
MySql中當(dāng)in或or參數(shù)過多時導(dǎo)致索引失效
今天的文章很短只講一件事情,但發(fā)現(xiàn)很多同學(xué)還不知道,以至于引發(fā)一些數(shù)據(jù)庫使用層面的慢查詢、訪問超時問題。
mysql有個閾值,決定了閾值之下使用索引查詢,而超過閾值則退化,優(yōu)化器選擇索引下潛,進而引起iops過高或者慢查詢問題,導(dǎo)致超時。
大家一定要記著:MySQL優(yōu)化器決定使用某個索引執(zhí)行查詢的僅僅是因為:使用該索引時的成本足夠低。也就是說即使我們有下邊的語句:
SELECT?*?FROM?t?WHERE key1?IN?('b',?'c');MySQL優(yōu)化器需要去分析一下如果使用二級索引idx_key1執(zhí)行查詢的話,鍵值在['b', 'b']和['c', 'c']這兩個范圍區(qū)間的記錄共有多少條,然后通過一定方式計算出成本,與全表掃描的成本相對比,選取成本更低的那種方式執(zhí)行查詢。
MySQL優(yōu)化器針對IN子句對應(yīng)的范圍區(qū)間的多少而指定了不同的策略:
如果IN子句對應(yīng)的范圍區(qū)間比較少,那么將率先去訪問一下存儲引擎,看一下每個范圍區(qū)間中的記錄有多少條(如果范圍區(qū)間的記錄比較少,那么統(tǒng)計結(jié)果就是精確的,反之會采用一定的手段計算一個模糊的值,當(dāng)然算法也比較麻煩),這種在查詢真正執(zhí)行前優(yōu)化器就率先訪問索引來計算需要掃描的索引記錄數(shù)量的方式稱之為index dive。
如果IN子句對應(yīng)的范圍區(qū)間比較多,這樣就不能采用index dive的方式去真正的訪問二級索引idx_key1(因為那將耗費大量的時間),而是需要采用之前在背地里產(chǎn)生的一些統(tǒng)計數(shù)據(jù)去估算匹配的二級索引記錄有多少條(很顯然根據(jù)統(tǒng)計數(shù)據(jù)去估算記錄條數(shù)比index dive的方式精確性差了很多)。
那什么時候采用index dive的統(tǒng)計方式,什么時候采用index statistic的統(tǒng)計方式呢?
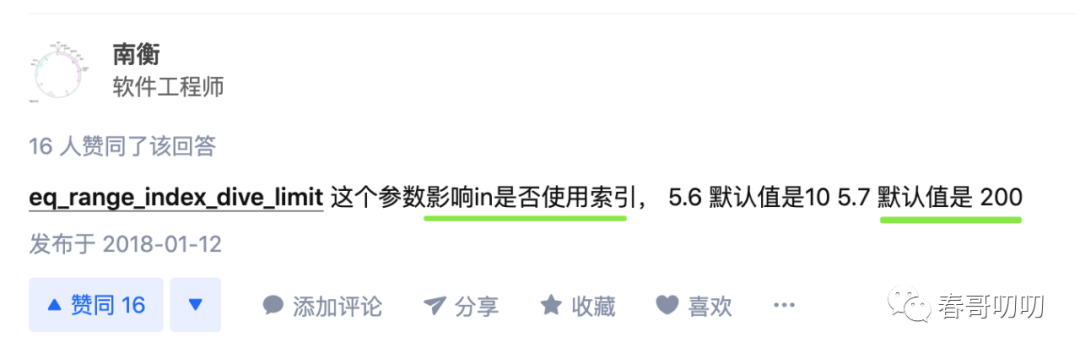
這就取決于我們要說的系統(tǒng)變量eq_range_index_dive_limit的值了。
這個值在5.6版本默認(rèn)是10,5.7版本默認(rèn)是200,如下圖:
ep_range_index_dive_limit參數(shù)提供一個閾值,優(yōu)化器在預(yù)估掃描行數(shù)時,會根據(jù)這個參數(shù),來進行預(yù)估策略。通常優(yōu)化器有兩種預(yù)估策略:索引統(tǒng)計和索引下潛。
1、當(dāng)?shù)陀趀q_range_index_dive_limit參數(shù)閥值時,采用index dive方式預(yù)估影響行數(shù),該方式優(yōu)點是相對準(zhǔn)確,但不適合對大量值進行快速預(yù)估。2、當(dāng)大于或等于eq_range_index_dive_limit參數(shù)閥值時,采用index statistics方式預(yù)估影響行數(shù),該方式優(yōu)點是計算預(yù)估值的方式簡單,可以快速獲得預(yù)估數(shù)據(jù),但相對偏差較大。
在eq_range_index_dive_limit設(shè)置過小且索引分布極不均勻的情況下,MySQL可能會由于成本計算誤差太大,導(dǎo)致選擇錯誤的執(zhí)行計劃這一災(zāi)難性后果!
簡單理解:
參數(shù)超過閾值,會導(dǎo)致索引退化,索引失效。此規(guī)則適用于in、or:
col_name IN(val1, …, valN)col_name = val1 OR … OR col_name = valN
怎么解決呢?
簡單來說,就是我們需要控制in、or語句中的參數(shù)個數(shù),閾值是200,但是我們代碼更傾向于控制在50內(nèi),也就是說我們需要有機制識別與控制(cr方式、組件攔截方式、編碼規(guī)范等)避免類似的風(fēng)險被觸發(fā),而不是完全無視,極致一些,只要是in場景,就需要加limit限制。
希望對你有用。