
前端正則進階篇,高薪必看【超詳細】

閑談
說起正則 大家第一反應肯定是各種表單驗證 什么用戶名 密碼 郵箱... 的確 前端使用正則進行用戶輸入驗證是最常見的場景 但是我相信大多數(shù)的前端都忽略了正則這一塊的知識點 和我一樣 Ctrl+c Ctrl+v 各種正則表達式就到手了
哈哈 直到我看 Vue 源碼-模板解析這塊正則時 我的內(nèi)心是崩潰的(這是什么火星文) 既如此那就讓我們代表月亮消滅它
vue源碼-解析屬性相關(guān)正則
/^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
1 正則表達式 是什么
答:正則表達式就是處理字符串的
如何處理呢?
正則表達式(regular expression)描述了一種字符串匹配的模式,可以用來檢查一個字符串是否含有某種子串、將匹配的子串做替換或者從某個字符串中取出符合某個條件的子串等。
記住兩個關(guān)鍵作用:
1.搜索字符串 2.替換字符串
2 正則表達式 怎樣創(chuàng)建
方法一:字面量方式
語法格式為: /正則表達式主體/修飾符(可選)
const reg = /\d/gi;
方法二:構(gòu)造函數(shù)
語法格式為:new RegExp(正則表達式主體[, 修飾符])
const reg = new RegExp('\d', 'gi')
對比:字面量方式更簡潔效率更高 但是無法拼接變量
常用_修飾符_如下
| 修飾符 | 作用 |
|---|---|
| i | 忽略大小寫匹配 |
| g | 全局匹配,即是匹配一個后繼續(xù)匹配,直到結(jié)束 |
| m | 多行匹配,即是遇到換行后不停止匹配,直到結(jié)束 |
3 正則表達式語法
3.1 字符集合與范圍類[ ]

“
字符集合和范圍類都是使用中括號[]定義的 區(qū)別:范圍類在中括號[]里面是用短橫線-連接(左邊的要小于右邊的 不然會報錯)
3.2 預定義元字符類
| 代碼 | 說明 |
|---|---|
| . | 匹配任意單個字符,除換行和結(jié)束符 |
| \d | 匹配數(shù)字,等價于 [0-9] |
| \D | 匹配非數(shù)字,等價于 [^0-9] |
| \s | 匹配空白字符 主要有(\n、\f、\r、\t、\v) |
| \S | 匹配非空白字符 |
| \w | 匹配任意單詞字符(數(shù)字、字母、下劃線),等價于[A-Za-z0-9_] |
| \W | 匹配任意非單詞字符,與\w 相反,等價于[^a-za-z0-9_] |
3.3 邊界類
| 代碼 | 說明 | 舉例 |
|---|---|---|
| ^ | 匹配字符串的開始 | /^a/匹配"an A",而不匹配"An a" |
| $ | 匹配字符串的結(jié)束 | /a$/匹配"An a",而不匹配"an A" |
| \b | 匹配單詞的開始或結(jié)束 | /\bno/ 匹配 "at noon" 中的 "no" |
3.4 量詞類
| 代碼 | 說明 |
|---|---|
| * | 重復零次或更多次 |
| + | 重復一次或更多次(至少有一次) |
| ? | 重復零次或一次(可有可無) |
| {n} | 重復 n 次 |
| {n,m} | 至少 n 次最多 m 次 |
| {n,} | 至少 n 次 |
3.5 特殊符號類
| 代碼 | 說明 | 舉例 |
|---|---|---|
| / | 字面量方式聲明正則時的界定符 | /xxx/ |
| \ | 對正則表達式功能字符的還原 | ?匹配它前面元字符 0 次或 1 次,/ba?/將匹配 b,ba,加了\后,"/ba\?"/將只匹配"ba?" |
| a |
3.6 捕獲分組與非捕獲分組( )
捕獲分組(x) 匹配 x 并且捕獲匹配項
例如:/(foo)/ 匹配且捕獲 "foo bar" 中的 "foo"。被匹配的子字符串可以通過 元素[n] 中找到,或 RegExp 對象的屬性 $n 中找到
`"foo bar".match(/(foo)\s+bar/)`
`// ["foo bar", "foo"]`
非捕獲分組(?:x) 匹配 x 不會捕獲匹配項。匹配項不能夠從結(jié)果再次訪問
`"foo bar".match(/(?:foo)\s+bar/)`
`// ["foo bar"]`
“
上面的例子看上去非捕獲分組貌似沒什么用 其實它的用處很大 我們看看下面的例子
希望匹配字母,且字母之間可以為1或2時,但最終結(jié)果不需要中間的數(shù)字 只需要兩邊的字母
'abcd1j452h'.match(/[a-z]+(1|2)+([a-z]+)/);
["abcd1j", "1", "j"] //不使用非捕獲分組 會把中間數(shù)字1也放入結(jié)果
'abcd1j452h'.match(/[a-z]+(?:1|2)+([a-z]+)/);
["abcd1j", "j"] //這樣才完成需求
3.7 貪婪與非貪婪模式
默認使用貪婪模式 盡可能多的匹配
在重復量詞后面加一個?,代表使用非貪婪模式,盡可能短的匹配
`"1234567".match(/\d{2,5}/)
//默認貪婪模式(盡可能匹配多)
[12345]`
`"1234567".match(/\d{2,5}?/)
//轉(zhuǎn)成非貪婪模式
[12]`
3.8 正向肯定查找和正向否定查找
| 代碼 | 說明 |
|---|---|
| x(?=y) | 只有當 x 后面緊跟著 y 時,才匹配 x。 |
| x(?!y) | 只有當 x 后面不是緊跟著 y 時,才匹配 x。 |
`const target = 'bg.png index.html app.js index.css test.png'
//從以上字符串中找出以png結(jié)尾的文件名
//不使用正向肯定查找的做法
target.match(/\b(\w+)\.png/g)
//["bg.png", "test.png"] 我們只想要文件名 不想要.png后綴`
`使用正向肯定查找
target.match(/\b(\w+)(?=\.png)/g)
// ["bg", "test"]`
“
注意:x(?=y)需要和非捕獲分組(?:)區(qū)分開(寫法很類似) 其次 x(?=y)最終匹配結(jié)果只有 x 沒有 y
4 正則實例屬性
RegExp.prototype.global 是否開啟全局匹配
RegExp.prototype.ignoreCase 是否要忽略字符的大小寫
RegExp.prototype.lastIndex 下次匹配開始的字符串索引位置
RegExp.prototype.multiline 是否開啟多行模式匹配(影響 ^ 和 $ 的行為)
RegExp.prototype.source 正則對象的源模式文本
RegExp.prototype.sticky 是否開啟粘滯匹配
5 正則實例方法
5.1 test
語法:regObj.test(str) 對字符串執(zhí)行搜索
返回值:布爾值。測試 str 中是否存在匹配 regObj 模式的字符串,存在返回 true,不存在返回 false
“
用法很簡單 但是有坑點 該方法在正則對象是否帶有全局屬性(g)下的表現(xiàn)不同
先介紹下正則對象的 lastIndex 屬性,lastIndex 是正則表達式匹配內(nèi)容時,開始匹配的位置。
不帶全局屬性 g
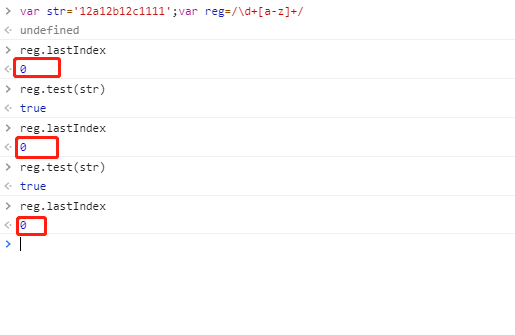
由上可見:剛開始都是從下標 0 處開始匹配,不帶 g 時,無論執(zhí)行多少次,該正則對像的 lastIndex 屬性均不變
帶全局屬性 g
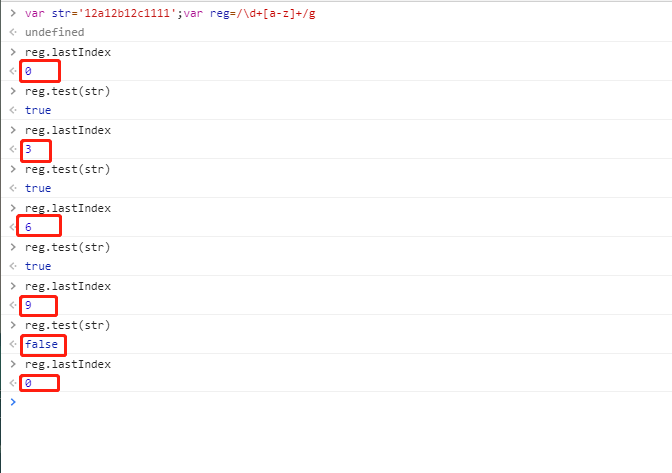
由上可見:該開始從下標為 0 處開始匹配,匹配后會自動修改該正則對象的 lastIndex 屬性,且修改為當前表達式匹配內(nèi)容的最后一個字符的下一個位置。一直到字符串結(jié)尾,重新設(shè)置 lastIndex 為 0。可見其中有一次匹配失敗了 因為從 lastIndex 為 9 開始繼續(xù)查找就沒有匹配的結(jié)果了 這一點一定要注意
5.2 exec
語法:regObj.exec(str)對字符串執(zhí)行搜索
返回值:如果沒有匹配的文本則返回 null,否則返回一個結(jié)果數(shù)組:
返回的數(shù)組:第一個元素與正則表達式相匹配的文本;第二個元素是與 RegExpObject 的第一個捕獲組相匹配的文本(如果有的話);第三個元素是與 RegExpObject 的第二個捕獲組相匹配的文本(如果有的話),以此類推。
“
該方法在正則對象是否帶有全局屬性(g)下的表現(xiàn)不同 其表現(xiàn)和 test 一致
不帶 g 時

帶 g 時

6 字符串實例方法
6.1 search
語法:str.search(reg)找出首次匹配項的索引
返回值:返回匹配成功的第一個位置,如果沒有任何匹配,則返回-1
'abc'.search(/b/)
//1
6.2 split
語法:str.split(reg[,maxLength]) 第一個參數(shù)可以是字符串或者正則表達式,它是分隔符;第二個參數(shù)可選,限制返回數(shù)組的最大長度。
返回值:數(shù)組
'abc-def_mno+xyz'.split(/[-_+]/, 3);
//["abc", "def", "mno"]
6.3 match
語法:str.match(reg)找到一個或多個正則表達式的匹配
返回值:數(shù)組或者 null
“
該方法在正則對象是否帶有全局屬性(g)下的表現(xiàn)不同
不帶 g 時(只查找一次 遇到匹配之后就停止 返回結(jié)果和 exec 方法一致)
var str='12a12b12c1111';
var reg=/\d+([a-z]+)/;
str.match(reg)
//["12a", "a", index: 0, input: "12a12b12c1111", groups: undefined]
帶 g 時(全局檢索 如果找到了一個或多個匹配字符串,則返回一個數(shù)組--不包含捕獲組)
var str='12a12b12c1111';
var reg=/\d+([a-z]+)/g;
str.match(reg)
//["12a", "12b", "12c"]
6.4 replace
語法:str.replace(reg/substr,newStr/function) 第一個參數(shù)可以是字符串或者正則表達式,它的作用是匹配。第二個參數(shù)可以是字符串或者函數(shù),它的作用是替換。
返回值:替換了之后的新的字符串,原字符串不變
第一個參數(shù)是字符串和正則表達式的區(qū)別在于:正則表達式的表達能力更強,而且可以全局匹配。因此參數(shù)是字符串的話只能進行一次替換。
`'abc-xyz-abc'.replace('abc', 'biu');
// "biu-xyz-abc"`
`'abc-xyz-abc'.replace(/abc/g, 'biu');
// "biu-xyz-biu"`
第二個參數(shù)是字符串時
replace 方法為第二個參數(shù)是字符串的方式提供了一些特殊的變量,能滿足一般需求。
$ 數(shù)字代表相應順序的捕獲組。注意,雖然它是一個變量,但是不要寫成模板字符串${$1}biu,replace 內(nèi)部邏輯會自動解析字符串,提取出變量。
var reg=/(\d{2})\/(\d{2})\/(\d{4})/
var str='09/05/2020'
var res=str.replace(reg,'$3-$2-$1') // 2020-05-09
第二個參數(shù)是函數(shù)時
字符串的變量畢竟只能引用,無法操作。與之相對,函數(shù)的表達能力就強多了。
函數(shù)的返回值就是要替換的內(nèi)容。函數(shù)如果沒有返回值,默認返回undefined,所以替換內(nèi)容就是 undefined。
先看例子
var str='a1b2c3d4e'
var result=str.replace(/(\d)(\w)(\d)/g,(matchStr,group1,group2,group3,index,originStr)=>{
return group1+group3
}) //'a12c34e'
第一個參數(shù) matchStr 是匹配結(jié)果 第二個參數(shù)以及到倒數(shù)第二個參數(shù)為止 如果有捕獲組,函數(shù)的后順位參數(shù)與捕獲組一一對應。例如我們例子里面的 group1 到 group3 倒數(shù)第二個參數(shù)是匹配結(jié)果在文本中的位置 最后一個參數(shù)是源文本
ok 我們分析一下例子
第一次查找匹配到'1b2' 然后我們 return group1+group3 group1 是第一個捕獲組 就是 1 group3 是第三個捕獲組 2 字符串'1'+'2'就是'12' 所以用 12 替換了'1b2' 第一次替換之后的結(jié)果就是'a12' 然后繼續(xù)向后查找將'3d4'替換成'34' 最終結(jié)果就是'a12c34e'
原文地址
https://juejin.cn/post/6844904153131515912