
一文理解Kafka的選舉機(jī)制與Rebalance機(jī)制
Kafka是一個(gè)高性能,高容錯(cuò),多副本,可復(fù)制的分布式消息系統(tǒng)。在整個(gè)系統(tǒng)中,涉及到多處選舉機(jī)制,被不少人搞混,這里總結(jié)一下,本篇文章大概會(huì)從三個(gè)方面來講解。
控制器(Broker)選舉機(jī)制
分區(qū)副本選舉機(jī)制
消費(fèi)組選舉機(jī)制
如果對Kafka不了解的話,可以先看這篇博客《一文快速了解Kafka》。
控制器選舉
控制器是Kafka的核心組件,它的主要作用是在Zookeeper的幫助下管理和協(xié)調(diào)整個(gè)Kafka集群。集群中任意一個(gè)Broker都能充當(dāng)控制器的角色,但在運(yùn)行過程中,只能有一個(gè)Broker成為控制器。
控制器的作用可以查看文末
控制器選舉可以認(rèn)為是Broker的選舉。
集群中第一個(gè)啟動(dòng)的Broker會(huì)通過在Zookeeper中創(chuàng)建臨時(shí)節(jié)點(diǎn)/controller來讓自己成為控制器,其他Broker啟動(dòng)時(shí)也會(huì)在zookeeper中創(chuàng)建臨時(shí)節(jié)點(diǎn),但是發(fā)現(xiàn)節(jié)點(diǎn)已經(jīng)存在,所以它們會(huì)收到一個(gè)異常,意識(shí)到控制器已經(jīng)存在,那么就會(huì)在Zookeeper中創(chuàng)建watch對象,便于它們收到控制器變更的通知。
那么如果控制器由于網(wǎng)絡(luò)原因與Zookeeper斷開連接或者異常退出,那么其他broker通過watch收到控制器變更的通知,就會(huì)去嘗試創(chuàng)建臨時(shí)節(jié)點(diǎn)/controller,如果有一個(gè)Broker創(chuàng)建成功,那么其他broker就會(huì)收到創(chuàng)建異常通知,也就意味著集群中已經(jīng)有了控制器,其他Broker只需創(chuàng)建watch對象即可。
如果集群中有一個(gè)Broker發(fā)生異常退出了,那么控制器就會(huì)檢查這個(gè)broker是否有分區(qū)的副本leader,如果有那么這個(gè)分區(qū)就需要一個(gè)新的leader,此時(shí)控制器就會(huì)去遍歷其他副本,決定哪一個(gè)成為新的leader,同時(shí)更新分區(qū)的ISR集合。
如果有一個(gè)Broker加入集群中,那么控制器就會(huì)通過Broker ID去判斷新加入的Broker中是否含有現(xiàn)有分區(qū)的副本,如果有,就會(huì)從分區(qū)副本中去同步數(shù)據(jù)。
防止控制器腦裂
如果控制器所在broker掛掉了或者Full GC停頓時(shí)間太長超過zookeepersession timeout出現(xiàn)假死,Kafka集群必須選舉出新的控制器,但如果之前被取代的控制器又恢復(fù)正常了,它依舊是控制器身份,這樣集群就會(huì)出現(xiàn)兩個(gè)控制器,這就是控制器腦裂問題。
解決方法:
為了解決Controller腦裂問題,ZooKeeper中還有一個(gè)與Controller有關(guān)的持久節(jié)點(diǎn)/controller_epoch,存放的是一個(gè)整形值的epoch number(紀(jì)元編號,也稱為隔離令牌),集群中每選舉一次控制器,就會(huì)通過Zookeeper創(chuàng)建一個(gè)數(shù)值更大的epoch number,如果有broker收到比這個(gè)epoch數(shù)值小的數(shù)據(jù),就會(huì)忽略消息。
分區(qū)副本選舉機(jī)制
由控制器執(zhí)行。
從Zookeeper中讀取當(dāng)前分區(qū)的所有ISR(in-sync replicas)集合。
調(diào)用配置的分區(qū)選擇算法選擇分區(qū)的leader。
Unclean leader選舉
ISR是動(dòng)態(tài)變化的,所以ISR列表就有為空的時(shí)候,ISR為空說明leader副本也掛掉了。此時(shí)Kafka要重新選舉出新的leader。但I(xiàn)SR為空,怎么進(jìn)行l(wèi)eader選舉呢?
Kafka把不在ISR列表中的存活副本稱為“非同步副本”,這些副本中的消息遠(yuǎn)遠(yuǎn)落后于leader,如果選舉這種副本作為leader的話就可能造成數(shù)據(jù)丟失。所以Kafka broker端提供了一個(gè)參數(shù)unclean.leader.election.enable,用于控制是否允許非同步副本參與leader選舉;如果開啟,則當(dāng) ISR為空時(shí)就會(huì)從這些副本中選舉新的leader,這個(gè)過程稱為 Unclean leader選舉。
可以根據(jù)實(shí)際的業(yè)務(wù)場景選擇是否開啟Unclean leader選舉。一般建議是關(guān)閉Unclean leader選舉,因?yàn)橥ǔ?shù)據(jù)的一致性要比可用性重要。
消費(fèi)組選主
在Kafka的消費(fèi)端,會(huì)有一個(gè)消費(fèi)者協(xié)調(diào)器以及消費(fèi)組,組協(xié)調(diào)器(Group Coordinator)需要為消費(fèi)組內(nèi)的消費(fèi)者選舉出一個(gè)消費(fèi)組的leader。
如果消費(fèi)組內(nèi)還沒有l(wèi)eader,那么第一個(gè)加入消費(fèi)組的消費(fèi)者即為消費(fèi)組的leader,如果某一個(gè)時(shí)刻leader消費(fèi)者由于某些原因退出了消費(fèi)組,那么就會(huì)重新選舉leader,選舉方式如下:
private val members = new mutable.HashMap[String, MemberMetadata]
leaderId = members.keys.headOption
在組協(xié)調(diào)器中消費(fèi)者的信息是以HashMap的形式存儲(chǔ)的,其中key為消費(fèi)者的member_id,而value是消費(fèi)者相關(guān)的元數(shù)據(jù)信息。而leader的取值為HashMap中的第一個(gè)鍵值對的key(等同于隨機(jī))。
消費(fèi)組的Leader和Coordinator沒有關(guān)聯(lián)。消費(fèi)組的leader負(fù)責(zé)Rebalance過程中消費(fèi)分配方案的制定。
消費(fèi)端Rebalance機(jī)制
就Kafka消費(fèi)端而言,有一個(gè)難以避免的問題就是消費(fèi)者的重平衡即Rebalance。Rebalance是讓一個(gè)消費(fèi)組的所有消費(fèi)者就如何消費(fèi)訂閱topic的所有分區(qū)達(dá)成共識(shí)的過程,在Rebalance過程中,所有Consumer實(shí)例都會(huì)停止消費(fèi),等待Rebalance的完成。因?yàn)橐V瓜M(fèi)等待重平衡完成,因此Rebalance會(huì)嚴(yán)重影響消費(fèi)端的TPS,是應(yīng)當(dāng)盡量避免的。
觸發(fā)Rebalance的時(shí)機(jī)
Rebalance 的觸發(fā)條件有3個(gè)。
消費(fèi)組成員個(gè)數(shù)發(fā)生變化。例如有新的Consumer實(shí)例加入或離開該消費(fèi)組。
訂閱的 Topic 個(gè)數(shù)發(fā)生變化。
訂閱 Topic 的分區(qū)數(shù)發(fā)生變化。
Rebalance 發(fā)生時(shí),Group 下所有Consumer 實(shí)例都會(huì)協(xié)調(diào)在一起共同參與,kafka 能夠保證盡量達(dá)到最公平的分配。但是 Rebalance 過程對 consumer group 會(huì)造成比較嚴(yán)重的影響。在 Rebalance 的過程中 consumer group 下的所有消費(fèi)者實(shí)例都會(huì)停止工作,等待 Rebalance 過程完成。
Rebalance過程
Rebalance過程分為兩步:Join和Sync。
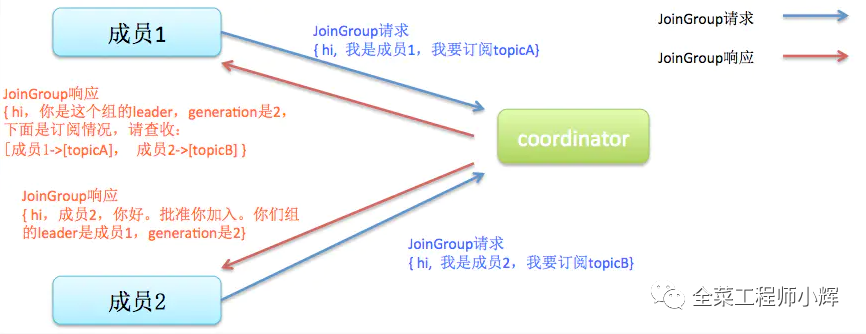
Join。所有成員都向Group Coordinator發(fā)送JoinGroup請求,請求加入消費(fèi)組。一旦所有成員都發(fā)送了JoinGroup請求,Coordinator會(huì)從中選擇一個(gè)Consumer擔(dān)任leader的角色,并把組成員信息以及訂閱信息發(fā)給leader——注意leader和coordinator不是一個(gè)概念。leader負(fù)責(zé)消費(fèi)分配方案的制定。
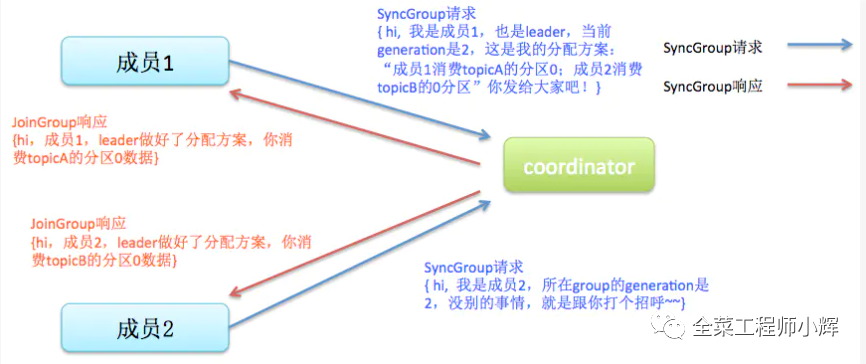
Sync。這一步leader開始分配消費(fèi)方案,即哪個(gè)consumer負(fù)責(zé)消費(fèi)哪些topic的哪些partition。一旦完成分配,leader會(huì)將這個(gè)方案封裝進(jìn)SyncGroup請求中發(fā)給coordinator,非leader也會(huì)發(fā)SyncGroup請求,只是內(nèi)容為空。coordinator接收到分配方案之后會(huì)把方案塞進(jìn)SyncGroup的response中發(fā)給各個(gè)consumer。這樣組內(nèi)的所有成員就都知道自己應(yīng)該消費(fèi)哪些分區(qū)了。
避免不必要的Rebalance
前面說過Rebalance發(fā)生的時(shí)機(jī)有三個(gè),后兩個(gè)時(shí)機(jī)是可以人為避免的。發(fā)生Rebalance最常見的原因是消費(fèi)組成員個(gè)數(shù)發(fā)生變化。
這其中消費(fèi)者成員正常的添加和停掉導(dǎo)致Rebalance,也是無法避免。但是在某些情況下,Consumer實(shí)例會(huì)被Coordinator錯(cuò)誤地認(rèn)為已停止從而被踢出Group。從而導(dǎo)致rebalance。
這種情況可以通過Consumer端的參數(shù)session.timeout.ms和max.poll.interval.ms進(jìn)行配置。
有關(guān)這種情況,可以查看博客《一文理解Kafka重復(fù)消費(fèi)的原因和解決方案》
除了這個(gè)參數(shù),Consumer還提供了控制發(fā)送心跳請求頻率的參數(shù),就是heartbeat.interval.ms。這個(gè)值設(shè)置得越小,Consumer實(shí)例發(fā)送心跳請求的頻率就越高。頻繁地發(fā)送心跳請求會(huì)額外消耗帶寬資源,但好處是能夠更快地知道是否開啟Rebalance,因?yàn)镃oordinator通知各個(gè)Consumer實(shí)例是否開啟Rebalance就是將REBALANCE_NEEDED標(biāo)志封裝進(jìn)心跳請求的響應(yīng)體中。
總之,要為業(yè)務(wù)處理邏輯留下充足的時(shí)間使Consumer不會(huì)因?yàn)樘幚磉@些消息的時(shí)間太長而引發(fā)Rebalance,但也不能時(shí)間設(shè)置過長導(dǎo)致Consumer宕機(jī)但遲遲沒有被踢出Group。
補(bǔ)充
Kafka控制器的作用
Kafka控制器的作用是管理和協(xié)調(diào)Kafka集群,具體如下:
主題管理:創(chuàng)建、刪除Topic,以及增加Topic分區(qū)等操作都是由控制器執(zhí)行。
分區(qū)重分配:執(zhí)行Kafka的reassign腳本對Topic分區(qū)重分配的操作,也是由控制器實(shí)現(xiàn)。
Preferred leader選舉。
因?yàn)樵贙afka集群長時(shí)間運(yùn)行中,broker的宕機(jī)或崩潰是不可避免的,leader就會(huì)發(fā)生轉(zhuǎn)移,即使broker重新回來,也不會(huì)是leader了。在眾多l(xiāng)eader的轉(zhuǎn)移過程中,就會(huì)產(chǎn)生leader不均衡現(xiàn)象,可能一小部分broker上有大量的leader,影響了整個(gè)集群的性能,所以就需要把leader調(diào)整回最初的broker上,這就需要Preferred leader選舉。
集群成員管理:控制器能夠監(jiān)控新broker的增加,broker的主動(dòng)關(guān)閉與被動(dòng)宕機(jī),進(jìn)而做其他工作。這也是利用Zookeeper的ZNode模型和Watcher機(jī)制,控制器會(huì)監(jiān)聽Zookeeper中/brokers/ids下臨時(shí)節(jié)點(diǎn)的變化。
數(shù)據(jù)服務(wù):控制器上保存了最全的集群元數(shù)據(jù)信息,其他所有broker會(huì)定期接收控制器發(fā)來的元數(shù)據(jù)更新請求,從而更新其內(nèi)存中的緩存數(shù)據(jù)。
Kafka協(xié)調(diào)器
Kafka中主要有兩種協(xié)調(diào)器:
組協(xié)調(diào)器(Group Coordinator)
消費(fèi)者協(xié)調(diào)器(Consumer Coordinator)
Kafka為了更好的實(shí)現(xiàn)消費(fèi)組成員管理、位移管理以及Rebalance等,broker服務(wù)端引入了組協(xié)調(diào)器(Group Coordinator),消費(fèi)端引入了消費(fèi)者協(xié)調(diào)器(Consumer Coordinator)。
每個(gè)broker啟動(dòng)時(shí),都會(huì)創(chuàng)建一個(gè)組協(xié)調(diào)器實(shí)例,負(fù)責(zé)監(jiān)控這個(gè)消費(fèi)組里的所有消費(fèi)者的心跳以及判斷是否宕機(jī),然后開啟消費(fèi)者Rebalance。
每個(gè)Consumer啟動(dòng)時(shí),會(huì)創(chuàng)建一個(gè)消費(fèi)者協(xié)調(diào)器實(shí)例并會(huì)向Kafka集群中的某個(gè)節(jié)點(diǎn)發(fā)送FindCoordinatorRequest請求來查找對應(yīng)的組協(xié)調(diào)器,并跟其建立網(wǎng)絡(luò)連接。
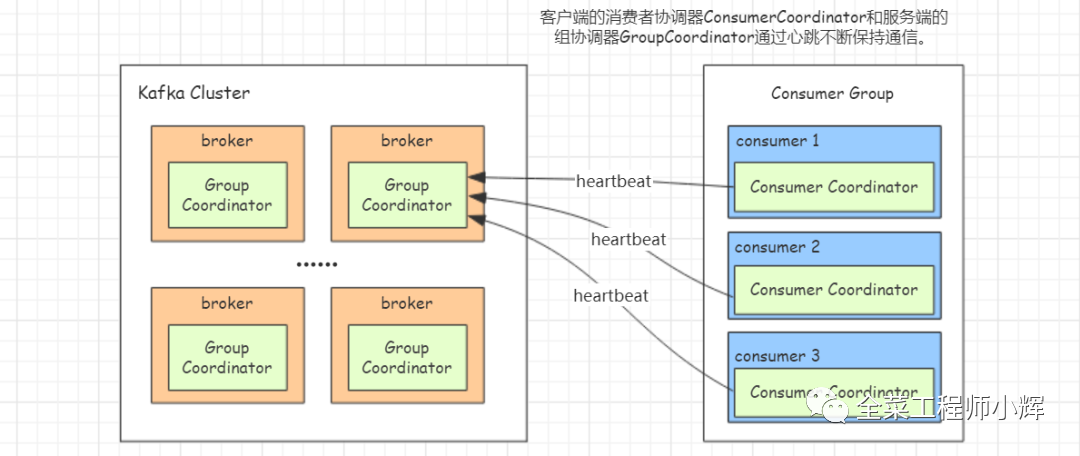
客戶端的消費(fèi)者協(xié)調(diào)器和服務(wù)端的組協(xié)調(diào)器會(huì)通過心跳保持通信。
Kafka舍棄ZooKeeper的理由
Kafka目前強(qiáng)依賴于ZooKeeper:ZooKeeper為Kafka提供了元數(shù)據(jù)的管理,例如一些Broker的信息、主題數(shù)據(jù)、分區(qū)數(shù)據(jù)等等,還有一些選舉、擴(kuò)容等機(jī)制也都依賴ZooKeeper。
運(yùn)維復(fù)雜度
運(yùn)維Kafka的同時(shí)需要保證一個(gè)高可用的Zookeeper集群,增加了運(yùn)維和故障排查的復(fù)雜度。
性能差
在一些大公司,Kafka集群比較大,分區(qū)數(shù)很多的時(shí)候,ZooKeeper存儲(chǔ)的元數(shù)據(jù)就會(huì)很多,性能就會(huì)變差。
ZooKeeper需要選舉,選舉的過程中是無法提供服務(wù)的。
Zookeeper節(jié)點(diǎn)如果頻繁發(fā)生Full Gc,與客戶端的會(huì)話將超時(shí),由于無法響應(yīng)客戶端的心跳請求,從而與會(huì)話相關(guān)聯(lián)的臨時(shí)節(jié)點(diǎn)也會(huì)被刪除。
所以Kafka 2.8版本上支持內(nèi)部的quorum服務(wù)來替換ZooKeeper的工作。