
阿里規(guī)定禁止超過三張表 join!
不點(diǎn)藍(lán)字關(guān)注,我們哪來故事?
概述
前段時(shí)間在跟其他公司DBA交流時(shí)談到了mysql跟PG之間在多表關(guān)聯(lián)查詢上的一些區(qū)別,相比之下mysql只有一種表連接類型:嵌套循環(huán)連接(nested-loop),不支持排序-合并連接(sort-merge join)與散列連接(hash join),而PG是都支持的,而且mysql是往簡(jiǎn)單化方向去設(shè)計(jì)的,如果多個(gè)表關(guān)聯(lián)查詢(超過3張表)效率上是比不上PG的。
摘要
不超過3層是為了效率。 更通用 ,更好為了分布式做準(zhǔn)備。
下面也對(duì)mysql多表關(guān)聯(lián)這個(gè)特性簡(jiǎn)單探討下~
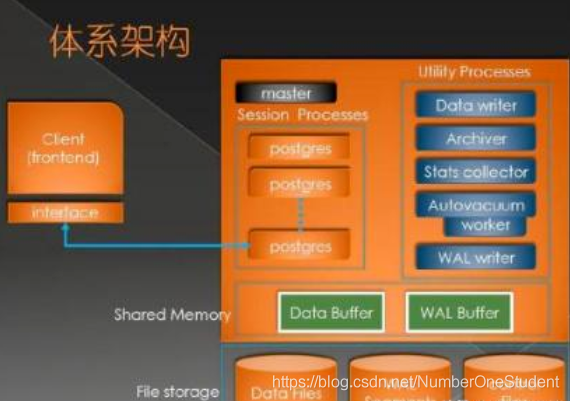
MySQL多表關(guān)聯(lián)查詢效率高點(diǎn)還是多次單表查詢效率高?
A,B兩個(gè)表數(shù)據(jù)規(guī)模十幾萬,數(shù)據(jù)規(guī)模都不大,單機(jī)MySQL夠用了,在單機(jī)的基礎(chǔ)上要關(guān)聯(lián)兩表的數(shù)據(jù),先說一個(gè)極端情況,A,B兩個(gè)表都沒有索引,并且關(guān)聯(lián)是笛卡爾積,那關(guān)聯(lián)結(jié)果會(huì)爆炸式增長(zhǎng),可能到億級(jí)別,這個(gè)時(shí)候網(wǎng)絡(luò)IO成了瓶頸,這個(gè)時(shí)候兩次十萬行結(jié)果集的拉去可能遠(yuǎn)小于1次億級(jí)別的結(jié)果集的拉取,那么將關(guān)聯(lián)合并拉到service層做更快。
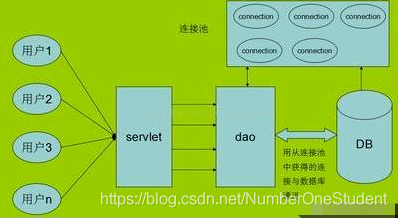
但實(shí)際業(yè)務(wù)中一般不會(huì)有這么蠢的行為,一般關(guān)聯(lián)會(huì)有連接條件,并且連接條件上會(huì)有索引,一般是有一個(gè)結(jié)果集比較小,拿到這個(gè)結(jié)果集去另一張表去關(guān)聯(lián)出其它信息。
如果放到service層去做,最快的方式是,先查A表,得到一個(gè)小的結(jié)果集,一次rpc,再根據(jù)結(jié)果集,拼湊出B表的查詢條件,去B表查到一個(gè)結(jié)果集,再一次rpc,再把結(jié)果集拉回service層,再一次rpc,然后service層做合并,3次rpc。
如果用數(shù)據(jù)庫(kù)的join,關(guān)聯(lián)結(jié)果拉回來,一次rpc,幫你省了兩次rpc,當(dāng)然數(shù)據(jù)庫(kù)上做關(guān)聯(lián)更快,對(duì)應(yīng)到數(shù)據(jù)庫(kù)就是一次blk nested loop join,這是業(yè)務(wù)常用情況。
但是確實(shí)大多數(shù)業(yè)務(wù)都會(huì)考慮把這種合并操作放到service層,一般是有以下幾方面考慮:
第一
單機(jī)數(shù)據(jù)庫(kù)計(jì)算資源很貴,數(shù)據(jù)庫(kù)同時(shí)要服務(wù)寫和讀,都需要消耗CPU,為了能讓數(shù)據(jù)庫(kù)的吞吐變得更高,而業(yè)務(wù)又不在乎那幾百微妙到毫秒級(jí)的延時(shí)差距,業(yè)務(wù)會(huì)把更多計(jì)算放到service層做,畢竟計(jì)算資源很好水平擴(kuò)展,數(shù)據(jù)庫(kù)很難啊,所以大多數(shù)業(yè)務(wù)會(huì)把純計(jì)算操作放到service層做,而將數(shù)據(jù)庫(kù)當(dāng)成一種帶事務(wù)能力的kv系統(tǒng)來使用,這是一種重業(yè)務(wù),輕DB的架構(gòu)思路
第二
很多復(fù)雜的業(yè)務(wù)可能會(huì)由于發(fā)展的歷史原因,一般不會(huì)只用一種數(shù)據(jù)庫(kù),一般會(huì)在多個(gè)數(shù)據(jù)庫(kù)上加一層中間件,多個(gè)數(shù)據(jù)庫(kù)之間就沒辦法join了,自然業(yè)務(wù)會(huì)抽象出一個(gè)service層,降低對(duì)數(shù)據(jù)庫(kù)的耦合。
第三
對(duì)于一些大型公司由于數(shù)據(jù)規(guī)模龐大,不得不對(duì)數(shù)據(jù)庫(kù)進(jìn)行分庫(kù)分表,對(duì)于分庫(kù)分表的應(yīng)用,使用join也受到了很多限制,除非業(yè)務(wù)能夠很好的根據(jù)sharding key明確要join的兩個(gè)表在同一個(gè)物理庫(kù)中。而中間件一般對(duì)跨庫(kù)join都支持不好。
舉一個(gè)很常見的業(yè)務(wù)例子,在分庫(kù)分表中,要同步更新兩個(gè)表,這兩個(gè)表位于不同的物理庫(kù)中,為了保證數(shù)據(jù)一致性,一種做法是通過分布式事務(wù)中間件將兩個(gè)更新操作放到一個(gè)事務(wù)中,但這樣的操作一般要加全局鎖,性能很捉急,而有些業(yè)務(wù)能夠容忍短暫的數(shù)據(jù)不一致,怎么做?
讓它們分別更新唄,但是會(huì)存在數(shù)據(jù)寫失敗的問題,那就起個(gè)定時(shí)任務(wù),掃描下A表有沒有失敗的行,然后看看B表是不是也沒寫成功,然后對(duì)這兩條關(guān)聯(lián)記錄做訂正,這個(gè)時(shí)候同樣沒法用join去實(shí)現(xiàn),只能將數(shù)據(jù)拉到service層應(yīng)用自己來合并了。。。
到這里答案就很清楚了~
對(duì)關(guān)聯(lián)查詢進(jìn)行分解
很多高性能的應(yīng)用都會(huì)對(duì)關(guān)聯(lián)查詢進(jìn)行分解。

簡(jiǎn)單地,可以對(duì)每個(gè)表進(jìn)行一次單表查詢,然后將結(jié)果在應(yīng)用程序中進(jìn)行關(guān)聯(lián)。例如,下面這個(gè)查詢:
select * from tag
join tag_post on tag_post.tag_id=tag.id
join post on tag_post.post_id=post.id
where tag.tag=’mysql’;
可以分解成下面這些查詢來代替:
Select * from tag where tag=’mysql’;
Select * from tag_post where tag_id=1234;
Select * from post where id in(123,456,567,9989,8909);
為什么會(huì)這樣做呢?原本一條查詢,這里卻變成了多條查詢,返回結(jié)果又是一模一樣。
事實(shí)上,用分解關(guān)聯(lián)查詢的方式重構(gòu)查詢具有如下優(yōu)勢(shì):
讓緩存的效率更高。 許多應(yīng)用程序可以方便地緩存單表查詢對(duì)應(yīng)的結(jié)果對(duì)象。另外對(duì)于MySQL的查詢緩存來說,如果關(guān)聯(lián)中的某個(gè)表發(fā)生了變化,那么就無法使用查詢緩存了,而拆分后,如果某個(gè)表很少改變,那么基于該表的查詢就可以重復(fù)利用查詢緩存結(jié)果了。 將查詢分解后,執(zhí)行單個(gè)查詢可以減少鎖的競(jìng)爭(zhēng)。 在應(yīng)用層做關(guān)聯(lián),可以更容易對(duì)數(shù)據(jù)庫(kù)進(jìn)行拆分,更容易做到高性能和可擴(kuò)展。 查詢本身效率也可能會(huì)有所提升 可以減少冗余記錄的查詢。 更進(jìn)一步,這樣做相當(dāng)于在應(yīng)用中實(shí)現(xiàn)了哈希關(guān)聯(lián),而不是使用MySQL的嵌套環(huán)關(guān)聯(lián),某些場(chǎng)景哈希關(guān)聯(lián)的效率更高很多。
解釋
RPC(Remote Procedure Call):遠(yuǎn)程過程調(diào)用,它是一種通過網(wǎng)絡(luò)從遠(yuǎn)程計(jì)算機(jī)程序上請(qǐng)求服務(wù),而不需要了解底層網(wǎng)絡(luò)技術(shù)的思想。
END
若覺得文章對(duì)你有幫助,隨手轉(zhuǎn)發(fā)分享,也是我們繼續(xù)更新的動(dòng)力。
長(zhǎng)按二維碼,掃掃關(guān)注哦
?「C語(yǔ)言中文網(wǎng)」官方公眾號(hào),關(guān)注手機(jī)閱讀教程 ?