
【譯】關(guān)系型數(shù)據(jù)庫的工作原理
一、前言
在進(jìn)行高性能 Java 持久性培訓(xùn)時(shí),我意識(shí)到有必要解釋關(guān)系數(shù)據(jù)庫的工作原理,否則,很難掌握許多與事務(wù)相關(guān)的概念,例如原子性、持久性和檢查點(diǎn)。
在這篇文章中,我將對(duì)關(guān)系數(shù)據(jù)庫的內(nèi)部工作方式進(jìn)行高層次的解釋,同時(shí)還暗示一些特定于數(shù)據(jù)庫的實(shí)現(xiàn)細(xì)節(jié)。
二、一圖勝千文
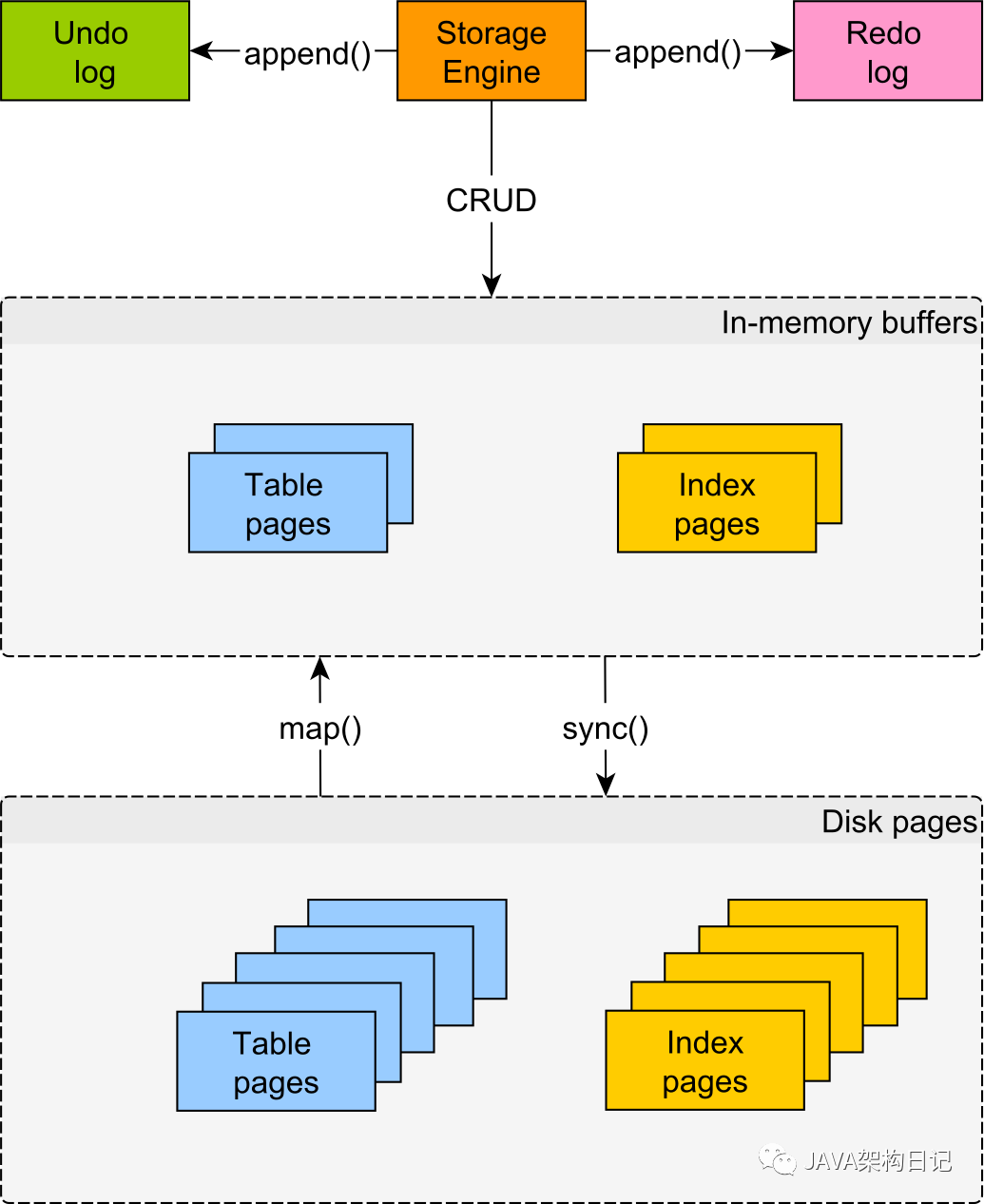
二、Data pages
磁盤訪問速度很慢。另一方面,內(nèi)存甚至比固態(tài)硬盤還要快幾個(gè)數(shù)量級(jí)。出于這個(gè)原因,數(shù)據(jù)庫供應(yīng)商試圖盡可能延遲磁盤訪問。無論我們談?wù)摰氖潜磉€是索引,數(shù)據(jù)都被分成一定大小(例如 8 KB)的 page。
當(dāng)需要讀取數(shù)據(jù)(表或索引)時(shí),關(guān)系數(shù)據(jù)庫會(huì)將基于磁盤的頁面映射到內(nèi)存緩沖區(qū)。當(dāng)需要修改數(shù)據(jù)時(shí),關(guān)系數(shù)據(jù)庫會(huì)更改內(nèi)存 pages。要將內(nèi)存 pages 與磁盤同步,必須進(jìn)行 flush(例如 fsync)。
存儲(chǔ)基于磁盤的 page 的緩沖池大小有限,因此通常需要存儲(chǔ)數(shù)據(jù)工作集。只有當(dāng)整個(gè)數(shù)據(jù)可以放入內(nèi)存時(shí),緩沖池才能存儲(chǔ)整個(gè)數(shù)據(jù)集。但是,如果需要緩存新 page 時(shí)磁盤上的總體數(shù)據(jù)大于緩沖池大小,則緩沖池將不得不逐出舊 pages 為新 pages 騰出空間。
三、Undo log
因?yàn)閮?nèi)存中的變化可以被多個(gè)并發(fā)事務(wù)訪問,所以必須采用并發(fā)控制機(jī)制(例如 2PL 和 MVCC)來確保數(shù)據(jù)完整性。因此,一旦事務(wù)修改了表行,未提交的更改將應(yīng)用于內(nèi)存結(jié)構(gòu),而先前的數(shù)據(jù)會(huì)臨時(shí)存儲(chǔ)在 undo log append-only 結(jié)構(gòu)中。
雖然這種結(jié)構(gòu)在 Oracle 和 MySQL 中稱為 undo log,但在 SQL Server 中,事務(wù)日志起著這種作用。PostgreSQL 沒有 undo log,但是通過多版本表結(jié)構(gòu)達(dá)到了相同的目的,因?yàn)楸砜梢源鎯?chǔ)同一行的多個(gè)版本。然而,所有這些數(shù)據(jù)結(jié)構(gòu)都用于提供回滾能力,這是原子性的強(qiáng)制性要求。
如果當(dāng)前運(yùn)行的事務(wù)回滾,undo log 將用于重建事務(wù)開始時(shí)的內(nèi)存 pages。
四、Redo log
一旦事務(wù)提交,內(nèi)存中的更改必須保持不變。但是,這并不意味著每個(gè)事務(wù)提交都會(huì)觸發(fā) fsync。事實(shí)上,這對(duì)應(yīng)用程序性能非常不利。然而,從 ACID 事務(wù)屬性,我們知道提交的事務(wù)必須提供持久性,這意味著即使我們拔掉數(shù)據(jù)庫引擎,提交的更改也需要持久化。
那么,關(guān)系數(shù)據(jù)庫如何提供持久性而不在每次事務(wù)提交時(shí)發(fā)出 fsync 呢?
這就是 redo log 發(fā)揮作用的地方。redo log也是一種 append-only 基于磁盤的結(jié)構(gòu),用于存儲(chǔ)給定事務(wù)所經(jīng)歷的每個(gè)更改。因此,當(dāng)事務(wù)提交時(shí),每個(gè)數(shù)據(jù)頁更改也將寫入_redo log。與刷新固定數(shù)量的 data pages 相比,寫入 redo log 非常快,因?yàn)轫樞虼疟P訪問比 Random access 快得多。因此,它還允許事務(wù)快速處理。
雖然這種結(jié)構(gòu)在 Oracle 和 MySQL 中被稱為 redo log,但在 SQL Server 中,事務(wù)日志也扮演著這個(gè)角色。PostgreSQL 將其稱為預(yù)寫日志 (WAL)。
但是,何時(shí)將內(nèi)存中的更改 flush 到磁盤?
關(guān)系數(shù)據(jù)庫系統(tǒng)使用檢查點(diǎn)將內(nèi)存中的臟 pages 與其基于磁盤的對(duì)應(yīng)物同步。為避免 IO 流量擁塞,同步通常在較長的時(shí)間段內(nèi)分塊完成。
但是,如果關(guān)系數(shù)據(jù)庫在將所有臟內(nèi)存 pages 刷新到磁盤之前崩潰會(huì)發(fā)生什么?
萬一發(fā)生崩潰,在啟動(dòng)時(shí),數(shù)據(jù)庫將使用 redo log 重建自上次成功檢查點(diǎn)以來未同步的基于磁盤的 data pages。
五、結(jié)論
采用這些設(shè)計(jì)考慮是為了克服基于磁盤的存儲(chǔ)的高延遲,同時(shí)仍然提供持久性存儲(chǔ)保證。因此,需要 undo log 來提供原子性(回滾能力),而需要 redo log 來確保基于磁盤的 page(表和索引)的持久性。
六、譯者說:
大家好,我是 如夢(mèng)技術(shù)春哥(mica 開源作者)翻譯不易,請(qǐng)幫忙分享給更多的同學(xué),謝謝!!!