
圖解B+樹的生成過程!
你知道的越多,不知道的就越多,業(yè)余的像一棵小草!
你來,我們一起精進(jìn)!你不來,我和你的競爭對手一起精進(jìn)!
編輯:業(yè)余草
來源:juejin.cn/post/7162856738692005918
推薦:https://www.xttblog.com/?p=5357
自律才能自由
本文大概字?jǐn)?shù)三千多,預(yù)計(jì)觀看時(shí)長十分鐘,練習(xí)時(shí)長兩個(gè)半小時(shí)。希望大家都能學(xué)到知識。

前提
不少網(wǎng)友看 B+ 樹,看不懂樹結(jié)構(gòu)什么意思。希望本文可以幫你理解樹結(jié)構(gòu)生成的過程。
在說 B+ 樹之前,需要知道,一頁的大小是多少。
show global status like 'innodb_page_size'
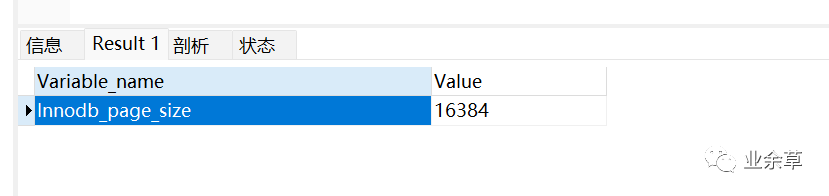
這個(gè)是看出,一頁是 16384 也就是16384/1024 = 16kbinnodb 中一頁的大小默認(rèn)是 16kb。
正文
創(chuàng)建表結(jié)構(gòu) 指定引擎為 Innodb。
CREATE TABLE tree(
id int PRIMARY key auto_increment,
t_name VARCHAR(20),
t_code int
) ENGINE=INNODB
查看一下當(dāng)前表的索引情況
show index from tree
B 樹和 B+ 樹的顯示都是 BTREE,但是實(shí)際使用的 B+ 樹。B+ 樹也是 B 樹的升級版,這里顯示為 B 樹也是沒有問題的。

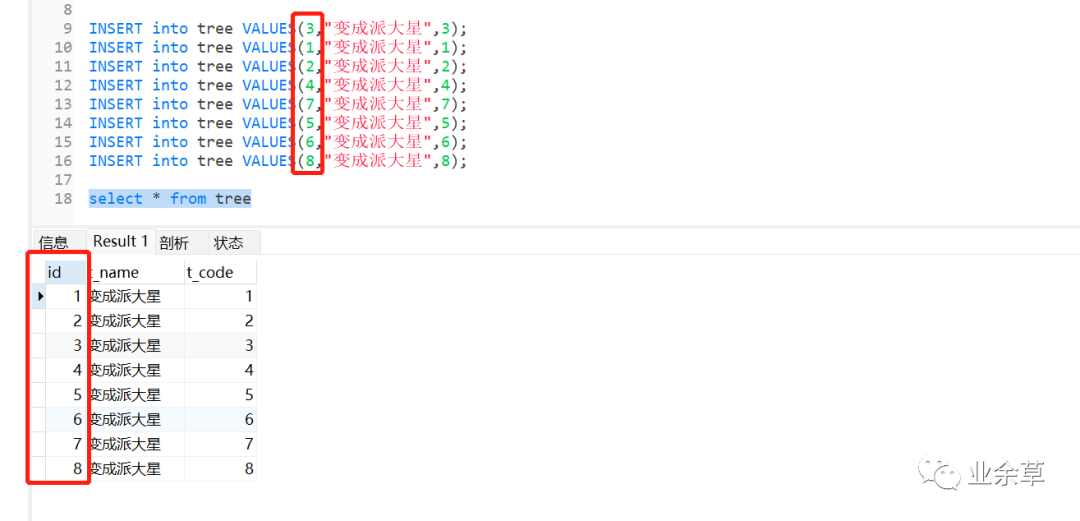
創(chuàng)建數(shù)據(jù),這里會有一個(gè)小知識點(diǎn),如果看過上一篇文章的朋友可以明白是為什么。
INSERT into tree VALUES(3,"變成派大星",3);
INSERT into tree VALUES(1,"變成派大星",1);
INSERT into tree VALUES(2,"變成派大星",2);
INSERT into tree VALUES(4,"變成派大星",4);
INSERT into tree VALUES(7,"變成派大星",7);
INSERT into tree VALUES(5,"變成派大星",5);
INSERT into tree VALUES(6,"變成派大星",6);
INSERT into tree VALUES(8,"變成派大星",8);
疑問
為什么創(chuàng)建數(shù)據(jù)的時(shí)候數(shù)據(jù)是亂序的,但是在創(chuàng)建好數(shù)據(jù),被排好順序了。
基礎(chǔ)知識
我們在尋找答案之前,想明白一些基礎(chǔ)知識。
細(xì)心的朋友可以看出來,我們插入 Id 時(shí)候數(shù)據(jù)是亂的,插入進(jìn)去之后,數(shù)據(jù)就自動幫我通過 Id 進(jìn)行排序了,這是為什么呢?接著往下看。
我們?nèi)绻麑τ?B+ 樹有點(diǎn)了解的話就知道 B+ 樹是每頁 16KB 進(jìn)行數(shù)據(jù)儲存。在進(jìn)行數(shù)據(jù)查詢的時(shí)候也是一頁一頁的去查詢。
相當(dāng)于下面的數(shù)據(jù)。
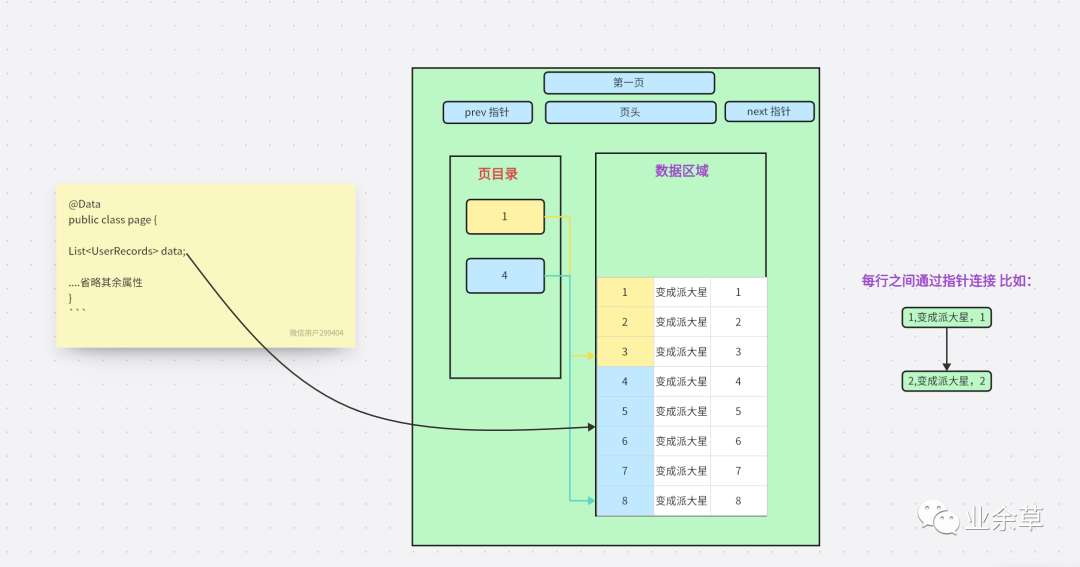
首先每一頁都有很多數(shù)據(jù),就像我們平常去寫分頁的時(shí)候我們返回給前端的數(shù)據(jù)也會有很多屬性。
這個(gè)可能比較抽象,我是把他當(dāng)成平常,分頁查詢的思想代入進(jìn)去。
我們可以把一頁想成是一個(gè)對象。
@Data
public class page {
List<UserRecords> data;
// ....省略其余屬性
}
我們先看一下,一頁數(shù)據(jù)的圖是什么樣子,僅僅是進(jìn)行邏輯思考畫的圖。
這里的 Data,就相當(dāng)于 一頁中的數(shù)據(jù)區(qū)域。
但是這里是有限制的,上面我們說到,一頁的數(shù)據(jù)只能是 16Kb,也就是一個(gè) Page 里面的 data 只能16Kb。當(dāng)數(shù)據(jù)超過 16Kb,就會新開一個(gè)對象相當(dāng)于在進(jìn)行創(chuàng)建樹的時(shí)候增加了判斷。
Java 代碼思路模擬:

當(dāng) Page 對象的大小已經(jīng)達(dá)到16Kb 就算完成這一頁。把這一頁放到,磁盤中等待使用就行了,到時(shí)候進(jìn)行查詢數(shù)據(jù)的時(shí)候會直接返回這一頁,里面包含這些數(shù)據(jù)。
我們回到最初的問題 為什么我們在進(jìn)行插入的時(shí)候明明 Id 是亂的?等到插入到數(shù)據(jù)的時(shí)候,數(shù)據(jù)就變成有序的了?我們知道,同時(shí)這個(gè)數(shù)據(jù)是根據(jù)主鍵進(jìn)行排序的,InnoDB 的數(shù)據(jù)儲存一定是要依賴主鍵的,有些人會想,我就是不創(chuàng)建主鍵,他還能排序嗎?
疑問二
我們在疑問一的基礎(chǔ)上,產(chǎn)生出的疑問,不設(shè)置主鍵 Mysql 怎么辦?
解答
InnoDB 對聚簇索引處理如下:
如果定義了主鍵,那么 InnoDB 會使用主鍵作為聚簇索引 如果沒有定義主鍵,那么會使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作為聚簇索引 如果既沒有主鍵也找不到合適的非空索引,InnoDB 會自動幫你創(chuàng)建一個(gè)不可見的、長度為 6 字節(jié)的 row_id,而且 InnoDB 維護(hù)了一個(gè)全局的 dictsys.row_id,所以未定義主鍵的表都共享該row_id,每次插入一條數(shù)據(jù),都把全局 row_id 當(dāng)成主鍵 id,然后全局 row_id 加 1
很明顯,缺少主鍵的表,InnoDB 會內(nèi)置一列用于聚簇索引來組織數(shù)據(jù)。而沒有建立主鍵的話就沒法通過主鍵來進(jìn)行索引,查詢的時(shí)候都是全表掃描,小數(shù)據(jù)量沒問題,大數(shù)據(jù)量就會出現(xiàn)性能問題。
但是,問題真的只是查詢影響嗎?不是的,對于生成的 ROW_ID,其自增的實(shí)現(xiàn)來源于一個(gè)全局的序列,而所以有 ROW_ID 的表共享該序列,這也意味著插入的時(shí)候生成需要共享一個(gè)序列,那么高并發(fā)插入的時(shí)候?yàn)榱吮3治ㄒ恍跃捅苊獠涣随i的競爭,進(jìn)而影響性能
解答
我們看完疑問二的解答就知道,即便我們不設(shè)置主鍵。數(shù)據(jù)也會幫我們?nèi)ド梢粋€(gè)默認(rèn)的主鍵,有點(diǎn)像,類默認(rèn)生成構(gòu)造器的思想。
有了主鍵之后呢?
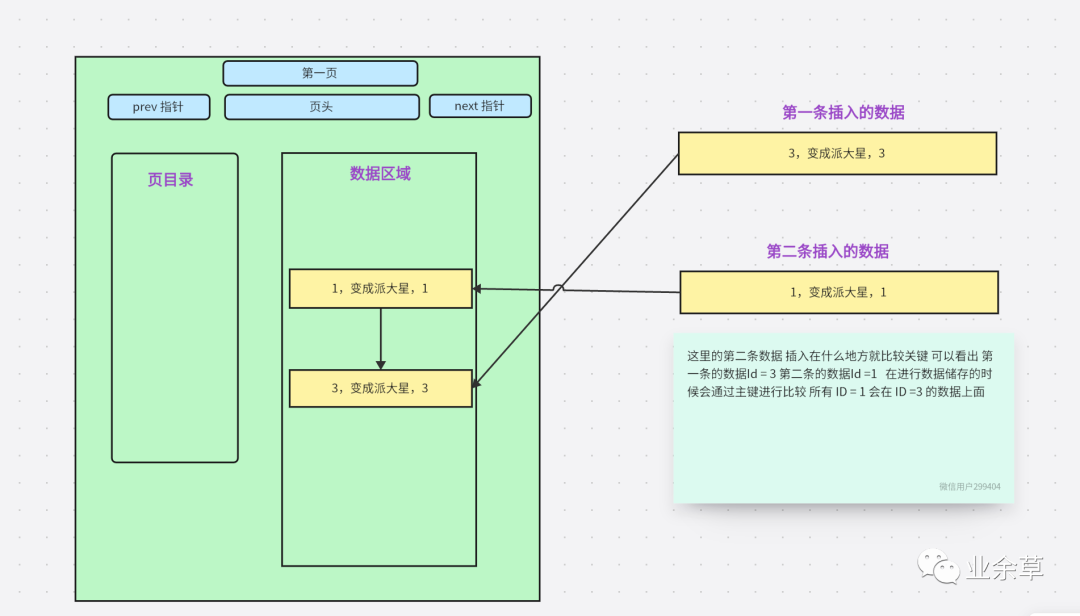
為什么會自動排序,大家都知道了。其實(shí)在文章之初就會有很多人明白是為什么,大概腦子里會有答案。
疑問三
為什么要進(jìn)行排序?
解答
我們都知道,在進(jìn)行數(shù)據(jù)查找的時(shí)候,比如幾個(gè)基礎(chǔ)的查找算法的,前提都是,先進(jìn)行排序。再者 List 和 Map 的一些區(qū)別肯定都很熟悉了。排序當(dāng)然是為了更快,所以無須的 Id 會對插入效率造成影響,也就是為什么很多文章說使用自增 Id 比 UUID 或者雪花算效率高的原因。第一個(gè)是 UUID 他們是隨機(jī)的 每次都要重新排序,甚至可能會因?yàn)榕判虻脑蛟斐身摂?shù)據(jù)的更換。還有就是 UUID 一般都比較長,一頁是 16Kb 數(shù)據(jù)越短。一頁的數(shù)據(jù)就會越多,查詢的速度也就比較快。
這里說完為什么排序 還有一個(gè)點(diǎn)就是上面的「頁目錄」
疑問三
頁目錄的作用是什么?
頁目錄的作用是減少范圍。
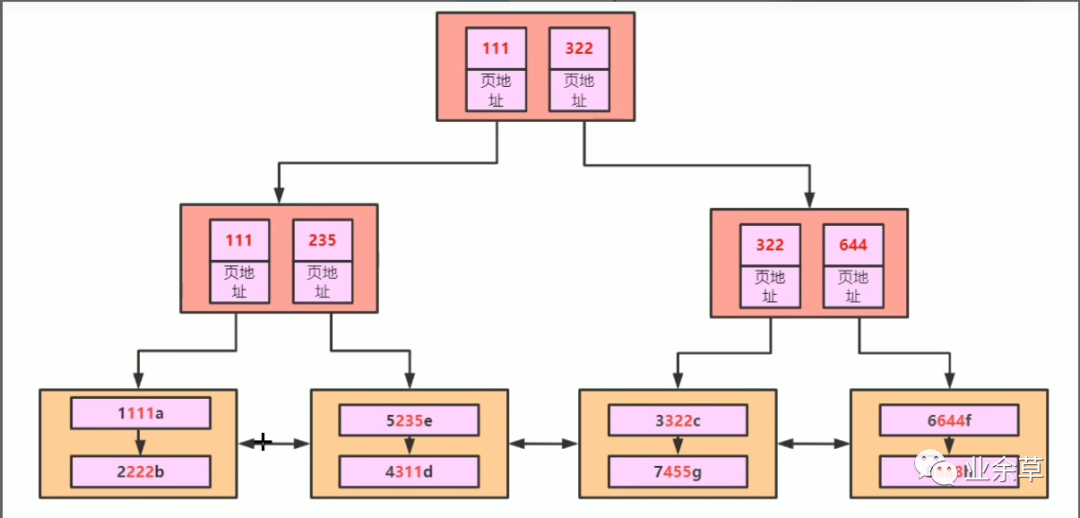
這里的第三層是數(shù)據(jù),上面都是目錄,可以增加數(shù)據(jù)的檢索效率。
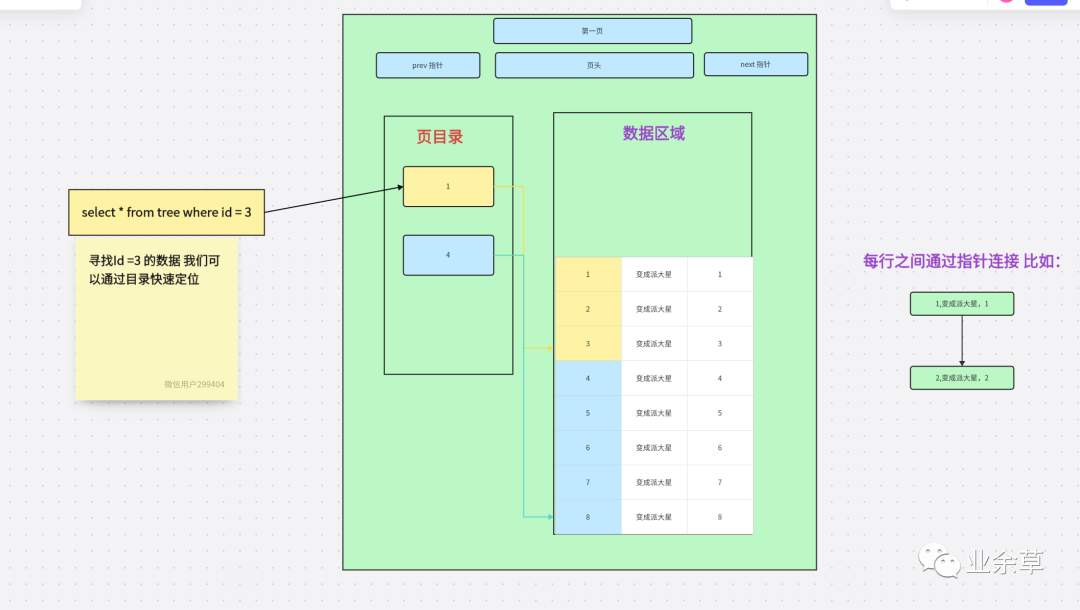
如果沒有目錄我們需要去直接遍歷數(shù)據(jù)區(qū)域,會降低效率。目錄能幫我們縮小范圍,這里,我們查詢 ID = 3。我們可以通過目錄知道 1 < 3 < 4,如果在 1 中沒有找到對應(yīng)數(shù)據(jù)。但是因?yàn)?3 < 4 就不會接著往下查詢了,直接返回空結(jié)果。
當(dāng)?shù)谝豁摏]有的時(shí)候去第二頁查詢,不會直接跳到第二頁查詢。
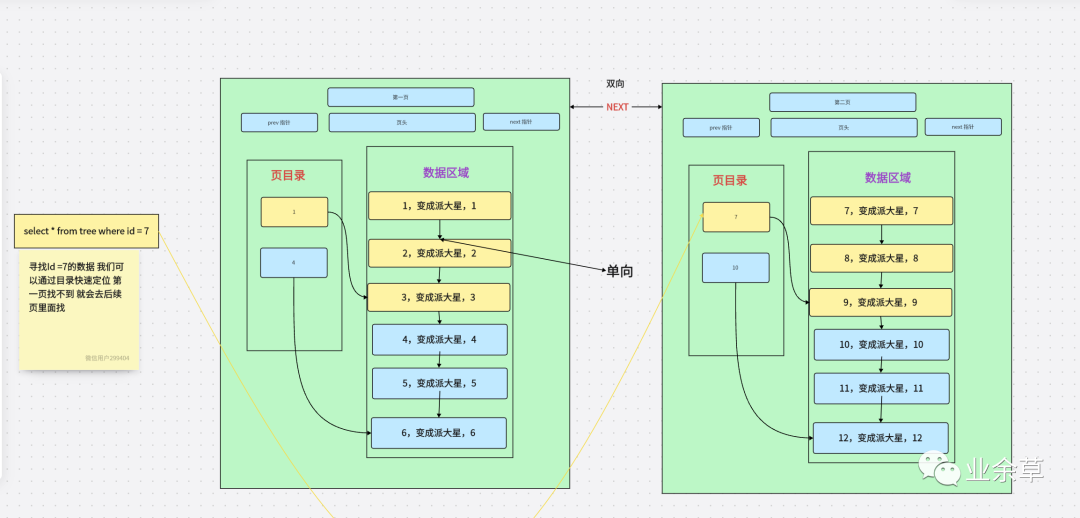
為了提高效率,當(dāng)目錄數(shù)據(jù)數(shù)量過多時(shí),就會網(wǎng)上延伸一層樹,同時(shí)可以減少磁盤的 IO 次數(shù)。
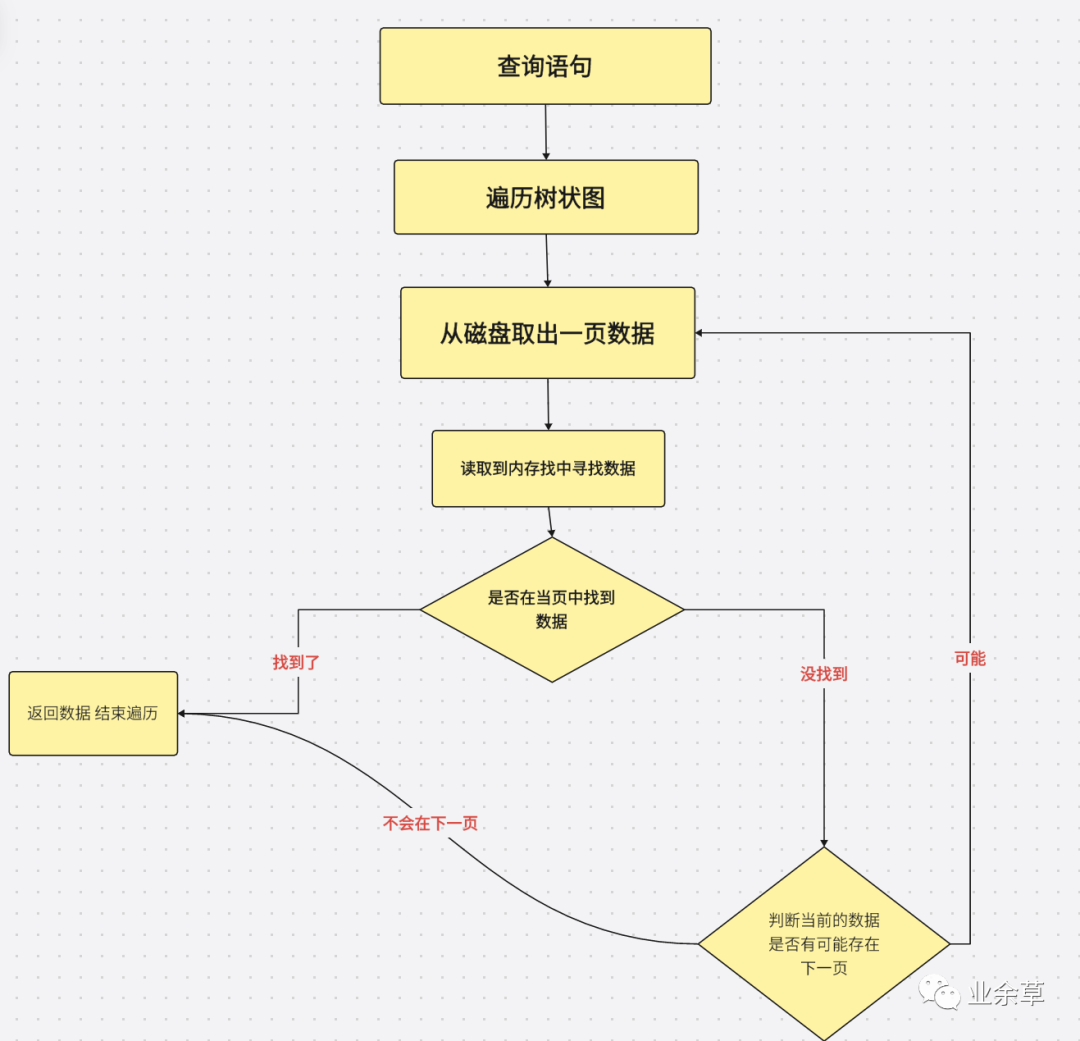
關(guān)于所有葉子節(jié)點(diǎn)都處于同一深度是如何實(shí)現(xiàn)的?這與 B+ 樹具體的插入和刪除算法有關(guān)。簡單解釋一下插入時(shí)的情況,根據(jù)插入值的大小,逐步向下直到對應(yīng)的葉子節(jié)點(diǎn)。如果葉子節(jié)點(diǎn)關(guān)鍵字個(gè)數(shù)小于 2t,則直接插入值或者更新衛(wèi)星數(shù)據(jù);如果插入之前葉子節(jié)點(diǎn)已經(jīng)滿了,則分裂該葉子節(jié)點(diǎn)成兩半,并把中間值提上到父節(jié)點(diǎn)的關(guān)鍵字中,如果這導(dǎo)致父節(jié)點(diǎn)滿了的話,則把該父節(jié)點(diǎn)分裂,如此遞歸向上。所以樹高是一層層的增加的,葉子節(jié)點(diǎn)永遠(yuǎn)都在同一深度。
小總結(jié)
內(nèi)部節(jié)點(diǎn)并不存儲真正的信息,而是保存其葉子節(jié)點(diǎn)的最小值作為索引。 每次插入刪除都進(jìn)行更新(此時(shí)用到parent指針),保持最新狀態(tài)。 B+ 樹非葉子節(jié)點(diǎn)上是不存儲數(shù)據(jù)的,僅存儲鍵值 B+ 樹只在葉子節(jié)點(diǎn)上儲存“數(shù)據(jù)”,上層就會存儲更多的鍵值,相應(yīng)的樹的階數(shù)(節(jié)點(diǎn)的子節(jié)點(diǎn)樹)就會更大,樹就會更矮更胖,如此一來我們查找數(shù)據(jù)進(jìn)行磁盤的 IO 次數(shù)又會再次減少,數(shù)據(jù)查詢的效率也會更快。 B+ 樹的階數(shù)是等于鍵值的數(shù)量的,如果我們的 B+ 樹一個(gè)節(jié)點(diǎn)可以存儲 1000 個(gè)鍵值,那么 3 層 B+ 樹可以存儲 1000×1000×1000=10 億個(gè)數(shù)據(jù)。 一般根節(jié)點(diǎn)是常駐內(nèi)存的,所以一般我們查找 10 億數(shù)據(jù),只需要 2 次磁盤 IO。 因?yàn)?B+ 樹索引的所有“數(shù)據(jù)”均存儲在葉子節(jié)點(diǎn),而且數(shù)據(jù)是按照順序排列的。 那么 B+ 樹使得范圍查找,排序查找,分組查找以及去重查找變得異常簡單 有心的讀者可能還發(fā)現(xiàn)上圖 B+ 樹中各個(gè)頁之間是通過雙向鏈表連接的,葉子節(jié)點(diǎn)中的數(shù)據(jù)是通過單向鏈表連接的。 其實(shí)上面的 B 樹我們也可以對各個(gè)節(jié)點(diǎn)加上鏈表。這些不是它們之前的區(qū)別,是因?yàn)樵?MySQL 的 InnoDB 存儲引擎中,索引就是這樣存儲的。 我們通過數(shù)據(jù)頁之間通過雙向鏈表連接以及葉子節(jié)點(diǎn)中數(shù)據(jù)之間通過單向鏈表連接的方式可以找到表中所有的數(shù)據(jù)。
結(jié)尾
感覺寫的有點(diǎn)啰嗦了 但是還是有點(diǎn)加深印象的 后續(xù)會接著整理一下相關(guān)的資料 補(bǔ)充進(jìn)來
如果你是直接跳到這里,看看文章有多長 建議收藏如果你一步步看到這里,感覺有點(diǎn)幫助 贊贊來一個(gè)如果感覺文章有問題,建議評論區(qū)指出 會修正
周日愉快!文章完結(jié)??