
涼了,stress 無論如何也無法打滿 CPU
關(guān)注")
概述
今天,想嘗試復(fù)現(xiàn)一個(gè)問題,需要達(dá)到一個(gè)效果就是將 CPU 打滿,制造一個(gè)負(fù)載很高的情況,我的第一想法就是使用 stress,結(jié)果發(fā)現(xiàn)居然一直都打不滿,只能打到一半(50%)就到頂了,所以就探索了一下什么問題,順便記錄一下。
操作過程
首先,我先看了一下這臺(tái)機(jī)器上有幾個(gè)核,總共有幾個(gè)線程,然后以對(duì)應(yīng)線程數(shù)量去啟動(dòng) stress:
$ cat /proc/cpuinfo | grep "core id" | wc -l
6
$ cat /proc/cpuinfo | grep "processor" | wc -l
6
這里需要看的是邏輯核心數(shù)(線程數(shù)),實(shí)際上物理核是 6 個(gè),每個(gè)核的線程數(shù)是 1 個(gè),所以總共需要 6 個(gè),沒問題。接著就是啟動(dòng) stress 了:
$ stress -c 6
然后就看到 CPU 使用率是這樣的:
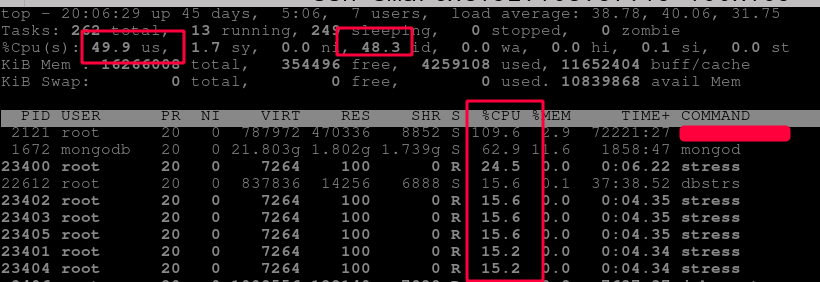
這就很厲害了,可以看到其實(shí) stress 只占用了一個(gè) core,然后使用率就是只有一個(gè) 100%,并沒有達(dá)到我的預(yù)期,然后我就像,我多開兩個(gè)不就行了,然后又開了一個(gè) terminal,再跑一個(gè),結(jié)果就變成這樣了:
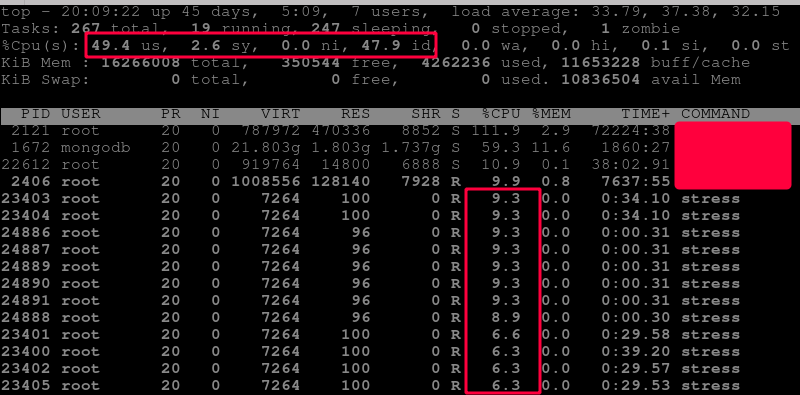
你看他們,波瀾不驚,繼續(xù)平分,多么氣人。那么這是什么問題呢?為什么會(huì)另開 terminal 也會(huì)跑到同一個(gè) core 里面去呢,這應(yīng)該有一些貓膩。
問題定位
所以我的懷疑方向是有同事限制了 shell 的 cgroup,導(dǎo)致我只能用固定的 core,于是我就先看看 stress 的 cgroup 是啥:
$ cat /proc/5813/cgroup
11:perf_event:/
10:cpuset:/zbs/app
9:devices:/system.slice/sshd.service
8:freezer:/
7:pids:/
6:blkio:/system.slice/sshd.service
5:net_prio,net_cls:/
4:hugetlb:/
3:cpuacct,cpu:/system.slice/sshd.service
2:memory:/system.slice/sshd.service
1:name=systemd:/system.slice/sshd.service
ok,從這里可以看到使用的 cpuset 是一個(gè)叫做 /zbs/app 的 cgroup 項(xiàng),那再一步看看具體是怎么限制的:
$ cat /etc/cgconfig.conf | grep -A 7 zbs/app
group zbs/app {
cpuset {
cpuset.cpus = "4,5";
cpuset.mems = "0";
cpuset.cpu_exclusive = "0";
cpuset.mem_hardwall = "1";
}
}
可以看到是被限制到了 cpu 4 和 5 上了,對(duì)照一下 top 的 cpu 使用率看是否吻合:

ok,看上去就是這個(gè)問題,那么我要將 CPU 打滿的話, 最簡(jiǎn)單的處理方式就是去掉這個(gè) cgroup 限制就好了,但是這不太友好,所以更友好的方式應(yīng)該是單獨(dú)過濾我的 stress 進(jìn)程,其他的照舊。
原文鏈接:https://liqiang.io/post/stress-not-make-cpu-100-percent


你可能還喜歡
點(diǎn)擊下方圖片即可閱讀


云原生是一種信仰 ??
關(guān)注公眾號(hào)
后臺(tái)回復(fù)?k8s?獲取史上最方便快捷的 Kubernetes 高可用部署工具,只需一條命令,連 ssh 都不需要!


點(diǎn)擊 "閱讀原文" 獲取更好的閱讀體驗(yàn)!
發(fā)現(xiàn)朋友圈變“安靜”了嗎?
