特征矩陣,方法transform需要重構(gòu)
?????def?transform(self,?X):
?????????transformer_idx_list?=?map(lambda?trans,?idx:(trans[0],?trans[1],?idx),?self.transformer_list,?self.idx_list)
?????????Xs?=?Parallel(n_jobs=self.n_jobs)(
?????????????#從特征矩陣中提取部分輸入transform方法
?????????????delayed(_transform_one)(trans,?name,?X[:,idx],?self.transformer_weights)
?????????????for?name,?trans,?idx?in?transformer_idx_list)
?????????if?any(sparse.issparse(f)?for?f?in?Xs):
?????????????Xs?=?sparse.hstack(Xs).tocsr()
?????????else:
?????????????Xs?=?np.hstack(Xs)
?????????return?Xs
from?numpy?import?log1p
from?sklearn.preprocessing?import?OneHotEncoder
from?sklearn.preprocessing?import?FunctionTransformer
from?sklearn.preprocessing?import?Binarizer
#新建將部分特征矩陣進(jìn)行獨熱編碼的對象
step2_1?=?('OneHotEncoder',?OneHotEncoder(sparse=False))
#新建將部分特征矩陣進(jìn)行對數(shù)函數(shù)轉(zhuǎn)換的對象
step2_2?=?('ToLog',?FunctionTransformer(log1p))
#新建將部分特征矩陣進(jìn)行二值化類的對象
step2_3?=?('ToBinary',?Binarizer())
#新建部分并行處理對象
#參數(shù)transformer_list為需要并行處理的對象列表,該列表為二元組列表,第一元為對象的名稱,第二元為對象
#參數(shù)idx_list為相應(yīng)的需要讀取的特征矩陣的列
step2?=?('FeatureUnionExt',?FeatureUnionExt(transformer_list=[step2_1,?step2_2,?step2_3],?idx_list=[[0],?[1,?2,?3],?[4]]))
三、流水線處理
from?numpy?import?log1p
from?sklearn.preprocessing?import?Imputer
from?sklearn.preprocessing?import?OneHotEncoder
from?sklearn.preprocessing?import?FunctionTransformer
from?sklearn.preprocessing?import?Binarizer
from?sklearn.preprocessing?import?MinMaxScaler
from?sklearn.feature_selection?import?SelectKBest
from?sklearn.feature_selection?import?chi2
from?sklearn.decomposition?import?PCA
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.pipeline?import?Pipeline
#新建計算缺失值的對象
step1?=?('Imputer',?Imputer())
#新建將部分特征矩陣進(jìn)行定性特征編碼的對象
step2_1?=?('OneHotEncoder',?OneHotEncoder(sparse=False))
#新建將部分特征矩陣進(jìn)行對數(shù)函數(shù)轉(zhuǎn)換的對象
step2_2?=?('ToLog',?FunctionTransformer(log1p))
#新建將部分特征矩陣進(jìn)行二值化類的對象
step2_3?=?('ToBinary',?Binarizer())
#新建部分并行處理對象,返回值為每個并行工作的輸出的合并
step2?=?('FeatureUnionExt',?FeatureUnionExt(transformer_list=[step2_1,?step2_2,?step2_3],?idx_list=[[0],?[1,?2,?3],?[4]]))
#新建無量綱化對象
step3?=?('MinMaxScaler',?MinMaxScaler())
#新建卡方校驗選擇特征的對象
step4?=?('SelectKBest',?SelectKBest(chi2,?k=3))
#新建PCA降維的對象
step5?=?('PCA',?PCA(n_components=2))
#新建邏輯回歸的對象,其為待訓(xùn)練的模型作為流水線的最后一步
step6?=?('LogisticRegression',?LogisticRegression(penalty='l2'))
#新建流水線處理對象
#參數(shù)steps為需要流水線處理的對象列表,該列表為二元組列表,第一元為對象的名稱,第二元為對象
pipeline?=?Pipeline(steps=[step1,?step2,?step3,?step4,?step5,?step6])
四、自動化調(diào)參
from?sklearn.grid_search?import?GridSearchCV
iris?=?load_iris()
#新建網(wǎng)格搜索對象
#第一參數(shù)為待訓(xùn)練的模型
#param_grid為待調(diào)參數(shù)組成的網(wǎng)格,字典格式,鍵為參數(shù)名稱(格式“對象名稱__子對象名稱__參數(shù)名稱”),值為可取的參數(shù)值列表
grid_search?=?GridSearchCV(pipeline,?param_grid={'FeatureUnionExt__ToBinary__threshold':[1.0,?2.0,?3.0,?4.0],?'LogisticRegression__C':[0.1,?0.2,?0.4,?0.8]})
#訓(xùn)練以及調(diào)參
grid_search.fit(iris.data,?iris.target)
五、持久化
#持久化數(shù)據(jù)
#第一個參數(shù)為內(nèi)存中的對象
#第二個參數(shù)為保存在文件系統(tǒng)中的名稱
#第三個參數(shù)為壓縮級別,0為不壓縮,3為合適的壓縮級別
dump(grid_search,?'grid_search.dmp',?compress=3)
#從文件系統(tǒng)中加載數(shù)據(jù)到內(nèi)存中
grid_search?=?load('grid_search.dmp')
?回顧

推薦閱讀 1、上熱搜了!這款工具可以讓代碼終端變「高逼格」 2、Python 中有哪些讓人眼前一亮的工具? 3、丟棄傳統(tǒng)可視化庫!事實已證明,它更牛啊! 4、效率低?這 8 種 Python 數(shù)據(jù)處理的技巧你會了嗎! 5、愛了愛了!8 個被低估但功能非常強大的 VSCode 插件! 如果你對數(shù)據(jù)分析、數(shù)據(jù)挖掘、數(shù)據(jù)化運營感興趣,卻又無從下手,那么我來給你推薦一本不錯的書籍--《Python數(shù)據(jù)科學(xué)手冊》。
領(lǐng)取方式:
長按掃碼,發(fā)消息?[數(shù)據(jù)分析]


評論
圖片
表情